Django ORM中 , 每个Django模型 ( Model ) 至少有一个管理器 , 默认的管理器名称为objects .
objects是一个非常重要的管理器 ( Manager ) 实例 , 它提供了与数据库进行交互的接口 .
通过管理器 , 可以执行数据库查询 , 保存对象到数据库等操作 .
objects管理器的主要作用 :
- 创建和保存对象 : 虽然直接通过模型类也可以创建和保存对象 , 但objects管理器也提供了如create ( ) 这样的方法来一次性创建并保存对象 .
- 查询数据库 : 通过objects管理器 , 可以使用Django提供的查询集 ( QuerySet ) API来构建和执行复杂的数据库查询 .
- 删除对象 : 使用objects . delete ( ) 方法可以删除查询集中的所有对象 , 或者使用 . delete ( ) 方法在单个对象上调用以删除该对象 .
- 自定义管理器 : 虽然每个模型都有一个默认的objects管理器 , 但也可以定义自己的管理器来执行特定的数据库操作 .
通过ORM模型管理器提供的API ( objects的方法 ) , 开发者可以像操作对象一样来操作数据库中的数据 , 而不需要编写大量的SQL语句 .
修改models文件 , 创建一个User模型用于测试 :
from django. db import models
class User ( models. Model) :
name = models. CharField( max_length= 32 )
age = models. IntegerField( )
register_time = models. DateTimeField( auto_now_add= True )
DateTimeField是一个非常常用的字段类型 , 用于存储日期和时间 .
当设置auto_now_add = True时 , Django会自动在对象首次被保存到数据库时设置这个字段的值为当前的日期和时间 .
Django确实会默认使用UTC时间来存储时间戳 , 但这主要取决于Django项目的时区设置 .
Django通过在settings . py文件的TIME_ZONE设置来指定项目的时区 .
如果TIME_ZONE设置为 'UTC' , 那么auto_now_add = True将会以UTC时间来保存日期和时间 .
如果TIME_ZONE设置为其他时区 ( 例如 : 'Asia/Shanghai' ) , Django在内部仍然会使用UTC来存储时间戳 ,
但在模板渲染 , 表单处理或管理界面等地方 , Django会根据TIME_ZONE的设置自动进行时区转换 , 以便显示给用户的是他们所在时区的时间 .
执行数据迁移命令 :
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0001_initial. py
- Create model User
PS D: \MyDjango> python manage. py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying contenttypes. 0001_initial. . . OK
Applying auth. 0001_initial. . . OK
Applying admin. 0001_initial. . . OK
Applying admin. 0002_logentry_remove_auto_add. . . OK
Applying admin. 0003_logentry_add_action_flag_choices. . . OK
Applying contenttypes. 0002_remove_content_type_name. . . OK
Applying auth. 0002_alter_permission_name_max_length. . . OK
Applying auth. 0003_alter_user_email_max_length. . . OK
Applying auth. 0004_alter_user_username_opts. . . OK
Applying auth. 0005_alter_user_last_login_null. . . OK
Applying auth. 0006_require_contenttypes_0002. . . OK
Applying auth. 0007_alter_validators_add_error_messages. . . OK
Applying auth. 0008_alter_user_username_max_length. . . OK
Applying auth. 0009_alter_user_last_name_max_length. . . OK
Applying auth. 0010_alter_group_name_max_length. . . OK
Applying auth. 0011_update_proxy_permissions. . . OK
Applying auth. 0012_alter_user_first_name_max_length. . . OK
Applying index. 0001_initial. . . OK
Applying sessions. 0001_initial. . . OK
PS D: \MyDjango>
使用Navicat工具查看创建的表格 .
如果想要查看API转换的SQL语句 , 记得在settings . py配置文件中添加ORM日志 .
LOGGING = {
'version' : 1 ,
'disable_existing_loggers' : False ,
'handlers' : {
'console' : {
'level' : 'DEBUG' ,
'class' : 'logging.StreamHandler' ,
} ,
} ,
'loggers' : {
'django.db.backends' : {
'handlers' : [ 'console' ] ,
'propagate' : True ,
'level' : 'DEBUG' ,
} ,
}
}
每个Django应用 ( app ) 通常会有一个tests . py文件 , 这个文件用于存放该应用的测试代码 .
下面的代码片段主要用于在脚本或命令行环境中直接运行Django的代码 .
( 这种做法通常用于脚本或临时测试 , 而不是标准的Django测试用例 . )
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index import models
instance = models. User. objects. create( field1= 'value1' , field2= 'value2' )
print ( instance)
在Django框架中 , id和pk ( Primary Key ) 通常用于指代数据库表中的主键字段 , 但在实际使用上它们之间有着微妙的区别和联系 .
id通常是Django自动为模型 ( Model ) 添加的一个主键字段 , 除非你在模型中显式定义了其他字段作为主键 .
Django在创建模型时 , 默认会添加一个名为id的AutoField字段作为主键 , 如果没有指定其他主键字段的话 .
当查询或引用某个模型实例时 , 可以直接使用id来访问其主键值 .
pk是primary key的缩写 , 用于指代模型实例的主键 .
在Django的模型实例上 , pk是一个属性 , 它总是指向该实例的主键值 , 无论主键字段的名称是什么 .
如果模型的主键字段名为id ( 这是最常见的情况 ) , 那么pk和id在大多数情况下可以互换使用 .
但是 , 如果模型显式定义了一个不同的主键字段 ( 比如user_id ) , 那么pk仍然会指向这个主键字段的值 ,
而id则不会存在 ( 除非你同时也定义了一个名为id的字段 ) .
QuerySet对象有一个query属性 : 用于查看ORM生成的SQL语句 .
这个属性主要面向Django内部开发者和高级用户 , 了解它可以更深入地理解Django如何与数据库交互 .
注意事项 :
在使用query属性时 , 需要先调用其他操作方法 , 否则会引发异常 .
query属性仅用于调试目的 , 不应在生产环境中使用 .
假设我们有一个User模型 , 如下所示 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
sql = User. objects. all ( ) . query
print ( sql)
User . objects . all ( ) . query是一个Django查询 , 用于获取User模型的所有对象 .
这里涉及到以下几个部分 :
- User : 这是一个Django模型类 , 表示数据库中的一个表 .
- objects : 这是Django模型类的一个管理器 ( Manager ) , 用于对数据库进行操作 .
- all ( ) : 这是一个方法 , 用于获取模型类对应的表中的所有记录 .
- query : 这是一个属性 , 用于查看生成的SQL查询语句 .
create ( ) 方法是模型管理器 ( 通常是objects ) 的一个便捷方法 , 它可以一次性设置模型字段的值并保存新创建的实例到数据库中 .
create ( ) 方法会返回一个保存后的数据对象 , 这意味着可以通过 '对象.field' 访问这个实例的任何字段 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index import models
new_user = models. User. objects. create( name= 'kid' , age= 18 )
print ( new_user, type ( new_user) )
print ( new_user. id )
print ( new_user. pk)
print ( new_user. name)
print ( new_user. age)
print ( new_user. register_time)
( 0.015 )
INSERT INTO ` index_user` ( ` name` , ` age` , ` register_time` )
VALUES ( 'kid' , 18 , '2024-07-09 02:28:30.707461' ) ;
args= [ 'kid' , 18 , '2024-07-09 02:28:30.707461' ]
使用Navicat工具查看index_user表数据 .
如果需要在将数据保存到数据库之前执行一些自定义操作 ,
比如设置额外的字段值或基于其他字段的值进行计算 , 可以首先创建一个模型 ( Model ) 的实例 .
随后 , 可以对这个实例进行修改 , 以满足需求 .
最后 , 通过调用该实例的save ( ) 方法 , 将修改后的数据保存到数据库中 .
save ( ) 方法通常没有返回值 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index import models
new_user = models. User( name= 'qq' )
print ( new_user, type ( new_user) )
new_user. age = 25
res = new_user. save( )
print ( res)
( 0.015 )
INSERT INTO ` index_user` ( ` name` , ` age` , ` register_time` )
VALUES ( 'qq' , 25 , '2024-07-09 02:56:45.114005' ) ;
args= [ 'qq' , 25 , '2024-07-09 02:56:45.114005' ]
执行脚本之后 , 使用Navicat工具查看index_user表格的数据 .
对于需要批量创建大量记录的场景 , 可以使用Django的批量创建bulk_create ( ) 方法 .
调用create ( ) 时 , Django都会执行一个单独的数据库查询来插入新记录 .
而bulk_create ( ) 则将所有待插入的记录组合成一个单一的数据库查询 , 这显著减少了与数据库的交互次数 , 从而提高了效率 .
bulk_create ( ) 方法中 , 不能直接为创建的对象设置主键值 ( 自增的ID字段 ) .
这是因为bulk_create ( ) 旨在高效地批量插入数据到数据库中 ,
是通过构建一个SQL语句来一次性插入多个记录 , 而不会为每个记录单独发送SQL语句 .
如果允许用户指定主键值可能会破坏批量插入的性能优势 , 特别是当主键是自增类型时 .
bulk_create ( ) 方法返回一个包含所有新创建对象的列表 , 但这些对象通常是传入bulk_create ( ) 方法的原始对象的副本 .
这些对象不包含由数据库自动生成的id字段值 , 默认值不其他参数自动生成的值不受影响 .
如果尝试访问这些新创建对象的ID , 会遇到None .
实际应用中 , 如果不需要立即访问这些自动生成的字段值 , 那么bulk_create ( ) 是一个非常好的选择 , 因为它可以显著提高大量数据插入的性能 . 如果需要这些值 , 可能需要重新考虑的数据处理策略 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = [
User( name= "aa" , age= 19 ) ,
User( name= "bb" , age= 19 ) ,
User( name= "cc" , age= 19 ) ,
]
created_users = User. objects. bulk_create( Users)
print ( created_users, type ( created_users) )
for user in created_users:
print ( user. name, user. age, user. id )
( 0.000 )
INSERT INTO ` index_user` ( ` name` , ` age` , ` register_time` )
VALUES
( 'aa' , 19 , '2024-07-09 04:33:00.323082' ) ,
( 'bb' , 19 , '2024-07-09 04:33:00.323082' ) ,
( 'cc' , 19 , '2024-07-09 04:33:00.323082' ) ;
args= (
'aa' , 19 , '2024-07-09 04:33:00.323082' ,
'bb' , 19 , '2024-07-09 04:33:00.323082' ,
'cc' , 19 , '2024-07-09 04:33:00.323082'
)
new_user = models . User . objects . create ( name = 'qq' , . . . )
自动保存 : 此方法会立即将新创建的用户对象保存到数据库中 .
返回值 : 它返回新创建并保存到数据库中的用户对象实例 . 这个实例包含了由数据库自动生成的字段值 ( 如自增ID ) .
new_user = models . User ( name = 'qq' )
不自动保存 : 此方法仅创建一个用户对象的实例 ( 未分配ID ) , 但它不会立即将这个实例保存到数据库中 .
手动保存 : 为了将对象保存到数据库中 , 需要手动调用该实例的save ( ) 方法 .
save ( ) 方法的返回值 : 当调用save ( ) 方法时 , 它会将对象保存到数据库中 . 没有返回值 .
created_users = User . objects . bulk_create ( Users )
批量保存 : 此方法接受一个对象列表 ( 例子中Users包含多个User实例 ) , 并将它们一次性插入到数据库中 .
这是一个高效的批量插入操作 , 比单独调用每个对象的save ( ) 方法要快得多 .
返回值 : bulk_create ( ) 返回一个包含所有传入对象的列表 ( 副本 ) . 这些对象没有从数据库中检索更新后的值 ( id字段 ) .
在Django中 , 当使用models . User . objects . create ( ) 方法创建一个新的用户实例并保存到数据库中时 , 得到的是一个User对象的实例 .
这个实例代表了数据库中新创建的行 ( 或记录 ) . 当打印这个对象时 ( 如print ( new_user ) ) ,
Django默认的行为是显示这个对象的类型 ( 这里是User ) 和它的数据库ID ( 在这个例子中是 1 ) , 这就是为什么看到输出是 : User object ( 1 ) .
这个输出并不是特别有用 , 尤其是当想要查看或调试这个对象的详细信息时 .
为了更清晰地看到对象的属性 , 在Django模型中 , 可以通过定义__str__方法来指定打印对象时应该显示什么 .
__str__方法是Python中的一个特殊方法 , 用于定义对象的字符串表示形式 . 它对用户友好 , 通常用于打印输出或转换为字符串的操作 .
注意 : 修改__str__方法不需要数据迁移 , 因为它不改变数据库的结构或内容 . 它只是改变了对象在Python代码中的表示方式 .
例如 , 如果想要在打印时显示用户名 , 可以这样做 :
from django. db import models
class User ( models. Model) :
name = models. CharField( max_length= 32 )
age = models. IntegerField( )
register_time = models. DateTimeField( auto_now_add= True )
def __str__ ( self) :
return self. name
在测试的时候 , 打印用户对象则会展示其字符串的表现形式 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index import models
new_user = models. User. objects. filter ( name= 'kid' )
print ( new_user)
( 0.000 ) SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` name` = 'kid'
LIMIT 21 ; args= ( 'kid' , )
现在 , 当打印new_user时 , 它将显示 'kid' 而不是User object ( 1 ) .
也可以使用Python的字符串格式化功能来打印对象的多个属性 :
return f "User: {new_user.name}, Age: {new_user.age}"
这样更清晰地看到模型对象的详细信息 .
objects管理器提供了许多方法来执行数据库查询和相关的操作 .
这些方法使得Django ORM能够以一种非常Pythonic的方式来操作数据库 , 以下是一些常用的查询方法 :
* 1. all ( ) 或get_queryset : 返回查询集中所有的对象 . ( all ( ) 方法只干了一件事 , 那就是是调用get_queryset方法 . . . )
* 2. filter ( kwargs ) : 返回一个新的查询集 , 它包含满足给定查找参数的对象 .
* 3. exclude ( kwargs ) : 返回一个新的查询集 , 它包含不满足给定查找参数的对象 .
* 4. get ( kwargs ) : 返回与所给查找参数相匹配的对象 , 如果找到多个匹配项 , 则抛出MultipleObjectsReturned异常 ,
如果没有找到任何匹配项 , 则抛出DoesNotExist异常 .
* 5. order_by ( * fields ) : 根据提供的字段对查询集进行排序 .
* 6. reverse ( ) : 将查询集中的对象顺序反转 .
* 7. values ( * fields , expressions ) : 返回一个包含字典的查询集 , 每个字典表示一个对象 , 字典的键由指定的字段名组成 .
* 7. values_list ( * fields , flat = False ) : 与values ( ) 类似 , 但返回的是元组而不是字典 .
如果flat = True , 并且只有一个字段被指定 , 则返回的将是单个值的列表 .
* 7. distinct ( * fields ) : 返回查询集中不同 ( 去重 ) 的对象集合 .
如果指定了 * fields , 则仅在这些字段上进行去重 .
* 8. count ( ) : 返回查询集中的对象数量 .
* 9. first ( ) 和last ( ) : 分别返回查询集中的第一个和最后一个对象 .
* 10. exists ( ) : 如果查询集包含数据 , 则返回True , 否则返回False .
* 11. only ( ) 和defer ( ) 方法允许你控制从数据库中检索哪些字段 , 从而减少网络传输的数据量以及Django处理这些数据所需的资源 .
Django ORM中的QuerySet对象是一种特殊的 '不可变' 集合 , 用于表示数据库查询的结果 , 并具备一系列独特而强大的特性 .
QuerySet的特性及说明 :
* 1. 惰性执行 : 当通过Django ORM的API执行数据库查询时 , 并不会立即执行查询操作 .
相反 , 会返回一个QuerySet对象 , 该对象包含了执行查询所需的所有信息 ( 包括构建一个查询的SQL语句 ) , 但实际的数据库查询会被延迟 .
查询的执行被延迟到QuerySet被迭代 ( 如通过for循环遍历 ) , 或者调用一些触发查询的方法时 ( 如count ( ) , exists ( ) , list ( ) 等 ) .
* 2. 缓存 : Django会对每个QuerySet的查询结果进行缓存 .
这意味着 , 如果对同一个QuerySet进行多次求值 ( 例如 , 在多次迭代或调用触发查询的方法时 ) ,
Django会返回之前缓存的结果 , 而不是重新执行数据库查询 .
需要注意的是 , 缓存是针对同一个QuerySet实例的 .
如果对QuerySet进行修改 ( 如添加过滤条件或排序 ) , 则会生成一个新的QuerySet实例 , 并可能执行新的查询 .
* 3. 可迭代性 : QuerySet是可迭代的 , 这意味着可以使用Python的for循环来遍历它 , 获取其中的元素 ( 即数据库中的记录 ) .
* 4. 支持切片 : QuerySet支持Python的切片语法 , 允许限制查询结果集的大小 ( 类似于SQL中的LIMIT和OFFSET ) .
这对于分页显示数据非常有用 .
* 5. 链式调用 : QuerySet的API设计支持链式调用 , 允许通过在一系列方法调用中构建复杂的查询 .
例如 , 可以连续使用 . filter ( ) , . exclude ( ) , . order_by ( ) 等方法来逐步构建查询条件 .
all ( ) 方法 : 用于从数据库中检索模型的所有对象 . 返回一个QuerySet对象 , 该对象包含了模型表中所有记录的查询集 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. all ( )
print ( Users)
( 0.016 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
LIMIT 21 ;
args= ( )
在这个例子中 , User . objects . all ( ) 返回一个包含所有用户对象的查询集 .
然后 , 可以打印或遍历这个查询集 , 并对每个用户对象执行操作 , 比如打印用户的名字 .
Django的ORM是惰性的 , 意味着它会在需要时才真正执行数据库查询 .
这种机制是为了优化性能 , 避免不必要的数据库访问 .
QuerySet评估 ( Evaluation ) 是一个重要的概念 , 它指的是QuerySet对象与数据库进行交互 , 并实际执行查询操作的过程 .
评估触发 : 有几种情况会触发QuerySet的评估 , 包括但不限于 :
* 1. 遍历QuerySet ( 如使用for循环 ) .
* 2. 对QuerySet进行切片操作 , 并且使用了步长 ( step ) 参数 .
* 3. 对QuerySet调用len ( ) 函数 ( 注意 , 这会触发查询并将所有结果加载到内存中 , 因此在使用时应谨慎 ) .
* 4. 在布尔上下文中使用QuerySet ( 如if语句 ) , 但通常建议使用exists ( ) 方法代替 , 因为它更高效且不会触发QuerySet的完全评估 .
上例中执行 : Users = User . objects . all ( ) 时 , 这行代码本身并不直接触发数据库的查询而是返回一个查询集 ( QuerySet ) .
这个查询集是一个特殊的Python对象 , 它表示了数据库中的一个查询 , 但在这个查询实际执行并返回数据之前 , 它不会与数据库进行交互 .
当将for user in Users : 这行代码注释掉时 , 由于Users = User . objects . all ( ) 之后的代码块没有执行任何会触发查询的操作
( 比如迭代 , 切片 , 列表化等 ) , Django的ORM日志就不会显示任何数据库查询的信息 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. all ( )
使用索引来访问QuerySet中的单个对象 , 注意 : QuerySet不支持负数索引 , 否则会显示AssertionError错误 .
但这种方式并不推荐用于遍历 , 因为它可能会导致查询被多次触发 , 特别是在遍历整个QuerySet时 .
对QuerySet使用索引时 , Django ORM会将其转换为SQL查询中的LIMIT和OFFSET子句 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. all ( )
for i in range ( 5 ) :
print ( Users[ i] )
( 0.000 ) SELECT * FROM `index_user` LIMIT 1 ; args= ( )
( 0.000 ) SELECT * FROM `index_user` LIMIT 1 OFFSET 1 ; args= ( )
( 0.000 ) SELECT * FROM `index_user` LIMIT 1 OFFSET 2 ; args= ( )
( 0.000 ) SELECT * FROM `index_user` LIMIT 1 OFFSET 3 ; args= ( )
( 0.000 ) SELECT * FROM `index_user` LIMIT 1 OFFSET 4 ; args= ( )
当处理大量数据时 , 为了避免一次性将所有数据加载到内存中 , 可以使用QuerySet的iterator ( ) 方法 .
这个方法会返回一个生成器 , 允许一次只从数据库中获取一个对象 , 从而降低内存消耗 .
调用iterator ( ) 时 , Django会执行一个数据库查询来获取数据的游标 ( cursor ) ,
然后iterator ( ) 方法会逐个从这个游标中读取数据 , 直到所有数据都被遍历完毕 .
游标是数据库管理系统 ( DBMS ) 提供的一种机制 , 允许按顺序遍历查询结果集中的数据 , 而不需要一次性将整个结果集加载到内存中 .
每次获取下一个对象时 , Django会检查是否已经加载了下一个对象到内存中 .
如果没有 , 它会通过游标从数据库中检索下一个对象并将其加载到内存中 .
这个过程会一直持续到结果集中的所有对象都被遍历完毕 .
注意事项 :
- 使用iterator ( ) 后 , 将无法再次遍历相同的QuerySet , 因为它会消耗掉生成器中的元素 .
- 虽然iterator ( ) 减少了内存使用 , 但它可能会稍微降低性能 ,
因为每次迭代都需要与数据库进行交互 ( 尽管这种交互通常是通过高效的游标操作来完成的 ) .
如果查询结果集非常大 , 而又需要遍历整个结果集 , 那么使用iterator ( ) 可能会比一次性加载整个结果集到内存中需要更长的时间 .
然而 , 在内存受限的情况下 , iterator ( ) 是一个非常有用的工具 .
在Django的ORM中 , 可以像Python列表一样使用切片来限制QuerySet返回的查询结果集的大小 .
对QuerySet使用切片时 , Django ORM会将其转换为SQL查询中的LIMIT和OFFSET子句 .
例如 , MyModel . objects . all ( ) [ : 2 ] 会生成一个SQL查询 , 该查询仅返回表中的前 10 条记录 .
这里是一个使用切片来限制QuerySet返回结果的例子 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( ) [ : 2 ]
for user in queryset:
print ( user)
切片同样可以指定起始点 , 比如获取第 3 条到第 5 条记录 ( 注意Python切片是左闭右开的 ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( ) [ 2 : 6 ]
for user in queryset:
print ( user)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 4 OFFSET 2 ;
args= ( )
没有设置切片的时候 , 默认情况下LIMIT的值为 21 , 如下图所示 .
ORM日志 ( 字段简化为 * ) : SELECT * FROM ` index_user ` LIMIT 21 ;
如果QuerySet对象的数据超过了 21 条数据 , 直接打印这个它 ,
第 21 条记录会显示 "...(remaining elements truncated, 剩余元素被截断)..." .
这意味着原本应该展示更多内容的地方 , 由于某种原因 ( 如空间限制 , 性能考虑 , 用户设置等 ) , 只展示了部分内容 , 而剩余的部分被省略了 .
< QuerySet [ < User: User object ( 1 ) > , < User: User object ( 2 ) > , < User: User object ( 3 ) > , < User: User object ( 4 ) > ,
< User: User object ( 5 ) > , < User: User object ( 6 ) > , < User: User object ( 7 ) > , < User: User object ( 8 ) > ,
< User: User object ( 9 ) > , < User: User object ( 10 ) > , < User: User object ( 11 ) > , < User: User object ( 12 ) > ,
< User: User object ( 13 ) > , < User: User object ( 14 ) > , < User: User object ( 15 ) > , < User: User object ( 16 ) > ,
< User: User object ( 17 ) > , < User: User object ( 18 ) > , < User: User object ( 19 ) > , < User: User object ( 20 ) > ,
'...(remaining elements truncated)...' ] >
如果需要获取全部的数据 , 可以通过遍历QuerySet对象开解决 .
QuerySet是可迭代的 , 这意味着可以使用Python的迭代机制 ( 如for循环 ) 来遍历它 .
QuerySet最常见的遍历方式就是使用for循环 .
在循环开始前执行一个查询来获取结果集中的所有对象 , 并将这些对象一次性加载到内存中 .
然后 , for循环会逐个遍历这些已经加载到内存中的对象 .
直接使用for循环遍历一个QuerySet时 , Django会在循环开始之前执行一个查询来获取所有的对象 .
这意味着无论QuerySet有多大 , 都只会执行一次查询来获取所有的结果 , 但这可能会导致大量的数据被加载到内存中 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. all ( )
for user in Users:
print ( user)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ;
args= ( )
当处理大量数据时 , 为了避免一次性将所有数据加载到内存中 , 可以使用QuerySet的iterator ( ) 方法 .
这个方法会返回一个生成器 , 允许一次只从数据库中获取一个对象 , 从而降低内存消耗 .
调用iterator ( ) 时 , Django会执行一个数据库查询来获取数据的游标 ( cursor ) ,
然后iterator ( ) 方法会逐个从这个游标中读取数据 , 直到所有数据都被遍历完毕 .
游标是数据库管理系统 ( DBMS ) 提供的一种机制 , 允许按顺序遍历查询结果集中的数据 , 而不需要一次性将整个结果集加载到内存中 .
每次获取下一个对象时 , Django会检查是否已经加载了下一个对象到内存中 .
如果没有 , 它会通过游标从数据库中检索下一个对象并将其加载到内存中 .
这个过程会一直持续到结果集中的所有对象都被遍历完毕 .
注意事项 :
- 使用iterator ( ) 后 , 将无法再次遍历相同的QuerySet , 因为它会消耗掉生成器中的元素 .
- 虽然iterator ( ) 减少了内存使用 , 但它可能会稍微降低性能 ,
因为每次迭代都需要与数据库进行交互 ( 尽管这种交互通常是通过高效的游标操作来完成的 ) .
如果查询结果集非常大 , 而又需要遍历整个结果集 , 那么使用iterator ( ) 可能会比一次性加载整个结果集到内存中需要更长的时间 .
然而 , 在内存受限的情况下 , iterator ( ) 是一个非常有用的工具 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. iterator( )
for user in Users:
print ( user)
( 0.016 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ;
args= ( )
总结 : 在大多数情况下 , 如果不确定数据集的大小 , 或者数据集可能很大 , 那么使用iterator ( ) 是一个更安全的选择 .
但是 , 如果知道数据集很小 , 或者你需要对结果集进行多次迭代 , 并且希望避免多次查询数据库 , 那么直接遍历QuerySet可能更合适 .
filter ( ) 方法 : 用于根据给定的条件过滤查询集 , 返回一个新的查询集 , 这个查询集包含了满足条件的所有对象 .
filter ( ) 方法总是返回一个查询集 , 即使没有任何对象满足条件也是如此 ( 这时返回的查询集将是空的 ) .
与all ( ) 方法不同 , filter ( ) 方法接受一个或多个关键字参数 , 这些参数指定了过滤条件 .
传递多个参数来应用多个过滤条件时这些条件作为AND逻辑连接起来 .
与all ( ) 方法一样 , filter ( ) 方法也是惰性的 , 即它不会立即执行数据库查询 , 而是返回一个可以链式调用的查询集对象 .
数据库查询只会在需要查询集中的数据时执行 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. filter ( age= 19 )
for user in Users:
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 19 ; a
rgs= ( 19 , )
过滤条件可以基于模型的任何字段 , 并且可以使用Django提供的字段查找 ( 如 : __year , __gt ( 大于 ) , __lt ( 小于 ) 等 ) 来进一步细化查询 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. filter ( age= 19 , id__gt= 4 )
for user in Users:
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ( ` index_user` . ` age` = 19 AND ` index_user` . ` id` > 4 ) ;
args= ( 19 , 4 )
exclude ( ) 方法 : 用于从查询集中排除满足给定条件的对象 .
传递多个参数来应用多个排除条件时这些条件作为AND逻辑连接起来 .
这个方法与filter ( ) 方法相反 , filter ( ) 是筛选出满足条件的对象 , 而exclude ( ) 则是过滤掉满足条件的对象 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. exclude( age= 19 )
for user in Users:
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE NOT ( ` index_user` . ` age` = 19 ) ;
args= ( 19 , )
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. exclude( age= 18 , name= 'kid' )
for user in Users:
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE NOT ( ` index_user` . ` age` = 18 AND ` index_user` . ` name` = 'kid' ) ;
args= ( 18 , 'kid' )
get ( ) 方法 : 用于从数据库中检索并返回一个满足特定条件的记录对象 .
注意事项 :
get ( ) 方法接收一个或多个关键字参数 , 这些参数定义了要检索的对象的查询条件 .
如果数据库中存在一个且仅有一个对象满足这些条件 , 那么该对象将被检索并返回 .
如果查询匹配多个对象或没有对象 , get ( ) 方法将引发异常 .
详细说明 :
- 如果找到多个匹配的对象 , get ( ) 方法将引发MultipleObjectsReturned ( 返回了多个对象 ) 异常 .
- 如果没有找到任何匹配的对象 , get ( ) 方法将引发DoesNotExist ( 不存在 ) 异常 .
这些异常都是Django ORM定义的 , 允许优雅地处理查询结果不符合预期的情况 .
建议 ( 不推荐使用get方法 ) :
如果不确定查询是否会返回多个结果 , 或者希望查询返回可能存在的多个对象 , 那么使用filter ( ) 方法可能更合适 .
filter ( ) 方法返回一个查询集 , 它可以包含零个 , 一个或多个对象 , 而不会引发异常 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
user = User. objects. get( name= 'kid' )
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` name` = 'kid'
LIMIT 21 ; args= ( 'kid' , )
MultipleObjectsReturned异常测试 , 如果有多个记录会抛出异常 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. get( age= 19 )
print ( Users)
( 0.000 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
WHERE `index_user`. `age` = 19
LIMIT 21 ;
args= ( 19 , )
错误提示信息 : index . models . MultipleObjectsReturned : get ( ) returned more than one User -- it returned 3 !
DoesNotExist异常测试 , 如果没有获取到记录会抛出异常 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. get( age= 199 )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 199
LIMIT 21 ;
args= ( 199 , )
错误提示信息 : index . models . DoesNotExist : User matching query does not exist .
order_by ( ) 方法 : 用于对查询集中的对象进行排序 .
可以指定一个或多个字段名 , 以及排序的方向 ( 升序或降序 ) , 以此来决定查询结果中对象的顺序 .
当指定多个字段进行排序时 , 这些字段将按照你提供的顺序被依次考虑 .
只有在前一个字段的值相同的情况下 , 才会根据下一个字段的值来进行排序 .
每个字段都可能带有前缀以指示降序排序 , 这些前缀参数决定了查询集中对象的排序方式 , 排序前缀如下 :
* 1. 默认情况下 , 字段名前面的负号 ( - ) 表示降序排序 .
* 2. 如果没有前缀或前缀为正号 ( + ) 表示升序排序 .
注意 , 正号通常是可选的 , 因为升序是默认的 .
注意事项 :
- User . objects . order_by ( 'xx' ) 和User . objects . all ( ) . order_by ( '' ) 这两种情况在逻辑上是等效的 , 它们都会生成相同的SQL查询 .
在实践中 , 直接使用User . objects . order_by ( 'xx' ) 更为简洁 , 且没有性能上的损失 .
- order_by ( ) 方法返回的是一个新的查询集 , 它包含了根据指定字段排序后的对象 , 原始查询集不会被修改 ( 如果有的话 ) .
在大多数情况下 , 直接对模型管理器如 : User . objects调用order_by ( ) 时 , 并没有一个显式的 '原始查询集' 变量 ) .
- 应该避免在大型数据集上进行复杂的排序操作 , 因为这可能会对数据库性能产生不利影响 .
- 如果可能的话 , 考虑在数据库级别上优化查询或使用索引来加速排序操作 .
- 没有提供参数时 , Django生成的SQL查询将不包含ORDER BY子句 , 因此数据库将返回其默认的 , 不可预测的结果顺序 .
这意味着数据库将按照它自己的默认方式返回查询结果 , 这通常是基于表在磁盘上的物理存储顺序 ,
但这个顺序对于开发者来说是不可预测的 , 因为它可能会随着数据的插入 , 更新 , 删除等操作而发生变化 .
没有提供参数时 , Django生成的SQL查询将不包含ORDER BY子句 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. order_by( )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 21 ; args= ( )
查询所有数据先按age字段升序 , 在按age字段降序 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. order_by( 'age' )
for user in Users:
print ( user. age)
print ( '---------------' )
Users = User. objects. order_by( '-age' )
for user in Users:
print ( user. age)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` age` ASC ;
args= ( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` age` DESC ;
args= ( )
User . objects . order_by ( 'xx' ) 和User . objects . all ( ) . order_by ( '' ) 这两种情况在逻辑上是等效的 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. all ( )
Users = Users. order_by( 'age' )
for user in Users:
print ( user. age)
print ( '---------------' )
Users = User. objects. order_by( 'age' )
for user in Users:
print ( user. age)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` age` ASC ;
args= ( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` age` ASC ;
args= ( )
在Django ORM中 , 查询集的链式调用是一个强大的特性 , 它允许开发者通过连续调用多个方法 , 在一个查询集对象上逐步构建出复杂的查询逻辑 .
当对一个模型的objects管理器调用方法 ( 如all ( ) , order_by ( ) 等 ) 时 , 会获得一个查询集对象 .
这个对象代表了数据库查询的初始状态 , 此时并没有立即执行数据库查询 , 只是构建了一个查询的 '蓝图' 或 '规范' .
开发者可以逐步向这个 '蓝图' 中添加筛选条件 , 排序字段等 , 从而构建出满足特定需求的查询规范 .
新增的调用方法会返回一个新的QuerySet对象 , 它包含了原始QuerySet的所有条件以及新添加的条件 .
注意 : QuerySet是不可变的 , 这意味着当对一个QuerySet链式调用方法时 , 而不是修改原始的QuerySet对象 .
链式调用可以写成一句或多句 , 这主要取决于编码风格和可读性需求 .
链式调用允许以流畅的方式将多个方法调用串联起来 , 每个方法调用都返回一个新的查询集 , 该查询集包含了对前一个查询集进行修改后的结果 .
写成一句通常是为了提高代码的可读性和简洁性 . 例如 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. filter ( age= 19 ) . order_by( 'name' )
for user in Users:
print ( user. name)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 19
ORDER BY ` index_user` . ` name` ASC ;
args= ( 19 , )
可以基于之前的查询集对象在后面链接上其他方法 , 以构建更复杂的查询条件 .
因此可以根据需要在任何时候向查询集中添加额外的过滤 , 排序或其他操作 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
user_age_19 = User. objects. filter ( age= 19 )
print ( user_age_19)
user_name_aa = user_age_19. filter ( name= 'aa' )
print ( user_name_aa)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 19
LIMIT 21 ;
args= ( 19 , )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ( ` index_user` . ` age` = 19 AND ` index_user` . ` name` = 'aa' )
LIMIT 21 ;
args= ( 19 , 'aa' )
QuerySet在Django中是不可变的 ( immutable ) , 这意味着当你对一个QuerySet进行链式调用方法时 ,
实际上是在创建并返回一个新的QuerySet对象 , 而不是修改原始的QuerySet对象 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
all_users = User. objects. all ( )
print ( "原始QuerySet:" , all_users)
user_age_19 = all_users. filter ( age= 19 )
print ( "age为19的用户QuerySet:" , user_age_19)
print ( "原始QuerySet:" , all_users)
sorted_user_age_19 = user_age_19. order_by( 'name' )
print ( "按name排序的age为19的用户QuerySet:" , sorted_user_age_19)
print ( "age为19的用户QuerySet:" , user_age_19)
( 0.000 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
LIMIT 21 ;
args= ( )
( 0.000 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user` WHERE `index_user`. `age` = 19
LIMIT 21 ;
args= ( 19 , )
( 0.000 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
LIMIT 21 ;
args= ( )
( 0.016 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
WHERE `index_user`. `age` = 19
ORDER BY `index_user`. `name` ASC
LIMIT 21 ;
args= ( 19 , )
( 0.000 )
SELECT `index_user`. `id `, `index_user`. `name`, `index_user`. `age`, `index_user`. `register_time`
FROM `index_user`
WHERE `index_user`. `age` = 19
LIMIT 21 ;
args= ( 19 , )
reverse ( ) 方法 : 用于反转查询集中对象的顺序 .
注意 : 这个方法必须与order_by ( ) 方法一起使用 , 确保在反转之前查询集已经根据某个或某些字段进行了排序 , 否则没有效果 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. reverse( )
print ( Users)
Users = User. objects. order_by( 'id' ) . reverse( )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 21 ;
args= ( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` id` DESC
LIMIT 21 ;
args= ( )
values ( * fields , expressions ) 方法 : 返回一个包含字典的查询集 .
每个字典代表数据库中的一个对象 ( 通常是模型的一个实例 ) , 字典的键是传递给values ( ) 方法的字段名 , 而字典的值则是对应字段的值 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. values( 'pk' , 'name' , 'age' )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` FROM ` index_user` LIMIT 21 ;
args= ( )
values_list ( * fields , flat = False ) 方法 : 与values ( ) 类似 , 但它返回的是元组的列表 , 而不是字典的列表 .
元组的每个元素对应于传递给values_list ( ) 方法的字段名 .
如果flat设置为True , 并且只传递了一个字段名给values_list ( ) , 那么返回的将是一个单一值的列表 , 而不是元组的列表 .
这在只需要模型的一个字段值时特别有用 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. values_list( 'pk' , 'name' , 'age' )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` FROM ` index_user` LIMIT 21 ;
args= ( )
如果设置flat = True并只传递一个字段 , 则返回一个包含所有字段值的列表 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. values_list( 'name' , flat= True )
print ( Users)
( 0.000 )
SELECT ` index_user` . ` name` FROM ` index_user` LIMIT 21 ;
args= ( )
distinct ( * fields ) : 返回查询集中不同 ( 去重 ) 的对象集合 .
如果指定了 * fields , 则仅在这些字段上进行去重 .
distinct ( ) 方法默认作用于所有查询的字段上 , 以去除完全相同的记录 .
但是 , Django ORM并不直接支持在指定字段上进行去重 , 因为数据库层面的DISTINCT操作通常是针对整行记录而言的 .
不过 , 可以通过一些技巧 ( 如使用values ( ) 或values_list ( ) 与distinct ( ) 结合 ) 来模拟在特定字段上的去重效果 .
注意 : 所有键 ( 包括id ) 唯一才去重 , 并且id几乎不会重复 , 索引写查询语句一定排除id字段 , 否则无效果 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. distinct( )
for user in Users:
print ( user. name, user. age)
Users = User. objects. values( 'name' , 'age' ) . distinct( )
print ( Users)
for user in Users:
print ( user)
( 0.000 )
SELECT DISTINCT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 21 ;
args= ( )
( 0.000 )
SELECT DISTINCT ` index_user` . ` name` , ` index_user` . ` age` FROM ` index_user` LIMIT 21 ;
args= ( )
first ( ) 方法 : 返回查询集中的第一个对象 ( 按id升序获取第一条记录 ) .
last ( ) 方法 : 返回查询集中的最后一个对象 ( 按id降序获取第一条记录 ) .
注意事项 :
- 使用first ( ) 和last ( ) 时 , 确保查询集已经通过order_by ( ) 方法进行了排序 ,
因为 '第一个' 和 '最后一个' 的定义依赖于排序的顺序 .
- 如果查询集是空的 ( 即没有找到任何匹配的对象 ) , first ( ) 和last ( ) 都会返回None .
- 在处理大量数据时 , first ( ) 和last ( ) 方法比检索整个查询集并手动选择第一个或最后一个元素要高效得多 ,
因为它们允许数据库在内部进行优化 , 只返回需要的一个对象 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
user = User. objects. first( )
print ( user. id )
user = User. objects. last( )
print ( user. id )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` id` ASC
LIMIT 1 ;
args= ( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ORDER BY ` index_user` . ` id` DESC
LIMIT 1 ;
args= ( )
count ( ) 方法 : 用于返回查询集中对象的数量 .
注意 : 频繁使用count ( ) 方法可能会对性能产生影响 , 特别是当处理大量数据时 .
在这种情况下 , 考虑是否有其他方法来优化你的查询或逻辑 , 比如使用缓存来存储计算结果等 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
num = User. objects. count( )
print ( num)
( 0.015 )
SELECT COUNT ( * ) AS ` __count` FROM ` index_user` ;
args= ( )
exists ( ) 方法 : 返回一个布尔值 ( True 或 False ) , 用于检查查询集中是否存在至少一个对象 .
exists ( ) 方法是处理大型数据集时检查查询集是否为空的推荐方法 , 因为它可以显著提高性能 .
它直接对数据库执行一个EXISTS SQL查询 , 这通常比检索整个查询集然后检查其长度要快得多 .
if queryset : 会导致Django执行查询并加载整个查询集到内存中 ( 如果查询集还没有被加载的话 ) , 即使只是想要检查查询集是否为空 .
这可能会消耗大量的内存和处理时间 , 特别是在处理大量数据时 . ( 最慢 , 数据越少越慢 )
执行的SQL语句为 : SELECT * FROM ` index_user ` ;
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
if queryset:
print ( 1 )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ;
args= ( )
queryset . count ( ) 方法 : 会返回查询集中的对象数量 , 但它也会执行一个查询来计算这个数量 . ( 稍快 )
执行的SQL语句为 : SELECT COUNT ( * ) AS ` __count ` FROM ` index_user ` ;
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
if queryset. count( ) :
print ( 1 )
( 0.000 ) SELECT COUNT ( * ) AS ` __count` FROM ` index_user` ; args= ( )
exists ( ) 方法 : 只需要检查是否存在至少一个对象 , 而不需要计算确切的数量 , ( 最快 )
执行的SQL语句为 : SELECT 1 AS ` a ` FROM ` index_user ` LIMIT 1 ;
代码的意思是 : 如果index_user表是空的 ( 即不包含任何行 ) , 那么由于LIMIT 1 的存在 , 查询将不会返回任何行 .
因为即使尝试检索 , 也没有符合条件的行可以返回 .
如果index_user表包含至少一行数据 , 那么查询将返回一行 , 这一行的a列值为 1.
这是因为查询指定了SELECT 1 AS a , 即无论表中有什么数据 , 都会返回一个值为 1 的a列 , 并且由于LIMIT 1 , 它只返回这一行 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
if queryset. exists( ) :
print ( 1 )
( 0.000 ) SELECT ( 1 ) AS ` a` FROM ` index_user` LIMIT 1 ; args= ( )
Django ORM中的QuerySet缓存机制是一个重要的特性 , 用于减少不必要的数据库查询 , 提高应用性能 .
缓存机制 : Django会为已经评估过的QuerySet提供缓存机制 .
一旦QuerySet被完整评估并返回结果 , 这些结果就会被缓存起来 .
如果后续再次对该QuerySet进行评估 ( 且查询条件没有变化 ) , Django就会直接返回缓存中的结果 , 而无需再次与数据库交互 .
Django的QuerySet缓存机制是在QuerySet被评估 ( 即触发数据库查询 ) 后起作用的 , 而不是在 '普通评估' ( 如过滤 , 排序等操作 ) 阶段 .
这些 '普通评估' 操作只是构建了查询的条件 , 而真正的查询和缓存发生在这些条件被用来从数据库中检索数据时 .
触发完整评估的方法 :
- 迭代QuerySet , 迭代QuerySet会触发完整评估 ( 即执行数据库查询并缓存结果 ) .
使用iterator ( ) 会绕过Django的QuerySet缓存机制 , 因为每次调用next ( ) 时都会从数据库中检索下一个数据项 .
- 转换为列表 : 使用Python内置的list ( ) 函数将QuerySet对象转换为列表 .
这个操作会触发QuerySet的完整评估 , 因为列表需要包含QuerySet中所有的数据项 .
- 检查QuerySet是否为真 : 在布尔上下文中使用QuerySet ( 如使用bool ( ) 函数或在if语句中 ) 也会触发完整评估 .
Django会检查QuerySet中是否有数据项存在 , 以决定是否返回True或False .
- 序列化QuerySet : 当需要将QuerySet对象序列化为JSON或其他格式时 , 也会触发完整评估 .
因为序列化过程需要遍历QuerySet中的所有数据项 , 并将其转换为指定的格式 .
- 其他方法 : 还有一些其他方法可能会触发QuerySet的完整评估 , 如 : len ( ) 获取QuerySet的长度 .
如果只对QuerySet进行了部分迭代或切片 , 而没有进行完整迭代 , 通常不会触发缓存 .
因为Django无法确定是否需要缓存整个QuerySet的结果 .
当QuerySet被完整迭代时 , Django会执行查询并将结果存储在QuerySet的_result_cache属性中 .
这意味着 , 之后对相同QuerySet的任何迭代都将直接从缓存中读取数据 , 而不需要再次查询数据库 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
for user in queryset:
print ( user)
for user in queryset:
print ( user)
print ( queryset. _result_cache)
注意 :
执行queryset = User . objects . all ( ) 之后 ,
直接打印queryset , 执行的的SQL是 : SELECT * FROM ` index_user ` LIMIT 21 ; 做了性能优化 , 没有缓存 .
使用for遍历queryset , 执行的的SQL是 : SELECT * FROM ` index_user ` ; 获取所有数据 , 可以缓存 .
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ;
args= ( )
如果只对QuerySet进行了部分迭代或切片 , 而没有进行完整迭代 , 通常不会触发缓存 ( 一般只有完整的 ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
for user in queryset[ : 2 ] :
print ( user)
for user in queryset[ : 2 ] :
print ( user)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 2 ;
args= ( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` LIMIT 2 ;
args= ( )
可以用Python内置的list ( ) 函数将QuerySet对象转换为列表 , 这个操作会触发QuerySet的完整评估 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
print ( list ( queryset) )
print ( list ( queryset) )
print ( queryset)
print ( queryset. _result_cache)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 19 ;
args= ( 19 , )
在布尔上下文中使用QuerySet , 如 : if queryset执行的SQL语句是 : SELECT * FROM ` table ` ; 获取所有数据 , 会触发完整评估 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
queryset = User. objects. all ( )
if queryset:
print ( 1 )
if queryset. count( ) :
print ( 1 )
if queryset. exists( ) :
print ( 1 )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` ;
args= ( )
queryset . count ( ) 和queryset . exists ( ) 在Django中确实不会触发对QuerySet的完整评估 , 即它们不会检索QuerySet中的所有数据项 .
这两个方法都用于检查QuerySet是否包含数据 , 但它们以不同的方式执行此操作 , 并且都旨在优化性能 .
only ( * fields ) 方法 : 允许指定在查询时只加载哪些字段 ( 默认会添加id字段 ) .
