






前言
近期准备秋招,于是将之前的WebServer项目捡起来,重新设计整理了一番。加入了日志系统用来记录服务器的运行状态。为了不给服务器增添负担,遂打算构建异步日志库。
异步日志系统主要涉及了两个模块,一个是日志模块,一个是阻塞队列模块。其中加入阻塞队列模块主要是为了异步写入日志。
本文致力于让非科班的入门级程序员能够理解日志系统的原理,所以在表述上可能有些不当之处,敬请谅解。
一、阻塞队列的实现
阻塞队列的设计涉及到了互斥锁、条件变量、信号量、线程管理等。信号量是一种线程/进程间同步的一种手段,可以用来管理有限资源的访问。
1.1 <semaphore.h>库简介
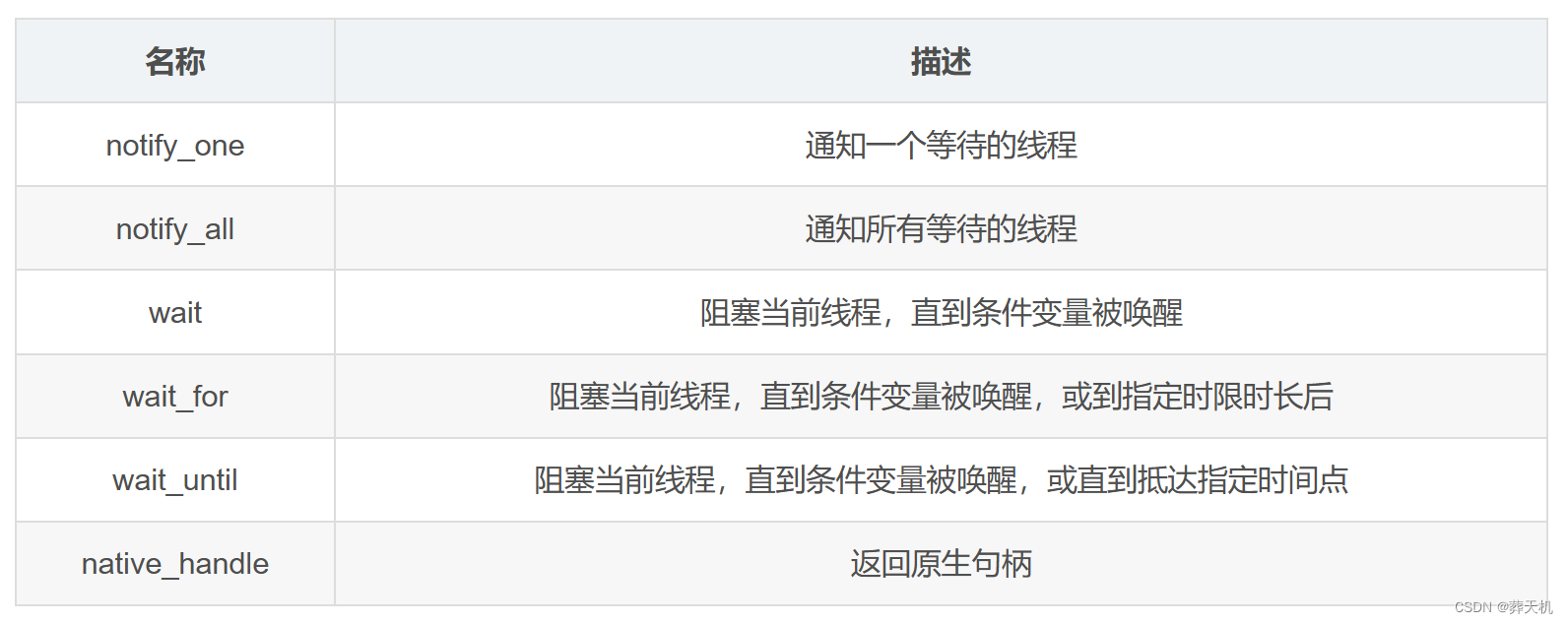
而实现信号量需要使用<semaphore.h>库,其对标准库<mutex>互斥量和<condition_variable>条件变量中的操作进行了封装,提供了更便捷的接口实现。condition_variable 类是同步原语,能用于阻塞一个线程,或同时阻塞多个线程,直至另一线程修改条件变量并通知 condition_variable对象 。condition_variable 只可与 std::unique_lock<std::mutex> 一同使用,同时允许容许 wait 、 wait_for 、 wait_until 、 notify_one 及 notify_all 成员函数的同时调用。
1.2 <semaphore.h>的简易实现
以下是一个简易版的<semaphore.h>库实现,方便理解信号量的工作原理。
#pragma once
#include<mutex>
#include<condition_variable>
class semaphore {
public:
semaphore(long count = 0) :count(count) {}
void wait() {
//std::unique_lock是 C++ 标准库中的一个模板类,用于提供互斥量(mutex)的封装和管理。
//lock是该类的一个实例化对象,(mx)是传入类构造函数的参数。
std::unique_lock<std::mutex>lock(mx);
cond.wait(lock, [&]() {return count > 0; });
--count;
}
void signal() {
std::unique_lock<std::mutex>lock(mx);
++count;
cond.notify_one();
}
private:
std::mutex mx;
std::condition_variable cond;
long count;
};
cond是一个条件变量(condition_variable)对象,用于在多线程编程中进行线程间的同步和通信。条件变量通常和互斥量一起使用,用于等待和通知线程的状态变化。lock是一个 unique_lock <mutex> 类型的锁对象,通常用于管理与条件变量关联的互斥量mutex,创建该对象就相当于加锁了。以wait函数为例子阐述二者的关系。
当线程调用cond的wait()函数时,lock会自动释放它所持有的互斥量。这是为了防止死锁,因为wait () 方法可能会使线程进入休眠状态,等待其他线程的通知。如果互斥量在休眠期间仍然被持有,那么其他试图访问共享资源的线程将永远无法获取到互斥量,从而导致死锁。
当cond的wait()方法返回时(无论是由于被其他线程通知还是因为假唤醒),lock会自动重新锁定它所管理的互斥量。这是为了确保在wait方法之后,线程能够安全地访问被保护的共享资源。当semaphore的wait方法执行完毕后,lock会执行析构函数销毁,自动释放mutex。
[&]() {return count > 0; }: 这是一个 lambda 表达式,用于指定条件变量的等待条件。lambda 表达式 [&]() {return count > 0; } 表示当 count 大于 0 时等待条件得到满足,即线程在等待时会检查条件是否满足,如果不满足则等待。为了提高效率,并防止“假唤醒”(即条件变量在没有被通知的情况下唤醒线程),wait接受一个谓词(即一个返回布尔值的可调用对象,如 lambda 表达式、函数指针、函数对象等)。这个谓词在每次线程被唤醒时都会被检查,只有当谓词返回True 时,线程才会继续执行;如果谓词返回False,则线程会再次进入等待状态。
因此,wait的作用是在 lock 对象管理的互斥量上进行等待操作,等待条件变量 cond 满足 lambda 表达式中指定的条件(即 count > 0)。在满足条件或被通知后,线程将被唤醒继续执行。
同理signal()方法是一样的。
1.2 信号量实现同步机制的原理
关于为什么信号量能实现同步机制我还要想说的两点:
1、在信号量的实现中,count是一个共享资源,假设提供了一个其他的函数来对count进行操作,若不通过lock和mutex来上锁,那么多个线程都可以同时调用该函数对count进行操作,修改共享资源。
2、在sem类中,并不是wait或者signal创建lock之后其他线程就不能访问count了,而是说当某个线程持有lock(即mx互斥量被锁定)时,其他试图锁定同一个互斥量的线程会被阻塞,直到持有锁的线程释放锁。mutex确保了在任何时刻只有一个线程可以执行临界区内的代码,即那些需要访问共享资源(如count)的代码。
