






1.项目背景:
首先,整个项目的灵感源于一档名为《十字路口》的播客中分享的“2024年最令人惊艳的十大AI落地项目”之一。项目详情如下:
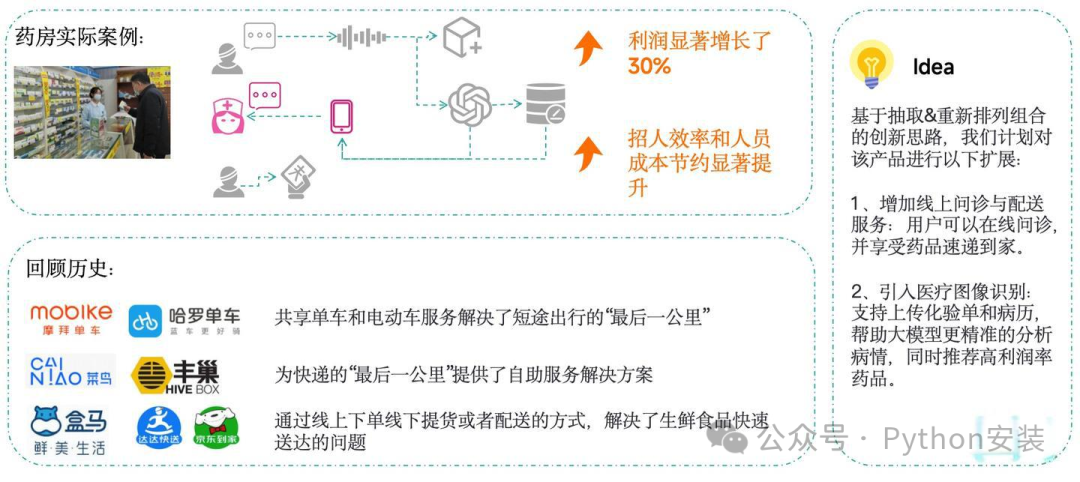
某全国万店连锁药房推出驻店销售APP,可对到店客户的病情描述进行录音并转为文字输入大模型。大模型输出对应药品介绍及推销文案,辅助销售人员完成高利润药品的推荐。
与传统AI辅助应用不同,该APP专门针对利润较高的药品设计推荐逻辑,同时通过自然流畅的交互设计降低顾客的推销感知。例如,销售人员会以“帮您查询最新会员优惠信息”等话术解释操作,在维护顾客信任的同时,提升互动质量。
公开数据显示,引入该APP后,连锁药店利润显著增长30%。值得关注的是,药品行业中价格与利润并非正相关,因此模型的推荐策略设计尤为关键。此外,APP降低了对销售人员专业背景的依赖,简化招聘流程的同时有效压缩人力成本,为连锁药店创造了更多成本优化空间与发展机遇。
然后我们团队又回顾了一下,中国近10年的互联网发展史。发现我们非常善于解决老百姓最后X公里这件事。
例如:
- 共享单车:满足了短途出行需求,尤其在城市场景下,助力人们轻松实现从公共交通站点到目的地的“最后一公里”衔接。
- 三通一达&京东快递:这些物流企业依托高效配送网络,打通了从城市电商仓库或站点到消费者家门口的“最后五公里”配送链路,大幅提升了网购商品送达的便利性。
- 各类外卖平台:以美团、饿了么为例,其服务范畴不仅涵盖便捷的餐食配送,还延伸至日用品、药品等多品类的即时配送领域,极大丰富了消费者的生活选择,压缩了等待时长,让“足不出户享尽各类服务”成为现实。
最后,我们开动脑洞,发现能不能这个真实的案例之上,做一层扩展呢。然后我又做了一个用户场景的分析,如下所示:
到此,我们基本就敲定了,模拟一个线上问诊,购药的APP。在保证推荐高利润药品的同时,解决最后的配送问题。
2.技术架构及选型:
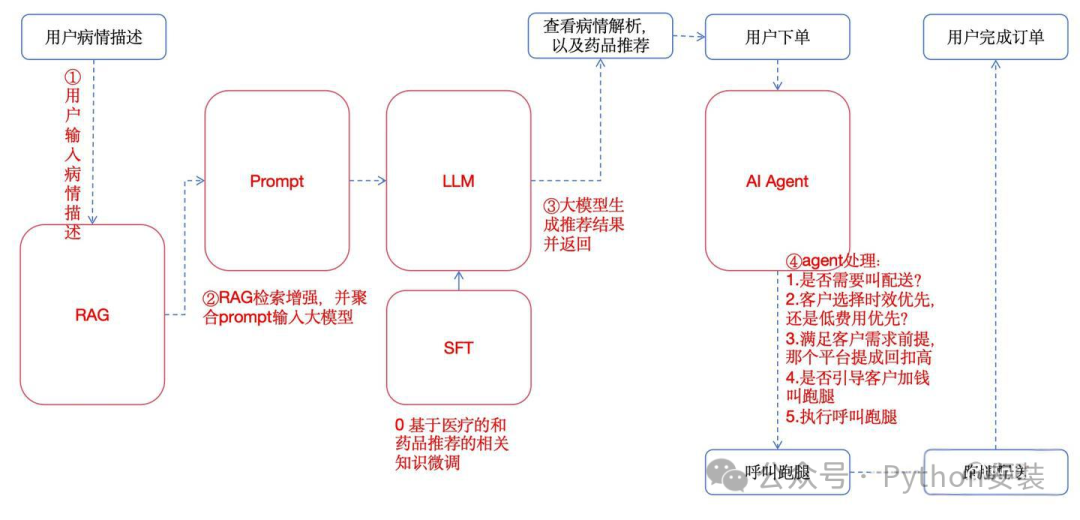
最初版本的产品核心架构
