随机模块 random
方法:
. random ( ) 随机产生 0 - 1 之间的小数
. randint ( 1 , 6 ) 随机产生 1 - 6 之间的整数
. uniform ( 1 , 6 ) 随机产生 1 - 6 这几件的小数
. choice ( [ 元素 1 , 元素 2 ··· ] ) 随机抽取一个元素
. sample ( [ 元素 1 , 元素 2 ··· ] , num ) 抽取指定样本 num为几抽取几个数
. shuffle ( [ 元素 1 , 元素 2 ··· ] ) 随机打乱容器元素的排序
import random
for i in range ( 5 ) :
num = chr ( random. randint( 48 , 57 ) )
upper = chr ( random. randint( 65 , 90 ) )
lower = chr ( random. randint( 97 , 122 ) )
list1 = [ num, upper, lower]
print ( random. choice( list1) , end= '' )
系统操作 os模块
方法:
. mkdir ( '目录名' ) 创建单级别目录 不能xx / xxx 在当前程序运行目录下创建
. makedirs ( '目录名/目录名' ) 创建多级目录 可以xx / xxx
. rmdir ( '目录名' ) 删除目录 只能删空目录
. removedirs ( '目录名/目录名' ) 移除多级目录 只能删空目录
. listdir ( '路径' ) 列出当前目录下的文件 / 文件名
. remove ( '文件路径' ) 移除一个文件
. rename ( '老文件名' , '新文件名' ) 重命名
. getcwd ( ) 查看当前路径
. chdir ( '路径' ) 切换路径
import os
os. mkdir( 'aa' )
os. makedirs( r'aa\bb\ccc' )
os. rmdir( r'aa' )
os. rmdir( r'aa\bb\ccc' )
os. removedirs( 'aa/bb' )
print ( os. listdir( ) )
os. remove( 'a.txt' )
os. rename( 'aa' , 'bb' )
print ( os. getcwd( ) )
os. chdir( r'F:\backups\notes\Project\test\bb' )
print ( os. getcwd( ) )
. path下方法
. join ( '路径' , '路径' ) 路径拼接
能自动识别当前系统的路径分隔符,linux / windows \ '/也能用'
. exists ( '路径' ) 判断路径是否存在
. isfile ( '路径' ) 判断路径是否为一个文件
. isdir ( '路径' ) 判断路径是否为一个目录
. getsize ( '路径' ) 获取文件大小 字节数 字母 1 字节 中文 3 字节
path1 = os. getcwd( )
print ( os. path. join( path1, 'bb' ) )
print ( os. path. exists( r'F:\backups\notes\Project\test\bb' ) )
print ( os. path. isfile( r'F:\backups\notes\Project\test\bb' ) )
print ( os. path. isdir( r'F:\backups\notes\Project\test\bb' ) )
print ( os. path. getsize( r'F:\backups\notes\Project\test\1.py' ) )
import os
"""
创建一个文件夹
在穿件5个文件
展示文件,并绑定编号,选择编号查看文件信息。
"""
file_name = input ( '创建文件\n输入文件的名字>>>:' ) . strip( )
os. mkdir( file_name)
PATH_DIR = os. getcwd( )
for i in [ 'a' , 'b' , 'c' , 'd' , 'e' ] :
file_path = os. path. join( PATH_DIR, file_name, '%s.txt' % i)
with open ( file_path, mode= 'w' , encoding= 'utf8' ) as f:
f. write( '%s 的文件内容' % i)
file_path = os. path. join( PATH_DIR, file_name)
os. chdir( file_path)
all_file = os. listdir( )
for x, y in enumerate ( all_file) :
print ( x+ 1 , y)
while True :
choice = input ( '选择文件观看>>>:' ) . strip( )
if choice. isdigit( ) :
choice = int ( choice) - 1
if choice in range ( len ( all_file) ) :
read_file_name = all_file[ choice]
file_path = os. path. join( PATH_DIR, file_name, read_file_name)
with open ( file_path, mode= 'r' , encoding= 'utf8' ) as f:
print ( f. read( ) )
else :
print ( '选项不存在!' )
else :
print ( '输入不合法!' )
解释器操作 sys模块
. path python导入文件或者模块查找的路径
sys . path python的搜索模块的路径集,是一个list .
