







回归经典,发现自己不能看懂Vit代码,重新来学一遍
1.论文介绍
An Image is worth 16X16 words: Transformers for image recognition at scale
一幅图像相当于16X16个字:用于大规模图像识别的Transformer
ICLR 2021 谷歌团队
Paper Code
2.摘要
虽然Transformer架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。本文证明了这种对CNN的依赖是不必要的,直接应用于图像块序列的纯Transformer可以在图像分类任务中表现得非常好。当对大量数据进行预训练并传输到多个中型或小型图像识别基准测试(ImageNet,CIFAR-100,VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)获得了出色的结果,同时需要更少的计算资源进行训练。
Keywords:纯Transformer,vision Transformer,无CNN
3.Introduction
之前基于自我注意力的架构,特别是Transformer,已成为自然语言处理(NLP)的首选模型。主要的方法是在大型文本语料库上进行预训练,然后在较小的特定于任务的数据集上进行微调。但在计算机视觉中,卷积架构仍然占主导地位。之前的尝试是CNN类架构与自我注意力相结合,还有一些完全取代卷积。后一种模型虽然理论上是有效的,但由于使用了特殊的注意力模式,尚未在现代硬件加速器上有效地扩展。
本文尝试将标准的Transformer直接应用于图像,并尽可能少地进行修改。要做到这一点,我们将图像分割成补丁,并提供这些补丁的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像补丁的处理方式与标记(单词)相同。我们以监督的方式训练图像分类模型。
当在没有强正则化的中型数据集(如ImageNet)上进行训练时,这些模型的准确率比类似大小的ResNet低几个百分点。这一看似令人沮丧的结果可能是意料之中的:变压器缺乏一些CNN有的归纳偏见,例如平移等变性和局部性,因此当在不足的数据量上训练时不能很好地泛化。但在大数据集上,这种情况就会有所改善。
4.模型详解
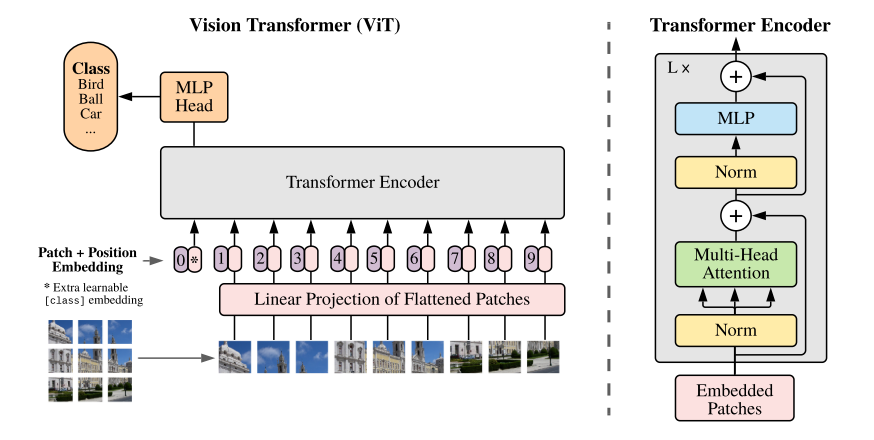
上图是ViT的整体架构。它输入一个patch embedding序列,经过Encoder和MLP Head,得到分类结果。
1)输入一张2D图片,首先将图像
x
∈
R
H
×
W
×
C
x ∈ R^{H×W×C}
x∈RH×W×C 划分成块即patch(一个patch就是一个token,不能把像素点整成一个token,是因为计算量太大,复杂度太高):
x
i
∈
R
h
×
w
×
C
x_i∈ R^{h×w×C}
xi∈Rh×w×C,如果h=w=P,则(P,P)就是每个图像补丁patch的分辨率,
x
i
∈
R
P
×
P
×
C
x_i∈ R^{P×P×C}
xi∈RP×P×C,其中(H,W)是原始图像的分辨率,C是通道数。一张图像
x
∈
R
H
×
W
×
C
x ∈ R^{H×W×C}
x∈RH×W×C 划分成
N
=
H
W
/
P
2
N = HW/P^2
N=HW/P2个patch
x
i
∈
R
P
×
P
×
C
x_i∈ R^{P×P×C}
xi∈RP×P×C。
2)patch为正方形,不能直接输入Transformer中,还需要进行embedding。
a:首先把patch展平,这样patch序列就变成:
x
p
∈
R
N
×
(
P
2
⋅
C
)
x_p ∈ R^{N×(P^2·C)}
xp∈RN×(P2⋅C) ,
N
=
H
W
/
P
2
N = HW/P^2
N=HW/P2是补丁的数量,它也是Transformer的有效输入序列长度。
b:Transformer在其所有层中使用恒定的潜在向量大小D,(会给出dim or embedding size,dim与P×P有差别)所以需要一个线性投影层进行映射,最后的映射结果是patch embedding。
3)a:后面为了与原Transformer相符,还生成Class 的Token embedding:(但是这个其实没必要,论文中有提加不加结果一样的),类似于BERT的[class]令牌,将可学习的嵌入预先添加到嵌入的补丁序列(
z
0
0
=
x
c
l
a
s
s
z^0_0 = x_{class}
z00=xclass),其在Transformer编码器(
z
L
0
z^0_L
zL0)的输出处的状态用作图像表示y
y
=
L
N
(
z
L
0