在项目开始之初,我们的思路是:
首先,用户输入病情描述,随后经RAG检索增强并结合prompt输入大模型,生成推荐结果。接着,用户查看病情解析和药品推荐后下单购买药品。最后,用户完成订单。在此流程中,AI Agent会处理若干特定问题,例如是否需要呼叫配送、客户选择时效优先还是低费用优先、哪个平台提成回扣较高等。若有需要,还将执行呼叫跑腿和跑腿配送操作。
从中可见,我们本意是借助Agent进行一些判断,同时将获取各平台跑腿价格和下单接口封装为工具。然而,由于Agent的推理本质上也是通过Prompt实现的,且Prompt由人工编写,这意味着需要反复调整,同时推理结果存在不稳定性。这会大幅增加整个项目的集成复杂度,且在时间有限的情况下,我们最终放弃了Agent方案。
随后确定了以下版本的技术架构方案:
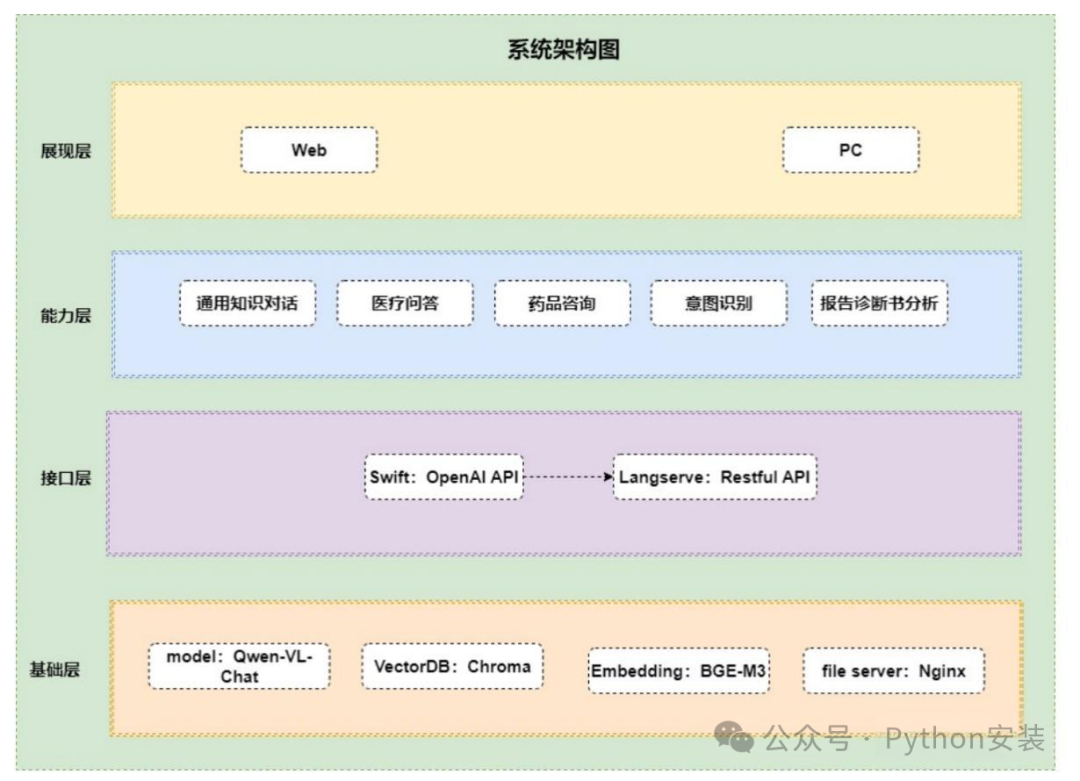
最终敲定版本的技术架构图
基础层:以Qwen - VL - Chat作为大模型底座,借助其多模态能力达成医疗图像的识别与解答。同时选取BGE - M3作为向量模型,Chroma数据库作为向量数据库,用以搭建药品和医疗知识补充的知识库。最后运用Nginx进行请求映射。
接口层:采用Swift:OpenAI API与LangServe:Restful API,发挥承上启下的作用,实现大模型与业务能力的串联整合。
能力层:打造“通用知识对话”“医疗问答”“药品咨询”“意图识别”“报告诊断书识别”等能力。
展现层:通过PC、Web展示Demo最终效果。
3.多模态模型微调:
这次比赛项目,我们为了保险起见采用了双轨机制。一组使用Qwen-VL-Chat进行微调,另一组使用LLaVA1.5-7b-hf进行微调(选择7b是因为算力有限,实属无奈)。后边会分别介绍两组的微调过程和结果分析说明:
3.1 Qwen-VL-Chat 微调
采用了魔搭推荐的SWIFT框架进行微调,微调方式为LoRA,同时使用了transformer中默认的计算QKV大矩阵的训练的方式。
