









文章目录
省流版
json分割
主要使用json.loads、json.dump。
import json
# 把path文件分割成num个,并存入path2中
# path: 文件路径 path2 : 目标路径 num: 结果的数量
def jsonSplit(path, path2, num):
count = 0
for count, line in enumerate(open(path, 'rU', encoding='utf-8')):
pass
count += 1
nums = [(count * i // num) for i in range(1, num + 1)]
current_lines = 0
data_list = []
# 打开大文件,拆成小文件
with open(path, 'r', encoding='utf-8') as file:
i = 0
for line in file:
# line = line.replace('},','}')
data_list.append(json.loads(line))
current_lines += 1
if current_lines in nums:
# print(current_lines)
# 保存文件
file_name = path2 + str(current_lines) + '.json'
with open(file_name, 'w', encoding='utf-8') as f:
# print(len(data_list))
data = json.dumps(data_list)
f.write(data)
data_list = []
data = []
json.gz 转换成 jsonl.gz
主要使用gzip、jsonlines。
import os
import gzip
import jsonlines
import json
# 把path对应的json.gz文件,转化成jsonlines文件,再压缩成jsonl.gz文件
# path:数据集的路径 path2:结果路径
def jsonTojsonlGZ(path, path2):
with gzip.open(path, 'rt') as pf:
# 加载json
data = pf.read()
all_data = json.loads(data)
# 打开jsonl并写入
filename = path2 + '.jsonl'
with jsonlines.open(filename, mode='a') as writer:
for item in all_data:
writer.write(item)
# 打开jsonl.gz并写入jsonl文件的内容
f_gzip = gzip.GzipFile(filename + '.gz', "wb")
with open(filename, 'rb') as f_in:
f_gzip.write(f_in.read())
# 删除jsonl文件
os.remove(filename)
json格式化显示
import json
dic = {'a': 1, 'b': 2, 'c': 3}
js = json.dumps(dic)
print(js)
遍历目录及子目录,对某种类型的文件内容查找是否有指定字符串
# coding:utf-8
import re
import os
import gzip
import sys
file_behind=sys.argv[1]
dirname=sys.argv[2]
tofind=sys.argv[3]
def searchInDir(dirname):
for root,dirs,files in os.walk(dirname):
for dir in dirs:
searchInDir(dir)
for filename in files:
if(os.path.splitext(filename)[1]!=file_behind):
continue
file=os.path.join(root,filename)
if(file_behind==".gz"):
with gzip.open(file,"rt",encoding='utf-8') as f:
content = f.read()
print(file, re.findall(tofind,content))
else:
with open(file,"rt",encoding='utf-8') as f:
content = f.read()
print(file, re.findall(tofind,content))
searchInDir(dirname)
效果:
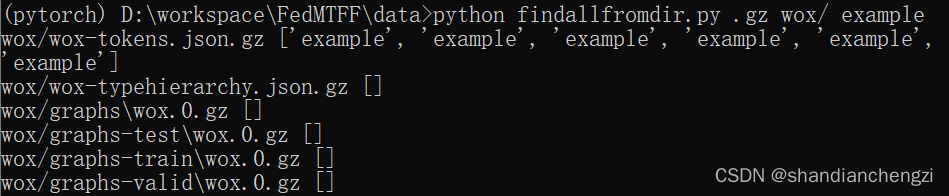
详细解释版
JSON分割
JSON分割主要使用json.loads和json.dump。下面是一个将大JSON文件分割成多个小文件的Python函数。
import json
def json_split(path, path2, num):
"""
将大JSON文件分割成num个小文件,并保存到path2目录下。
参数:
path (str): 大JSON文件的路径
path2 (str): 目标路径
num (int): 结果文件的数量
"""
data_list = []
with open(path, 'r', encoding='utf-8') as file:
for line in file:
data_list.append(json.loads(line))
if len(data_list) == num:
# 保存文件
file_name = f"{path2}/part_{len(data_list) - num}.json"
with open(file_name, 'w', encoding='utf-8') as f:
data = json.dumps(data_list, ensure_ascii=False)
f.write(data)
data_list = []
# 处理剩余数据
if data_list:
file_name = f"{path2}/part_last.json"
with open(file_name, 'w', encoding='utf-8') as f:
data = json.dumps(data_list, ensure_ascii=False)
f.write(data)
JSON.GZ转换成JSONL.GZ
JSON.GZ转换成JSONL.GZ主要使用gzip和jsonlines库。下面是一个转换函数的实现。
import gzip
import jsonlines
import os
def json_gz_to_jsonl_gz(path, path2):
"""
将JSON.GZ文件转换成JSONL.GZ文件。
参数:
path (str): JSON.GZ文件的路径
path2 (str): 目标JSONL.GZ文件的路径
"""
with gzip.open(path, 'rt', encoding='utf-8') as f_in:
data = json.load(f_in)
with gzip.open(path2, 'wt', encoding='utf-8') as f_out:
writer = jsonlines.Writer(f_out)
for item in data:
writer.write(item)
JSON格式化显示
JSON格式化显示可以直接使用json.dumps方法,并设置indent参数。
import json
dic = {'a': 1, 'b': 2, 'c': 3}
formatted_json = json.dumps(dic, indent=4, ensure_ascii=False)
print(formatted_json)
遍历目录及子目录,对某种类型的文件内容查找是否有指定字符串
这个函数遍历指定目录及其子目录,查找某种类型的文件中是否包含指定字符串。
import re
import os
import gzip
import sys
def search_in_dir(dirname, file_extension, search_string):
"""
遍历目录及其子目录,查找某种类型的文件中是否包含指定字符串。
参数:
dirname (str): 目录路径
file_extension (str): 文件扩展名,如'.txt'或'.gz'
search_string (str): 要查找的字符串
"""
for root, dirs, files in os.walk(dirname):
for file in files:
if file.endswith(file_extension):
file_path = os.path.join(root, file)
if file_extension == '.gz':
with gzip.open(file_path, 'rt', encoding='utf-8') as f:
content = f.read()
matches = re.findall(search_string, content)
if matches:
print(f"File: {file_path}, Matches: {matches}")
else:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
matches = re.findall(search_string, content)
if matches:
print(f"File: {file_path}, Matches: {matches}")
if __name__ == '__main__':
file_behind = sys.argv[1]
dirname = sys.argv[2]
to
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/123771666。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。


















 5477
5477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