这意味着除了指定的字段之外 , 其他所有字段都不会被检索出来 .
这在只需要模型中的几个字段时特别有用 , 因为它可以显著减少从数据库检索的数据量 .
假设有一个Book模型 ( 自己随便定义一个 , 再插入两条数据用于测试即可 ) , 它有很多字段 , 但现在只需要title和author字段 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
books = Book. objects. only( 'title' , 'price' )
for book in books:
print ( book. title, book. price, book. author)
( 0.015 ) SELECT ` index_book` . ` id` , ` index_book` . ` title` FROM ` index_book` ; args= ( )
其他方法执行的都是SELECT * FROM table加载全部字段 , 而only则加载指定字段的数据 .
defer ( * fields ) 方法 : 允许指定在查询时不想加载的字段 .
这意味着 , 当查询一个模型实例时 , 指定的字段将不会被检索出来 , 直到显式地请求它们 .
这种方法对于当只需要模型中的少数几个字段时非常有用 , 因为它可以减少从数据库检索的数据量 .
继续使用Book模型的例子 , 但这次只关心title和author字段 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
books = Book. objects. defer( 'price' )
for book in books:
print ( book. id , book. title, book. publish_date, book. price)
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` publish_date` , ` index_book` . ` publisher_id` FROM ` index_book` ;
args= ( )
( 0.016 )
SELECT ` index_book` . ` id` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` id` = 3
LIMIT 21 ;
args= ( 3 , )
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` id` = 4
LIMIT 21 ; args= ( 4 , )
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` id` = 5
LIMIT 21 ; args= ( 5 , )
最后的注释解释了Django ORM的defer方法的一个关键行为 :
当使用defer方法指定了一些不想在初始查询中加载的字段 ( 即 'deferred' 字段 ) 后 ,
如果在后续的代码中尝试访问这些被deferred的字段 ,
Django不会自动知道你已经标记了这些字段为deferred , 并且不会在初始查询中检索它们 .
因此 , 当尝试访问一个被deferred的字段时 ( 比如book . price ) ,
Django会注意到这个字段在当前的查询结果集中不可用 ,
并且会为你当前正在访问的特定实例动态地执行一个新的数据库查询来检索这个字段的值 .
这种行为可能会导致所谓的 ' N + 1 查询问题 ; , 即如果在一个循环中访问了多个实例的deferred字段 , 并且每个实例都触发了一个新的数据库查询 ,
那么总的数据库查询次数就会是初始查询次数 ( 1 次 , 用于加载非deferred字段 ) 加上循环中实例的数量 ( N次 , 每次用于加载一个deferred字段 ) .
这可能会显著影响你的应用程序的性能 , 特别是当实例数量很大时 .
为了避免这种情况 , 应该仔细考虑哪些字段是真正需要的 , 并只使用defer或only来优化那些确实可以减少数据传输量的查询 .
如果发现自己经常需要访问被deferred的字段 , 那么可能最好不要使用defer , 而是让Django加载所有字段 , 或者重新考虑你的数据访问模式 .
尽管Django ORM提供了丰富的 API 来执行大多数数据库操作 , 但在某些情况下 , 可能需要编写自定义的SQL查询 .
raw ( ) 方法允许执行原始SQL查询并返回一个RawQuerySet .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
sql = "SELECT * FROM index_user WHERE name = %s"
raw_queryset = User. objects. raw( sql, [ 'kid' ] )
for user in raw_queryset:
print ( user. id , user. name)
( 0.000 ) SELECT * FROM index_user WHERE name = 'kid' ; args( 'kid' , )
在Django的ORM中 , 构造一个查询条件 , 比如 : id > 4 , 这样的条件不能直接作为位置参数传递给filter ( ) 方法 .
在方法调用时像filter ( id > 4 ) 这样写 , Python解释器会将id > 4 视为一个布尔值表达式 ,
会将表达式的值 ( True或False ) 传递给filter ( ) , 这显然不是想要的结果 .
Django提供了一系列的字段查找操作符 , 用于在filter ( ) , exclude ( ) , annotate ( ) , order_by ( ) 等查询方法中构建复杂的查询条件 .
以下是一些常用的Django ORM字段查找操作符及其简介 :
* 1. __exact : 精确匹配 .
这是默认的查找方式 , 如果没有指定查找类型 , 则使用__exact .
例如 , filter ( name__exact = "John" ) 等同于filter ( name = "John" ) .
* 2. __iexact : 不区分大小写的精确匹配 .
例如 , filter ( name__iexact = "john" ) 会匹配John , john , JOHN等 .
* 3. __contains : 包含 .
对于文本字段 , 匹配字段中包含的字符串 .
例如 , filter ( name__contains = "ohn" ) 会匹配John , Jonathan等 .
* 4. __icontains : 不区分大小写的包含 .
例如 , filter ( name__icontains = "ohn" ) 会匹配John , john , jOhn等 .
* 5. __gt , __gte , __lt , __lte : 分别表示大于 , 大于等于 , 小于 , 小于等于 . 这些操作符通常用于数值或日期字段 ,
例如 , filter ( age__gt = 18 ) 会匹配所有年龄大于 18 的记录 .
* 6. __in : 如果指定的字段在序列中 , 则返回True ; 否则返回False .
例如 , filter ( id__in = [ 1 , 2 , 3 ] ) 会匹配ID为 1 , 2 或 3 的记录 .
* 7. __startswith , __istartswith : 以指定值开始 . __istartswith是不区分大小写的版本 .
例如 , filter ( name__startswith = "J" ) 会匹配所有名字以J开头的记录 .
* 8. __endswith , __iendswith : 以指定值结束 . __iendswith是不区分大小写的版本 .
* 9. __isnull : 判断字段是否为NULL .
例如 , filter ( birthday__isnull = True ) 会匹配所有没有生日 ( 即birthday字段为NULL ) 的记录 .
* 9. __range : 指定一个范围 , 以筛选出位于这个范围内的记录 . 通常用于数值或日期字段 .
例如 , filter ( age__range = ( 20 , 30 ) ) 会匹配年龄在 18 到 30 岁之间的记录 ( 包括 20 和 30 ) .
* 10. __year , __month , __day , __week_day , __hour , __minute , __second : 这些操作符用于日期和时间字段 ,
分别提取并匹配年 , 月 , 日 , 星期几 , 小时 , 分钟 , 秒 .
* 11. __regex , __iregex : 正则表达式匹配 . __iregex是不区分大小写的版本 .
例如 , filter ( name__regex = r '^J' ) 会匹配所有名字以J开头的记录 .
请注意 , 上述操作符中的__前缀是Django ORM用于区分字段名和查找类型的约定 .
此外 , Django还提供了更多的高级查找功能 , 如Q对象 ( 用于构建复杂查询逻辑 , 如OR查询 ) 和F表达式 ( 用于数据库级别的字段值比较和计算 ) .
定义一个Person的模型用于测试 , 表中包含id , name , age , birthday字段 .
from django. db import models
class Person ( models. Model) :
name = models. CharField( max_length= 100 )
age = models. IntegerField( )
birthday = models. DateTimeField( null= True , blank= True )
def __str__ ( self) :
return self. name
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0002_person. py
- Create model Person
. . .
PS D: \MyDjango> python manage. py makemigrations
. . .
在Django中 , 当USE_TZ = True时 , 所有DateTimeField都应该接收时区感知的datetime对象 , 这些对象包含时区信息 .
如果你不提供时区信息 , Django会尝试使用默认的时区 ( TIME_ZONE设置在settings . py中 ) 来转换这个naive datetime对象 ,
但这可能会导致不期望的行为 ( 例 : RuntimeWarning ) , 特别是当数据库服务器和Django应用的时区设置不一致时 .
创建一些示例数据 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
from datetime import datetime
from django. utils import timezone
aware_datetime1 = timezone. make_aware( datetime( 1995 , 10 , 10 , 14 , 30 , 45 ) , timezone. get_default_timezone( ) )
aware_datetime2 = timezone. make_aware( datetime( 1990 , 5 , 5 , 16 , 11 , 45 ) , timezone. get_default_timezone( ) )
aware_datetime3 = timezone. make_aware( datetime( 1985 , 2 , 10 , 20 , 30 , 45 ) , timezone. get_default_timezone( ) )
Person. objects. create( name= "John Doe" , age= 25 , birthday= aware_datetime1)
Person. objects. create( name= "john smith" , age= 30 , birthday= aware_datetime2)
Person. objects. create( name= "Jane Doe" , age= 22 , birthday= None )
Person. objects. create( name= "Jonathan Davis" , age= 35 , birthday= aware_datetime3)
( 0.000 )
INSERT INTO ` index_person` ( ` name` , ` age` , ` birthday` )
VALUES ( 'John Doe' , 25 , '1995-10-10 14:30:45' ) ;
args= [ 'John Doe' , 25 , '1995-10-10 14:30:45' ]
( 0.000 )
INSERT INTO ` index_person` ( ` name` , ` age` , ` birthday` )
VALUES ( 'john smith' , 30 , '1990-05-05 16:11:45' ) ;
args= [ 'john smith' , 30 , '1990-05-05 16:11:45' ]
( 0.000 )
INSERT INTO ` index_person` ( ` name` , ` age` , ` birthday` )
VALUES ( 'Jane Doe' , 22 , NULL ) ;
args= [ 'Jane Doe' , 22 , None]
( 0.000 )
INSERT INTO ` index_person` ( ` name` , ` age` , ` birthday` )
VALUES ( 'Jonathan Davis' , 35 , '1985-02-10 20:30:45' ) ;
args= [ 'Jonathan Davis' , 35 , '1985-02-10 20:30:45' ]
__exact : 精确匹配 .
这是默认的查找方式 , 如果没有指定查找类型 , 则使用__exact .
例如 , filter ( name__exact = "John" ) 等同于filter ( name = "John" ) .
__iexact : 不区分大小写的精确匹配 ( 使用了LIKE模糊查询 ) .
例如 , filter ( name__iexact = "john" ) 会匹配John , john , JOHN等 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( name__exact= "John Doe" ) )
print ( Person. objects. filter ( name__iexact= "john doe" ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` = 'John Doe'
LIMIT 21 ;
args= ( 'John Doe' , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE 'john doe'
LIMIT 21 ;
args= ( 'john doe' , )
__contains : 包含 . ( 使用了 % % 通配符 )
对于文本字段 , 匹配字段中包含的字符串 .
例如 , filter ( name__contains = "ohn" ) 会匹配John , Jonathan等 .
__icontains : 不区分大小写的包含 . ( % like % )
例如 , filter ( name__icontains = "ohn" ) 会匹配John , john , jOhn等 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( name__contains= "Doe" ) )
print ( Person. objects. filter ( name__icontains= "doe" ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE BINARY '%Doe%'
LIMIT 21 ;
args= ( '%Doe%' , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE '%doe%'
LIMIT 21 ;
args= ( '%doe%' , )
__gt , __gte , __lt , __lte : 分别表示大于 , 大于等于 , 小于 , 小于等于 . 这些操作符通常用于数值或日期字段 ,
例如 , filter ( age__gt = 18 ) 会匹配所有年龄大于 18 的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( age__gt= 25 ) )
print ( Person. objects. filter ( age__lt= 25 ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` age` > 25
LIMIT 21 ;
args= ( 25 , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` age` < 25
LIMIT 21 ;
args= ( 25 , )
__in : 如果指定的字段在序列中 , 则返回True ; 否则返回False .
例如 , filter ( id__in = [ 1 , 2 , 3 ] ) 会匹配ID为 1 , 2 或 3 的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( age__in= [ 25 , 30 ] ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` age` IN ( 25 , 30 )
LIMIT 21 ;
args= ( 25 , 30 )
__startswith , __istartswith ( 不区分大小写 ) : 以指定值开始 .
__endswith , __iendswith ( 不区分大小写 ) : 以指定值结束 .
例如 , filter ( name__startswith = "J" ) 会匹配所有名字以J开头的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( name__startswith= "J" ) )
print ( Person. objects. filter ( name__istartswith= "e" ) )
print ( Person. objects. filter ( name__iendswith= "Doe" ) )
print ( Person. objects. filter ( name__iendswith= "doe" ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE BINARY 'J%'
LIMIT 21 ;
args= ( 'J%' , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE 'e%'
LIMIT 21 ;
args= ( 'e%' , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE '%Doe'
LIMIT 21 ;
args= ( '%Doe' , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` name` LIKE '%doe'
LIMIT 21 ;
args= ( '%doe' , )
__isnull : 判断字段是否为NULL .
例如 , filter ( birthday__isnull = True ) 会匹配所有没有生日 ( 即birthday字段为NULL ) 的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( birthday__isnull= True ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` birthday` IS NULL
LIMIT 21 ;
args= ( )
__range : 指定一个范围 , 以筛选出位于这个范围内的记录 . 通常用于数值或日期字段 .
例如 , filter ( age__range = ( 20 , 30 ) ) 会匹配年龄在 20 到 30 岁之间的记录 ( 包括 20 和 30 ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( age__range= ( 20 , 30 ) ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` age` BETWEEN 20 AND 30
LIMIT 21 ;
args= ( 20 , 30 )
__year : 匹配年份部分 .
__month : 匹配月份部分 .
__day : 匹配日份部分 .
__week_day : 用于匹配星期几 ( 通常是从 0 或 1 开始的索引 , 表示星期一到星期日 ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( birthday__year= 1995 ) )
print ( Person. objects. filter ( birthday__month= 10 ) )
print ( Person. objects. filter ( birthday__day= 10 ) )
print ( Person. objects. filter ( birthday__week_day= 3 ) )
( 0.000 ) SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE ` index_person` . ` birthday` BETWEEN '1995-01-01 00:00:00' AND '1995-12-31 23:59:59.999999'
LIMIT 21 ;
args= ( '1995-01-01 00:00:00' , '1995-12-31 23:59:59.999999' )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE EXTRACT( MONTH FROM ` index_person` . ` birthday` ) = 10
LIMIT 21 ;
args= ( 10 , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE EXTRACT( DAY FROM ` index_person` . ` birthday` ) = 10
LIMIT 21 ;
args= ( 10 , )
( 0.000 ) SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE DAYOFWEEK( ` index_person` . ` birthday` ) = 3
LIMIT 21 ;
args= ( 3 , )
EXTRACT是一个SQL函数 , 用于从日期或时间值中提取特定的部分 ) 如年 , 月 , 日 , 小时等 ) .
- EXTRACT ( MONTH FROM ` index_person ` . ` birthday ` ) : 这个函数调用从birthday字段中提取月份部分 .
- EXTRACT ( DAY FROM ` index_person ` . ` birthday ` ) : 这个函数调用从birthday字段中提取日期部分 .
DAYOFWEEK ( ) 函数用于获取一个日期是周几 .
__hour : 匹配小时部分 .
__minute : 匹配分钟部分 .
__second : 匹配取秒部分 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( birthday__hour= 14 ) )
print ( Person. objects. filter ( birthday__minute= 30 ) )
print ( Person. objects. filter ( birthday__second= 45 ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE EXTRACT( HOUR FROM ` index_person` . ` birthday` ) = 14
LIMIT 21 ;
args= ( 14 , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE EXTRACT( MINUTE FROM ` index_person` . ` birthday` ) = 30
LIMIT 21 ;
args= ( 30 , )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE EXTRACT( SECOND FROM ` index_person` . ` birthday` ) = 45
LIMIT 21 ;
args= ( 45 , )
EXTRACT ( HOUR FROM ` index_person ` . ` birthday ` ) : 这个函数调用从birthday字段中提取小时部分 .
EXTRACT ( MINUTE FROM ` index_person ` . ` birthday ` ) : 这个函数调用从birthday字段中提取分钟部分 .
EXTRACT ( SECOND FROM ` index_person ` . ` birthday ` ) : 这个函数调用从birthday字段中提取秒部分 .
__regex , __iregex ( 不区分大小 ) : 正则表达式匹配 .
例如 , filter ( name__regex = r '^J' ) 会匹配所有名字以J开头的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Person
print ( Person. objects. filter ( name__regex= r'^J' ) )
print ( Person. objects. filter ( name__iregex= r'^j' ) )
( 0.000 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE REGEXP_LIKE( ` index_person` . ` name` , '^J' , 'c' )
LIMIT 21 ;
args= ( '^J' , )
( 0.016 )
SELECT ` index_person` . ` id` , ` index_person` . ` name` , ` index_person` . ` age` , ` index_person` . ` birthday` FROM ` index_person` WHERE REGEXP_LIKE( ` index_person` . ` name` , '^j' , 'i' )
LIMIT 21 ;
args= ( '^j' , )
Django ORM提供了多种修改数据库表记录的方式 , 主要包括更新记录 , 批量更新记录等方式 .
更新记录通常涉及以下几个步骤 :
* 1. 查询记录 : 首先 , 使用filter ( ) 等方法查询出需要更新的记录集 ( QuerySet ) .
* 2.1 保存更改 : 如果使用对象属性修改方式 , 则需要调用对象的save ( ) 方法来保存更改 ;
* 2.2 修改属性 : 然后 , 可以通过遍历QuerySet中的对象并修改其属性 , 或者直接使用update ( ) 方法 ( 对于QuerySet ) 来更新字段值 .
save ( ) 方法 : 它是Django模型 ( Model ) 实例的一个方法 , 用于将模型的更改保存到数据库中 .
当修改了模型实例的某个字段后 , 调用该实例的save ( ) 方法会将这些更改提交到数据库 , 并触发相关的模型信号 ( 如 : pre_save和post_save ) .
返回值 : save ( ) 方法没有返回值 ( 在Python中 , 这通常意味着返回None ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
user = User. objects. get( id = 1 )
user. name = '张三'
res = user. save( )
print ( res)
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` id` = 1
LIMIT 21 ;
args= ( 1 , )
( 0.016 )
UPDATE ` index_user` SET ` name` = '张三' , ` age` = 18 , ` register_time` = '2024-07-09 02:49:31.475065'
WHERE ` index_user` . ` id` = 1 ;
args= ( '张三' , 18 , '2024-07-09 02:49:31.475065' , 1 )
批量修改 : 通过循环遍历模型的查询集并为每个模型字段设置新的字段然后调用save ( ) 方法 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
Users = User. objects. filter ( age= 19 )
for user in Users:
user. age = 20
user. save( )
( 0.000 )
SELECT ` index_user` . ` id` , ` index_user` . ` name` , ` index_user` . ` age` , ` index_user` . ` register_time` FROM ` index_user` WHERE ` index_user` . ` age` = 19 ;
args= ( 19 , )
( 0.016 )
UPDATE ` index_user` SET ` name` = 'aa' , ` age` = 20 , ` register_time` = '2024-07-09 04:33:00.323082'
WHERE ` index_user` . ` id` = 3 ;
args= ( 'aa' , 20 , '2024-07-09 04:33:00.323082' , 3 )
( 0.000 )
UPDATE ` index_user` SET ` name` = 'bb' , ` age` = 20 , ` register_time` = '2024-07-09 04:33:00.323082'
WHERE ` index_user` . ` id` = 4 ;
args= ( 'bb' , 20 , '2024-07-09 04:33:00.323082' , 4 )
( 0.000 )
UPDATE ` index_user` SET ` name` = 'cc' , ` age` = 20 , ` register_time` = '2024-07-09 04:33:00.323082'
WHERE ` index_user` . ` id` = 5 ;
args= ( 'cc' , 20 , '2024-07-09 04:33:00.323082' , 5 )
对于大量的数据更新 , 这种方法会非常低效 , 因为它会产生大量的数据库调用 .
这种情况 , Django ORM中推荐的批量更新是使用update ( ) 方法 .
update ( ) 方法 : 它是Django查询集 ( QuerySet ) 的一个方法 , 用于批量更新满足特定条件的记录 .
与save ( ) 方法不同 , update ( ) 直接在数据库层面执行更新操作 , 不需要先加载记录到内存中 .
返回值 : update ( ) 方法返回一个整数 , 表示受影响的记录数 ( 即被更新的记录数 ) .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
res = User. objects. filter ( age= 20 ) . update( age= 21 )
print ( res)
这种方式比遍历QuerySet中的每个对象并调用save ( ) 方法更高效 , 因为它减少了数据库交互的次数 .
( 0.000 ) UPDATE ` index_user` SET ` age` = 21 WHERE ` index_user` . ` age` = 20 ; args= ( 21 , 20 )
在Django ORM中 , 删除表中的记录可以通过模型的delete ( ) 方法来完成 .
这个方法既可以应用于单个模型实例 , 也可以应用于一个查询集 ( QuerySet ) .
返回值 : delete ( ) 方的返回值是一个元组 , 其中包含两个整数值 :
第一个元素是一个整数 , 表示被直接删除的记录总数 ( 即调用 . delete ( ) 方法的查询集中所包含的记录数 ) .
第二个元素是一个字典 , 其键是的字符串表示 , 值是该模型删除的记录数 .
如果每次删除记录则显示为 : ( 0 , { } ) .
注意事项 :
- 在使用delete ( ) 方法时 , Django会发出pre_delete和post_delete信号 , 如果需要在删除操作前后执行一些自定义逻辑 , 可以监听这些信号 .
- 删除操作是不可逆的 , 因此在执行之前请确保这是真正想要的操作 .
删除单条记录 : 需要先获取到想要删除的模型实例 , 一旦有了这个实例 , 就可以调用它的delete ( ) 方法来删除它 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
user = User. objects. filter ( id = 1 )
res = user. delete( )
print ( res)
( 0.000 ) DELETE FROM ` index_user` WHERE ` index_user` . ` id` = 1 ; args= ( 1 , )
删除查询集中的多个记录 : 先获取查询集 ( QuerySet ) , 在调用它的delete ( ) 方法删除查询集中所有的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import User
res = User. objects. filter ( age= 21 ) . delete( )
print ( res)
( 0.016 ) DELETE FROM ` index_user` WHERE ` index_user` . ` age` = 21 ; args= ( 21 , )
Raw SQL , 即原始SQL , 指的是直接在应用程序或数据库管理系统中执行的SQL ( Structured Query Language , 结构化查询语言 ) 语句 .
Raw SQL的使用允许开发者绕过ORM ( 对象关系映射 ) 框架或其他数据库抽象层 , 直接对数据库执行具体的SQL语句 .
在Django中 , 虽然ORM ( 对象关系映射 ) 是推荐的方式来与数据库交互 , 但在某些情况下 , 可能需要直接使用原始SQL语句来执行数据库操作 .
这可以通过Django的cursor对象来实现 .
在Django框架中 , django . db . connection是一个代表当前数据库连接的对象 .
这个对象提供了与数据库交互的能力 , 包括执行SQL查询 , 管理事务等 .
使用connection . cursor ( ) 方法可以获取一个数据库游标 ( cursor ) 对象 , 这个游标对象允许执行SQL语句并获取结果 .
手写的sql语句可以不在末尾加上 ; 号 , 使用的数据库模块会自动加上 .
如果加上了 ; 号 , 在ORM日志中会看到执行的SQL语句会有两个分号 ; ; .
使用原始SQL插入一条记录到User表中 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from django. db import connection
import time
with connection. cursor( ) as cursor:
sql = "INSERT INTO index_user (name, age, register_time) VALUES (%s, %s, %s);"
formatted_time = time. strftime( "%Y-%m-%d %H:%M:%S" )
val = ( 'Python' , 18 , formatted_time)
res = cursor. execute( sql, val)
print ( res)
with connection . cursor ( ) as cursor : 这行代码利用了Python的上下文管理器 ( context manager ) 特性 ,
这是一种常用的模式 , 用于确保资源 ( 如文件句柄 , 数据库连接等 ) 在使用后能够被正确释放或关闭 .
( 0.000 )
INSERT INTO index_user ( name, age, register_time)
VALUES ( 'Python' , 18 , '2024-07-12 16:55:28' ) ; ;
args= ( 'Python' , 18 , '2024-07-12 16:55:28' )
使用原始SQL查询User表中的数据 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from django. db import connection
with connection. cursor( ) as cursor:
sql = "SELECT * FROM index_user WHERE id = %s;"
cursor. execute( sql, ( 8 , ) )
row = cursor. fetchone( )
if row:
print ( f'id: { row[ 0 ] } , name: { row[ 1 ] } , register_time: { row[ 3 ] } ' )
( 0.000 ) SELECT * FROM index_user WHERE id = 8 ; ; args= ( 8 , )
使用原始SQL修改User表中的一条记录 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from django. db import connection
with connection. cursor( ) as cursor:
sql = "UPDATE index_user SET name = %s WHERE id = %s"
val = ( 'Linux' , 8 )
res = cursor. execute( sql, val)
print ( res)
( 0.015 ) UPDATE index_user SET name = 'Linux' WHERE id = 8 ; args= ( 'Linux' , 8 )
使用原始SQL删除User表中的一条记录 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from django. db import connection
with connection. cursor( ) as cursor:
sql = "DELETE FROM index_user WHERE id = %s;"
val = ( 8 , )
res = cursor. execute( sql, val)
print ( res)
( 0.000 ) DELETE FROM index_user WHERE id = 8 ; ; args= ( 8 , )
Q查询提供了在查询中构建复杂逻辑条件的能力 .
默认情况下 , Django ORM的查询是逻辑与 ( AND ) 连接的 , 而Q查询允许使用逻辑或 ( OR ) , 逻辑非 ( NOT ) 等条件来构建更复杂的查询 .
导入方式 : from django . db . models import Q
Q对象之间可以使用 : | ( OR ) , & ( AND ) , ~ ( NOT ) 操作符来组合使用 .
定义一个图书表模型示例 , 使用它来举例说明Q查询 .
from django. db import models
class Book ( models. Model) :
title = models. CharField( max_length= 25 )
author = models. CharField( max_length= 25 )
price = models. DecimalField( max_digits= 10 , decimal_places= 2 )
def __str__ ( self) :
return self. title
生成迁移文件并执行数据迁移 :
PS D: \MyDjango> python manage. py makemigrations
. . .
PS D: \MyDjango> python manage. py migrate
. . .
写入一些测试数据 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
Book. objects. create( title= 'Python' , author= 'aa' , price= 52.0 )
Book. objects. create( title= 'Linux' , author= 'bb' , price= 45.0 )
Book. objects. create( title= 'MySQL' , author= 'cc' , price= 40.0 )
过滤方法中可以提供多个参数作为查询条件 , 这个条件之间是AND关系 .
例如 , 查询书名为 'Python' , 作者是 'aa' 的书籍记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
query_set = Book. objects. filter ( title= 'Python' , author= 'aa' )
print ( query_set)
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ( ` index_book` . ` author` = 'aa' AND ` index_book` . ` title` = 'Python' )
LIMIT 21 ;
args= ( 'aa' , 'Python' )
查看ORM日志 , 可以得出结论 : 默认情况下 , Django ORM的查询是逻辑与 ( AND ) 连接的 .
Q查询允许使用逻辑或 ( OR ) 条件来构建更复杂的查询 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import Q
query_set = Book. objects. filter ( Q( title= 'Python' ) | Q( author= 'aa' ) )
print ( query_set)
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ( ` index_book` . ` title` = 'Python' OR ` index_book` . ` author` = 'aa' )
LIMIT 21 ;
args= ( 'Python' , 'aa' )
在这个例子中 , Q ( title = 'Python' ) 和 Q ( author = 'aa' ) 分别构建了两个查询条件 , 然后通过 | ( 逻辑或 ) 操作符将它们组合起来 .
这样 , Django ORM 就会返回所有满足任一条件的Book实例 .
Q查询允许使用逻辑非 ( NOT ) 条件来构建更复杂的查询 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import Q
query_set = Book. objects. filter ( ~ Q( title= 'Python' ) )
print ( query_set)
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ( NOT ( ` index_book` . ` title` = 'Python' ) AND NOT ( ` index_book` . ` author` = 'aa' ) )
LIMIT 21 ;
args= ( 'Python' , 'aa' )
Q查询允许混合使用逻辑操作符 ( 如 & , | , ~ ) 来构建复杂的查询条件 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import Q
query_set = Book. objects. filter ( ~ Q( title= 'Python' ) | ~ Q( author= 'aa' ) )
print ( query_set)
query_set = Book. objects. filter ( ~ Q( title= 'Python' ) & ~ Q( author= 'aa' ) )
print ( query_set)
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE NOT ( ` index_book` . ` title` = 'Python' )
LIMIT 21 ;
args= ( 'Python' , )
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ( NOT ( ` index_book` . ` title` = 'Python' ) OR NOT ( ` index_book` . ` author` = 'aa' ) )
LIMIT 21 ;
args= ( 'Python' , 'aa' )
F查询用于在更新操作中引用字段的当前值 .
导入方式 : from django . db . models import F
这在需要根据字段的当前值来更新它时非常有用 .
比如 , 想将一个字段的值增加或减少一定的量 , 而不是直接设置为一个固定的值 .
Django支持多种操作符与F ( ) 表达式一起使用 , 包括但不限于加法 ( + ) , 减法 ( - ) , 乘法 ( * ) , 除法 ( / ) , 模除 ( % ) , 幂运算 ( * * ) . . .
示例 : 为Book模型的price字段的价格增加 10 % .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import F
price_tup = Book. objects. values_list( 'price' , flat= True )
print ( price_tup)
res = Book. objects. all ( ) . update( price= F( 'price' ) * 1.1 )
print ( res)
price_tup = Book. objects. values_list( 'price' , flat= True )
print ( price_tup)
F对象允许在查询中动态地引用字段的值 .
这意味着可以在查询中直接使用字段名 ( 通过F对象封装 ) 来引用该字段在数据库中的当前值 .
( 0.000 ) SELECT ` index_book` . ` price` FROM ` index_book` LIMIT 21 ; args= ( )
( 0.000 ) UPDATE ` index_book` SET ` price` = ( ` index_book` . ` price` * 1.1 e0) ; args= ( 1.1 , )
( 0.000 ) SELECT ` index_book` . ` price` FROM ` index_book` LIMIT 21 ; args= ( )
在这个例子中 , F ( 'price' ) 引用了Book模型中每个实例的price字段的当前值 , 并将其乘以 1.1 来更新该字段 .
Book . objects . all ( ) . update ( price = F ( 'price' ) * 1.1 ) 可以省略all ( ) 方法 ,
直接写为 : Book . objects . update ( price = F ( 'price' ) * 1.1 )
这行代码的效率和效果与原始代码完全相同 , 但更加简洁 .
这是Django ORM设计的一个便利之处 , 允许开发者以更直观和高效的方式与数据库交互 .
F ( ) 查询表达式可以与Django ORM中的查找操作符 ( 如 : __lt、__lte、__gt、__gte 等 ) 结合使用 .
注意 : 这些查找操作符通常用于filter ( ) , exclude ( ) 等方法中来过滤查询集 , 而不是直接用于update ( ) 方法中的赋值表达式 .
示例 : 为价格大于 50 的书籍打 9 折 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import F
price_tup = Book. objects. values_list( 'price' , flat= True )
print ( price_tup)
Book. objects. filter ( price__gt= 50 ) . update( price= F( 'price' ) * 0.9 )
price_tup = Book. objects. values_list( 'price' , flat= True )
print ( price_tup)
( 0.000 ) SELECT ` index_book` . ` price` FROM ` index_book` LIMIT 21 ; args= ( )
( 0.000 ) UPDATE ` index_book` SET ` price` = ( ` index_book` . ` price` * 0.9 e0) WHERE ` index_book` . ` price` > 50 ;
args= ( 0.9 , Decimal ( '50' ) )
( 0.016 ) SELECT ` index_book` . ` price` FROM ` index_book` LIMIT 21 ; args= ( )
字段表达式允许在查询时构建复杂的字段值 , 这些值可以基于模型字段的当前值 , 常量值 , 函数调用等 .
在Django ORM中 , Concat函数和Value函数是用于数据库查询时构造复杂字段表达式的工具 .
Concat函数 : 用于将多个字段值或常量值连接 ( 拼接 ) 成一个字符串 . 这在需要将多个字段的值合并为一个单一字段的查询结果时非常有用 .
Concat函数可以接受多个参数 , 这些参数可以是字段的引用 ( 使用F ( ) 表达式 ) , 也可以是常量值 ( 使用Value ( ) 函数 ) .
导入方式 : from django . db . models . functions import Concat
Value函数 : 用于在查询中插入一个常量值 . 这个值可以是任何类型 , 但在与Concat函数一起使用时 , 它通常是一个字符串 .
Value函数使得在数据库查询中直接包含静态值成为可能 .
导入方式 : from django . db . models import Value
示例 : 为所有的书籍名称添加一个后缀 , ( 例如 , 格式为 '书名-v1' ) , 可以这样做 :
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import F, Value
from django. db. models. functions import Concat
title_tup = Book. objects. values_list( 'title' , flat= True )
print ( title_tup)
books = Book. objects. update( title= Concat( F( 'title' ) , Value( '-v1' ) ) )
title_tup = Book. objects. values_list( 'title' , flat= True )
print ( title_tup)
在这个例子中 , Concat函数将title字段 , 一个常量值 '-v1' 连接起来 .
( 0.000 ) SELECT ` index_book` . ` title` FROM ` index_book` LIMIT 21 ; args= ( )
( 0.016 ) UPDATE ` index_book` SET ` title` = CONCAT_WS( '' , ` index_book` . ` title` , '-v1' ) ; args= ( '-v1' , )
( 0.000 ) SELECT ` index_book` . ` title` FROM ` index_book` LIMIT 21 ; args= ( )
Replace函数 : 是一个数据库函数封装 , 用于在查询集 ( QuerySet ) 的更新或注释 ( annotation ) 操作中执行字符串替换 .
Replace函数通常接受三个参数 : 原始字符串 , 要查找的子字符串 , 以及用于替换的子字符 .
导入方式 : from django . db . models . functions import Replace
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
from django. db. models import F, Value, Func
from django. db. models. functions import Replace
Book. objects. update( title= Replace( F( 'title' ) , Value( '-v1' ) , Value( '' ) ) )
title_tup = Book. objects. values_list( 'title' , flat= True )
print ( title_tup)
( 0.000 ) UPDATE ` index_book` SET ` title` = REPLACE ( ` index_book` . ` title` , '-v1' , '' ) ; args= ( '-v1' , '' )
( 0.000 ) SELECT ` index_book` . ` title` FROM ` index_book` LIMIT 21 ; args= ( )
值得一提的是从Django 2.2 开始 , Django ORM引入了对更多数据库函数的支持 .
在Django ORM中 , Django的查询集API使用提供了union , intersection和difference这样的SQL集合操作 .
union ( 并集 ) 操作 : 用于合并多个查询集 , 并自动去除重复的行 . 即 , 重复的行只留下一个结果 .
intersection ( 交集 ) 操作 : 返回多个查询集的交集 . 即 , 只留下重复的行 .
difference ( 差集 ) 操作 : 找出存在于第一个查询集中但不在第二个查询集中的记录 .
Django ORM的intersection方法和difference ( ) 方法在目前MySQL ( 9.0 ) 上不受支持,
django . db . utils . NotSupportedError : intersection is not supported on this database backend .
UNION操作允许合并两个或多个查询集 ( QuerySet ) 的结果 , 并自动去除重复的行 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
query_set1 = Book. objects. filter ( title= 'Python' )
print ( query_set1)
query_set2 = Book. objects. filter ( title= 'Linux' )
print ( query_set2)
combined_books = query_set1. union( query_set2)
print ( combined_books)
( 0.015 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` title` = 'Python'
LIMIT 21 ;
args= ( 'Python' , )
( 0.000 )
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` title` = 'Linux'
LIMIT 21 ;
args= ( 'Linux' , )
( 0.000 )
(
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` title` = 'Python'
)
UNION
(
SELECT ` index_book` . ` id` , ` index_book` . ` title` , ` index_book` . ` author` , ` index_book` . ` price` FROM ` index_book` WHERE ` index_book` . ` title` = 'Linux'
)
LIMIT 21 ;
args= ( 'Python' , 'Linux' )
INTERSECT ( 交集 ) 操作 : 返回多个查询集的交集 . 即 , 只留下重复的行 .
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.sqlite3' ,
'NAME' : BASE_DIR / 'db.sqlite3' ,
}
}
PS D: \MyDjango> python manage. py makemigrations
. . .
PS D: \MyDjango> python manage. py migrate
. . .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
Book. objects. create( title= 'Python' , author= 'aa' , price= 52.0 )
Book. objects. create( title= 'Linux' , author= 'bb' , price= 45.0 )
Book. objects. create( title= 'MySQL' , author= 'cc' , price= 40.0 )
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
query_set1 = Book. objects. all ( )
print ( query_set1)
query_set2 = Book. objects. filter ( title= 'Linux' )
print ( query_set2)
intersection_books = query_set1. intersection( query_set2)
print ( intersection_books)
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
LIMIT 21 ;
args= ( )
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
WHERE "index_book" . "title" = 'Linux'
LIMIT 21 ;
args= ( 'Linux' , )
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
INTERSECT
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
WHERE "index_book" . "title" = 'Linux'
LIMIT 21 ;
args= ( 'Linux' , )
difference ( 差集 ) 操作 : 找出存在于第一个查询集中但不在第二个查询集中的记录 .
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
query_set1 = Book. objects. all ( )
print ( query_set1)
query_set2 = Book. objects. filter ( title= 'Linux' )
print ( query_set2)
difference_books = query_set1. difference( query_set2)
print ( difference_books)
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
LIMIT 21 ;
args= ( )
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
WHERE "index_book" . "title" = 'Linux'
LIMIT 21 ;
args= ( 'Linux' , )
( 0.000 )
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
EXCEPT
SELECT "index_book" . "id" , "index_book" . "title" , "index_book" . "author" , "index_book" . "price"
FROM "index_book"
WHERE "index_book" . "title" = 'Linux'
LIMIT 21 ;
args= ( 'Linux' , )
在MySQL中,由于ORM框架是构建在SQL之上的 , 而MySQL本身不直接支持INTERSECT和EXCEPT操作符 ,
因此在使用这些ORM框架时也无法直接使用intersection和difference方法 .
既然无法在数据库层面实现 , 那就在Python层面实现 .
以下是一个具体的实现步骤 :
* 1. 获取模型的ID值 .
首先 , 需要分别执行两个查询来获取两个不同集合的ID值 . 这些ID值将代表您想要进行交集或差集操作的两组数据 .
ids_from_a = ModelA. objects. filter ( some_condition= True ) . values_list( 'id' , flat= True )
ids_from_b = ModelB. objects. filter ( another_condition= True ) . values_list( 'id' , flat= True )
* 2. 使用Python集合进行交集或差集操作 .
接下来 , 将这两个查询结果转换为Python的集合 , 并使用集合的交集 ( & ) 或差集 ( - ) 操作符 ( 或对应的方法 ) 来获取您需要的ID集合 .
ids_intersection = set ( ids_from_a) & set ( ids_from_b)
ids_difference = set ( ids_from_a) - set ( ids_from_b)
* 3. 使用过滤后的ID集合查询数据 .
最后 , 使用过滤后的ID集合 ( ids_intersection或ids_difference ) 来查询原始模型 , 获取您需要的完整数据记录 .
models_with_intersection = ModelA. objects. filter ( id__in= ids_intersection)
models_with_difference = ModelA. objects. filter ( id__in= ids_difference)
注意事项 : 当处理大量数据时 , 将ID列表转换为集合可能会消耗大量内存 .
import os
if __name__ = = "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index . models import Book
query_set1 = Book. objects. all ( )
print ( query_set1)
query_set1_id = query_set1. values_list( 'id' , flat= True )
set1_id = set ( query_set1_id)
print ( query_set1_id, set1_id)
query_set2 = Book. objects. filter( title= 'Linux' )
print ( query_set2)
query_set2_id = query_set2. values_list( 'id' , flat= True )
set2_id = set ( query_set2_id)
print ( query_set2_id, set2_id)
intersection_id = set1_id. intersection( set2_id)
print ( intersection_id)
intersection_books = Book. objects. filter( id__in= intersection_id)
print ( intersection_books)
import os
if __name__ == "__main__" :
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
import django
django. setup( )
from index. models import Book
query_set1 = Book. objects. all ( )
print ( query_set1)
query_set1_id = query_set1. values_list( 'id' , flat= True )
set1_id = set ( query_set1_id)
print ( query_set1_id, set1_id)
query_set2 = Book. objects. filter ( title= 'Linux' )
print ( query_set2)
query_set2_id = query_set2. values_list( 'id' , flat= True )
set2_id = set ( query_set2_id)
print ( query_set2_id, set2_id)
intersection_id = set1_id. difference( set2_id)
print ( intersection_id)
intersection_books = Book. objects. filter ( id__in= intersection_id)
print ( intersection_books)
可以使用连表 ( JOIN ) 操作或子查询等来间接实现集合功能 , 连表操作通常用于将来自不同表但具有相关性的数据行组合在一起 .
然而 , 通过巧妙地构造查询 , 可以利用连表来模拟集合的并集 , 交集或差集 .
SELECT id, title FROM index_book
UNION
SELECT id, title FROM index_book;
SELECT A. id, . . .
FROM index_book as A
INNER JOIN index_book as B
ON A. id = B. id
WHERE A. some_condition = 'true'
AND B. another_condition = 'true' ;
SELECT A. id, . . .
FROM index_book AS A
WHERE NOT EXISTS (
SELECT 1
FROM index_book AS B
WHERE B. some_condition = 'true'
AND A. id = B. id
) ;
了解这些之后 , 可以使用别的思路来模拟集合的并集 , 交集或差集操作 .









