







对于HDD硬盘来说,都会将盘片划分成一个个大小都是512字节的扇区。
但是对于SSD固态硬盘来说,不存在真正的扇区。就没有扇区的定义。它是由4KB的page组成的。
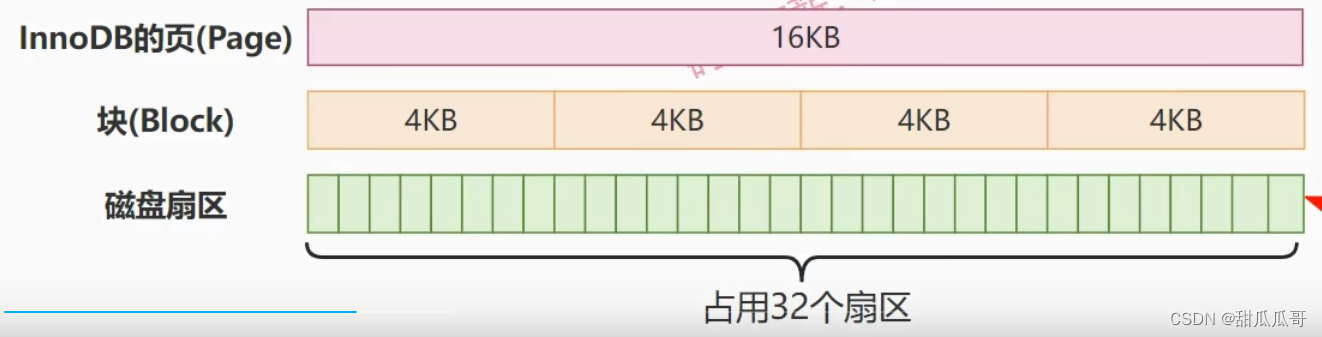
对于HDD硬盘,如果我们现在有这样一张MySQL表,一共有32条数据,假设每条记录占用的存储空间是512字节。那么他就会占用32个扇区来存储这些数据。试想一下,如果我们现在要查找的目标数据的ID=32,如果现在也没有建立索引,就一定会发生全表扫描。
那么一定需要32次IO才能找到目标数据吗?
其实并不是这样的。因为操作系统都有连续读和缓冲数据的原理。
在计算机领域中,当一个数据被用到时,通常他附近的数据也会被用到。因此磁盘在每次发生读操作的时候,都会在找到目标数据之后,都会去连续读取4KB的数据。比如说磁盘随着磁头的转动,再连续读取4KB的数据。

这样的话,在文件系统中就把一个块的大小定义成了4KB,相当于每次IO操作,他会加载8个扇区的数据到内存中。
因此,我们可以看见,在文件系统中,即使这个文件只存储了一个字节的数据,但是他占用的物理数据仍然是4KB。
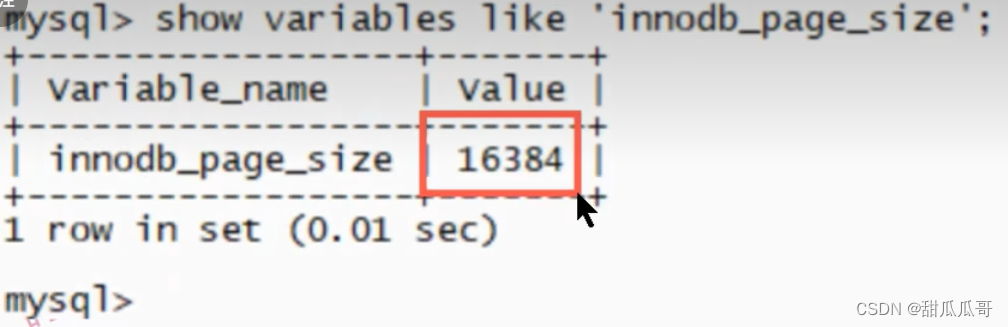
