







java输入与输出
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
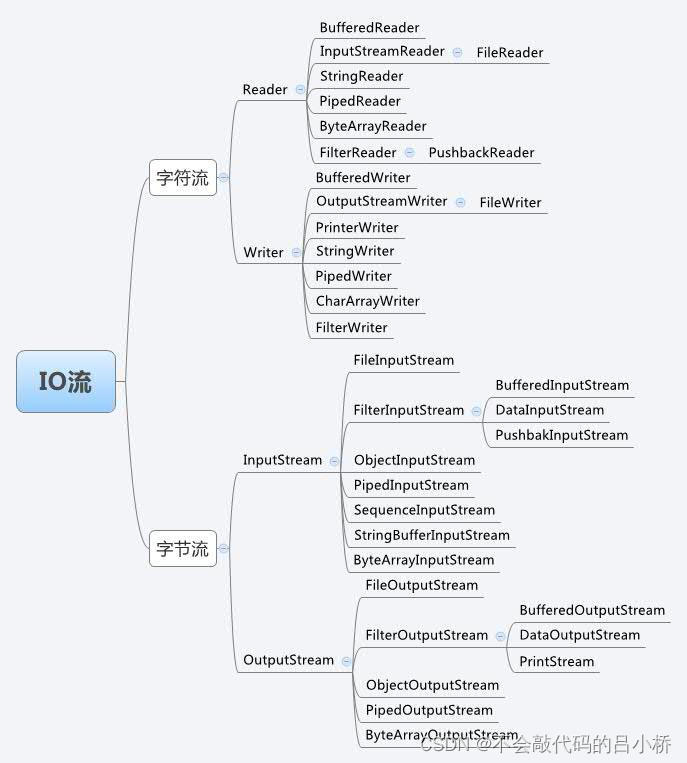
IO流的分类
根据处理数据类型的不同分为:字符流和字节流
根据流向不同分为:输入流和输出流
字符流和字节流
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
(3)字节流在操作的时候本身是不会用到缓冲区的,是文件本身的直接操作的;而字符流在操作的时候下后是会用到缓冲区的,是通过缓冲区来操作文件,我们将在下面验证这一点。
结论:优先选用字节流。首先因为硬盘上的所有文件都是以字节的形式进行传输或者保存的,包括图片等内容。但是字符只是在内存中才会形成的,所以在开发中,字节流使用广泛。
输入流和输出流
对输入流只能进行读操作,对输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
javaIO类图
字符流
InputStream
InputStream是所有输入字节流的父类,它是一个抽象类。
包含方法:
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
int | available() | 返回从该输入流中可以读取(或跳过)的字节数的估计值,而不会被下一次调用此输入流的方法阻塞。 |
void | close() | 关闭此输入流并释放与流相关联的任何系统资源 |
void | mark() | 标记此输入流中的当前位置 |
boolean | markSupported() | 测试这个输入流是否支持mark和reset方法 |
abstract int | read() | 从输入流读取数据的下一个字节 |
int | read(byte[] b) | 从输入流读取一些字节数,并将他们存储到缓冲区b |
int | read(byte[] b, int off, int len) | 从输入流读取最多len字节的数据到一个字节数组 |
void | reset() | 将此流重新定位到上次在此输入流上调用mark方法时的位置 |
long | skip(long n) | 跳过并丢弃来自此输入流的n字节数据 |
字节输出流 InputStream 的典型实现 FileInputStream
/**
* 从路径中读取文件
* 如果写相对路径,则从项目的根路径下查找
* 如果写绝对路径,则根据绝对路径进行查找
*/
File file = new File("test.txt");
// 创建一个输入流,从文件中向java代码输入。
// 如何判断使用输入或输出流?以java自身出发,读取就是输入流,输出就是输出流
InputStream in = new FileInputStream(file);
// 读取一个字节
int read = in.read();
System.out.println((char)read);
// 读取n个字节到数组中,n为数组的长度
byte[] buffer = new byte[10];
in.read(buffer);
System.out.println(Arrays.toString(buffer));
System.out.println(new String(buffer));
// 读取多个字节,存储到数组中,从索引off开始读取len个字节
in.read(buffer, 0, 3);
System.out.println(Arrays.toString(buffer));
System.out.println(new String(buffer));
// 关闭流
in.close();
OutputStream
这个抽象类是表示字节输出流的所有类的超类。 输出流接收输出字节并将其发送到某个接收器。
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
void | close() | 关闭此输出流并释放与流相关联的任何系统资源 |
void | flush() | 刷新此输出流并强制任何缓冲的输出字节被写出 |
void | write(byte[] b) | 从b字节数组中写入b.length字节 |
void | write(byte[] b, int off, int len) | 从指定的字节数组off开始,写入len个字节 |
abstract void | write(int b) | 将指定字节写人此输出流 |
字节输出流 OutputStream 的典型实现 FileOutputStream
// 指定文件位置
File target = new File("test.txt");
// 创建文件的字节输出流对象,第二个参数表示后面写入的文件追加到数据后面,false 表示覆盖,true表示追加
OutputStream out = new FileOutputStream(target,true);
out.write(123);
out.write("QWE".getBytes());
out.write("ABCDEFG".getBytes(), 1, 5);
//4、关闭流资源
out.close();
System.out.println(target.getAbsolutePath());
