







 本文提出了一种新型的腹部CT图像多器官分割模型,结合U-Net架构、空间注意力块和可变形卷积,以提高分割精度和鲁棒性。模型通过考虑器官位置和大小,有效减少背景干扰,结果显示在参数增加较少的情况下,分割性能显著提升,优于传统方法。
本文提出了一种新型的腹部CT图像多器官分割模型,结合U-Net架构、空间注意力块和可变形卷积,以提高分割精度和鲁棒性。模型通过考虑器官位置和大小,有效减少背景干扰,结果显示在参数增加较少的情况下,分割性能显著提升,优于传统方法。
1.介绍
Multi-organ segmentation network for abdominal CT images based on spatial attention and deformable convolution
基于空间注意力和变形卷积的腹部CT图像多器官分割网络
2022年发表在Expert Systems With Applications上。
Paper
2.摘要
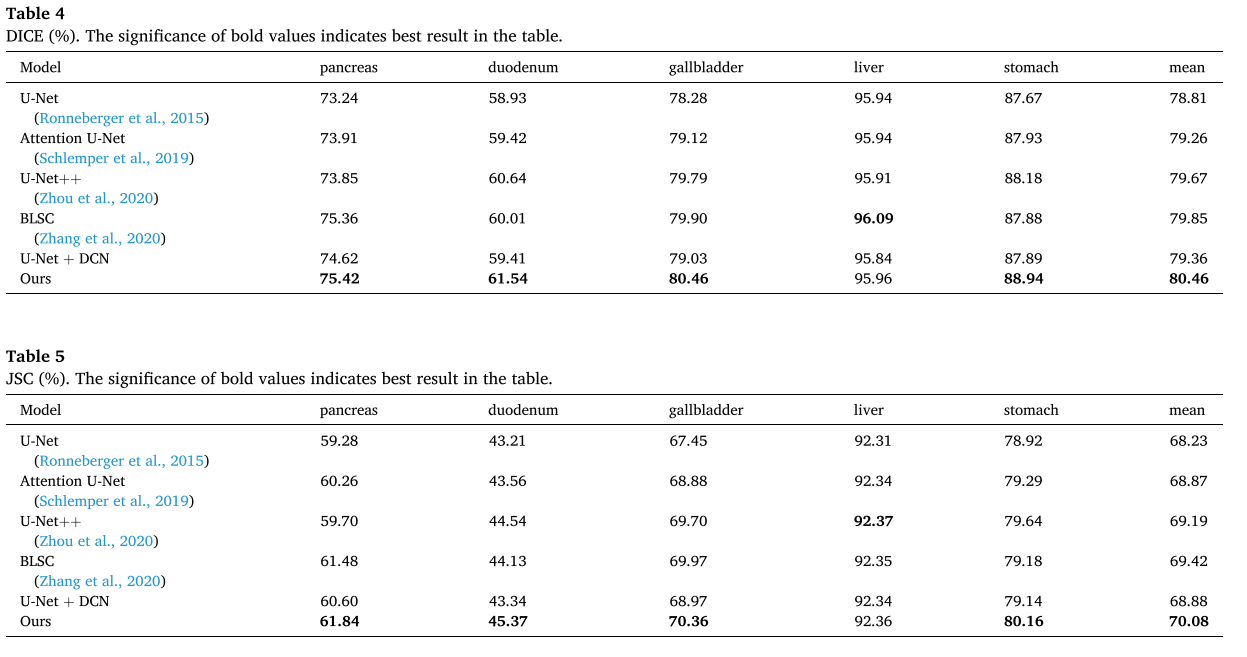
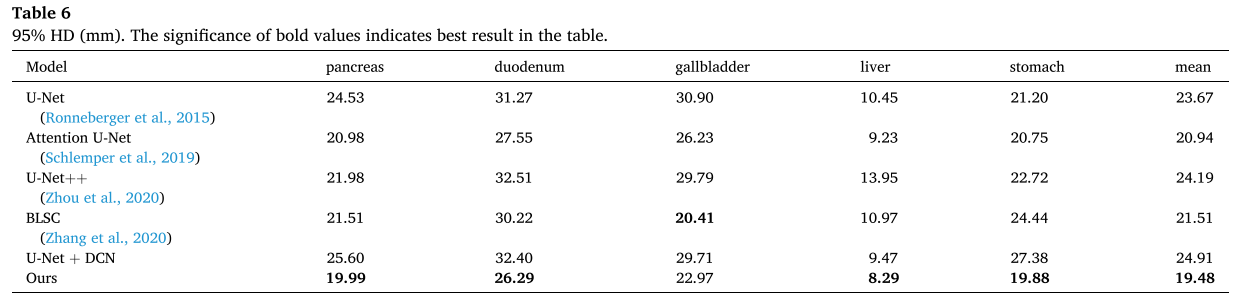
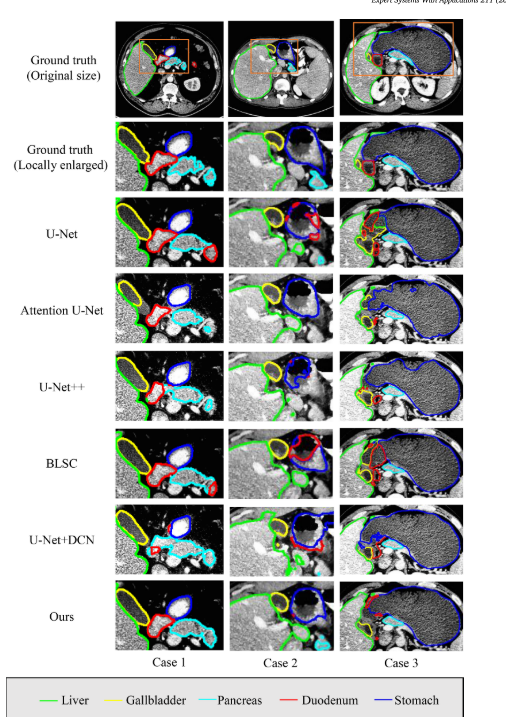
基于计算机断层扫描(CT)图像的多器官的准确分割对于腹部疾病的诊断(诸如癌症分期)和手术规划(诸如减少对靶器官周围的健康组织的损伤)是重要的。由于CT背景的复杂性以及不同器官的可变大小和形状,这项任务极具挑战性。针对肝胆胰外科手术中涉及的胰腺、十二指肠、胆囊、肝脏和胃等5个器官,提出了一种基于U-Net的分割模型。该模型具有可变形的感受野,并利用器官的位置和大小结构来减少复杂背景的干扰,使其成为一种高效准确的分割方法。提出了一种空间注意块,通过明确的外部监督学习空间注意图,在特征提取过程中突出感兴趣的器官区域。