第一个目录就是运行的py文件所在的目录
. version 解释器版本
. platform 返回系统标识
window -- > ’win32‘
linux -- > ’linux‘
Mac OS -- > ‘darwin’
Windows / Cygwin-- > ‘cygwin’
. argv 获取当前执行文件的绝对路径
import sys
print ( sys. argv)
print ( sys. version)
print ( sys. platform)
print ( sys. argv)
print ( sys. argv[ 0 ] )
sys . argv = = sys . argv [ 0 ]
从 1 开始就是一个列表
sys . argv = = sys . argv [ 1 ] 从一开始都是如果有值这会获取输入的第一个字符组 以 空格分割
sys . argv = = sys . argv [ 2 ] 获取第二个值
模拟mysql 的登入
在交互环境下使用
python3 D : \ 13600 \ Desktop \ test . py kid 123
import sys
try :
username = sys. argv[ 1 ]
password = sys. argv[ 2 ]
if username == 'kid' and password == '123' :
print ( '正常执行文件内容' )
else :
print ( '用户名或密码错误' )
except Exception:
print ( '请输入用户名和密码' )
print ( '(游客模式)' )
subprocess模块远程操作工具
方法
. Popen ( 'dos命令' , 给参数赋值 )
结果是bytes类型数据,基于网络传输远程控制,需要对数据进制传输。
在中国的 windows系统 电脑内部编码是 gbk编码 文件是utf- 8 但是系统内部又不一样。
ps :
tasklist 查看进程 正在执行的程序
net stop 服务名称 管理器权限执行 -- > 停止xxx服务
C: \Users\13600 > tasklist
映像名称 PID 会话名 会话
System Idle Process 0 Services 0 8 K
System 4 Services 0 148 K
Registry 148 Services 0 27 , 128 K
···
import subprocess
res = subprocess. Popen( 'tasklist' ,
stdout= subprocess. PIPE,
stderr= subprocess. PIPE
)
"""
stdout: Optional[_FILE] = ...,
stderr: Optional[_FILE] = ...,
"""
data = res. stdout. read( )
print ( data. decode( 'gbk' ) )
"""
映像名称 PID 会话名 会话# 内存使用
========================= ======== ================ =========== ============
System Idle Process 0 Services 0 8 K
System 4 Services 0 148 K
"""
Python内置time模块。
. time ( ) 获取时间戳
. sleep ( num ) 阻塞num秒
. strftime ( ) 格式化时间
参数 % Y % m % d % H % M % S 年月日 时分秒 ( % X )
. localtime ( ) 获取结构化时间
import time
print ( time. time( ) )
time. sleep( 3 )
print ( time. strftime( '%Y:%m:%d %H-%M-%S' ) )
print ( time. strftime( '%Y:%m:%d %X' ) )
time. struct_time
(
tm_year= 2021 , 年
tm_mon= 11 , 小时 '东0区时间'
tm_mday= 25 , 天
tm_hour= 20 , 小时 '东8区时间 中国'
tm_min= 34 , 分
tm_sec= 21 , 秒
tm_wday= 3 , 星期几,从0 开始
tm_yday= 329 , 今年的第几天
tm_isdst= 0 夏令时
)
Python内置datetime模块。
. date . today ( ) 年月日
. datetime . today ( ) 是分秒
import datetime
print ( datetime. date. today( ) )
print ( datetime. datetime. today( ) )
res = datetime. datetime. today( )
print ( res. date( ) )
print ( res. today( ) )
print ( res. time( ) )
print ( res. weekday( ) )
print ( res. isoweekday( ) )
timedelta对象 可以设置时间参数
days : float = . . . ,
seconds : float = . . . ,
microseconds : float = . . . ,
milliseconds : float = . . . ,
minutes : float = . . . ,