结合使用
实现将test.txt文件中的内容写入到test1.txt中
//创建源和目标
File srcFile = new File("test.txt");
File descFile = new File("test1.txt");
//创建输入输出流对象
InputStream in = new FileInputStream(srcFile);
OutputStream out = new FileOutputStream(descFile);
//读取和写入操作
byte[] buffer = new byte[10];
int len;
while ((len = in.read(buffer)) != -1) {
// 写入数据
out.write(buffer, 0, len);
}
//关闭流资源
out.close();
in.close();
File类
File类:文件和目录路径名的抽象表示。
File 类的字段
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
static String | pathSeparator | 与系统相关的路径分隔符,表示为字符串 |
static char | pathSeparatorChar | 与系统相关的路径分隔符 |
static String | separator | 与系统相关的默认名称 |
static char | separatorChar | 与系统相关的默认分隔符 |
File 类的常用方法
创建方法
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
boolean | createNewFile() | 不存在返回true 存在返回false |
boolean | mkdir() | 创建目录,如果上一级目录不存在,则会创建失败 |
boolean | mkdirs() | 创建多级目录,如果上一级目录不存在也会自动创建 |
删除方法
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
boolean | delete() | 删除文件或目录,如果表示目录,则目录下必须为空才能删除 |
boolean | deleteOnExit() | 文件使用完成后删除 |
判断方法
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
boolean | canExecute() | 判断文件是否可执行 |
boolean | canRead() | 判断文件是否可读 |
boolean | canWrite() | 判断文件是否可写 |
boolean | exists() | 判断文件或目录是否存在 |
boolean | isDirectory() | 判断此路径是否为一个目录 |
boolean | isFile() | 判断是否为一个文件 |
boolean | isHidden() | 判断是否为隐藏文件 |
boolean | isAbsolute() | 判断是否是绝对路径 文件不存在也能判断 |
获取方法
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
String | getName() | 获取此路径表示的文件或目录名称 |
String | getPath() | 将此路径名转换为路径名字符串 |
String | getAbsolutePath() | 返回此抽象路径名的绝对形式 |
String | getParent() | 如果没有父目录返回null |
long | lastModified() | 获取最后一次修改的时间 |
long | length() | 返回由此抽象路径名表示的文件的长度。 |
boolean | renameTo() | 重命名由此抽象路径名表示的文件。 |
File[] | liseRoots() | 获取机器盘符 |
String[] | list() | 返回一个字符串数组,命名由此抽象路径名表示的目录中的文件和目录。 |
String[] | list(FilenameFilter filter) | 返回一个字符串数组,命名由此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
File dir = new File("test.txt");
File file = new File(dir,"new.txt");
//判断dir 是否存在且表示一个目录
if(!(dir.exists()||dir.isDirectory())){
//如果 dir 不存在,则创建这个目录
dir.mkdirs();
//根据目录和文件名,创建 a.txt文件
file.createNewFile();
}
//返回由此抽象路径名表示的文件或目录的名称。
System.out.println(file.getName());
//返回此抽象路径名的父null的路径名字符串,如果此路径名未命名为父目录,则返回null。
System.out.println(file.getParent());
//将此抽象路径名转换为路径名字符串。
System.out.println(file.getPath());
字节流
为什么要使用字符流?