此外,一个可变形的卷积块被设置来处理的形状和大小的变化,通过产生合理的感受野不同的器官,通过额外的可训练的偏移。此外,通过使用多尺度注意图和高层语义信息,改进了U-Net的跳跃连接结构。在TCIA多器官分割数据集上将该模型与U-Net和几种改进的模型进行了比较,包括分割性能、时间消耗和模型参数。实验结果表明,该模型在模型参数增加7.86%的情况下,平均DICE为80.46%,有效地提高了整体分割性能。与U-Net相比,平均DICE增加了1.65%,平均JSC增加了1.79%,平均95%HD减少了4.08。这是一种有竞争力的多器官分割方法,具有较好的应用前景。
Keywords:U-Net、多器官分割、空间注意力、可变形卷积
3.Introduction
基于计算机断层扫描(CT)的器官的准确分割对于计算机辅助诊断、手术规划和放射疗法中靶器官的位置。它是深度学习在图像分割中的研究热点。准确的器官分割结果是诊断定量分析的前提,有助于病变的定位和分期。CT图像的手工分割是一种非常繁琐且容易出错的分割方法,因此自动分割技术得到了广泛的研究。多器官分割对于腹部疾病的诊断和治疗是必不可少的。腹部器官如肝、胆囊和胰腺在解剖学上密切相关,并且在功能上相互补充。因此,肝胆胰相关疾病的诊断和治疗需要考虑器官之间的关系,而不仅仅是一个器官的精确轮廓。
传统的CT图像分割方法,诸如基于阈值的、区域增长,通过使用强度或梯度的差异来实现。这种方法需要大量的专业知识和大量的人工设计的特征,并且最终的分割结果受到特征选择的影响。例如,基于阈值的分割方法对阈值的选择非常敏感,并且在具有不均匀灰度值和模糊边界的多器官分割中鲁棒性较差。因此,这些方法仅用于粗略的器官分割或特定器官的分割。逐渐地,以U-Net为代表的深度学习方法可以自动提取图像特征,无需复杂的非刚性配准。因此,这些模型在多器官分割的有效性和效率方面具有很大的优势。
