文本给人类阅读 , 字节序列供计算机处理 .
--Estther Nam和Travis Fistcher
'Character Encoding and Unicode in Python' ①
( 注 1 : PyCon 2014 , 'Character Encoding and Unicede in Python' 演讲第 12 张幻灯片 . )
Python 3 明确区分了人类可读的文本字符串和原始的字节序列 .
把字节序列隐式转换成Unicode文本已成过去 .
本章讨论Unocode字符串 , 二进制序列 , 以及在二者之间转换时使用的编码 .
深入理解Unicode对你可能十分重要 , 也可能无关紧要 , 这取决于Python编程场景 .
不过 , 现在用不到 , 并不代表以后用不到 , 至少总有需求区分str和byte的时候 .
此外 , 你会发现专门的二进制序列类型所提供的功能 , 有些是Python2中 '全功能' 的str类型不具备的 .
本章涵盖以下内容 :
• 字符 , 码点和字节表诉 ;
• bytes , bytearray和memoryview等二进制序列的特性 ;
• 全部Unicode和陈旧字符串集的编码 ;
• 避免和处理编码错误 ;
• 处理文本文件的最佳实践 ;
• 默认编码的陷阱和标准I / O的问题 ;
• 规范化Unicode文本 , 进行安全比较 ;
• 规范化 , 大小写同一化和暴力移除变音符的使用函数 ;
• 使用locale模块和pyuca库正确排序Unicode文本 ;
• Unicode数据库中的字符元数据 ;
• 能处理str和bytes的双模式API .
Python 3 对Unicode的支持已完善 , 稳定 , 本章最大的变化是新增了 4.9 .1 节 ,
介绍了一个用于搜索Unicode数据库的实用函数 , 方便在命令行中查找带圈数字的笑脸猫等 .
另外 , 6.1 节的 '了解默认编码' 还有一处小变化 , 讲到自Python 3.6 起 , Windows对Unicode的支持更好 , 更简单 .
下面先从字符 , 码点和字节序列讲起 , 这些概念并不新奇 , 却是根基 .
'字符串' 是个相当简单的概念 : 一个字符串就是一个字符序列 . 问题出在 "字符" 的定义上 .
在 2021 年 , '字符' 的最佳定义是Unicode字符 . 因此 , 从Python 3 的str对象中获取的项是Unicode字符 ,
从Python 2 中unicode对象获取的项也是Unicode字符 , 而从Python 2 的str对象中获取的项是原始字节序列 .
Unicode标准明确区分字符的标识和具体的字节表述 .
• 字符的标识 , 即 '码点' , 是 0 ~ 1 114 111 范围内的数 ( 十进制 ) ,
在Unicode标准中以 4 ~ 6 个十六进制数表示 , 前加 'U+' , 取值范围时U + 0000 ~ U + 10 FFFF .
例如 , 字母A的码点是U + 0041 , 欧元符号的码点是U + 20 AC , 音乐中高音谱号的码点是U + 1 D11E .
在Python 3.10 .0 b4中使用的Unicode 13.0 .0 标准中 , 约 13 % 的有效码点对应着字符 .
• 字符的具体表述取决于所有的 '编码' . 编码是在码点和字节序列之间转换时使用的算法 .
例如 , A ( U + 0041 ) 在UTF- 8 编码中使用单个字节 \ x41表述 , 而在UTF- 16 LE编码中使用字节序列 \ x41 \ x00表述 .
再比如 , 欧元符号 ( U + 20 AC ) 在UTF- 8 编码中需要 3 个字节 , 即 \ xe2 \ x82 \ xac ,
而在UTF- 16 LE中 , 同一个码点编码成两个字节 , 即 \ xac \ x20 .
把码点转换成字节序列的过程叫 '编码' , 把字节序列转换成码点的过程叫 '解码' .
示例 4 - 1 演示了二者之间的区别 .
>> > s = 'café'
>> > len ( S)
4
>> > b = s. encode( 'utf-8' )
>> > b
b'caf\xc3\xa9'
>> > len ( b)
5
>> > b. decode( 'utf8' )
'café'
* --------------------------------------------------------------------------------------------- *
如果你记不住 . decode ( ) 和 . encode ( ) 的区别 ,
可以把字节序列当成晦涩难懂的机器核心转储 , 把Unicode字符串当成 '人类可读' 的文本 .
转储 ( Dump ) : 是一个计算机术语 ,
通常指将计算机内存 ( 或其他存储器 ) 中的数据以某种形式保存到磁盘或其他存储介质中的过程 .
这样你就知道 , 把字节码序列变成人类可读的字符串是 '解码' , 而把字符串变成用于存储或传输的字节序列是 '编码' .
* --------------------------------------------------------------------------------------------- *
虽然Python 3 的str类型基本相当于Python2的unicode类型 , 只不过换了个新名称而已 ,
但是Python 3 的types类型并不是把str类型换个名字那么简单 , 而且还有关系紧密的bytearray类型 .
在Python2中 , 字符串是字节串 ( bytes ) 类型 , 而在Python 3 中字符串是Unicode字符串 .
这是Python2到Python 3 的一个重大变化之一 .
在Python 3 中 , 要创建字节串需要使用字节串前缀b ,
例如 b 'hello' , 如果没有前缀b , 则会创建一个Unicode字符串 , 例如 'hello' .
在Python2中 , 类似的 , 要创建Unicode字符串需要在字符串前添加u前缀 , 例如 u 'hello' .
而没有u前缀的字符串则是字节串 .
注意点 : 在Python2中 , 如果字符串中包含非ASCII字符 , 它们会被自动转换为字节序列 , 无论是否使用了u前缀 .
这是因为Python2中的字符串默认是字节串 ( byte string ) , 而不是Unicode字符串 .
>> > s = 'hello'
>> > s
'hello'
>> > s = '你好!'
>> > s
'\xc4\xe3\xba\xc3!'
>> > s = u'你好'
>> > s
u'\u4f60\u597d'
在Python中 , "bytes" 和 "byte string" 这两个术语有时会混合使用 , 但它们有些微妙的区别 .
'byte string' ( 字节串 ) 通常是指在Python2中的字符串对象 ,
它由字节组成 , 可以包含任意的字节值 , 包括ASCII和非ASCII字符 .
'bytes' ( 字节 ) 是Python 3 中引入的数据类型 , 用于明确表示字节序列 .
bytes对象是不可变的 , 它由一系列字节组成 , 每个字节的值范围是 0 - 255.
你可以使用字面值语法b或者bytes ( ) 构造函数来创建bytes对象 .
虽然两者在表示字节数据方面的目的是相同的 , 但它们的一些细节和用法略有不同 :
* 1. 在Python2中 , 字节串 ( byte string ) 通常使用普通字符串对象表示 ,
而在Python 3 中 , bytes是一个独立的数据类型 .
* 2. 在Python2中 , 字节串可以直接与字符串进行操作 ,
但在Python 3 中 , bytes和字符串是不可混用的 , 它们有不同的方法和操作符 .
* 3. 在Python2中 , 字节串可以包含任意的字节 , 包括非ASCII字符 ,
而在Python 3 中,bytes对象的每个字节的值范围是 0 - 255 ( latin- 1 编码表上的字符对应的十进制 ) .
因此 , 尽管两者都用于处理字节数据 , 但根据Python版本的不同 , 它们的表示方式 , 用法和行为略有差异 .
因此 , 在讨论编码个解码问题之前 , 有必要介绍一下二进制序列类型 .
新的二进制序列类型在很多地方与Python2的str类型不同 .
首先要知道 , Python内置两种基本的二进制序列 :
Python 3 引入的不可变类型的bytes和Python2 . 6 添加的可变类型bytearray .