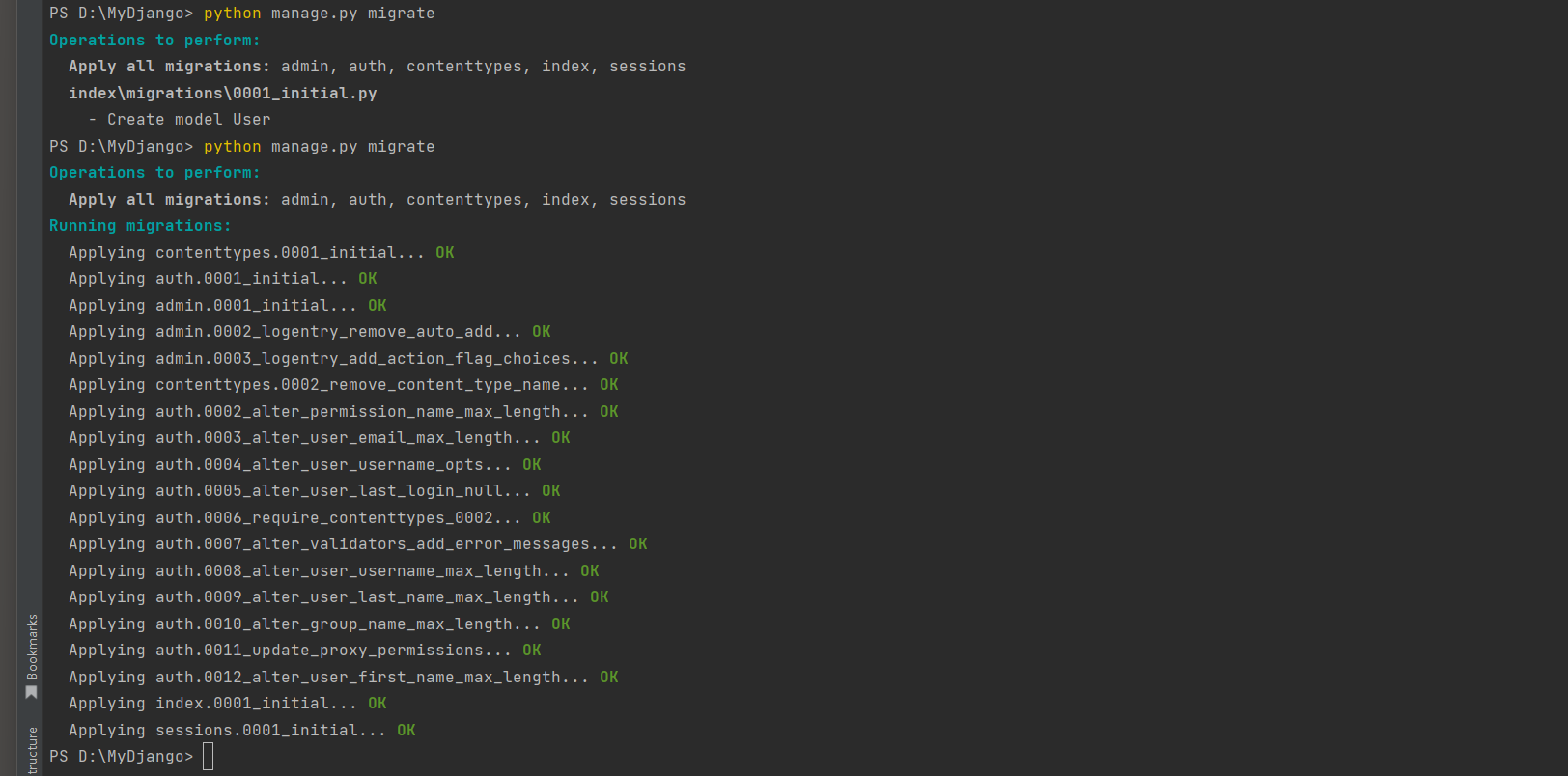
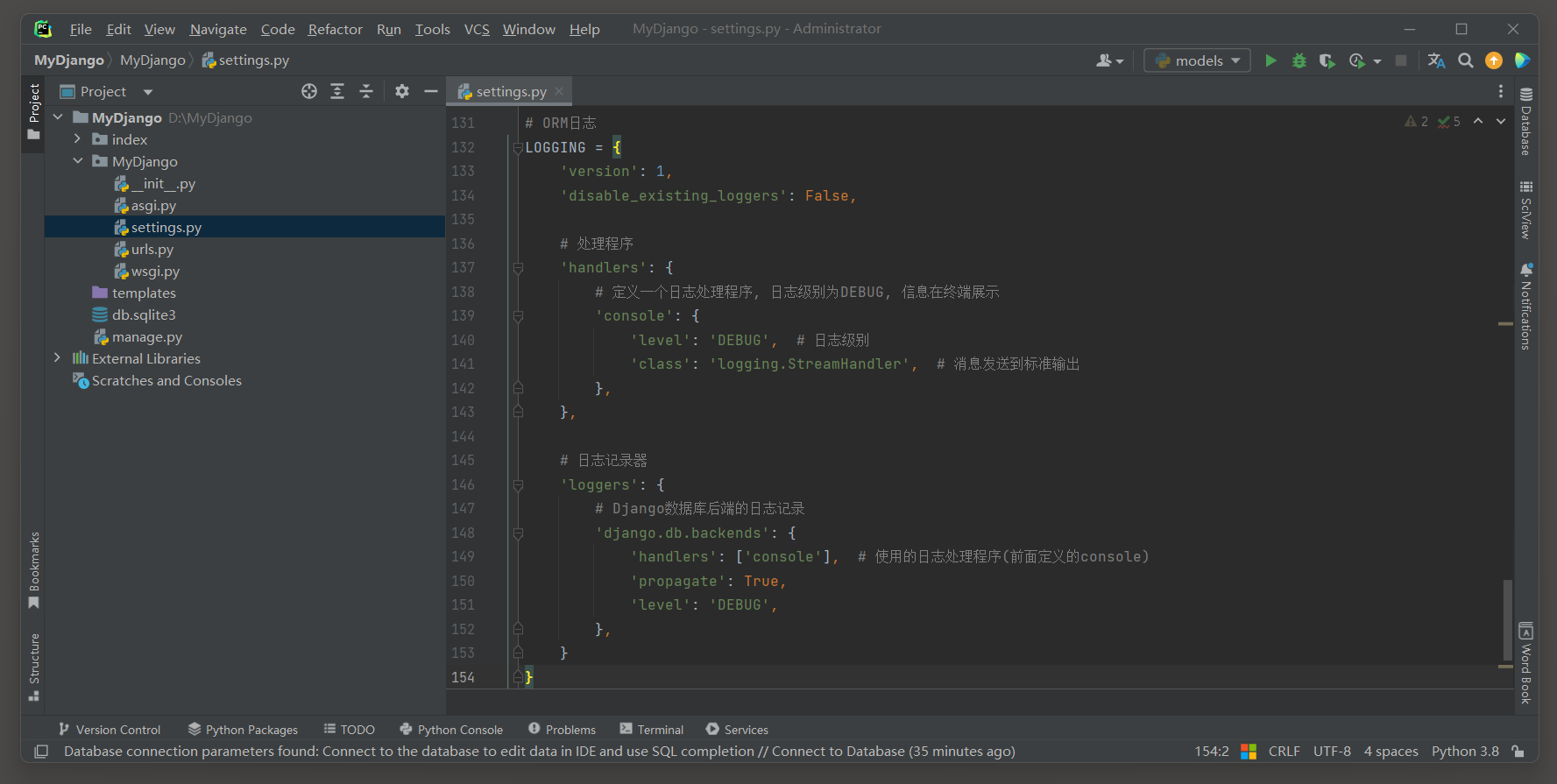
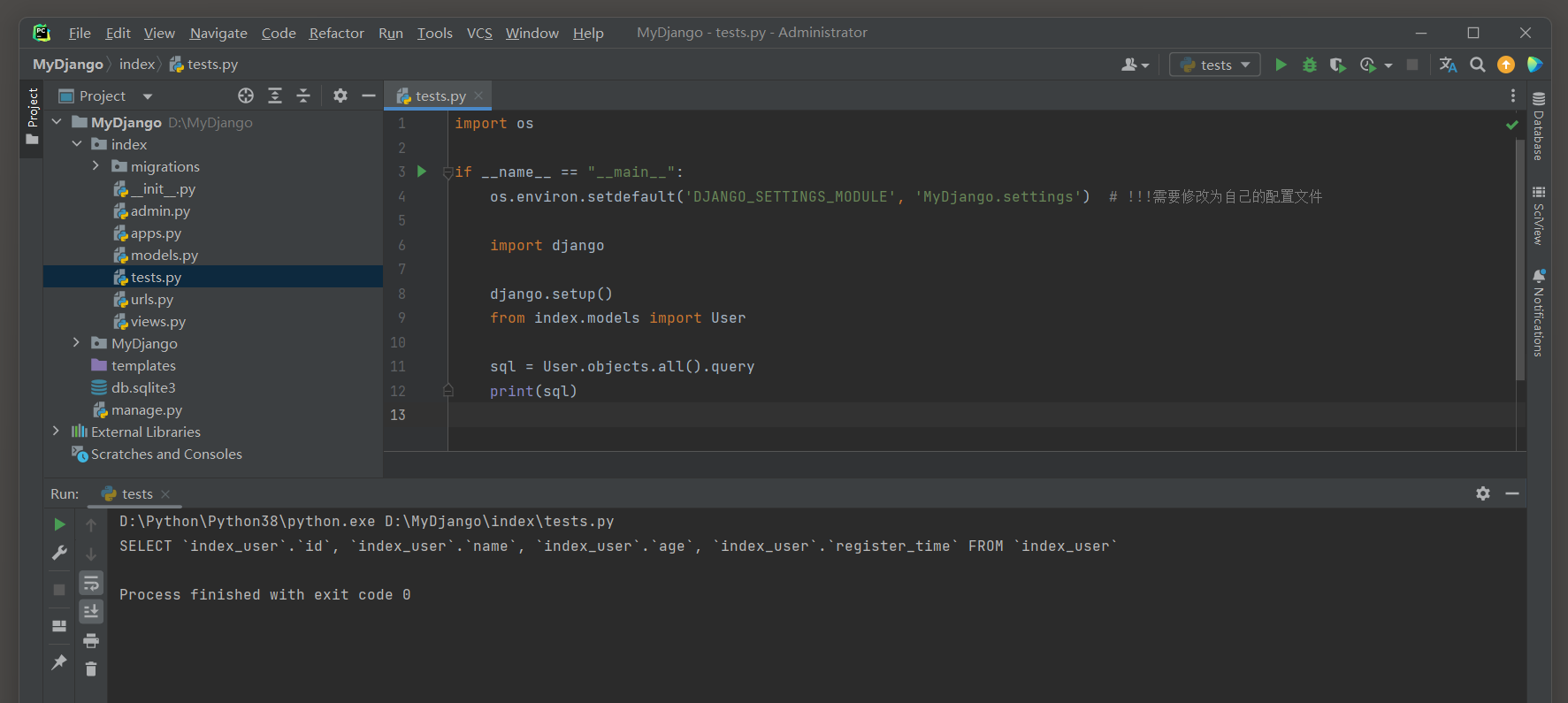

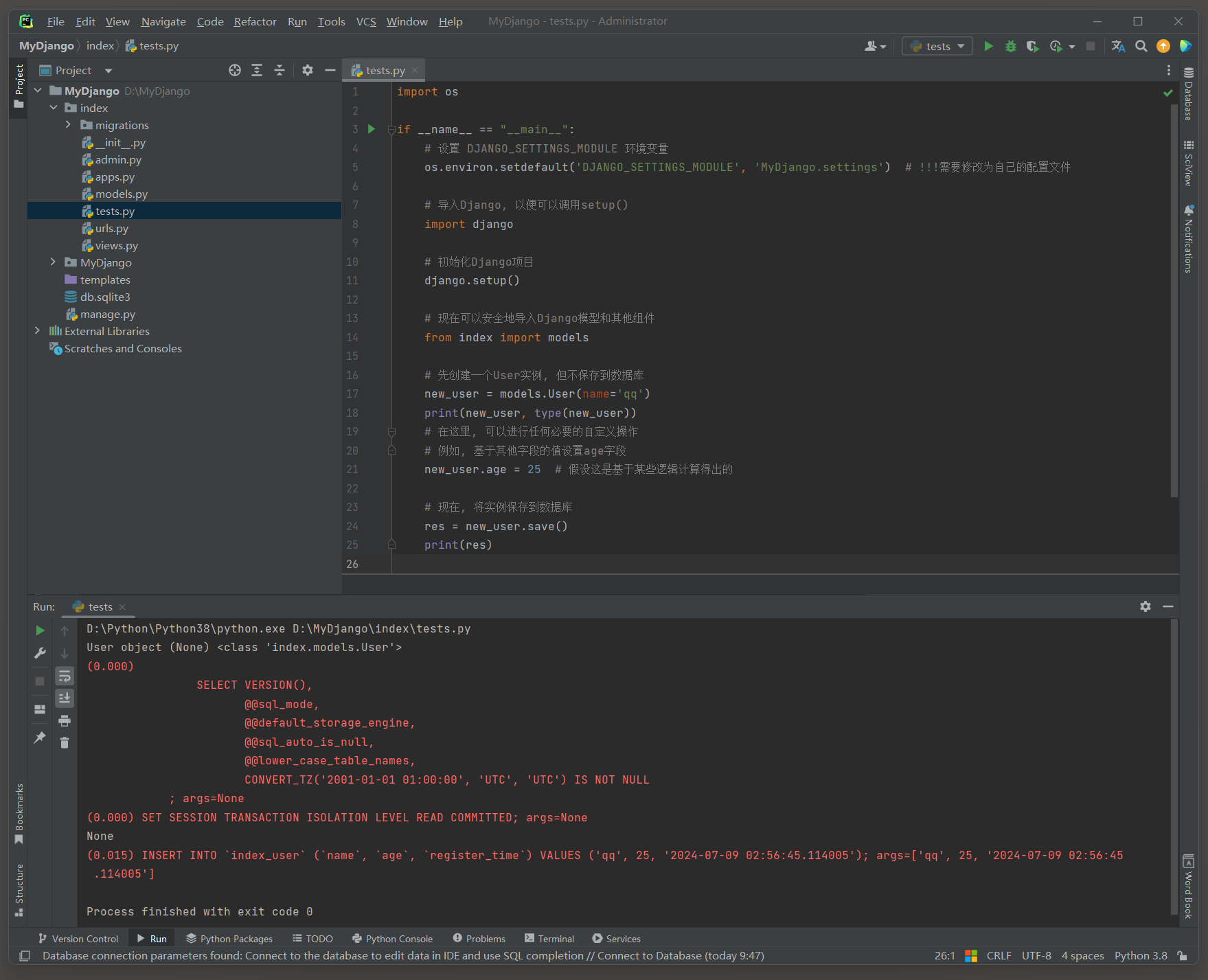
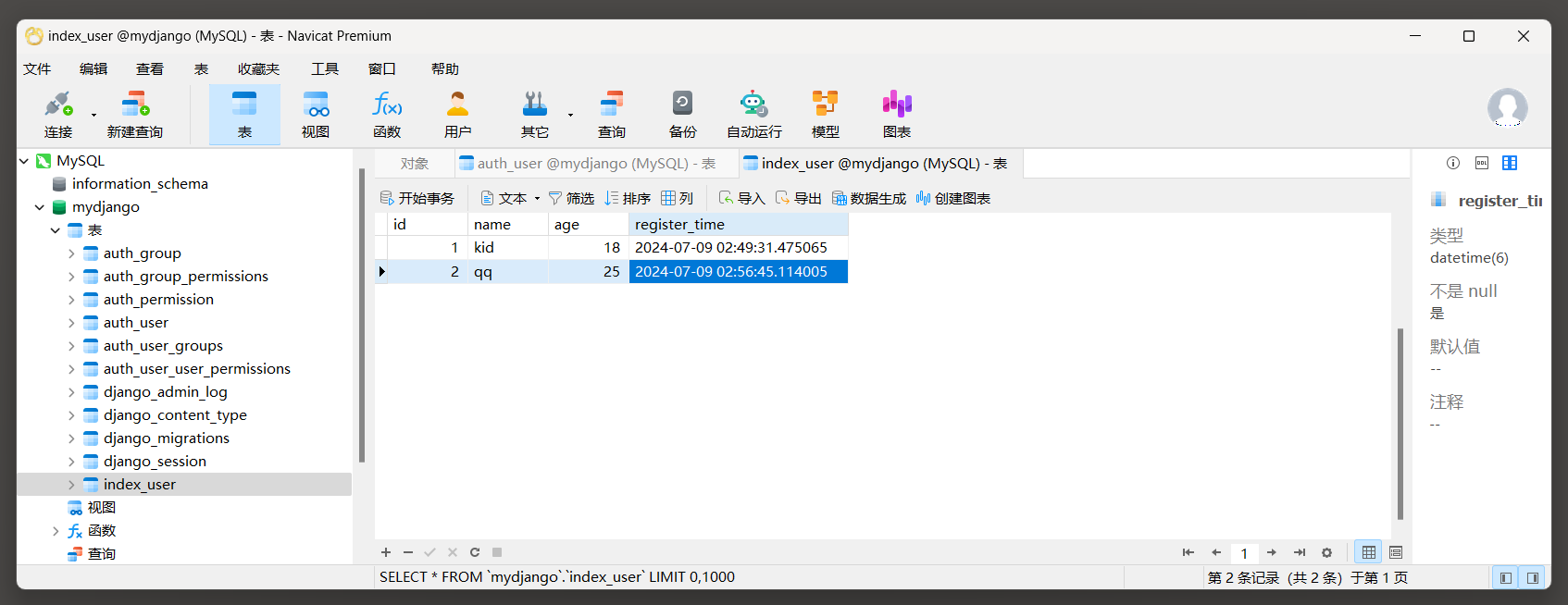
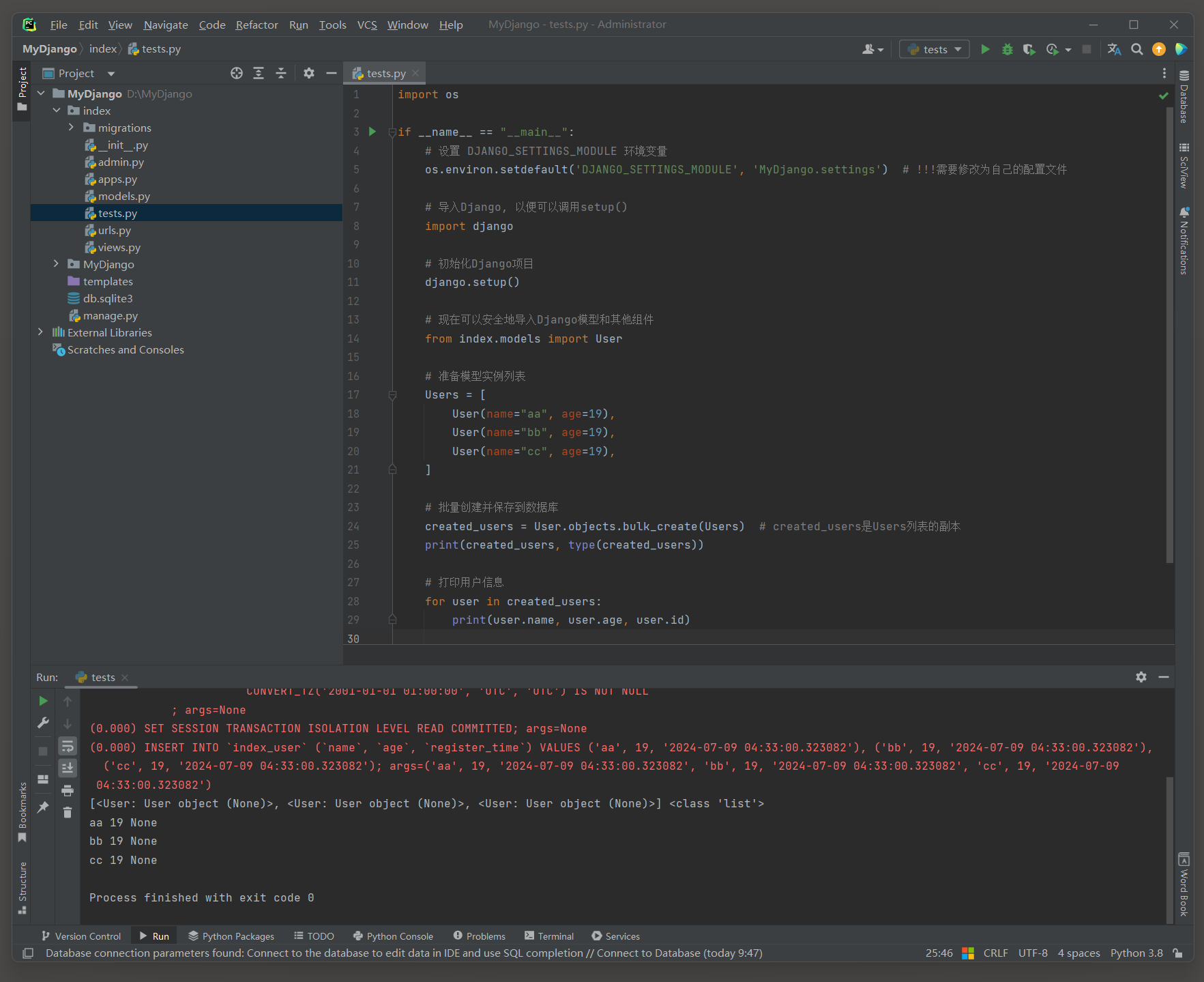
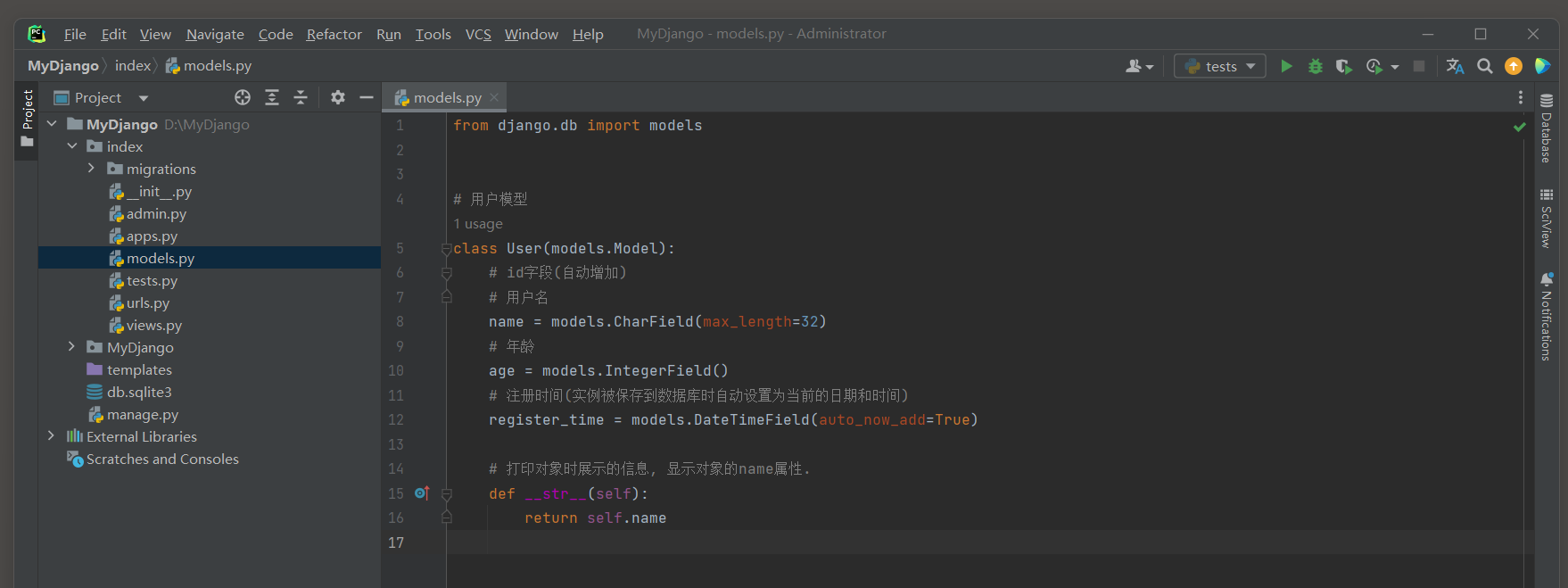
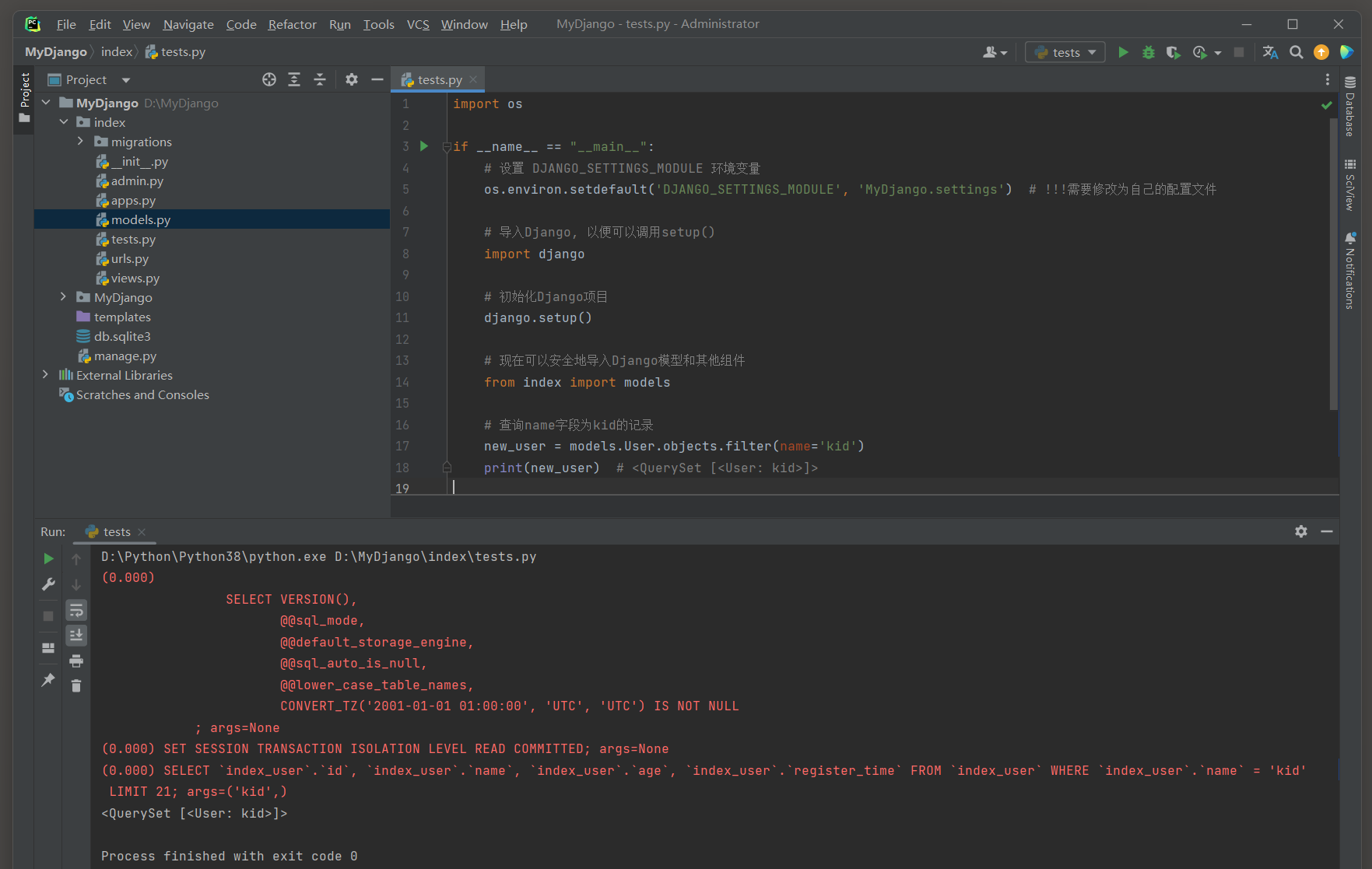
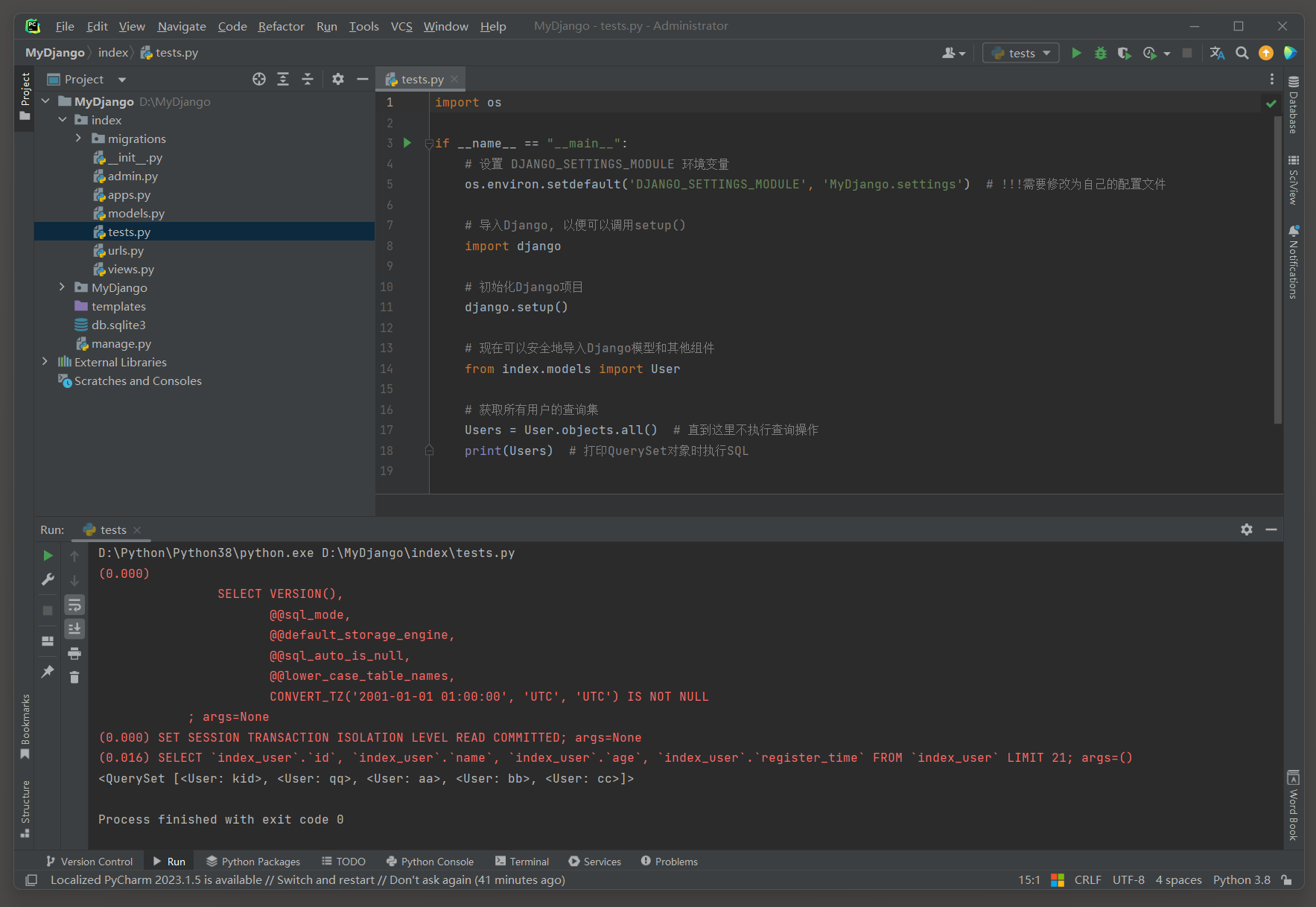
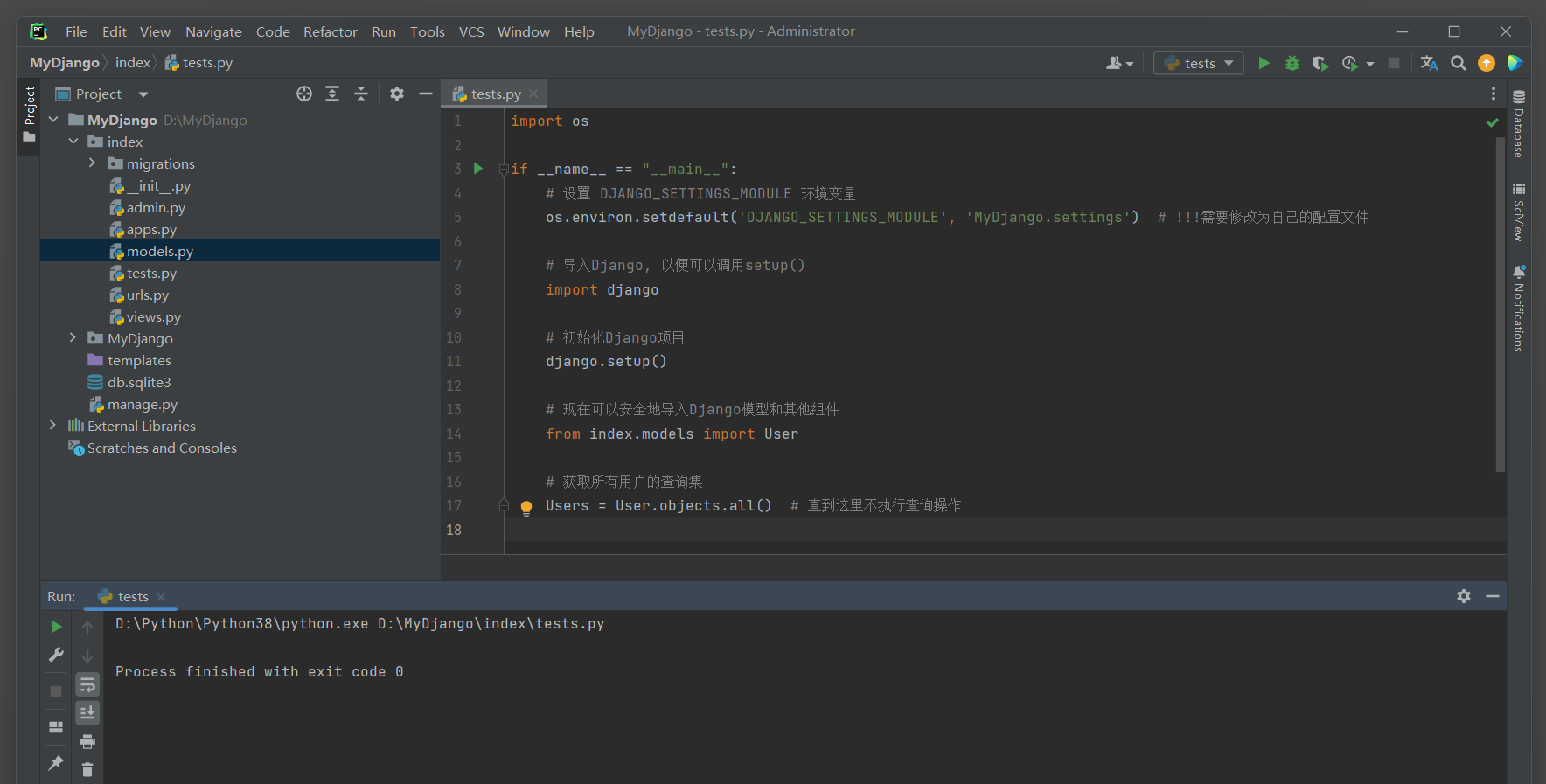
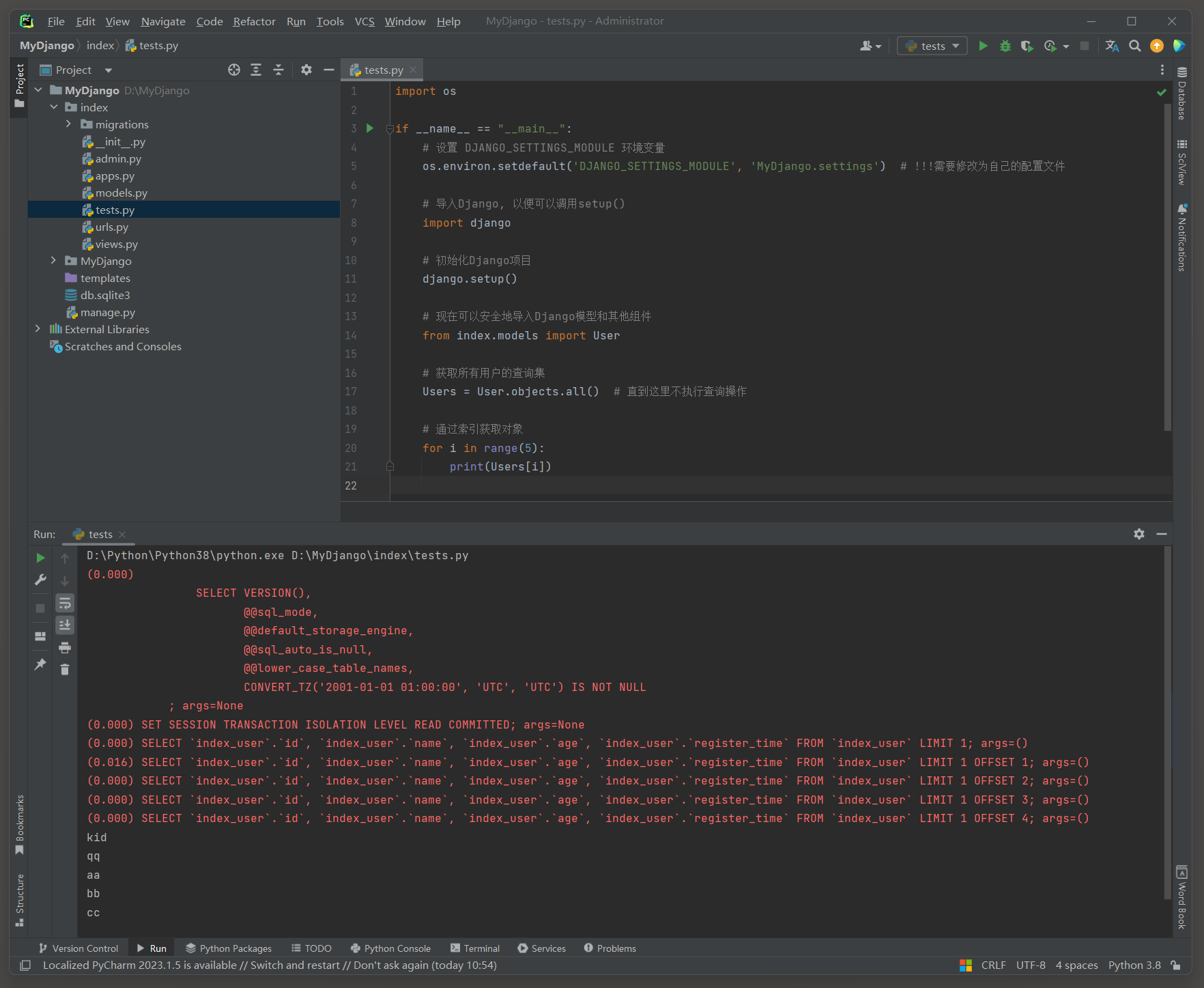
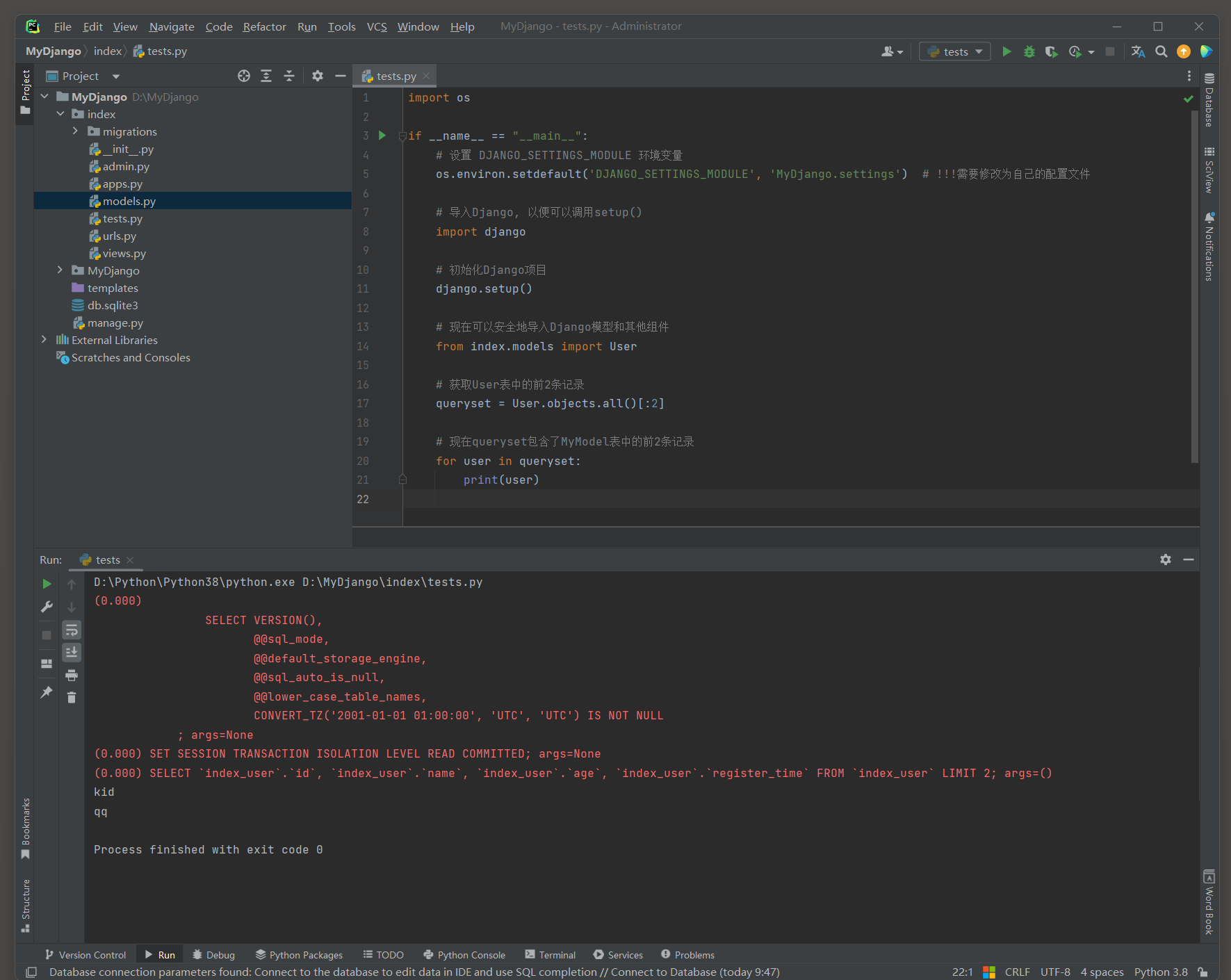
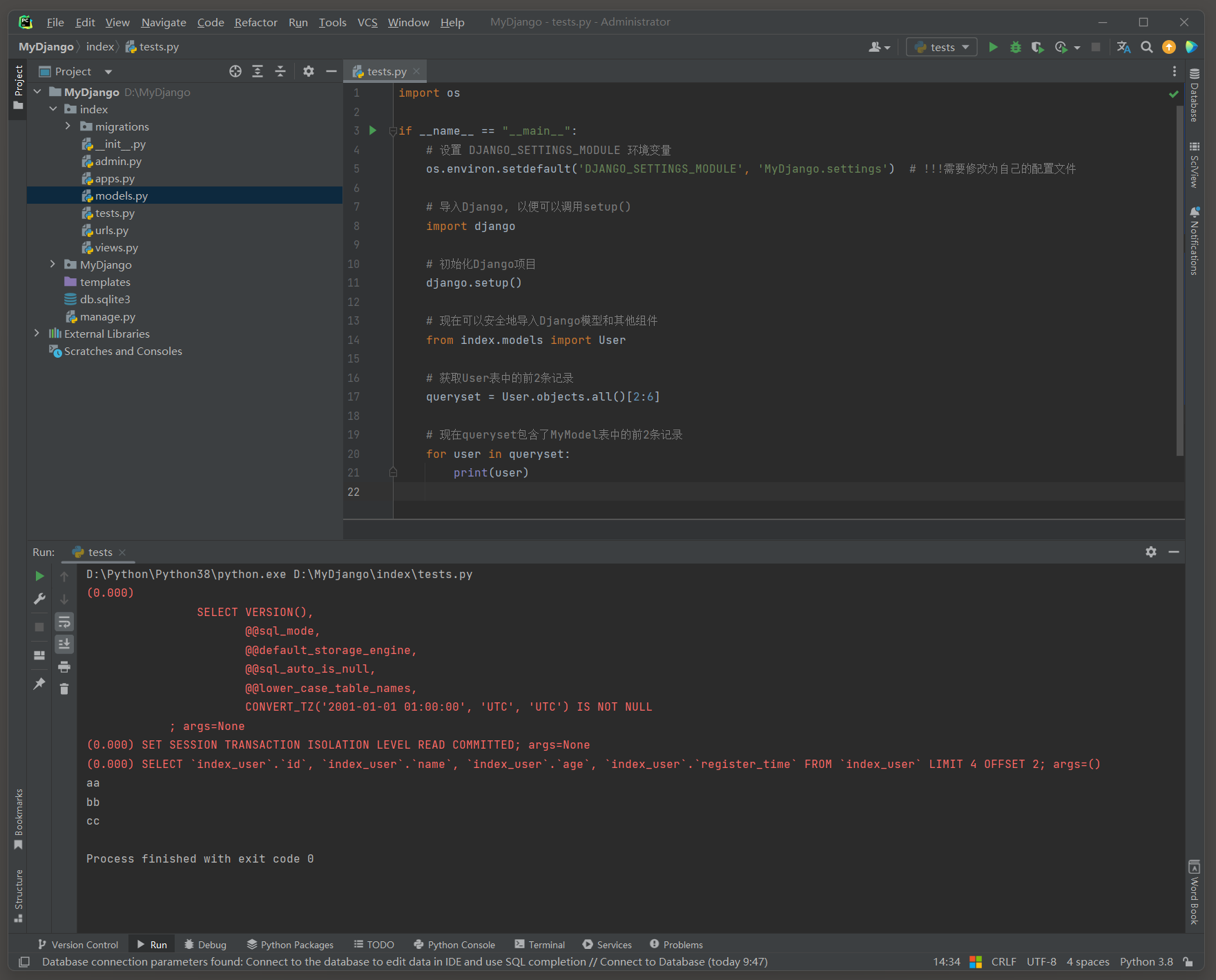
