






引言
在上一篇文章中,我们已经对Apifox Helper插件有了初步的了解。今天,我们将深入探讨Apifox的导出功能,看看如何通过其强大的内置能力,高效完成我们的开发效率。
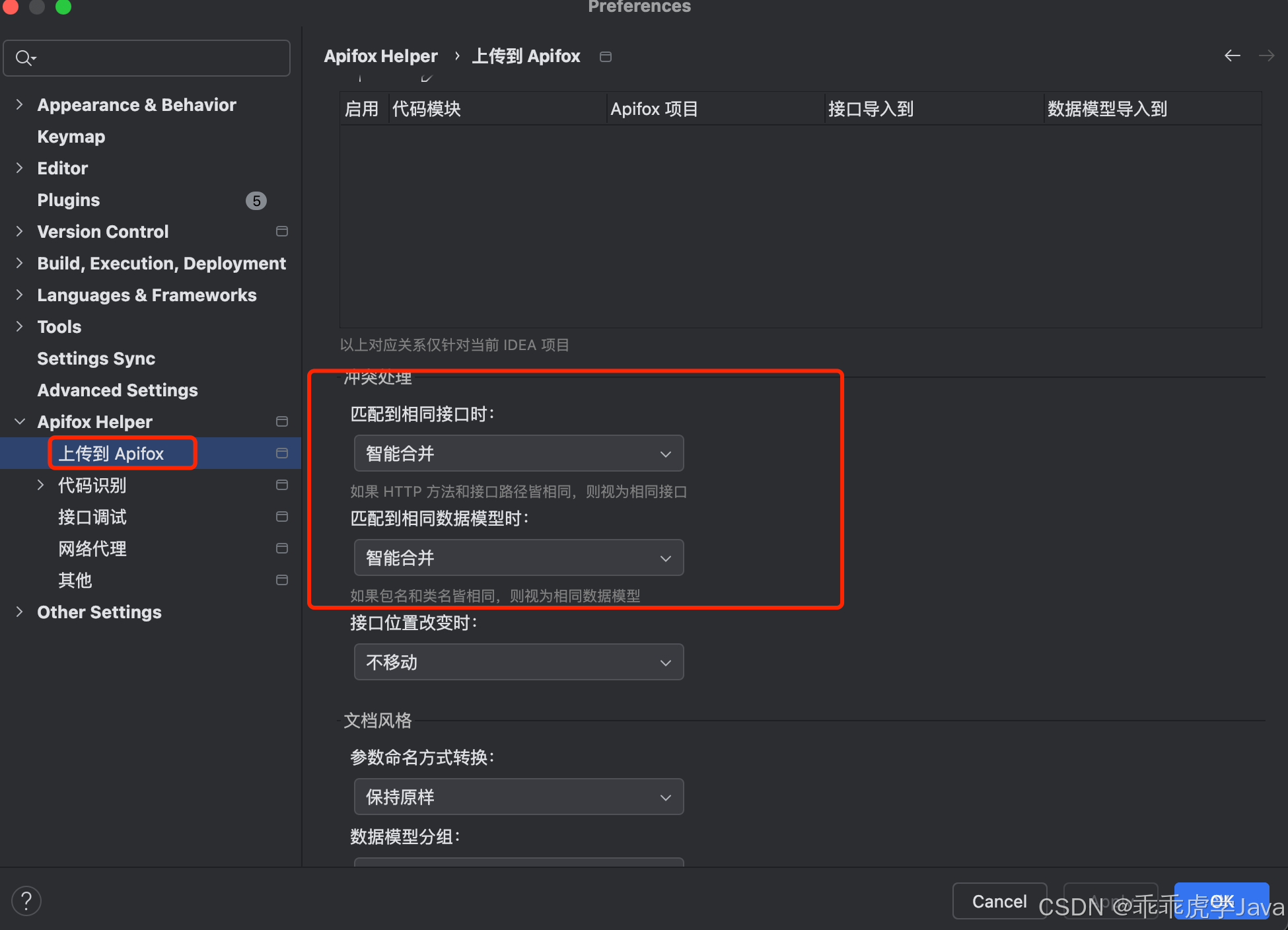
1. Apifox Helper 的冲突处理
在使用Apifox进行API管理时,冲突处理是一个非常重要的功能,尤其是在团队协作或频繁更新API的场景中。Apifox提供了多种冲突处理策略,帮助用户灵活应对数据同步问题。以下是对Apifox冲突处理的详细解析:
1.1 常见的冲突处理场景
在API管理中,冲突通常发生在以下情况:
- 相同URL的API被多次导入:Apifox默认将相同URL的API视为同一个接口,这可能导致新旧数据之间的冲突。
- 团队协作中的修改冲突:不同成员对同一个API的字段(如Mock数据、说明、请求示例等)进行了不同的修改。
1.2 Apifox Helper的冲突处理策略
1. 智能合并
- 机制:保留已修改的字段(如Mock数据、中文名、说明、请求示例、响应示例等),未修改的字段会被新数据覆盖。
- 优点:避免覆盖用户在 Apifox 中手动修改的内容,确保重要信息不丢失。