而MySQL又觉得4KB太小了,在MySQL中最小的存储单元是页。·一个页占用的存储空间是16KB。这个是默认值,我们是可以修改的。相当于每次IO操作,都可以缓存16KB的数据。它是以16KB作为一个存储单元,最小缓存16KB。然后会把这个16KB的数据放到BufferPool中。在BufferPool中,每个ByteBuffer的大小恰好是16KB。而ByteBuffer的空间释放也不需要等待JVM的GC操作。因此就不会发生stop the world。这个效率就非常高了。
因此对于这个32行的表,即使我们不创建索引,也未必会感受到慢。
这就是顺序读和BufferPool给我们带来的便利。
但是当数据量达到几十、几百万甚至上千万的时候,我们就不得不创建索引了。
在MySQL中,所有的数据都是存储在page中的,由page去管理这些数据。因此,即使是这样非常小的一张表,这个school表占用的存储空间是96KB,它是16KB的6倍。
因为在MySQL中,统计数据的占用空间是根据page来计算的。一个page的大小是16KB, 如果一行MySQL的记录是512字节,那么一个page最多可以存储32条数据。
因此,我们可以假设这样一个场景,在我们这个假设的场景中:
- 如果使用的是SSD硬盘。那么每一次加载数据就相当于对于HDD硬盘来说,可能要发生32次顺序读。就是这种即使是顺序读,才能把这个32数据加载到内存。