hours : float = . . . ,
weeks : float = . . . ,
import datetime
old_time = datetime. datetime. today( )
set_time = datetime. timedelta( days= 3 )
print ( old_time + set_time)
日期对象 = 日期对象 + / - timedelta对象
timedelta对象 = 日期对象 + / - 日期对象
import datetime
old_time = datetime. datetime. today( )
set_time = datetime. timedelta( days= 3 )
next_time = old_time + set_time
print ( next_time - old_time)
print ( next_time - old_time)
datetime . date ( 2000 , 11 , 11 ) 设置一个时间
import datetime
birthday = datetime. date( 1997 , 3 , 26 )
new_time = datetime. date. today( )
print ( new_time - birthday)
json 模块实现不通程序语言的数据转换。
json模块在支持python 中 整型 字符串 列表 字典 元组 布尔值 None 转换为其他语言的类型。
json数据格式格式是bytes(二进制)。
ps : 网络传输的数据必须是二进制。
序列化:将其他数据类型转为json格式字符串的过程
反序列化:将json格式字符串转换为其他的数据类型的过程
方法
. dumps 序列化
. loads 反序列化
( 基于网络传递数据如果是json格式转二进制发送过来的话 , loads方法会自动解码在反序列化 )
对汉字会转换为ASCII编码形式的字符串
ensure_ascii = False 关闭后为unicode
文件操作
. dunp 序列化
. load 反序列化
import json
dic = { 'k1' : 1 }
st = json. dumps( dic)
print ( st, type ( st) )
dit = json. loads( st)
print ( dit, type ( dit) )
import json
dic2 = { 'name' : '胡歌' }
res = json. dumps( dic2)
print ( res)
res1 = json. dumps( dic2, ensure_ascii= False )
print ( res1)
import json
tuple1 = ( 1 , 2 , 3 , 4 )
res = json. dumps( tuple1)
print ( res, type ( res) )
res1 = str ( tuple1)
print ( str ( res1) , type ( res1) )
import json
dic1 = { 'k1' : 1 }
dic2 = { 'k2' : 2 }
with open ( 'a.txt' , mode= 'w' , encoding= 'utf8' ) as f:
res1 = json. dumps( dic1)
f. write( '%s\n' % res1)
res2 = json. dumps( dic2)
f. write( '%s\n' % res2)
with open ( 'a.txt' , mode= 'r' , encoding= 'utf8' ) as f:
for line in f:
res = json. loads( line)
print ( res)
对类型先转换再直接写入文件
写文件
json . dump ( 内容 , 文件句柄f )
读文件
json . load ( f )
import json
dic = { 'k1' : 1 }
with open ( 'a.txt' , mode= 'w' , encoding= 'utf8' ) as f:
json. dump( dic, f)
with open ( 'a.txt' , mode= 'r' , encoding= 'utf8' ) as f:
res = json. load( f)
print ( res)
pickle模块,它能够实现任意对象与文本之间的相互转化,仅在Python中使用。
转为二进制类型。
方法:
. dumps ( ) 序列化
. load ( ) 反序列化
import pickle
d = { 'k1' : 1 }
res = pickle. dumps( d)
print ( res)
import pickle
d = { 'k1' : 1 }
with open ( 'a.txt' , mode= 'wb' ) as f1:
pickle. dump( d, f1)
with open ( 'a.txt' , mode= 'rb' ) as f1:
res = pickle. load( f1)
print ( res)
该模块提供了一些高阶的数据类型。
nametuple 具名元组
deque 双端队列
orderedDict 有序字典
defaultdict 默认值字典
Counter 计算器
具名有名字的元组
导入:
from collcetions import namedtuple
格式:
namedtuple ( '名字' , '名字1 名字2···' )
