







目录
1.模型介绍
1.1 模型内容
一般地,将数据分为三种颜色系统,对应的解释如下图。

灰色模型的定义为:对灰色系统建立的模型称为灰色模型。灰色模型就是通过少量的、不完全的信息,建立灰色微分预测模型,对事物发展规律作出模糊性的长期描述。灰色预测模型又称GM模型,揭示了系统内部事物连续发展变化的过程。
在所有的灰色预测模型中,灰色预测模型GM(1.1)是目前影响最大、应用最为广泛的形式。灰色预测模型的特点是:模型使用的是不是原始序列,而是处理过的累加序列。
1.2 模型评价
灰色模型的优点:
1. 模型所需数据较少(一般不超过20个),降了数据搜集的难度;
2. 模型使用微分方程来挖掘信息,整体的预测精度较高。
灰色模型的缺点:
1. 模型需要对原始数据进行级比检验,对数据具有一定的要求,适用性偏低;
2. 模型只适合短期的预测,预测周期有限。
2. 代码复现
2.1 源代码
公式的推导此处省略,直接展示代码以及对应的应用。模型的复现代码如下。
import numpy as np
class GM11(object):
def __init__(self, data, N):
'''
data:原始数据
N: 预测未来N期的数据
'''
self.data = np.array(data)
self.lens = len(data)
self.N = N
def Stage_ratio(self):
# 计算级比,并判断数据是否可以建模
rate = [self.data[i - 1] / self.data[i] for i in range(1, self.lens)]
rate_min = np.exp(-2 / (self.lens + 1))
rate_max = np.exp(2 / (self.lens + 1))
if np.max(rate) < rate_max and np.min(rate) > rate_min:
print('级比检验通过!可以进行建模!')
res = 'true'
else:
print('级比检验失败,不可进行建模!')
res = 'false'
return res
def Coefficient(self):
# 构建微分方程,并求解a,b的值
# 构造累加序列
sum_list = self.data.cumsum()
# 构造紧邻均值序列
mean_list = [(sum_list[i - 1] + sum_list[i]) / 2 for i in range(1, self.lens)]
# 建立微分方程
Y = np.array(self.data[1:]).reshape(self.lens - 1, 1)
B = np.array(mean_list)
one = np.ones(len(mean_list))
B1 = np.array([-B, one]).T
# 求解方程,a为发展系数,b为灰色作用量
a, b = np.dot(np.dot(np.linalg.inv(np.dot(B1.T, B1)), B1.T), Y)
return a[0], b[0]
def Fit(self, k):
# 进行拟合,同时也可以预测第K个数对应的数值
a, b = self.Coefficient()
c = b / a
value = (self.data[0] - c) * (np.exp(-a * (k - 1))) + c
next_value = (self.data[0] - c) * (np.exp(-a * k)) + c
predict_value = next_value - value
return predict_value
def Residual_test(self):
# 检验后验差比
# 原始序列残差
var_value = np.array(self.data).var()
# 预测数值与原始序列的残差
residual_list = []
for x in range(1, self.lens):
p = self.Fit(x + 1)
residual = p - self.data[x]
residual_list.append(residual)
residual_var = np.array(residual_list).var()
C = residual_var / var_value
if C <= 0.35:
print(C, '模型预测精度等级:好')
elif 0.35 < C <= 0.5:
print(C, '模型预测精度等级:合格')
elif 0.5 < C <= 0.65:
print(C, '模型预测精度等级:勉强')
else:
print(C, '模型预测精度等级:不合格')
return C
def Precidt(self, dy=None):
# 输出预测的数据,包含原始序列内以及原始序列以外的预测
pre_list = []
for x in range(1, self.lens + self.N ):
pre = self.Fit(x)
pre_list.append(pre)
if dy == None:
# 默认输出所有预测数据
out_list = pre_list
elif dy == 'pre':
# 输出序列以外的所有预测数据
out_list = pre_list[self.lens-1:]
elif dy == 'last':
# 输出第N期的预测数据
out_list = pre_list[-1]
return out_list2.2 检验
分别对数据和模型进行相应的检验,对应的代码为:
if __name__ == '__main__':
# 原始数据及预测周期
data = [101.1, 102.4, 102.8, 102.1, 101.4]
N = 5
# 调用模型
model = GM11(data, N)
# 级比检验,若不通过,则建模无效
stage_ratio = model.Stage_ratio()
# 后验差比检验,主要是评价模型的预测效果
posterior_test = model.Residual_test()
对应得到的检测结果是:

可以看出,检测通过可以进行后续预测。需要注意的是,如果级比检验未通过,则需要对数据进行转换,笔者尝试过一些转换方法,但是最终效果的都不太理想。因此,当遇到级比检验不通过时,更建议更换模型,因为转换数据通过级别检验的概率比较低,有兴趣者可以对数据的转换做进一步深入,此处选择忽略。
2.3 预测
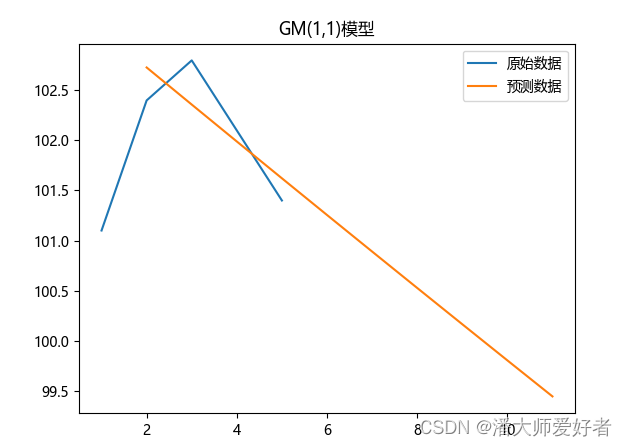
上一步数据检验通过,对数据进行预测,并将结果可视化。
# 进行预测
predict = model.Precidt('pre') # 于是数据外预测数据
predict1 = model.Precidt() # 所有预测数据
# 可视化
import matplotlib.pyplot as plt
zt = plt.figure()
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
x = [x for x in range(1, len(data) + 1)]
x1 = [x for x in range(2, len(data) + N + 1)]
plt.title('GM(1,1)模型')
plt.plot(x, data, label='原始数据')
plt.plot(x1, predict1, label='预测数据')
plt.legend(loc='best')
plt.show()对应的可视化结果为:
前期有些分享写的太细,相对比较耗时且显得啰嗦。为了提高效率和进度,后期的文章更多是类似自我的笔记,会精简内容。本期分享到此结束,有何问题欢迎交流。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









