1. 互联网知识介绍
互联网: 是由网络设备(网线, 路由器, 交换机, 防火墙...)和一台台计算机链接而成.
互联网建立的目的: 数据的共享/传递.
俗称的'上网': 由用户端计算机发送请求给目标计算机, 将目标计算机的数据下载到本地的过程.
浏览器提交请求 -> 下载页面代码 -> 解析/渲染成页面.
2. 爬虫
2.1 爬虫介绍
爬虫的价值: 互联网中最有价值的便是数据.
爬虫程序主要做的事情: 模拟浏览器提交请求下载页面代码, 提取有用的数据存放到数据库或文件中.
2.2 基本流程
* 1. 发送请求: 使用http向目标站点发起Request请求对象.
Request请求对象: 将用户自己的信息通过浏览器(socket client) 发给服务器(socket server)
Request包含: 请求首行, 请求头, /r/n, 请求体
* 2. 获取相应内容: 服务器正常响应, 会接受到Response响应对象.
Response响应对象: 服务器接受请求, 分析用户发送的请求, 返回对应数据.
Response包含: 响应首行(响应状态码), 响应头, /r/n, 响应体(html, json, 图片, 视频...)
* 3. 解析内容:
解析html数据: 正则表达式, 第三方解析库(Beautifulsoup, pyquery...)
解析json数据: json模块
解析二进制数据: 以b模式写入到文件
* 4. 保存数据: 保存到数据库或文件中.
2.3 爬虫所需工具
框架: scrapy
工具:
1. 请求库: requests, selenium
2. 解析库: 正则, beautifulsoup, pyquery
3. 存储库: Mongodb, Mysql, Redis, 文件
3. Request请求对象
爬虫模拟发送请求时会在请求头中添加数据(网站的登入信息).
3.1 请求方法
常用的请求方法: GET, POST
其他请求方法: HEAD, PUT, DELETE, OPTHONS
get请求参数直接放在url后面, 最终的数据并拼接成 url?k1=v1&k2=v2 格式.
post请求参数放在请求体中
3.2 请求url
url: 统一资源定位符.
url编码: https://www.baidu.com/?wd=xx
3.3 请求头
客户端使用的设备信息:
Host: 访问的站点
User-agent: 请求头中如果没有user-agent客户端配置, 服务器可能将你当做一个非法用户.
用户的网站通信证
cookies: 针对需要登入才能操作的页面必须提供
Referer: 大型网站通常都会根据该参数判断请求的来源
3.4 请求体
post请求方法, 请求体是fromat data
登入窗口, 文件上传等信息会被附加到请求体中.
登入, 输入错误的信息提交才能看到post, 正确登入之后会跳转无法捕捉post查看
4. Response响应对象
4.1 响应状态
200: 代表成功
301: 代表跳转
403: 权限
404: 文件不存在
505: 服务器错误
4.2 Respone header
set-cookie: 浏览器将cookie保存.
4.3 preview网页源代码
请求资源内容(html, 图片...)
二进制数据
未知加密数据(加密的网页数据, 需要解密, 解密是使用js的方法在自己的电脑上解密的, 需要将这个方法复制)
页面的加载过程:
加载一个页面, 通常先加载document文档, 在解析document文档的时候, 遇到图片链接,
则针对超链接发起下载图片的地址.
5. requests请求库使用
5.1 请求库介绍
requests库的作用是模拟浏览器发送请求.
内置模拟浏览器发送请求模块:
1. python2 内置 urllib2
2. python3 内置 urllib3 (requests库本质是在这个基础上封装)
5.2 安装模块
安装requests模块: pip install requests
Collecting charset-normalizer~=2.0.0
Downloading requests-2.28.0-py3-none-any.whl (62 kB) # 下载requests模块
|████████████████████████████████| 62 kB 30 kB/s
Collecting urllib3<1.27,>=1.21.1
Downloading urllib3-1.26.9-py2.py3-none-any.whl (138 kB) # 下载urllib3模块
|████████████████████████████████| 138 kB 27 kB/s
...其他...
5.3 请求库的方法及参数
注意: requests库发送请求将网页内容下载下来以后, 并不会执行js代码.
这需要我们自己分析目标站点然后发起新的request请求.
对象的方法: GET, OPTIONS, HEAD, POST, PUT, PATCH, DELETE.
常用请求方式:
requests.get('地址', 关键字参数)
requests.post('地址', 关键字参数)
...
构造参数:
:param data: (可选) 字典、元组列表、字节列表或在正文中发送的类似文件的对象.
:param json: (可选) 一个 JSON 可序列化 Python 对象,用于在 Request的主体中发送。
:param headers: (可选) 字典, 发送的 HTTP 标头
:param cookies:(可选) Dict或CookieJar对象.
:param files:(可选) 字典key:file-like-objects 或 {'name': file-tuple}) 用于多部分编码上传。
file-tuple可以是:
2-tuple ('filename', file obj)
3-tuple ('filename', fileobj, 'content_type')
4-tuple ('filename', fileobj, 'content_type', custom_headers)
content-type 是定义给定文件的内容类型的字符串,
custom_headers是一个类似于 dict 的对象,其中包含要为文件添加的附加标题。
...
访问成功之后, 返回一个响应对象.
响应对象方法:
.status_code 响应状态码
.url 访问的地址
.text 网页文本数据
.content 二进制数据
.iter_content() 二进制数据迭代器
5.4 GET请求与POST请求的区别
(HTTP默认的请求方法就是GET)
GET请求:
* 1. 没有请求体
* 2. 数据必须在1K之内
* 3. 请求数据会暴露在浏览器的地址栏中.
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL, 那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时, 表单默认使用GET请求, 但可以设置为POST
POST请求:
* 1. 数据不会出现在地址栏中
* 2. 数据的大小没有上限
* 3. 有请求体
* 4. 请求体中如果存在中文, 会使用URL编码!
requests.post()用法与requests.get()完全一致,
特殊的是requests.post()有一个data参数用来存放请求体数据.
5.5 GET请求
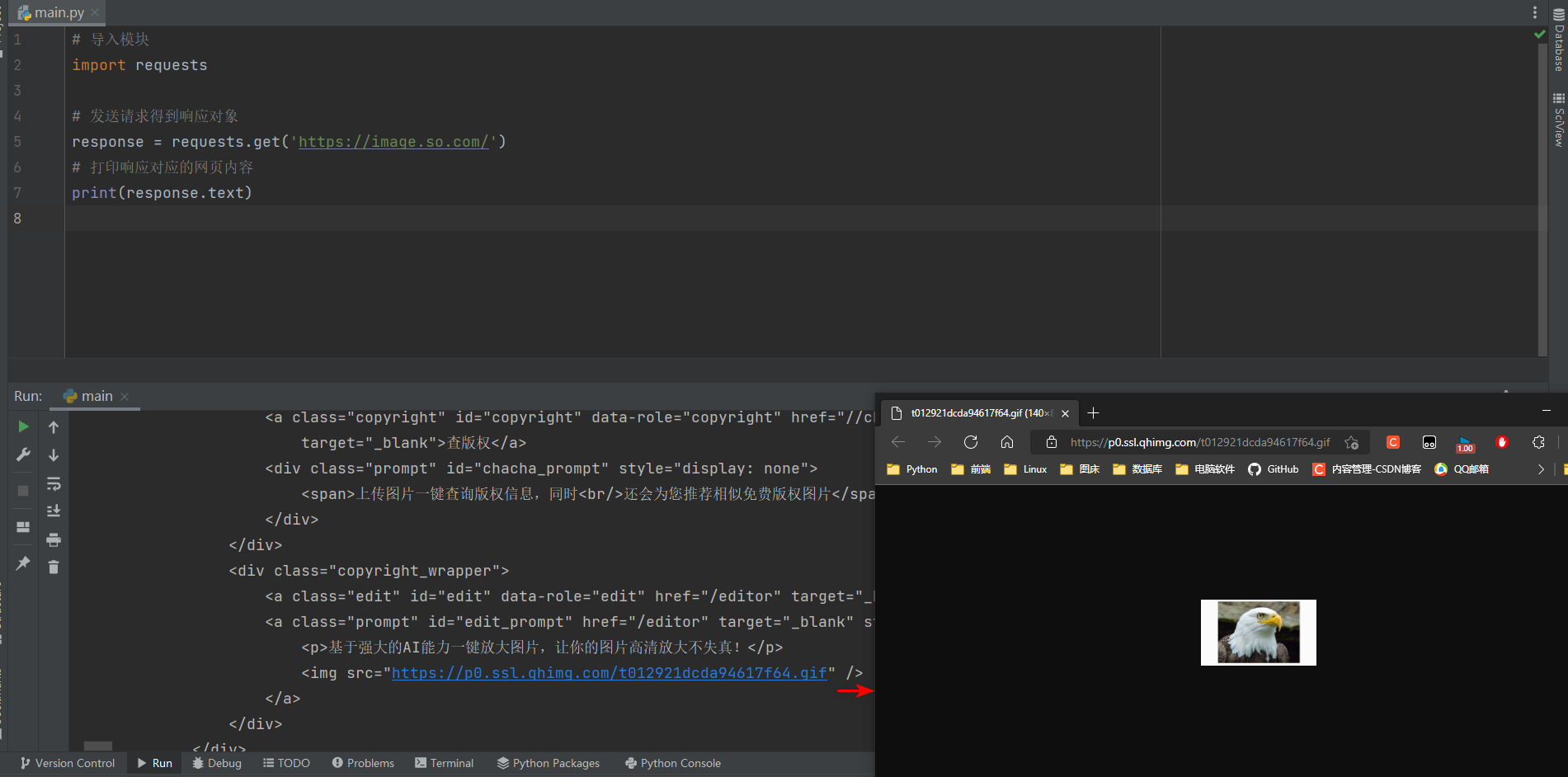
访问网站, 可以直接获取到.
