







下面我们就来分别实现服务端和客户端。
服务端的实现
以前,我们需要自己实现Zipkin服务端,但从Spring Boot 2.0以后,官方推出了Zipkin服务端,我们只需要把下载好的服务端jar包放到服务器上启动即可。具体操作如下。
(1)从网络上下载Zipkin服务端的可执行jar包,下载地址: https:/repo1.maven.org/maven2/io/zipkin/java/zipkin-server/2.9.4/zipkin-server-2.9.4-exec.jar。
(2)将zipkin-server-2.9.4-exec.jar修改为zipkin.jar。
(3)执行下面的命令进入zipkin.jar所在目录:
java -jar zipkin.jar
启动成功后,会出现如图12-2所示的界面。

Zipkin服务端的默认启动端口为9411,浏览器访问localhost:9411即可进入Zipkin服务端管理界面,如图12-3所示。

Spring Boot官方推荐使用此方式。当然,读者也可以自己实现Zipkin服务端。接下来,将介绍如何实现自己的Zipkin服务端。
(1)在blog父工程中创建一个 Module,命名为zipkin,在pom.xml中添加以下依赖:
io.zipkin.java
zipkin-server</ artifactId>2.8.4
io.zipkin.java
zipkin-autoconfigure-ui2.8.4
在上述配置中,zipkin-server是Zipkin的服务端依赖,zipkin-autoconfigure-ui是Zipkin的管理界面依赖。Zipkin提供了Web管理界面,方便我们追踪查看,因此有必要依赖它。
(2)创建工程启动类并加入Zipkin注解:
@SpringBootApplication@EnablezipkinServer
public class ZipkinApplication {
public static void main(String[] args){
SpringApplication.run(ZipkinApplication.class,args);
}
}
其中,@EnableZipkinServer注解表示开启Zipkin服务端。
(3)创建配置文件application.yml :
server:
port: 9411management:
metrics:
web:
server:
auto-time-requests: false
auto-time-requests默认为true,该配置的作用是标识Spring MVC或WebFlux处理的请求是否自动计时,如果要使用计时器可以在每个接口方法处添加@Timed注解。需要注意的是,在Spring Boot 2.0以后,需要将auto-time-requests设置为false,否则会抛出java.lang.IllegalAngumentException异常。
(4)运行ZipkinApplication.jar,启动Zipkin服务端,通过浏览器访问localhost:9411,依然可以看到图12-3所示的界面。
客户端集成Spring Cloud Sleuth
单纯启动Zipkin服务端还达不到追踪的目的,我们还必须让微服务客户端集成Zipkin才能跟踪微服务。下面是集成Spring Cloud Sleuth的步骤。
(1)在common工程的pom.xml文件中添加以下依赖:
org.springframework.cloud
spring-cloud-sleuth-zipkin
(2)在Git仓库的配置文件eurekaclient.yml中添加以下内容:
spring:
zipkin:
base-url: http://localhost:9411sender:
type: web
sleuth:
sampler:
probability : 1
其中,spring.zipkin.base-url用来指定Zipkin服务端的地址; spring.sleutch.sampler.probability用来指定采样请求的百分比(默认为0.1,即 10%); spring.zipkin.sender.type为追踪日志发送类型,可选值有web、kafka、rabbit,默认为空,因此必须进行设置,否则·Zipkin 不知道以何种类型发送日志,就无法正确追踪服务链路。