- 缺点:如果用户在代码中修改了某些字段(如说明),这些修改可能无法同步到Apifox中。
- 适用场景:适合需要保留Apifox中手动修改内容的场景。
2. 覆盖所有字段
- 机制:当两个接口的方法和路径相同时,新的API数据会完全覆盖旧的API数据。
- 优点:确保代码中的改动能够完全同步到Apifox中,避免数据不一致。
- 缺点:Apifox中手动修改的内容会被覆盖,可能导致重要信息丢失。
- 适用场景:适合需要完全同步代码改动的场景。
3. 不导入
- 机制:当两个接口的方法和路径相同时,第二次导入的API数据会被忽略,旧数据保持不变。
- 优点:避免重复导入,保留原始数据。
- 缺点:代码中的改动无法同步到Apifox中。
- 适用场景:适合需要避免重复导入的场景。
4. 保留两者
- 机制:当两个接口的方法和路径相同时,新数据会被导入,但旧数据不会被删除,两者同时存在。
- 优点:保留所有版本的数据,方便后续对比和选择。
- 缺点:可能导致数据冗余,增加管理复杂度。
- 适用场景:适合需要保留历史数据的场景。
1.3 适用范围
Apifox的冲突处理策略不仅适用于API,还适用于数据模型。用户可以根据实际需求,自由调整API和数据模型的冲突处理策略,确保数据同步的灵活性和准确性。