import requests
response = requests.get('https://image.so.com/')
print(response.text)
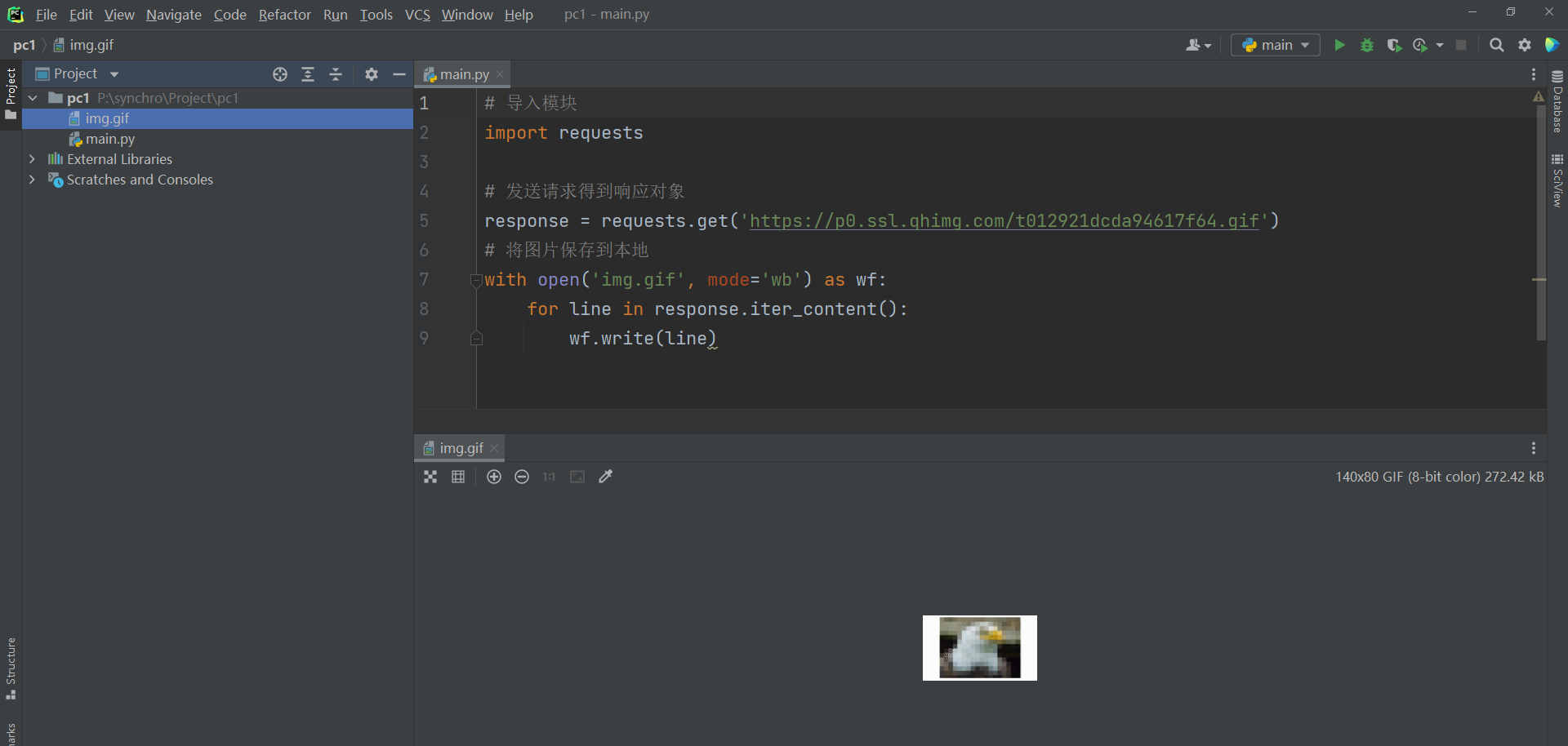
将数据保存到本地.
import requests
response = requests.get('https://p0.ssl.qhimg.com/t012921dcda94617f64.gif')
with open('img.gif', mode='wb') as wf:
for line in response.iter_content():
wf.write(line)
1. 携带参数
通常在发送请求时都需要带上请求头, 请求头是将自身伪装成浏览器的关键.
常见的有用的请求头如下:
Host: 访问的站点
Referer: 大型网站通常都会根据该参数判断请求的来源
User-Agent: 客户端设备信息
Cookie : ookie信息虽然包含在请求头里, 但requests模块有单独的参数来处理他,headers={}内就不要放它了
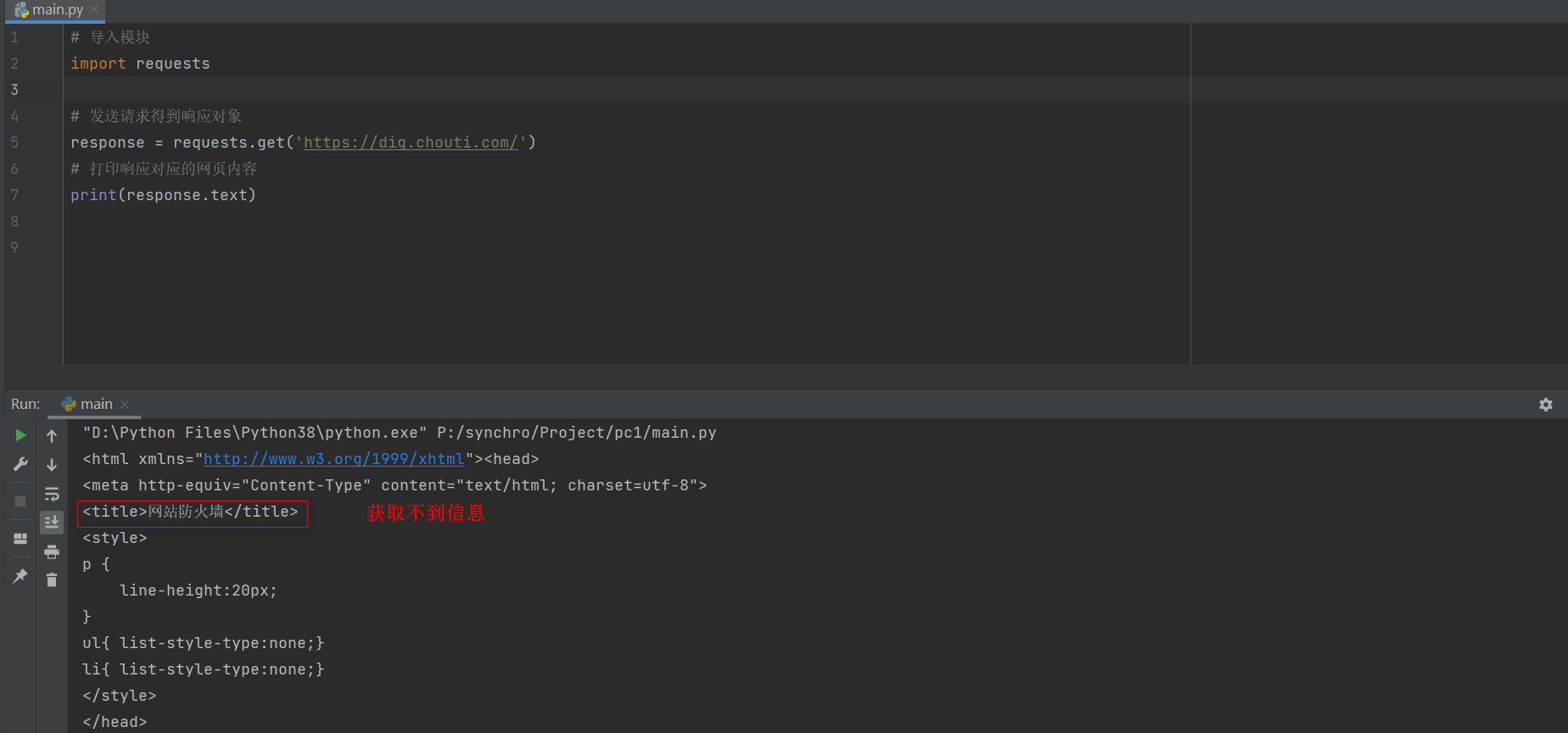
下例网站的信息无法直接获取到.