在sem类的wait和signal方法中,unique_lock <mutex>在构造时尝试锁定互斥量mx。如果mx当时没有被其他线程锁定,那么当前线程就会获得锁,并可以安全地访问和修改count。如果mx已经被其他线程锁定,那么当前线程就会阻塞,直到锁被释放。
1.3 POSIX 信号量库<semaphore.h>的使用
标准<semaphore.h>库使用sem_t关键字来创建信号量对象,并提供了许多方法。
其中比较重要的有以下一些:
int sem_init(sem_t *sem, int pshared, unsigned int value);pshared 参数:这个参数决定了信号量是在进程内(线程间)共享还是跨多个进程共享。如果 pshared 的值为 0(或者 PTHREAD_PROCESS_PRIVATE,这是一个可选的宏定义,与 0 等价),则信号量只在调用 sem_init 的进程的线程间共享。这是默认值。如果 pshared 的值为非零(或者 PTHREAD_PROCESS_SHARED,这是一个可选的宏定义),则信号量可以在多个进程间共享。但是,为了在多个进程间共享信号量,通常需要将信号量存储在一个共享内存区域中(如使用 mmap 或 shmget 等函数创建的)。
value 参数:这个参数设置了信号量的初始值。信号量的值是一个非负整数,表示可用的“许可”或“资源”的数量。例如,如果你有一个信号量并初始化为 1,那么你可以将其视为一个互斥锁(mutex),因为只有一个线程或进程可以“获得”这个信号量(将其值减至 0),而其他尝试“获得”的线程或进程将被阻塞,直到信号量再次变得可用(即其值变为非零)。如果你将信号量初始化为一个大于 1 的值,那么你可以将其视为一个计数信号量(counting semaphore),它允许多个线程或进程同时访问某种资源,只要资源的数量不超过信号量的初始值。
总之,pshared 参数决定了信号量的共享范围,而 value 参数则设置了信号量的初始值。
int sem_wait(sem_t *sem);sem_wait 函数尝试将信号量的值-1(即执行一个“P”操作),如果成功,sem_wait 返回 0。
如果信号量的值大于零,那么-1操作成功,函数立即返回,并且线程可以继续执行。
如果信号量的值已经是零,那么调用 sem_wait 的线程将被阻塞(放入等待队列),直到信号量的值变为非零。这通常是由另一个线程或进程调用 sem_post(或称为“V”操作)来增加信号量的值来完成的。
sem_wait 通常用于实现线程间的互斥(mutex)或同步(synchronization)。
当用作互斥时,信号量通常被初始化为 1,这样在任何时候都只有一个线程可以“获得”信号量(即执行 sem_wait 成功)。这可以确保对共享资源的互斥访问。
当用作同步时,信号量可以被初始化为任意非负整数,表示可用的资源数量或允许并发执行的线程数量。
int sem_post(sem_t *sem);sem_post 函数将信号量的值+1。这通常表示释放了一个资源或允许一个额外的线程或进程进入某个临界区,如果成功,sem_post 返回 0。
如果在调用 sem_post 之前信号量的值已经是某个非负整数,那么增加操作将简单地使该值+1。
如果在调用 sem_post 时有线程或进程正在等待(被 sem_wait 阻塞)该信号量变为非零,那么其中一个等待的线程或进程将被唤醒(从等待队列中移除),并允许其继续执行。
sem_post 和 sem_wait 一起使用时,可以实现线程间的互斥(mutex)或同步(synchro nization)。
当信号量用作互斥时,通常初始化为 1。一个线程在访问共享资源前会调用 sem_wait,这会将信号量值减至 0 并阻塞其他尝试进入临界区的线程。当线程完成资源访问后,它会调用 sem_post 将信号量值加回 1,从而允许其他线程进入临界区。
当信号量用作同步时,它可以初始化为任意非负整数,表示可用的资源数量或允许并发执行的线程数量。线程在需要资源时会调用 sem_wait,并在释放资源时调用 sem_post。
int sem_destroy(sem_t *sem);sem_destroy 函数将销毁指定的信号量,并释放其占用的所有资源。这包括等待队列中的任何线程(如果有的话),以及与信号量关联的任何系统资源,sem_destroy 返回 0。
在销毁信号量之前,必须确保没有线程正在等待该信号量(即没有线程被 sem_wait 阻塞)。否则,sem_destroy 的行为是未定义的,并且可能会导致程序崩溃或其他不可预测的行为。
销毁信号量后,任何对该信号量的后续引用(例如再次调用 sem_wait 或 sem_post)都是无效的,并且可能导致程序崩溃。
1.4 POSIX线程库<pthread.h> 的使用
POSIX 线程库(pthread)提供了一套 API,用于在多线程环境下创建、同步和管理线程。使用 pthread 库的主要优势是其跨平台性。由于 POSIX 标准的存在,大多数 UNIX-like 系统都支持 pthread,包括 Linux、Mac OS X 和 BSD 系统等。这使得开发者能够编写可移植的多线程程序,而无需关心底层操作系统的细节。此外,pthread 库提供了一套相对简单且易于使用的 API,通过这些 API,开发者可以方便地创建和管理线程,并进行线程间的同步和通信。