② Python文档有时把bytes和bytearray统称为 '字节字符串' , 这个术语有歧义 , 我一般不用 .
( 注 2 : Python2 . 6 和 2.7 还有bytes类型 , 只不过是str类型的别名 . )
bytes和bytearray中的项是 0 ~ 255 ( 含 ) 的整数 , 而不像Python2的字符串那样是单个字符 .
然而 , 二进制序列的切片始终是同一类型的二进制序列 , 包括长度为 1 的切片 , 如示例 4 - 2 所示 .
>> > cafe = bytes ( 'café' , encoding= 'utf-8' )
>> > cafe
b'caf\xc3\xa9'
>> > cafe[ 0 ]
99
>> > cafe[ : 1 ]
b'c'
>> > cafe_arr = bytearray ( cafe)
>> > cafe_arr
bytearray ( b'caf\xc3\xa9' )
>> > cafe_arr[ - 1 : ]
* * * ----------------------------------------------------------------------------------------- * * *
my_bytes [ 0 ] 获取的是一个整数 , 而my_bytes [ : 1 ] 返回的是一个长度为 1 的字节序列 .
如果你不理解这种行为 , 只能说明你习惯了Python真的str类型 . 对str类型来说 , s [ 0 ] = = s [ : 1 ] .
除此之外 , 对于Python中的其他所有序列类型 , 一个项不能等同于长度为 1 的切片 .
* * * ----------------------------------------------------------------------------------------- * * *
虽然二进制序列其实是整数序列 , 但是它们的字面量表示法表明其中含有ASCII文本 .
因此 , 字节的值可能会使用一下 4 种不同方式显示 .
• 十进制代码在 32 ~ 126 范围内的字节 ( 从空格到波浪号 ~ ) , 使用ASCII字符本身 .
• 制表符 , 换行符 , 回车符和 \ 对应的字节 , 使用转义序列 \ t , \ n , \ r和 \ \ .
• 如果字节序列同时包含两种字符串分割符号 '和", 整个序列使用' 区隔 , 序列内的 ' 转义为 \ ' . ③
( 注 3 : 小知识 , Python默认用作字符串分割符的ASCII "单引号" 字符 ,
在Unicode标准中的名称实际上是apostrophe ( 撇号 ) . 真正的单引号是不对称的 , 左边是U + 2018 , 右边是U + 2019. )
• 其他字节的值 , 使用十六进制转义序列 ( 例如 , \ x00是空字符 ) .
因此 , 在示例 4 - 2 中 , 我们看到的是b 'caf\xc3\xa9' :
前 3 个字节b 'caf' 在可打印的ASCII范围内 , 后两个字节则不同 .
在str类型的一众方法中 , 除了格式化方法format和format_map ,
以及Unicode数据的方法casefold , isdecimal , isiddentifiel , isnumerice , isprintable和encode之外 ,
其他方法均受bytes和bytearray类型的支持 .
这意味着可以使用熟悉的字符串方法处理二进制序列 ,
例如endswith , replace , strip , translate , upper等 , 只不过把str类型的参数换成bytes .
另外 , 如果正则表达式编译自二进制序列而不是字符串 , 那么re模块中的正则表达式函数也能处理二进制序列 .
从Python 3.5 开始 , % 运算符又能处理二进制序列了 . ④
( 注 4 : 在Python 3.0 ~ 3.4 中 , % 运算符不能处理而进制序列 , 为需要处理二进制数据的开发人员带来很多痛苦 .
这次逆转的说明见 'PEP 461--Adding % formatting to bytes and bytearray' . )
二进制序列有一个类方法是str没有的 , 名为fromhex ,
它的作用是解析十六进制数字对 ( 数字对之间的空格是可选的 ) , 构建二进制序列 .
>> > bytes . fromhex( '31 4B CE A9' )
b'1K\xce\xa9'
构建bytes或bytearray实例还可以调用各自的构造函数 , 传入已下参数 .
• 一个str对象和encoding关键字参数 .
• 一个可迭代对象 , 项为 0 ~ 255 范围内的数 .
• 一个实现了缓冲协议对象 ( 例如bytes , bytearray , memoryview , array . array ) .
构造函数把源对象中的字节序列复制到新创建的二进展序列中 .
* * * ----------------------------------------------------------------------------------------- * * *
在Python 3.5 之前 , bytes和bytearray构造函数的还可以是一个整数 , 使用空字节创建对应长度的二进制序列 .
这种签名在Python 3.5 中弃用 , 在Python 3.6 中正式移除 .
详见 'PEP 467-Minor API improvements for binary sequences' .
* * * ----------------------------------------------------------------------------------------- * * *
使用缓冲对象构建二进制序列是一种底层操作 , 可能涉及类型转换 , 如示例 4 - 3 所示 .
>> > import array
>> > numbers = array. array( 'h' , [ - 2 , - 1 , 0 , 1 , 2 ] )
>> > octets = bytes ( numbers)
>> > octets
b'\xfe\xff\xff\xff\x00\x00\x01\x00\x02\x00'
使用缓冲类对象创建bytes或bytearray对象 , 始终复制源对象中的字节序列
( 意思是复制一份源对象的内容 , 不是共享数据的意思 ) .
与之相反 , memoryviem对象在二进制数据结构之间共享内存 , 详见 2.10 .2 节 .
简要探讨Python的二进制序列类型之后 , 下面说明如何在它们和字符串之间转换 .
Python自带超过 100 种 '编码解释器' ( codec , encoder / decoder ) , 用于在文本和字节之间相互转换 .
每种编码解释器都有一个名称 , 例如 'utf_8' , 而且经常有几个别名 , 例如 'utf8' , 'utf-8' 和 'U8' .
这些名称可以传给open ( ) , str . encode ( ) , bytes . decode ( ) 等函数的encoding参数 .
示例 4 - 4 使用 3 种编码解释器把相同的文本编码成不同的字节序列 .
>> > for codec in [ 'latin_1' , 'utf_8' , 'utf_16' ] :
. . . print ( codec, 'EI Niño' . encode( codec) , sep= '\t' )
. . .
latin_1 b'EI Ni\xf1o'
utf_8 b'EI Ni\xc3\xb1o'
utf_16 b'\xff\xfeE\x00I\x00 \x00N\x00i\x00\xf1\x00o\x00'
图 4 - 1 展示了不同编码解释器对字母 'A' 和高音谱号等字符编码后得到的字节序列 .
注意 , 后 3 种是可变长度多字节编码 .
字符 码点 ascii latin1 cp1252 cp437 gb2312 utf-8 utf-16le A U+0041 41 41 41 41 41 41 41 00 ¿ U+00BF * BF BF AB * C2 BF BF 00 Ã U+00C3 * C3 C3 * * C3 83 C3 00 á U+00E1 * E1 E1 A0 A8 A2 C3 A1 E1 00 Ω U+03A9 ** * * EA A6 B8 CE A9 A9 03 ڿ U+06BF * * * * * DA BF BF 06 “ U+201C * * 93 * A1 B0 E2 80 9C 1C 20 € U+20AC * * 80 * * E2 81 AC AC 20 ┌ U+250C * * * DA A9 B0 E2 94 BC 0C 25 气 U+6C14 * * * * C6 F8 E6 B0 94 14 6C * U+6C23 * * * * * E6 B0 A3 23 6C 𝄞 U+1D11E * * * * * F0 9D 84 9E 34 DB 1E DD
图 4 - 1 : 12 个字符 , 它们的码点及不同编码的字节表述 ( 十六进制 : 信号表示字符不能使用那种编码表述 )
图 4 - 1 中的星号表明 , 某些编码 ( 例如ASCII和多字节的GB2312 ) 不能表示所有Unicode字符 .