import requests
response = requests.get('https://dig.chouti.com/')
print(response.text)
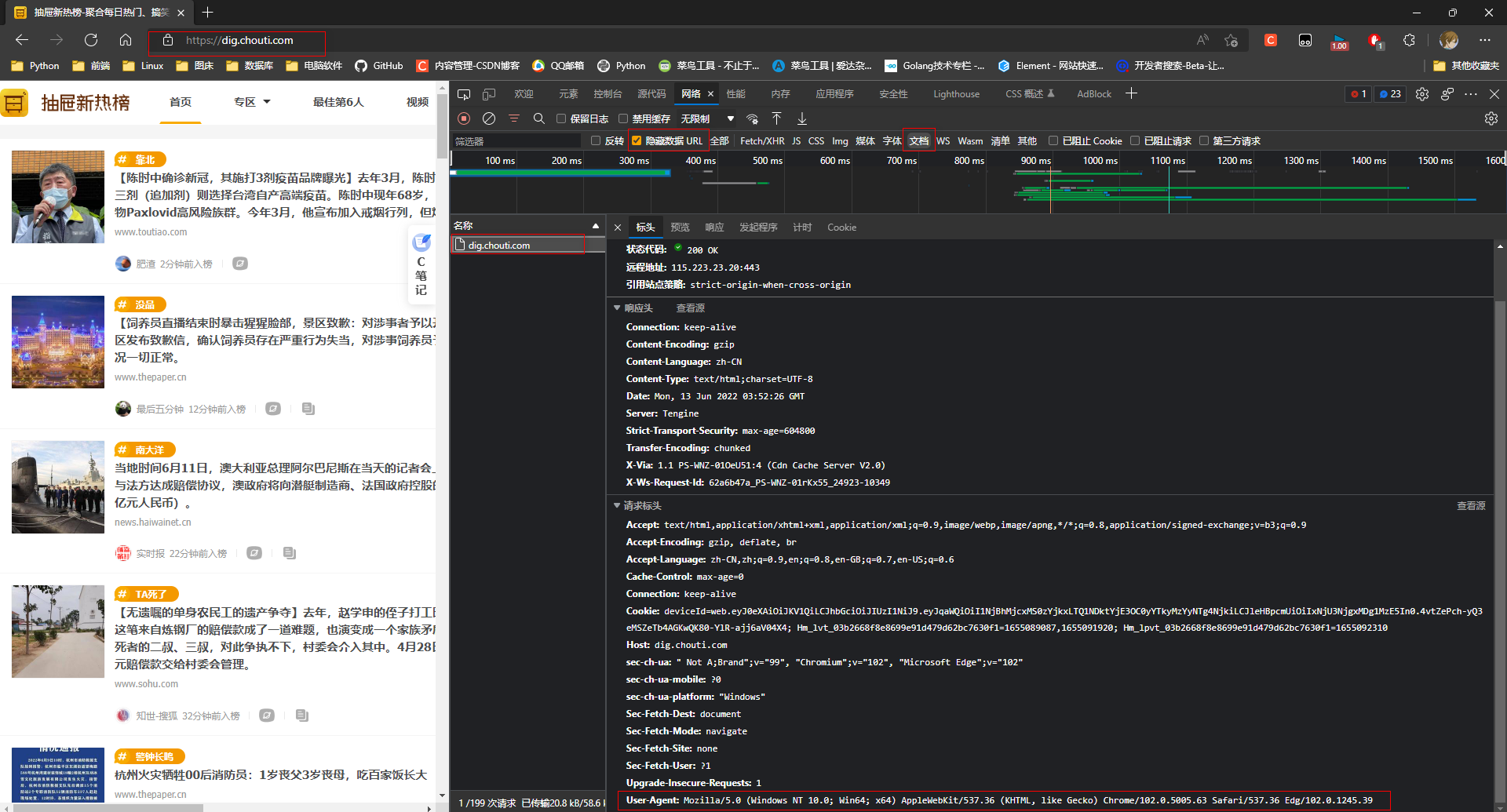
2. 设备信息
复制请求头的中的设备信息
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39
方式1:
requests.get('url', header={'User-Agent':'xx'})
方式2: (定义变量)
header={'User-Agent':'xx'}
requests.get('url', header=header)
import requests
response = requests.get('https://dig.chouti.com/', headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39'})
print(response.text)
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39'}
response = requests.get('https://dig.chouti.com/', headers=headers)
print(response.text)
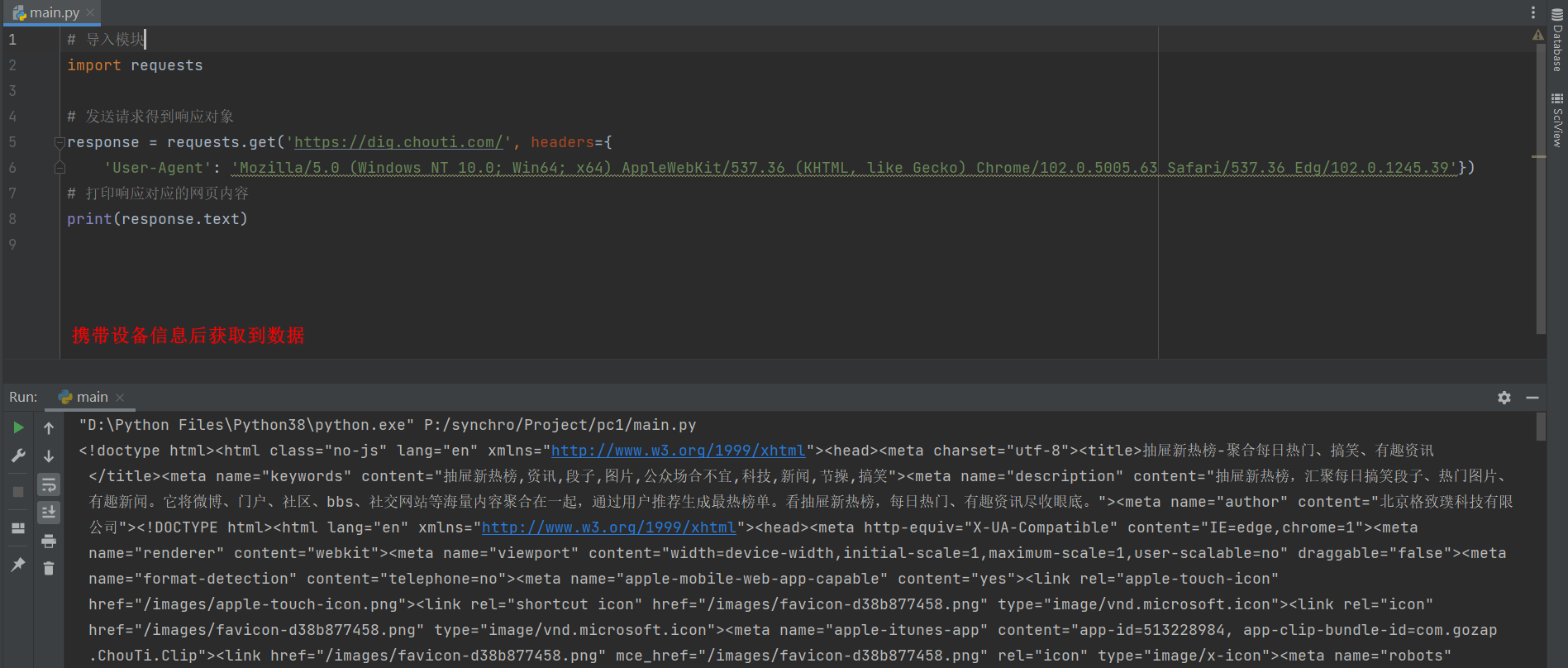
3. 网站信息
Referer: 记录的是送请求的网站地址, 服务器判断这个网站不是自己规定的网站, 会拒绝访问.
图片防盗链通常才采用这种方式. 有找到合适的案例, 遇到在补充.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39',
'Referer': 'xxx.xxx.xxx'
}
response = requests.get('图片url地址', headers=headers)
with open('img.png', mode='wb') as wf:
for line in response.iter_content():
wf.write(line)
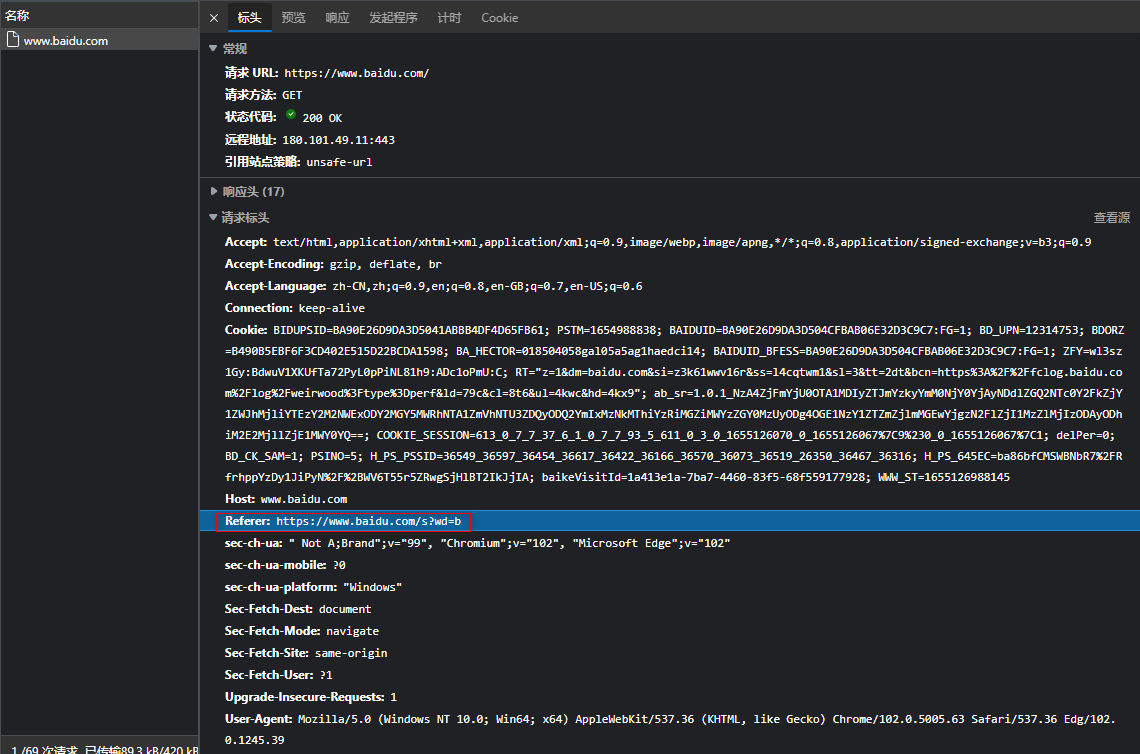
4. 登入信息
Cookie信息可以写在请求头headers= {'cookie': '键'='值'},
requests模块有单独的cookies参数来处理 cookies={'键': '值'}
* 1. github, 进入设置页面
https://github.com/settings/profile
import requests
response = requests.get('https://github.com/settings/profile')
print('Public profile' in response.text)
* 2. 查看cookies, 并复制
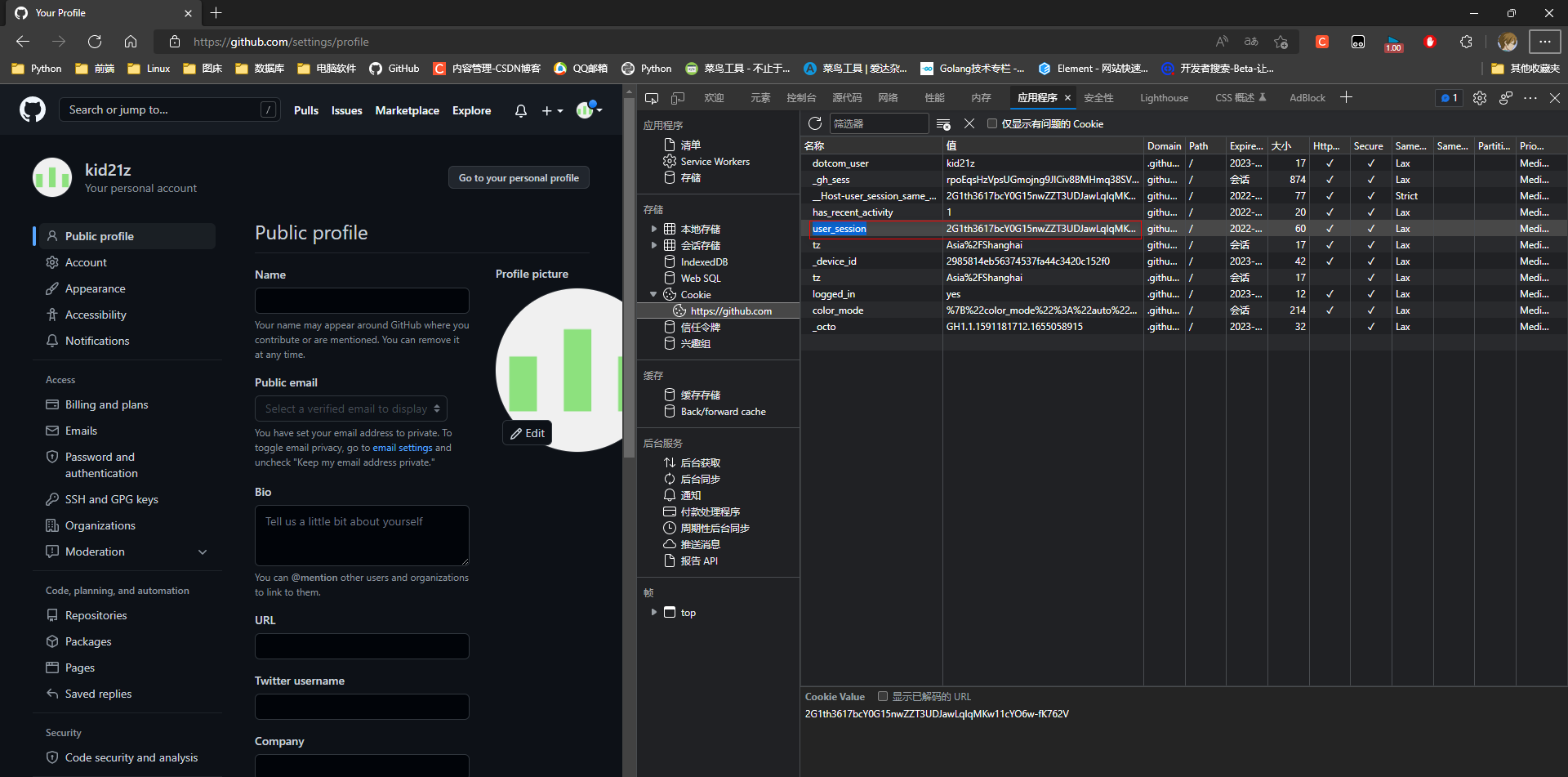
键: user_session
值: 2G1th3617bcY0G15nwZZT3UDJawLqIqMKw11cYO6w-fK762V
import requests
cookies = {'user_session': '2G1th3617bcY0G15nwZZT3UDJawLqIqMKw11cYO6w-fK762V'}
response = requests.get('https://github.com/settings/profile', cookies=cookies)