与线程相关的有以下函数:

下面是一个简单的示例,展示了如何使用 pthread 在 C++ 中创建和管理线程:
#include <iostream>
#include <pthread.h>
// 线程函数
void* threadFunction(void* arg) {
int* numPtr = static_cast<int*>(arg);
std::cout << "Hello from thread! Number: " << *numPtr << std::endl;
return nullptr;
}
int main() {
pthread_t threadId;
int number = 42;
// 创建线程
int result = pthread_create(&threadId, nullptr, threadFunction, &number);
if (result != 0) {
std::cerr << "Failed to create thread." << std::endl;
return 1;
}
// 等待线程结束
result = pthread_join(threadId, nullptr);
if (result != 0) {
std::cerr << "Failed to join thread." << std::endl;
return 1;
}
std::cout << "Main thread exiting." << std::endl;
return 0;
}
线程创建函数pthread_create的第一个参数是pthread_t 类型对象的地址/引用,是一个传出参数,传递进去的 threadId 会得到系统为我们创建好的线程句柄。第二个参数默认为NULL即可,第三个参数是新线程执行的线程函数,第四个参数为线程函数的参数。
pthread_join的第一个参数是线程标识符,即线程ID,因为不需要传出,故为值传递。第二个参数定义的指针,用来存储被等待线程的返回值,如果不需要则传入NULL。
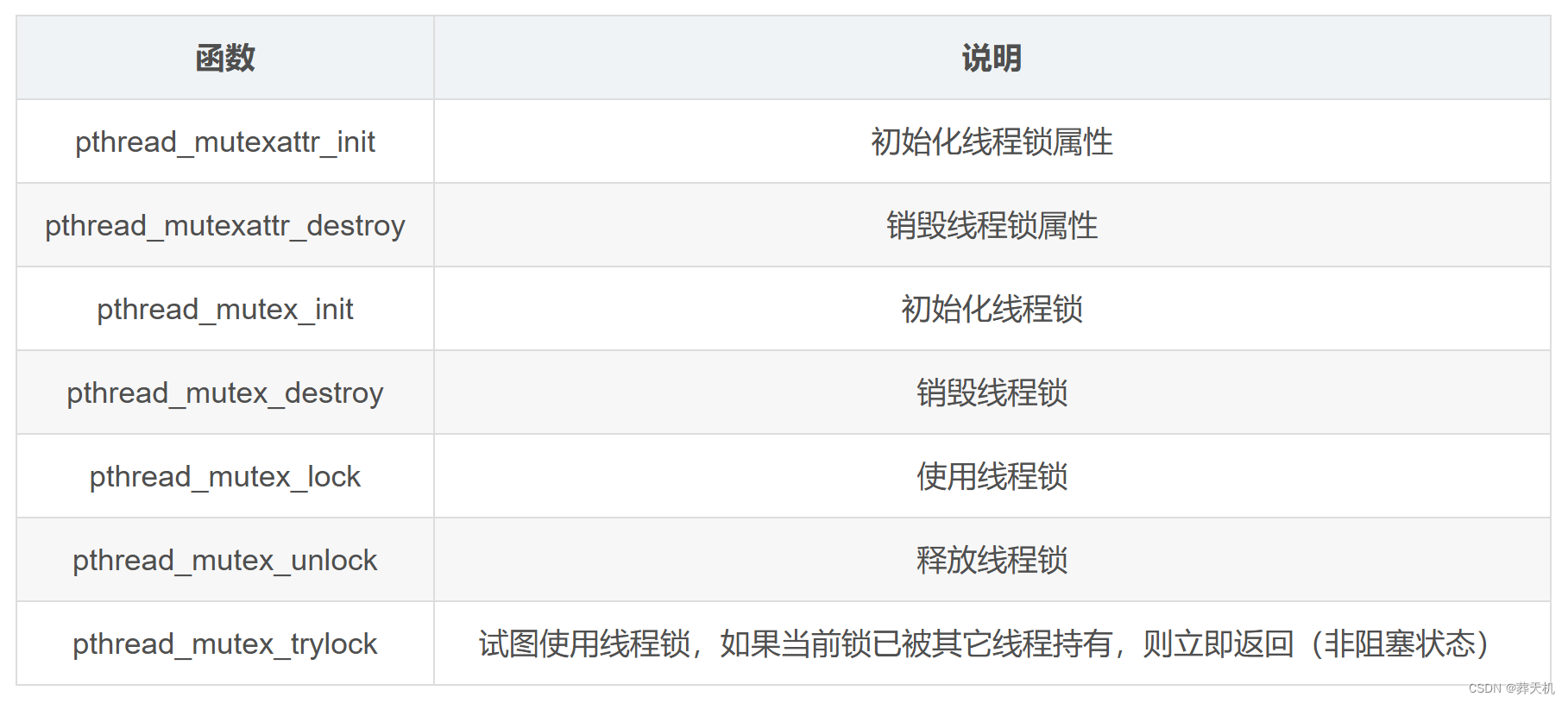
与线程锁相关的函数:
下面是一个简单的示例,展示了如何使用线程锁相关函数在 C++ 中维护线程安全:
pthread_mutex_t mutex;
int num;
void *num_increment(void *params) {
for (int i = 0; i < 10000; ++i) {
usleep(100);
pthread_mutex_lock(&mutex);
num += 1;
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
void main() {
//定义互斥属性
pthread_mutexattr_t mutexattr;
//初始化互斥属性
pthread_mutexattr_init(&mutexattr);
//初始化互斥锁
pthread_mutex_init(&mutex, &mutexattr);
//创建线程1,执行 num+=1
pthread_t thread1;
pthread_create(&thread1, nullptr, num_increment, nullptr);
//创建线程2
pthread_t thread2;
pthread_create(&thread2, nullptr, num_increment, nullptr);
//等待线程1、线程2,执行完成
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
//num == 20000,如果不加锁则 num < 20000
LOGD("num = %d", num);
//释放mutexattr
pthread_mutexattr_destroy(&mutexattr);
//释放mutex
pthread_mutex_destroy(&mutex);
}
在这段代码中,如果不使用互斥锁(pthread_mutex_t)来保护对共享变量 num 的访问,结果会小于 20000 的原因是发生了数据竞争(data race)。它发生在两个或更多的线程在没有同步的情况下访问同一个内存位置,并且至少有一个线程是写入操作。
在 num_increment 函数中,每个线程都会试图增加 num 的值 10000 次。然而,如果没有互斥锁的保护,两个线程可能会同时读取 num 的值,各自增加 1,然后写回结果。这可能会导致一个线程的增加操作覆盖了另一个线程的增加操作,因此 num 的最终值会小于两个线程预期增加的总和(即 20000)。
例如,假设 num 的初始值为 0,两个线程同时读取了 num 的值。然后,线程 1 将 num 增加到 1 并写回,同时线程 2 也将 num 增加到 1 并写回。由于两个线程都基于初始值 0 进行了增加操作,所以 num 的值仍然是 1,而不是预期的 2。这个过程会在整个循环中多次发生,导致 num 的最终值远小于 20000。