然而 , UTF编码的设计目的就是处理每一个Unicode码点 .
图 4 - 1 中展示的是一些经典编码 , 介绍如下 .
latin1 ( 即iso8859_1 ) : 一种重要的编码 , 是其他编码的基础 ,
例如 , cp1252和Unicode ( 注意 , latin1与cp1252的字节值是一样的 , 甚至连码点也相同 ) .
cp1552 : Microsoft制定的latin1超级 , 添加了有用的符号 , 例如 , 弯号引号和€ ( 欧元符号 ) .
Windows应用程序将其称为 'ANSI' , 但它并不是ANSI标准 .
cp437 : IBM PC最初的字符集 , 包含框图符号 . 以后来出现的latin1不兼容 .
gb2312 : 用于编码简体中文的陈旧标准 . 亚洲语言使用较广泛的多字节编码之一 .
utf- 8 : 目前Web最常用的 8 位编码 .
据W3Techs发布的 'Usage statistics of character encodings for websites' 报告 ,
截至 2021 年 7 月 , 97 % 的网站使用UTF- 8. 2014 年 9 月 , 本书英文版第 1 版出版时 , 这一比例是 81.4 % .
utf- 16 le : UTF 16 位编码方案的一种形式 .
所有UTF- 16 支持通过转义序列 ( 称为 '代理对' , surrogate pair ) 表示超过U + FFFF的码点 .
* * * ----------------------------------------------------------------------------------------- * * *
UTF- 16 取代了 1996 年发布的Unicode 1.0 编码 ( UCS- 2 ) .
UCS- 2 编码支持的码点最大只到U + FFFF , 现已弃用 , 不过在很多系统中仍有使用 .
截至 2021 年 , 已分配的码点中超过 57 % 大于U + FFFF , 其中包括十分重要的表情符号 ( emoji ) .
* * * ----------------------------------------------------------------------------------------- * * *
概述常用的编码之后 , 下面探讨编码和解码操作涉及的问题 .
UnicodeError是一般性的异常 ,
Python在报告错误时通常更具体 , 抛出UnicodeEncodeErroe ( 把str转换成二进制序列是出错 )
或UnicodeDecodeError ( 把二进制序列转换成str是出错 ) .
如果源码的编码与预期不符 , 那么加载Python模块时还可能抛出SyntaxError .
接下来的几节说明如何处理这些错误 .
* --------------------------------------------------------------------------------------------- *
出现与Unicode有关的错误时 , 首先要明确异常的类型 .
要知道导致编码问题的究竟是UnicodeEncodeError , UnicodeDecodeError , 还是其他错误 ( SyntaxError ) .
解决问题之前必须清楚这一点 .
* --------------------------------------------------------------------------------------------- *
多数非UTF编码解码器只能处理Unicode字符的一小部分子集 .
把文本转换字节序列使 , 如果目标编码没有定义某个字符 , 则会抛出UnicodeEncodeError ,
除非把errors参数传给编码方法或函数 , 做特殊处理 .
处理错误的方式如示例 4 - 5 所示 .
>> > city = 'São Paulo'
>> > city. encode( 'utf_8' )
b'S\xc3\xa3o Paulo'
>> > city. encode( 'utf-16' )
b'\xff\xfeS\x00\xe3\x00o\x00 \x00P\x00a\x00u\x00l\x00o\x00'
>> > city. encode( 'iso8859_1' )
b'S\xe3o Paulo'
>> > city. encode( 'cp437' )
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
File "C:\Python_set\Python 310\lib\encodings\cp437.py" , line 12 , in encode
return codecs. charmap_encode( input , errors, encoding_map)
UnicodeEncodeError:
'charmap' codec can't encode character
'\xe3' in position 1 : character maps to < undefined>
>> > city. encode( 'cp437' , errors= 'ignore' )
b'So Paulo'
>> > city. encode( 'cp437' , errors= 'replace' )
b'S?o Paulo'
>> > city. encode( 'cp437' , errors= 'xmlcharrefreplace' )
b'São Paulo'
* * ------------------------------------------------------------------------------------------- * *
编码解释器的错误处理方式可以拓展 .
可以为errors参数注册额外的字符串 , 方法是把一个名称和一个错误处理函数传递codecs . register_error函数 .
详见codes . register . error函数的文档 .
* * ------------------------------------------------------------------------------------------- * *
据我所知 , ASCII是所有编码的共同子集 , 因此 , 只要文本全是ASCII字符 , 编码就一定能成功 .
Python 3.7 新增了布尔值方法str . isascii ( ) , 用于检查Unicode文本是不是全部由ASCII字符构成 .
如果是 , 那就可以放心使用任何编码把文本转换成字节序列 , 而且肯定不会抛出UnicodeEncodeError .
并非所有字节都包含有效的ASCII字符 , 也并非所有字节序列都是有效的UTF- 8 或UTF- 16 码点 .
因此 , 把二进制序列转换成文本时 , 如果假定使用的是这两个编码中的一个 ,
则遇到无法转换的字节序列时将抛出UnicodeError .
另一方面 , 'cp1252' , 'iso8859_1' 和 'koi8_r' 等陈旧的 8 位编码能解码任何字节序列流 ( 包括随机噪声 ) ,
而不抛出错误 .
因此 , 如果程序使用错误的 8 位编码 , 则可能生成乱码 , 也不会报错 .
* --------------------------------------------------------------------------------------------- *
乱码字符称为鬼符 ( gremlin ) 或mojibake ( 文字化け , '变形文本' 的日文 ) .
* --------------------------------------------------------------------------------------------- *
>> > octets = b'Montr\xe9al'
>> > octets. decode( 'cp1252' )
'Montréal'
>> > octets. decode( 'iso8859_7' )
'Montrιal'
>> > octets. decode( 'koi8_r' )
'MontrИal'
>> > octets. decode( 'utf_8' )
File "<stdin>" , line 1 , in < module>
UnicodeDecodeError:
'utf-8' codec can't decode byte 0xe9 in position 5 : invalid continuation byte
>> > octets. decode( 'utf_8' , errors= 'replace' )
'Montr�al'
Python 3 默认使用UTF- 8 编码源码 , Python2则默认使用ASCII .
如果加载的 . py模块中包含UTF- 8 之外的数据 , 而没有声明编码 , 那么将看到类似下面的消息 .
SyntaError: Non- UTF- 8 code starting with '\xe1' in file ola. py on line
1 , but no encoding declared; see http: // python. org/ dev/ peps/ pep- 0263 / for details
GND / Linux和macOS系统大都使用UTF- 8 ,
因此打开在Windows系统中使用cp1252编码的 . py文件时就可能遇到这种情况 .
注意 , 这个错误在Windows版Python中可能会发生 , 因为Python 3 源码在所有平台均默认使用UTF- 8 编码 .
为了解决这个问题 , 可以在文件顶部添加一个神奇的coding注释 , 如示例 4 - 7 所示 .
示例 4 - 7 ola . py : 打印葡萄牙语 '你好, 世界!' .
print ( 'Olá, Mundo!' )
* --------------------------------------------------------------------------------------------- *
现在 , Python 3 源码不再限于使用ASCII , 而是默认使用优秀的UTF- 8 编码 ,
因此要修正源码的陈旧编码 ( 例如 'cp1252' ) 问题 , 最好将其转换成UTF- 8 , 别去麻烦coding注释 .
如果你的编辑器不支持UTF- 8 , 那么是时候换一个了 .
( 国内Windows系统上的命令行使用的默认编码是GBK ,
因此在cmd中启动Python解释器后 , 输入的命令也会默认使用GBK编码 . )
* --------------------------------------------------------------------------------------------- *
假如有一个文本文件 , 里面保存的是源码或诗句 , 但是你不知道它的编码 .