然而,由于多器官分割的复杂性,基于深度学习模型的分割方法仍然面临两个明显的困难。首先,腹部CT的背景非常复杂,相邻器官之间的边界模糊。由于不同结构之间纹理和形状的细微变化,这些模糊边界的分割具有挑战性。第二,不同靶器官在大小和形状上有很大差异。因此,较小的结构更容易被忽略,这会影响较小器官的分割性能。
多器官分割由于背景复杂、边界模糊、器官大小和形状多变而极具挑战性。基于特定图像特征的分割方法只能解决部分器官的分割问题。为了解决这个问题,基于知识的方法从标记的数据集中获得不同器官的解剖知识,这提高了多器官分割的鲁棒性和准确性。常见的基于知识的方法包括多图谱,统计形状模型和深度学习模型。这些深度学习模型在相对较小的数据集上实现了更好的分割精度。同时,深度学习模型在分割速度和对不同器官的适应性方面也显示出明显的优势,这使得它们在临床应用中更具潜力。多图谱将来自训练数据集的图像配准到新图像,并结合图谱中的标签以生成分割结果。统计形状模型将训练数据集中的图像配准,以构建器官的相应形状分布的统计模型。这些方法由于图像配准效率低而耗时,其分割精度也受到配准精度的限制。深度学习模型无需寄存器,并在GPU的支持下实现高效分割。
为了解决上述困难,提出了基于U-Net的新骨干,例如3D网络、混合2D-3D网络和级联网络。这些方法可以利用三维空间信息或提供先验信息的器官,通过粗到细的分割策略。因此,它们实现了比U-Net更好的分割性能。然而,与U-Net相比,这些骨干网的复杂结构带来了大量的模型参数和计算成本,这限制了它们的应用。提高分段性能的另一种常见方法是将改进的块引入U-Net。改进的块,例如密集块和金字塔块被证明在自然图像分割,分类和定位任务中表现良好。然而,这种改进的块倾向于忽略器官在相对大小和位置方面的结构,并且容易受到复杂背景的干扰,这使得它们在边界模糊且大小和形状变化较大的多器官分割方面较差。