









 本文探讨了GM(1,1)模型在中短期人口预测中的应用,强调其优点如高精度计算和MATLAB集成,同时指出其对历史数据依赖性和长期预测误差的问题。通过级比检验和多因素GM(1,n)模型提升,文章介绍了建模步骤、代码实现及检验方法,包括残差检验、关联度检验等。
本文探讨了GM(1,1)模型在中短期人口预测中的应用,强调其优点如高精度计算和MATLAB集成,同时指出其对历史数据依赖性和长期预测误差的问题。通过级比检验和多因素GM(1,n)模型提升,文章介绍了建模步骤、代码实现及检验方法,包括残差检验、关联度检验等。
灰色预测
参考文章
适用于中短期预测
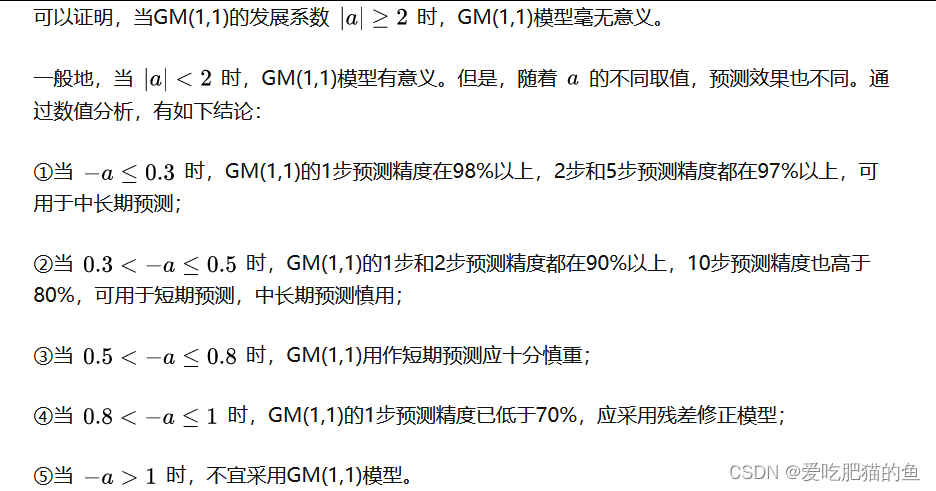
1、GM(1,1)模型的适用范围
(1)GM(1,1)模型的优点
GM(1,1)预测模型在计算过程中主要以矩阵为主,它与MATLAB的结合解决了它在计算中的问题,由MATLAB编制的灰色预测程序简单实用,容易操作,预测精度较高。
(2)GM(1,1)模型的缺点
该模型时指运用曲线拟合和灰色系统理论对我国人口发展进行预测的方法,因此它对历史数据有很强的依赖性,而且GM(1,1)的模型没有考虑各个因素的联系。因此,误差偏大,尤其是对中长期预测,例如对中国人口总数变化的情况做长期预测时,误差偏大,脱离实际,下面我们来讨论GM(1,1)模型的适用范围。
GM(1,1)模型的白化微分方程:
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/0a812f194bfd19bd74169b8ec6d2b91f.png)
其中 :a 为发展系数。
如果要考虑到多因素的联系和影响,此时我们不妨建立GM(1,n)模型,GM(1,n)模型能模拟系统发展的动态过程,不仅吸收了传统的灰色模型的建立,而且建立了多种改进的灰色模型,提高了预测精度。
2、算法步骤
1、数据的级比检验
 2、建立GM(1,1)模型
2、建立GM(1,1)模型
参考文章
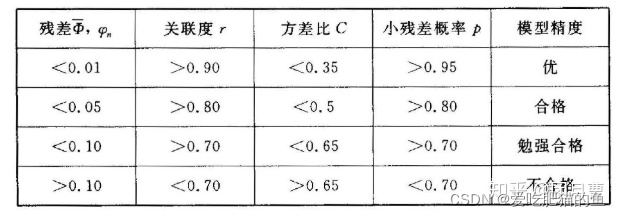
3、模型检验
检验方法:
①残差检验

②关联系数检验
 计算关联度r:
计算关联度r:
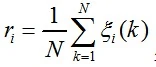
判别标准:λ=0.5时,r>0.6即满足检验。
③后验差检验