)
y = LN(z^0 _L)
y=LN(zL0),在预训练和微调期间,将分类头连接到
z
L
0
z^0_L
zL0。分类头由具有一个隐藏层的MLP在预训练时间和由单个线性层在微调时间实现。
b:生成所有序列的位置编码:位置嵌入被添加到patch嵌入以保留位置信息。使用标准的可学习的1维的位置嵌入(因为使用更高级的2D感知位置嵌入的性能并没有提升)。
c:token embedding + 位置编码,得到的嵌入向量序列作为编码器的输入。
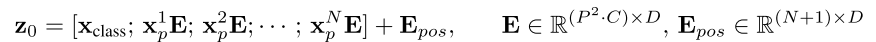
4)原Transformer编码器由交替层的多头自我注意力(MSA)和MLP块构成。在每个块之前应用层范数(LN),并且在每个块之后应用残差连接。MLP包含具有GELU非线性的两个层。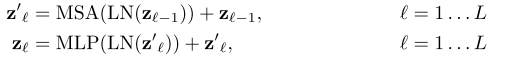
多头自注意力:
标准的自注意力是神经架构的一个流行的构建块。对于输入序列 z ∈ R N × D z ∈ R^{N×D} z∈RN×D中的每个元素,计算序列中所有值v的加权和。注意力权重 A i j A_{ij} Aij基于序列的两个元素与它们各自的查询 q i q^i qi和关键字 k j k^j kj表示之间的成对相似性。
多头自注意(MSA)是SA的扩展,其中并行运行k个自注意操作,称为“头”,并投影它们的级联输出。为了在改变k时保持参数的计算和数量恒定,Dh通常设置为D/k。
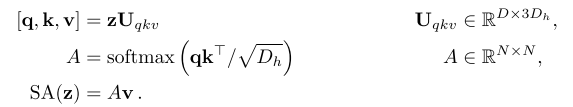
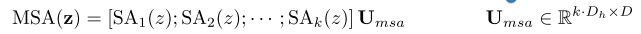
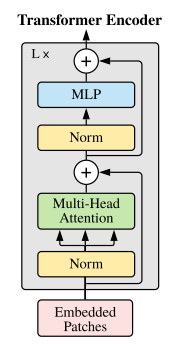
即有N个Encoder,每个Encoder先norm,再自注意力,再残差,再norm,再MLP,再残差,重复N次,得到一个输出,这里每个token都会有一个输出。
5)最后把第一个Token的输出作多分类任务。完成了全部流程。
归纳偏差(Inductive Bias):
指的是模型对数据的偏好或先验知识。文中指出,相比于CNNs,视觉Transformer具有更少的图像特定归纳偏差。在CNNs中,局部性、二维邻域结构和平移等变性都嵌入到整个模型的每一层中。但在ViT中,只有MLP层是局部的和平移等变的,而自注意力层是全局的。二维邻域结构只被非常节俭地使用:在模型的开头通过将图像切成块,并在微调时调整不同分辨率图像的位置嵌入(如下所述)。除此之外,初始化时的位置嵌入不包含关于块的2D位置的信息,所有块之间的空间关系都必须从头开始学习。
混合架构(Hybrid Architecture):
作为原始图像块的一种替代,输入序列可以由CNN的特征图形成。在这种混合模型中,将图像块嵌入投影 E(公式1)应用于从CNN特征图中提取的块。作为一种特殊情况,块可以具有空间尺寸为1x1,这意味着输入序列是通过简单地将特征图的空间维度展平并投影到Transformer维度获得的。分类输入嵌入和位置嵌入与上述相同方式添加。
微调和更高的分辨率:
通常情况下,会在大型数据集上预训练ViT,并对(较小的)下游任务进行微调。为此,移除预训练的预测头部,并附加一个零初始化的 D × K 前馈层,其中 K 是下游任务类别的数量。通常,将分辨率设置得比预训练时更高会更有益处。当输入更高分辨率的图像时,保持块大小不变,这导致了更大的有效序列长度。Vision Transformer可以处理任意长度的序列(受内存约束),然而,预训练的位置嵌入可能不再有意义。因此,根据它们在原始图像中的位置对预训练的位置嵌入进行二维插值。需要注意的是,这种分辨率调整和块提取是人为将有关图像的2D结构的归纳偏差手动注入到Vision Transformer中的唯一时机。
Transformer 与ViT的不同(Encoder):
1)Norm归一化放在多头自注意力前和MLP前。
2)序列长度一致,不补零。
3)更简单。
5.核心代码
下面结合ViT模型PyTorch代码进行剖析。
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
# 前馈神经网络
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
# 它接受一个维度为 dim 的输入,使用了大小为 hidden_dim 的隐藏层。在每个线性层之后都使用了 Layer Normalization 和 GELU 激活函数。在两个线性层之间添加 dropout 正则化。
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