print('Public profile' in response.text)
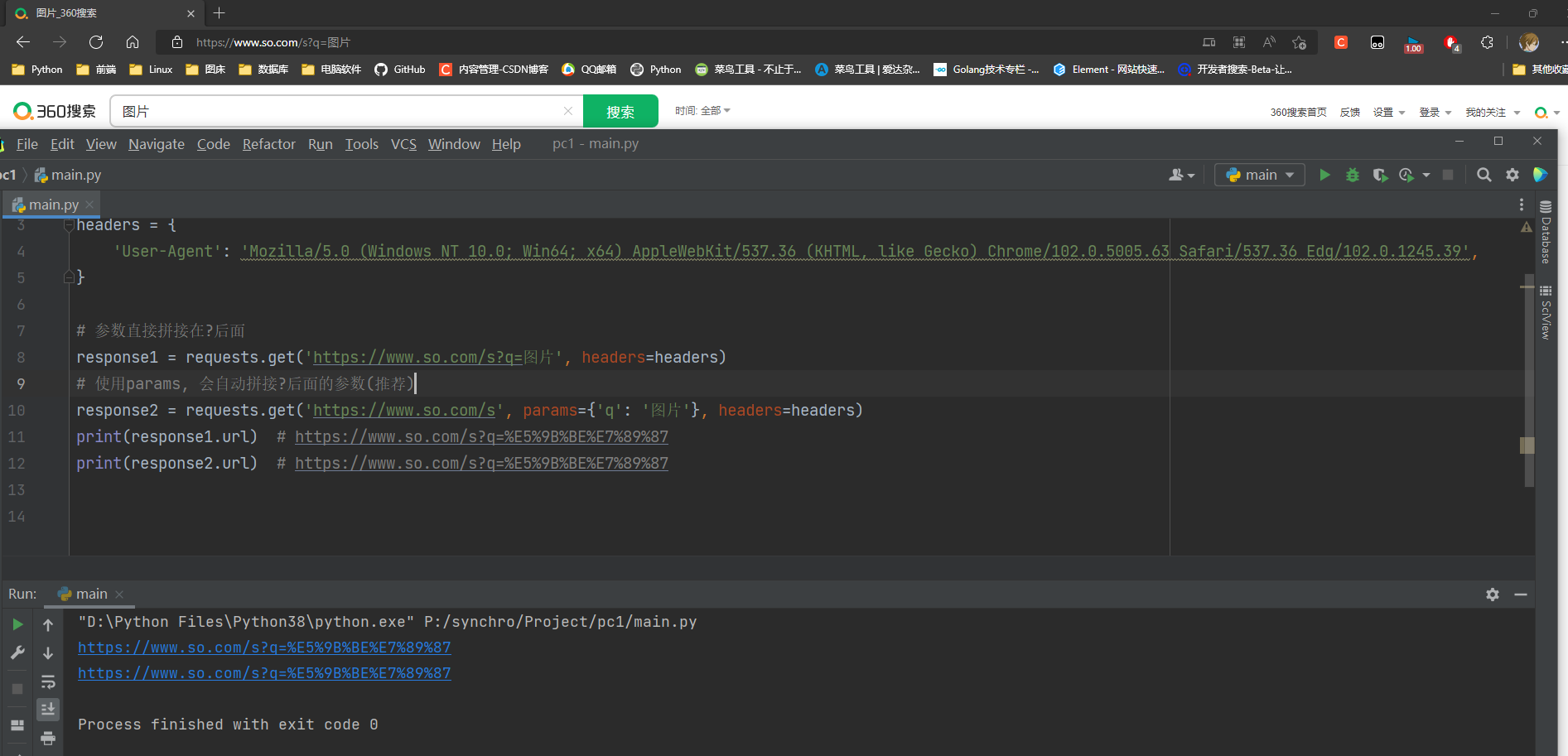
5. 请求地址携带数据方式
1. 直接拼接?后面
2. 使用params参数将参数拼接到?后面
参数的数据为urlencoded格式
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39',
}
response1 = requests.get('https://www.so.com/s?q=图片', headers=headers)
response2 = requests.get('https://www.so.com/s', params={'q': '图片'}, headers=headers)
print(response1.url)
print(response2.url)
6. 请求参数的转码与解码
urlencode模块: 将转码为网址查询字符串
unquote模块:将网址查询字符串转为字符串
from urllib.parse import urlencode, unquote
print(urlencode({'搜索': '嘻嘻嘻'}))
print(unquote('%E6%90%9C%E7%B4%A2=%E5%98%BB%E5%98%BB%E5%98%BB'))
5.6 POST请求
1. 携带数据
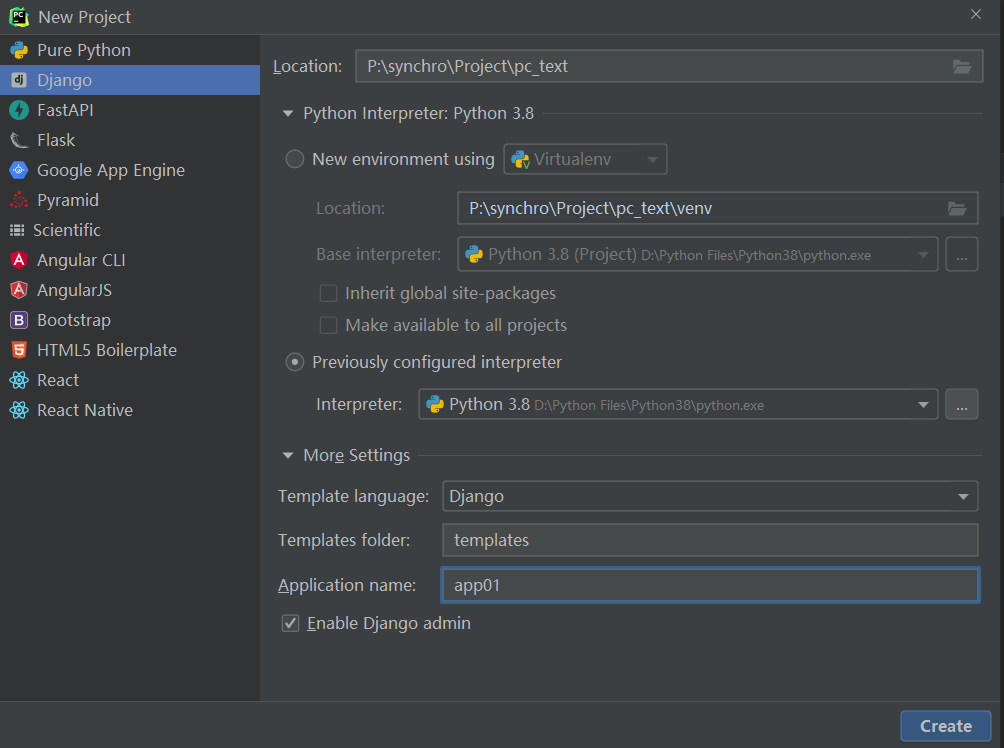
* 1. 新建django项目
* 2. 路由
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path('^login/', views.login)
]
* 3. 视图函数
from django.shortcuts import HttpResponse
def login(request):
print(request.META.get('HTTP_USER_AGENT'))
"""
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39
"""
username = request.POST.get('username')
password = request.POST.get('password')
if not username == 'kid' and password == '123':
return HttpResponse('用户信息校验失败!')
res = HttpResponse('登入成功')
res.set_cookie('django_login', 'abc123')
return res
* 4. settings.py中注销csrf中间件
MIDDLEWARE = [
...
...
]
* 5. 爬虫成功中, post请求提交的数据存放在data参数中.
import requests
data = {'user': 'kid', 'password': '123'}
response = requests.post('http://127.0.0.1:8000/login/', data=data)
print(response.text)
2. 自动携带cookie
使用.session()方法生成session对象.
session对象可以使用requests方法的方法和参数, 使用使用方式也一样.
session对象发送请求之后会自动保存返回的cookies, 下次在发送请求时会自动携带cookies访问.
