







 本文分析了线上教育平台的用户活跃度,通过Python进行数据预处理、用户流失率计算及课程受欢迎度评估。利用协同过滤算法实现课程推荐,旨在提升用户体验和用户留存。
本文分析了线上教育平台的用户活跃度,通过Python进行数据预处理、用户流失率计算及课程受欢迎度评估。利用协同过滤算法实现课程推荐,旨在提升用户体验和用户留存。
1 背景
近年来,随着互联网与通信技术的高速发展,学习资源共享与建设呈现出新的发展趋势,多样化的线上教育平台如雨后春笋般争相涌入大众视野。尤其是自2020年初,受新冠肺炎疫情的冲击,学生返校进行线下 授课受到严重阻碍,由此,网络线上平台由此成为“互联网+教育”成果的重要发展领地,如何根据教育 平台把握用户信息,掌握用户课程偏好并提供精准的远程课程推荐服务成为了线上教育的热点话题。因此, 利用数据分析技术对教育平台的线上信息和用户学习信息进行研究具有重大意义。
2 挖掘目标
1. 分析平台用户的活跃情况,计算用户的流失率,为平台管理决策提供建议。
2. 分析线上课程的受欢迎程度,构建课程智能推荐模型,为教育平台的线上推荐服务提供策略。
3 数据说明
本案例使用3个数据集,包含users.csv(用户信息表)、study_information.csv(学习详情表)和 login.csv(登录详情表)3个数据表。
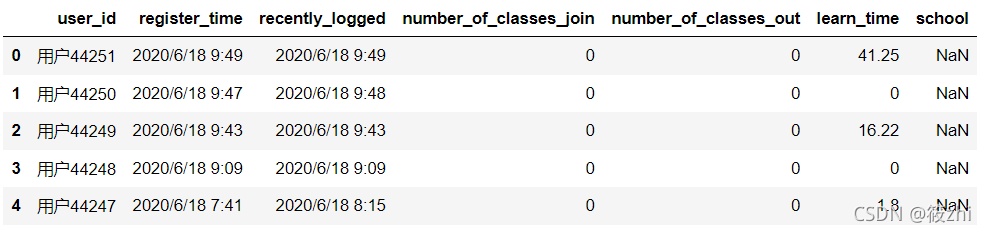
users.csv数据说明:
| 特征名称 | 特征说明 | |
|---|---|---|
| users | user_id | 用户id |
| register_time | 注册时间 | |
| recently_logged | 最近访问时间 | |
| number_of_classes_join | 加入班级数 | |
| number_of_classes_out | 退出班级数 | |
| learn_time | 学习时长(分) | |
| school | 用户所属学校 | |
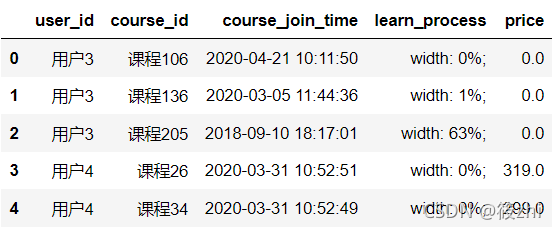
| study_information | user_id | 用户id |
| course_id | 课程id | |
| course_join_time | 加入课程的时间 | |
| learn_process | 学习进度 | |
| price | 课程单价 | |
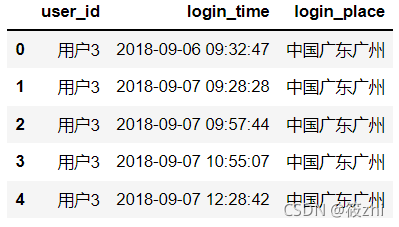
| login | user_id | 用户id |
| login_time | 登录时间 | |
| login_place | 登录地址 |
流程:
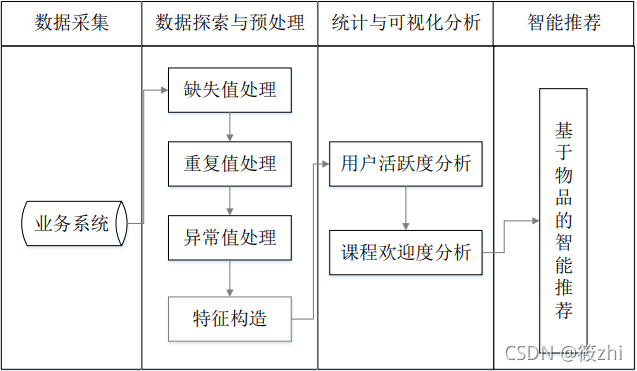
4 数据分析
4.1 导入第三方库
本文所用的库的版本分别为:
numpy的版本: 1.21.2 pandas的版本: 1.3.3 chinese_calendar的版本为: 1.5.0 pyecharts的版本: 1.9.0 scipy的版本: 1.3.1
import numpy as np
import pandas as pd
from chinese_calendar import is_workday # 用于判断是否为工作日
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import Geo
import matplotlib.pyplot as plt
import scipy.spatial.distance as dist #距离计算库
import re
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
4.2 数据加载
因为数据中包含中文,因此encoding使用gbk格式。
# 用户信息表
users = pd.read_csv('./users.csv',encoding='gbk')
users.head()
# 学习详情表
study_info = pd.read_csv('./study_information.csv',encoding='gbk')
study_info.head()
# 登录详情表
login = pd.read_csv('./login.csv',encoding='gbk')
login.head()代码运行结果分别为:
用户详情表
学习详情表
登录详情表
数据大小:
users.shape
# (43983 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2410
2410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