# 多头注意力
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.norm = nn.LayerNorm(dim)
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# 先Norm 这也是与Transformer不同的地方
x = self.norm(x)
# 把输入x 分成qkv元组
qkv = self.to_qkv(x).chunk(3, dim = -1)
# 分成多个头
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
Transformer:
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
# norm层
self.norm = nn.LayerNorm(dim)
# depth个encoder
# 每个encoder由多头自注意力和MLP or 前馈神经网络交叉组成
# 这里它把Norm层放到MSA和MLP里边去了 这样不好 网络结构就不那么鲜明了
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
FeedForward(dim, mlp_dim, dropout = dropout)
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
ViT:
class ViT(nn.Module):
'''
image_size:输入图像的宽高
patch_size:想要分割的patch的宽高
num_classes:分类的类别数
dim:输入encoder中想要的维度
depth:encoder的个数
heads:自注意力头的个数
mlp_dim:
pool:要不要cls token
'''
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
# 能分成的patch数目,即N
num_patches = (image_height // patch_height) * (image_width // patch_width)
# patch的维度,展平后的维度
patch_dim = channels * patch_height * patch_width
# 不加cls就池化
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
# 1.拉平
# 2.经过Norm层
# 3.通过线性映射层进行需要维度的映射
# 4.Norm
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
# 位置编码生成
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# 初始化cls token
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# dropout 减少过拟合
self.dropout = nn.Dropout(emb_dropout)
# 输入到transformer中
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
# 不做任何操作
self.to_latent = nn.Identity()
# 最后分类,前面应该加上Norm层才对
self.mlp_head = nn.Linear(dim, num_classes)
def forward(self, img):
# 生成patch embedding
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# 每个batch 都要有cls token
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
# 拼到x上
x = torch.cat((cls_tokens, x), dim=1)
# 加上位置编码
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
# 输入到encoder中
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
# 多分类输出
x = self.to_latent(x)
return self.mlp_head(x)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