那么 , 如何查明具体使用的是什么编码? 4.5 .4 节将揭晓答案 .
如何自己找出字节序列的编码呢? 简单来说 , 不能 . 这只能由别人告诉你 .
有些通行协议和文件格式 , 例如HTTP和XML , 通过首部明确指明内容编码 .
如果字节流中包含大于 127 的字节值 , 则可以肯定 , 用的不是ASCII编码 .
另外 , 按照UTF- 8 和UTF- 16 的设计方式 , 可用的字节序列也受到限制 .
( 在设计UTF- 8 和UTF- 16 编码方式时 , 字节序列的组合方式是受到限制的 ,
这是为了确保解码过程的正确性和一致性 .
例如 , UTF- 8 编码使用不同的字节序列来表示不同范围的Unicode字符 ,
而字节序列的格式和组合方式受到特定规范的限制 ,
例如 , 对于多字节字符 , 首字节的高位用来指示该字符所需的字节数 ,
后续字节的高位则有特定规则 , 以确保字节序列的有效性 . )
* -------------------------------------LEO猜测和UTF- 8 解码的技巧--------------------------------- *
( 以下几段摘自技术审校Leonardo Rochael在本书草稿中留下的评语 ) .
按照UTF- 8 的设计方式 , 一段随机字节序列 ,
甚至是使用其他编码得到的随机字节序列 , 解码结果几乎不可能是乱码 , 更不会抛出UnicodeDecodeError .
原因在于 , UTF- 8 转义序列绝不使用ASCII字符 , 而且转义序列具有位模式 ,
即使是随机数据也很难产生无效的UTF- 8 字符 .
因此 , 如果你可以把十进制代码大于 127 的字节解码为UTF- 8 , 那么它使用的编码可能就是UTF- 8.
( 上面只是猜测而已 , 实际上并非如此 , 不完整的字节序列可定会抛出UnicodeDecodeError . )
* --------------------------------------------------------------------------------------------- *
然而 , 就像人类语言也有规则和限制一样 , 只要假定字节流是人类可读的纯文本 , 就可能通过试探和分析找出编码 .
例如 , 如果b '\x00' 字节经常出现 , 那就可能是 16 为或 32 位编码 , 而不是 8 位编码方案 ,
因为纯文本中不能包含空字符 ;
( 空字符 ( Null character , 别名 '空格' ) : 是一种控制字符 ,
它在文本中用于分隔单词和句子,并提供可读性和排版效果其对应的ASCII码是 0.
空字符通常被认为是不可见或无意义的字符 , 并且在文本内容中是不被允许的 .
纯文本通常包含可打印字符 , 如字母 , 数字 , 标点符号等 , 但不包括控制字符或特殊字符 . )
如果字节序列b '\x20\x00' 经常出现 , 那就可能是UTF- 16 LE编码中的空格字符串 ( U + 0020 ) ,
而不是鲜为人知的U + 2000 EN QUAD 字符---谁知道这是什么呢 !
统一字符编码侦测包Chardet就是这么工作的 , 它能识别所有支持的 30 种编码 .
Chardet是一个Python库 , 可以在程序中使用 , 不过它也提供了命令行实用工具chardetect ,
下面使用他侦测本章书稿文件的编码 .
$ chardetect 04 -text-byte . asciiidoc
04 -text-byte . asciidoc : ytf- 8 with confidence 0.99
import chardet
str1 = '你好!'
for code in [ 'utf-8' , 'utf-16' , 'gbk' ] :
code_str = str1. encode( code)
print ( code_str)
result = chardet. detect( code_str)
print ( result[ 'encoding' ] )
"""
b'\xe4\xbd\xa0\xe5\xa5\xbd!'
utf-8
b'\xff\xfe`O}Y!\x00'
UTF-16
b'\xc4\xe3\xba\xc3!'
TIS-620
"""
二进制序列编码的文本通常不包含明确的编码线索 ,
而UTF格式可以在文本内容的开头添加一个字节序标记 , 详见 4.5 .4 节 .
在示例 4 - 4 中 , 你可能注意到了 , UTF- 16 编码的序列开头有几个额外的字节 , 如下所示 .
>> > u16 = 'El Niño' . encode( 'utf_16' )
>> > u16
b'\xff\xfeE\x00l\x00 \x00N\x00i\x00\xf1\x00o\x00'
我指的是b '\xff\xfe' . 这是BOM , 即 '字节序列标记' ( byte-order mark ) , 指明编码时使用Inter CPU的小端序 .
在小端序设备中 , 各个码点的最低有效字节在前面 .
例如 , 字母 'E' 的码点是U + 0045 ( 十进制数 69 ) , 在字节偏移的第 2 位和第 3 位编码为 69 和 0.
>> > list ( u16)
[ 255 , 254 , 69 , 0 , 108 , 0 , 32 , 0 , 78 , 0 , 105 , 0 , 241 , 0 , 111 , 0 ]
在大端序CPU中 , 表明顺序反过来 , 'E' 被编码为 0 和 69.
为了避免混淆 , UTF- 16 编码在要编码的文本前面加上特殊的不可见字符ZERO WIDTH NOBREAK SPACE ( U + FFFF ) .
在小端序系统中 , 这个字符编码为b '\xff\xfe' ( 十进制数 255 , 244 ) .
因为按照设计 , Unicode标准没有U + FFFF字符 , 在小端序编码中 ,
字节序列b '\xff\xfe' 必定是ZERO WIDTH NOBREAK SPACE , 所以编码解释器知道该用哪个字节序列 .
UTF- 16 有两个变种 : UTF16LE , 显式指明使用小端序 ; UTF- 16 BE , 显式指明使用大端序 .
如果直接使用这两个变种 , 则不生成BOM .
>> > u16le = 'El Niño' . encode( 'utf_16le' )
>> > list ( u16le)
[ 69 , 0 , 108 , 0 , 32 , 0 , 78 , 0 , 105 , 0 , 241 , 0 , 111 , 0 ]
>> > u16le = 'El Niño' . encode( 'utf_16be' )
>> > list ( u16le)
[ 0 , 69 , 0 , 108 , 0 , 32 , 0 , 78 , 0 , 105 , 0 , 241 , 0 , 111 ]
如果有BOM , 那么UTF- 16 编码解释器应把开头的ZERO WIDTH NOBREAK SPACE字符去掉 ,
只提供文件中真正的文本内容 .
根据Unicode标准 , 如果文件使用UTF- 16 编码 , 而且没有BOM , 那么应该假定使用的是UTF- 16 BR ( 大端序 ) .
然而 , Inter x86架构用的是小端序 , 因此也有很多文件用的是不带BOM的小端序UTF- 16 编码 .
字节序只对一个字 ( word ) 占的一个字节的编码 ( 例如UTF- 16 和UTF- 32 ) 有影响 .
UTF- 8 的一大优势是 , 不管设备使用哪种字节序 , 生成的字节序始终一致 , 因此不需要BOM .
尽管如此 , 某些Windows应用程序 ( 比如Notepad ) 依然会在UTF- 8 编码的文件中添加BIM .
而且 , Excel会根据有没有确定BOM来确定文件是不是UTF- 8 编码 ,
不然它就假设内容使用Windows代码页 ( code page ) 编码 .
带有BOM的UTF- 8 编码 , 在Python注意的编码解码器中叫作UTF- 8 -SIG .
UTF- 8 -SIG编码的U + FEFF字符是一个三字节序列 : b '\xef\xbb\xbf' .
因此 , 如果文件以这三个字节开头 , 可能就是带有BOM的UTF- 8 文件 .