因为使用字节流操作汉字或特殊符号语言的时候容易乱码,因为汉字不止一个字节,为了解决这个问题,建议使用字符流。
什么情况下使用字符流?
一般可以用记事本打开的文件,我们可以看到内容不乱码的。就是文本文件,可以使用字符流。而操作二进制文件(比如图片、音频、视频)必须使用字节流
Writer
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
Writer | append(char c) | 追加指定的字符 |
Writer | append(CharSequence csq) | 追加指定的字符序列 |
Writer | append(CharSequence csq, int start, int end) | 追加指定的字符序列的子串 |
abstract void | close() | 关闭流,先刷新,再关闭 |
abstract void | flush() | 刷新流 |
void | wirte(char[] cbuf) | 写入一个字符数组 |
abstract void | wirte(char[] cbuf, int off, int len) | 写入部分字符数组 |
void | wirte(int c) | 写入一个字符 |
void | wirte(String str) | 写入字符串 |
void | wirte(String str, int off, int len) | 写入部分字符串 |
字符输出流 Writer 的典型实现 FileWriter
//1、创建源
File srcFile = new File("test.txt");
//2、创建字符输出流对象
Writer out = new FileWriter(srcFile);
out.write(65);
out.write("Aa帅锅".toCharArray());
out.write("Aa帅锅".toCharArray(),0,2);
out.write("Aa帅锅");
out.flush();
out.close();
Reader
| 返回值类型 | 方法名称 | 描述 |
|---|---|---|
void | close() | 关闭流并释放与流相关联的任何系统资源 |
void | mark(int readAheadLimit) | 标记当前位置 |
boolean | markSupported() | 是否支持mark操作 |
int | read() | 读取一个字符 |
int | read(char[] cbuf) | 读取字符数组大小的数据到字符数组 |
int | read(char[] cbuf, int off, int len) | 读取off开始len个字符到字符数组 |
int | read(CharBuffer target) | 将字符读入指定的字符缓冲区 |
boolean | ready() | 是否准备好被读取 |
void | reset() | 重置流 |
long | skip(long n) | 跳过n个字符 |
字符输入流 Reader 的典型实现 FileReader
File srcFile = new File("test.txt");
Reader in = new FileReader(srcFile);
int len = -1;
while((len = in.read())!=-1){
System.out.print((char)len);
}
char[] buffer = new char[10];
while((len=in.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
while((len=in.read(buffer,0,10))!=-1){
System.out.println(new String(buffer,0,len));
}
in.close();
案例
文件复制
//创建源和目标
File srcFile = new File("test.txt");
File descFile = new File("test1.txt");
//创建字符输入输出流对象
Reader in = new FileReader(srcFile);
Writer out = new FileWriter(descFile);
//读取和写入操作
char[] buffer = new char[10];
int len = -1;
while((len=in.read(buffer))!=-1){
out.write(buffer, 0, len);
}
//关闭流资源
out.close();
in.close();
包装流
根据功能分为节点流和包装流
- 节点流:可以从或向一个特定的地方(节点)读写数据。如
FileReader. - 处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如
BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
什么是包装流包
- 装流隐藏了底层节点流的差异,并对外提供了更方便的输入\输出功能,让我们只关心这个高级流的操作
- 使用包装流包装了节点流,程序直接操作包装流,而底层还是节点流和
IO设备操作 - 关闭包装流的时候,只需要关闭包装流即可
缓冲流
缓冲流:是一个包装流,目的是缓存作用,加快读取和写入数据的速度。
- 字节缓冲流:
BufferedInputStream、BufferedOutputStream - 字符缓冲流:
BufferedReader、BufferedWriter
字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("a.txt"));
//定义一个字节数组,用来存储数据
byte[] buffer = new byte[1024];
int len = -1;//定义一个整数,表示读取的字节数
while((len=bis.read(buffer)) != -1){