(3)依次启动注册中心、配置中心和 test 工程,浏览器访问localhost:9999/test和 localhost:9411,进入Zipkin界面后,可以看到trace列表,选择Service Name为 test后点击Find a trace按钮,如图12-4所示。
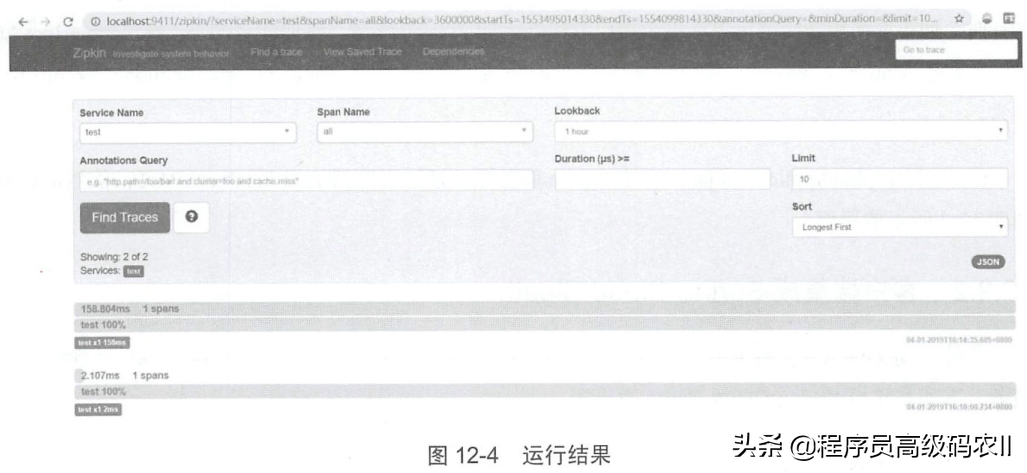
注意这里test工程需要引入eurekaclient.yml配置文件。在上述界面中,Find Traces按钮以上为搜索条件,Service Name为服务名,当前只访问了test,因此下拉框中只能看到test和 all,all为查询所有服务;Span Name为基本工作单元名,顾名思义为具体请求名,一个请求就是一个span;Lookback为记录时间; Annotations Query为自定义的查询条件,可以对标签进行查询,多个用and 隔开; Duration为服务调用时间,查询大于等于该时间的服务,单位是微秒(需要注意的是,下方的服务请求日志列表中以毫秒为单位,所以在筛选条件时需要进行一次转换,否则无法查询出正确的数据);Limit为显示数量,默认为10;Sort为排序规则。
Find Traces按钮下方,Showing表示当前请求数量,Services为当前选择的服务名,点击右边的JSON可以看到当前请求的JSON结构;下方列表展示了当前的请求情况,包括请求总耗时(单位为毫秒)、调用的时间、span的数量、请求耗时占比等。
在实际项目中,读者可以根据Zipkin统计的这些信息发现速度较慢的请求或查询,从而有针对性地对指定请求进行优化。
通过消息中间件实现链路追踪
=============
上一节,我们集成了服务链路追踪组件Zipkin,客户端通过指定Zipkin提供的HTTP地址即可完成日志收集。我们知道,客户端可以通过spring.zipkin.sender.type 指定发送类型,除了指定为web 类型还可以通过消息中间件来收集日志。
本节将利用消息中间件RabbitMQ来完成服务链路追踪日志的收集。
(1)命令行启动官网提供的zipkin.jar,注意,启动时需要指定RabbitMQ 的 host地址,如:
java -jar zipkin.jar --RABBIT_ADDRESSES=127.0.0.1
其中,–RABBIT_ADDRESSES即为RabbitMQ的host地址。
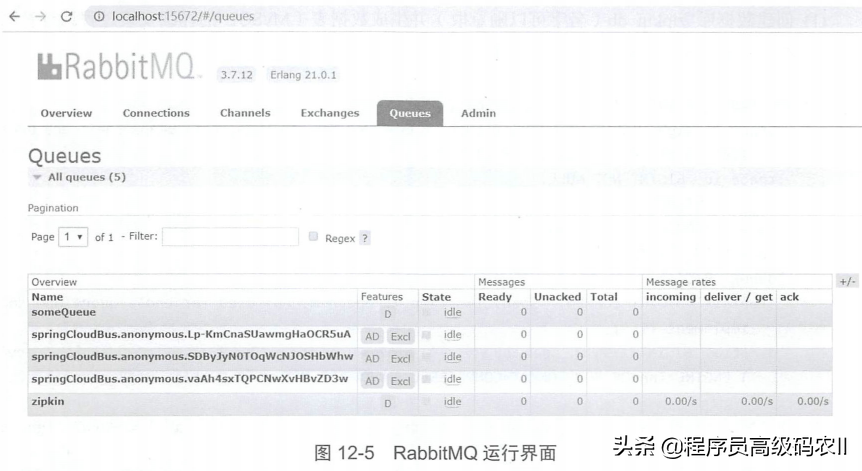
启动完成后,我们访问RabbitMQ的Web管理界面,可以看到,Zipkin Server已经为我们创建了一个名叫zipkin的队列,如图12-5所示。
(2)在common工程下增加以下依赖:
org.springframework.cloud
spring-cloud-stream-binder-rabbit
</ dependency>
该依赖实现了消息队列的收发机制,添加该依赖后,客户端就可以通过 RabbitMQ发送消息,ZipkinServer就可以通过RabbitMQ收集日志。
(3)将eurekaclient.xml的spring.zipkin.base-url注释掉并重启test工程,分别访问test工程接口和Zipkin的Web界面,正常情况下读者可以看到与图12-4类似的效果。
存储追踪数据
======
在前面的操作中,不管是基于Web还是基于消息中间件,收集的日志都默认存放在内存中,即Zipkin Server重启后,追踪的链路数据将被清除,这不符合我们的期望。比较合理的做法是将数据持久化,比如持久化到MySQL、MongoDB、ElasticSearch、Cassandra等数据库中。
下面以MySQL为例,演示如何将追踪数据存储到数据库中。
(1)创建数据库zipkin_db(名字可以随意取)并生成数据表(MySQL 的详细安装过程请查看第14章,Zipkin Server官方推荐使用MariaDB ):
CREATE TABLE IF NOT EXISTS zipkin_spans(
'trace_id_high` BIGINT NOT NULL DEFAULT 0 CONNENT 'Tf non zero,this means the trace uses
128 bit traceIds instead of 64 bit’,
trace_id BIGINT NOT NULL,
`id BIGINT NOT NULL,