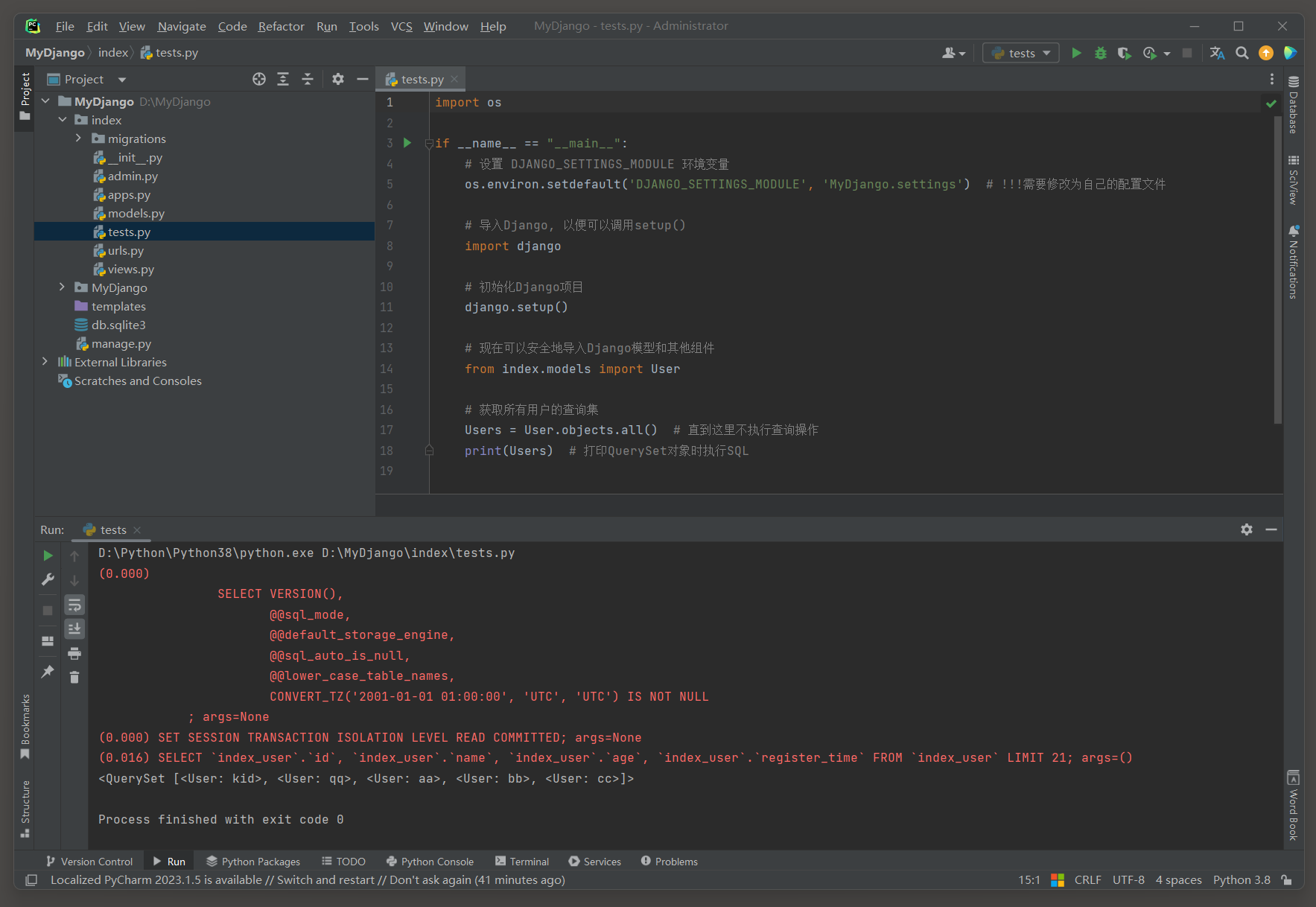
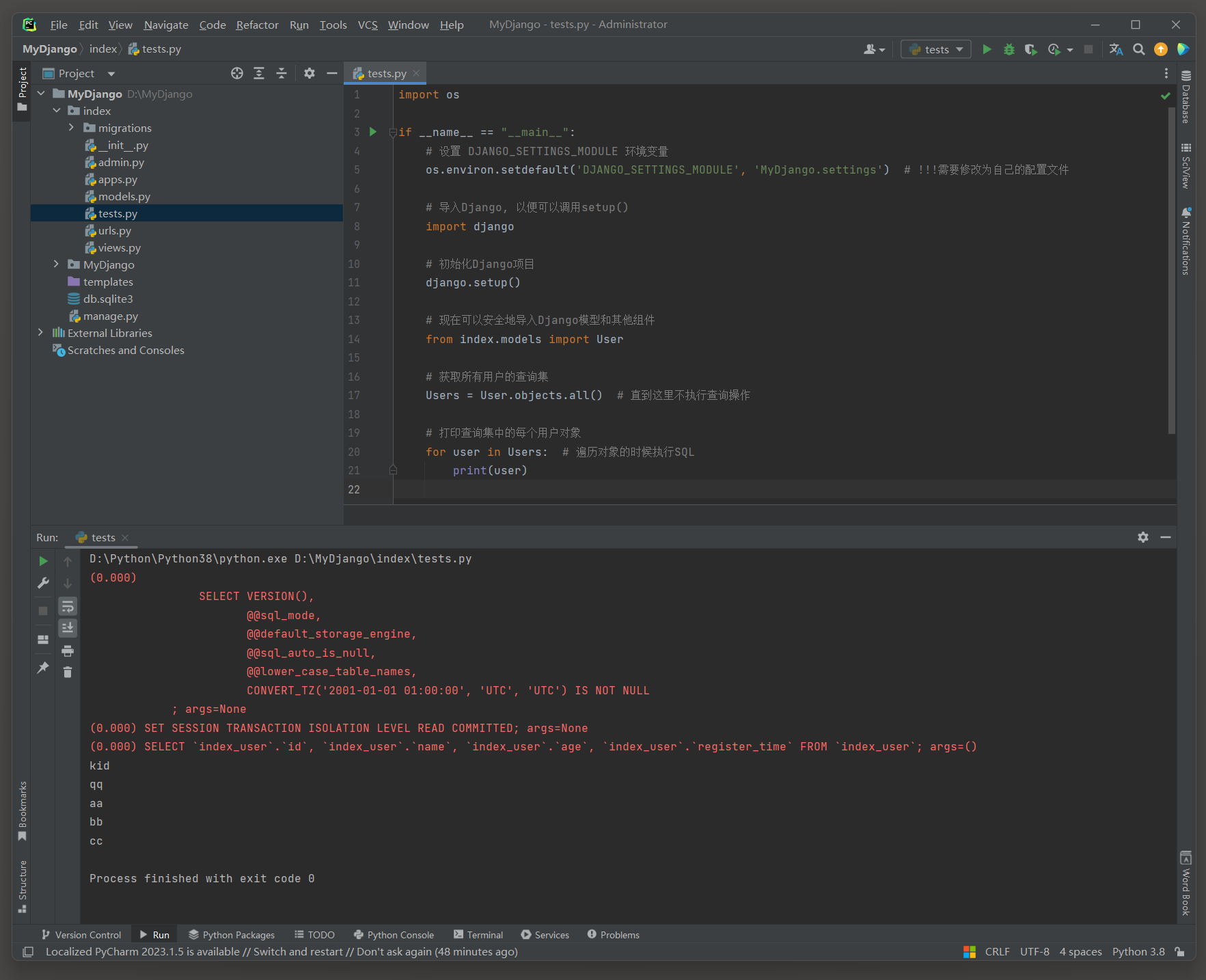
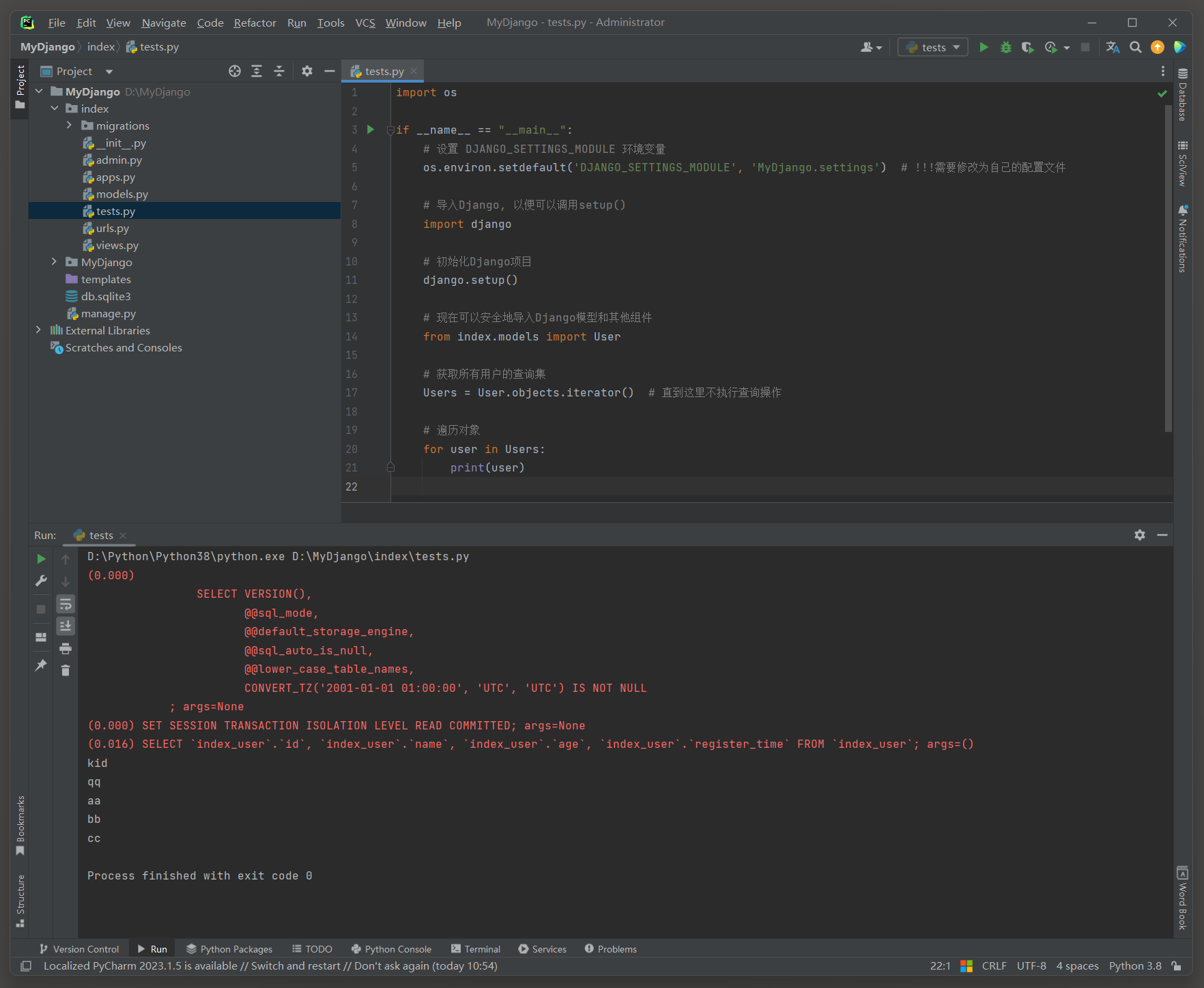
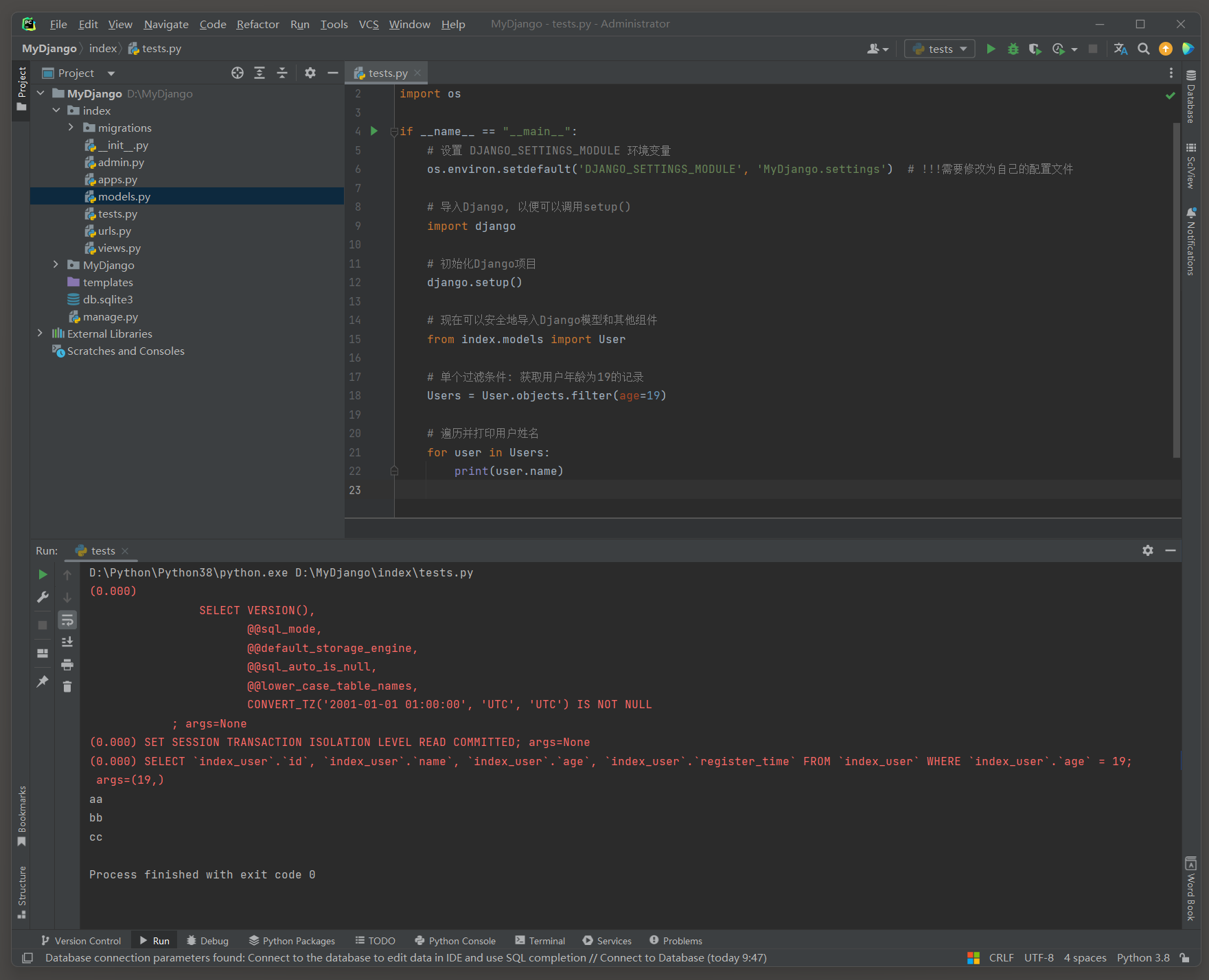
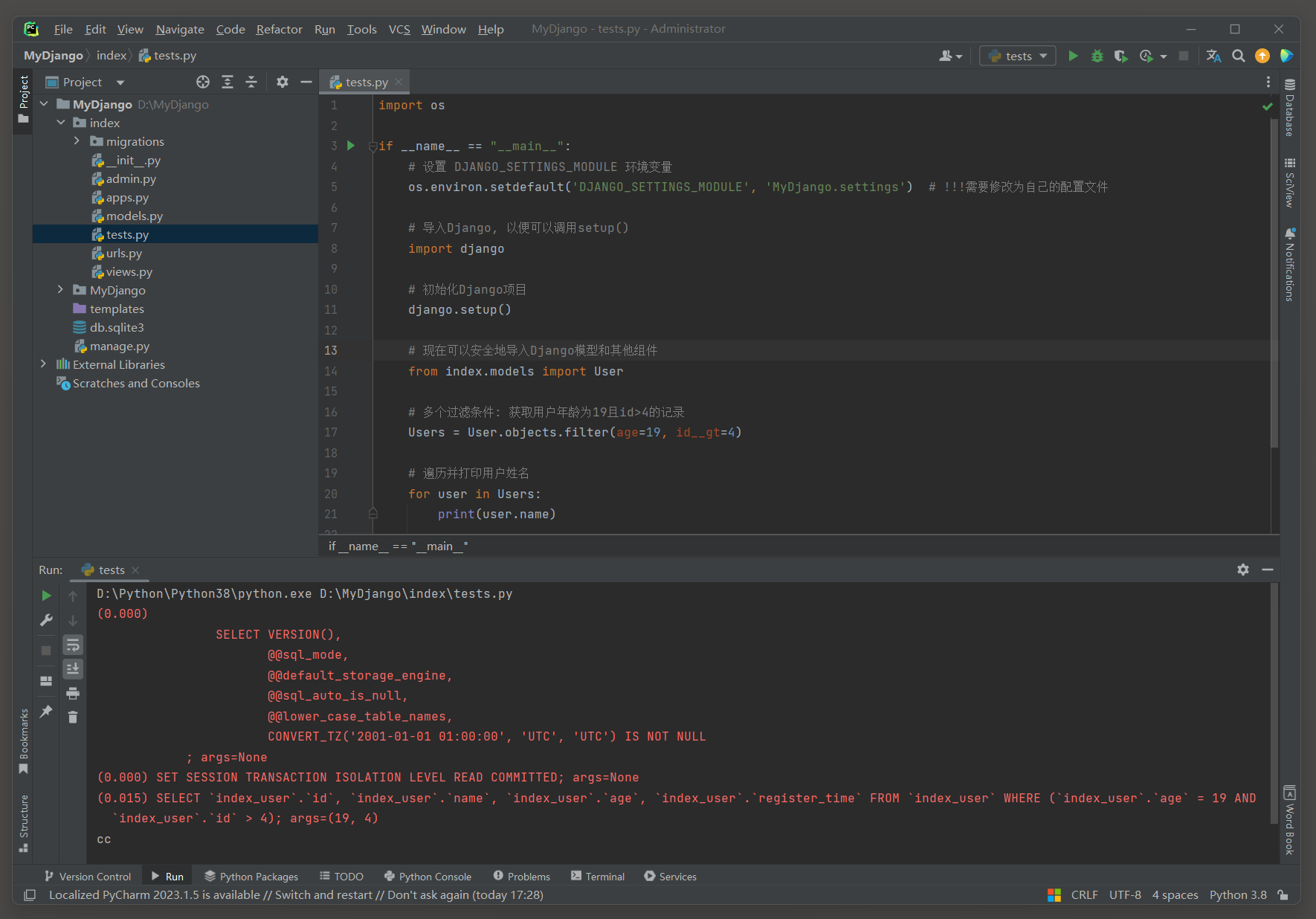
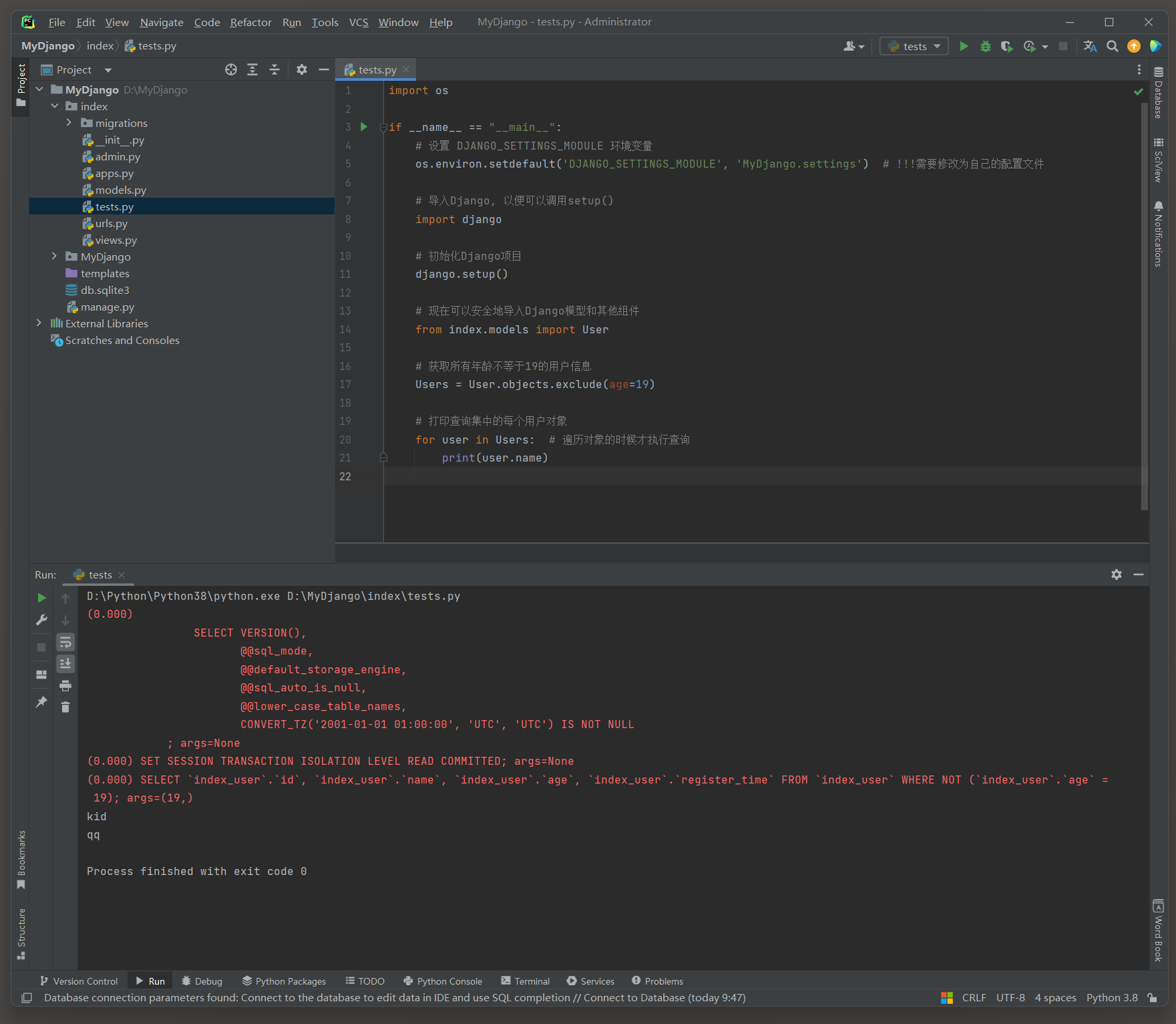
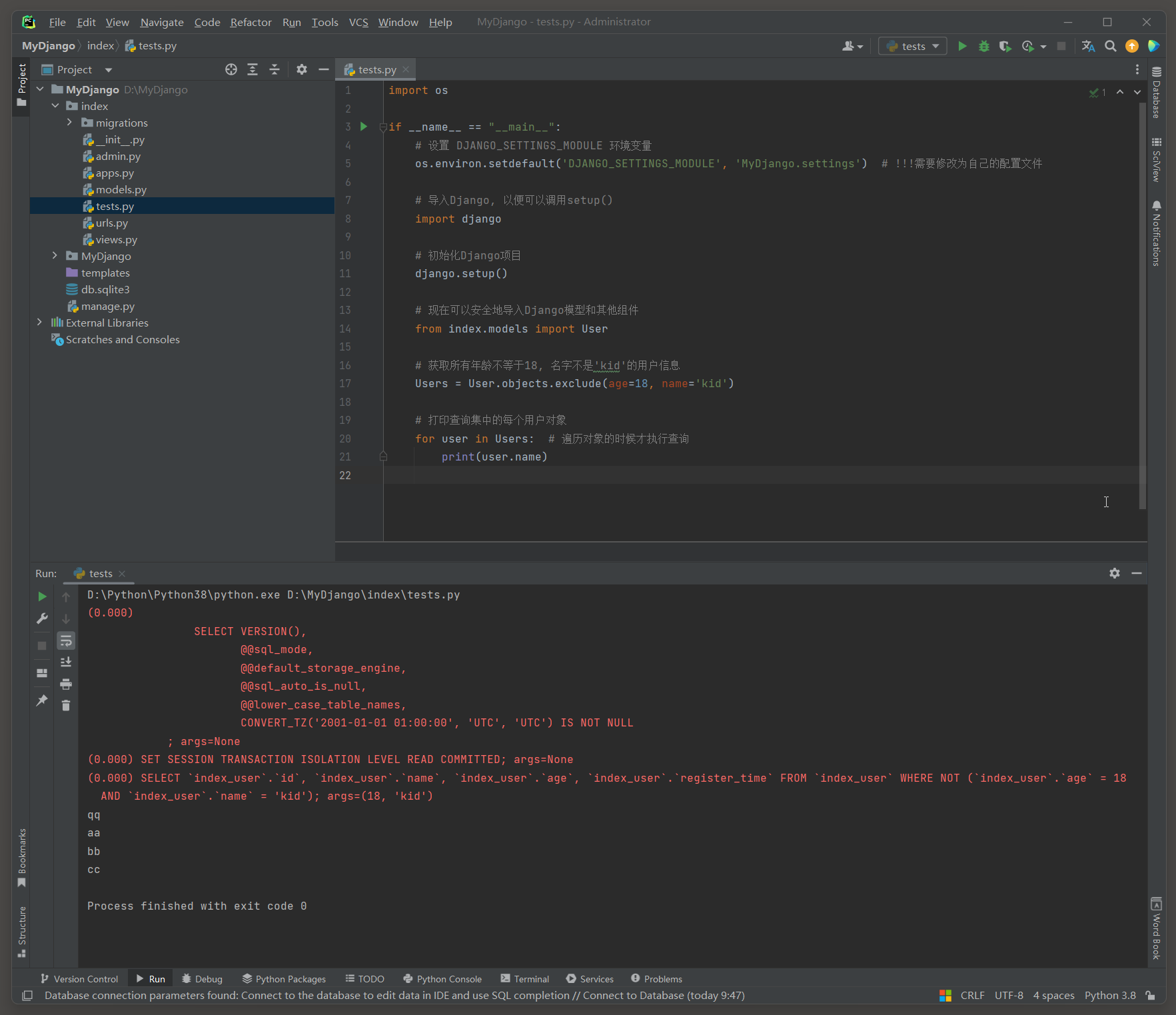
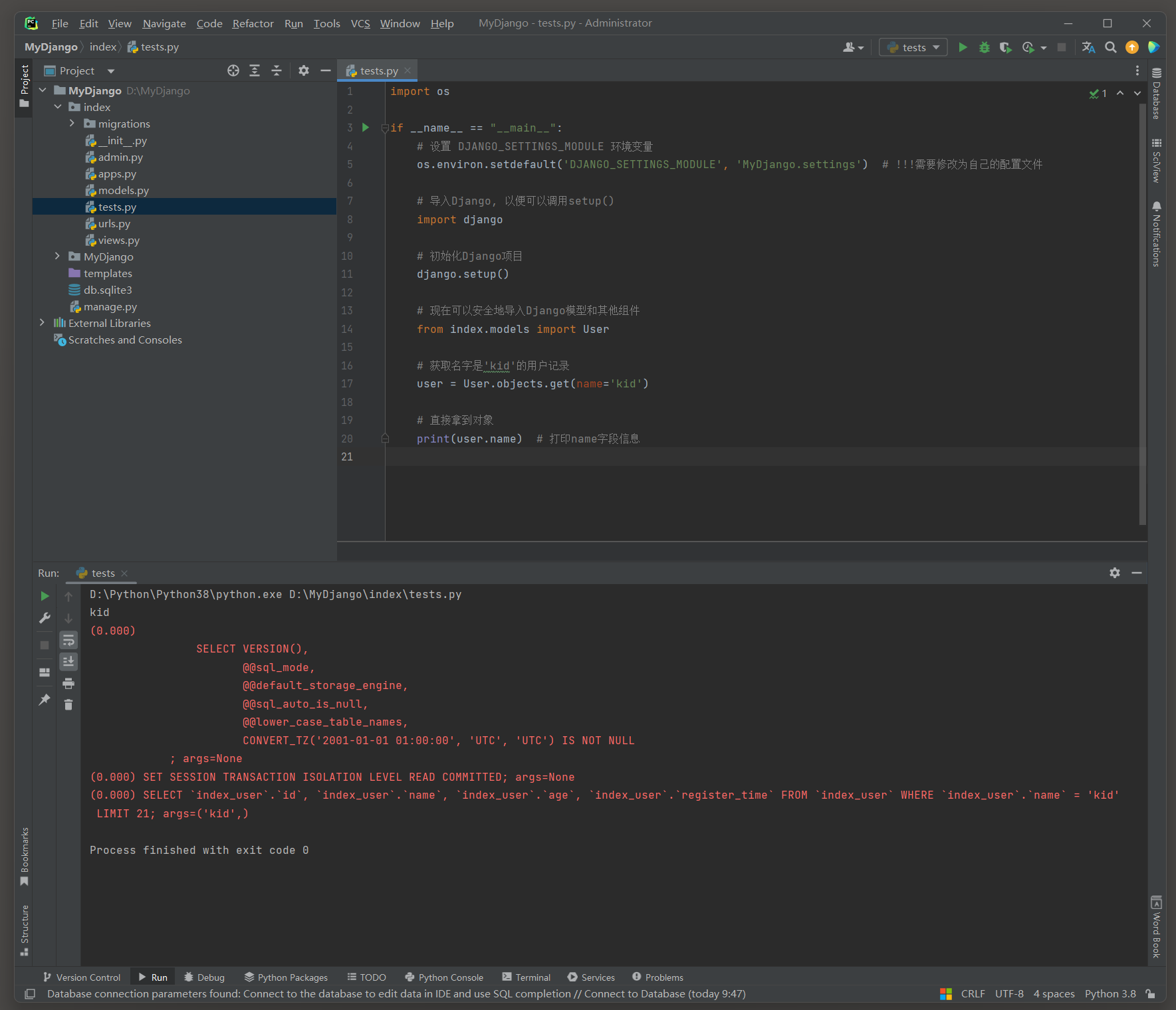
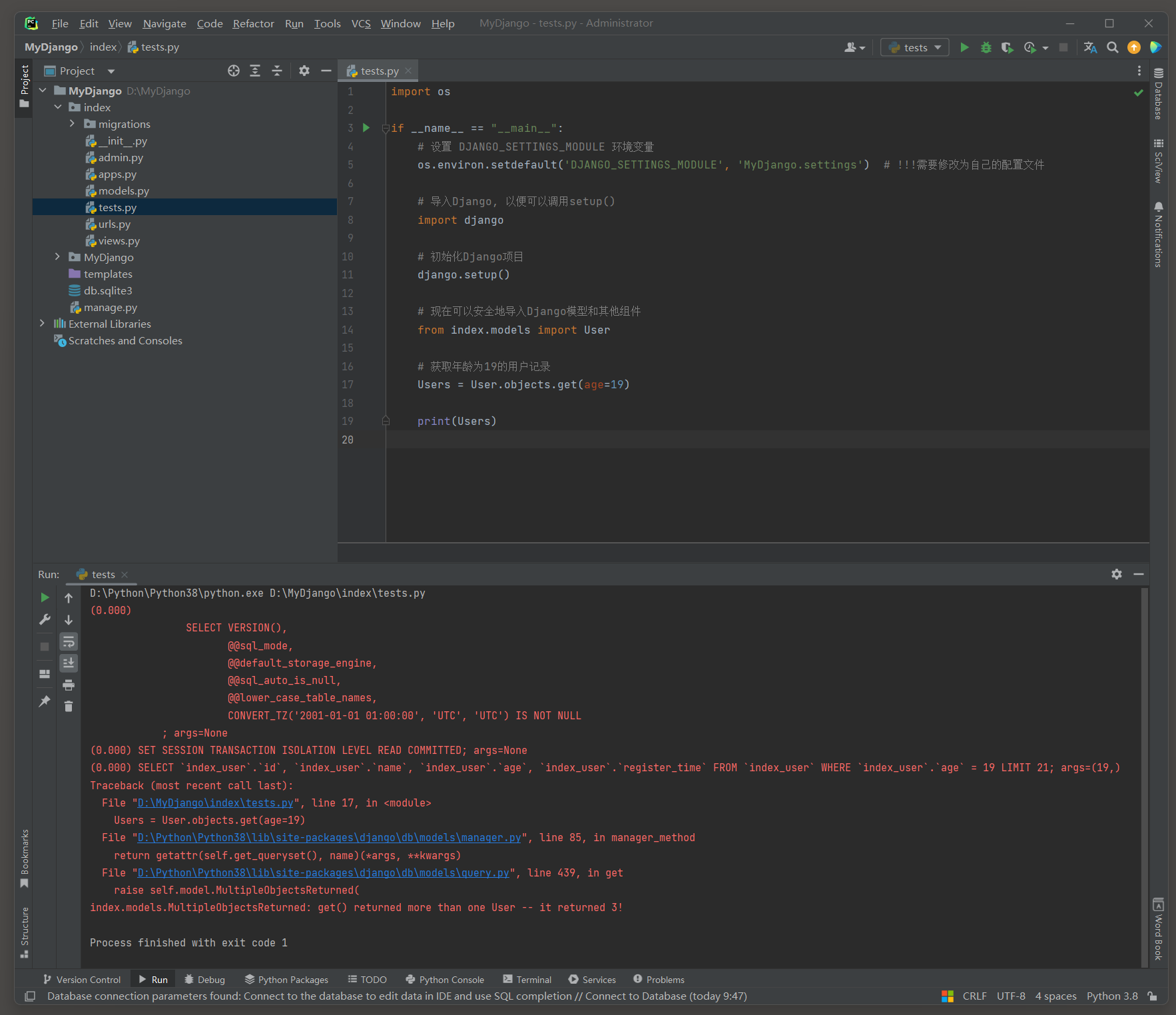
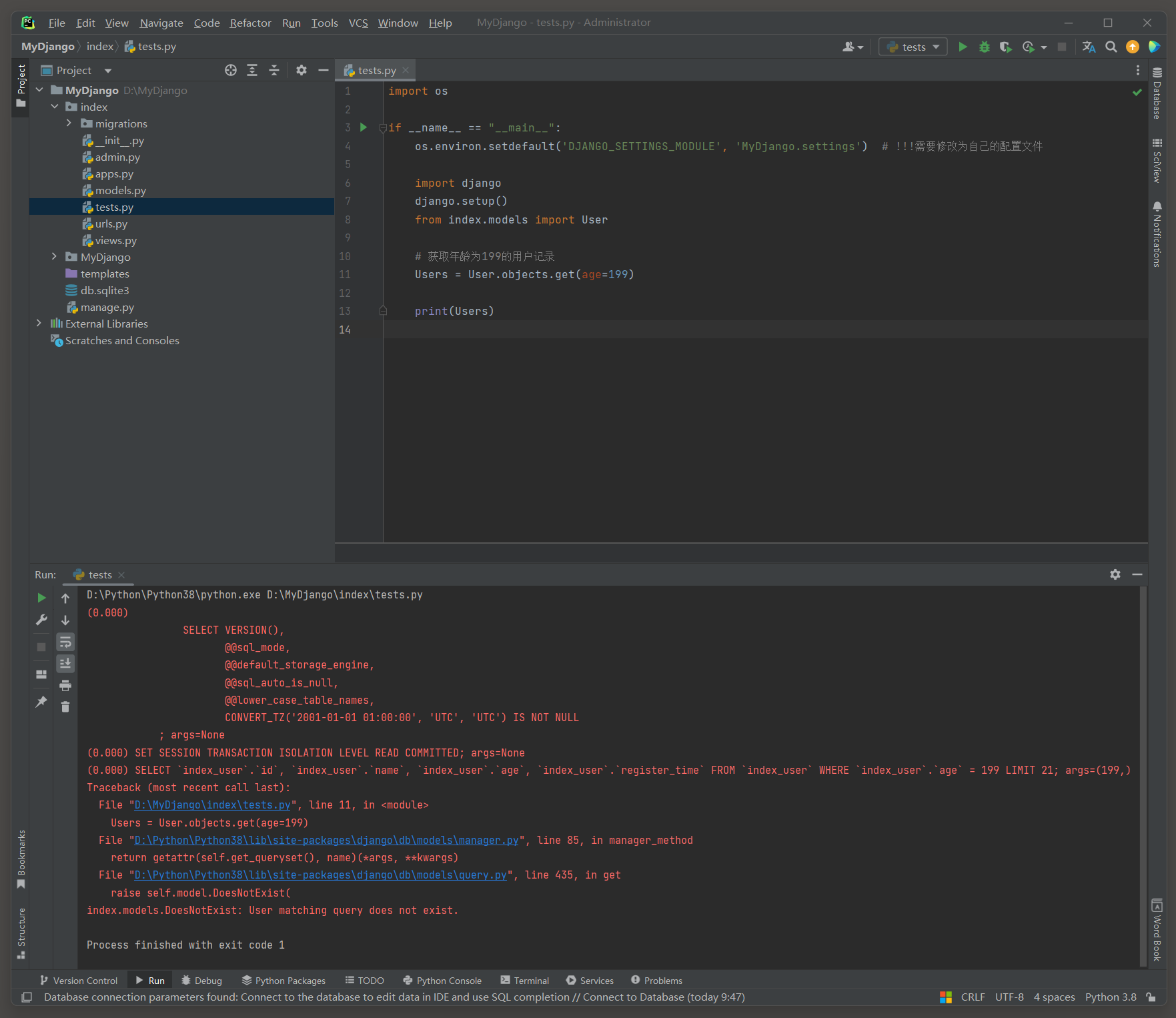
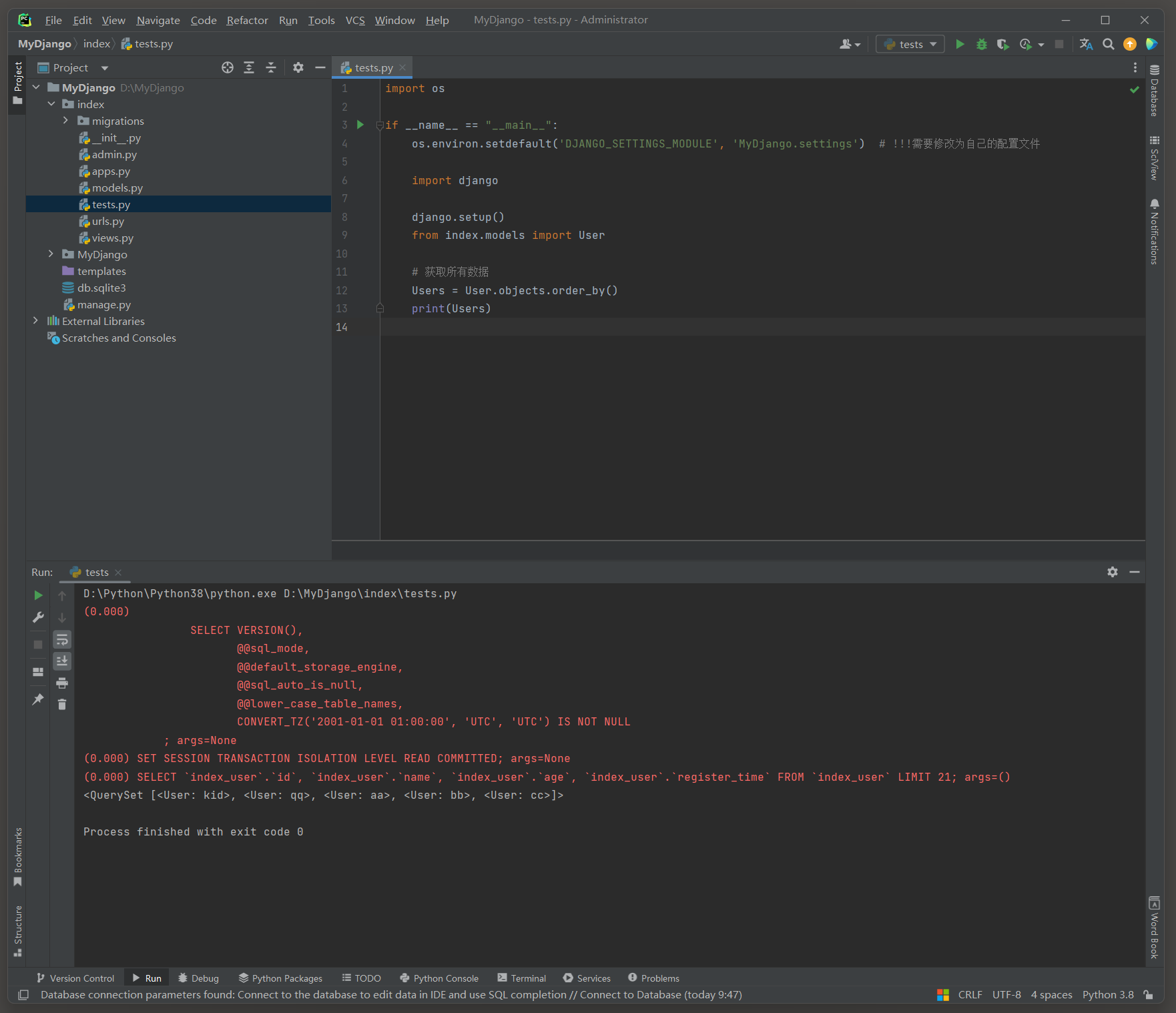
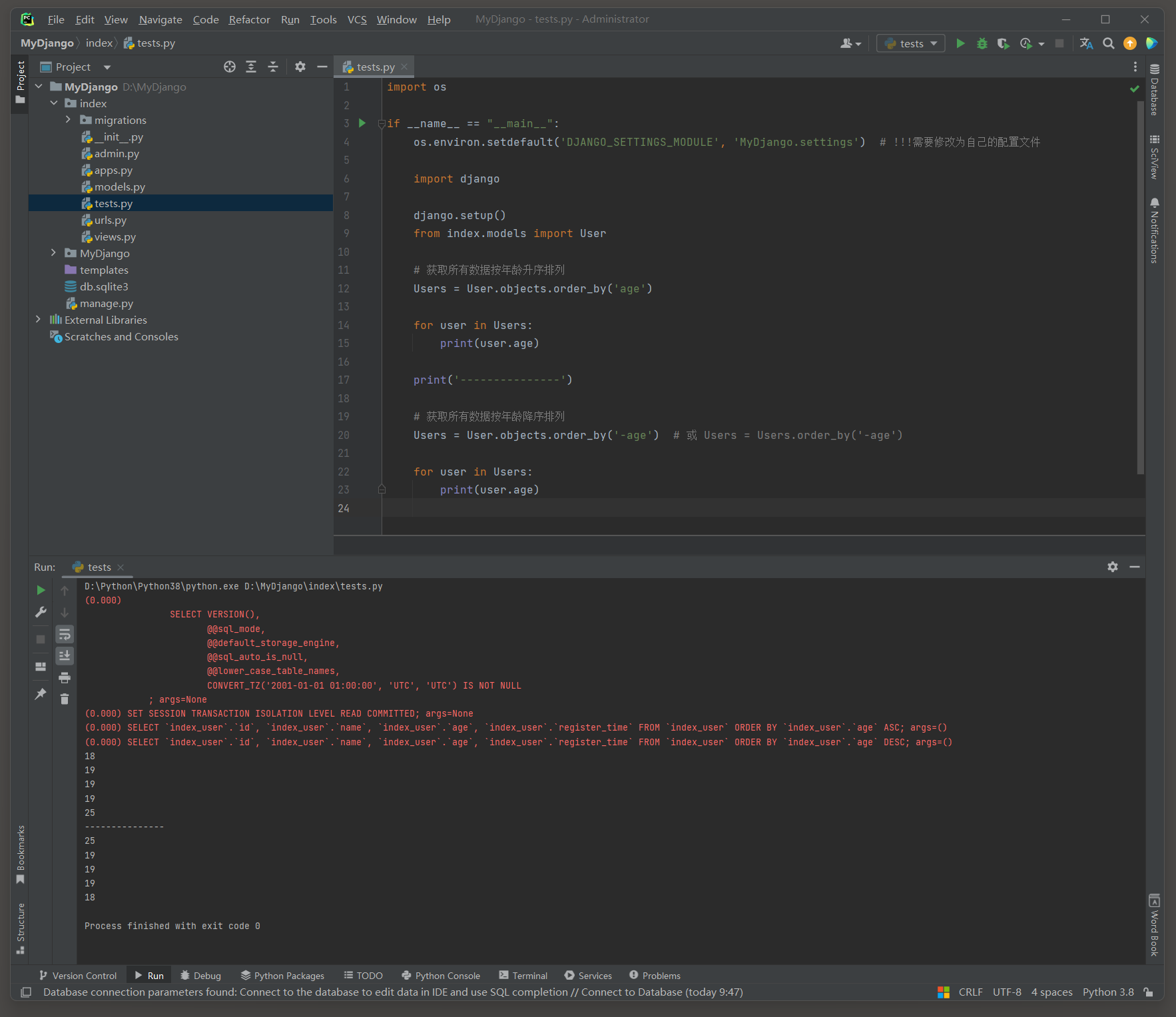
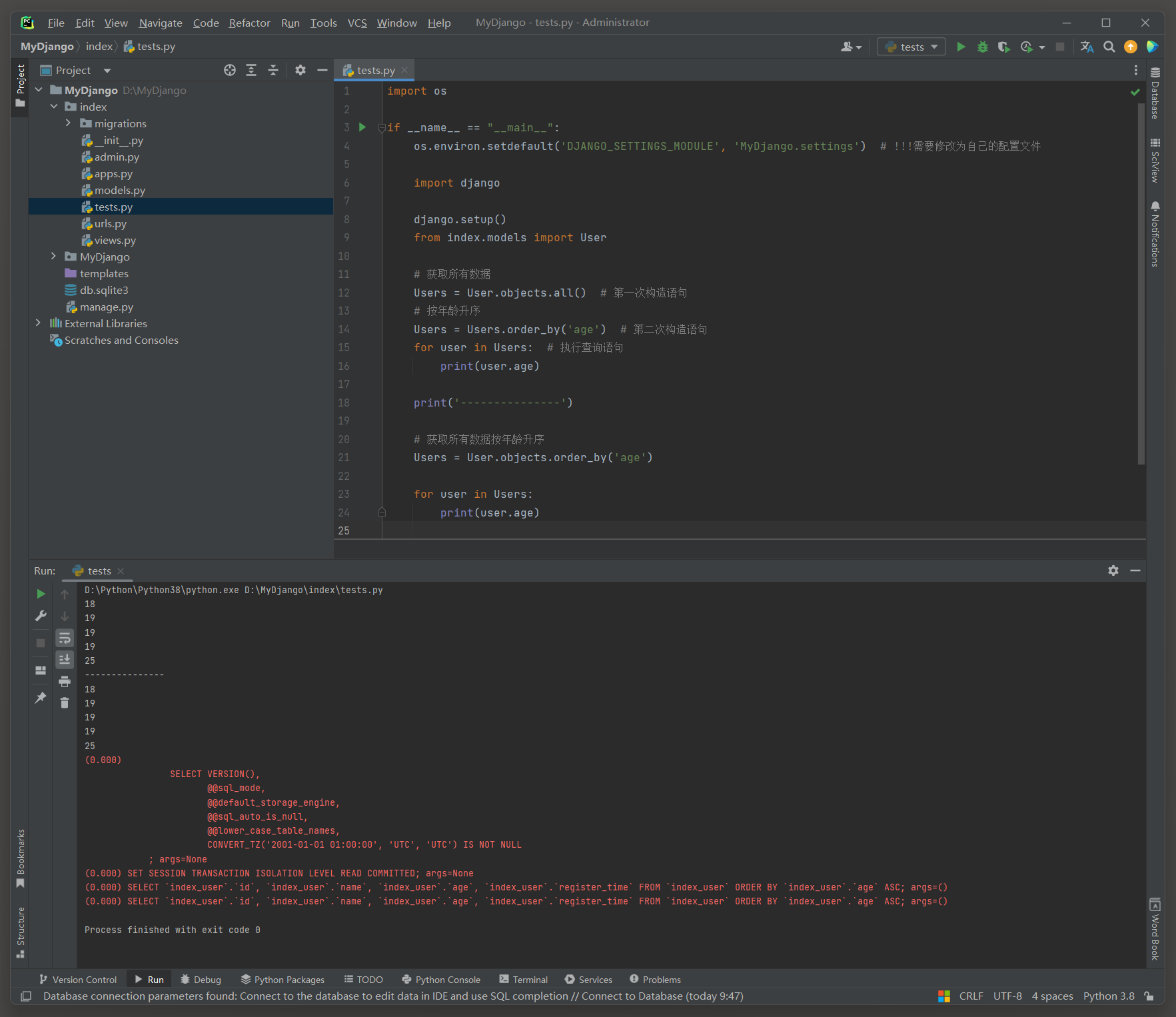