在Apifox中,冲突处理策略的设置路径如下:
- 打开 IntelliJ IDEA 软件,进入设置(Settings)。
- 找到并点击 Apifox Helper 选项。
- 在 Apifox Helper 设置页面中,选择上传到 Apifox。
- 在冲突处理部分,根据需要调整API和数据模型的冲突处理策略。
1.4 接口URL位置变化:是否需要同步更新文件夹结构
在API管理工具如Apifox中,当接口的URL位置发生变化时(例如从a控制器移动到b控制器),是否同步到新的文件夹是一个常见的需求。Apifox提供了两种处理方式:
- 不移动接口
-
含义:即使接口的URL发生了变化,接口仍然保留在原来的文件夹(如
a目录)中,不会自动移动到新的文件夹(如b目录)。 -
适用场景:
- 当你希望保持接口的组织结构不变,即使URL发生了变化。
- 当你认为接口的分类逻辑(如按功能模块划分)比URL的路径更重要时。
- 当你希望手动管理接口的移动,而不是自动跟随URL的变化。
- 跟随新的文件夹移动
-
含义:当接口的URL发生变化时,接口会自动移动到新的文件夹(如
b目录),以保持与URL路径的一致性。 -
适用场景:
- 当你希望接口的组织结构与URL路径保持一致。
- 当你认为URL路径的变化反映了接口的逻辑归属变化(如从
a控制器移动到b控制器)。 - 当你希望自动保持接口的组织结构,减少手动调整的工作量。
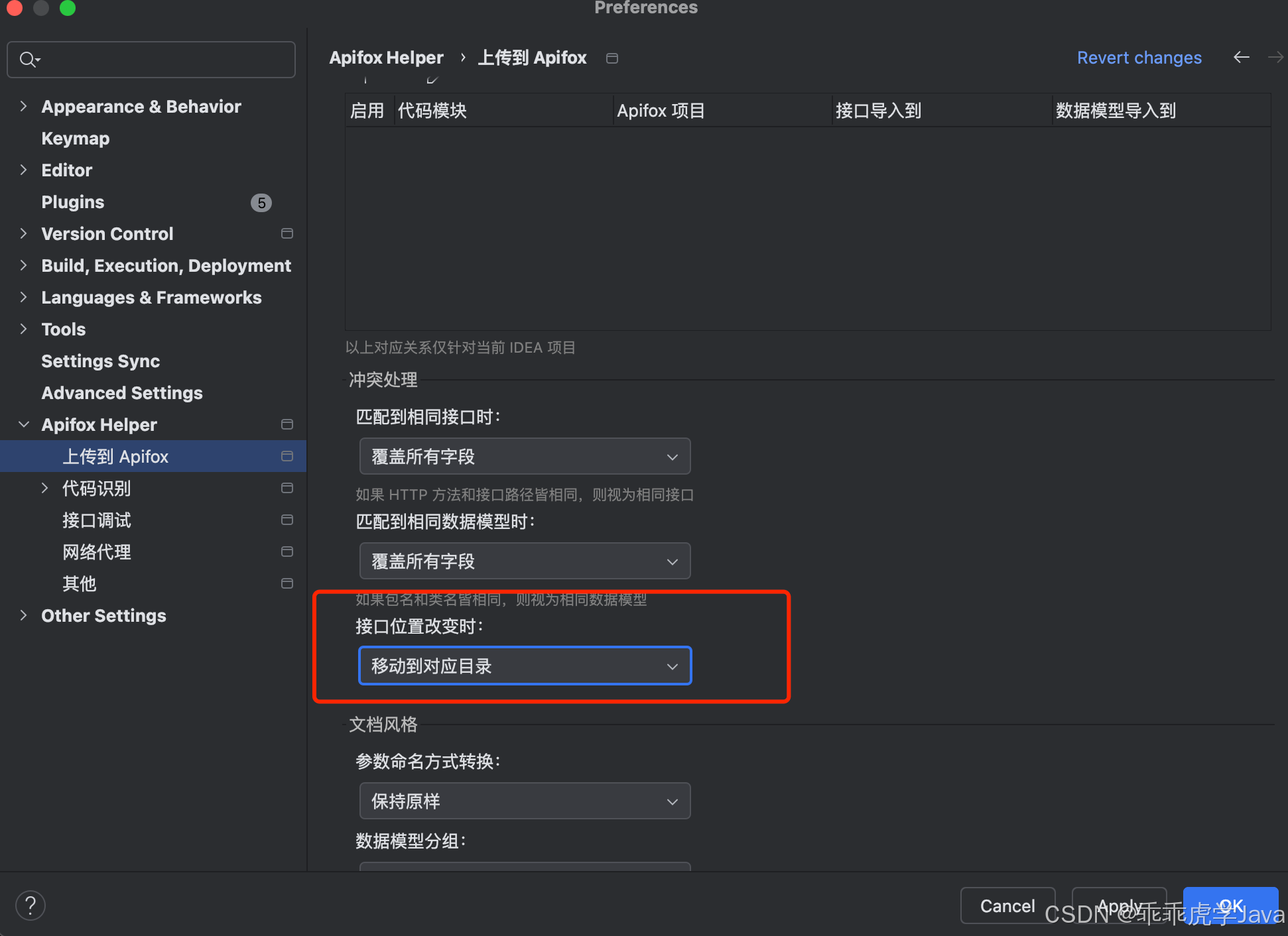
最后给大家我讲讲我的习惯,我个人是比较喜欢在代码里面进行管理的,在代码里面一把梭。我比较喜欢的组合是 覆盖所有字段、覆盖所有字段、移动到对应目录
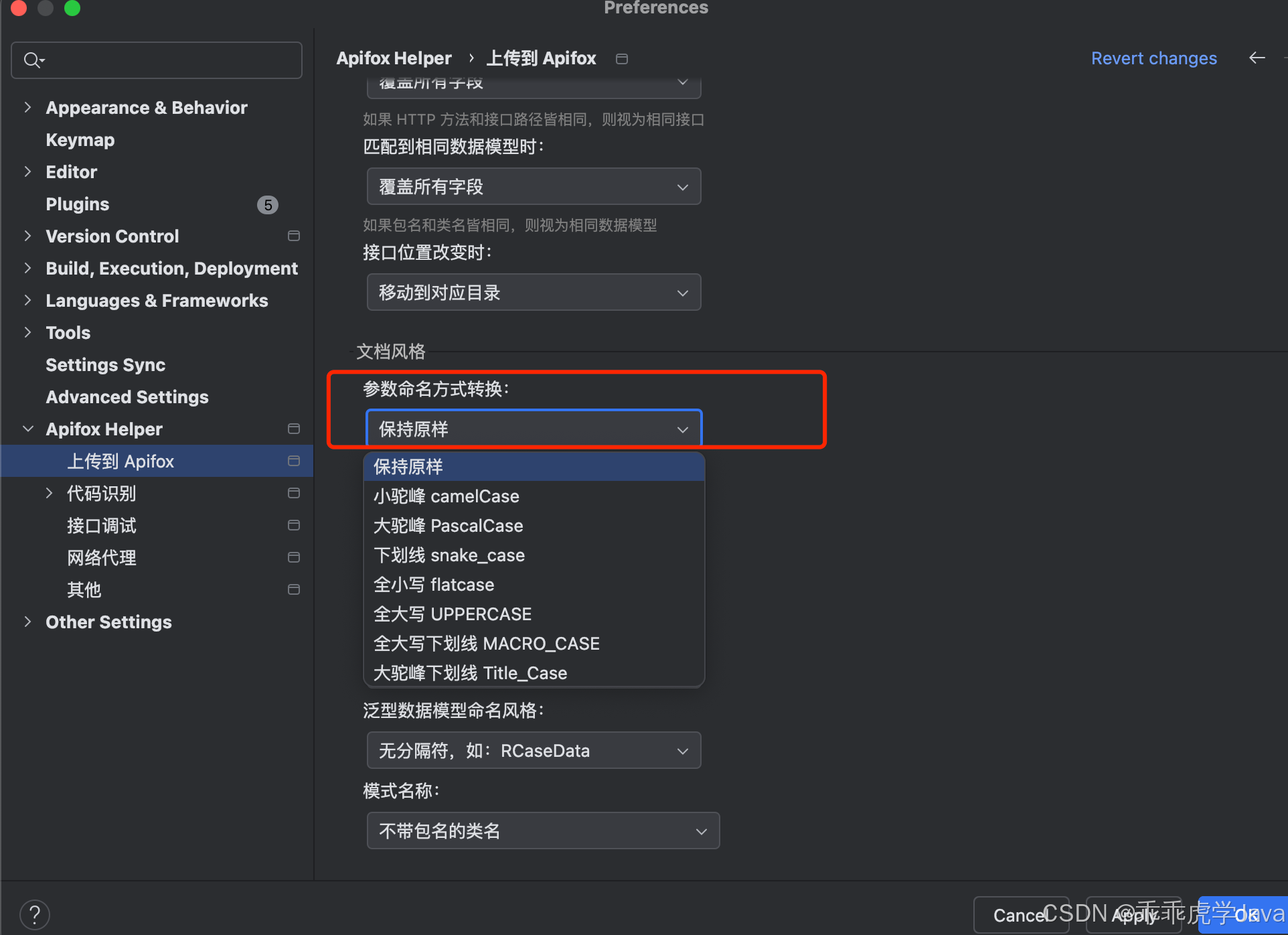
2. Apifox Helper 的文档风格
Apifox Helper 是一款强大的工具,旨在帮助用户将数据导出到 Apifox 时,灵活处理参数格式、排序规则以及泛型风格,以适应不同的开发需求和 OpenAPI 规范。以下是其主要功能和特点的详细说明:
2.1 参数格式处理
为了适应不同团队的编码规范和风格,Apifox Helper 支持对导入的参数进行多种格式处理,包括但不限于:
- 大驼峰(PascalCase):例如
UserName。 - 小驼峰(camelCase):例如
userName。 - 全小写(lowercase):例如