第二个参数如果是字符串名字之间用空格隔开。
namedtuple ( '名字' , [ '名字1' , '名字2' ··· ] )
对象可以通过点的方式取值。
from collections import namedtuple
res = namedtuple( '坐标' , [ 'x' , 'y' ] )
res = res( 30 , 40 )
print ( res)
print ( res. x)
print ( res. y)
res = namedtuple( '坐标' , 'x y' )
res = res( 30 , 40 )
print ( res)
print ( res. x)
print ( res. y)
--------------------------------------
--- 4 ------ 3 ----------- 2 ------- > 1 一端进一端出
--------------------------------------
queue 队列模块
方法:
. Queue ( ) 初始化
. put ( 参数 ) 往队列添加值
. get ( ) 从队列中拿值
import queue
res = queue. Queue( )
res. put( 'one' )
res. put( 'two' )
res. put( 'three' )
print ( res. get( ) )
print ( res. get( ) )
print ( res. get( ) )
print ( res. get( ) )
"""
传入三个值,拿四个,第四次拿不到值,程序会等待传入值,
如果传入三个值,拿三个,程序就此结束。
"""
----------------------------------------
--------------------------- >
4 1 2 3 5 两端进两端出
< ---------------------------
----------------------------------------
deque 双端队列模块
. deque ( ) 初始化
. appendleft ( ) 左边追加
. popleft ( ) 左边弹出
from collections import deque
res = deque( [ 1 , 2 , 3 ] )
res. appendleft( 4 )
res. append( 5 )
print ( res. pop( ) )
print ( res. popleft( ) )
print ( res. popleft( ) )
print ( res. popleft( ) )
print ( res. popleft( ) )
print ( res. popleft( ) )
"""
多取值会报错
"""
Python2 中能明显的看出字典的是无序的,Pycharm中做过优化,输出 '看起来' 很有规律。
OrderedDict 有序字典
返回的结果可以使用字典的方法。
from collections import OrderedDict
orderly_dic = OrderedDict( [ ( 'name' , 'kid' ) , ( 'age' , 18 ) ] )
print ( orderly_dic)
访问字典的时候,如果键不存在报错。
dic = { }
print ( dic[ 'a' ] )
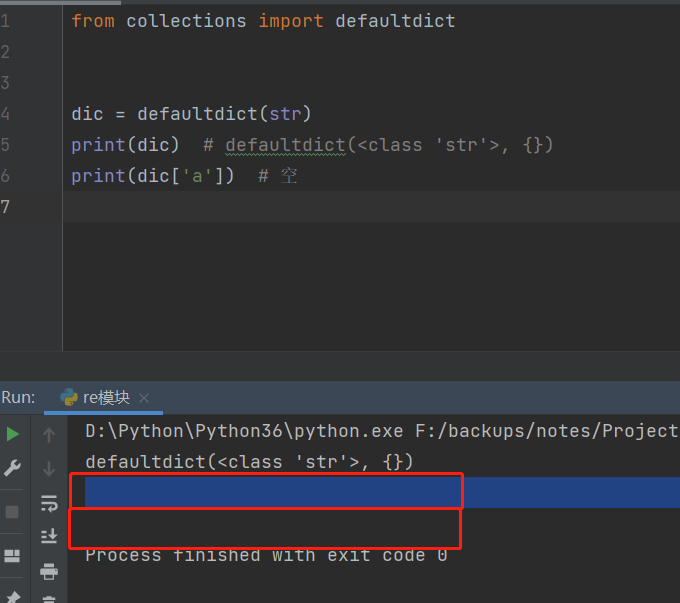
defaultdict ( 类型 ) 设置默认值当键不存在是返回默认值。
返回的结果可以使用字典的方法。
from collections import defaultdict
dic = defaultdict( int )
print ( dic)
print ( dic[ 'a' ] )
from collections import defaultdict
dic = defaultdict( str )
print ( dic)
print ( dic[ 'a' ] )
from collections import defaultdict
dic = defaultdict( list )
print ( dic)
print ( dic[ 'a' ] )
from collections import defaultdict
dic = defaultdict( dict )
print ( dic)
print ( dic[ 'a' ] )
from collections import defaultdict
ls = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]
my_dic = defaultdict( list )
for i in ls:
if i > 5 :
my_dic[ 'k2' ] . append( i)
else :
my_dic[ 'k1' ] . append( i)
print ( my_dic)
Counter 统计字符串中每个字符出现的次数。
返回的结果可以使用字典的方法。
from collections import Counter
res = 'abcdeabcdabcaba'
res = Counter( res)
print ( res)
正则表达式利用一些特殊的符号组合去字符串中筛选出符合条件的数据。
正则表达式是一门独立的语言,在Python中使用需要借助re模块。
Python内置re模块 .