^( t r a n s f o r m e r . h )( ? ! .*( l m _ h e a d | o u t p u t | e m b | w t e | s h a r e d )).*
(1)为了不出现因为专业能力提升,导致通识能力大步退化,甚至出现灾难性遗忘。在微调时也插入了一部分通识数据,包括:
alpaca-zh(中文版的Alpaca数据集),
alpaca-cleaned(Alpaca数据集的清理版本。原始的Alpaca数据集可能包含一些噪声和不规范的数据,)
sharegpt-gpt4(由社区贡献的GPT-4模型的训练数据集,包含了大量高质量的文本数据,用于训练和微调GPT-4模型),
swift-mix(是一个混合数据集,通常用于训练和微调Swift框架下的模型。包含了多种类型的数据,如文本、图像、音频等,旨在提供一个综合性的训练数据集。)
注:由于Qwen-VL-Chat是一个多模态大模型,所以在补充了基本预料数据集以外,还补充了swift-mix这种混合数据集。以此来保障其多模态的通识能力。
(2)医疗专业数据补充,基于medical-zh-instruct、Chinese-medical-dialogue、ChatMed_Consult_Dataset、disc-med-sft-zh(多轮对话)、UCSD26(多轮对话)、llava-med-zh-instruct(图文)数据集抽样40W数据进行微调。
相关微调参数为:
–learning_rate 1e-4 --warmup_ratio 0.03 --max_length 2048 --batch_size 4 – weight_decay 0.1 --gradient_accumulation_steps 16
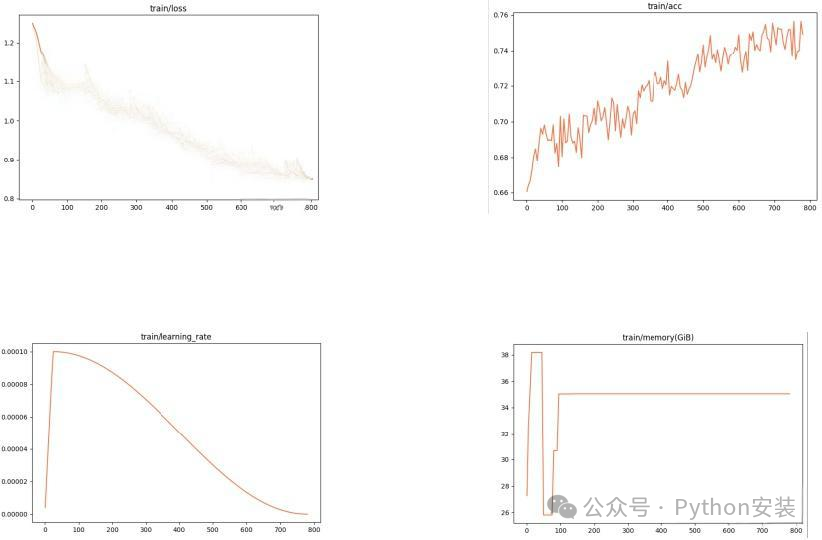
微调过程监控记录
在微调的过程中,训练损失(train/loss)虽然存在波动,但是整体上还是呈现下降趋势;训练准确率(train accuracy)也存在波动,但是整体上准确率还是呈现上升趋势。学习率(train learning rate)先从一个非常小的值逐渐达到峰值后降低,避免初期学习率过高导致模型不稳定。GPU内存使用量也是初始阶段呈上升趋势,达到约38G,然后保持稳定。