username。 - 全大写(UPPERCASE):例如
USERNAME。 - 蛇形命名(snake_case):例如
user_name。
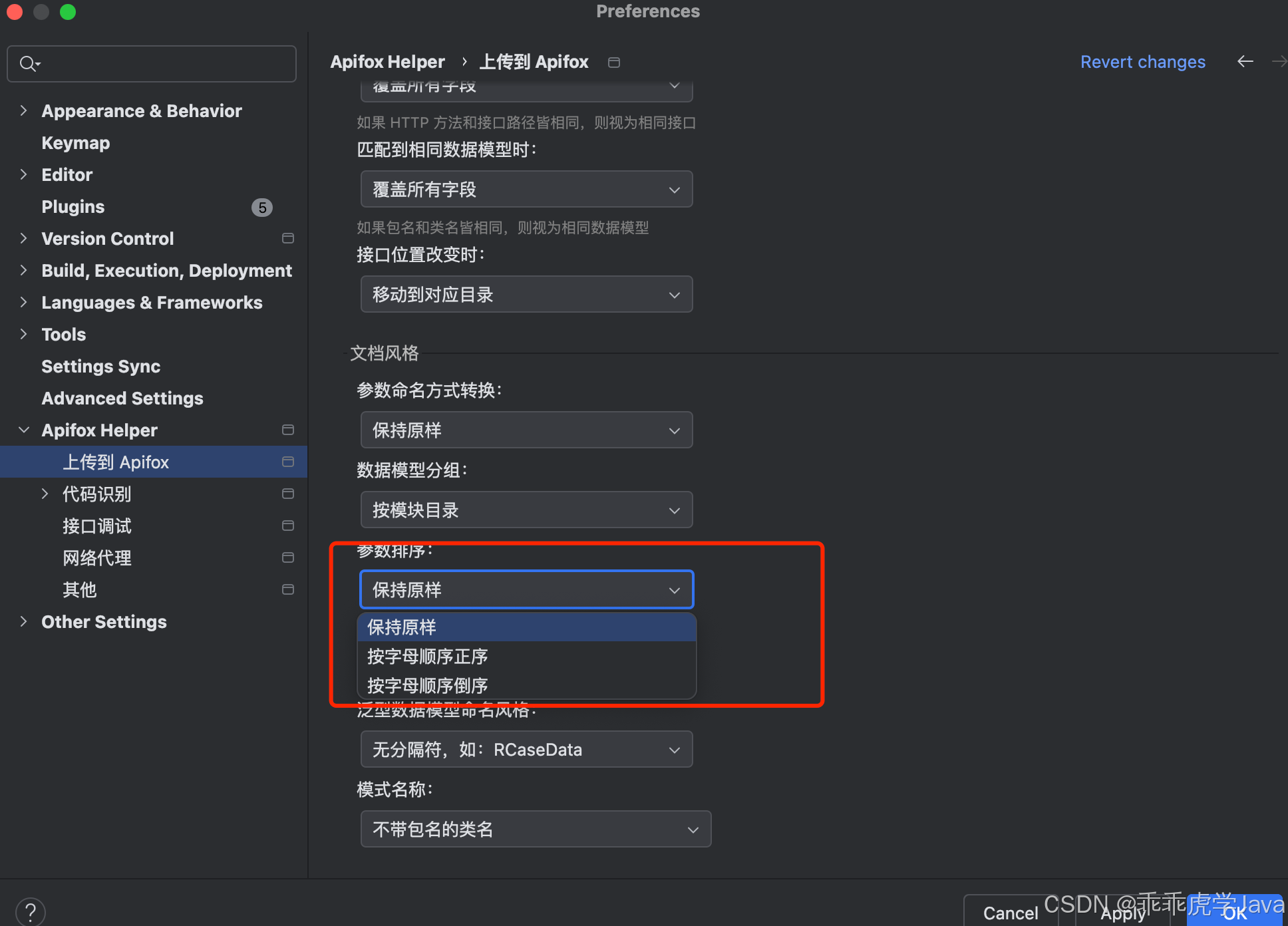
2.2 参数排序规则
Apifox Helper 提供了多种参数排序方式,帮助用户更好地组织和管理参数列表。支持的排序规则包括:
-
字母正序(A-Z):按照字母顺序从 A 到 Z 排列参数。
-
字母倒序(Z-A):按照字母顺序从 Z 到 A 排列参数。
-
父子类参数排序:
- 父类参数在前:优先排列父类参数,再排列子类参数。
- 子类参数在前:优先排列子类参数,再排列父类参数。
这些排序规则可以帮助用户快速定位参数,并按照逻辑层次组织参数结构,提升文档的可读性和维护性。
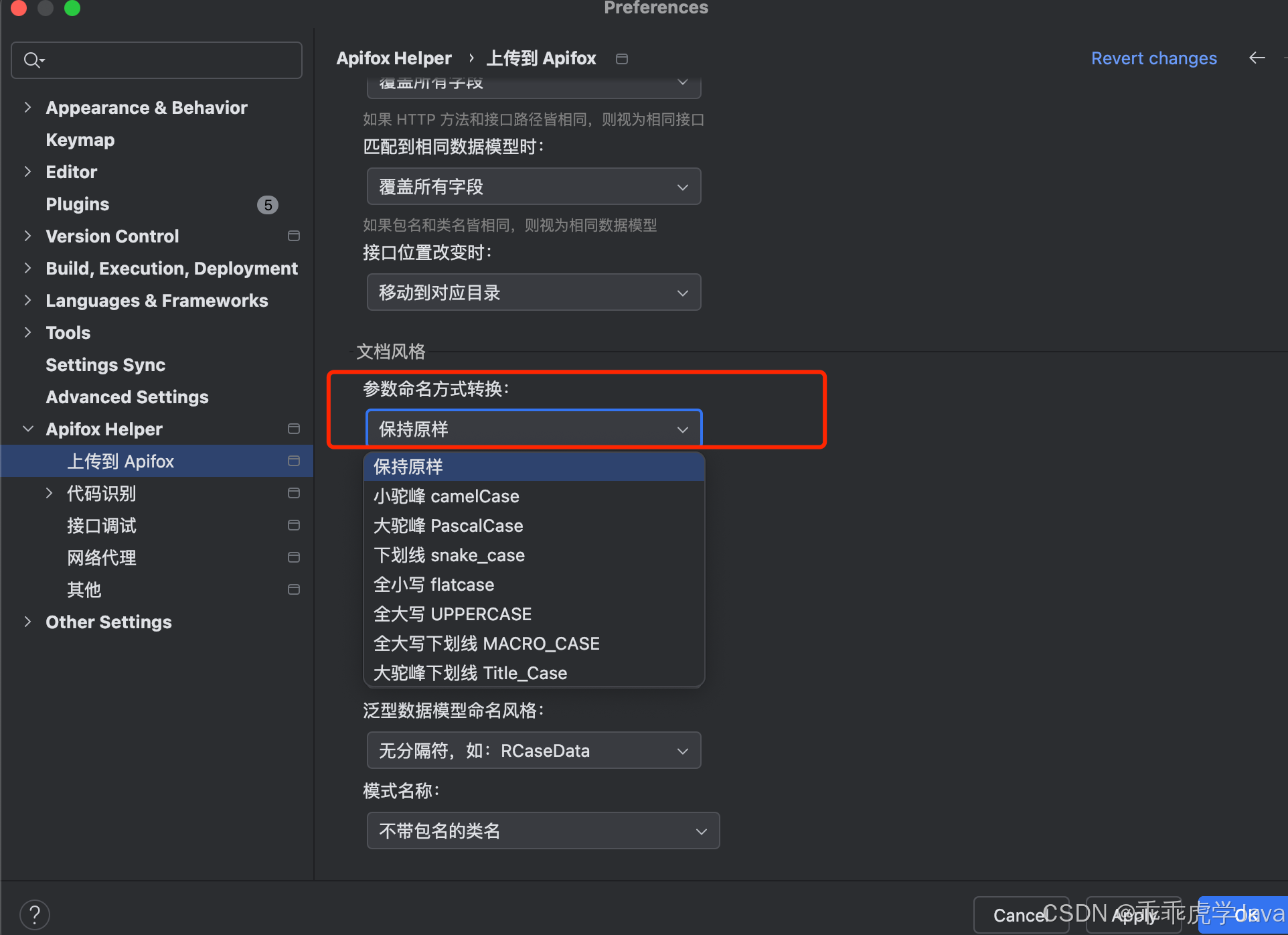
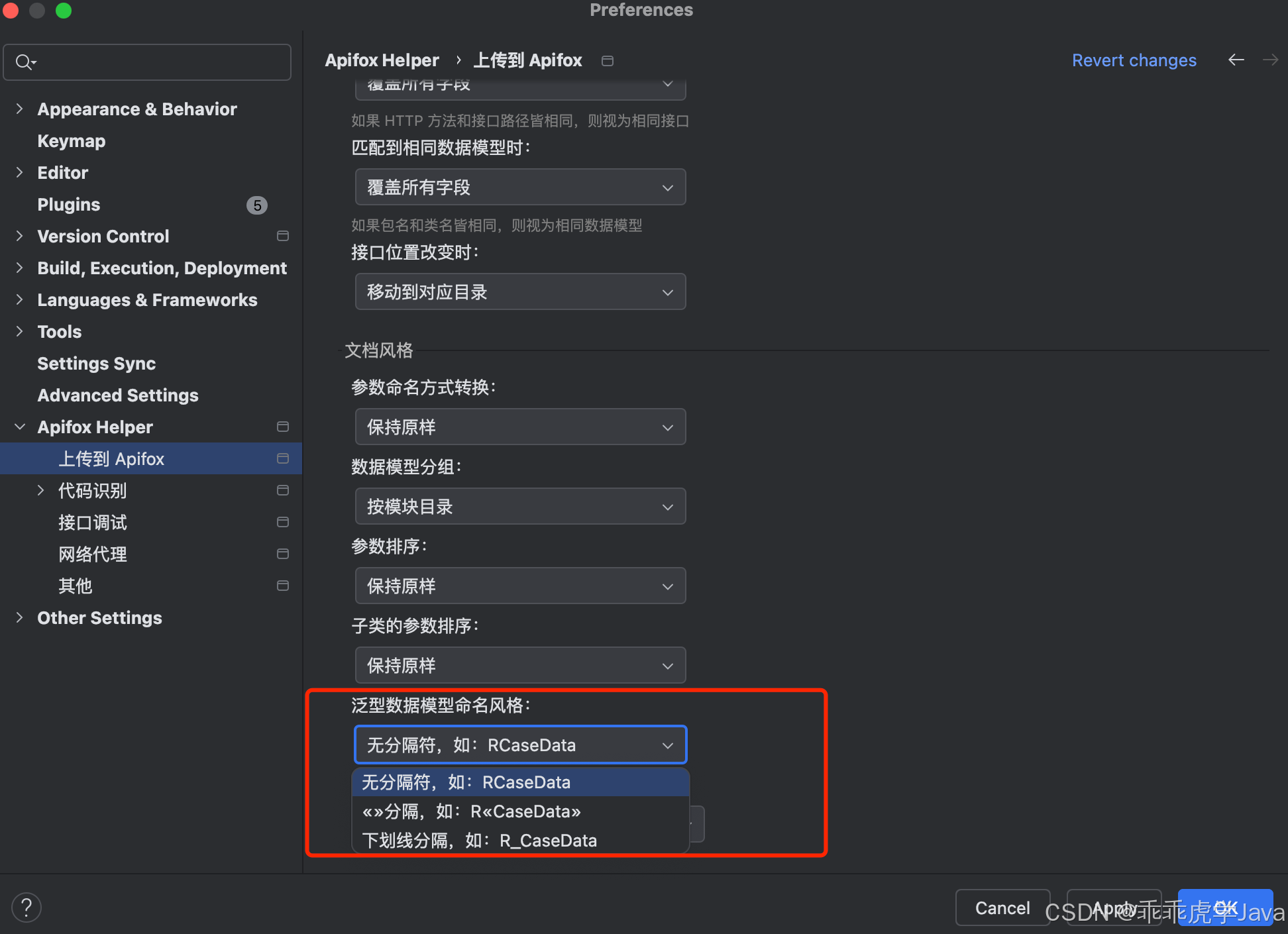
2.3 泛型风格组织
为了适应不同的 OpenAPI 规范和开发习惯,Apifox Helper 支持多种泛型风格的解析和组织,例如:
- R<T>:常见的泛型表示方式,例如