通过使用互斥锁(pthread_mutex_lock 和 pthread_mutex_unlock),可以确保在任何时候只有一个线程能够访问和修改 num。当一个线程持有锁时,其他试图获取锁的线程将被阻塞,直到锁被释放。这确保了每次只有一个线程能够读取、增加和写回 num 的值,从而避免了数据竞争,并保证了 num 的最终值等于两个线程增加的总和(即 20000)。
pthread_mutex_lock、pthread_mutex_unlock、pthread_mutex_init函数,成功后返回0。
注:也可以不定义互斥属性,在初始化时传入NULL使用默认属性,pthread_mutex_init(&mutex, NULL)。下面的pthread_cond_init
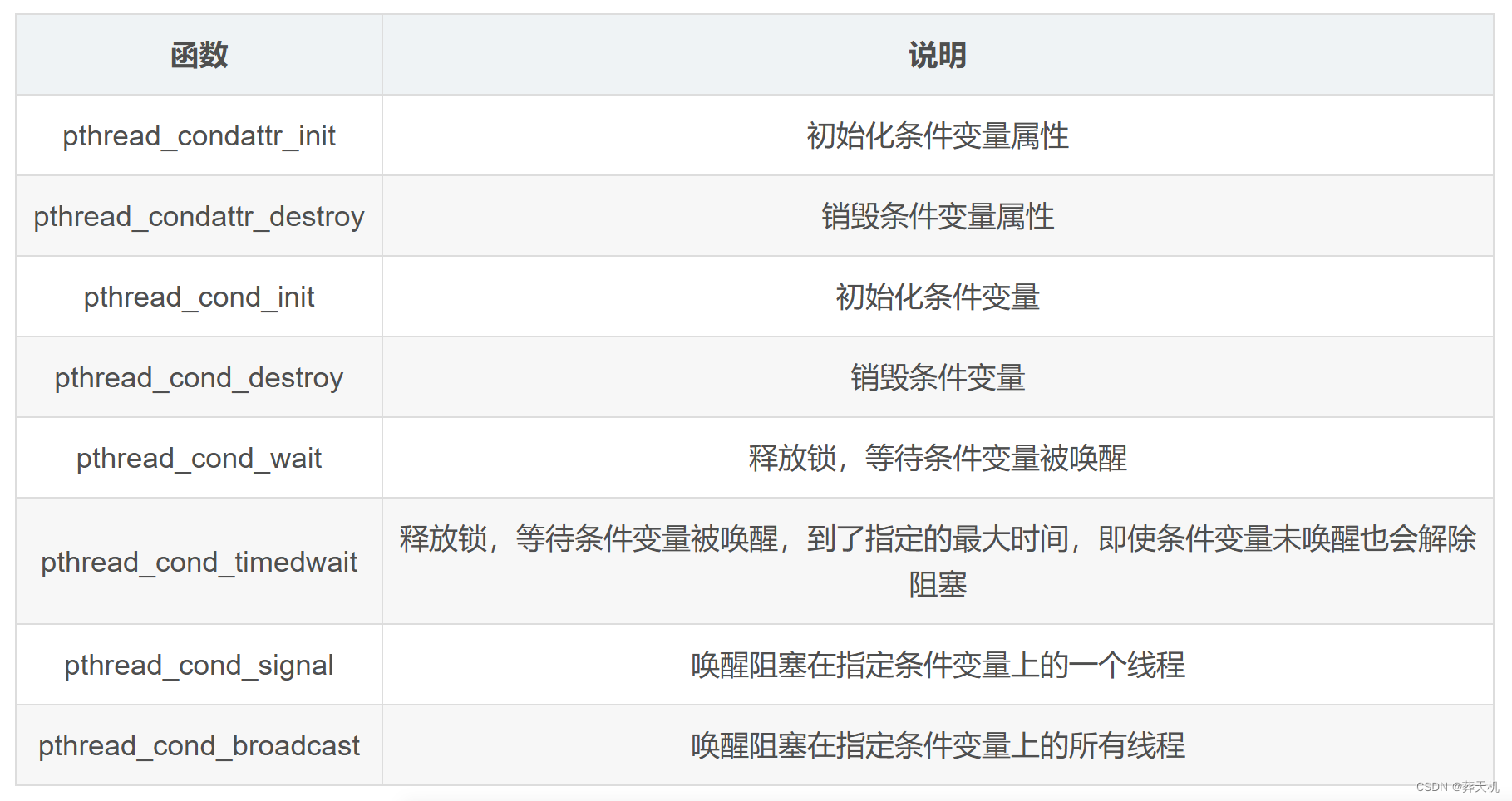
与线程条件变量相关的函数:
有了以上基础后,下面通过一个简单的示例,展示如何使用pthread实现生产者消费者模型:
//定义线程锁,并静态初始化线程锁,不需要调用 pthread_mutex_init 进行初始化
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
//定义条件变量,同样也可以通过 PTHREAD_COND_INITIALIZER 静态初始化
pthread_cond_t cond;
class Iphone {
private:
int phoneId;
public:
explicit Iphone(int id) : phoneId(id) {}
int getPhoneId() {
return phoneId;
}
};
int productId;
std::list<Iphone> iphoneList;
//生产者线程
void *producer_runnable(void *params) {
while (true) {
sleep(random() % 10);
pthread_mutex_lock(&mutex);
Iphone iphone(productId++);
iphoneList.push_back(iphone);
//发送信号,唤醒等待的线程
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
//消费者线程
void *consumer_runnable(void *params) {
while (true) {
pthread_mutex_lock(&mutex);
if (iphoneList.size() == 0) {
//释放锁并等待唤醒
pthread_cond_wait(&cond, &mutex);
}
Iphone iphone = iphoneList.front();
iphoneList.pop_front();
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
void main() {
//定义条件变量属性
pthread_condattr_t condattr;
//初始化条件变量属性
pthread_condattr_init(&condattr);
//初始化条件变量
pthread_cond_init(&cond, &condattr);
//创建生产者线程
pthread_t product_thread;
pthread_create(&product_thread, nullptr, producer_runnable, nullptr);
//创建消费者线程
pthread_t consume_thread;
pthread_create(&consume_thread, nullptr, consumer_runnable, nullptr);
}
创建商品IPhone类和缓冲队列iphoneList,创建生产者和消费者线程的执行函数,其中在执行操作前上锁,执行完操作后再解锁。生产者线程函数通过pthread_cond发送信号,唤醒因为iphoneList为空而调用pthread_cond_wait阻塞的消费者线程。若列表不为空,则消费者直接执行消费操作。
pthread_cond_wait(&cond, &mutex) 中传入mutex,1是为了阻塞不发生死锁而释放互斥量muetx,2是为了被唤醒时,能够抢mutex上锁。没抢到的锁的线程会继续等待,直到下次唤醒。
条件变量的等待操作pthread_cond_wait是用来主动阻塞线程的,why?往往是因为线程执行下面操作所需要的资源还么有准备到位,阻塞等待资源到位再继续执行下面的代码。在此处就是因为产品队列中没有产品资源的存在,消费者线程无法执行以下的消费操作,故在此调用将消费者线程放入等待队列并阻塞。如果让消费者线程不断轮询来检查资源是否准备到位的话,会占用CPU时间,提高CPU资源的占用率,同时轮询的频率会导致线程的响应变慢,如果是条件变量的话会立即唤醒线程。
1.5 阻塞队列代码实现
在了解了<semaphore.h>库中的semaphore类后就可以尝试实现阻塞队列了。
/*************************************************************