ARC_E 通用评测数据测评结果
在通用评测数据ARC_E上,qwen-vl-chat-sft(微调后)和qwen-vl-chat(微调前)分别取得了0.7259和0.7698的准确率,表明经过微调后的模型在原有通用能力上并没有太大的下降。
最后可以看一下微调效果对比:

微调后具备追问能力,同时回答的更加详细
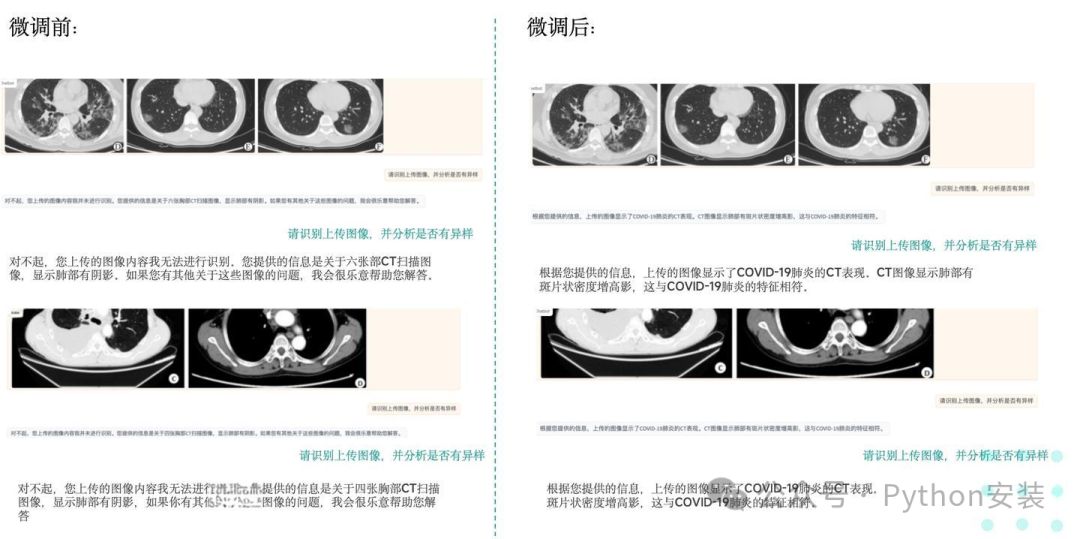
医疗图像微调前后效果比对
微调前,模型无法正确识别上传的CT图像,只能给出模糊的回答,如“抱歉,我无法识别这些图像”、“对不起,您上传的图像内并未包含识别到的信息”。
而微调后,模型能够正确识别出上传的CT图像显示的是COVID-19肺炎的症状,并给出了具体的解释:“CT图像显示肺部有斑片状密度增高影,这与COVID-19肺炎的特征相符。”
至此,经过了两轮的微调后,基本达到了作为本次项目底座的能力。
3.2 LLaVA 1.5 - 7b - hf 微调
同时我们也尝试了使用LLaVA1.5-7b-hf作为初始的通用领域多模态对话模型,再将模型训练到生物医学领域。对于基于LLaVA1.5-7b-hf的医疗大模型微调实践,共计尝试了3次微调。
本次使用了LLaMA-Factory框架进行微调,使用的数据集包括:
1)ava-med-zh-instruct-60k 包含60,000条中文指令,专门用于医疗领域的中文指令数据集
数据示例:
{
"instruction":"根据病历描述,给出初步诊断建议。",
"input":"患者主诉头痛,伴有恶心和呕吐,持续两天。",
"output":"初步诊断:偏头痛。建议进行头部CT检查以排除其他原因。"
}
2)PMC-15M 是一个包含1500万篇医学文献的数据集,这些文献来自PubMed Central(PMC),这是一个由美国国家医学图书馆(NLM)维护的免费全文生物医学和生命科学期刊数据库.