- 但是对于SSD硬盘来说,因为它的块是4KB,相当于它读取的速度会更快。SSD磁盘造价也是比较高的。这也就是说为什么HDD硬盘的应用范围更广。
如果数据都是杂乱无章地存储在这些page中,那么查找数据就变成了大问题了。因为我们不知道这个数据究竟是放到哪个page中。
我们也不可能把所有的page都遍历一遍,因此这个时候,我们就联想了B+树索引。我们可以给ID这一列数据创建索引。但是这个索引,他也是要占用物理存储空间的。

假设ID的数据类型是bigint。bigint占用8字节的存储空间,而在InnoDB中,索引指针占用的存储空间是6个字节。一行索引,占用的空间就是8+6=14个字节。所以一个page可以存储1170条索引。
这是一个什么概念呢?
就相当于我们可以建立一个1170阶的一级索引,1170阶的索引就是指一个page,可以指向1170个叶子节点。
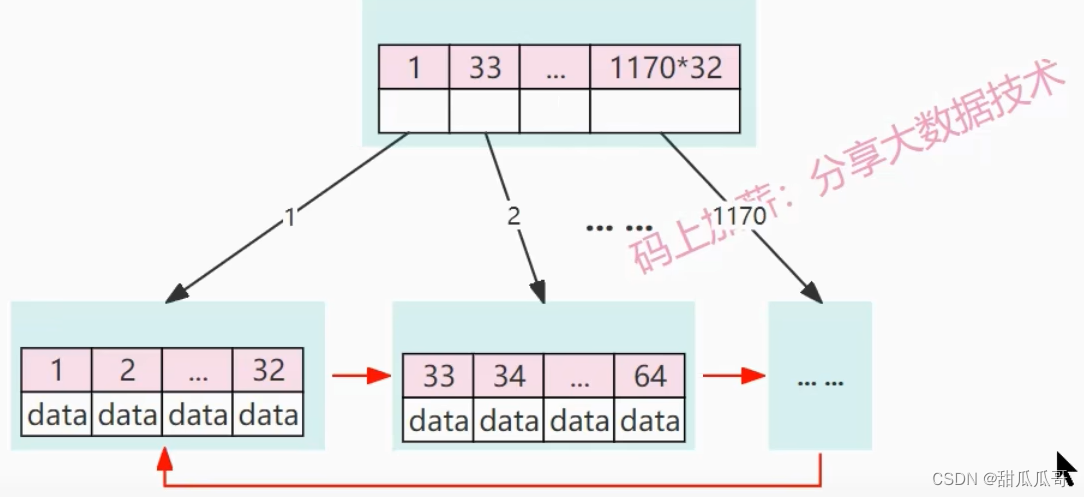
我们就可以构建成这样的一个B+树。本来B+树的叶子节点,它是一个单向的链表。
但是MySQL就把它优化成了双向链表。
如果每个叶子节点可以存储32行数据。那么一级索引就可以索引到1170*32=37440条数据。
而现在的树高仅仅是2,可见这个B+树是一颗矮树,树的高度越矮,那么查找效率就越高。
比如我们现在要查找目标元素ID=34,找这条数据,那么在第一次发生IO磁盘操作的时候,它首先要访问根节点。