*循环数组实现的阻塞队列,m_back = (m_back + 1) % m_max_size;
*线程安全,每个操作前都要先加互斥锁,操作完后,再解锁
**************************************************************/
#ifndef BLOCK_QUEUE_H
#define BLOCK_QUEUE_H
#include <iostream>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h>
#include "../lock/locker.h"
using namespace std;
template <class T>
class block_queue
{
public:
block_queue(int max_size = 1000)
{
if (max_size <= 0)
{
exit(-1);
}
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
}
void clear()
{
m_mutex.lock();
m_size = 0;
m_front = -1;
m_back = -1;
m_mutex.unlock();
}
~block_queue()
{
m_mutex.lock();
if (m_array != NULL)
delete [] m_array;
m_mutex.unlock();
}
//判断队列是否满了
bool full()
{
m_mutex.lock();
if (m_size >= m_max_size)
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
//判断队列是否为空
bool empty()
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
//返回队首元素
bool front(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_front];
m_mutex.unlock();
return true;
}
//返回队尾元素
bool back(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_back];
m_mutex.unlock();
return true;
}
int size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_size;
m_mutex.unlock();
return tmp;
}
int max_size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_max_size;
m_mutex.unlock();
return tmp;
}
//往队列添加元素,需要将所有使用队列的线程先唤醒
//当有元素push进队列,相当于生产者生产了一个元素
//若当前没有线程等待条件变量,则唤醒无意义
bool push(const T &item)
{
m_mutex.lock();
if (m_size >= m_max_size)
{
m_cond.broadcast();
m_mutex.unlock();
return false;
}
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
m_cond.broadcast();
m_mutex.unlock();
return true;
}
//pop时,如果当前队列没有元素,将会等待条件变量
bool pop(T &item)
{
m_mutex.lock();
while (m_size <= 0)
{
if (!m_cond.wait(m_mutex.get()))
{
m_mutex.unlock();
return false;
}
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
m_mutex.unlock();
return true;
}
//增加了超时处理
bool pop(T &item, int ms_timeout)
{
struct timespec t = {0, 0};
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
m_mutex.lock();
if (m_size <= 0)
{
t.tv_sec = now.tv_sec + ms_timeout / 1000;
t.tv_nsec = (ms_timeout % 1000) * 1000;
if (!m_cond.timewait(m_mutex.get(), t))
{
m_mutex.unlock();
return false;
}
}
if (m_size <= 0)
{
m_mutex.unlock();
return false;
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