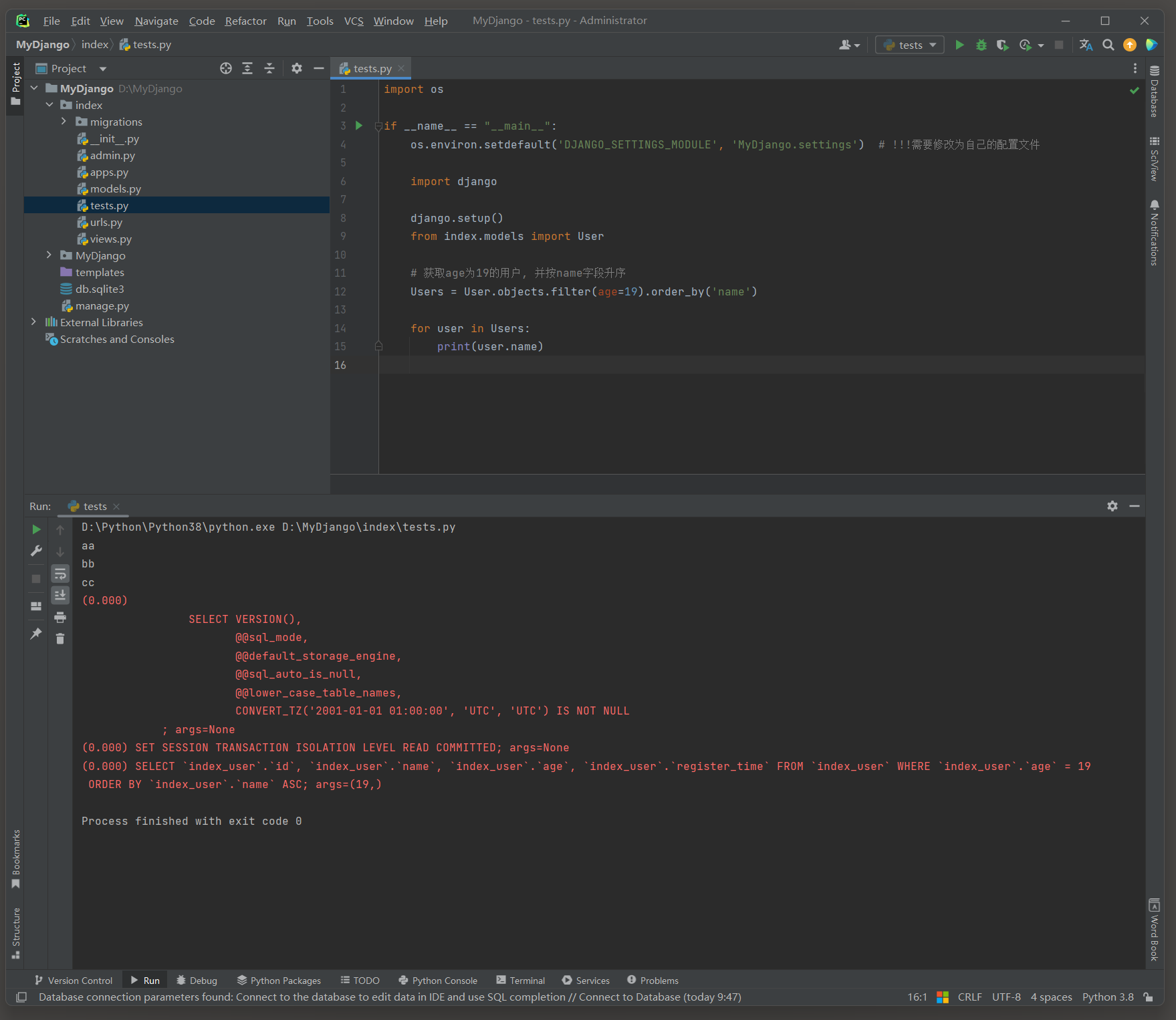
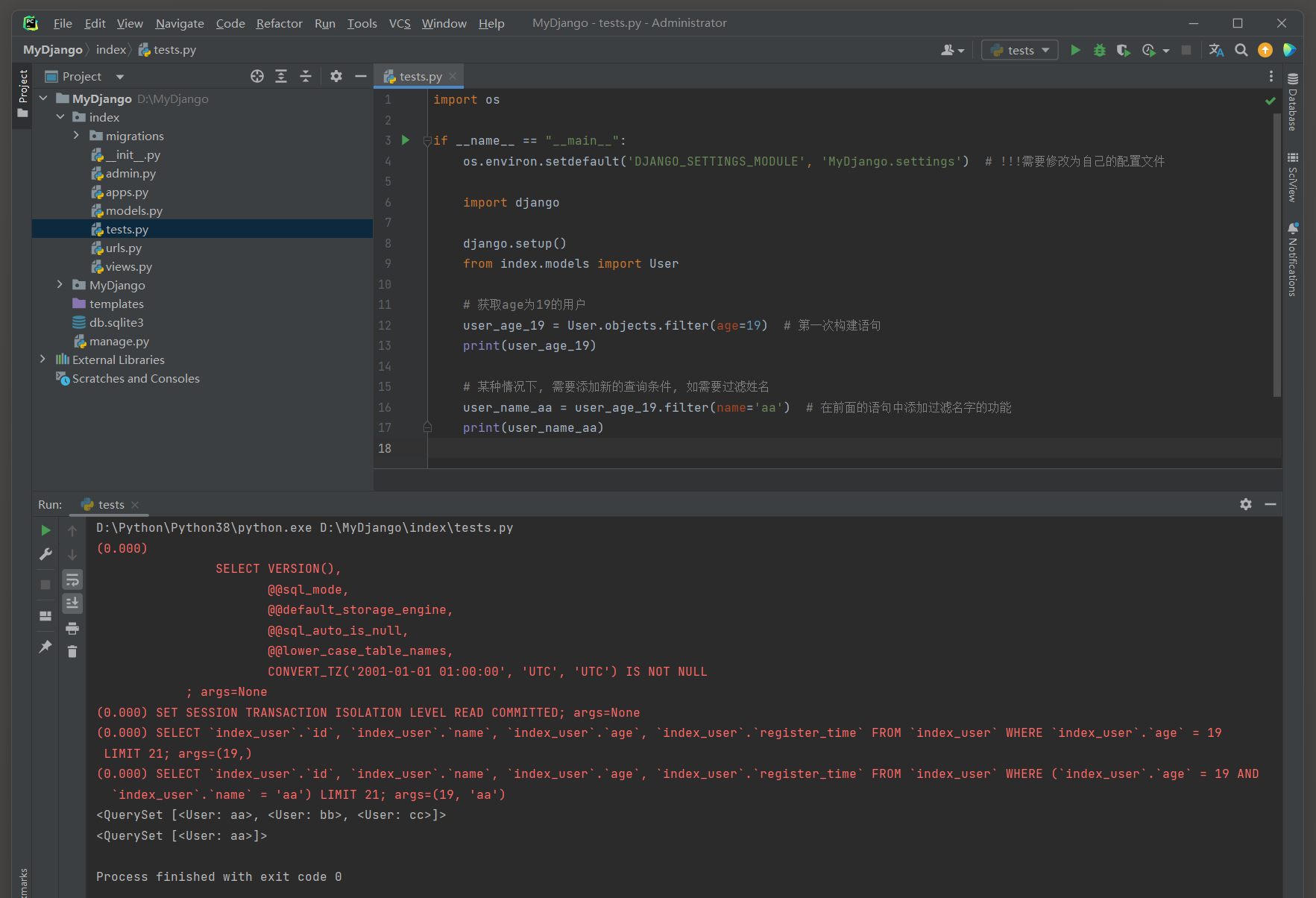
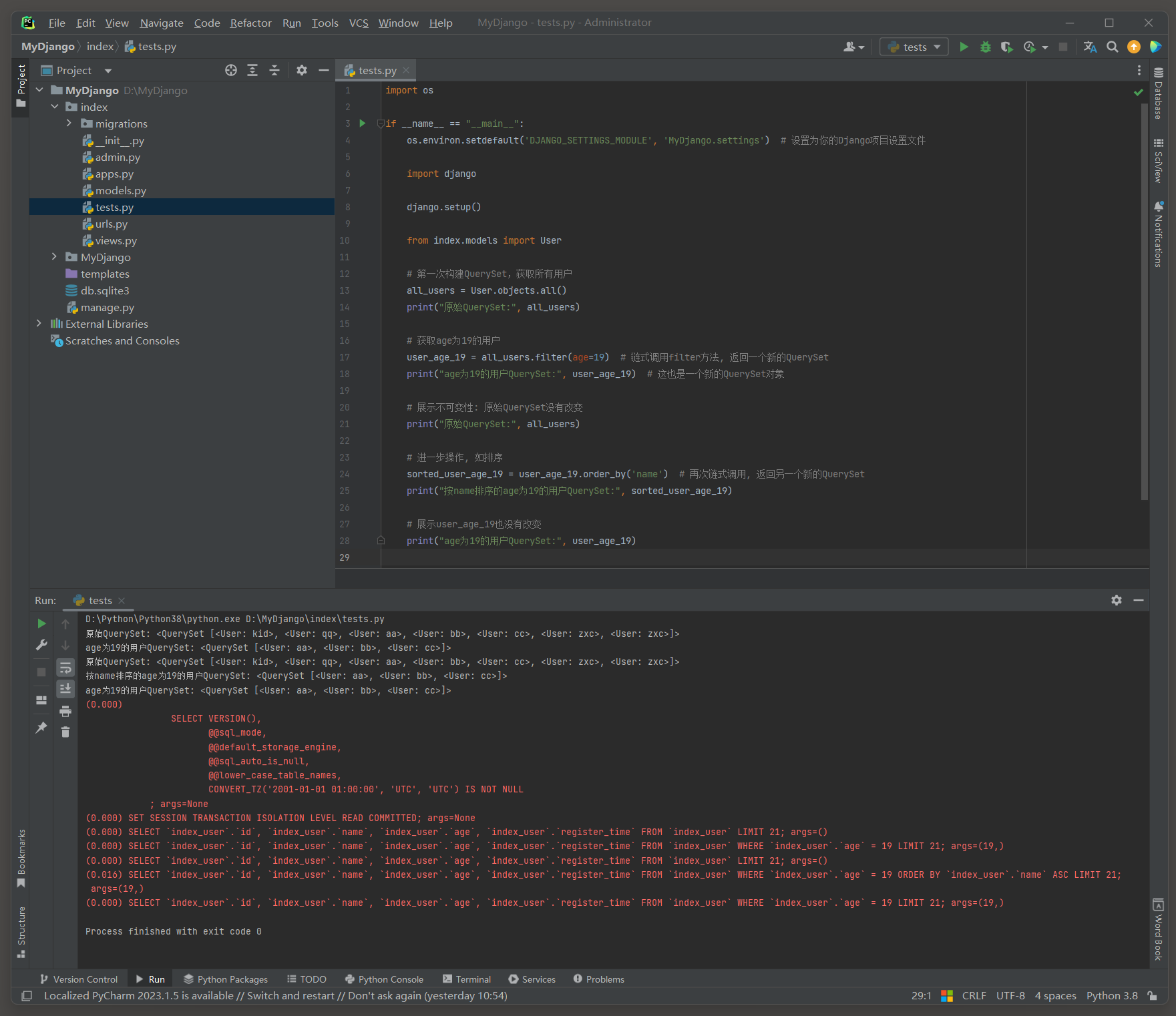
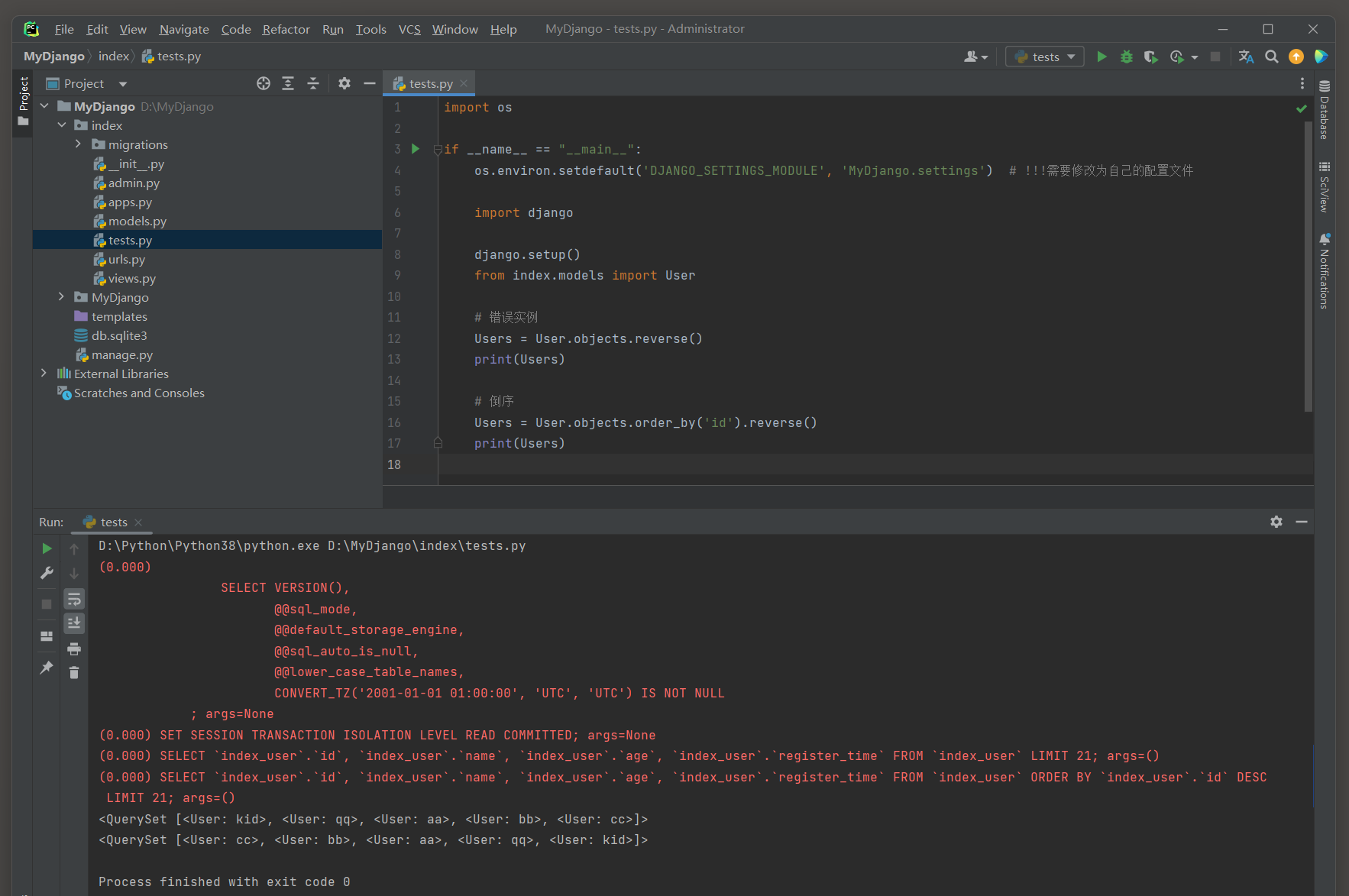
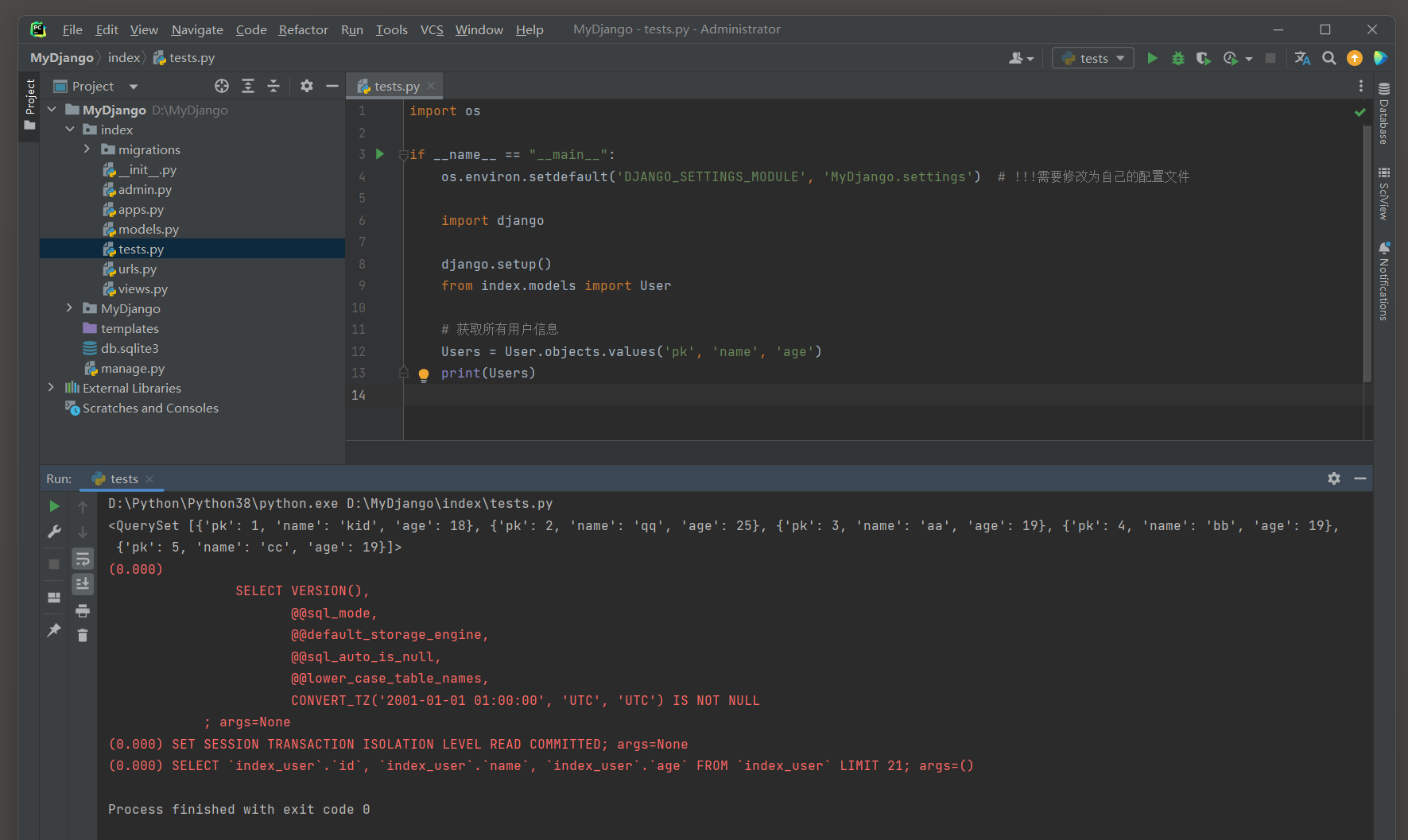
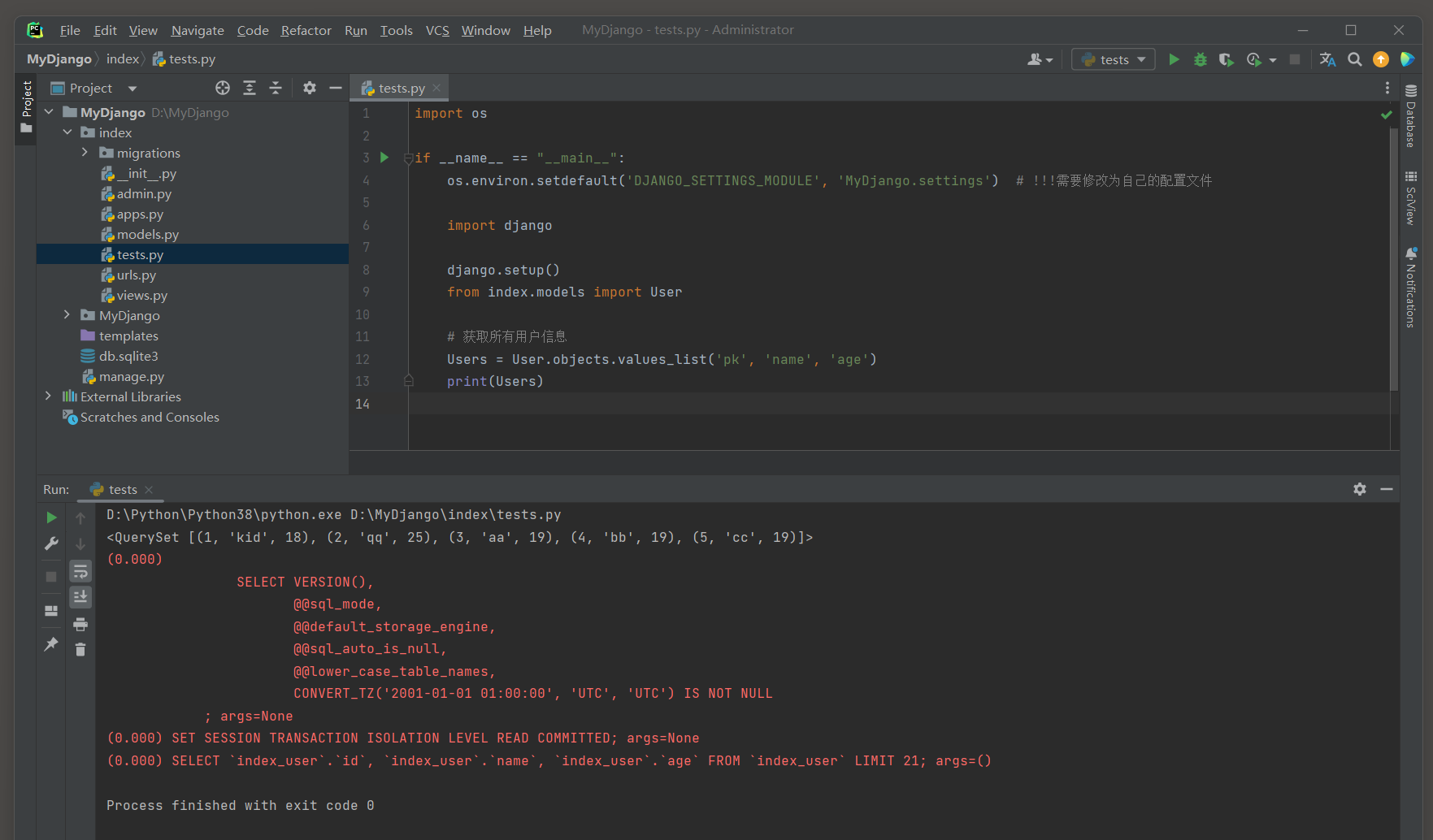
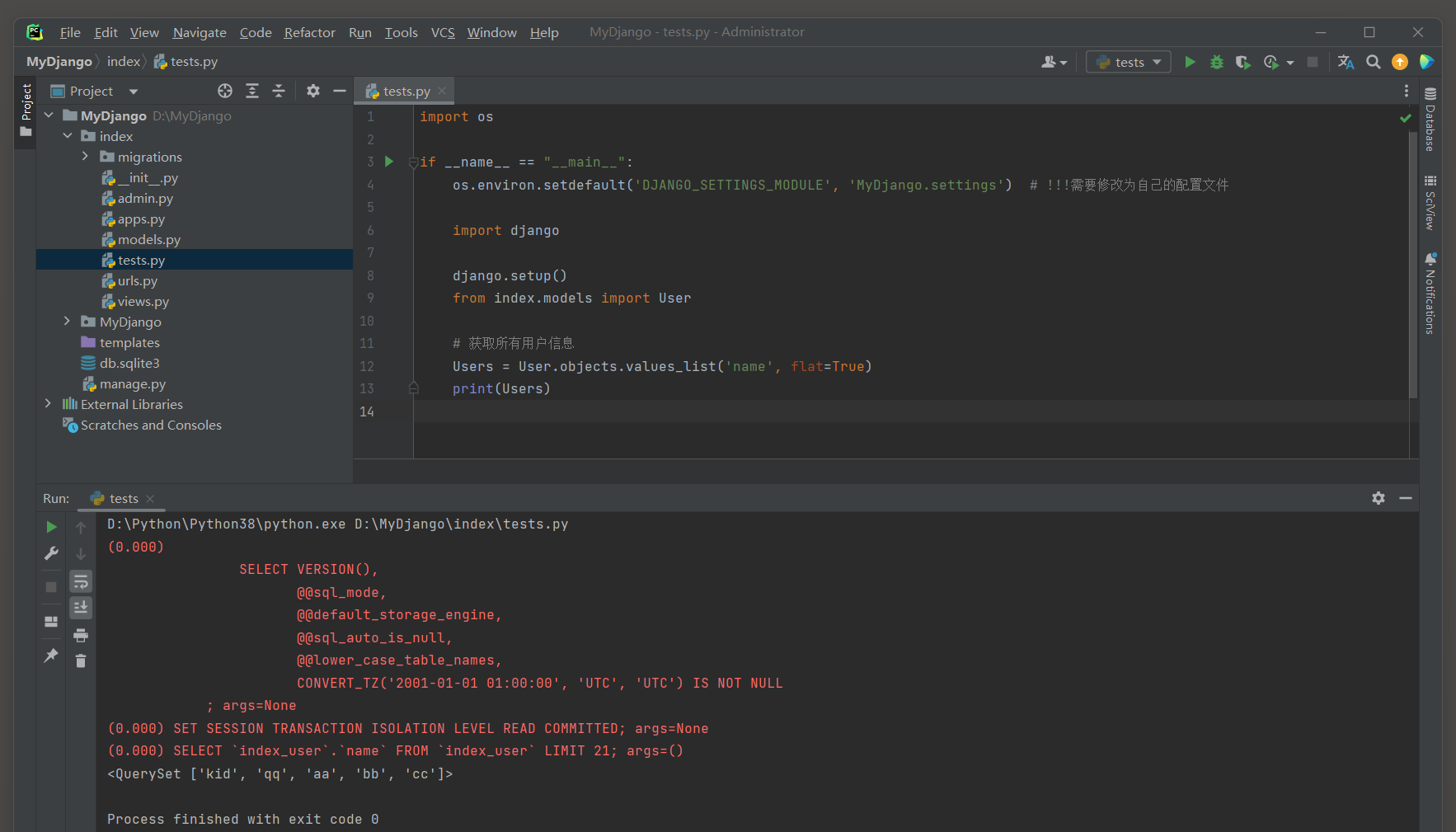
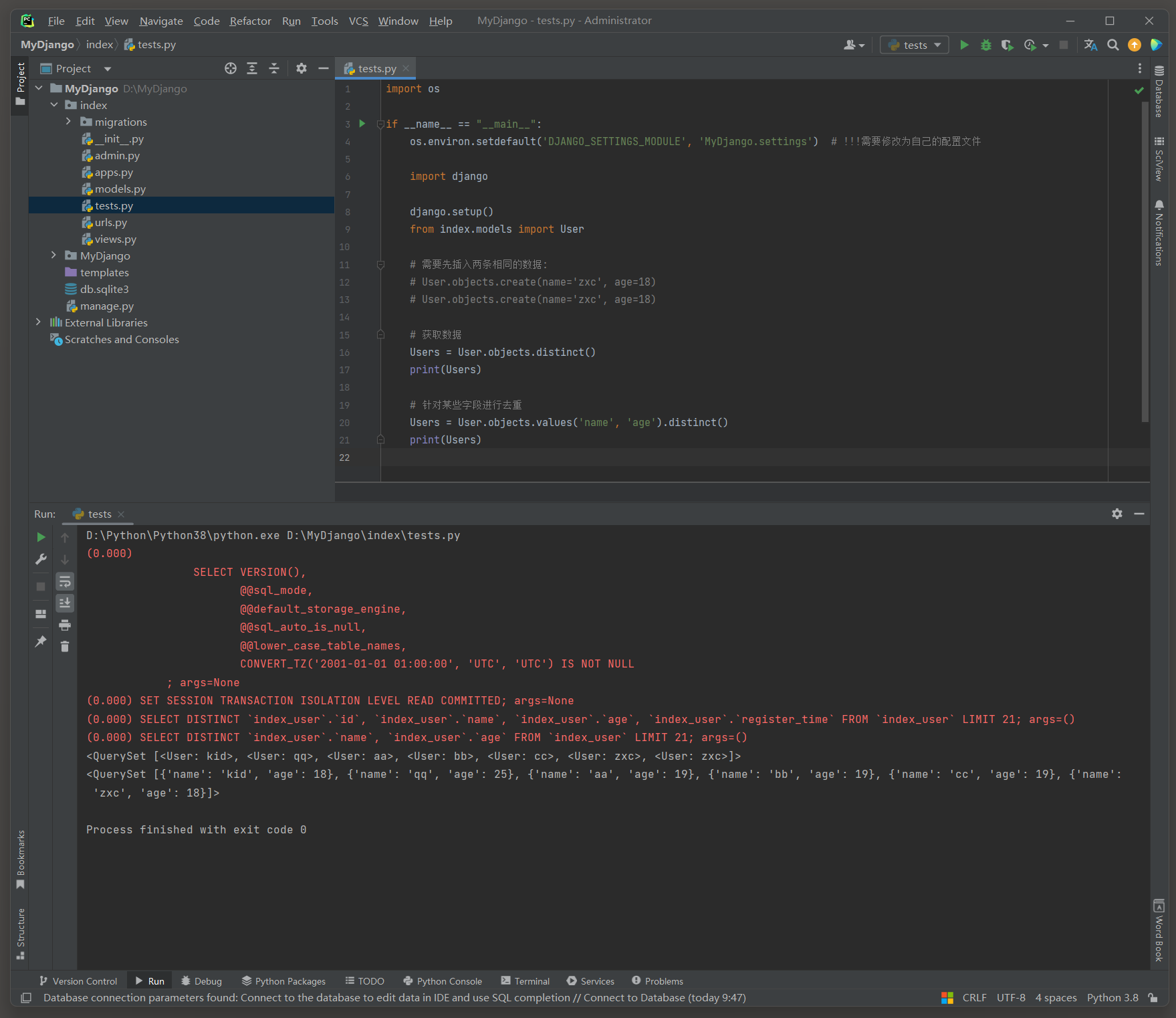
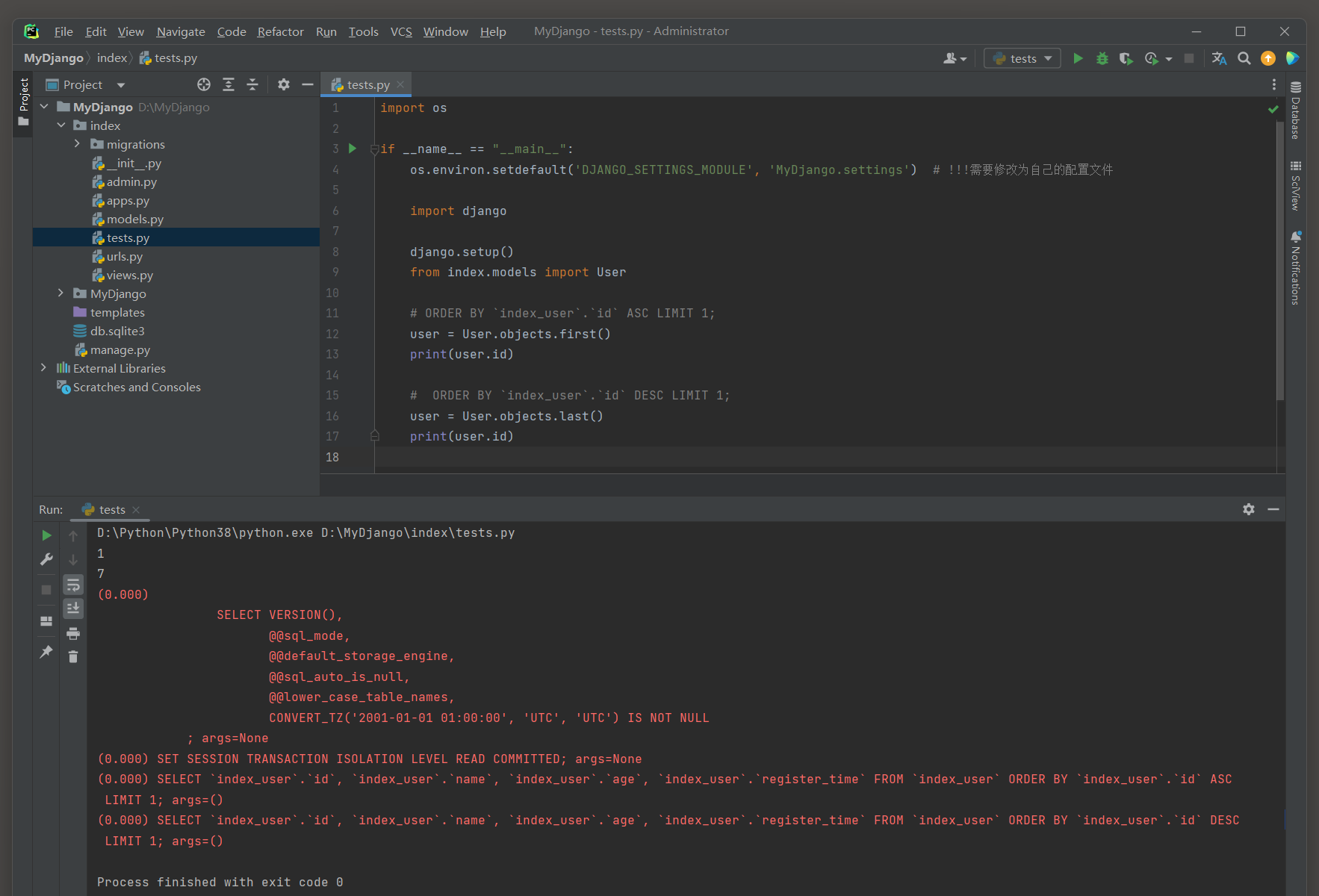
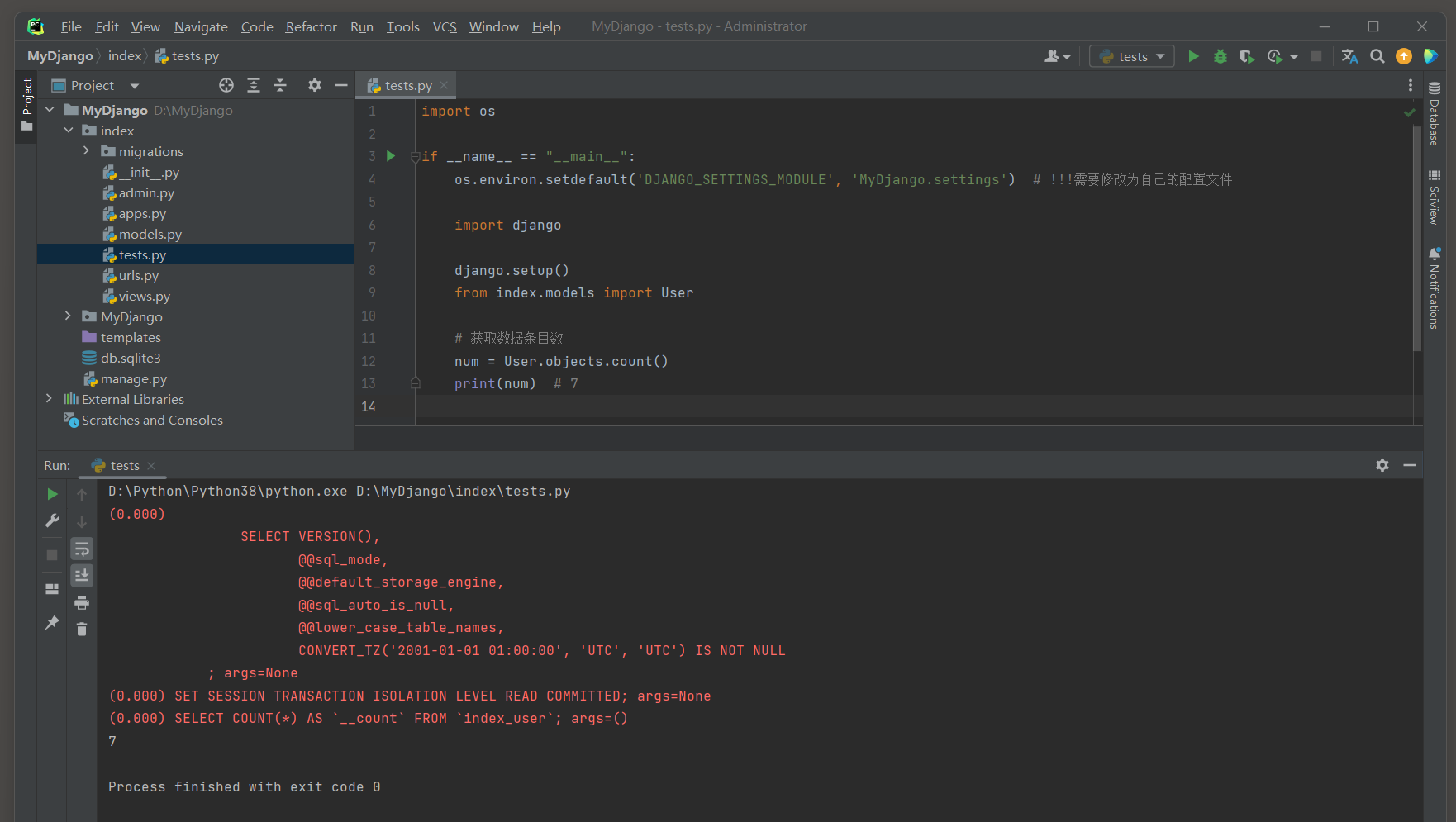
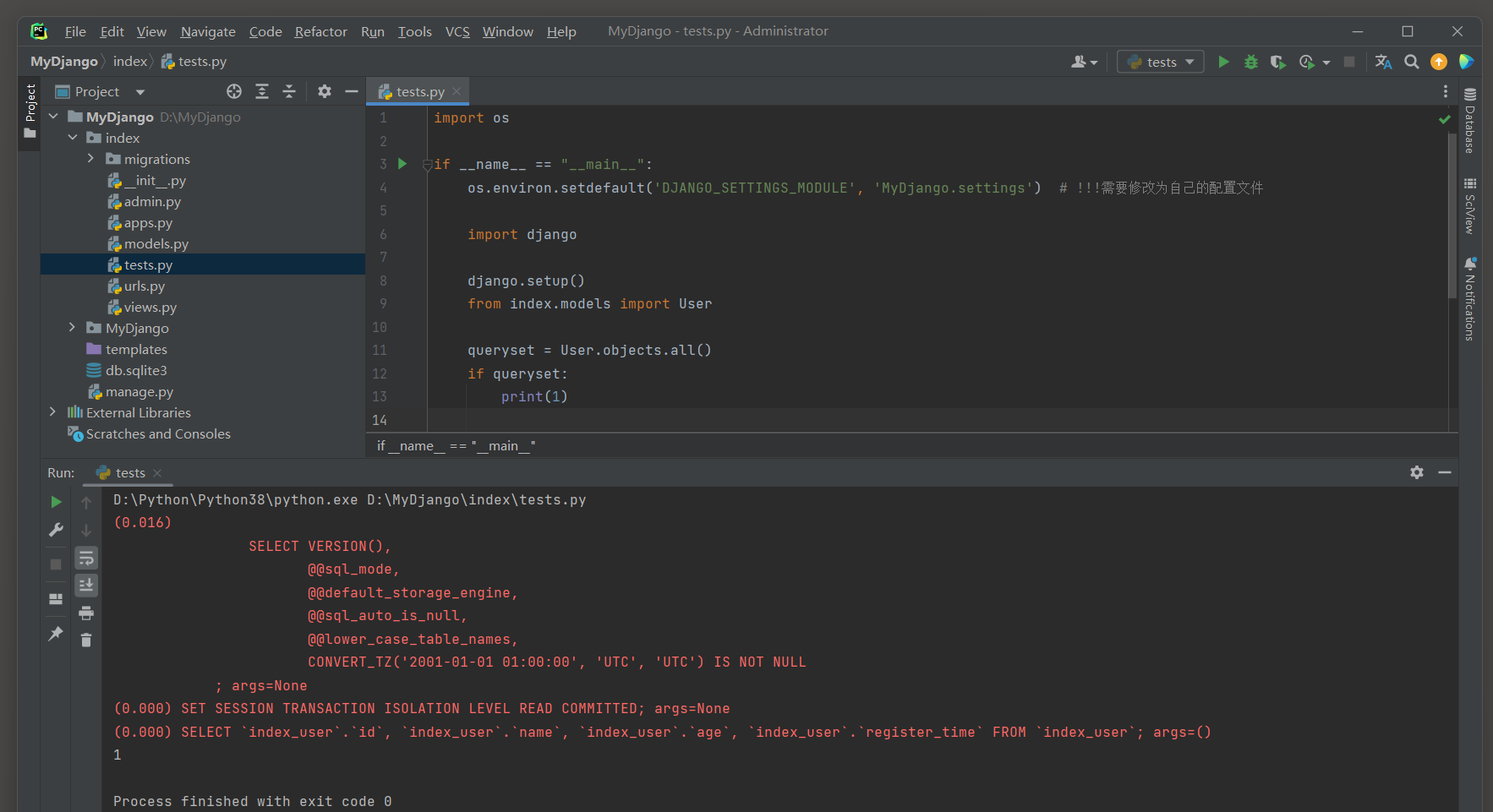
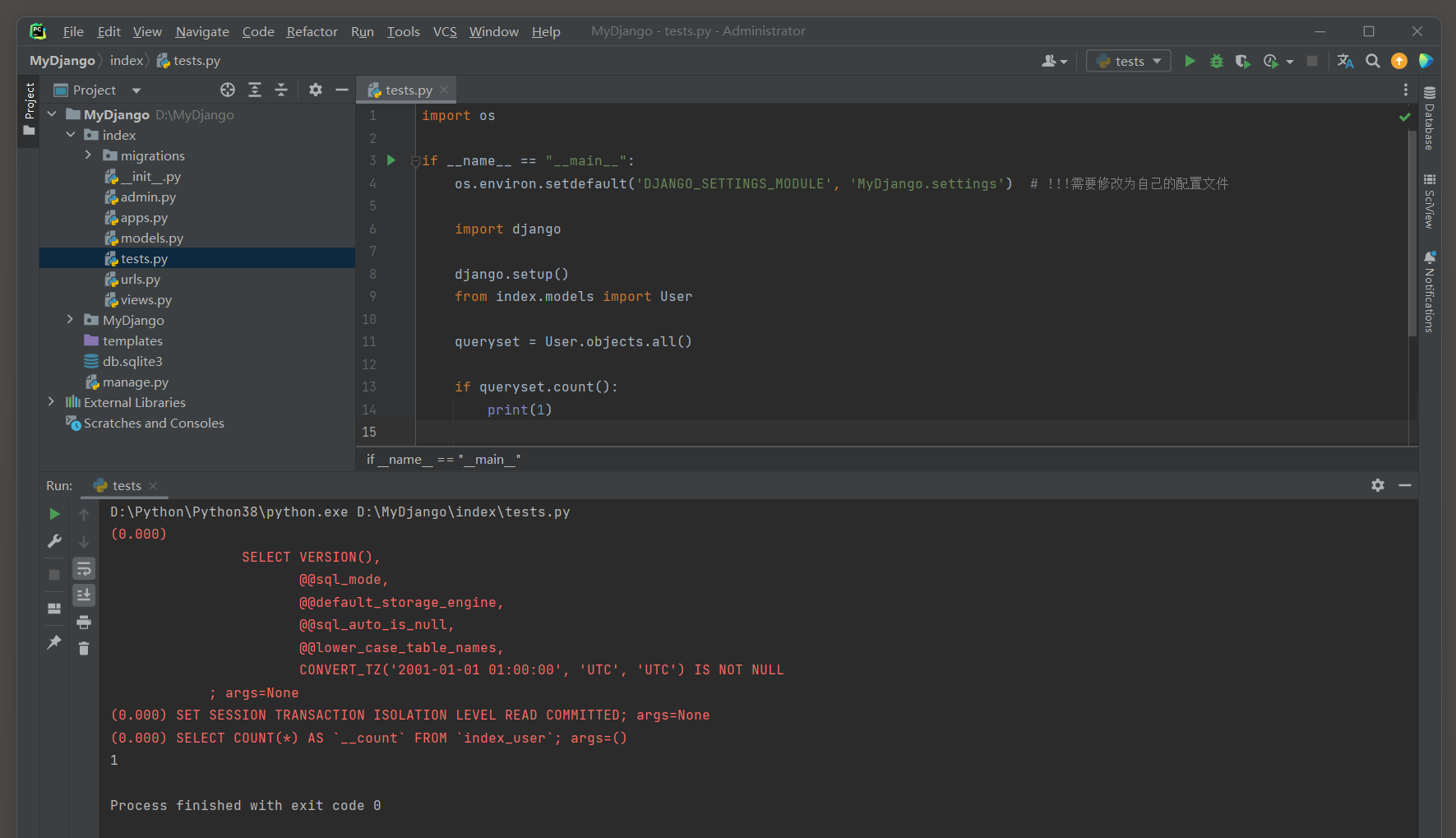
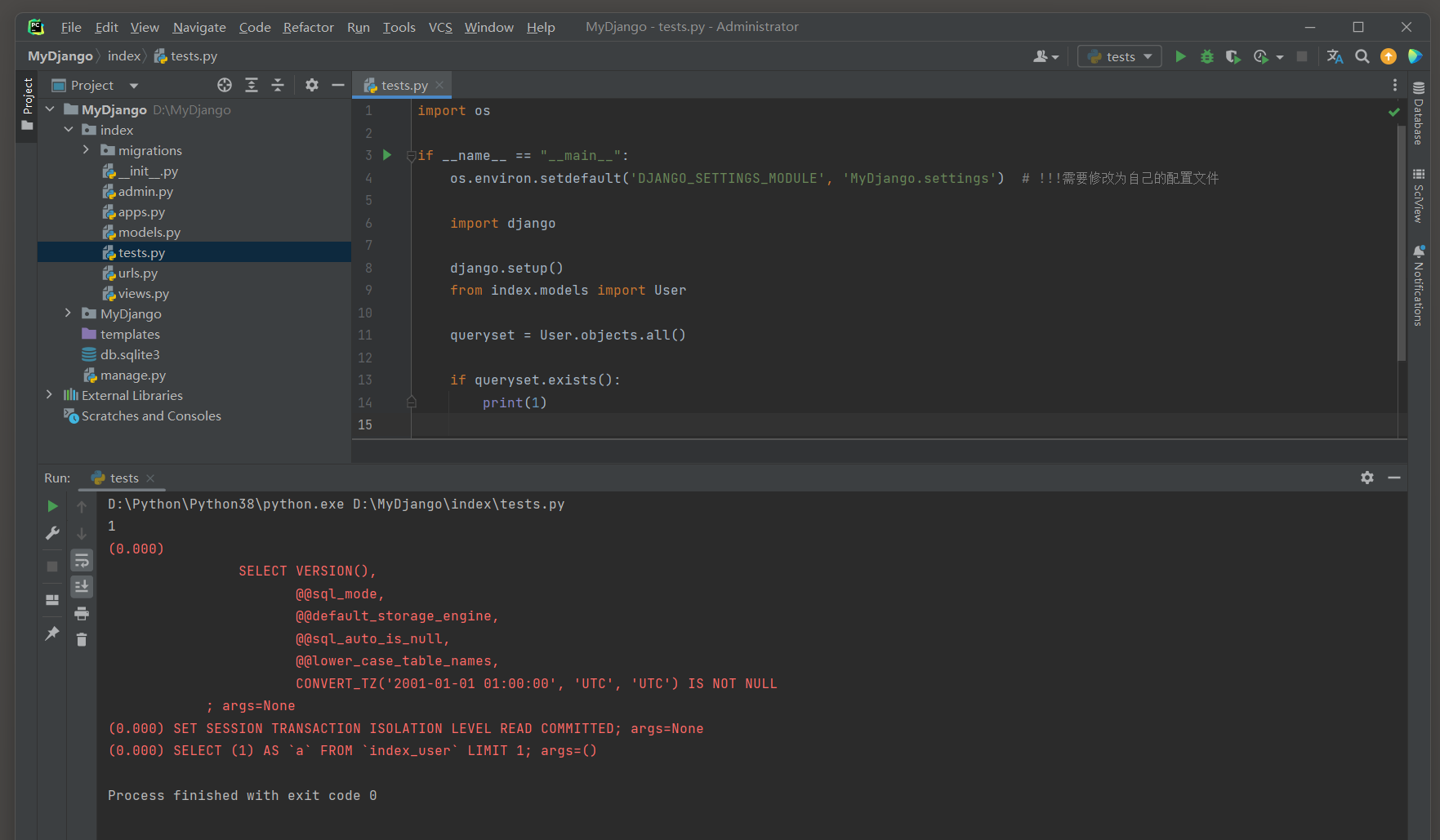