* 1. 新建主页路由
re_path('^home/', views.home)
* 2. 视图函数
def home(request):
django_login = request.COOKIES.get('django_login')
if django_login != 'abc123':
return HttpResponse('非法访问!')
return HttpResponse('访问主页成功!')
* 3. 爬虫程序
import requests
data = {'username': 'kid', 'password': '123'}
session = requests.session()
session.post('http://127.0.0.1:8000/login/', data=data)
response = session.get('http://127.0.0.1:8000/home/')
print(response.text)
3. 发送接受json格式数据
* 1. 路由
re_path('^json/', views.json)
* 2. 视图类
def json(request):
data = request.body
print(data, type(data))
import json
data = json.loads(data)
print(data, type(data))
from django.http.response import JsonResponse
return JsonResponse({'k1': 'v1'})
* 3. 爬虫程序提交json格式数据
提交的数据会自动序列化
import requests
import json
json_data = {'username': 'kid', 'password': '123'}
response = requests.post('http://127.0.0.1:8000/json/', json=json_data)
res = response.text
print(res, type(res))
res = json.loads(res)
print(res, type(res))
5.7 响应对象属性&方法
* 1. 爬虫程序
import requests
data = {'username': 'kid', 'password': '123'}
response = requests.post('http://127.0.0.1:8000/login/', data=data)
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.cookies.get_dict())
print(response.cookies.items())
* 2. 返回结果
200
{'Date': 'Tue, 14 Jun 2022 04:42:52 GMT', 'Server': 'WSGIServer/0.2 CPython/3.8.5', 'Content-Type': 'text/html; charset=utf-8', 'X-Frame-Options': 'DENY', 'Content-Length': '12', 'X-Content-Type-Options': 'nosniff', 'Referrer-Policy': 'same-origin', 'Cross-Origin-Opener-Policy': 'same-origin', 'Set-Cookie': 'django_login=abc123; Path=/'}
<RequestsCookieJar[<Cookie django_login=abc123 for 127.0.0.1/>]>
{'django_login': 'abc123'}
[('django_login', 'abc123')]
* 3. 新建路由
re_path('^redirect/', views.redirect_url)
* 4. 视图函数
def redirect_url(request):
return redirect('/login/')
* 5. 爬虫程序
重定向数据会携带提交的数据取访问重定向的地址
import requests
data = {'username': 'kid', 'password': '123'}
response = requests.post('http://127.0.0.1:8000/redirect/', data=data)
print(response.history)
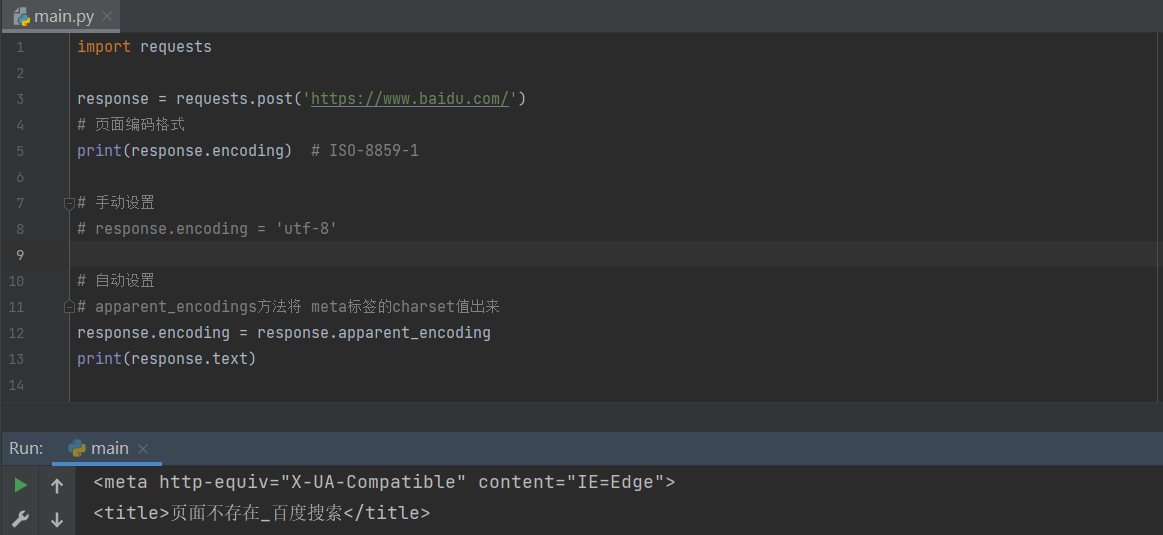