m_mutex.unlock();
return true;
}
private:
locker m_mutex;
cond m_cond;
T *m_array;
int m_size;
int m_max_size;
int m_front;
int m_back;
};
#endiflocker类和cond类分别对pthread_mutex和pthread_cond进行了封装,对外提供了更方便的接口,使用上类似。
不论是生产者线程执行函数,还是消费者线程执行函数,对阻塞队列进行的任何操作,首先都要m_mutex.lock()获取互斥量进行上锁,以阻止其他线程获取互斥量,其他线程若是运行中需要执行m_mutex.lock()就会阻塞在这一步,只有等到先得到锁的线程完成m_mutex.unlock()解锁后,其他阻塞的线程才可以继续竞争m_mutex.lock()上锁。
而且生产者线程执行函数调用的阻塞队列中的push函数,需要用m_cond.broadcast()来通知所有阻塞在m_cond.wait()或者m_cond.timewait()上的线程。消费者线程调用pop函数时,先上锁,若发现阻塞队列没有任务,则调用m_cond.wait()或者m_cond.timewait()等待生产者线程的通知,同时释放锁。
二、异步日志系统的实现
2.1 Log类的声明
#ifndef LOG_H
#define LOG_H
#include <stdio.h>
#include <iostream>
#include <string>
#include <stdarg.h>
#include <pthread.h>
#include "block_queue.h"
using namespace std;
class Log
{
public:
//C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
{
static Log instance;
return &instance;
}
static void *flush_log_thread(void *args)
{
Log::get_instance()->async_write_log();
}
//可选择的参数有日志文件、日志缓冲区大小、最大行数以及最长日志条队列
bool init(const char *file_name, int close_log, int log_buf_size = 8192, int split_lines = 5000000, int max_queue_size = 0);
void write_log(int level, const char *format, ...);
void flush(void);
private:
Log();
virtual ~Log();
void *async_write_log()
{
string single_log;
//从阻塞队列中取出一个日志string,写入文件
while (m_log_queue->pop(single_log))
{
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
private:
char dir_name[128]; //路径名
char log_name[128]; //log文件名
int m_split_lines; //日志最大行数
int m_log_buf_size; //日志缓冲区大小
long long m_count; //日志行数记录
int m_today; //因为按天分类,记录当前时间是那一天
FILE *m_fp; //打开log的文件指针
char *m_buf;
block_queue<string> *m_log_queue; //阻塞队列
bool m_is_async; //是否同步标志位
locker m_mutex;
int m_close_log; //关闭日志
};
#define LOG_DEBUG(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(0, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_INFO(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(1, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_WARN(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(2, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_ERROR(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(3, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#endif在Log.h文件中需要关注的点:
1、单例模式中的懒汉模式
//C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
{