Response<User>。 - RT:将泛型简化为前缀或后缀形式,例如
ResponseUser。 - R<<T>>:支持多层泛型嵌套,例如
Response<List<User>>。
通过灵活的泛型风格支持,Apifox Helper 能够更好地适配不同团队的技术栈和 OpenAPI 规范,确保导出的接口文档与代码实现保持一致。
2.4 数据模型分组
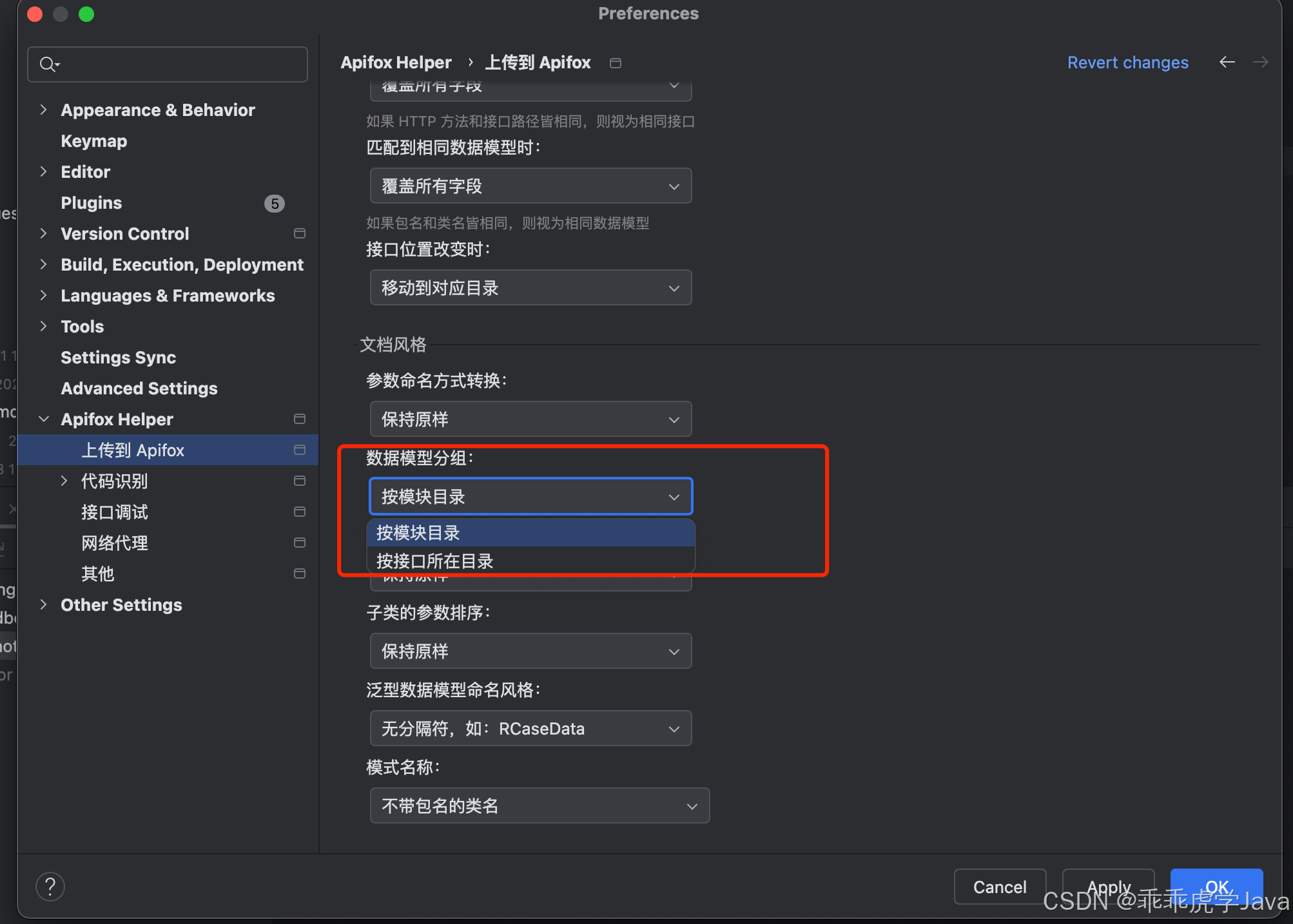
Apifox Helper 支持两种数据模型分组方式,帮助用户更好地组织和管理数据模型:
1. 按模块分组
-
功能描述:当代码由同一个模块管理时,所有数据模型会在该模块的根目录下进行排序,并显示在第一层级。
-
使用场景:
- 适合按功能模块划分的项目,例如用户模块、订单模块等。
- 所有与模块相关的数据模型集中管理,便于查找和维护。
2. 按文件分组
-
功能描述:根据接口所在的目录结构对数据模型进行分组,数据模型会在接口目录下多一个层级。
-
使用场景:
- 适合按文件或目录划分的项目,例如按控制器或服务划分。
- 数据模型的组织结构与代码目录保持一致,便于追溯和管理。
通过灵活的分组方式,用户可以根据项目结构选择最适合的组织形式,提升数据模型的可读性和可维护性。