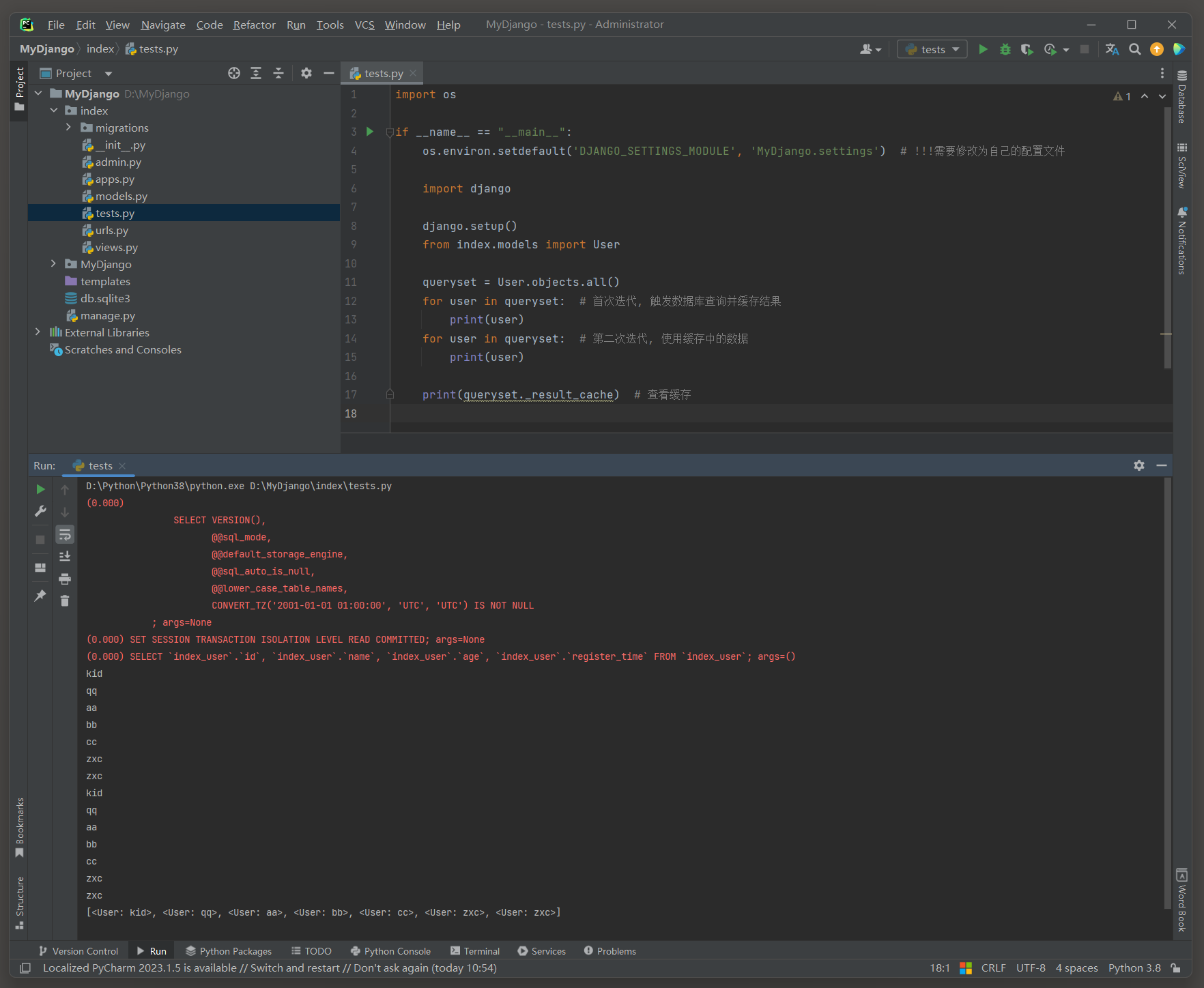
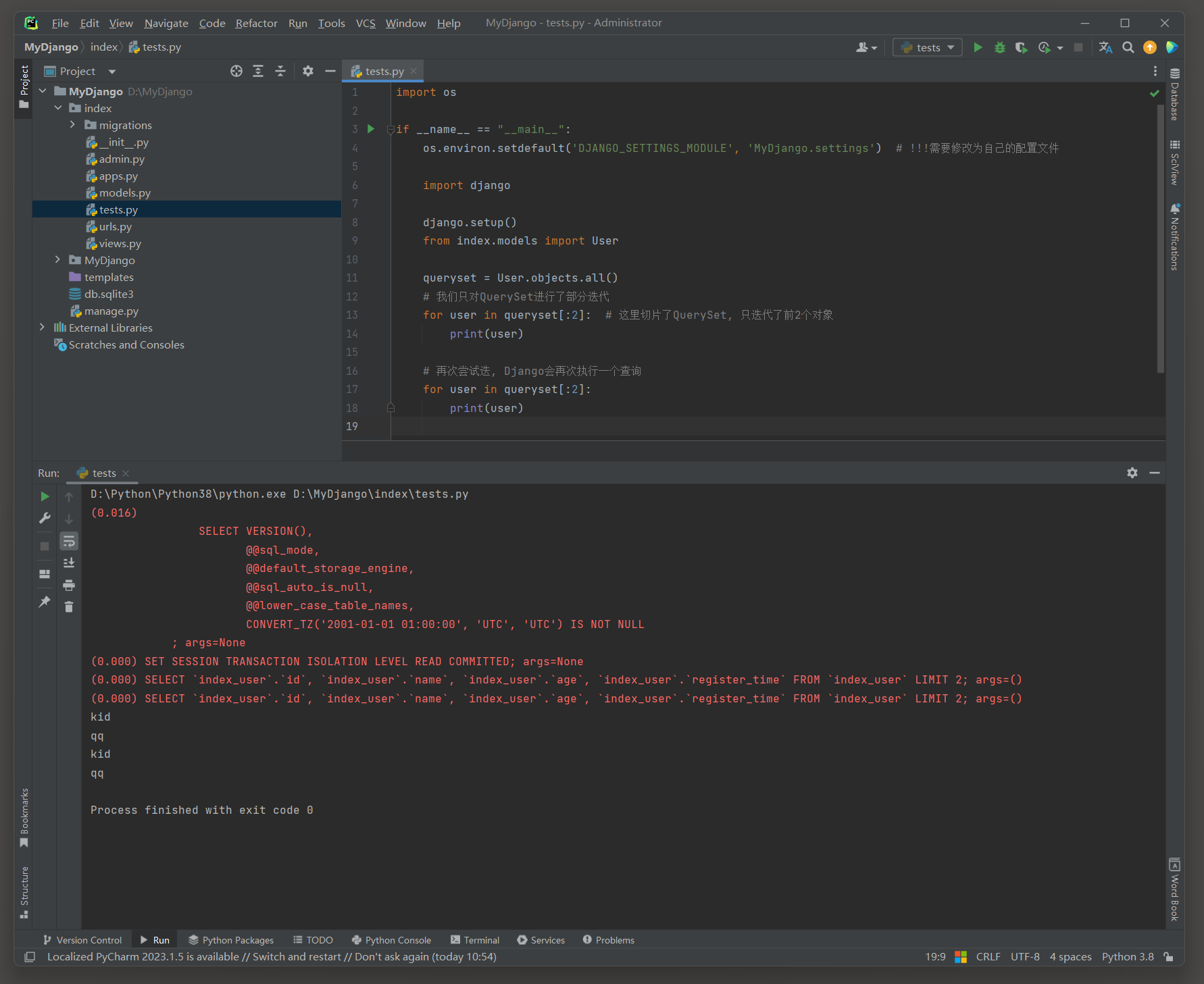
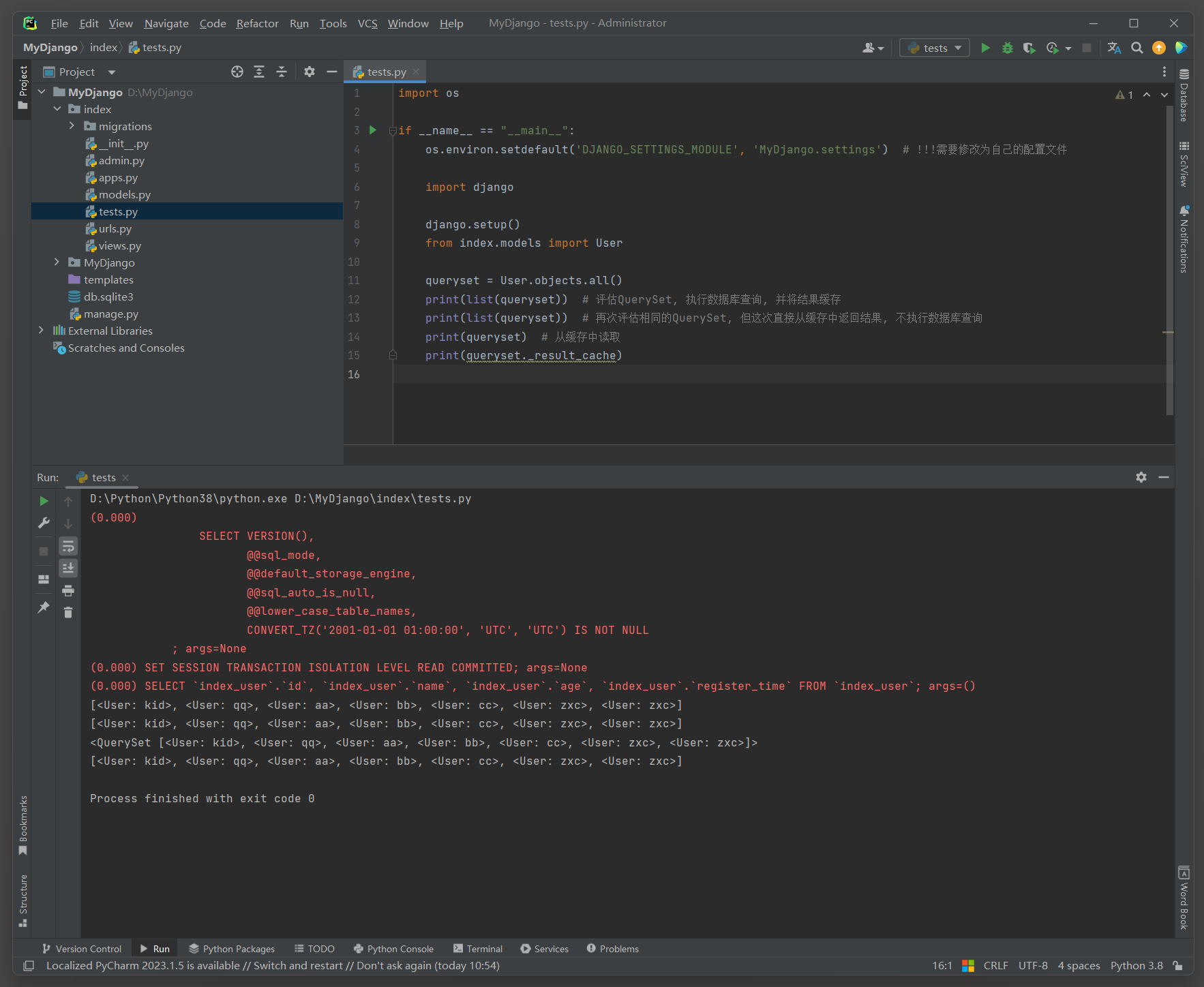
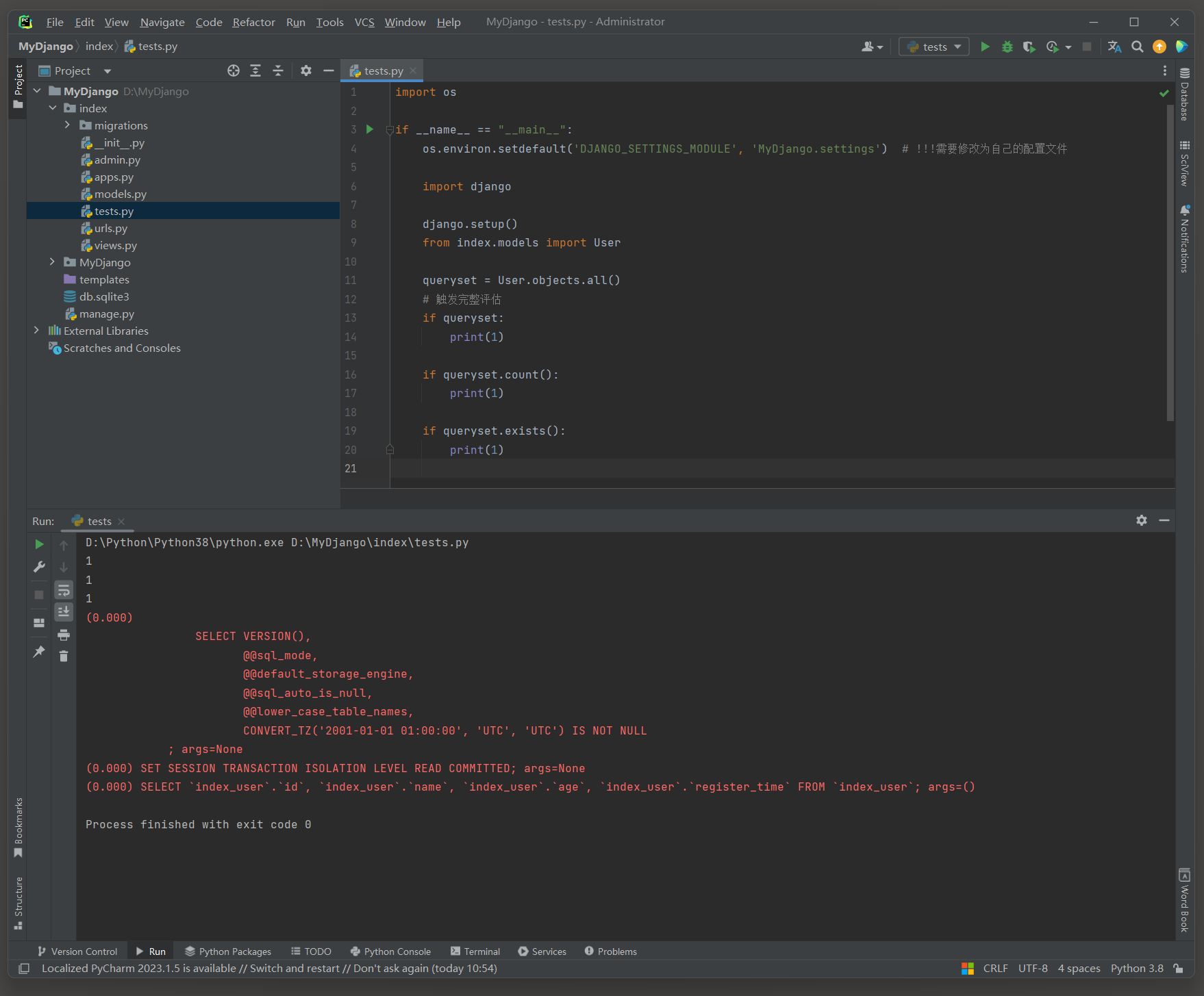
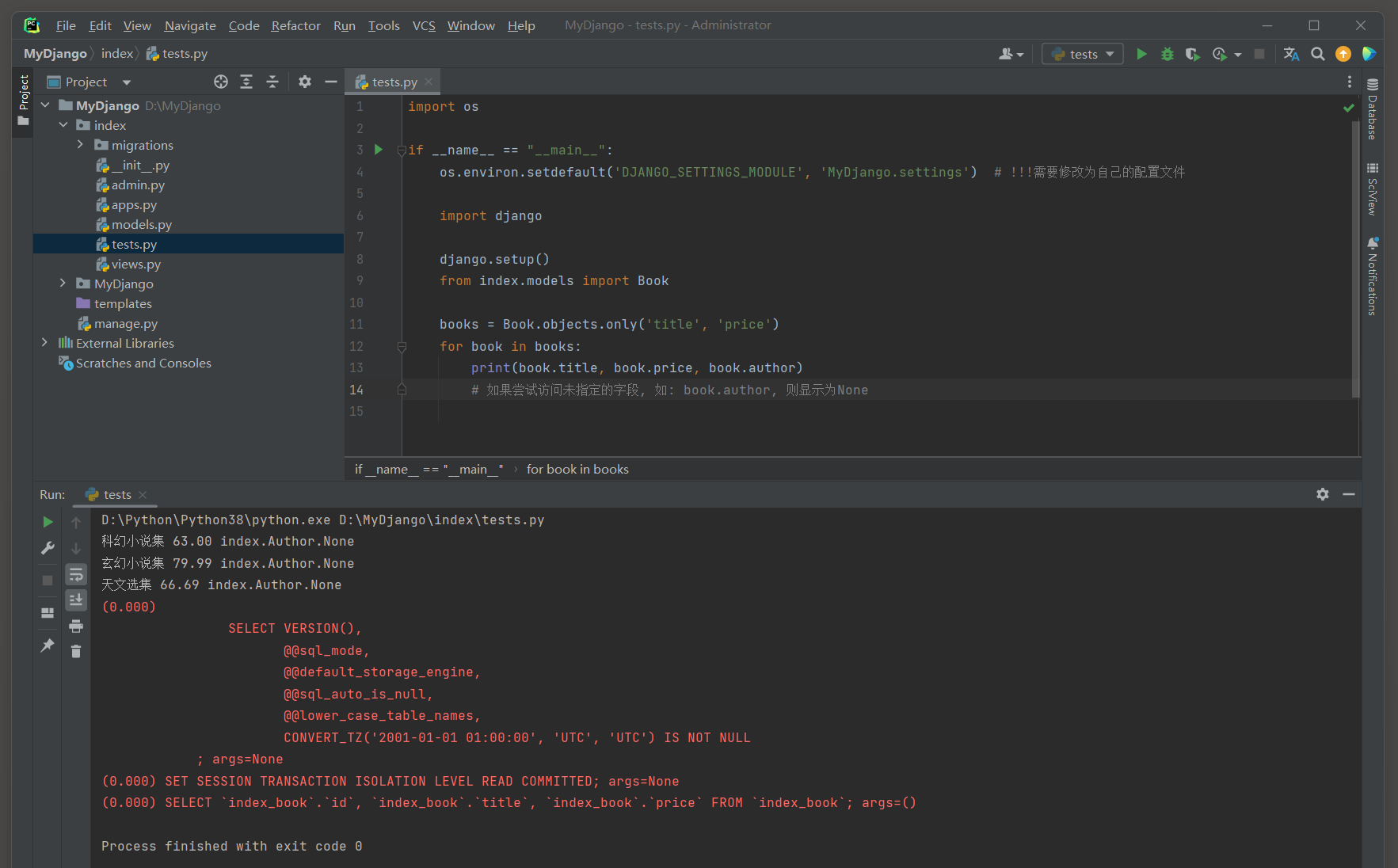
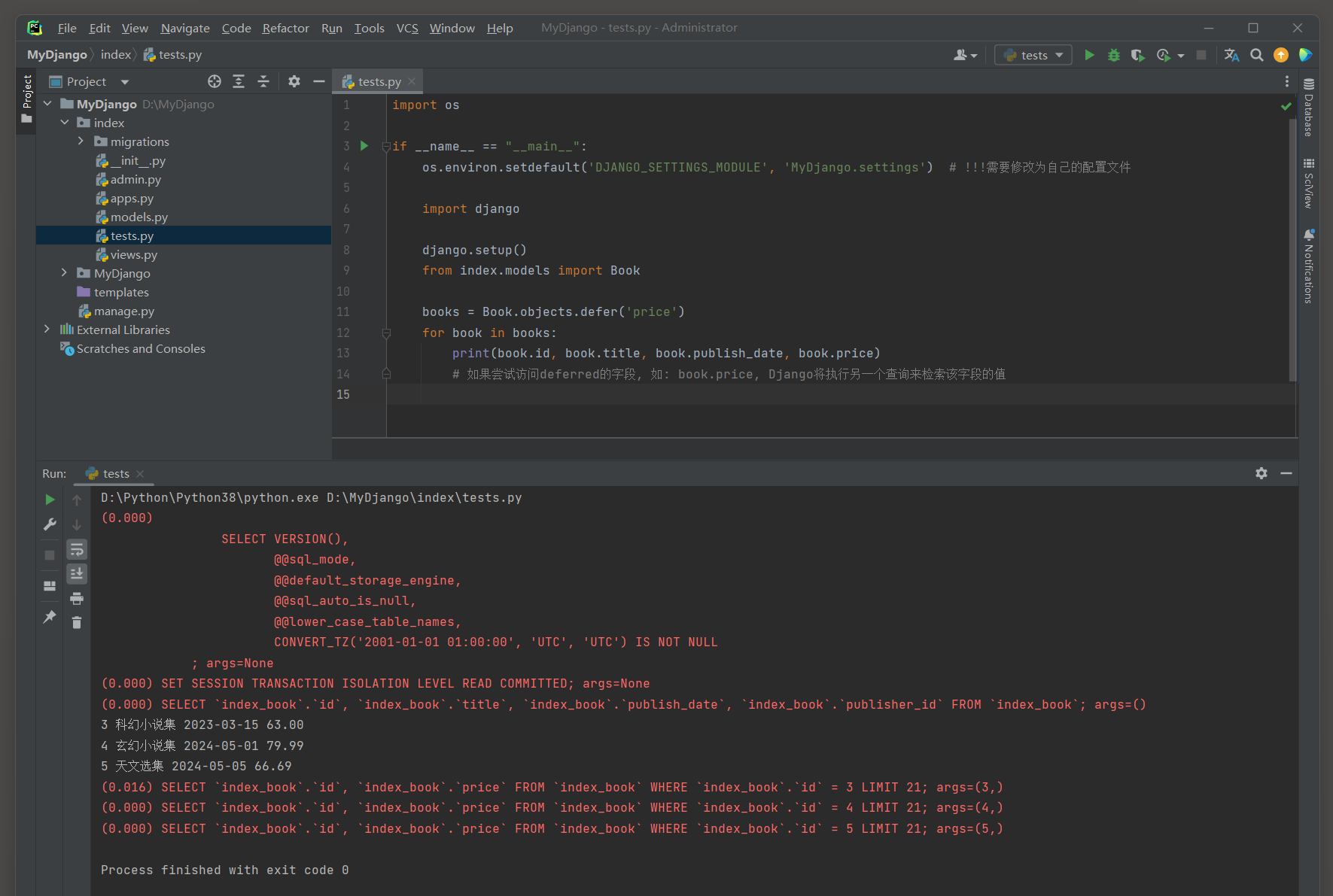
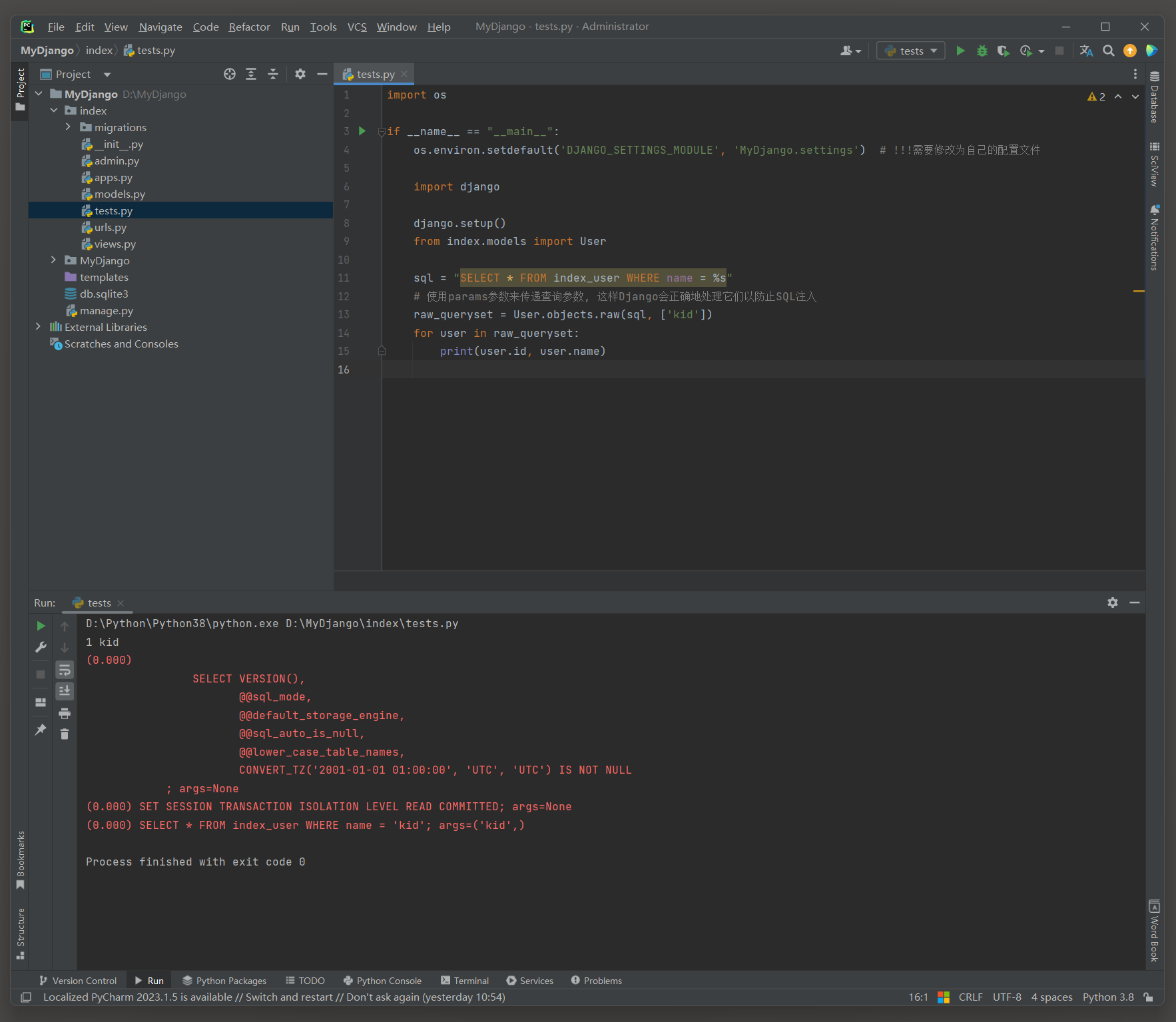
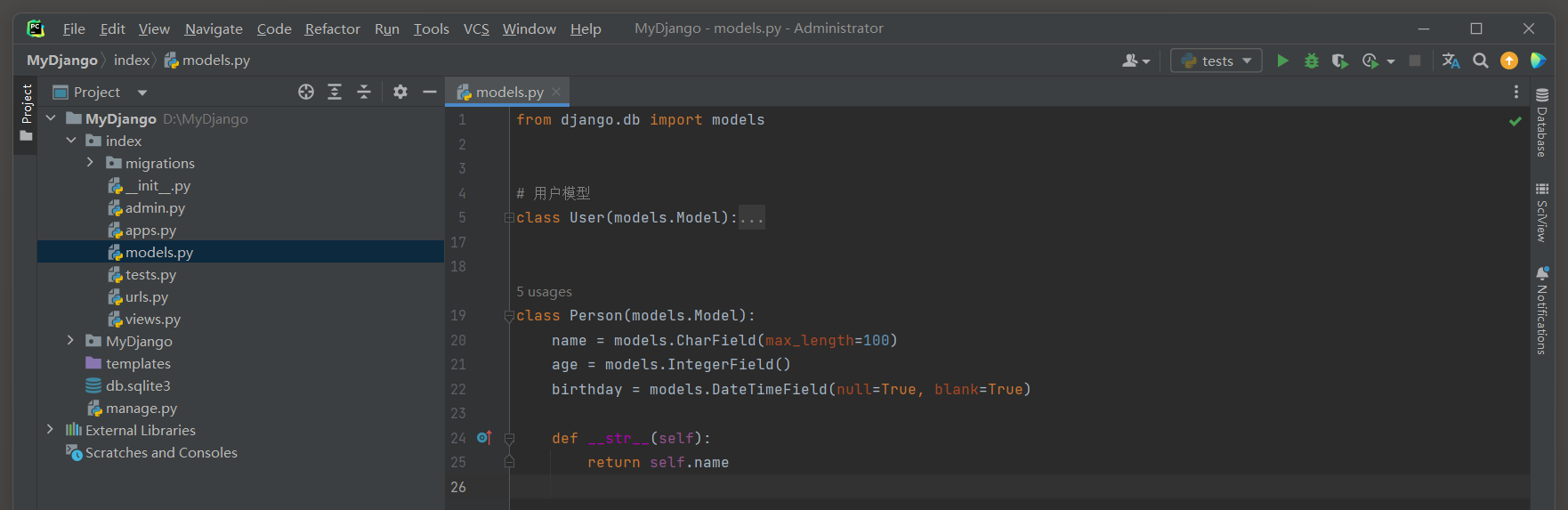
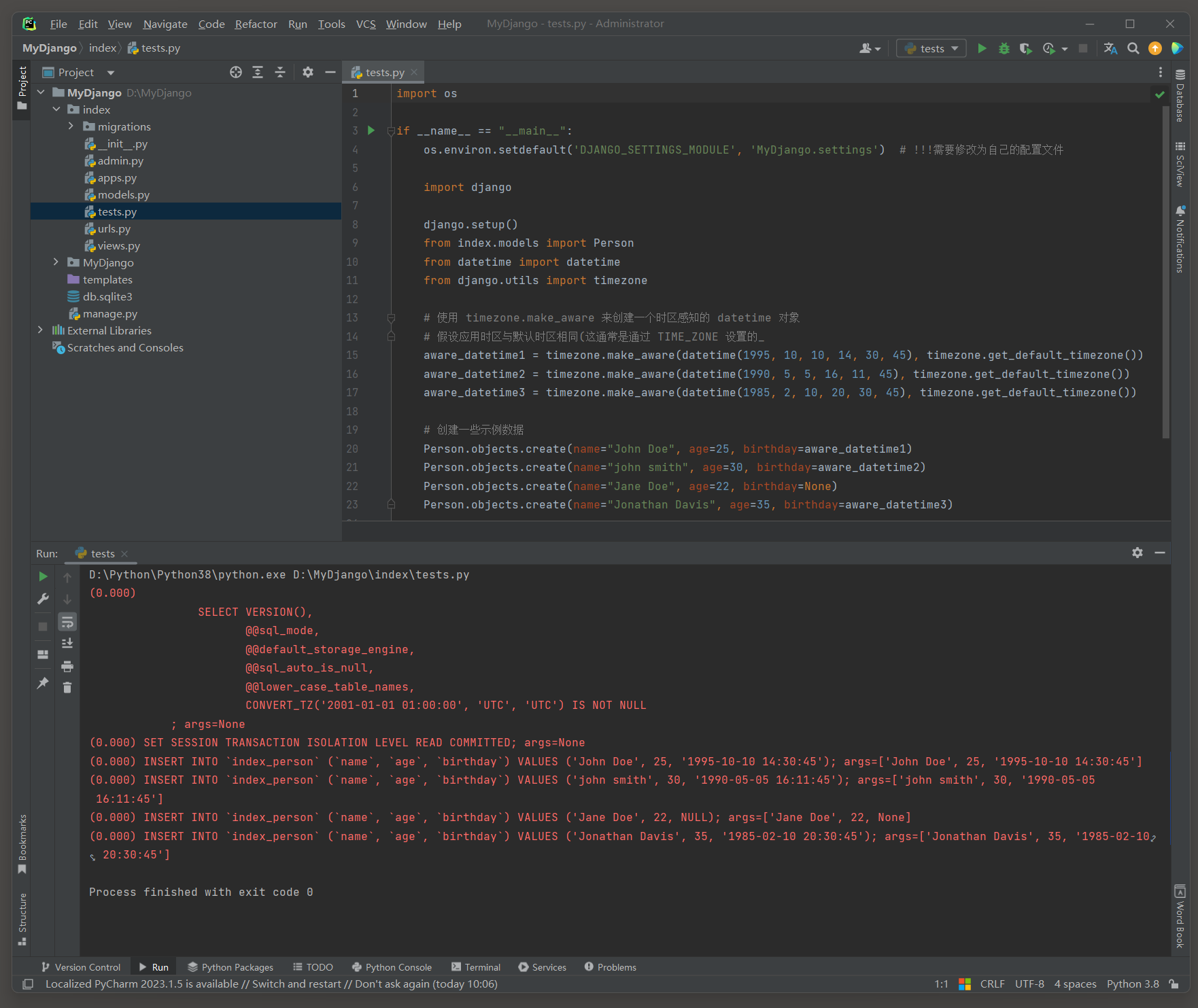
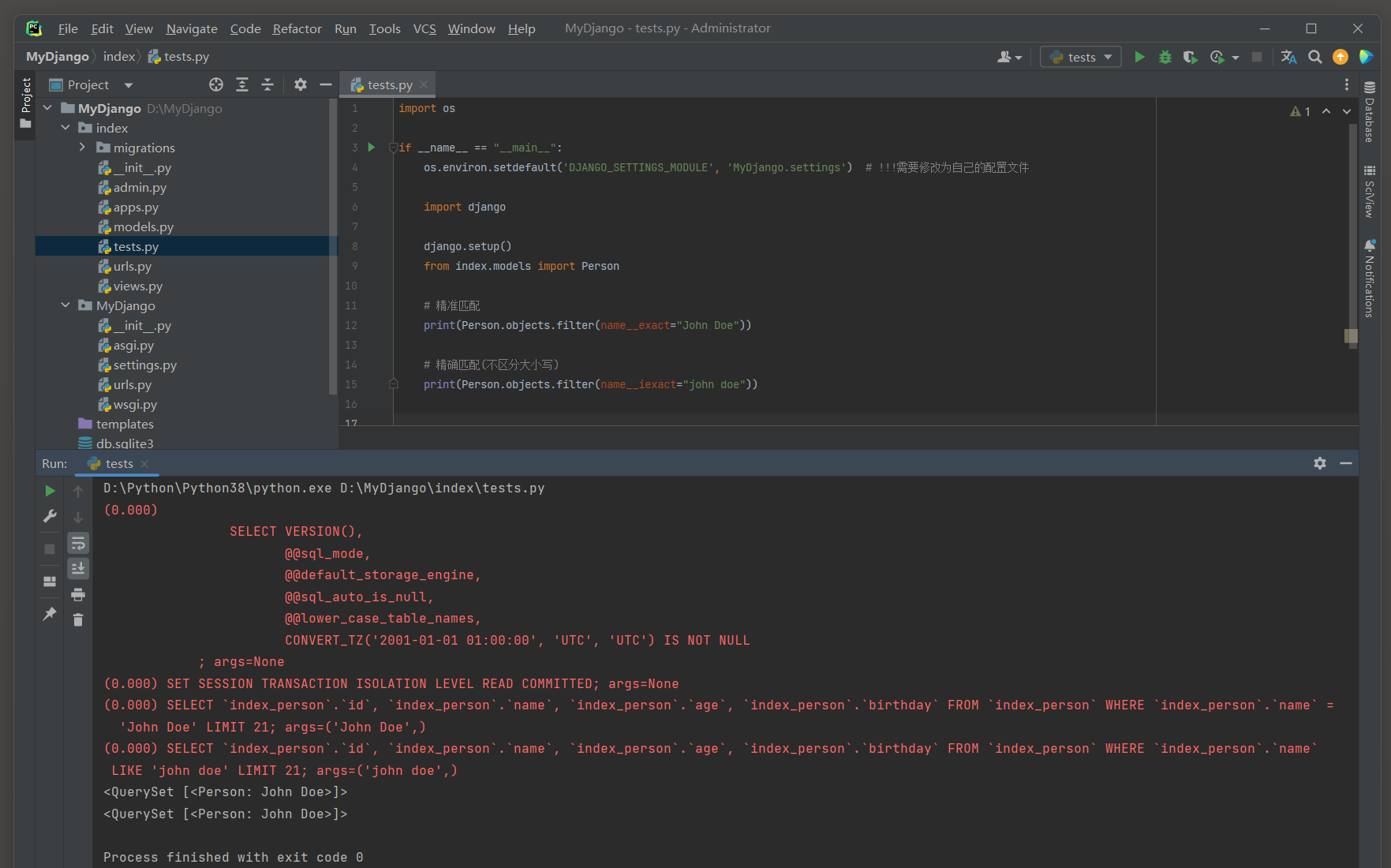
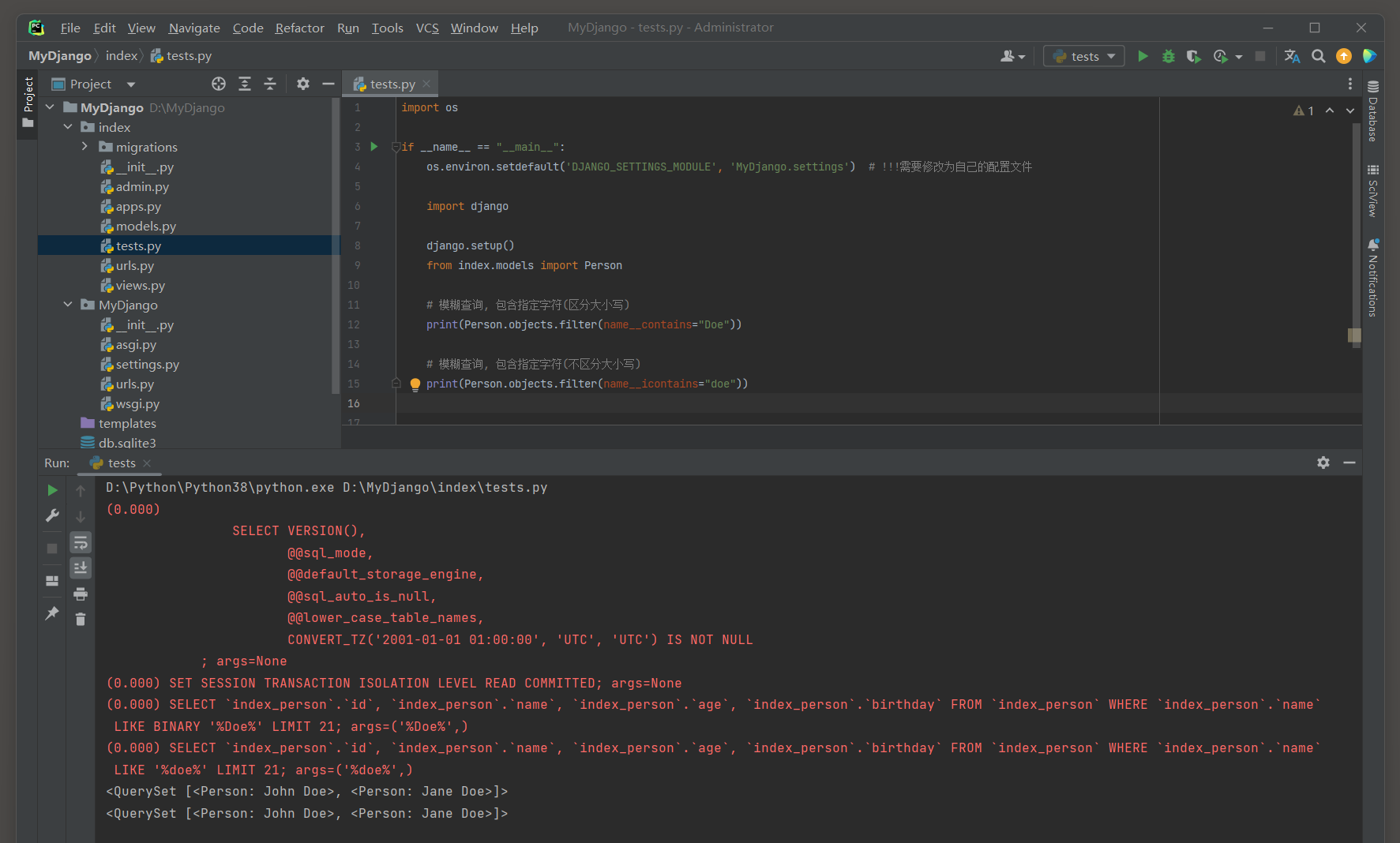
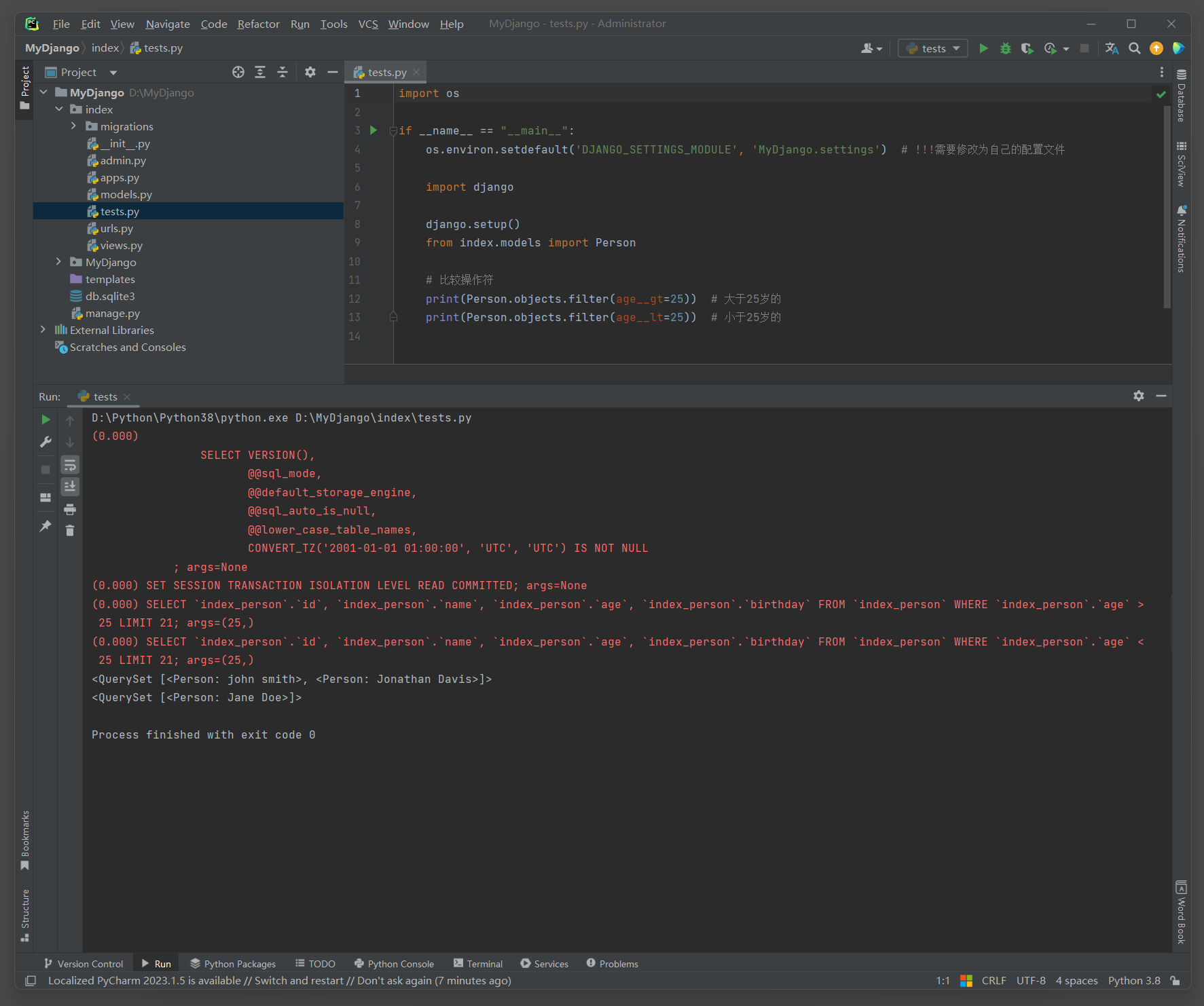
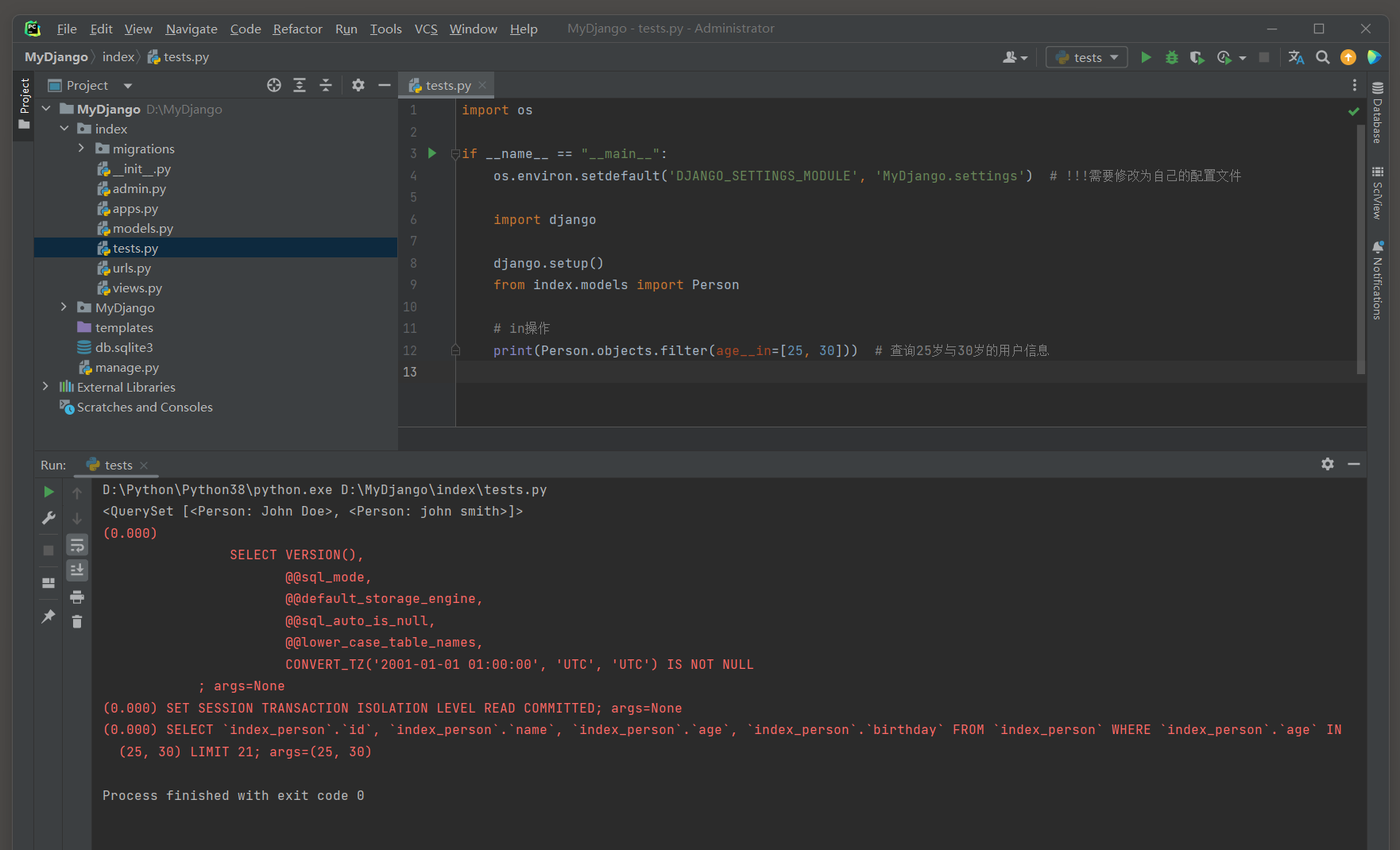