基于U-Net的改进骨干,包括V-Net,H-DenseUNet和BLSC,都在一定程度上提高了分割精度。然而,它们过于复杂的结构使得它们使用起来更加昂贵,并且更难以训练。相比之下,将改进的块引入U-Net是一种更有效的方法。注意力块和局部块分别增强全局建模能力和局部感知能力。现有的改进块,包括用于增强全局建模能力的注意力块和用于增强局部感知能力的局部块,有助于提高分割性能。虽然改进后的块被证明是有效的,但在处理模糊边界和形状差异时仍然存在不足。注意力块通过动态加权突出显著特征。注意力图通常通过计算外部相关性来获得,乘法注意和自我注意。然而,他们都忽略了腹部器官的相对位置和大小的结构,这导致了粗糙的注意Map。
因此,本文提出了一个空间注意力块,通过明确的外部监督,以获得更准确的注意力地图。局部块包括密集块、残差块、金字塔块和可变形卷积,通过提供复杂的感受野来提高分割性能。其中,可变形卷积通过使用可训练的偏移量来处理大小和形状的变化,在计算成本方面提供了明显的优势。但由于边界模糊的影响,变形卷积容易产生不合理的感受野,导致分割精度不高。本文提出了一种静态变形卷积,以获得更适合不同器官的感受野。
本文模型能够产生可变形的感受野,并为编码器和解码器提供器官的位置和大小信息。尤其是针对肝胆胰外科手术中的胰腺、十二指肠、胆囊、肝脏和胃等5个关键器官的分割问题,提出了3种改进的注意力块,并将其引入到U-Net中:(1)空间注意力块,利用外部监督获取精细的注意力图,突出目标器官的位置和大小;(2)静态变形卷积的可变形卷积块,通过使用附加的可训练偏移来改进偏移场的生成,并为不同器官提供更合理的感受野;(3)利用多尺度注意图和高层语义信息协调编码器和解码器特征之间的语义差异,消除复杂背景的干扰。
4.模型结构解析
基于改进U-Net的backbone
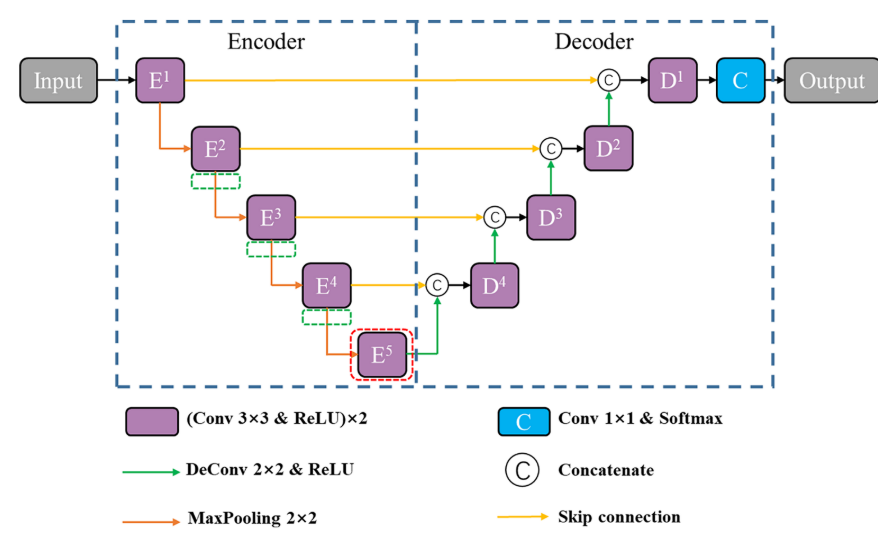