* ------------------------------------Caleb建议使用UTF- 8 -SIG------------------------------------ *
本书技术审校Caleb Hattingh建议始终使用UTF- 8 -SIG编码解码器读取UTF- 8 文件 .
这样做没有任何问题 , 因为不管文件带不带BOM , UTF- 8 -SIG都能正确读取 , 而且不返回BOM本身 .
不过 , 我在书中建议使用UTF- 8 方便互操作 .
举个例子 , 在Unix系统中 , 如果Python脚本以注释 # ! / usr / bin / env python3 开头 , 则可以用作可执行文件 .
为此 , 文件的前两个字节必须是b '#!' , 而有了BOM , 这个约定就被打破了 .
如果你需要导出带有BOM的数据 , 供其他应用使用 , 应使用UTF- 8 -SIG .
但是 , 请记住Python编码解码器文档中的一句话 : '不鼓励也不建议为UTF-8添加BOM' .
* --------------------------------------------------------------------------------------------- *
下面换个话题 , 讨论Python 3 处理文本文件的方式 .
目前处理文本的最佳实践是 'Unicode 三明治' 原则 ( 见图 4 - 2 ) . ⑤
( 注 5 : Ned Batchelder 在PyCon US 2012 做了精彩演讲 'Pragmatic Unicode' ,
这是我第一次听说 'Unicode 三明治' . )
根据这个原则 , 我们应当尽早把输入的bytes ( 例如读取文件得到 ) 解码成str .
在Unicode 三明治中 , '肉饼' 是程序的业务逻辑 , 在这里只能处理str对象 .
在其他处理过程中 , 一定不能编码或解码 .
对输出来说 , 则要尽量晚地把str编码成bytes .
多数Web框架是这样做的 , 在使用框架的过程中 , 我们很少接触butes .
例如 , 在Django中 , 视图应该输出Unicode字符串 ,
至于如何把响应编码成bytes ( 默认使用UTF- 8 ) , 是Django的事 .
图 4 - 2 : Unicode 三明治--目前处理文本的最佳实践
在Python 3 中 , 我们可以轻松地采纳 'Unicode 三明治' 的建议 ,
因为内置函数open ( ) 在读取文件时会做必要的解码 ,
以文本模式写入文件时还会做必要的编码 ,
所以调用my_file . read ( ) 方法得到的以及传给my_file . write ( text ) 方法的都是str对象 .
可见 , 处理文本文件很简单 .
但是 , 如果依赖默认编码 , 你就会遇到麻烦 .
看一下示例 4 - 8 中的控制台会话 . 你能发现问题吗 >
>> > open ( 'cafe.txt' , 'w' , encoding= 'utf_8' ) . write( 'café' )
4
>> > open ( 'cafe.txt' ) . read( )
'café'
示例 4 - 8 的问题是 , 写入文件时指定了UTF- 8 编码 , 读取文件时却没有这么做 .
Python假定使用Windows系统的默认编码 ( 代码页 1252 , Windows- 1252 , 全名Western European ,
导致文件的最后一个字节被解码成字符 'é' , 而不是 'é' .
我在 64 位Windows 10 ( build 18363 ) 中使用Python 3.8 .1 运行示例 4 - 8.
在新版GNU / Linux或MacOS中运行同样的语句则没有问题 ,
因为这几个操作系统的默认编码是UTF- 8 , 让人误以为一切正常 .
如果打开文件是为了写入 , 但是没有指定编码参数 , Python则会使用区域设置中的默认代码 ,
再使用同样的编码也能正确读取文件 .
然而 , 在不同的平台中 , 脚本生成的字节内容不一样 ,
即使是在同一个平台中 , 由于区域设置不同 , 也会导致兼容问题 .
* --------------------------------------------------------------------------------------------- *
需要在多台设备中或多种场合喜爱运行的代码 , 一定不能依赖默认编码 .
打开文件时始终应该明确传入encoding = 参数 ,
因为不同的设备使用的默认编码可能不同 , 有时隔一天也会发生变化 .
* --------------------------------------------------------------------------------------------- *
示例 4 - 8 有一个奇怪的细节 : 第一个语句中的write函数报告写入了 4 个字符 , 但是下一行读取时得到了 5 个字符 .
示例 4 - 9 在示例 4 - 8 的基础上增加了一些代码 , 对这个问题以及其他细节做了说明 .
>> > fp = open ( 'caft.txt' , 'w' , encoding= 'utf_8' )
>> > fp
< _io. TextIOWrapper name= 'caft.txt' mode= 'w' encoding= 'utf_8' >
>> > fp. write( 'café' )
4
>> > fp. close( )
>> > import os
>> > os. stat( 'cafe.txt' ) . st_size
5
>> > fp2 = open ( 'cafe.txt' )
>> > fp2
< _io. TextIOWrapper name= 'cafe.txt' mode= 'r' encoding= 'cp1252' >
>> > fp2. encoding
'cp1252'
>> > fp2. read( )
'café'
>> > fp3 = open ( 'caft.txt' , encoding= 'utf_8' )
>> > fp3
< _io. TextIOWrapper name= 'caft.txt' mode= 'r' encoding= 'utf_8' >
>> > fp3. read( )
'café'
>> > fp4 = open ( 'cafe.txt' , 'rb' )
>> > fp4
< _io. BufferedReader name= 'cafe.txt' >
>> > fp4. read( )
b'caf\xc3\xa9'
* --------------------------------------------------------------------------------------------- *
除非想判断编码 , 否则不要一二进制模式代开文本文件 .
即便你真的想判断编码 也应该使用Chardet , 而不是要中信发明轮子 ( 参见 4.5 .4 节 ) .
一般来说 , 而进制模式只能用于打开二进制文件 , 例如光栅图形 .
* --------------------------------------------------------------------------------------------- *
示例 4 - 9 的问题是 , 打开文本文件时依赖了默认设置 .
默认设置有许多来源 , 接下来会说明 .
在Python中 , I / O默认使用的编码都到几个设置的影响 ,
如示例 4 - 10 中的default_encodings . py脚本所示 .
import locale
import sys
expressions = """
locale.getpreferredencoding()
type(my_file)
my_file.encoding
sys.stdout.isatty()
sys.stdout.encoding
sys.stdin.isatty()
sys.stdin.encoding
sys.stderr.isatty()
sys.stderr.encoding
sys.getdefaultencoding()
sys.getfilesystemencoding()
"""
my_file = open ( 'dump' , 'w' )
for expression in expressions. split( ) :
value = eval ( expression)
print ( f' { expression: >30 } -> { value} ' )
sys . stdout . isatty ( ) : 它检查sys . stdout是否连接到终端设备上的控制台 .
如果返回True , 则表示sys . stdout是连接到终端设备上的标准输出流 .
否则 , 如果返回False , 则表示sys . stdout被重定向到另一个设备 , 如文件或管道 .
( Pycharm中运行肯对是False . )
示例 4 - 10 在GNU / Linux ( Ubuntu 14.04 ~ 19.10 ) 和macOS ( 10.9 ~ 10.14 ) 中的输入一样 ,
表明这些系统始终使用UTF- 8.
$ python3 default_encodings. py
locale. getpreferredencoding( ) - > 'UTF-8'
type ( my_file) - > < class '_io.TextIOWrapper' >
my_file. encoding - > 'UTF-8'
sys. stdout. isatty( ) - > True
sys. stdout. encoding - > 'utf-8'
sys. stdin. isatty( ) - > True
sys. stdin. encoding - > 'utf-8'
sys. stderr. isatty( ) - > True
sys. stderr. encoding - > 'utf-8'
sys. getdefaultencoding( ) - > 'utf-8'
sys. getfilesystemencoding( ) - > 'utf-8'
sys . stdin . encoding : 它是一个字符串 , 表示标准输入流 ( stdin ) 所使用的字符编码 .