static Log instance;
return &instance;
}2、工作线程写日志的执行函数
static void *flush_log_thread(void *args)
{
Log::get_instance()->async_write_log();
} void *async_write_log()
{
string single_log;
//从阻塞队列中取出一个日志string,写入文件
while (m_log_queue->pop(single_log))
{
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
// m_log_queue->pop(single_log)传入的是single_log的引用,若阻塞队列为空,返回false继续循环
// 若为true,则single_log成功获取队头元素字符串,即要写入的日志注意:工作线程在fputs写日志的时候,也进行了上锁解锁操作,说明即使是多线程,仍然是排队一个一个写,不能并行,这里创建多个线程写日志没有必要,日志系统在这里创建线程的意义是异步进行不会因为输出日志而阻塞主线程。
2.2 异步日志类的初始化
#include <string.h>
#include <time.h>
#include <sys/time.h>
#include <stdarg.h>
#include "log.h"
#include <pthread.h>
using namespace std;
Log::Log()
{
m_count = 0;
m_is_async = false;
}
Log::~Log()
{
if (m_fp != NULL)
{
fclose(m_fp);
}
}
//异步需要设置阻塞队列的长度,同步不需要设置
bool Log::init(const char *file_name, int close_log, int log_buf_size, int split_lines, int max_queue_size)
{
//如果设置了max_queue_size,则设置为异步
if (max_queue_size >= 1)
{
m_is_async = true;
m_log_queue = new block_queue<string>(max_queue_size);
pthread_t tid;
//flush_log_thread为回调函数,这里表示创建线程异步写日志
pthread_create(&tid, NULL, flush_log_thread, NULL);
}
设置异步,在堆区开辟阻塞队列,创建一个线程执行回调函数(此处因为单线程不需要竞争抢锁,也可以多创建几个线程,但感觉没必要,因为写log同时只能一个线程写,其他线程必须等待。不像服务器处理io后,处理业务逻辑时,不同连接请求不会访问同一块共享资源区),不断地尝试从阻塞队列获取任务,或者阻塞在队列中,等待条件变量的通知。
m_close_log = close_log;
m_log_buf_size = log_buf_size;
m_buf = new char[m_log_buf_size];
memset(m_buf, '\0', m_log_buf_size);
m_split_lines = split_lines;
time_t t = time(NULL);
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
const char *p = strrchr(file_name, '/');
char log_full_name[256] = {0};
if (p == NULL)
{
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
}
else
{
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday;
m_fp = fopen(log_full_name, "a");
if (m_fp == NULL)
{
return false;
}
return true;
}
然后准备日志的文件名,通过日期和最大行数来进行划分不同的txt文件。具体地,首先获取时间,然后判断给定的filename是不是符合格式,如果 file_name 是一个文件路径(例如 "/home/user/documents/file.txt"),那么 p 将指向路径中的 file.txt 之前的斜杠。如果 file_name 中不包含斜杠,或者 file_name 是 NULL,那么 p 将被设置为 NULL。
snprintf输出格式化的字符串,得到完整的日志文件路径log_full_name(大小为256),255限制了输出的大小以免越界。举例,或得的日志文件路径为 ./2024_06_09_ServerLog。
最后fopen以'a'追加模式打开日志文件,在“追加”模式下,如果文件已经存在,新的数据会被追加到文件的末尾,而不会覆盖原有的内容。如果文件不存在,它会被创建。
2.3 写日志
void Log::write_log(int level, const char *format, ...)
