







SpringCloud 系列列表:
| 文章名 | 文章地址 |
|---|---|
| 01、Eureka - 集群、服务发现 | https://blog.csdn.net/qq_46023503/article/details/128319023 |
| 02、Ribbon - 负载均衡 | https://blog.csdn.net/qq_46023503/article/details/128332288 |
| 03、OpenFeign - 远程调用 | https://blog.csdn.net/qq_46023503/article/details/128387961 |
| 04、Hystrix - 断路器 | https://blog.csdn.net/qq_46023503/article/details/128408601 |
| 05、Sleuth - 链路追踪 | https://blog.csdn.net/qq_46023503/article/details/128409339 |
| 06、Gateway - 网关 | https://blog.csdn.net/qq_46023503/article/details/128430842 |
| 07、Alibaba - 介绍 | https://blog.csdn.net/qq_46023503/article/details/128434080 |
| 08、Nacos - 安装、启动 | https://blog.csdn.net/qq_46023503/article/details/128460411 |
| 09、Nacos - 配置文件中心 | https://blog.csdn.net/qq_46023503/article/details/128460649 |
| 10、Nacos - 注册中心 | https://blog.csdn.net/qq_46023503/article/details/128460494 |
Sleuth - 链路追踪
1 链路追踪
1.1 什么是链路追踪
链路追踪就是:追踪微服务的调用路径
1.2 链路追踪的由来
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个请求都会开成一条复杂的分布式服务调用链路,链路中的任何 一环出现高延时或错误都会引导起整个请求最后的失败。(不建议微服务中链路调用超过 3 次)
1.3 分布式链路调用的监控
sleuth+zipkin(zipkin 就是一个可视化的监控控制台) Zipkin 是 Twitter 的一个开源项目,允许开发者收集 Twitter 各个服务上的监控数据,并提 供查询接口。 该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处 理时间等,可方便的监测系统中存在的瓶颈