这指定了从控制台读取文本时使用的字符编码 .
sys . stdout . encoding : 它是一个字符串 , 表示标准输出流 ( stdout ) 所使用的字符编码 .
这指定了在控制台上打印文本时使用的字符编码 .
sys . stderr . encoding : 它是一个字符串 , 表示标准错误流 ( stderr ) 所使用的字符编码 .
这指定了将错误消息输出到控制台时使用的字符编码 .
locale . getpreferredencoding ( ) : 这是一个函数 , 返回操作系统环境中的首选编码 .
它表示在处理文件和文本时应该使用的默认编码 .
该函数会尝试获取系统的首选编码 , 并返回一个字符串表示该编码 .
然而 , 在Windows中的输出有所不同 , 如示例 4 - 11 所示 .
> chep
Active code page: 437
> python default_encodings. py
locale. getpreferredencoding( ) - > 'cp1252'
type ( my_file) - > < class '_io.TextIOWrapper' >
my_file. encoding - > 'cp1252'
sys. stdout. isatty( ) - > True
sys. stdout. encoding - > 'utf-8'
sys. stdin. isatty( ) - > True
sys. stdin. encoding - > 'utf-8'
sys. stderr. isatty( ) - > True
sys. stderr. encoding - > 'utf-8'
sys. getdefaultencoding( ) - > 'utf-8'
sys. getfilesystemencoding( ) - > 'utf-8'
locale. getpreferredencoding( ) - > 'cp936'
type ( my_file) - > < class '_io.TextIOWrapper' >
my_file. encoding - > 'cp936'
sys. stdout. isatty( ) - > True
sys. stdout. encoding - > 'utf-8'
sys. stdin. isatty( ) - > True
sys. stdin. encoding - > 'utf-8'
sys. stderr. isatty( ) - > True
sys. stderr. encoding - > 'utf-8'
sys. getdefaultencoding( ) - > 'utf-8'
sys. getfilesystemencoding( ) - > 'utf-8'
自本书第一版出版后 , Windows自身和Windows版Python地域Unicode的支持有所改善 .
以前 , 在Windows7中使用Python 3.4 运行示例 4 - 11 , 报告 4 种编码 .
之前 , stdout . stdin和stderr使用的编码与chcp命名报告的代码也相同 , 现在全部使用utf- 8.
这样归功于Python 3.6 实现的 'PEP 528--Change Windows console encoding to UTF-8' ,
以及 ( 从 2018 年 10 月发布的Windows 1809 之后的 ) PowerShell和cmd . exe对Unicode的支持 .
⑥ 奇怪的是 , 把stdout写入控制台时 , chep和sys . stdout . encoding报告的编码不一样 .
( 注 6 : 来源 : 'Windows Command-Line: Unicode and UTF-8 Output Text Buffer' .
Windows命令行 : Unicode和UTF- 8 输出文本缓冲区 . )
( chep : 设置的代码页决定了控制台在显示文本时使用的字符编码 .
sys . stdout . encoding : 表示Python程序输出的编码 , 而不是控制台的代码页 .
当你使用print函数或将内容写入sys . stdout时 ,
Python会根据sys . stdout . encoding的值将字符串编码为字节流 , 并将其发送到标准输出 .
然后 , 操作系统将负责将这些字节流转换为控制台所使用的字符集编码进行显示 .
避免乱码你可以将Python的编码设置为与代码页相同的编码 .
命令行窗口中输入命令 : chcp 936
Python脚本中 :
import sys
sys . stdout . encoding = 'gbk'
以确保输出编码与代码页相同 . )
但是 , 现在我们可以在Windows中打印Unicode字符串了 , 不会出现编码错误 , 这是一大进步 .
然而 , 倘若把输出重定向到文件中 , 情况并不容乐观 , 详见后文 .
不要太过乐观 , 你心心念念的表情符号任然不一定能显示在控制台中 , 这取决于控制台使用的字体 .
另一个变化是同在Python 3.6 中实现的 'PEP 529--Change Windows filesystem encoding to UTF-8' ,
把文件系统的编码由Microsoft专属的MBCS改成了UTF- 8.
然而 , 如果把示例 4 - 10 的输出重定向到文件中 , 结果如下所示 .
Z: \> python default_encodings. py > encodings. log
locale. getpreferredencoding( ) - > 'cp936'
type ( my_file) - > < class '_io.TextIOWrapper' >
my_file. encoding - > 'cp936'
sys. stdout. isatty( ) - > False
sys. stdout. encoding - > 'gbk'
sys. stdin. isatty( ) - > True
sys. stdin. encoding - > 'utf-8'
sys. stderr. isatty( ) - > True
sys. stderr. isatty( ) - > True
sys. stderr. encoding - > 'utf-8'
sys. getdefaultencoding( ) - > 'utf-8'
sys. getfilesystemencoding( ) - > 'utf-8'
那么 , sys . stdout . isatty ( ) 的值变成False ,
sys . stout . encoding由 locale . getpreferredencoding ( ) 设置 ( 在那台设备中是 'cp1252' , 国内 'cp936' ) .
而sys . stdio . encoding和sys . stderr . encoding任然是utf- 8.
* --------------------------------------------------------------------------------------------- *
在示例 4 - 12 中 , 我使用 '\N{}' 转义Unicode字面量 , 内部是字符的名称 .
这样做是比较麻烦 , 不过安全 , 如果字符名称不存在 , 则Python抛出SyntaxError .
这比编写一个十六进制数好多了--它可能出错 , 而且不容易察觉 .
而且 , 有时你会在注释中说明字符代码的意思 , 那么直接使用 \ N { } 岂不是更好 .
* --------------------------------------------------------------------------------------------- *
这意味着 , 示例 4 - 12 把输出打印到控制台中时一切正常 , 而把输出中定向到文件中时就可能遇到问题 .
CP437 : 是英语 ( 美国 ) 的字符集 .
CP1252 : 是拉丁字母的字符编码 , 主要用于英文或某些其他西方文字 .
import sys
from unicodedata import name
print ( sys. version)
print ( )
print ( 'sys.stdout.isatty(): ' , sys. stdout. isatty( ) )
print ( 'sys.stdout.encoding: ' , sys. stdout. encoding)
print ( )
test_chars = [
'\N{HORIZONTAL ELLIPSIS}' ,
'\N{INFINITY}' ,
'\N{CIRCLED NUMBER FORTY TWO}' ,
]
for char in test_chars:
print ( f'Trying to output { name( char) } :' )
print ( char)
示例 4 - 12 显示sys . stdout . isatty ( ) 和sys . stdout . encoding的值 , 以及以下 3 个字符 .
• '…' ( HORIZONTAL ELLIPSIS ) : CP 1252 中存在 , CP 437 中不存在 .
• '∞' ( INFINITY ) : CP 437 中存在 , CP 1252 中不存在 .
• '㊷' ( CIRCLED NUMBER FORTY TWO ) : CP 437 和 CP 1252 中都不存在 .