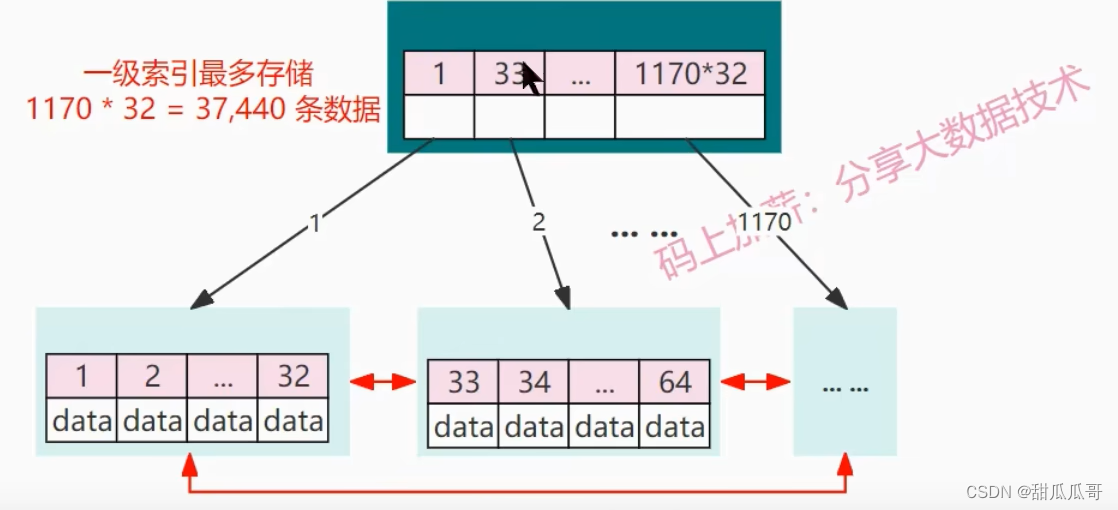
把根结点,也就是这个一级索引加载到内存中,也就是加载到BufferPool中。因为34是在33和64之间,因此就会在内存中顺序查找。找到根结点,然后访问根结点指向的叶子结点。
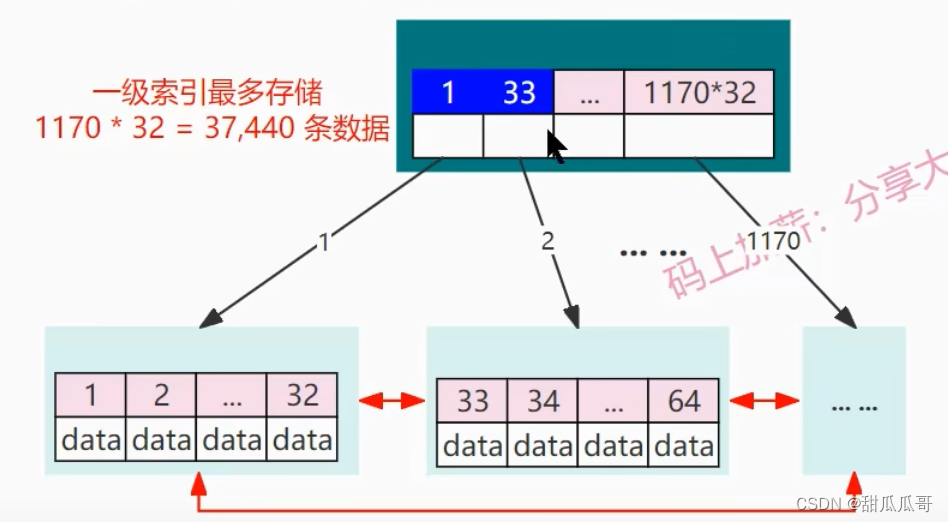
现在发生第二次IO操作,将这叶子节点的数据内容全部加载到内存中。然后顺序遍历叶子节点的数据。一直找到ID=34这条数据为止,可见现在仅仅发生了两次磁盘的IO操作,就找到了我们想要的目标数据。可见,这个查找效率还是非常高的。这个都是发生的内存的顺序查找。
想象一下,如果我们的数据不仅仅只有37000条,可能远远大于37000条,这个时候我们就会联想到可以创建二级索引。
二级索引的每个索引内容存储的都是索引值,因此它也可以最多存储1170个索引去指向1170个子节点。所以可以存储共4300万条数据,相当于到了4000万级别的数据量,而每个二级索引它又可以指向1170个一级索引,而每个一级索引又可以指向1170个叶子节点,这样我们就把一个B+树构建完了。
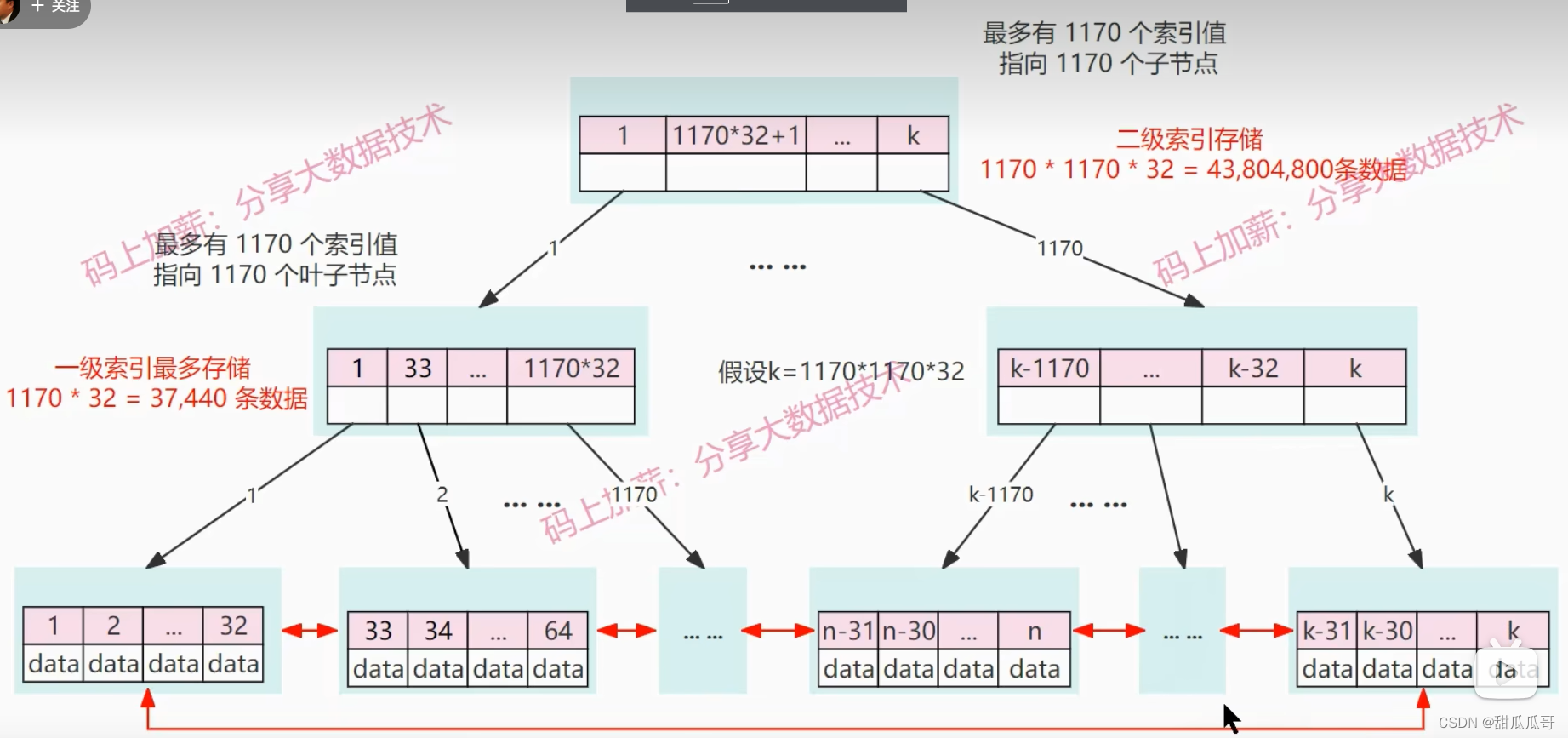
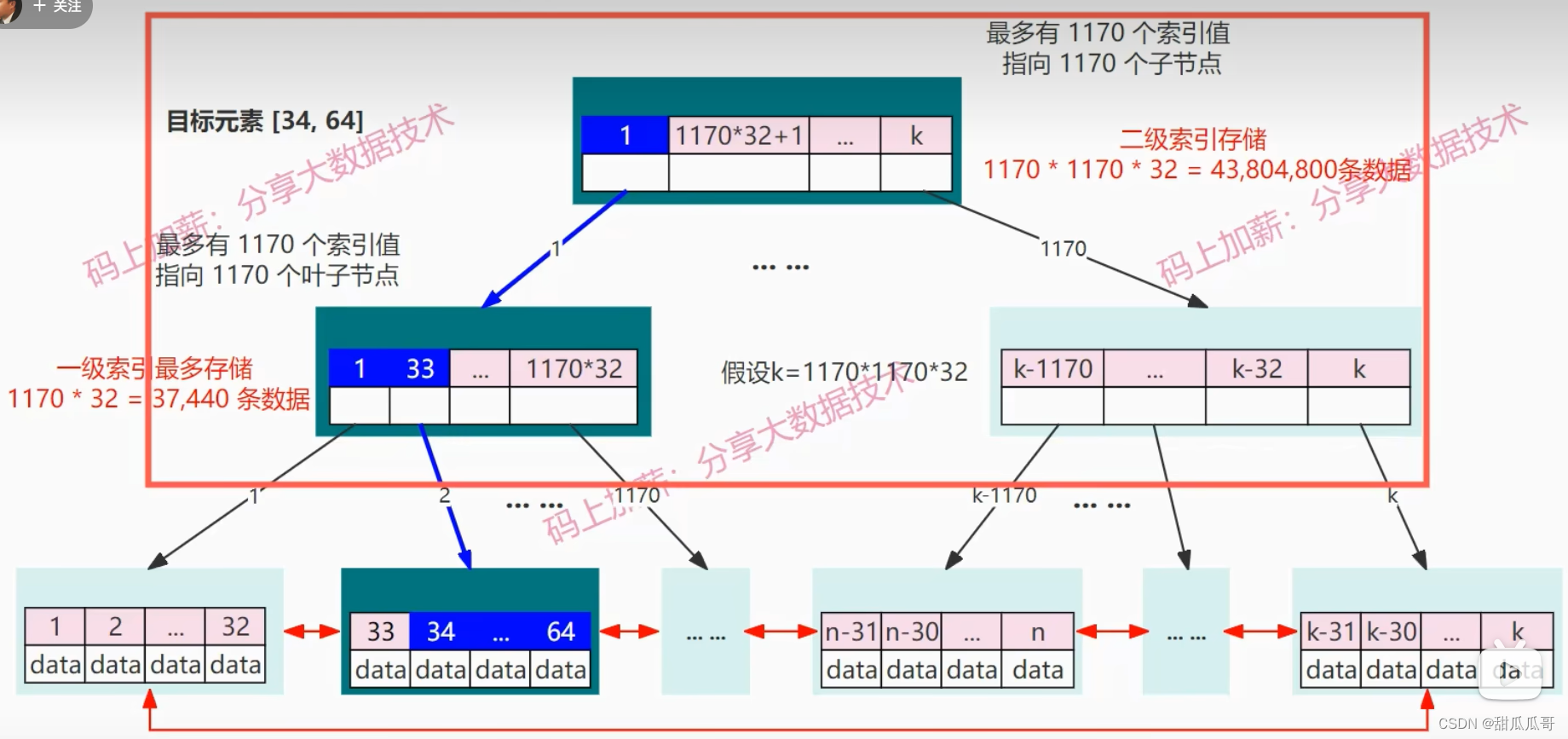