ps : 字符串默认只能单个单个字符匹配。
字符组的特征是用中括号括起来。
字符组 含义 [0123456789] 简写[0-9] 匹配0 - 9之间的任意一个数字 [a-z] 匹配小写字符 a - z 之间的任意一个字母 [A-Z] 匹配小写字符 A - Z 之间的任意一个字母 [a-zA-Z0-9] 匹配所有数字与字母
[ 1 ] 1111154545 五个 1 被匹配
[ 111 ] 1111154545 五个 1 被匹配 对个 1 看成是一个 1
[ 0 - 9 ] 10 个数字被匹配
[ a-z ] asdsasdasd 10 个字符被匹配
[ ab-z ] 这样写法没什么意义 功能同上
[ a-zA-Z0- 9 ] SDAF156SA1DF65AS6DF51AS6D5sad5a6 32 个字符
特殊字符 含义 . 匹配除换行符以外的任意字符 \d 匹配数字 ^ 以什么开头的字符 $ 以什么结尾的字符 ^xxx$ 组合使用,精准查找的数据 | 逻辑或 a|b 匹配a或者b () 匹配括号内的表达式,也表示一个组 [···] 匹配字符组中的字符 [^···] 取反 匹配除了 字符组中字符 的所有字符
. . aasdadasdasfddfaaa 两个字符的组合 出现了 9 次 成对匹配
\ d 0123456789 匹配到 10 个结果
\ d \ d 0123456789 匹配到 5 个结果
^ a asasa 匹配到 1 个结果
a$ asasa 匹配到 1 个结果
^ kid$ kid 匹配到 1 个结果, 除了kid其它的都不行
1 | 2 | 3 | 4 | 5 12315131535 匹配到 11 个结果
ad
( ad ) -- > ad adasaad 匹配到 2 个结果 单个字符与前后组合 匹配
[ ad ] -- > [ a-d ] adasaad 匹配到 6 个结果
[ ^ad ] adasaad 匹配到 1 个结果
1. 表达式在没有量词修饰的情况下都是与单个字符进行匹配
2. 量词必须结合(字符组,特殊符号···)一起使用,不能单独出现。
3. 量词只能影响前面的一个表达式,eg : ab + 只能影响b。
量词默认情况下都是贪婪匹配
量词 含义 * 重复零次或者更多次 + 重复一次或者更多次 ? 重复零次或一次 {n} 重复n次 {n, } 重复n次或更多次 {n,m} 重复n到m次
a . * asaaa 匹配到 1 条结果 . 表示一个除换行符的任意字符 , * 重复多次
a . + asaaa 匹配到 1 条结果 . 表示一个除换行符的任意字符 , + 重复多次
a . ? asaaa 匹配到 3 条结果 单个字符与前后组合 匹配
a { 2 } asaaa 匹配到 1 条结果 两个字符的组合 成对匹配
a { 1 , } 匹配到 2 条结果 如果连续重复多个出现算一个,否则按单个算
a { 1 , 2 } asaaa 匹配到 3 条结果 如果连续两个重复出现算一个,否则按单个算
正则表达式中的量词默认都是 '贪婪匹配' 。
贪婪匹配会尽可能的多匹配
惰性匹配尽可能的少匹配
贪婪匹配 . *
< a > www . baidu . com < / a > < . * 将a便签全部元素匹配
惰性匹配 . * ?