2 Zipkin(可视化平台)
2.1 下载
zipkin SpringCloud 从 F 版以后已不需要自己构建 Zipkin server 了,只需要调用 jar 包即可
- https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
- https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/
2.3 运行
zipkin java -jar zipkin-server-2.12.9-exec.jar
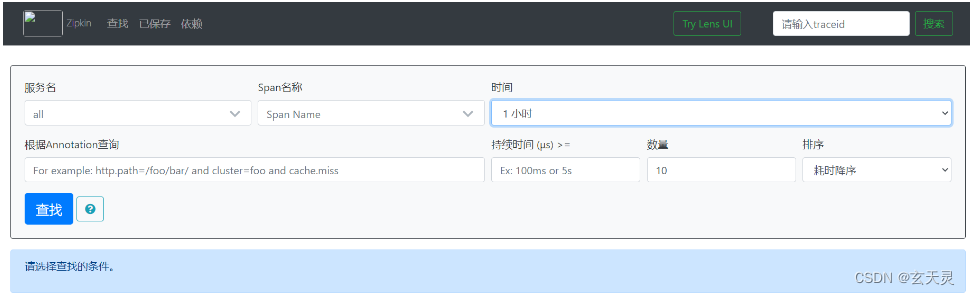
2.3 查看 zipkin 的控制台
http://localhost:9411
3 相关术语和名词解释
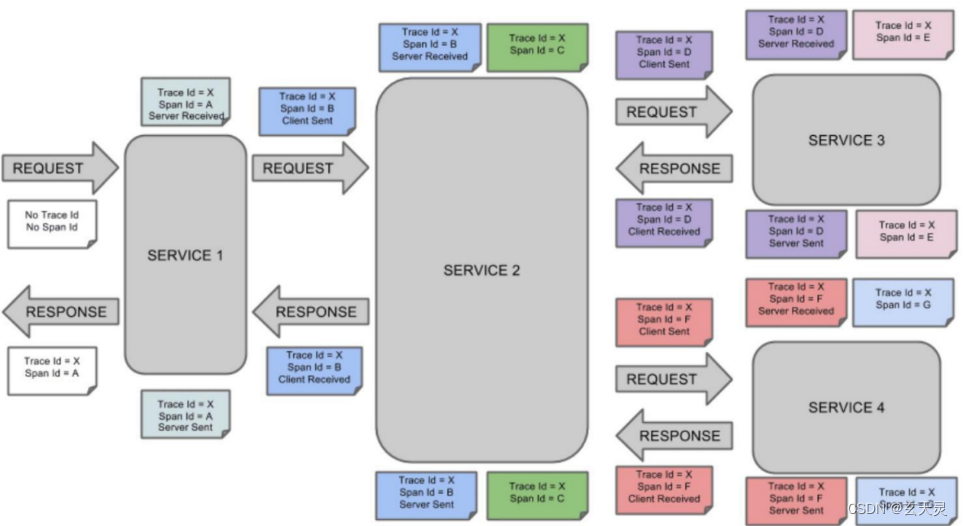
3.1 完整调用链路
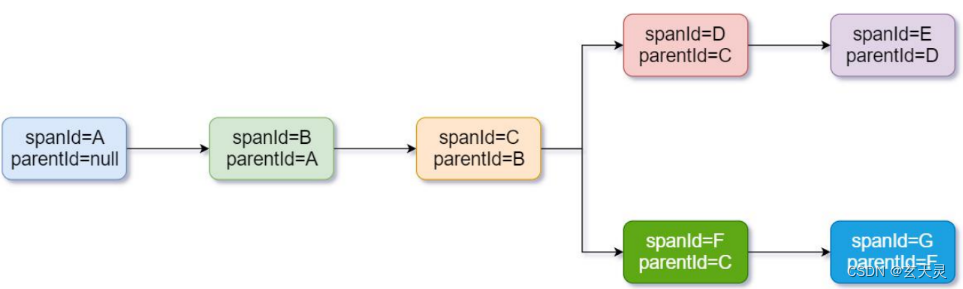
3.2 简化后
3.3 调用链路的依赖关系
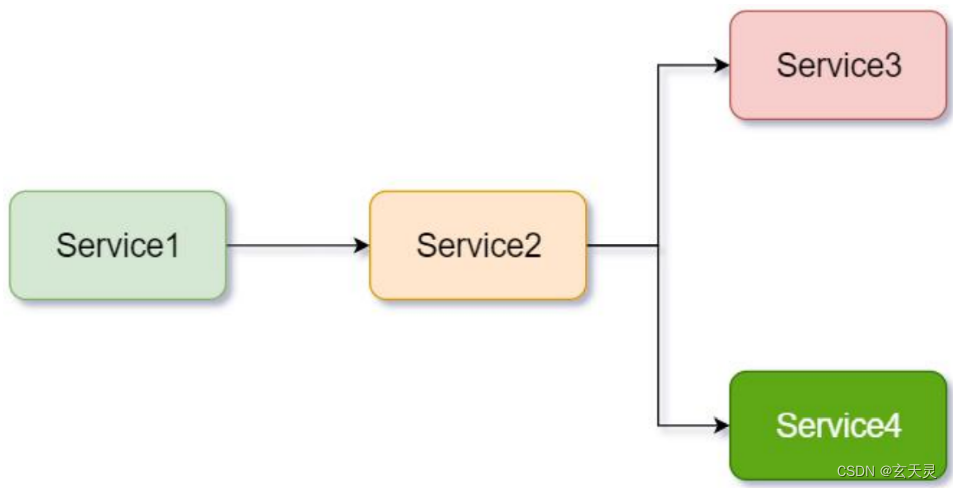
3.4 名词解释
- Trace:类似于树结构的 Span 集合,表示一条调用链路,存在唯一标识
- span:表示调用链路来源,通俗的理解 span 就是一次请求信息
4 Sleuth 快速入门
4.1 案例说明
- 直接用之前的案例:OpenFeign 案例
- eureka-server
- consumer-user-service
- provider-order-service
4.2 添加依赖
consumer-user-service 和 provider-order-service 都要加
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
4.3 修改配置文件
consumer-user-service 和 provider-order-service 都要修改该配置文件
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1 #配置采样率 默认的采样比例为: 0.1,即 10%,所设置的值介于 0 到 1 之间,1 则表示全部采集
rate: 10 #为了使用速率限制采样器,选择每秒间隔接受的 trace 量,最小数字为 0,最大值为 2,147,483,647(最大 int) 默认为 10。
4.4 启动访问,远程调用一下,再查看 zipkin
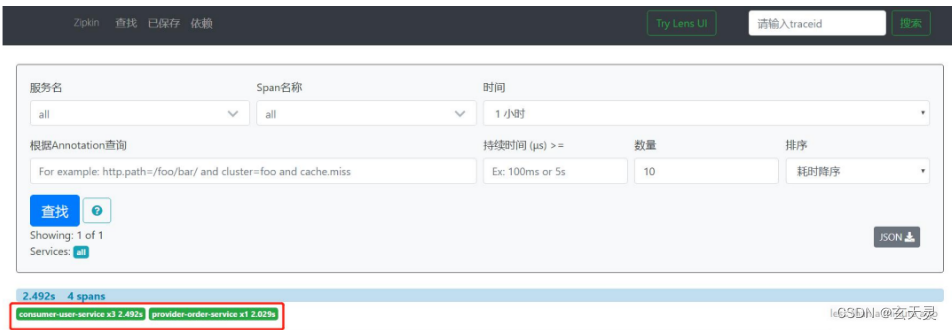
点一下依赖

建议:远程调用的次数不要超过 3 层,2 层最好

















 5466
5466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