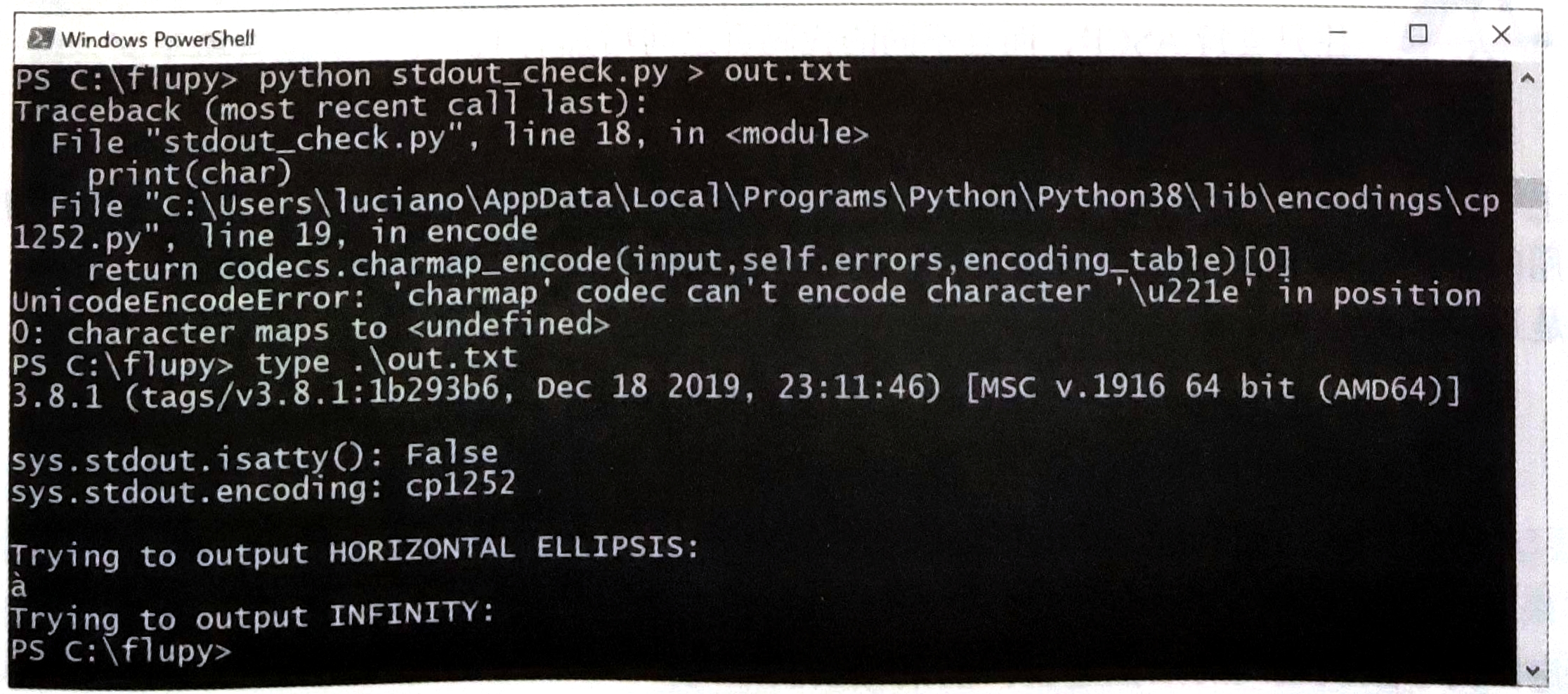
在PowerShell或cmd . exe中运行stdout_check . py , 结果如图 4 - 3 所示 .
图 4 - 3 : 在PowerShell中运行stdout_check . py .
尽管chcp报告当前的活动代码页是 437 , 但是sys . stdout . encoding的值是UTF- 8 ,
因此 , HORIZONTAL ELLIPSIS 和 INFINITY 都能正确输出 .
CIRCLED NUMBER FORTY TWO显示为一个方框 , 没有抛出错误 .
这可能表明PowerShell能识别这个字符 , 只是控制台使用的字体没有显示它的字形 .
然而 , 把stdout_check . py的输出重定向到文件中 , 我得到的结果如图 4 - 4 所示 .
图 4 - 4 : 在PowerShell中运行stdout_check . py , 重定向输出 .
图 4 - 4 中的第一个问题是提到 '\u221e' 字符的UnicodeEncodeError ,
因此sys . stdout . encoding的值是 'cp1252' , 这个代码页没有INFINITY字符 .
使用type命令读取out . txt文件 ( 也可以使用Windows平台中的编辑器 , 例如VS Code或Sublime Text ) ,
你会发现HORIZONTAL ELLIPSIS显示为 'à' ( LATIN SMALL LETTER A WITH GRAVE ) .
这是因为 , 字节值 0x85 在CP 1525 中表示 '...' , 而在CP 437 中表示 'à' .
可见 , 活动代码也还是有影响的 , 只是不那么合理 , 用处也不大 , 对Unicode体验有一定干扰 .
* * ------------------------------------------------------------------------------------------- * *
以上试验使用一台为美国市场配置的笔记本计算机 , 在Windows 10 OEM中运行 .
为其他国家及地区本地化的Windows版本可能使用不同的编码配置 .
例如 , 在巴西 , Windows控制台默认使用代码页 850 , 而不是 437.
* * ------------------------------------------------------------------------------------------- * *
根据示例 4 - 11 使用的不同编码 , 我们总结一下令人抓狂的默认编码 .
• 打开文件时如果没有指定encoding参数 ,
则默认编码由locale . getpreferredencoding ( ) 指定 ( 示例 4 - 11 中是 'cp1252' , 国内是 'cp936' ) .
• 在Python 3.6 之前 , sys . stdout / stdin / stderr编码由环境编码PYTHONIOENCODING设置 ,
现在 , Python忽略了这个变量 , 除非把PYTHONLEGACYWINDOWSSTDIO设为一个非空字符串 .
否则 , 交互环境下的标准I / O使用UTF- 8 编码 ,
重定向到文件I / O则使用locale . getpreferredencoding ( ) 定义的编码 .
• 在二进制数据和str之间转换时 , Python内部使用sys . getdefaultencoding ( ) .
改设置不可更改 .
• 编码和解码文件名 ( 不是文件内容 ) 使用sys . getfilesystemencoding ( ) .
对于open ( ) 函数 , 如果传入的文件名参数是str类型 , 则使用sys . getfilesystemencoding ( ) ,
如果传入的文件名称是bytes类型 , 则不经改动 , 直接传递给操作系统API .
* * ------------------------------------------------------------------------------------------- * *
在GNU / Linux和macOS中 , 这些编码的默认值都是UTF- 8 , 而且多年以来均是如此 , 因此I / O能处理所有Unicode字符 .
在Windows中 , 不仅同一个系统中使用不同的编码 , 而且一些代码页 ( 例如 'cp850' 和 'cp1252' ) 往往仅支持ASCII ,
而且不同的代码页 2 之间增加的 127 个字符也有所不同 .
因此 , 如不多加小心 , Windows用户就会更容易遇到编码问题 .
* * ------------------------------------------------------------------------------------------- * *
总综上 , locale . getpreferredencoding ( ) 返回的编码是最重要的 , 即使打开文本文件时默认使用的编码 ,
也是把sys . stdout / stdin / stderr重定向到文件时默认使用的编码 .
然而 , 文档是这样说的 ( 摘录部分 ) :
locale . getpreferredencoding ( do_setlocale = True )
根据用户偏好设置 , 返回文本数据的编码 .
用户偏好设置在不同的系统中以不同的方式设置 , 而且在某些系统中可能无法通过编程方式设置 ,
因此这个函数返回的只是猜测的的编码 . . . . . . .
因此 , 关于默认编码的最佳建议 : 别以来默认编码 .
遵从 'Unicode 三明治' 的建议 , 而且始终在程序中显示指定编码 , 你将避免很多问题 .
可惜 , 即使把bytes正确转换成str , Unicode仍然有不尽如人意的地方 .
4.7 节和 4.8 节讨论的话题对SACII世界来说很简单 , 但在Unicode领域就变得相当复杂 :
文本规范化 ( 即为了比较而把文本转换成统一的表述 ) 和排序 .