< a > < / a > < . * ? > 将a标签匹配出来
^ [ 1 - 9 ] \ d { 13 , 16 } [ 0 - 9 x ] $
1 - 9 开头 一个数
\ d { 13 - 16 } 13 - 16 位数字
0 - 9 或x结尾 一个位字符数字或字符
最低 15 位字符 最高 18
^ [ 1 - 9 ] \ d { 14 } ( \ d { 2 } [ 0 - 9 x ] ) ?$
1 - 9 开头 一个数字
\ d { 14 } 14 个数字
\ d { 2 } 两个数字 [ 0 - 9 x ] 一个数字或字符 ? 出现一次 或者不出现
最低 15 位字符 最高 18
^ ( [ 1 - 9 ] \ d { 16 } [ 0 - 9 x ] | [ 1 - 9 ] \ d { 14 } ) $
[ 1 - 9 ] 1 位数字
\ d { 16 } 16 位数字
[ 0 - 9 x ] 1 个数字或 1 个字符
118 位
或
[ 1 - 9 ] 1 位数字
\ d { 14 } 14 位数字
15 位
在原生正则表达式中 \ 加上某些字符会产生特殊的含义。
使用 \ 抑制 \ 如 : 换行 \ n --- > \ \ n
一个 \ 抑制 1 个 \
Python中取消转义 , 也能使用 \ , 但是推荐使用r '\n\a\t'
\ \ n ---匹配--- > \ n
\ \ \ \ n ---匹配--- > \ \ n
. findall ( '正则表达式' , '匹配的文本' ) 方法
根据正则匹配符合条件的数据 , 将数据存入一个列表中,如果没有匹配到,则返回一个空列表。
. search ( '正则表达式' , '匹配的文本' ) 方法
根据正则匹配符合条件的数据,匹配到一个则返回,结果为一个对象,通过 . group ( ) 取值
如果无法匹配则返回None , 在group ( ) 则会报错。
. match ( '正则表达式' , '匹配的文本' ) 方法
根据正则匹配符合条件的数据,从头匹配到尾。结尾为一个对象,通过 . group ( ) 取值。
如果无法匹配则返回None , 在group ( ) 则会报错。
import re
res = re. findall( 'a' , 'abca' )
print ( res)
res = re. findall( 'z' , 'abca' )
print ( res)
res = re. search( 'a' , 'abca' )
print ( res)
print ( res. group( ) )
res = re. search( 'z' , 'abca' )
if res:
print ( res. group( ) )
"""
print(res.group()) # 直接报错
"""
res = re. match( 'a' , 'abca' )
print ( res)
print ( res. group( ) )
res = re. match( 'z' , 'abca' )
print ( res)
if res:
print ( res. group( ) )
. split ( '字符' , '匹配的文本' )
maxsplit 参数设置切的次数。
按字符切分, 左右两边有值存入列表中。
有一边没有值会被切一个空字符出来
import re
res = re. split( 'b' , 'acbac' )
print ( res)
res = re. split( 'a' , 'acbac' )
print ( res)
res = re. split( '[ab]' , 'acbac' , maxsplit= 1 )
print ( res)
res = re. split( '[ab]' , 'acbac' , maxsplit= 2 )
print ( res)
res = re. split( '[ab]' , 'acbac' )
print ( res)
"""
先按a切得 '' 'cbac'
在按b切得 '' 'c' 'ac'
在按a切得 '' 'c' '' 'c'
"""
. sub ( '正则表达式' , '替换的字符' , '匹配的文本' , 次数 )
默认替换所有,也可以写入参数控制次数。
相当于 repleace替换
. subn ( '正则表达式' , '替换的字符' , '匹配的文本' , 次数 )
返回元组,并提示替换次数。
import re
res = re. sub( 'a' , 'b' , 'abca' )
print ( res)
res = re. subn( 'a' , 'b' , 'abca' )
print ( res)
变量 = re . compile ( '正则表达式' )
多个位置需要使用同一个表达式将表达式编译成一个固定的规则。
在用的时候直接使用。
import re
res = re. compile ( '\d+' )
print ( res)
print ( res. findall( '123' ) )
print ( res. search( '123' ) )