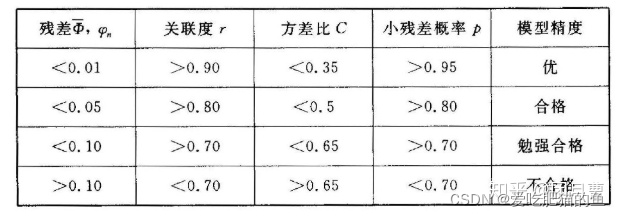
④小误差概率检验

5、残差级比值检验

检验对照值
3、代码
import numpy as np
import math
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
data = np.loadtxt('D:\Python Project_1\Data\grey data.txt')#原始数据
DATA_SIZE = data.shape[0]#数据量
ALPHA = 0.6#发展系数
#开始模型检验
#1、级比检验,
X = np.array([math.exp(-2/(DATA_SIZE+1)),math.exp(2/(DATA_SIZE+1))])#级比检验范围
LAMBDA = np.array([data[i-1]/data[i] for i in range(1,DATA_SIZE)])#计算级比LAMBDA
if np.all(LAMBDA<X[1]) and np.all(LAMBDA>X[0]):
print('->>[数据检验]通过级比检验')
else :
print('->>[数据检验]不通过级比检验,需要对数据进行调整')
# 开始建模
CUMSUM = np.cumsum(data)#AGO 累计生成数据
ZVALUE = np.array([ALPHA*CUMSUM[i] + (1-ALPHA)*CUMSUM[i-1] for i in range(1,DATA_SIZE)])#生成Z(k),白化背景值
#GM(1,1)模型 :Y = Bu 需要计算u
RESHAPE_ZVALUE = -ZVALUE.reshape(DATA_SIZE-1,1)
RESHAPE_ONES = np.ones_like(RESHAPE_ZVALUE)
B = np.hstack((RESHAPE_ZVALUE,RESHAPE_ONES))#拼接构造数据B
Y = data[1:].reshape(DATA_SIZE-1,1)#从X2开始的数据(x1,x2,x3,x4...)
#最小二乘法估计参数u(使用最小二乘法计算)
U_ = np.linalg.inv(np.dot(B.T,B))#(BT.B)-1
U_1 = np.dot(U_,B.T)#点乘BT
U = np.dot(U_1,Y)#计算参数U
print(f"->>[求解参数]{U.ravel()}")
# 计算预测值
a = U[0];b = U[1]
#预测x1,X2,X3,X4... 修改DATA_SIZE参数即可获得预测数据PREDICT_DATA
PREDICT_VALUE_ = [(data[0]-b/a)*np.exp(-a*k) + b/a for k in range(0,DATA_SIZE)]
Values = [0]
for value in PREDICT_VALUE_:
Values.append(value[0])
PREDICT_VALUE = np.array([Values[j]-Values[j-1] for j in range(1,DATA_SIZE+1)])#预测数据(还原)
# 模型检验
####残差检验:需要计算相对残差(也可以计算绝对误差)
# ∣ ε ( k ) ∣ < 0.1则认为到达较高的要求。如果对所有的 ∣ ε ( k ) ∣ < 0.1 达到较高要求
REDIS_ = (data-PREDICT_VALUE)/data#相对残差
if np.all(REDIS_<0.2):print('->>[模型检验]达到一般要求')
if np.all(REDIS_<0.1):print('->>[模型检验]达到较高要求')
###级比偏差值检验:没找到
###后验残差检验
STD_DATA = data.std(ddof=1)#S1原始数列的标准差
REDIS = PREDICT_VALUE-data#残差
STD_REDIS = REDIS.std(ddof=1)#S2残差的标准差
C = STD_REDIS/STD_DATA#方差比
print(f"->>[方差比]{C}")
##残差概率检验
R = (REDIS-data.mean())<0.6745*STD_DATA
P = R[R==True].shape[0]/R.shape[0]
print(f"-->>[残差概率]{P}")
###绘图
year = np.arange(DATA_SIZE)#年份
plt.plot(year,data,label='实际值')
plt.scatter(year,data,marker='^',edgecolors='black')
plt.plot(year,PREDICT_VALUE,label='预测值')
plt.scatter(year,PREDICT_VALUE,marker='s',edgecolors='black')
plt.legend()
plt.show()
years = 4#向后预测四年的数据
PREDICT_VALUE_ = [(data[0]-b/a)*np.exp(-a*k) + b/a for k in range(0,DATA_SIZE+years)]
Values = [0]
for value in PREDICT_VALUE_:
Values.append(value[0])
PREDICT_VALUE = [Values[j]-Values[j-1] for j in range(1,DATA_SIZE+1+years)]#预测数据(还原)
print("-->>[预测数据]",PREDICT_VALUE)
year = np.arange(DATA_SIZE+years)#年份
plt.plot(year,PREDICT_VALUE,label='预测值')
plt.scatter(year,PREDICT_VALUE,marker='s',edgecolors='black')
plt.legend()
plt.show()


















 3340
3340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