{
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
time_t t = now.tv_sec;
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
char s[16] = {0};
switch (level)
{
case 0:
strcpy(s, "[debug]:");
break;
case 1:
strcpy(s, "[info]:");
break;
case 2:
strcpy(s, "[warn]:");
break;
case 3:
strcpy(s, "[erro]:");
break;
default:
strcpy(s, "[info]:");
break;
}
日志输出的标准格式 2024-06-09 14:35:28.266149 [info]:具体的内容。
以上代码用来确定日志的级别 [info] 是通知 ,[erro]是错误等,方便在浏览日志的时候快速锁定自己想得到的内容。
//写入一个log,对m_count++, m_split_lines最大行数
m_mutex.lock();
m_count++;
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //everyday log
{
char new_log[256] = {0};
fflush(m_fp);
fclose(m_fp);
char tail[16] = {0};
snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
if (m_today != my_tm.tm_mday)
{
snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);
m_today = my_tm.tm_mday;
m_count = 0;
}
else
{
snprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail, log_name, m_count / m_split_lines);
}
m_fp = fopen(new_log, "a");
}
m_mutex.unlock();
上面代码主要是对写入log之前进行判断:如果运行过程中打开的m_fp是昨天的,即第二天零点后处理的得一条日志,那么需要重新创建一个txt文件来记录日志,同时将count置零;如果是同一天内的日志记录条数超过了设置的最大行数,那么需要新建一个txt文件以.n为后缀,表示这是今天第几个日志txt文件。最后重新打开新的txt文件记录日志。
va_list valst;
va_start(valst, format);
string log_str;
m_mutex.lock();
//写入的具体时间内容格式
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);
int m = vsnprintf(m_buf + n, m_log_buf_size - n - 1, format, valst);
m_buf[n + m] = '\n';
m_buf[n + m + 1] = '\0';
log_str = m_buf;
m_mutex.unlock();
if (m_is_async && !m_log_queue->full())
{
m_log_queue->push(log_str);
}
else
{
m_mutex.lock();
fputs(log_str.c_str(), m_fp);
m_mutex.unlock();
}
va_end(valst);
}
void Log::flush(void)
{
m_mutex.lock();
//强制刷新写入流缓冲区,将缓冲区的文件写入磁盘
fflush(m_fp);
m_mutex.unlock();
}va_list 是一个类型,用于在 C 语言中处理可变参数列表。va_start是一个宏,它初始化va_list 变量,使其指向传递给函数的第一个可变参数。这里,format 是固定参数列表中的最后一个参数,紧接着它的是可变参数列表。
日志输出的标准格式 2024-06-09 14:35:28.266149 [info]:具体的内容。
log_str 是要写入的日志具体内容,n 和 m 是函数返回的写入的字符数。
vsnprintf是一个函数,它类似于 snprintf,但允许你使用可变参数列表。这里,它将 format 字符串(以及由 valst 指定的可变参数)写入 m_buf 缓冲区的剩余部分。注意,这里计算了剩余的缓冲区大小,以确保不会发生缓冲区溢出。
随后添加换行符和字符串结束符,并将缓冲区的的地址赋给 logstr。
如果阻塞队列非满,则将 logstr 加入阻塞队列,阻塞队列通知工作线程。
注意:上述代码中写日志过程中曾2次上锁和释放锁,且第一次释放锁与第二次上锁之间只隔了这三行代码,实际上没有必要,会增加一些开销。
va_list valst;
va_start(valst, format);
string log_str;2.4 异步日志系统的工作原理
这一部分或许用图画的形式会比较直观,但笔者比较懒,就用文字来描述一下。
工作流程:
1、日志系统的初始化,创建一个写日志线程,执行函数设置为提交日志(将日志写入磁盘),创建并打开一个标准命名格式的txt文件。
2、在整个服务器项目运行过程中若有线程调用写日志函数 write_log(int level, const char *format, ...),则会按照标准输出日志格式例如 "2024-06-09 14:35:28.266149 [info]: *format"。随后 log_str 会被提交到阻塞队列中,阻塞队列中的push函数中封装了条件变量(pop也一样),会通知阻塞在 pop 上的所有线程(但实际上只创建了一个该线程)。
3、阻塞在 pop 调用内部 cond.wait 的提交日志线程,收到了来自 push 的 cond.boardcst(),被唤醒了,然后从阻塞队列中取出 log_str,调用 fputs 方法将其写入磁盘。
2.5 总结
重新梳理了一遍异步日志系统的实现,感觉对代码的理解更深了,哈哈哈。写的可能很粗糙,大家将就着看,希望对大家有所帮助,有疑问的欢迎评论区交流。
参考文章如下:
C++ 实现简易 log 日志库_c++ log-CSDN博客
C++实现简单的日志logger输出_c++ log(info)<<"helloworld-CSDN博客
C++11实现信号量semaphore_c++11 semaphore-CSDN博客
condition_variable 条件变量_conditionvariable-CSDN博客
Linux C++ pthread是什么缩写?(POSIX Threads)<pthread.h>_c++pthread.h-CSDN博客
















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