这时树的高度是3,如果我们现在要做一个范围查找,想查找ID在34到64之间的数据:
- 首先是将根节点加载到内存中,然后找到34所属的根节点1,找到根节点1指向的一级索引。将一级索引的内容加入到内存中。
- 这时发生了第二次IO操作。在一级索引中,顺序查找34所属的索引33,然后把33指向的叶子节点再次加载到内存中。
- 然后在内存中进行顺序查找。当找到目标节点是34的时候,然后开始顺序向后遍历,一直遍历到64为止。
如果我们现在把查找的范围扩大一些,比如说在66,最大值是66,那么它就通过指针再去找一下page的内容。然后去顺序读,可见,即使在这种千万级别的MySQL表中,如果想要查找某条数据或者用范围查找所花费的IO,也仅仅就是3次,就可以做到。
B+树所有的索引查询发生的IO次数都是树的高度,这就是B+树给我们带来的便利。B+树仅仅在叶子节点上存储数据。非叶子节点存储的都是索引的信息。
因此非叶子节点占用的空间也不大,但是这也毕竟是占用空间,因此B+树也是一种“用空间换时间”的做法。
“用空间换时间”的做法在计算机领域是非常普遍的。比如我们前面给大家讲解的跳跃表的原理。
















 4847
4847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