2D U-Net作为模型的骨干网,骨干网结构如上图所示。该算法采用对称的编解码器结构,将相同分辨率的编码器特征图与解码器特征图通过跳接结构进行复制和连接,以帮助恢复目标细节。为了解决内部协变量移位的问题并加快训练过程,在每个卷积层和ReLU激活层之间插入了一个批量归一化层。此外,每个卷积层中的滤波器数量设置为原始U-Net的一半,以减少训练时间并避免过拟合。
U-Net的编码器通过多层卷积、池化和ReLU实现特征提取和降维。由于复杂背景的影响,特征提取过程中容易丢失目标信息。因此,在池化层之前添加三个空间注意力块以处理该问题,其中池化层在上图中由绿色虚线框标记。同时,为了避免将无关的背景信息传递给解码器,对跳跃连接进行了改进,以充分利用多尺度注意力图的优势。最后,在上图中由红色虚线框标记的编码器的最深级被可变形卷积块代替,以通过使用高级特征为不同器官提供合适的感受野。
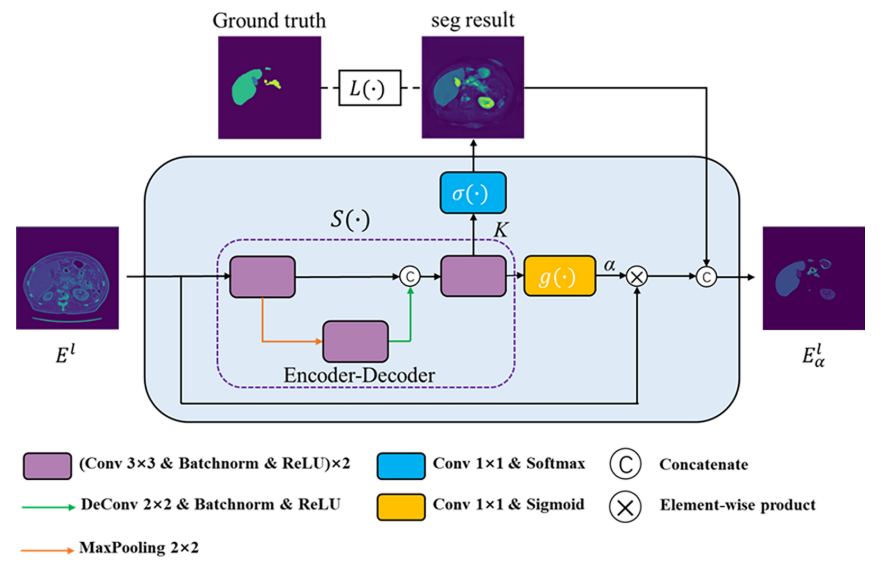
空间注意力块
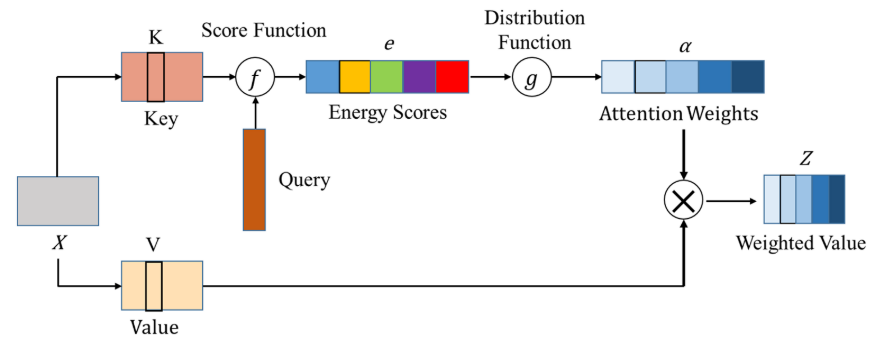
普通注意力的工作机制是:首先对输入信息计算注意力分布,然后根据注意力分布对源特征值进行加权。即
其中K和V是通过对源特征X进行编码而获得的,分别称为Key和Value; Query q是与任务相关的查询向量或矩阵。注意力模型利用得分函数f(·)对Key和Query之间的相关性进行评价,得到相应的能量得分e。分布函数g(·),如Sigmoid和Soft Max,将e转换为[0,1]范围内的注意力权重α。最后,通过将α乘以V来获得加权值Z。流程如下:
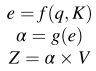
为了获得更准确的注意力图,提出了一种空间注意力块,以利用腹部器官的相对位置和大小的结构。如下图所示,空间注意力模块将编码器的层
l
l
l 输出的特征图
E
l
E^l