数据示例:
{
"pmcid":"PMC123456",
"title":"Effect of Exercise on Cardiovascular Health",
"abstract":"This study examines the impact of regular exercise on cardiovascular health in adults.",
"body":"Introduction: Regular physical activity has been shown to have numerous health benefits...",
"authors":["John Doe","Jane Smith"],
"journal":"Journal of Cardiology",
"year":2022,
"doi":"10.1001/jama.2022.12345",
"keywords":["exercise","cardiovascular health","physical activity"]
}
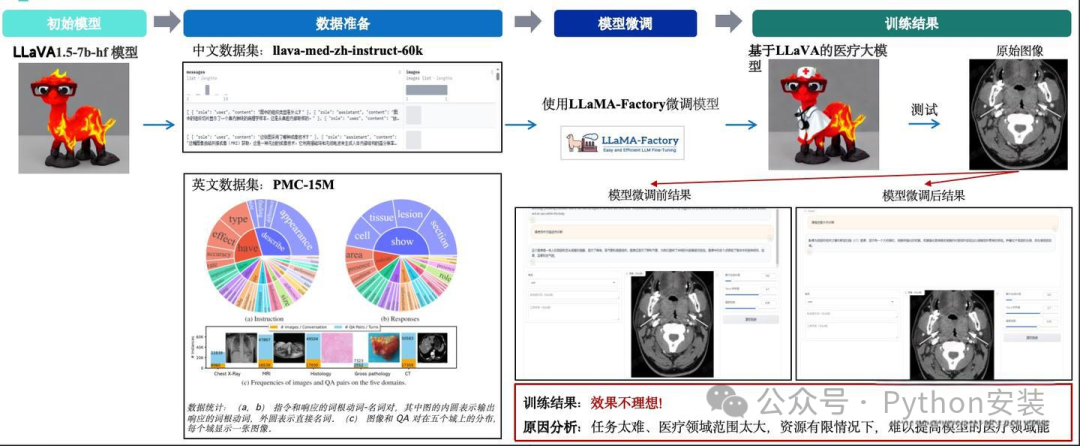
第一次微调过程及结果
其实第一次微调,也仅仅是使用一个中文数据集 & 一个英文医学论文库组成的数据集进行尝试。本来是计划根据第一次结果来调整后边的微调策略。但是第一次微调完成后,发现几乎是没有效果的。
于是就有第二次的尝试,增加了X-ray-6k(包含6000张胸部X光片)。并在Prompt上增加统一user的提问:‘根据X射线图像,分析心脏和肺部的情况’。
然而,在训练过程中,我们遇到了一些挑战:
- 模型看到输入的图片,无法理解,并一本正经胡说八道
- 出现灾难性遗忘
- 资源消耗过大
针对这些问题,我们进行了原因分析。发现特定任务微调后导致模型遵循通用指令能力变弱的主要原因是任务数据集的信息分布与原始LLM的信息分布之间存在差距。简单直白的说,就是模型被玩坏了…