print ( res. match( '123' ) )
. findall ( '正则表达式' , '匹配的文本' ) 方法
根据正则匹配符合条件的数据 , 数据的格式为迭代器对象存对象的形式。
import re
res = re. finditer( '\d+' , '1' )
print ( res)
print ( res. __next__( ) )
res = re. finditer( '\d+' , '123456789' )
res = [ i. group( ) for i in res]
print ( res)
import re
res = re. search( '^[1-9](\d{1})(\d{2}[0-9x])?$' , '12345' )
if res:
print ( res. group( ) )
print ( res. group( 0 ) )
print ( res. group( 1 ) )
print ( res. group( 2 ) )
findall 会优先显示分组的。
在括号没加上? : 取消优先展示。
import re
res = re. findall( '^[1-9](\d{1})(\d{2}[0-9x])?$' , '12345' )
if res:
print ( res)
res = re. findall( '^[1-9](?:\d{1})(\d{2}[0-9x])?$' , '12345' )
if res:
print ( res)
res = re. findall( '^[1-9](?:\d{1})(?:\d{2}[0-9x])?$' , '12345' )
if res:
print ( res)
在分组内使用?P < 名称 > 起别名。
. grounp ( '名称' ) 获取值。
import re
res = re. search( '^[1-9](?P<xx>\d{1})(?P<yy>\d{2}[0-9x])?$' , '12345' )
if res:
print ( res. group( 'xx' ) )
print ( res. group( 'yy' ) )
判断是否为手机号
1. 必须是 11 位
2. 必须是纯数字
3. 必须符合手机号的排布 15 16 18 19
phone = input ( '输入手机号>>>:' ) . strip( )
if len ( phone) == 11 :
if phone. isdigit( ) :
if int ( phone[ 0 : 2 ] ) in [ 15 , 16 , 18 , 19 ] :
print ( '输入合法!' )
else :
print ( '不是手机号' )
else :
print ( '不是纯数字' )
else :
print ( '位数不对' )
import re
in_data = input ( '输入号码>>>:' )
if re. findall( '^[15|16|18|19]\d{9}' , in_data) :
print ( '输入正确!' )
else :
print ( '输入不合法!' )
红牛分公司信息
import re
with open ( r'html.txt' , mode= 'r' , encoding= 'utf8' ) as f1:
data = f1. read( )
"""
<h2>红牛豫南分公司</h2>
<p class='mapIco'>驻马店市乐山路与通达路交叉口爱家会展国际公寓5B1105</p>
<p class='mailIco'>463000</p>
<p class='telIco'>0396-3336611</p>
"""
name_list = re. findall( '<h2>(.*?)</h2>' , data)
addr_list = re. findall( "<p class='mapIco'>(.*?)</p>" , data)
email_list = re. findall( "<p class='mailIco'>(.*?)</p>" , data)
phone_list = re. findall( "<p class='telIco'>(.*?)</p>" , data)
list1 = zip ( name_list, addr_list, email_list, phone_list)
list1 = list ( list1)
for message in list1:
print ( """
公司名称 %s
公司地址 %s
公司邮箱 %s
公司号码 %s
""" % ( message[ 0 ] , message[ 1 ] , message[ 2 ] , message[ 3 ] ) )








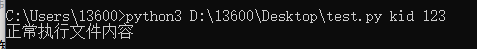

















 4477
4477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