El 作为输入,并通过外部监督获得注意力图;基于注意力图,空间注意力模块修剪特征图中的响应以保留与分割相关的激活,然后输出
E
α
l
E^l_α
Eαl。下图中虚线框标记的结构可以被视为轻量级分割网络,为编码器的其余阶段提供目标器官的大小和位置的先验信息。
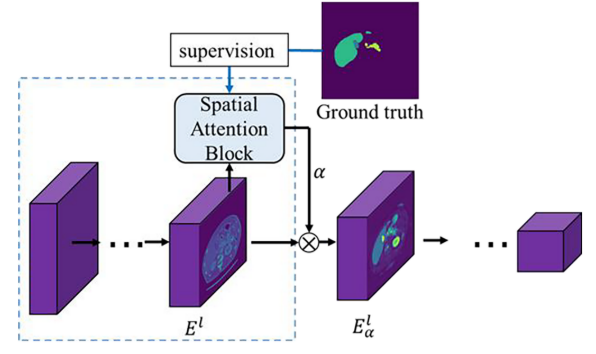
下图给出了所提出的空间注意力块的结构。S(·)是一个轻量级的编码器-解码器模型,用于获得粗略的分割结果。注意机制的过程可以表示为:
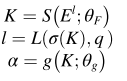
其中
θ
F
θ_F
θF 是S(·)的可学习参数; σ(·)是1 × 1卷积层和SoftMax激活层的组合,将K转换为粗略的分割结果; q是真值图;L(·)是分割损失函数;具有可学习参数
θ
g
θ_g
θg 的分布函数g(·)将1 × 1卷积层和Sigmoid激活层组合在一起。为了区分不同的器官,将粗分割结果与加权特征图连接以获得最终特征图
E
α
l
E^l_α
Eαl,其表示为:
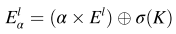
其中,
⊕
\oplus
⊕ 表示通道维度上的连接操作。
可变形卷积块
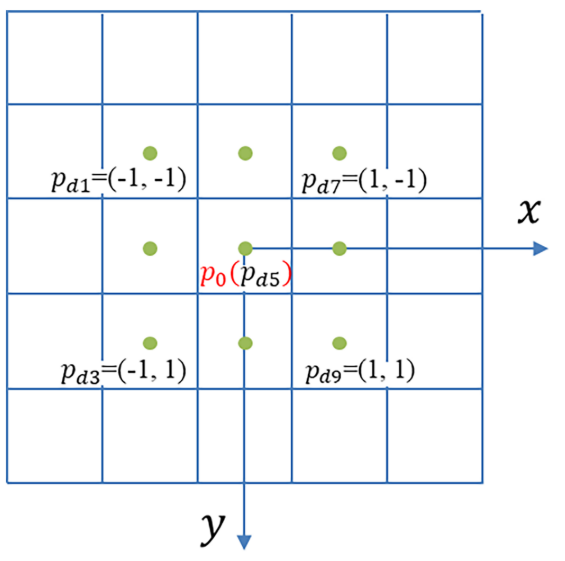
可变形卷积通过可训练偏移获得自适应感受野。以3 × 3卷积核为例,常规卷积的采样网格可以表示为 G d = { p d 1 , p d 2 , . . . , p d 9 } G_d = \{p_{d1},p_{d2},...,p_{d9}\} Gd={pd1,pd2,...,pd9},其中p_{d1} =(−1,−1),p_{d2} =(−1,0),…,p_{d5} =(0,0),p_{d9} =(1,1)。如下图所示,对于特征图上的位置p0,绿色点表示基于具有相应偏移的Gd获得的采样点,其中p_{d5}没有偏移并且与p0重合。对于每个输入特征图X,输出特征图Y在位置p0处的预测值可以表示为:
变形卷积中的预测值可以表示为:
其中pdi枚举Gd中的位置; Δpd是附加偏移,Wd是对应的权重向量。由于偏移距Δpd通常不是整数,因此偏移后采用双线性插值确定采样点的值。通过3 × 3卷积运算从X获得称为偏移场的特征图XO,每个位置p0对应的特征向量 X O X^O XO(p0)是预测Y(p0)所需的额外偏移Δpd。
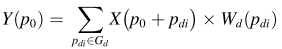
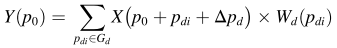
为了在生成偏移场
X
O
X^O
XO时获得更多的上下文信息,在可变形卷积块中添加附加的静态变形卷积,如下图所示。
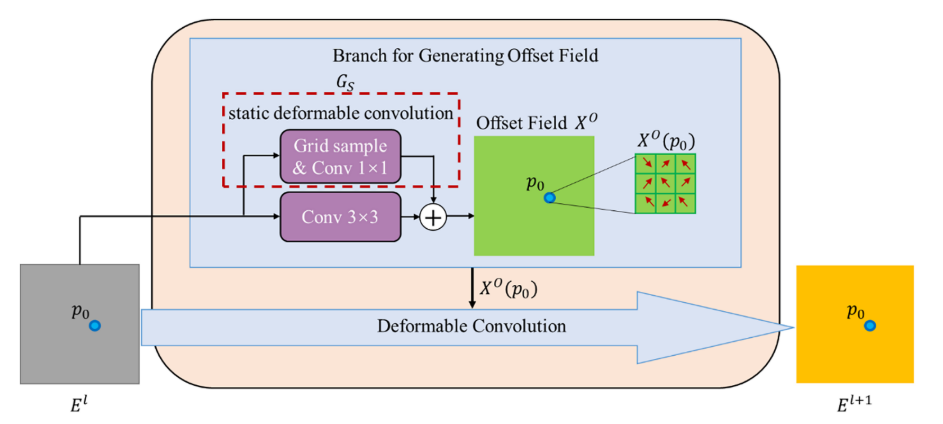
静态可变形卷积中的所有滤波器共享静态可变形卷积中的一组采样位置,这组采样位置是网络的可学习参数,并且在训练之后变得固定。这些采样点提供的不规则感受野使偏移场XO更合理。
上图给出了可变形卷积块的结构。设Gs为静态可变形卷积的采样网格。Gs被定义为
{
p
s
1
,
p
s
2
,
.
.
.
,
p
s
n
}
\{p_{s1},p_{s2},...,p_{sn}\}
{ps1,ps2,...,psn},其中
p
s
i
=
(
x
i
,
y
i
),
i
=
1
,
2
,
.
.
.
,
n
p_{si} =(x_i,y_i),i = 1,2,...,n
psi=(xi,yi),i=1,2,...,n。
p
s
i
p_{si}
psi表示每个采样位置与预测位置的偏移。p0处所需的偏移量可以计算为:
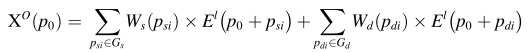