最后,我进行第三次微调。
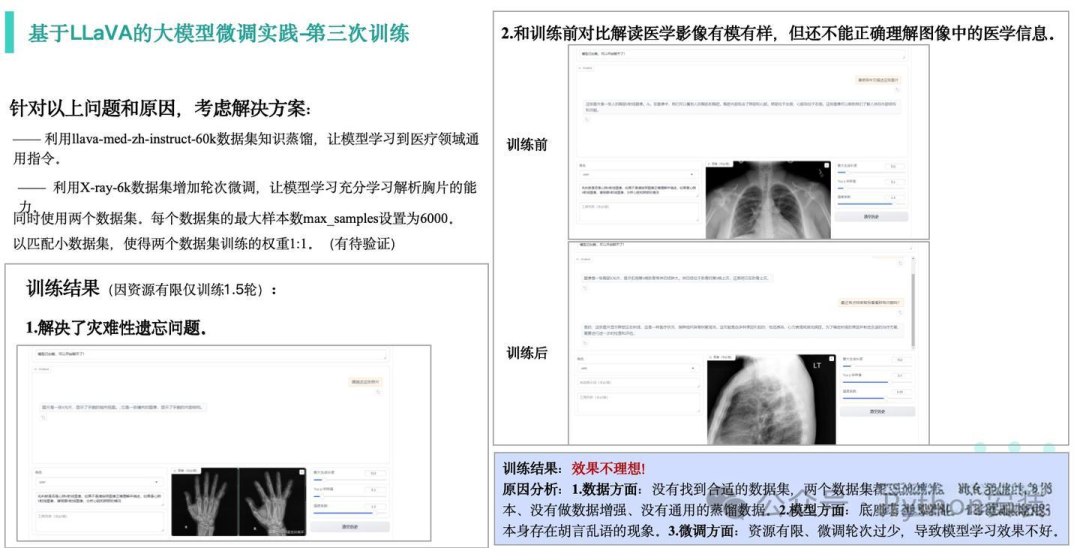
第三次微调过程及结果
第三次微调,在原来的基础上利用llava-med-zh-instruct-60k数据集的知识蒸馏,让模型学习医疗领域通用指令。使用X-ray-6k数据集增加轮次微调,使模型充分学习解剖胸片的能力。
时,为了匹配两个数据集,我们设置了每个数据集的最大样本数max_samples为6000,并保持了它们之间的权重平衡。
然后由于提供的孙阿里有限,我们只完成了1.5轮的训练。虽然解决了灾难性遗忘的问题,但在实际应用中仍存在问题。
由于比赛时间比较有限。我们直接选择Qwen-VL-Chat作为大模型底座,直接放弃LLaVA-1.5-7b微调的模型。不过通过这两次微调,我们也总结出来2个最核心的经验:
1) 数据集,非常重要。在微调前一定要多花时间精力找数据集。最好是在某个行业有比较好的认可性的,同时有足够的负样本、可以做数据增强、有通用的蒸馏数据的。不然很容易微调以后把模型玩坏。
2)模型选择,最好能结合清晰的目标选择模型,以及模型的大小。尽量在节约资源的情况下发挥不同类型(或不同大小)模型的最大能力。例如本次项目的LLaVA其实在选型的时候,团队还没有确定项目和场景。并且llava1.5-7b-hf模型不够强大,本身存在胡言乱语的现象。所以这个选择属实有点草率了。
4.RAG检索增强:
我们是在网上down了一些,医疗论文和相关药品说明的数据。然后通过BGE-3M模型Embedding后,存储到了一个Chroma DB中。
在RAG层面上,我们做了Multi - Query & ParentDocumentRetriever组合尝试。同时借鉴了ColBERT的思想,当需要更高粒度的嵌入时,对文档和查询中的每个标记使用受上下文影响的嵌入,以获得精细的查询-文档相似性分数。