System.out.println(new String(buffer,0,len));
}
//关闭流资源
bis.close();<br><br>
//字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("io"+File.separator+"a.txt"));
bos.write("ABCD".getBytes());
bos.close();
字节缓冲输入流
BufferedReader br = new BufferedReader(
new FileReader("io"+File.separator+"a.txt"));
char[] buffer = new char[10];
int len = -1;
while((len=br.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
br.close();
//字符缓冲输出流
BufferedWriter bw = new BufferedWriter(
new FileWriter("io"+File.separator+"a.txt"));
bw.write("ABCD");
bw.close();
转换流
把字节流转换为字符流
InputStreamReader:把字节输入流转换为字符输入流OutputStreamWriter:把字节输出流转换为字符输出流
//创建源和目标
File srcFile = new File("a.txt");
File descFile = new File("b.txt");
//创建字节输入输出流对象
InputStream in = new FileInputStream(srcFile);
OutputStream out = new FileOutputStream(descFile);
//创建转换输入输出对象
Reader rd = new InputStreamReader(in);
Writer wt = new OutputStreamWriter(out);
//读取和写入操作
char[] buffer = new char[10];
int len = -1;
while((len=rd.read(buffer))!=-1){
wt.write(buffer, 0, len);
}
//关闭流资源
rd.close();
wt.close();
序列化
什么是序列化与反序列化?
- 序列化:指把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。这个过程称为序列化。通俗来说就是将数据结构或对象转换成二进制串的过程
- 反序列化:把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
为什么要做序列化?
- 在分布式系统中,此时需要把对象在网络上传输,就得把对象数据转换为二进制形式,需要共享的数据的
JavaBean对象,都得做序列化。 - 服务器钝化:如果服务器发现某些对象好久没活动了,那么服务器就会把这些内存中的对象持久化在本地磁盘文件中(
Java对象转换为二进制文件);如果服务器发现某些对象需要活动时,先去内存中寻找,找不到再去磁盘文件中反序列化我们的对象数据,恢复成Java对象。这样能节省服务器内存。
怎么进行序列化?
- 需要做序列化的对象的类,必须实现序列化接口:
Java.lang.Serializable接口(这是一个标志接口,没有任何抽象方法),Java中大多数类都实现了该接口,比如:String,Integer - 底层会判断,如果当前对象是
Serializable的实例,才允许做序列化,Java对象instanceof Serializable来判断。 - 在 Java 中使用对象流来完成序列化和反序列化
ObjectOutputStream:通过 writeObject()方法做序列化操作
ObjectInputStream:通过 readObject() 方法做反序列化操作
模拟
创建一个类
public class Employee implements Serializable {
private String name;
private Integer salary;
private Integer year;
private Integer month;
private Integer day;
// 省略构造器,get和set方法等等
}
模拟序列化
OutputStream op = new FileOutputStream("a.txt");
ObjectOutputStream ops = new ObjectOutputStream(op);
ops.writeObject(new Employee("vae",100,1998,1,1));
ops.close();
如果你去观察a.txt中的内容,你会发现,里面是乱码状态,不用担心, 因为文件中的内容是二进制文件,是给计算机查看的。
模拟反序列化
InputStream in = new FileInputStream("a.txt");
ObjectInputStream os = new ObjectInputStream(in);
byte[] buffer = new byte[10];
int len = -1;
Employee p = (Employee) os.readObject();
System.out.println(p);
os.close();
补充:
- 如果一些字段不想参与序列化,则使用
transient关键字 - 在项目中建议增加
serialVersionUID字段,来保证序列化的版本
private static final long serialVersionUID = -1L;















 4930
4930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