5.9 编码问题
import requests
response = requests.post('https://www.baidu.com/')
print(response.encoding)
print(response.text)


import requests
response = requests.post('https://www.baidu.com/')
print(response.encoding)
response.encoding = response.apparent_encoding
print(response.text)
6. 高级用法
6.1 SSL证书验证
谷歌浏览器对大部分HTTP页面标记"不安全",
也就是说如果你的网站没有安装SSL证书, 当用户访问你的网站时, 浏览器就会显示不安全的告警提示.
没有网站的测试, 以后补上.
import requests
requests = requests.get('https://www.12306.cn')
print(requests.status_code)
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
requests=requests.get('https://www.12306.cn', verify=False)
print(respone.status_code)
import requests
requests=requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(respone.status_code)
6.2 代理
某一个ip的访问的网站次数过多, 会分进制访问. (封ip是常见的事情)
代理: 使用代理的ip去访问网站.先发送请求给代理, 然后由代理帮忙发送服务端.

代理ip的类型是http或https.
代理类型:
高匿 很难被追溯到原ip
透明 可以看到原ip
import requests
proxies = {'http': '120.29.124.131:8080'}
response = requests.get('https://www.12306.cn', proxies=proxies)
print(response.status_code)
6.3 超时设置
import requests
response = requests.get('https://www.12306.cn', timeout=0.0000000001)
print(response.status_code)
6.4认证设置(淘汰)
认证设置:登陆网站是,弹出一个框,要求你输入用户名密码(与alter很类似),此时是无法获取html的.
但本质原理是拼接成请求头发送
r.headers['Authorization'] = _basic_auth_str(self.username, self.password)
一般的网站都不用默认的加密方式, 都是自己写
那么我们就需要按照网站的加密方式, 自己写一个类似于_basic_auth_str的方法
得到加密字符串后添加到请求头
r.headers['Authorization'] =func('.....')
import requests
from requests.auth import HTTPBasicAuth
r=requests.get('xxx',auth=HTTPBasicAuth('user','password'))
print(r.status_code)
import requests
r=requests.get('xxx',auth=('user','password'))
print(r.status_code)
6.5 异常
import requests
from requests import exceptions
try:
response = requests.get('https://www.12306.cn', timeout=0.0000000001)
print(response.status_code)
except Exception as e:
print(e)
6.6 上传文件
* 1. 新建路由
re_path('^get_files/', views.get_files)
* 2. 视图函数
import requests
with open('A.png', mode='rb') as rf:
files = rf.read()
requests = requests.post('http://127.0.0.1:8000/get_files/', files=files)