name VARCHAR(255)NOT NULL,parent_id BIGINT,
`debug BIT(1),
start_ts BIGINT CONMENT 'Span.timestamp(): epoch micros used for endTs query and to
implement TTL’,
duration` BIGINT CONMENT ‘Span.duration(): micros used for minDuration and maxDuration query’
)ENGINE=InnoDB ROA_FORMAT=CONPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY('trace_id_high, ‘trace_id’, `id’)CONENT 'ignore
insert on duplicate’;
ALTER TABLE zipkin_spans ADD INDEX(trace_id_high ', 'trace_id', id’)CONNENT 'for joining
with zipkin_annotations’;
ALTER TABLE zipkin_spans ADD INDEX(trace_id_high, ‘trace_id"’) CONMMENT 'for getTracesByIds ';ALTER TABLE zipkin_spans ADD INDEX(name)COMMENT 'for getTraces and getSpanNames ';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts’)CONMENT 'for getTraces ordering and range ';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
'trace_id_high’BIGINT NOT NULL DEFAULT O CONMENT 'Tf non zero, this means the trace uses
128 bit traceIds instead of 64 bit’,
'trace_id BIGINT NOT NULL COMMENT ‘coincides with zipkin_spans.trace_id’,'span_id BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id ',
'a_key’ VARCHAR(255) NOT NJLL COWENT ‘BinaryAnnotation.key or Annotation.value if type == -1’,'a_value’ BLOB CONMENT ‘BinaryAnnotation.value(), which must be smaller than 64KB’,‘a_type` INT NOT NULL COMMENT‘BinaryAnnotation.type() or -1 if Annotation’,
'a_timestamp`BIGINT CONMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.
timestamp’,
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)


《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
/e5c14a7895254671a72faed303032d36.jpg" alt=“img” style=“zoom: 33%;” />
惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)
[外链图片转存中…(img-fQGbhS2O-1713328961385)]
[外链图片转存中…(img-niEVbW2p-1713328961385)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 8673
8673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