2.5 数据模型名称调整
Apifox Helper 支持对数据模型名称进行灵活调整,用户可以选择是否在导出的数据模型名称中包含包名,具体选项包括:
1. 包含包名
-
功能描述:导出的数据模型名称包含完整的包路径,确保模型名称的唯一性和清晰性。
-
使用场景:
- 适合包路径较长或需要明确区分不同模块中同名数据模型的场景。
- 例如:
com.apifox.Response<com.apifox.User>
-
优点:
- 避免命名冲突。
- 明确数据模型的来源和归属。
2. 不包含包名
-
功能描述:导出的数据模型名称不包含包路径,仅显示模型名称。
-
使用场景:
- 适合包路径较短或不需要区分包名的场景。
- 例如:
Response<User>
-
优点:
- 简化数据模型名称,提升可读性。
- 适合小型项目或模块较少的情况。
通过灵活的名称调整功能,用户可以根据项目需求选择是否包含包名,确保数据模型名称既清晰又简洁。
总结
Apifox Helper 插件通过其强大的功能,为开发者提供了高效、灵活的API管理和文档导出解决方案。无论是冲突处理、参数格式调整、排序规则,还是数据模型的分组与命名优化,Apifox Helper 都能满足不同团队和项目的需求。以下是核心亮点:
- 冲突处理策略:提供智能合并、覆盖所有字段、不导入和保留两者等多种策略,帮助用户灵活应对API和数据模型的同步问题,确保数据一致性和完整性。
- 参数格式与排序:支持多种命名风格(如大驼峰、小驼峰、蛇形命名等)和排序规则(如字母正序、父子类参数排序等),提升文档的可读性和维护性。
- 泛型风格支持:适配多种泛型表示方式(如
R<T>、RT、R<<T>>),确保接口文档与代码实现保持一致,满足不同技术栈的需求。 - 数据模型管理:支持按模块或文件分组,灵活调整数据模型名称(包含或不包含包名),帮助用户更好地组织和管理数据模型,提升协作效率。
- URL位置变化处理:提供“不移动接口”和“跟随新文件夹移动”两种方式,适应不同团队对接口组织结构的需求。
通过以上功能,Apifox Helper 不仅简化了API管理流程,还显著提升了文档的清晰度和团队协作效率。无论是小型项目还是大型团队协作,Apifox Helper 都能成为开发者的得力助手,助力高效开发与文档管理。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