同时,对于数据还做了一些传统数据加工工作,例如数据清洗 、 格式标准化 、 质量监控 、 反馈循环。这里就不再赘述了。
但是客观的说,整个RAG部分做的并不好,命中召回不高。截止在比赛答辩前其实也一直在尝试,但一直没有找到一个比较好的策略。
5.最终效果展示:
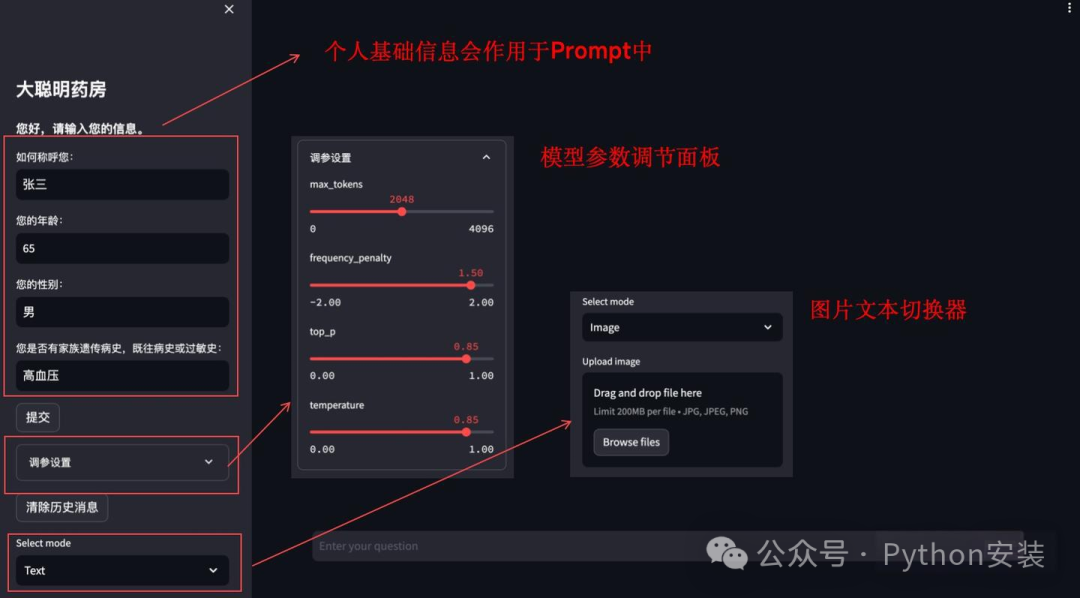
Demo 操作面板

演示效果 - 1
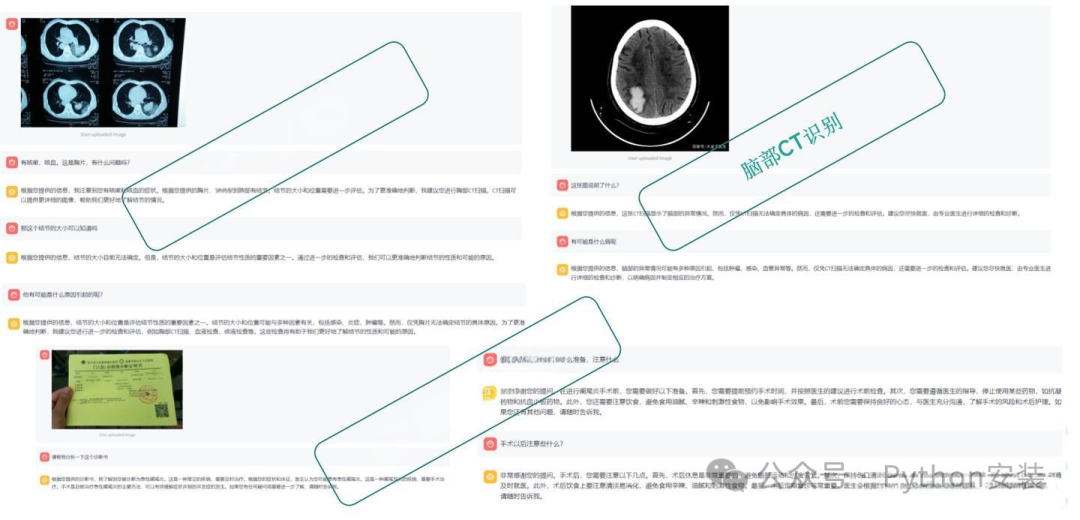
演示效果 - 2
最终在答辩前,其实是实现了最初的目标能力的。
1)药品推荐,可以根据症状描述推荐一些药物。但是推荐药品的重复率非常高。
2)医疗咨询,可以做简单的医疗问题回答,并回答基本病理。
3)英文问答,由于Qwen-VL-Chat在微调时,数据集比较全面和均衡,包含一部分英文数据集。所以在英文文档方面表现还算不错。
4)医疗影像识别,对于骨折,CT阴影都可以很好的识别到。但是具体病症存在胡说八道的情况,例如骨折位置说错,将新冠肺炎的胸片表现说成是肺结核。不过你用现在的通义千问去试效果也是一样的。可能医学领域确实比较复杂吧。我其实也不知道现在有哪家这方面可以做的非常好的,之前调研过一个百度的(百度AI用药助手),连医学影像识别能力都没有。讯飞晓医的小程序也一样,只能上传药盒或者药品说明书,并不支持医疗图像。或者说这个领域是不是都是专业的模型提供商,并没有很好的开源产品,有知道的大佬也可以给我留言,解答一下我的疑惑。
5)诊断书/病例识别,对于诊断书,病例,血常规可以做好比较好的识别。但在推荐药品时,也是胡乱推荐,或一直推荐重复的药品。
6)能力组合,对于一个复杂的对话,其实可以看到整个能力链 医疗图像识别 --> 症状追问 --> 药品推荐。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