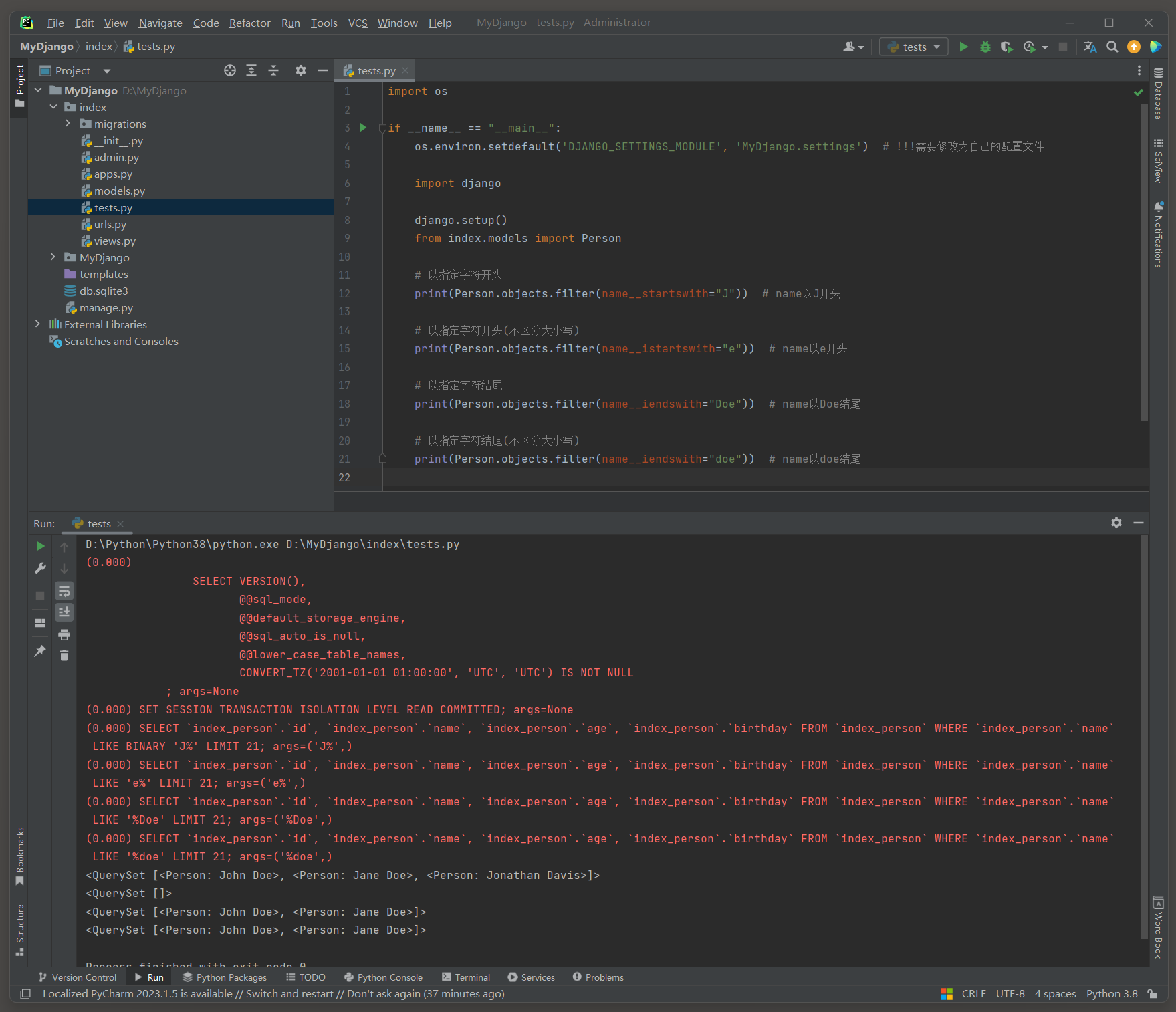
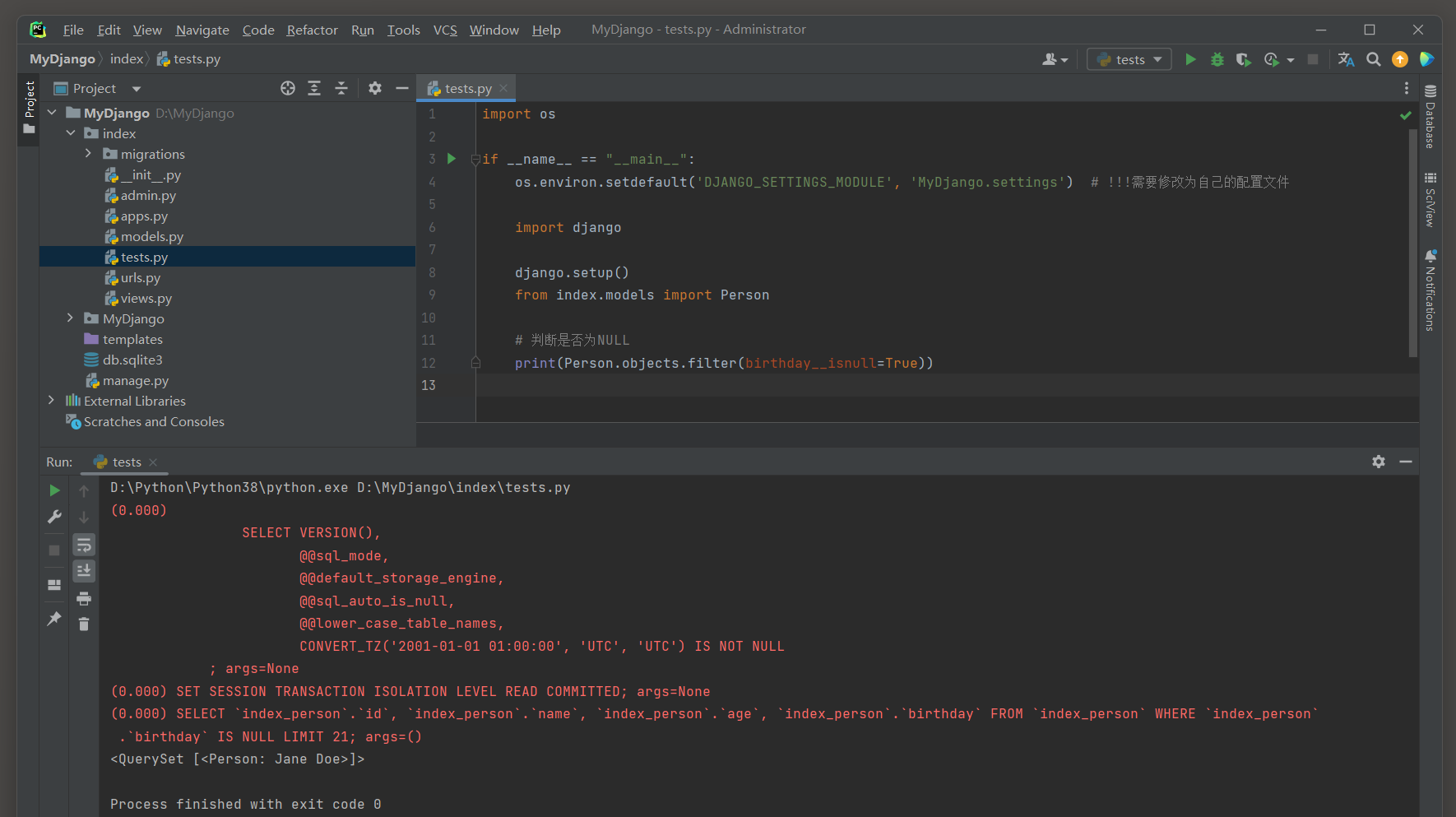
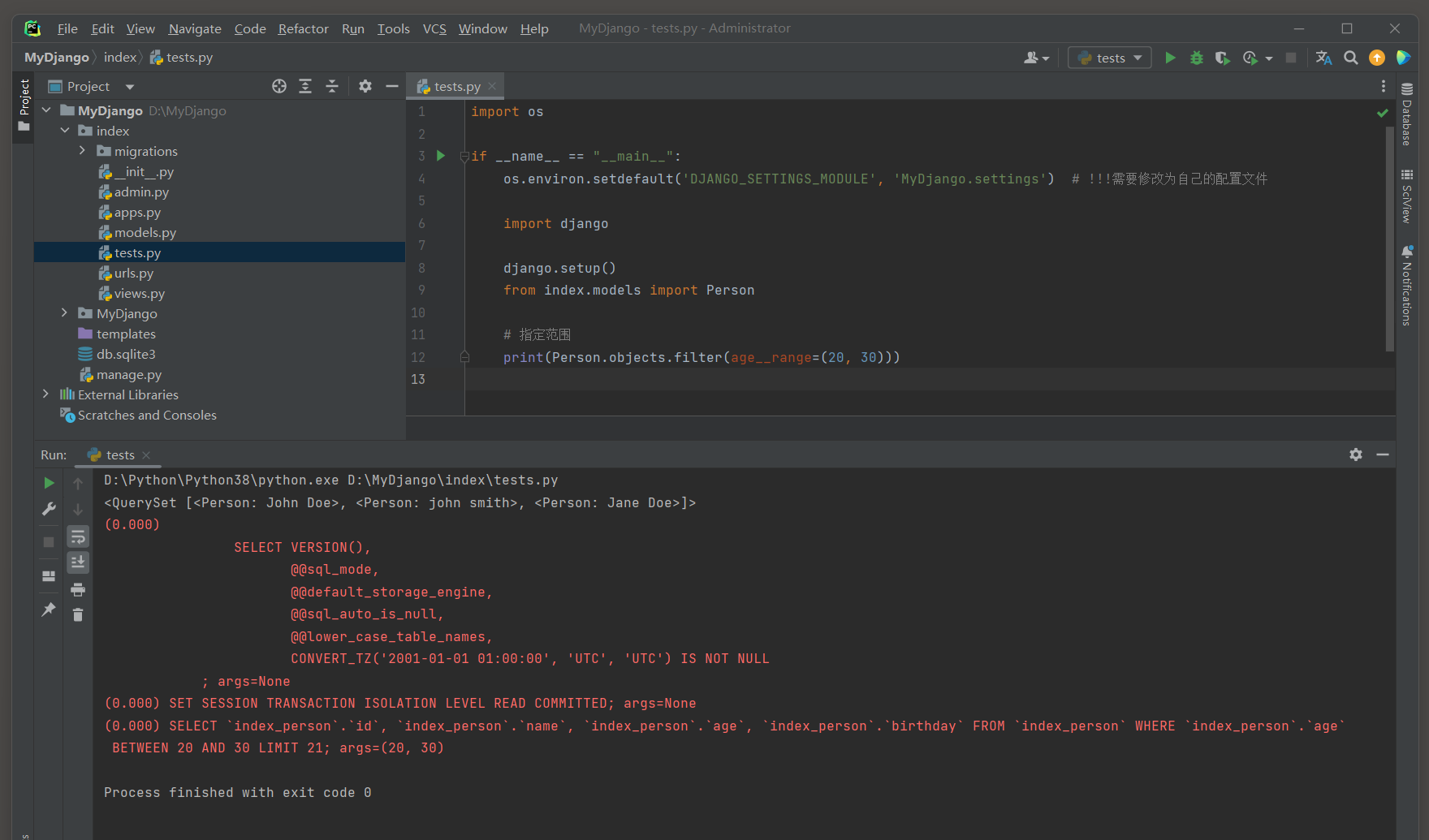
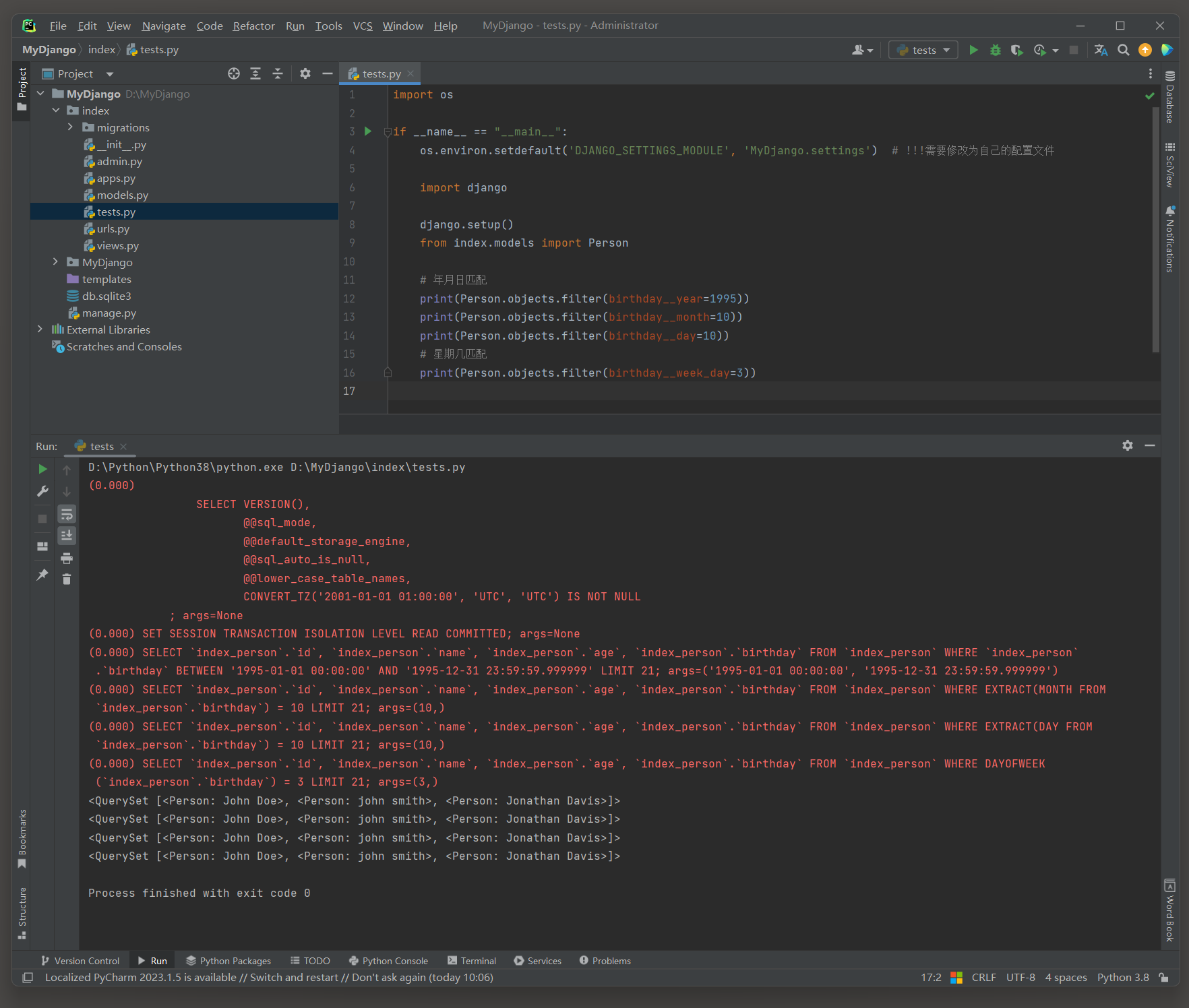
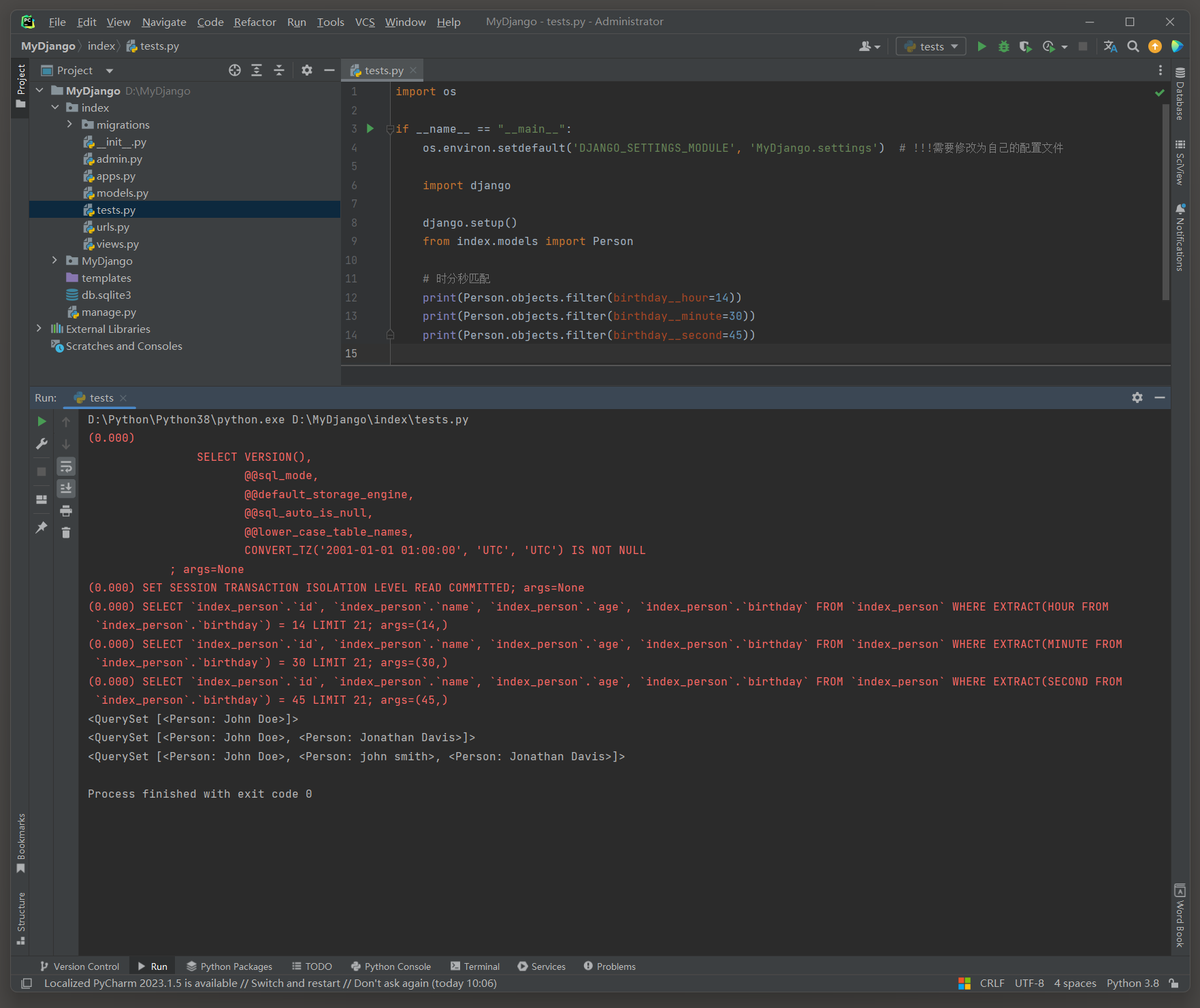
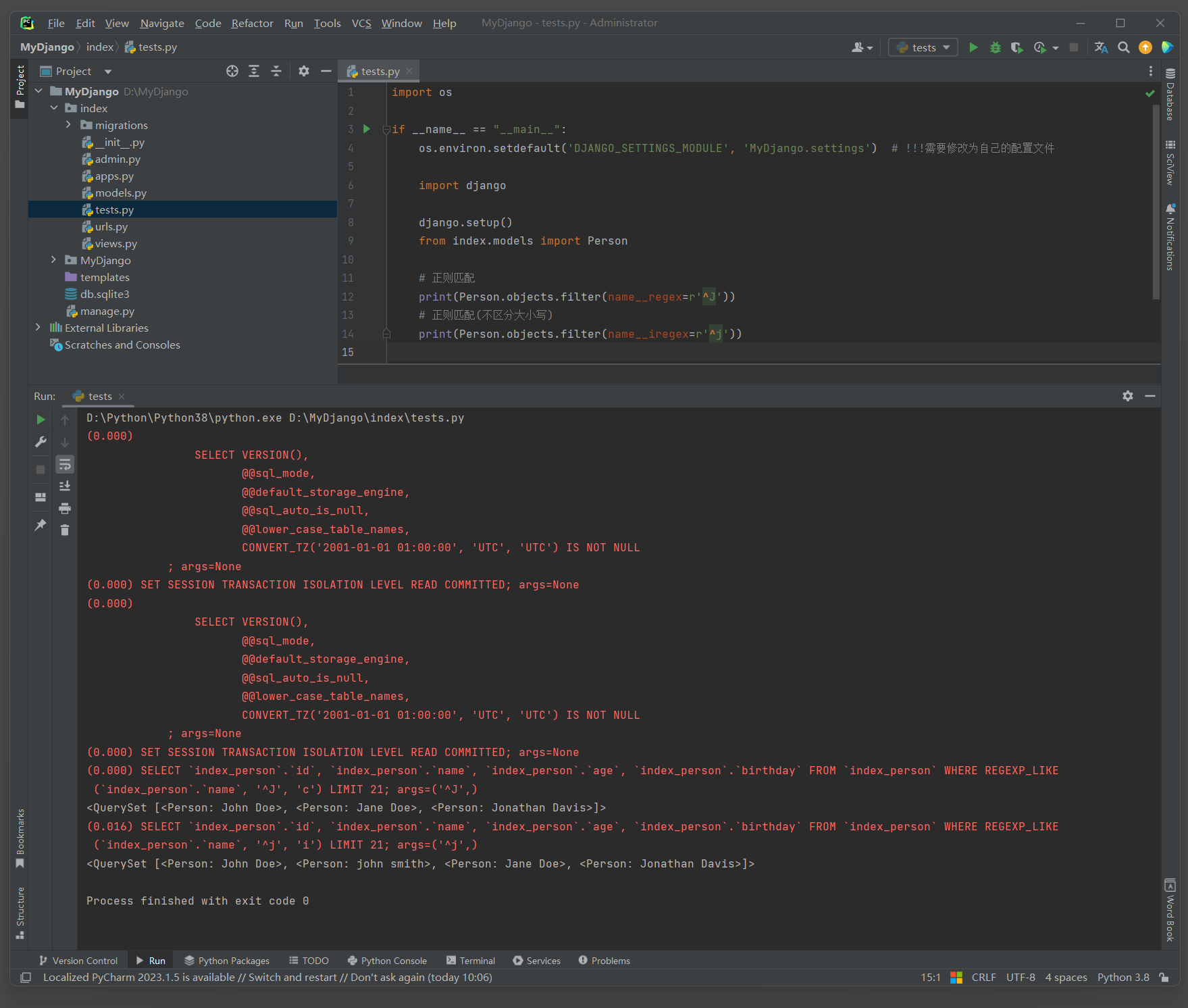
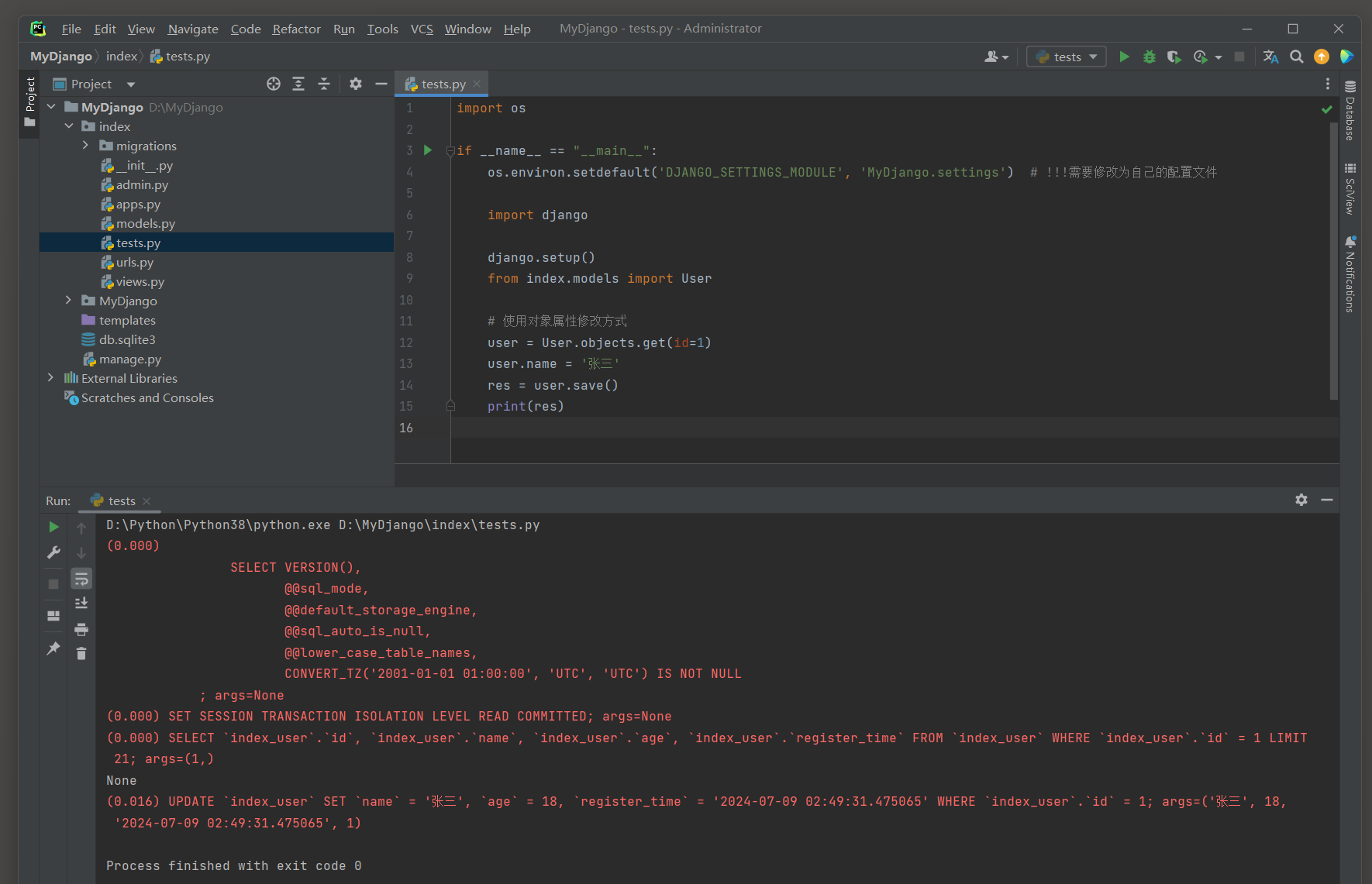
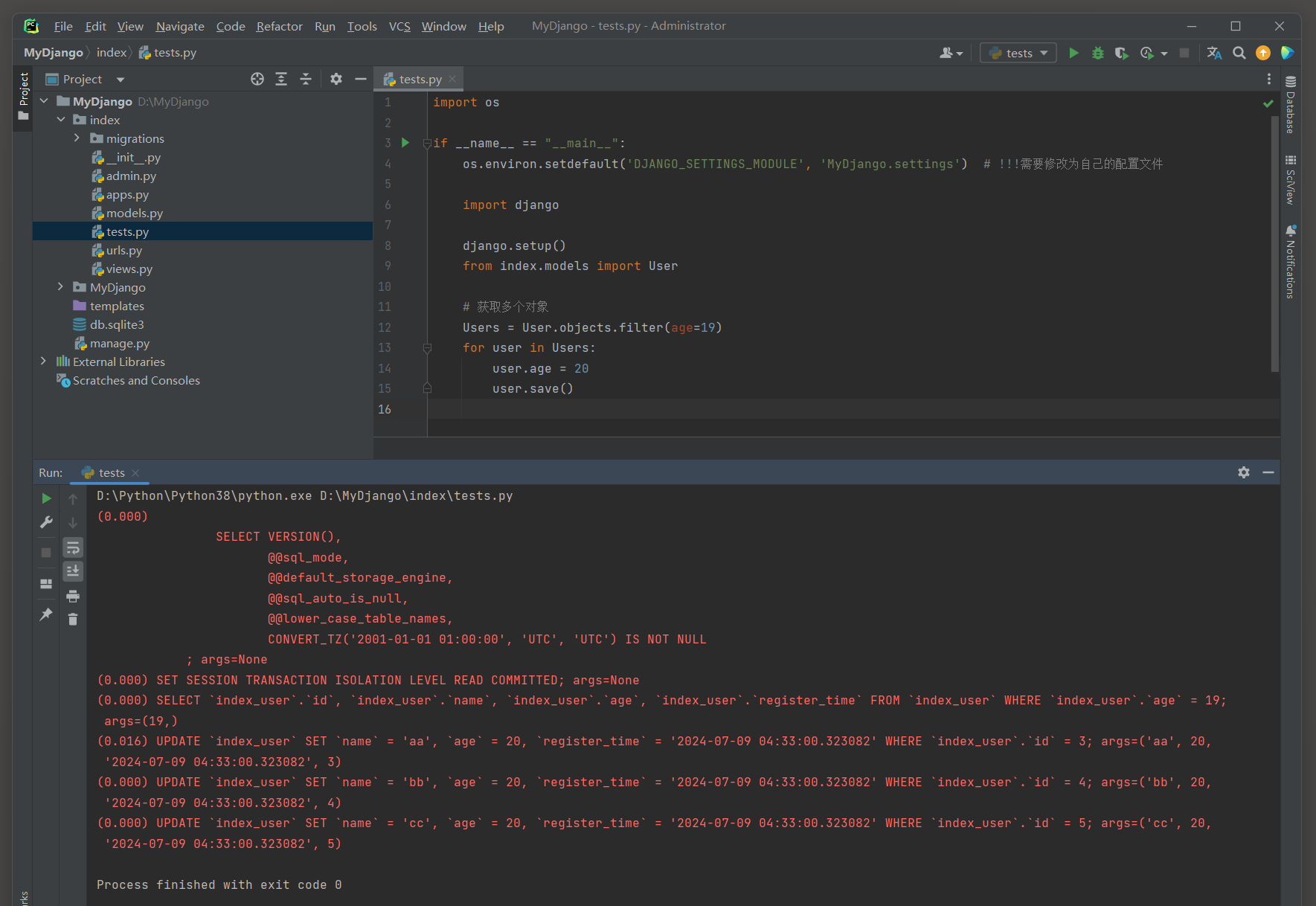
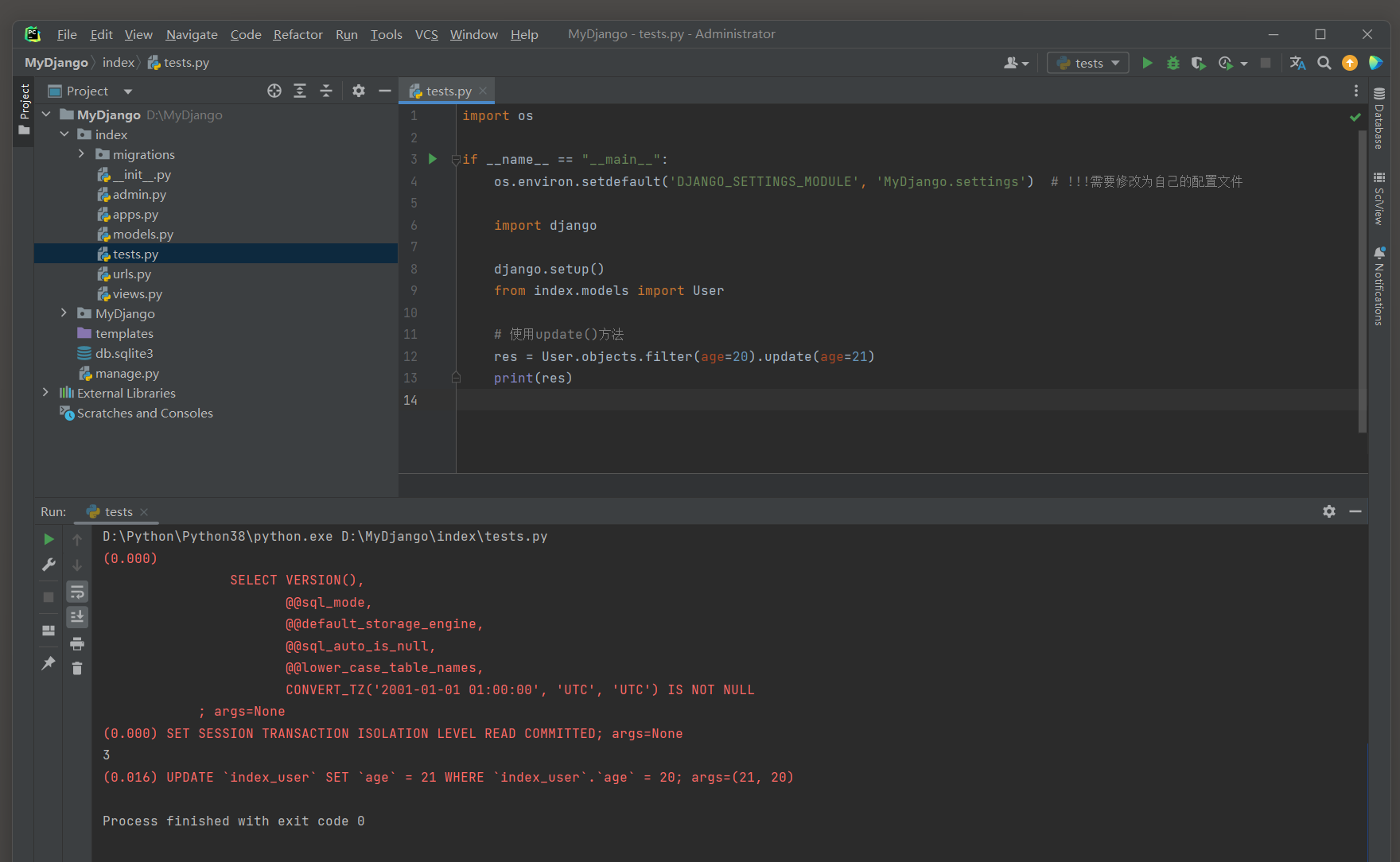
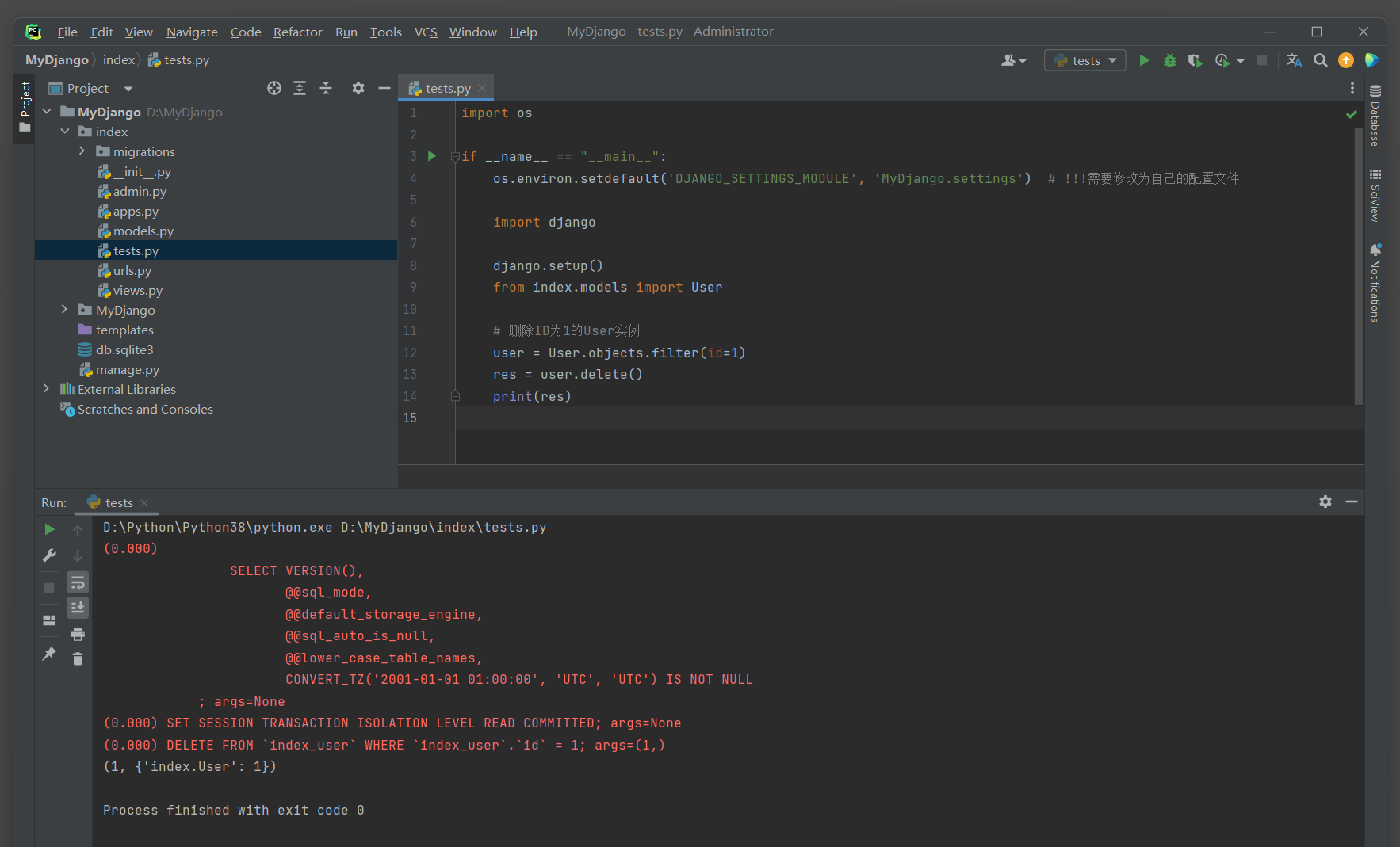
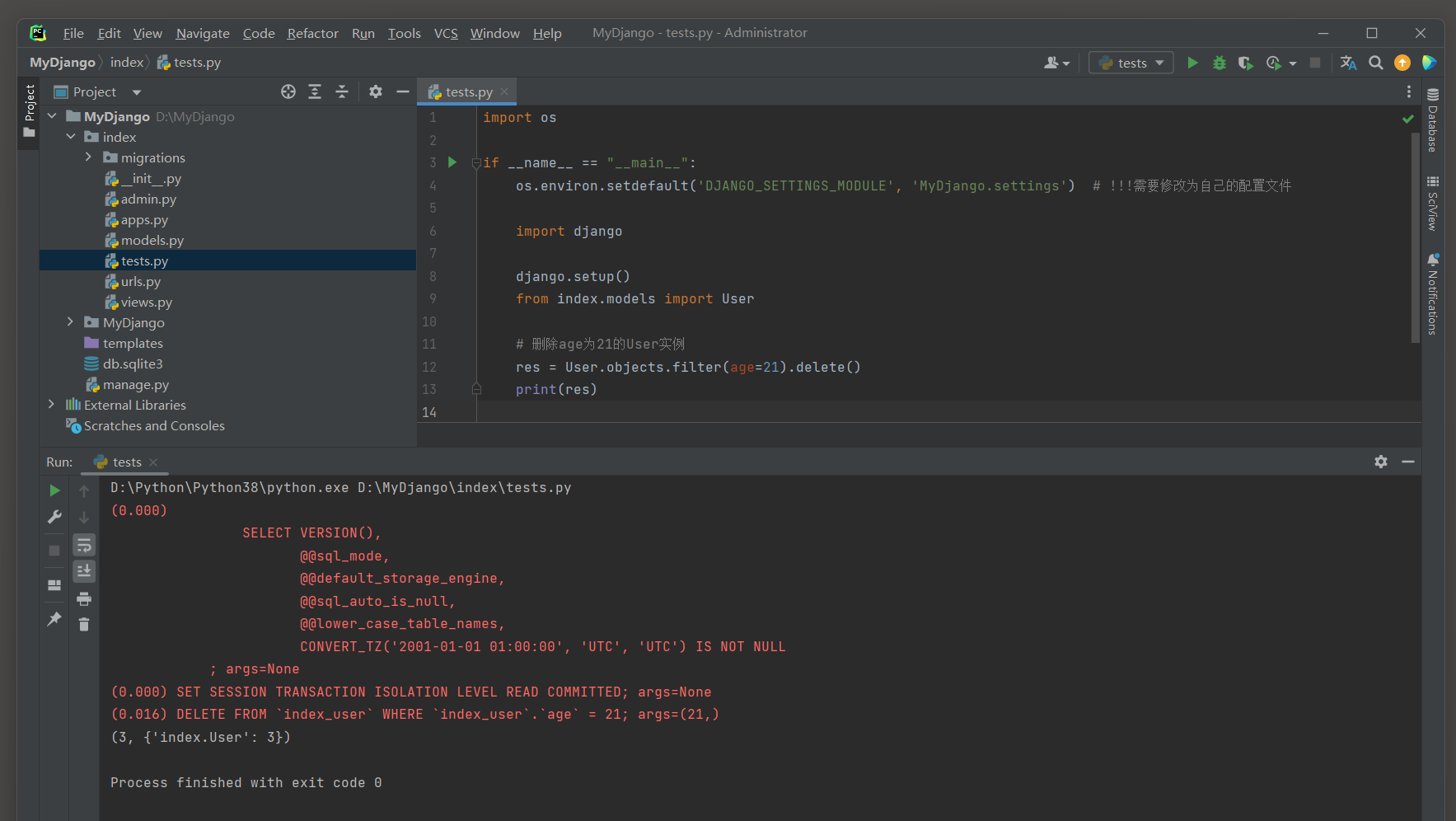
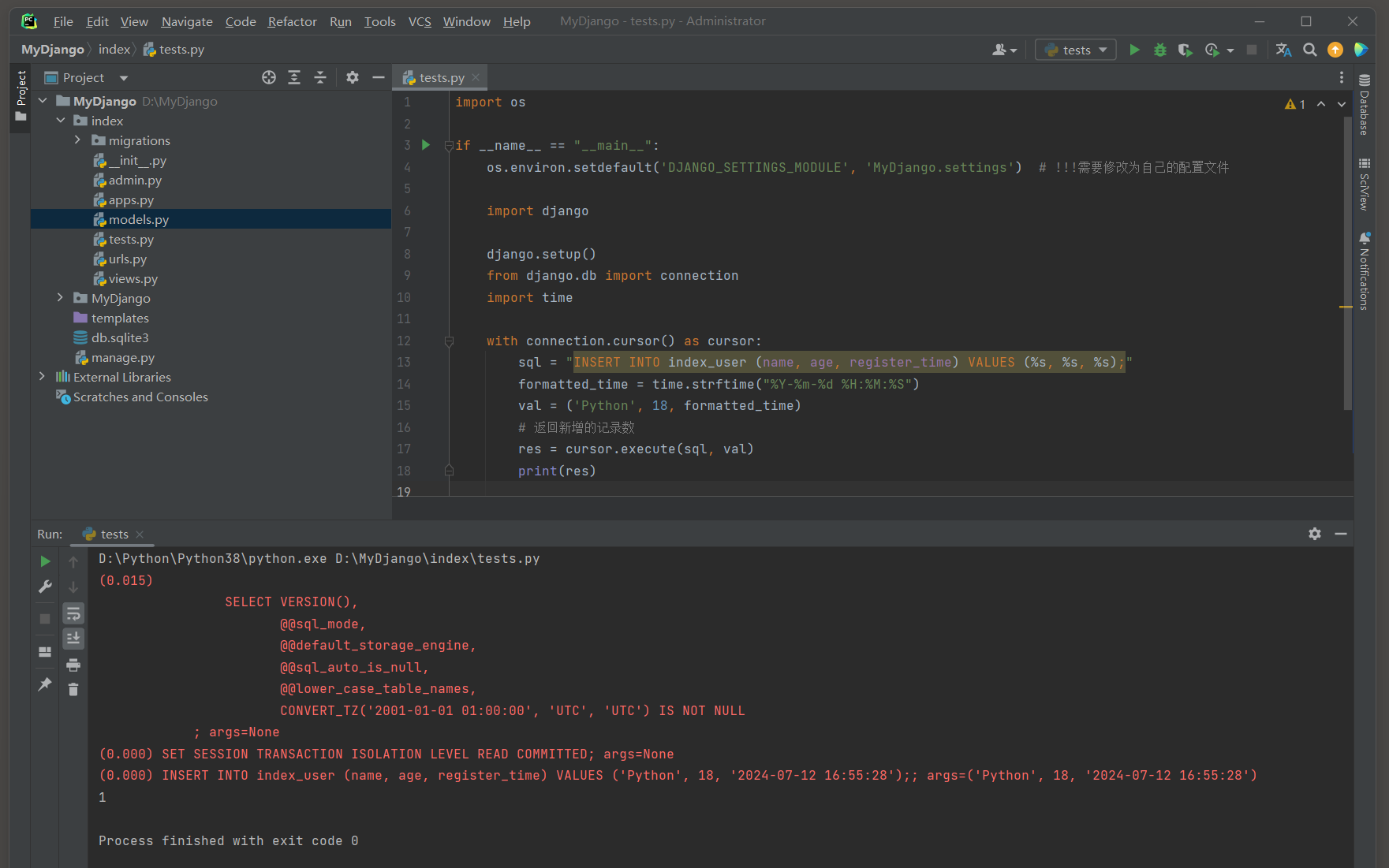
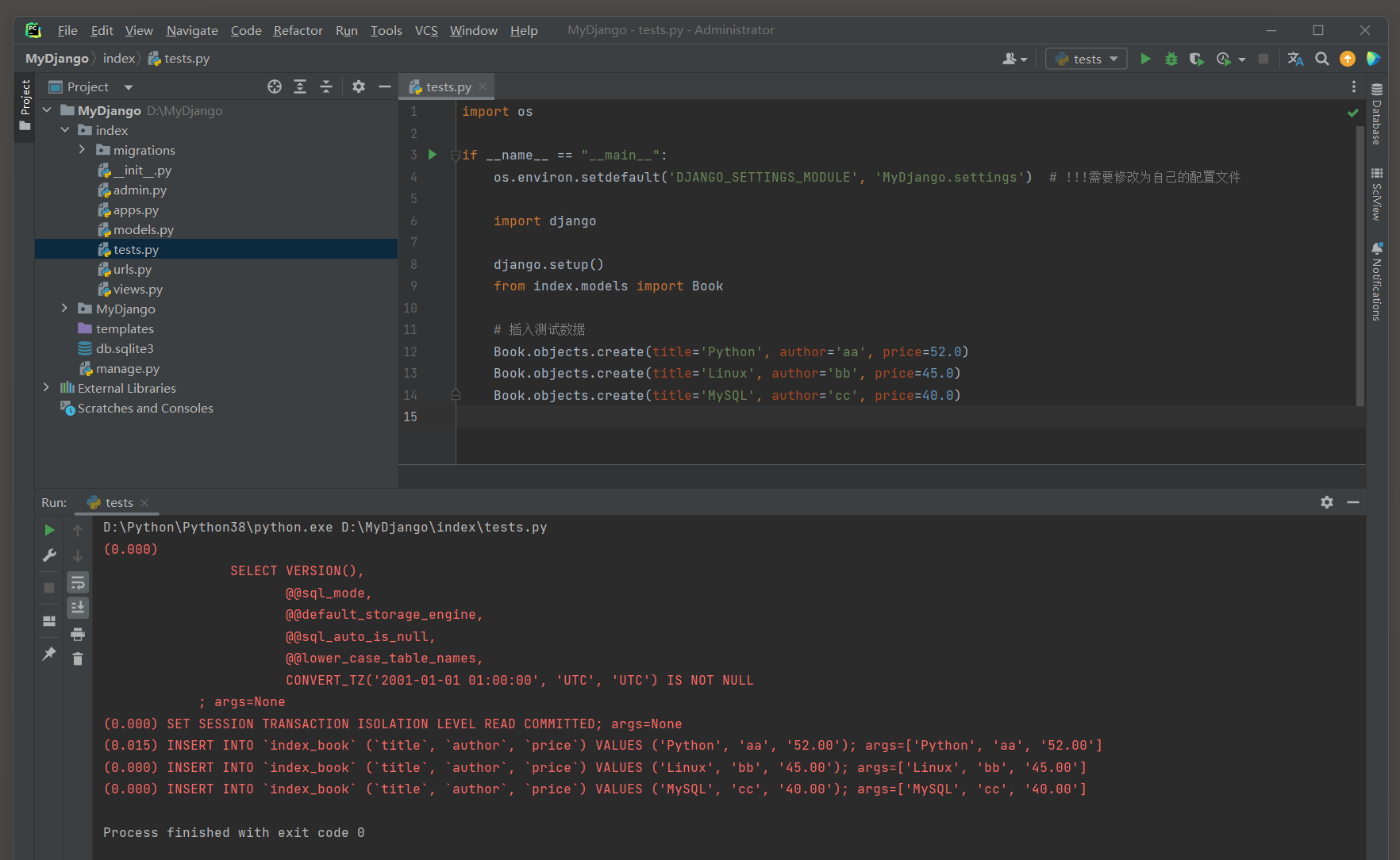