print(requests.status_code)
* 3. 爬虫程序
在根目录放一张图片

import requests
with open('A.png', mode='rb') as rf:
data = rf.read()
files = {'A.png': data}
requests = requests.post('http://127.0.0.1:8000/get_files/', files=files)
print(requests.status_code)
* 4. 运行程序之后, 后端会接受到图片
7. 模拟登入网站
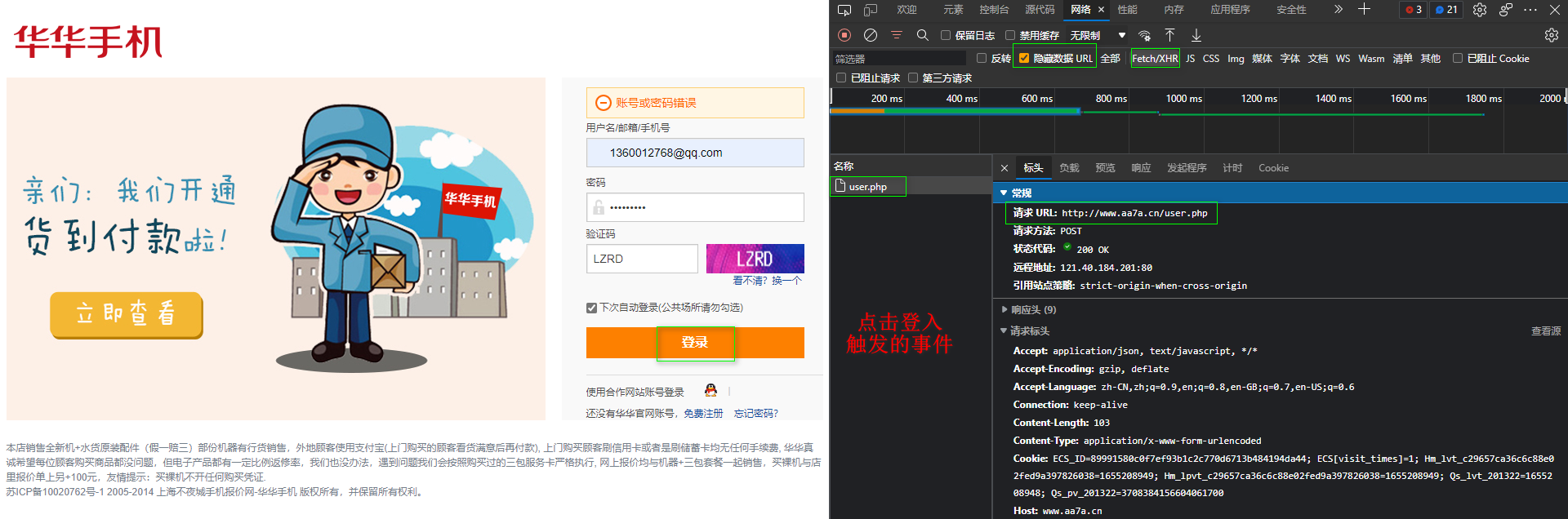
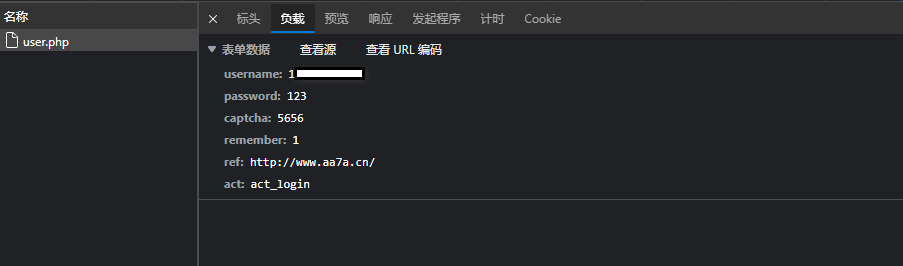
提交地址: http://www.aa7a.cn/user.php
提交方式: POST
提交数据:
username: 1360012768@qq.com
password: 123
captcha: 5656
remember: 1
ref: http://www.aa7a.cn/
act: act_login
import requests
data = {
'username': '1360012768@qq.com',
'password': 'zxc123456',
'captcha': '5656',
'remember': '1',
'ref': 'http://www.aa7a.cn/',
'act': 'act_login',
}
session = requests.session()
session.post('http://www.aa7a.cn/user.php', data=data)
response = session.get('http://www.aa7a.cn/')
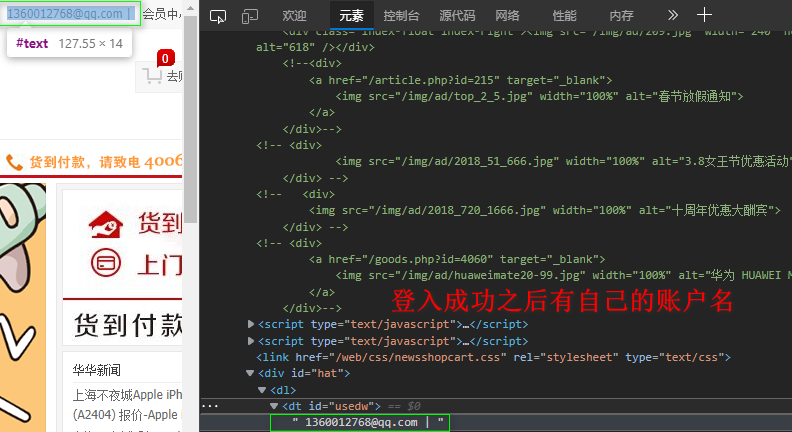
print(response.status_code)
print('1360012768@qq.com' in response.text)
8. 爬取视频
8.1 案例分析
* 1. 选择一个分类, 分析出获取视频的地址

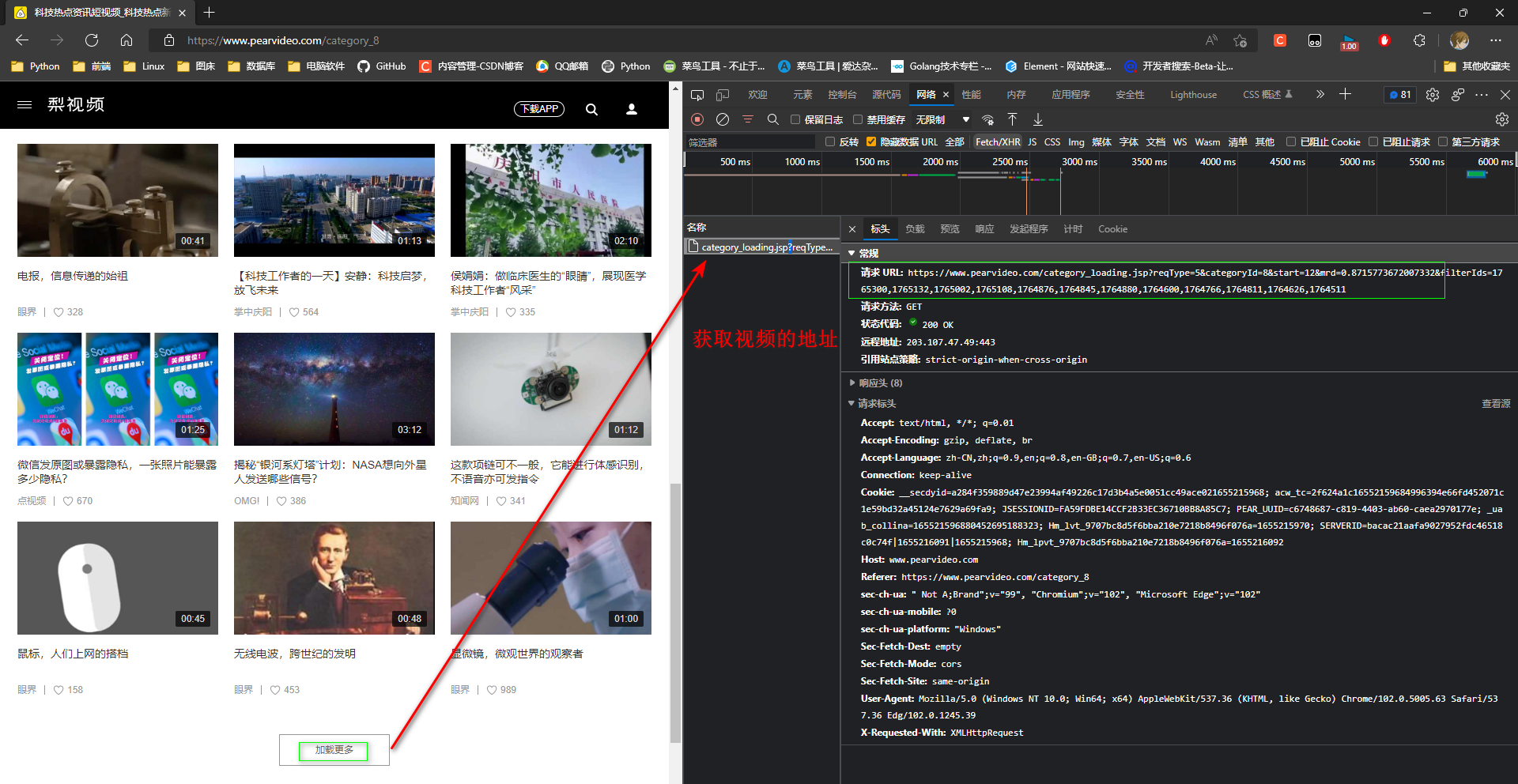
请求 URL: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12&mrd=0.8715773672007332&filterIds=1765300,1765132,1765002,1765108,1764876,1764845,1764880,1764600,1764766,1764811,1764626,1764511
URL: https://www.pearvideo.com/category_loading.jsp
# 需求类型
?reqType=5
# 分类id
&categoryId=8
# 起始位置(每次获取12条数据, 从0开始)
&start=12
# 时间,不懂干嘛的
&mrd=0.8715773672007332
# 视频id
&filterIds=1765300,1765132,1765002, ...
第一次展示:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0
下拉页再次发送请求:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12
点击加载更多再次发送请求:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24
* 2. 省略不需要的参数,浏览器中输入:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12
返回12条数据, 数据是后端封装的html代码.
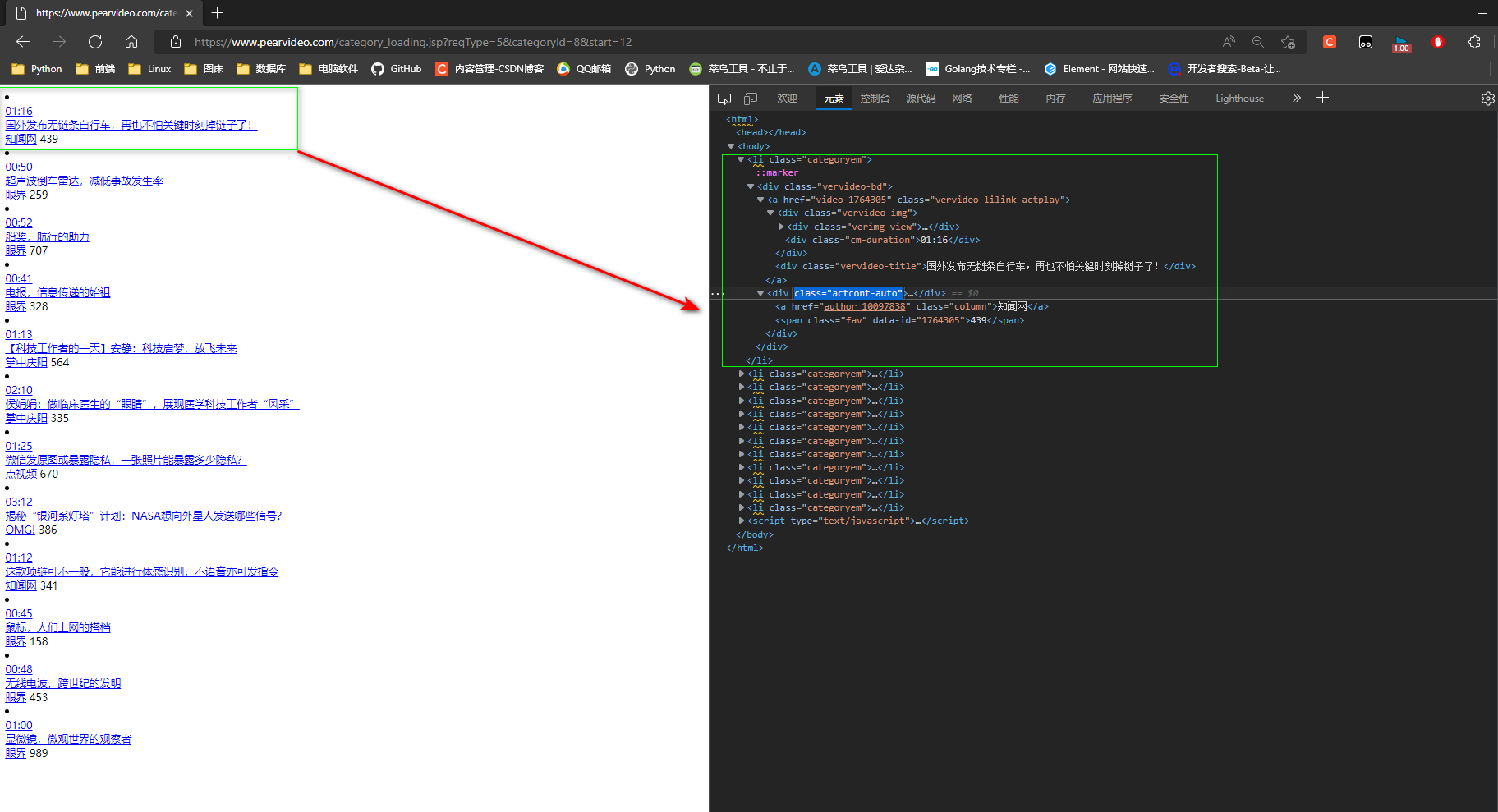
* 3. 点击视频播放链接跳转到详情
详情地址: 网站地址 + 路径

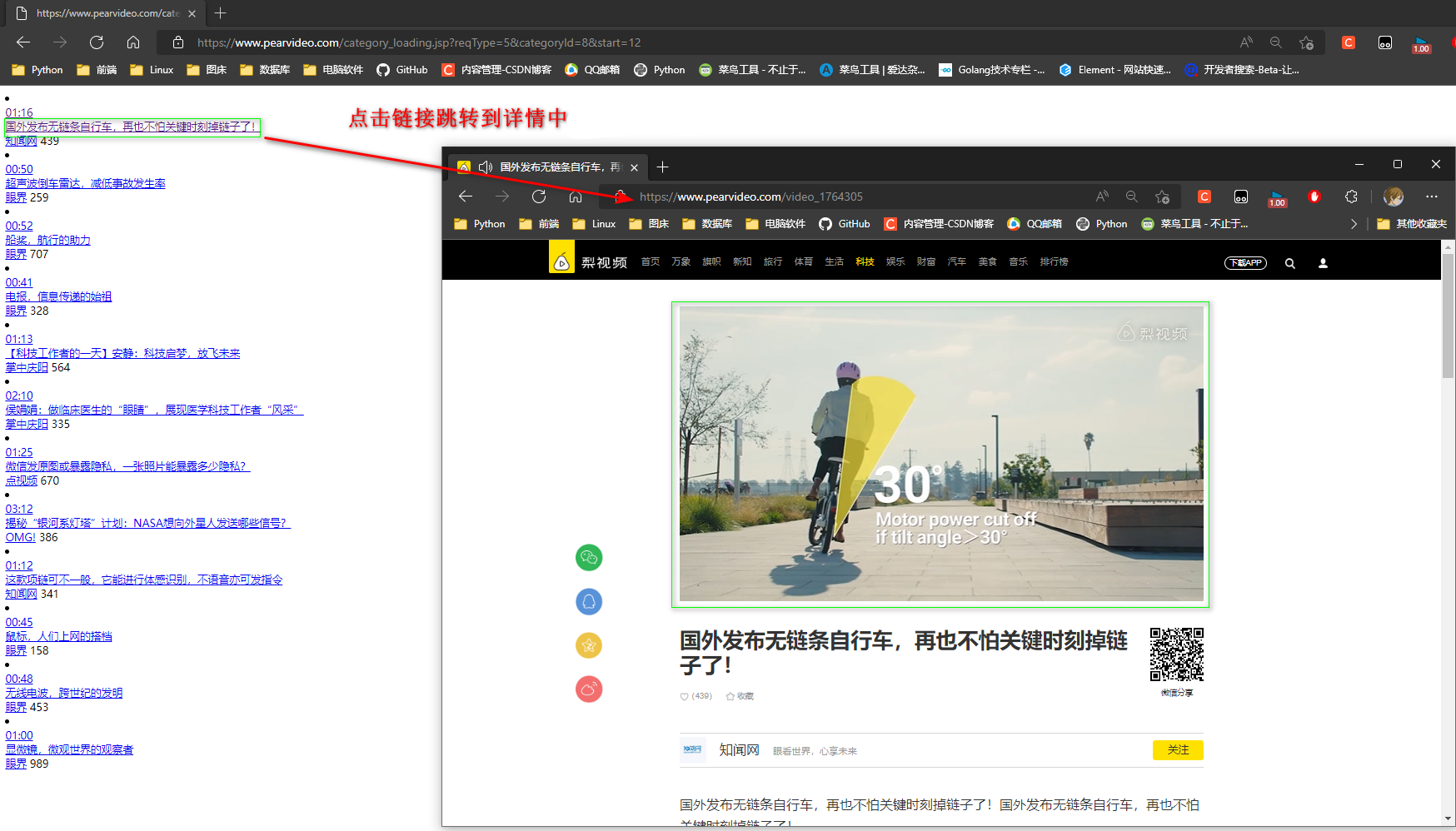
* 4. 访问详情页面时会向另一个地址发送一个get请求.
请求 URL:
https://www.pearvideo.com/videoStatus.jsp?contId=1764305&mrd=0.8020846672776398
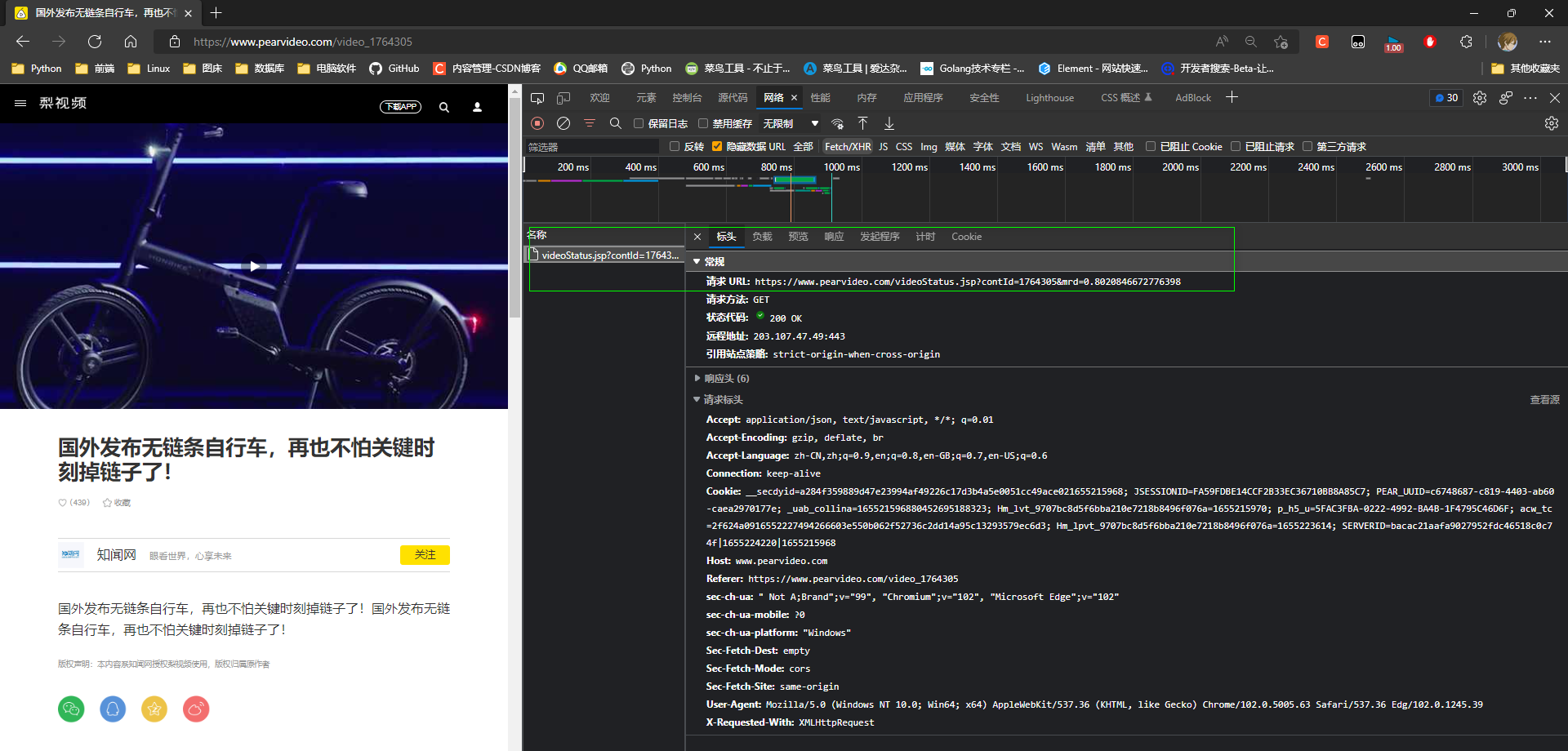
将视频相关信息已经发送到本地
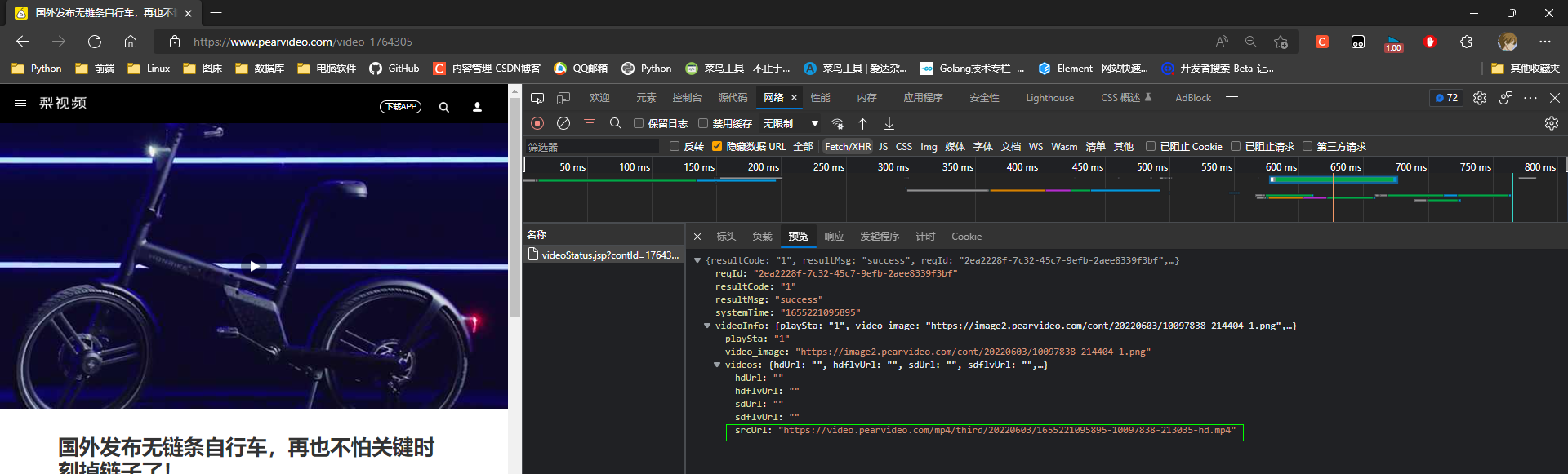