其中psi枚举Gs中的位置,Ws是相应的权重向量; Gd是3 × 3卷积的采样网格,pdi枚举Gd中的位置,Wd是相应的权重向量。Gs由网格采样操作实现,Ws由基于Pytorch的1 × 1卷积层实现。Gs由常规3 × 3卷积的采样网格Gd初始化。偏移字段XO具有与输入特征图El相同的分辨率。XO的通道数为2 · k2,其中k设置为3。则p0中输出的最终值可以表示为:
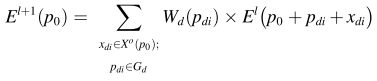
其中pdi枚举Gd中的位置,xdi枚举
X
O
X^O
XO(p0)中的位置。
整体结构
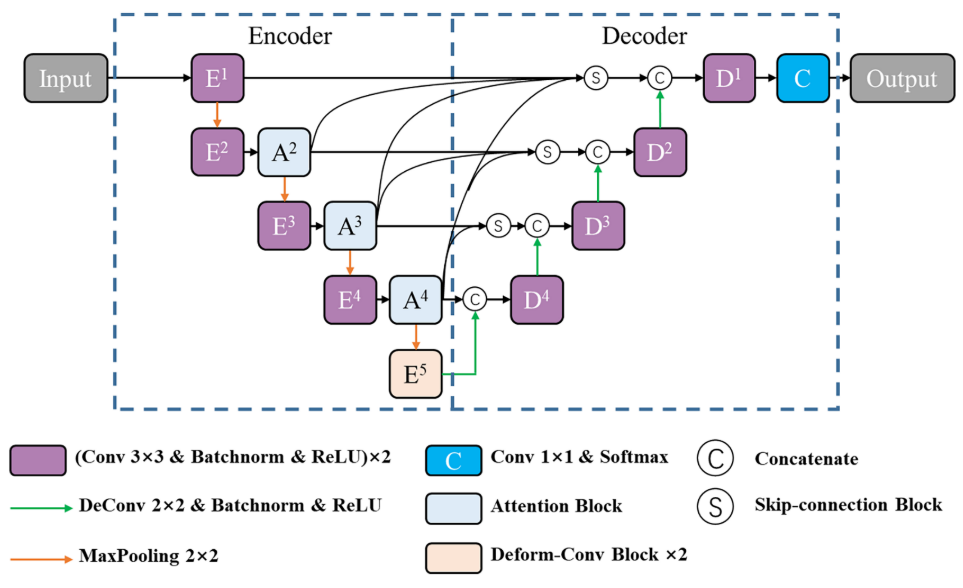
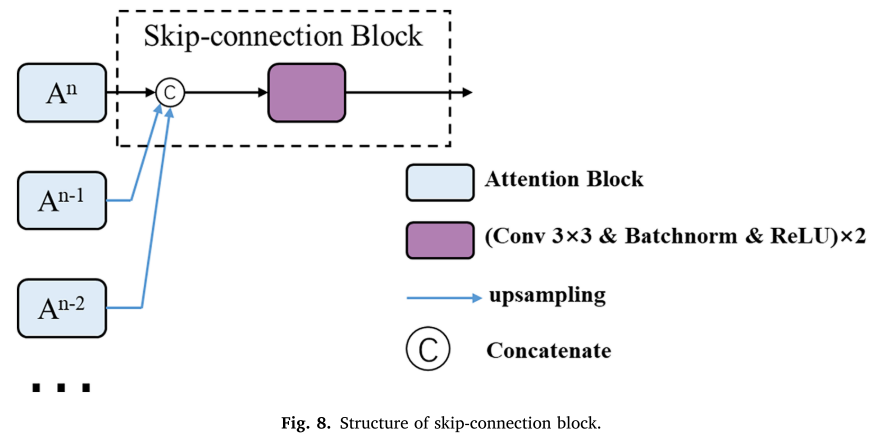
在U-Net的编码器中,除了第一层之外,空间注意力块被插入到每个池化层之前,因为编码器的较浅层通常提取低级特征。深度监督用于将空间注意力块的所有分割损失与网络的最终损失进行联合收割机组合。提出了一种新的跳跃连接以减少解码时复杂背景的干扰。如上图所示,跳跃连接块通过将该阶段的特征图与来自更深阶段的高级特征图组合来利用多尺度注意力图和高级语义信息。通过上采样操作,将来自较深阶段的高级特征图恢复为与较浅特征图相同的大小。然后,所有的特征图在通道维度上连接起来,并通过3 × 3卷积运算转换为新的特征图。通过提出的跳接块,协调了编码器和解码器特征之间的语义差异。可变形卷积依赖于高级特征图。因此,当在较浅的层中使用时,其性能较差。此外,较浅层中较大尺寸的特征图导致大量计算。因此,在U-Net编码器的最深级中使用可变形卷积块来处理不同器官的变化。具体来说,编码器中的最后两个3 × 3卷积层被所提出的可变形卷积块取代。
5.结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