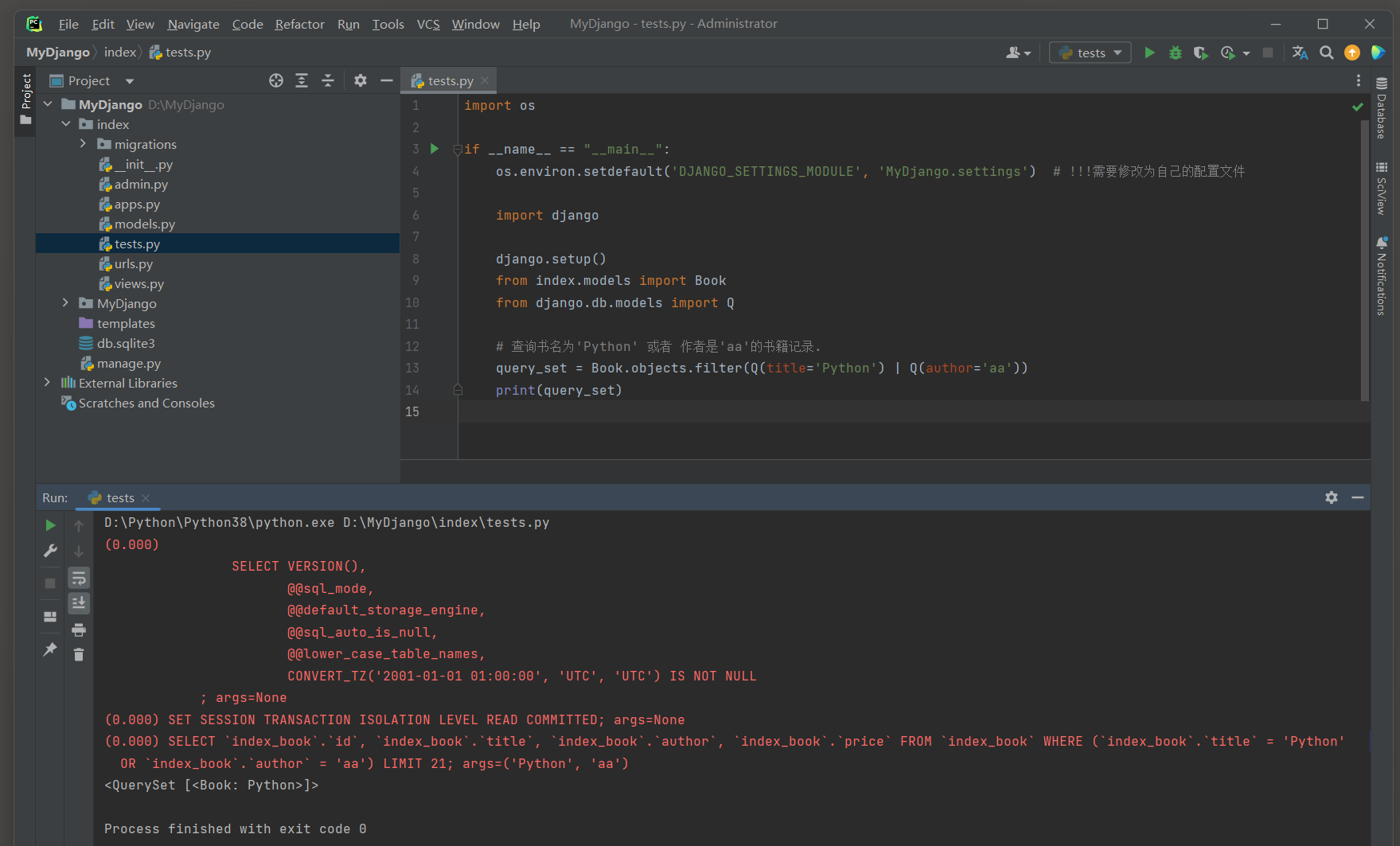
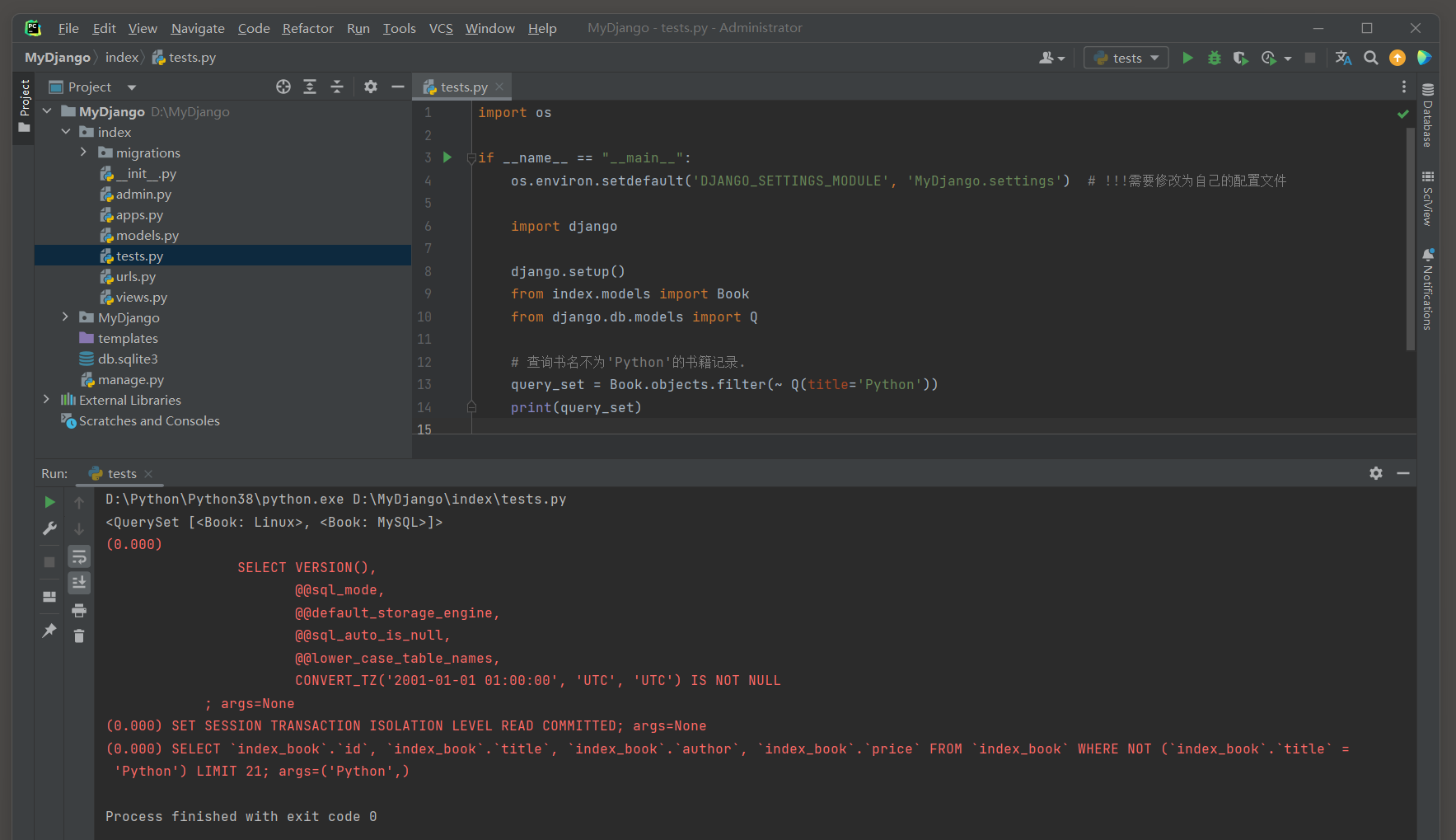
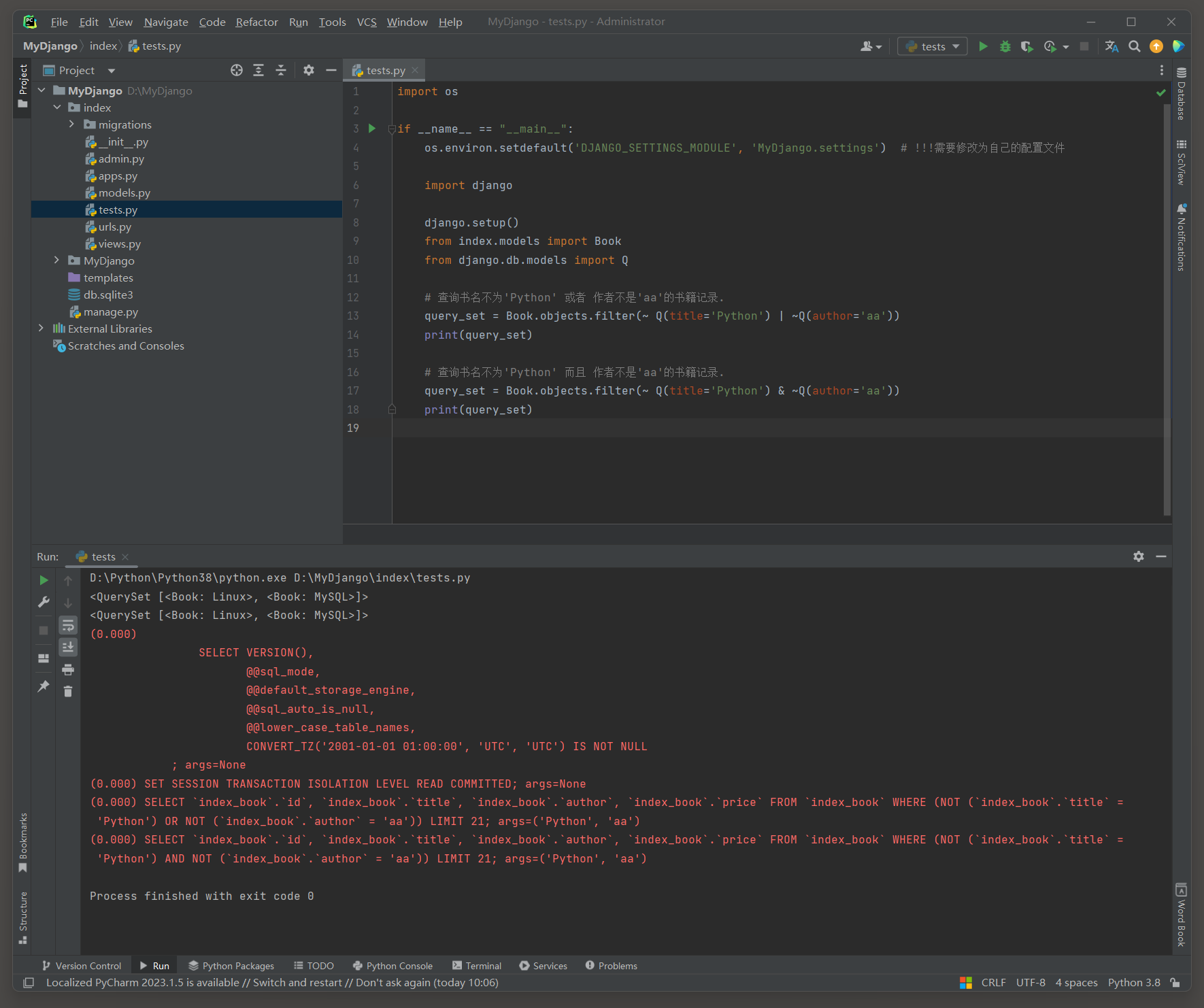
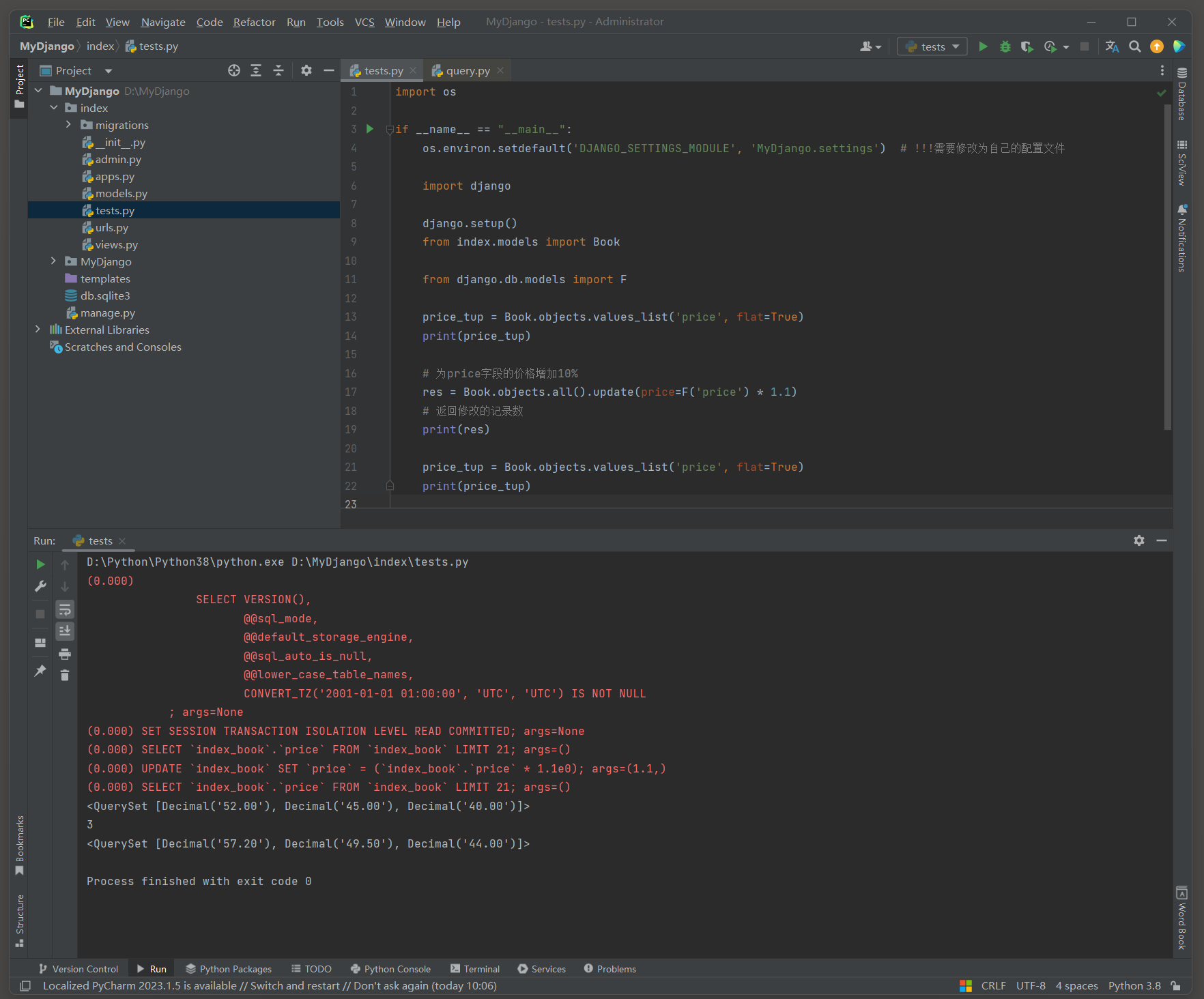
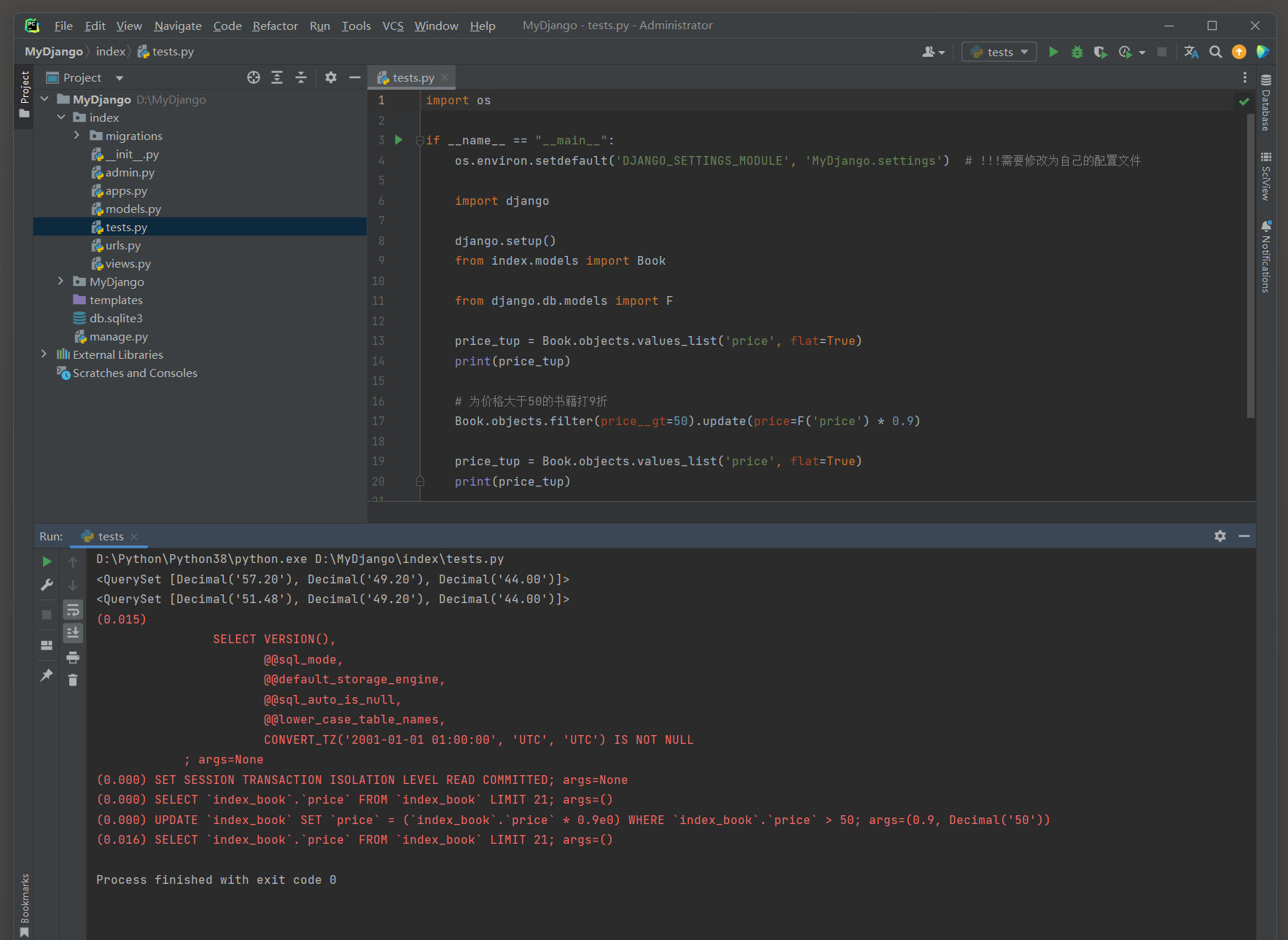
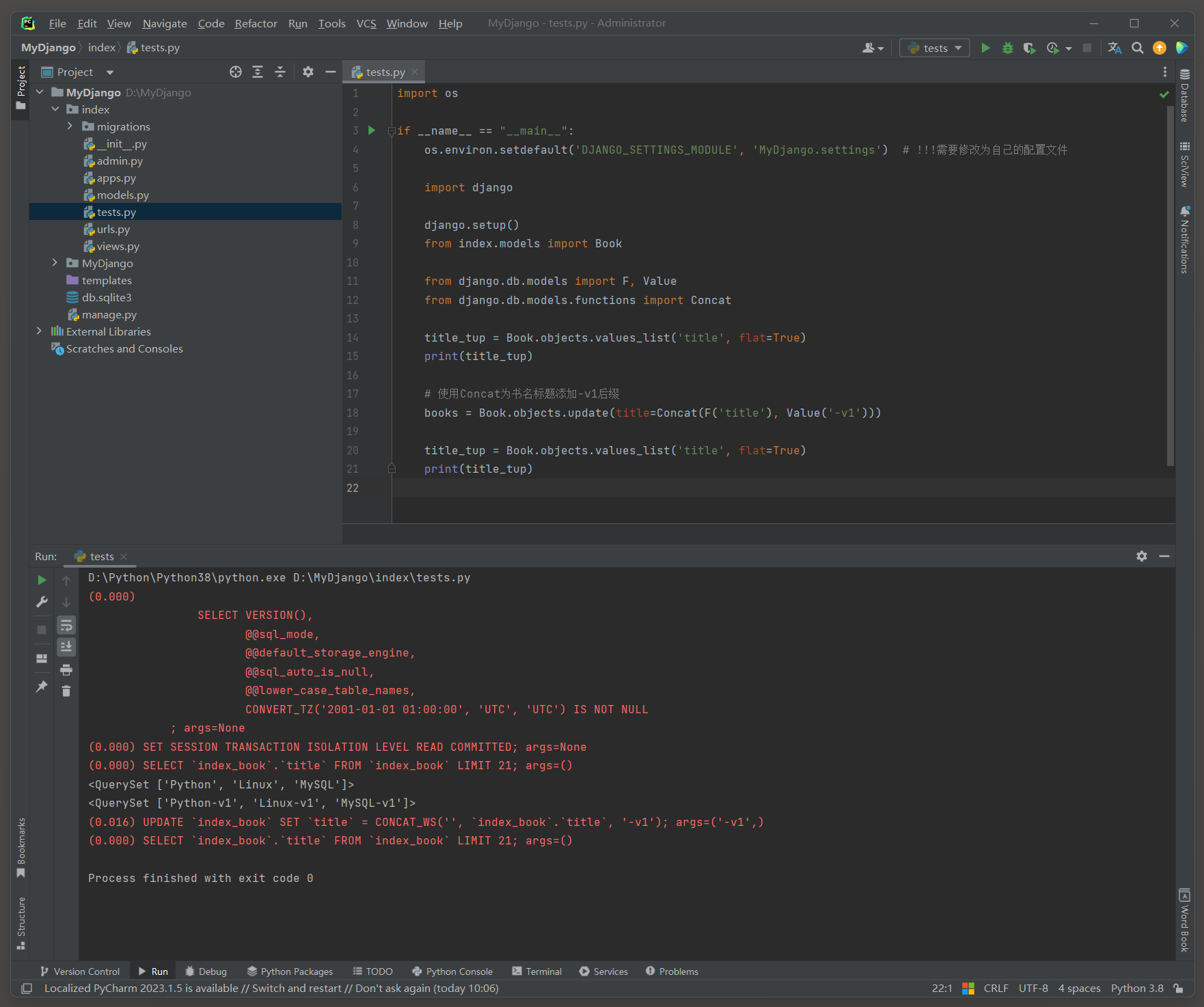
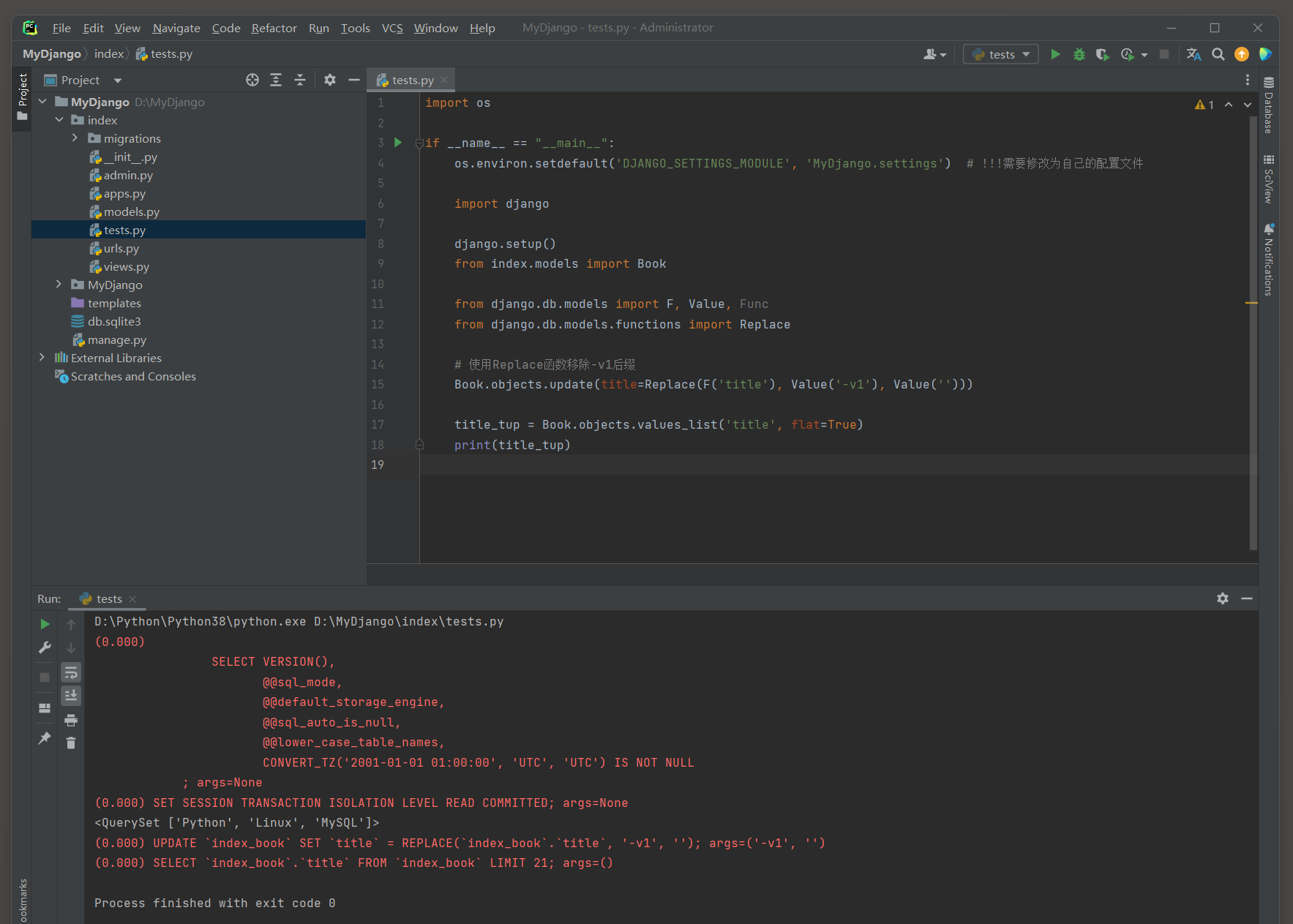
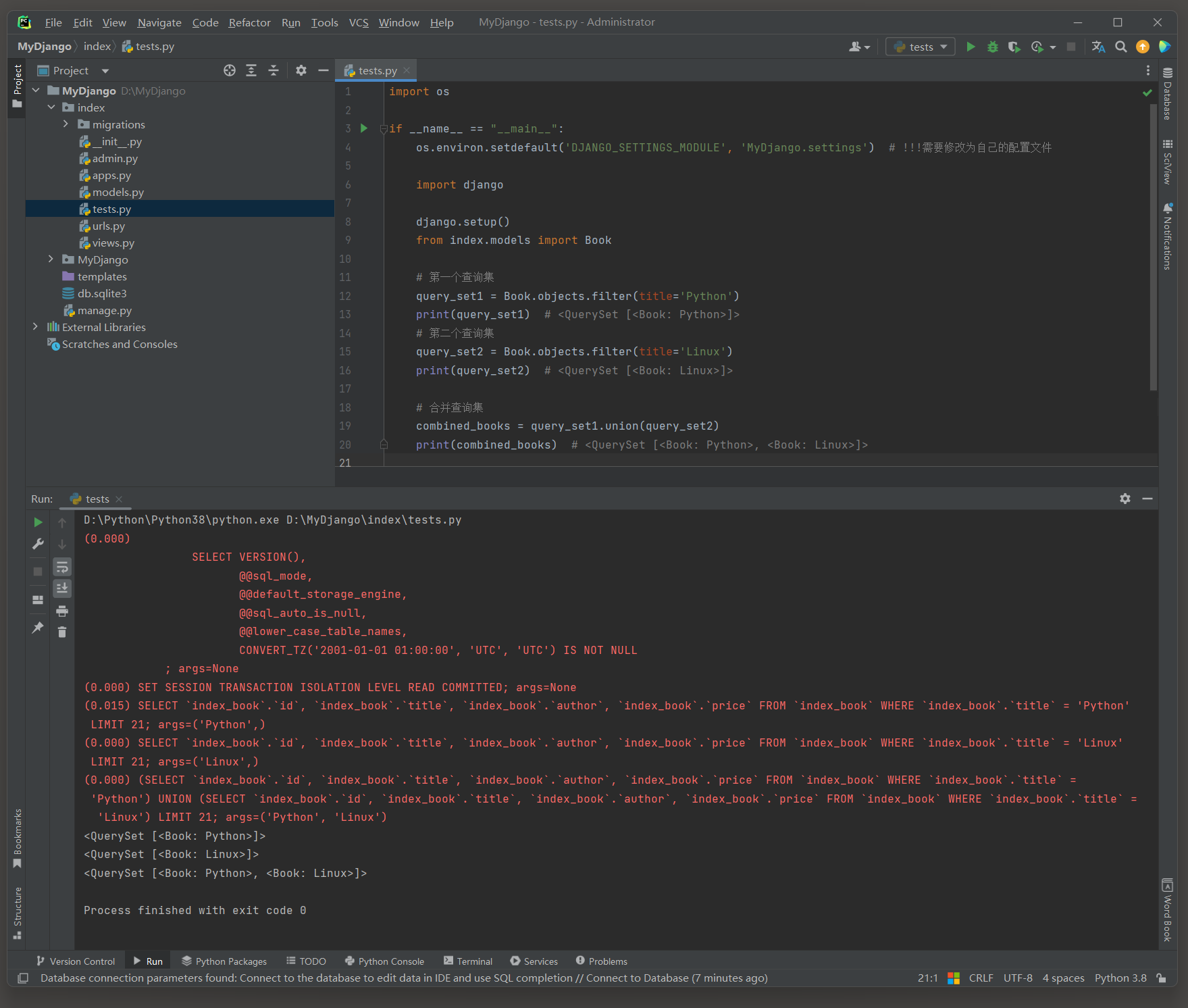
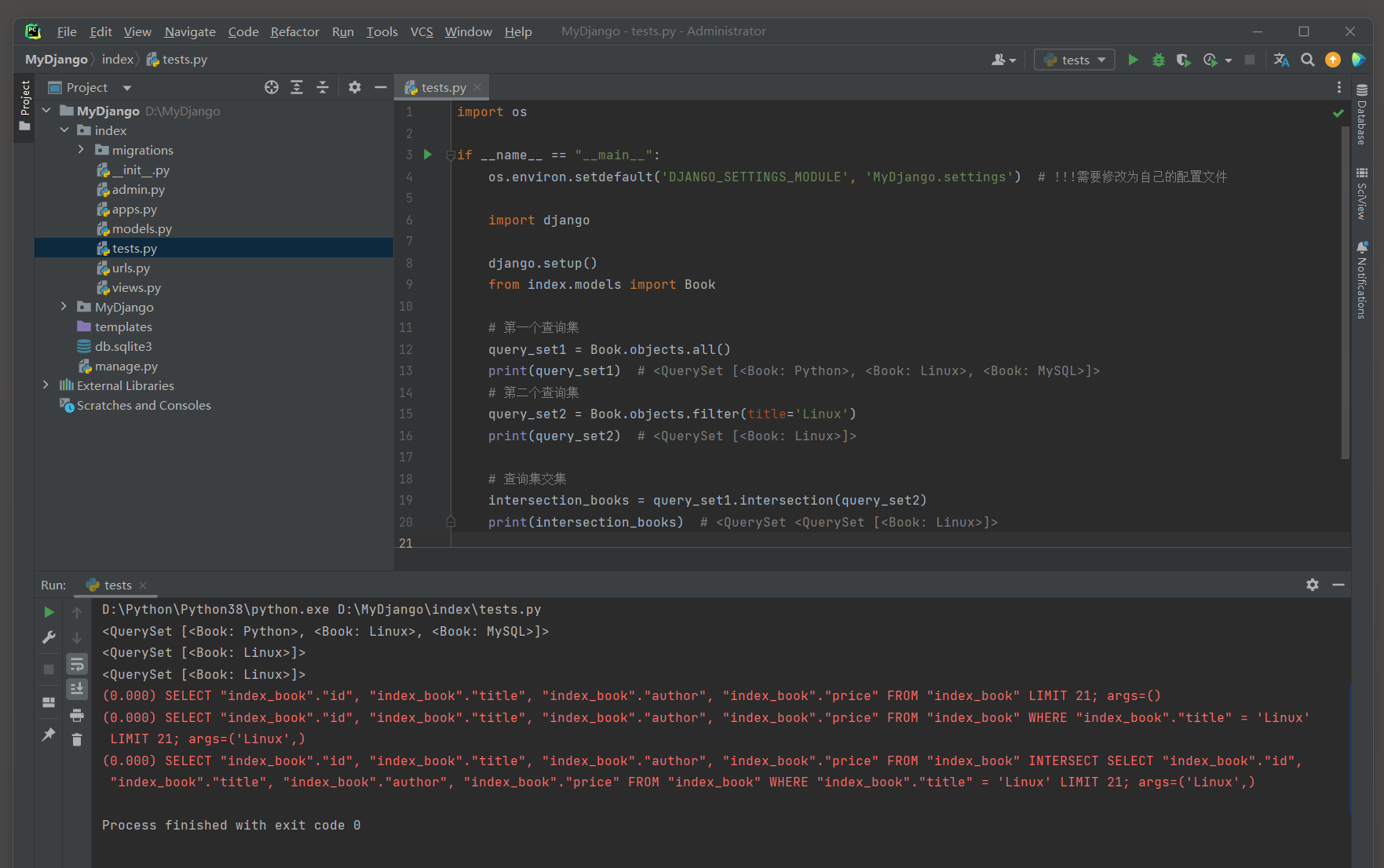
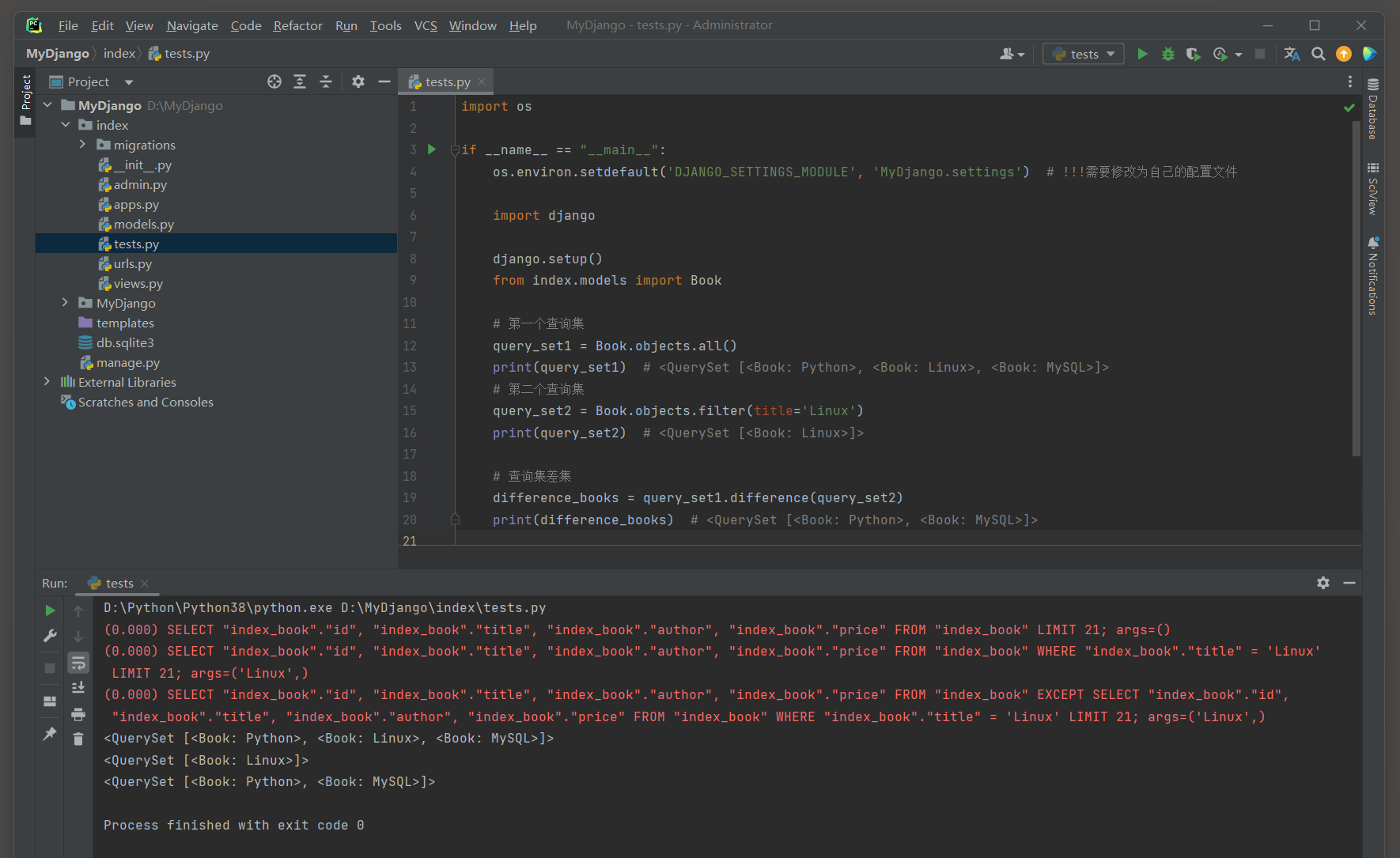
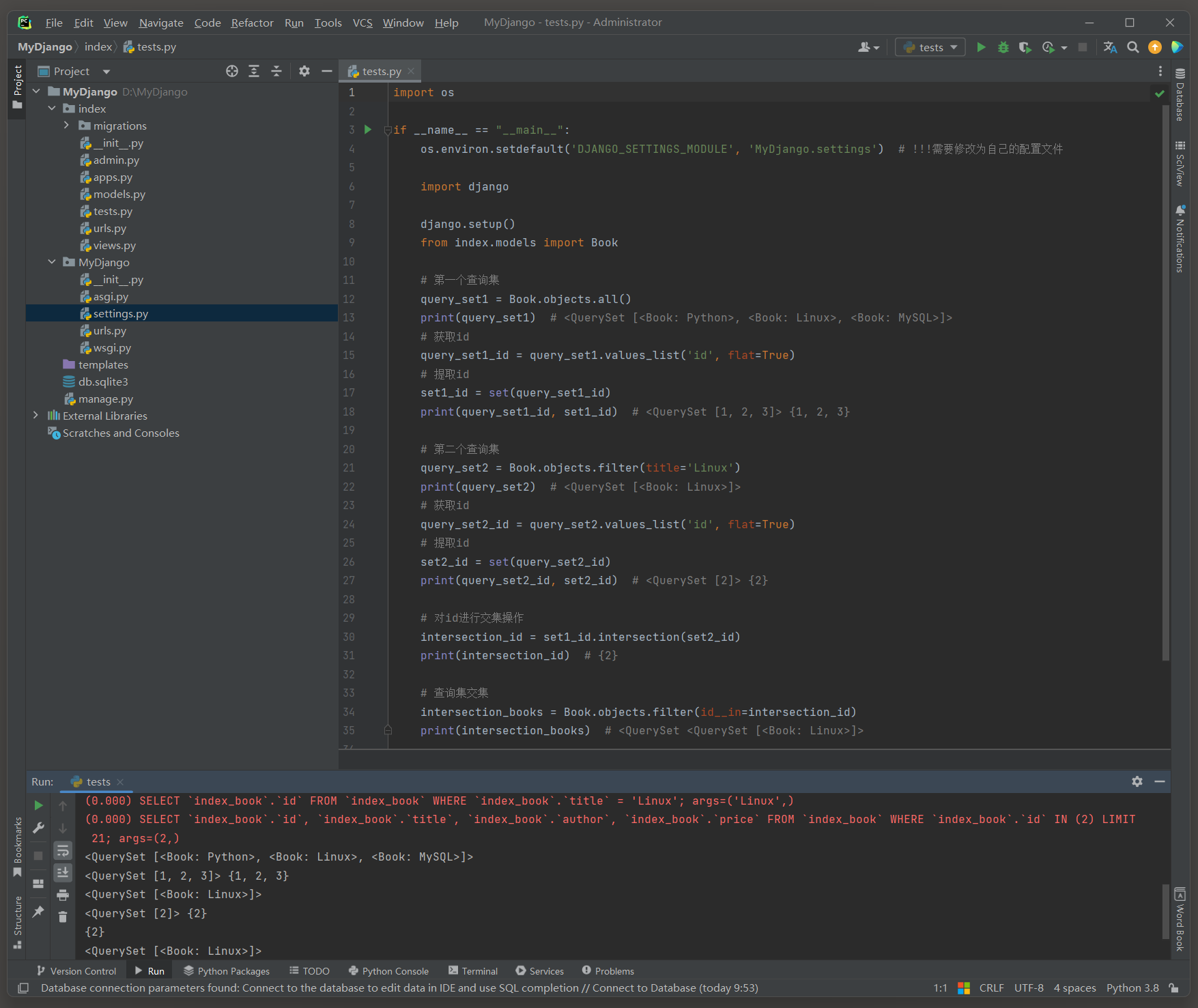















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