* 5. 开始是一个img标签, 展示封面, 在点击封面的时候会切换video标签播放视频
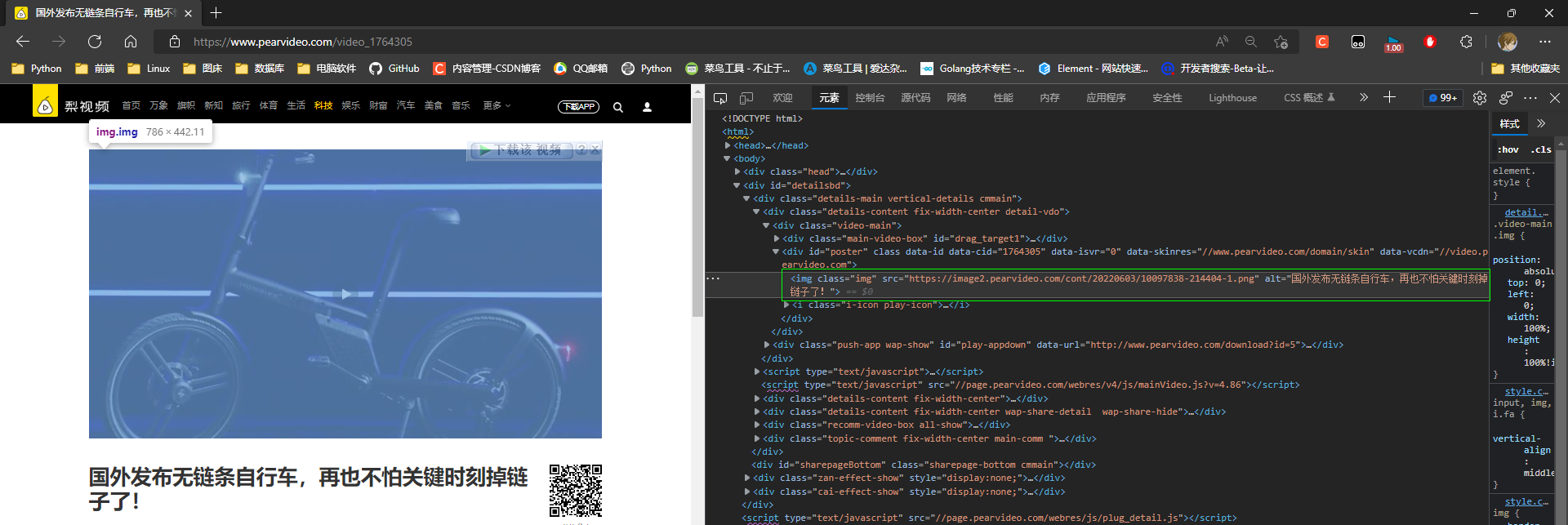

* 5. 视频地址
在爬虫程序中, 不取点击img的事件切换为video标签没法拿到视频链接
那么就自己在发送一次请求获取数据
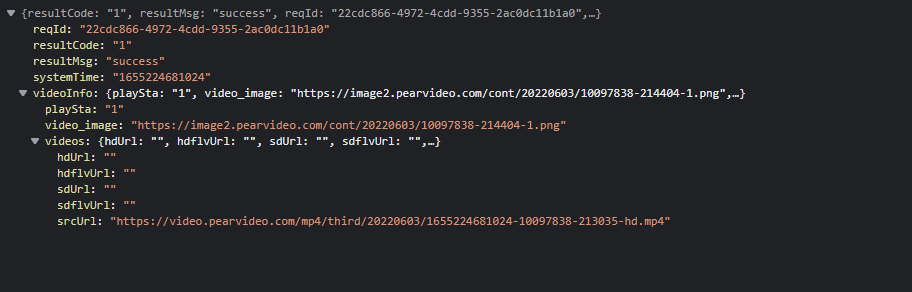
* 6. 视频地址对象
video中的视频地址: (复制链接可以访问, 复制到任何地址都可以访问, 说明没有请求头的要求)
https://video.pearvideo.com/mp4/third/20220603/cont-1764305-10097838-213035-hd.mp4
服务端返回的数据: (复制链接提示资源不存在)
https://video.pearvideo.com/mp4/third/20220603/1655223614164-10097838-213035-hd.mp4

cont-1764305则是 video_1764305 视频id替换了前缀
1655223614164是时间戳, 后端返回的systemTime: '1655223614164'
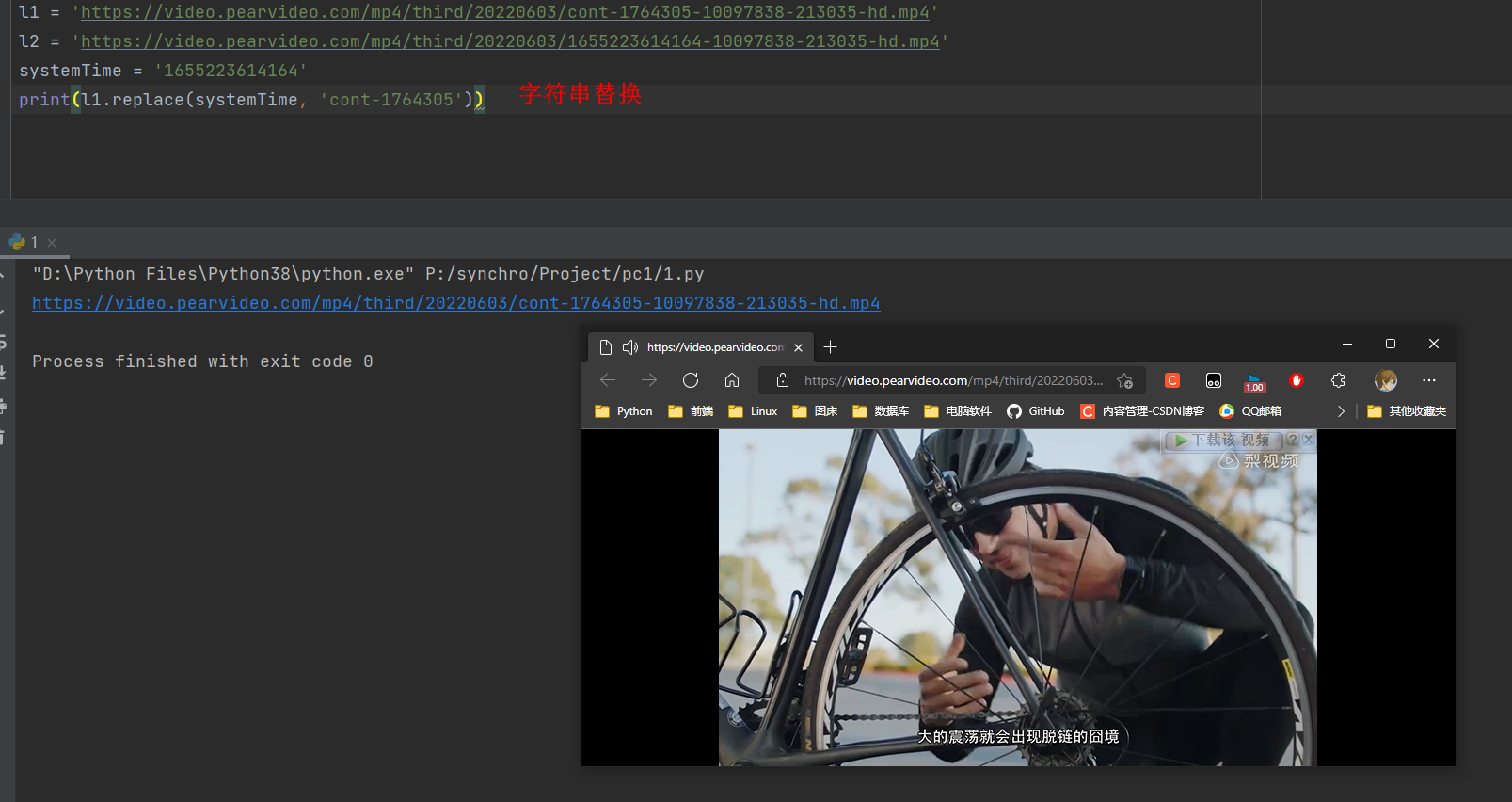
l1 = 'https://video.pearvideo.com/mp4/third/20220603/cont-1764305-10097838-213035-hd.mp4'
l2 = 'https://video.pearvideo.com/mp4/third/20220603/1655223614164-10097838-213035-hd.mp4'
systemTime = '1655223614164'
print(l1.replace(systemTime, 'cont-1764305'))
8.2 爬虫程序
import requests
import re
import json
response = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0')
video_id = '<a href="(.*?)" class="vervideo-lilink actplay">'
video_list = re.findall(video_id, response.text)
"""
视频id列表
['video_1764305', 'video_1758399', 'video_1758401', 'video_1758411',
'video_1763979', 'video_1763973', 'video_1763902', 'video_1763069',
'video_1762664', 'video_1757471', 'video_1757482', 'video_1757484']
"""
for video_id in video_list:
headers = {'Referer': 'https://www.pearvideo.com/' + video_id}
contId = video_id.strip('video_')
response = requests.get(f'https://www.pearvideo.com/videoStatus.jsp?contId={contId}', headers=headers)
response_dict = json.loads(response.text)
systemTime = response_dict.get('systemTime')
video_url = response_dict.get('videoInfo').get('videos').get('srcUrl')
video_name = video_url.split('/')[-1]
truly_video_url = video_url.replace(systemTime, f'cont-{contId}')
print(truly_video_url)
response = requests.get(truly_video_url)
with open(video_name, mode='wb') as wf:
for line in response.iter_content():
wf.write(line)
这是单进程下载, 很慢, 可以开启多线程下载.























 4049
4049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