因为Unicode有组合字符 ( 变音符和附加到前一个字符上的其他记号 , 打印是作为一个整体 ) ,
所以字符串比较起来很复杂 .
例如 , 'café' 这个词可以使用两种方式构成 , 分别有 4 个和 5 个码点 , 但是结果看起来完全一样 .
>> > s1 = 'café'
>> > s2 = 'cafe\N{COMBINING ACUTE ACCENT}'
>> > s1, s2
( 'café' , 'café' )
>> > len ( s1) , len ( s2)
( 4 , 5 )
>> > s1 == s2
False
把COMBINING ACUTE ACCENT ( U + 0301 ) 放在 'e' 后面 , 得到的字符是 'é' .
按Unicode标准规定 , 'é' 和 'e\u0301' 是标准等价物 ( canonical equivalent ) , 应用程序应把它们视作相同的字符 .
但是 , Python看到的不不同的码点 , 因此判断二者不相等 .
这个问题的解决方案是使用unicodedate . normalize ( ) 函数 .
该函数的第一个参数是 'NFC' , 'NFD' , 'NFKC' 和 'NFKD' 这 4 个字符串中的一个 .
下面先说明前两个 .
NFC ( normalization Form C ) 使用最少的码点构成等价的字符串 ,
而NFD把合成字符分解成字符和单独的组合字符 .
这两种规范化方式都让比较行为符合预期 , 如下所示 .
>> > from unicodedata import normalize
>> > s1 = 'café'
>> > s2 = 'cafe\N{COMBINING ACUTE ACCENT}'
>> > len ( s1) , len ( s2)
( 4 , 5 )
>> > len ( normalize( 'NFC' , s1) ) , len ( normalize( 'NFC' , s2) )
( 4 , 4 )
>> > len ( normalize( 'NFD' , s1) ) , len ( normalize( 'NFD' , s2) )
( 5 , 5 )
>> > normalize( 'NFC' , s1) == normalize( 'NFC' , s2)
True
>> > normalize( 'NFD' , s1) == normalize( 'NFD' , s2)
True
>> > from unicodedata import normalize, name
>> > e = normalize( 'NFD' , 'é' )
>> > len ( e) , e
( 2 , é)
>> > for s in e:
. . . print ( name( s) )
. . .
e LATIN SMALL LETTER E
́ COMBINING ACUTE ACCENT
键盘驱动通常能输出合成字符 , 因此用户输入的文本默认是NFC形式 .
不过 , 安全起见 , 保存文本之前 , 最好使用normalize ( 'NFC' , user_text ) 规范化字符串 .
NFC也是W3C推荐的规范化形式 ,
详见 'Character Model for the World Web:String Matching and Searching' .
使用NFC时 , 有些单体字符会被规范化成另一个单体字符 .
例如 , 电阻的单位欧姆 ( Ω ) 会被规范化成希腊字符大写的奥米伽 .
二者在视觉上是一样的 , 但是比较时并不相等 , 因此要规范化 , 以防止出现意外 .
>> > from unicodedata import normalize, name
>> > ohm = '\u2126'
>> > name( ohm)
'OHM SIGN'
>> > ohm_c = normalize( 'NFC' , ohm)
>> > name( ohm_c)
'GREEK CAPITAL LETTER OMEGA'
>> > ohm == ohm_c
False
>> > normalize( 'NFC' , ohm) == normalize( 'NFC' , ohm_c)
True
另外两种规范化形式NFKC和NFKD , 字母K表示 'compatibility' ( 兼容性 ) .
这个两种规范化形式较为严格 , 对所谓的 '兼容字符' 有影响 .
虽然Unicode的目标是为每一个字符提供 '标准' 的码点 , 但是为了兼容现有标准 , 有些字符会出现多次 .
例如 , 尽管希腊字母表中有 'μ' 这个字母 ( 码点是U + 03 BC , GREEK SMALL LETTER MU ) ,
但Uniocode还是添加了 '微' 符号µ ( U + 00 B5 , MICRO SIGN ) , 以便与latin1相互转换 .
因此 , '微' 符号是一个 '兼容字符' .
在NFKC和NFKD形式中 , 兼容字符经兼容性分解 , 被替换成一个或多个字符 .
即便这样有些格式损失 , 但仍然是 '首选' 表述--理想情况下 , 格式化是外部标记的职责 , 不应该由Unicode处理 .
举两个例子 , 二分之一 '½' ( U + 00 BD ) 经过兼容性分解 , 得到 3 个字符序列 , 即 '1/2' ;
'微' 符号μ ( U + 00 B5 ) 经过兼容性分解 , 得到小写字母 'μ' ( U + 03 BC ) . ⑦
( 注 7 : '微' 符号是兼容字符 , 而欧姆符号不是 , 这真是奇怪 .
鉴于此 , NFC不改动 '微' 符号 , 但会把欧姆符号变成大写的奥米伽 .
而NFKC和NFKD则把欧姆符号和 '微' 符号都变成其他字符 . )
下面是NFKC规范化的具体效果 .
>> > from unicodedata import normalize, name
>> > half = '\N{VULGAR FRACTION ONE HALF}'
>> > print ( half)
½
>> > normalize( 'NFKC' , half)
'1⁄2'
>> > for char in normalize( 'NFKC' , half) :
. . . print ( char, name( char) , sep= '\t' )
. . .
1 DIGIT ONE
⁄ FRACTION SLASH
2 DIGIT TWO
>> > four_squared = '4²'
>> > normalize( 'NFKC' , four_squared)
'42'
>> > micro = 'µ'
>> > micro_kc = normalize( 'NFKC' , micro)
>> > micro, micro_kc
( 'µ' , 'μ' )
>> > ord ( micro) , ord ( micro_kc)
( 181 , 956 )
>> > name( micro) , name( micro_kc)
( 'MICRO SIGN' , 'GREEK SMALL LETTER MU' )
使用 '1/2' 替代 '½' 可以接受 , '微' 符号也确实是小写希腊字母 'µ' , 但是把 '4²' 转换成 '42' 就改变原意了 .
应用程序可以把 '4²' 保存为 '4<sup>2</sup>' , 可是normalize函数对格式一无所知 .
因此 , NFKC或NFKD可能会损失或曲解信息 , 不过可以为搜索和索引提供便利的中间表述 .
然而 , Unicode出现之前 , 看似简单的事情往往变得更复杂 .
VULGAR FRACTION ONE HALF经NFKC规范化 , 1 和 2 之间用的是FRACTION SLASH , 而不是SOLIDUS ,
即我们熟悉的ASCII字符 '斜线' ( 十进制代码为 47 ) .
因此 , 如果用户搜索由 3 个ASCII字符序列构成的 '1/2' , 则不会找到规范化之后的Unicode序列 .
* * * ----------------------------------------------------------------------------------------- * * *
NFKC和NFKD规范化形式会导致数据损失 , 应只在特殊情况下使用 ,
例如 , 搜索和索引 , 而不能用于持久存储文本 .
* * * ----------------------------------------------------------------------------------------- * * *
为搜索或索引准备文本时 , 还有一个有用的操作 , 即 4.7 .1 节讨论的大小写同一化 .
大小写同一化其实就是把所有文本变成小写 , 再做些其他转换 .
这个操作由str . casefold ( ) 方法实现 .
对于只包含latin1字符的字符串s , s . casefold ( ) 得到的结果与s . lower ( ) 一样 ,
唯有两个例外 : '微' 符号 'µ' 变成小写希腊字母 'µ' ( 在多数字体中二者看起来一样 ) ;
德语Eszett ( 'sharp' , ß ) 变成 'ss' .
>> > micro = 'µ'
>> > name( micro)
'MICRO SIGN'
>> > micro_cf = micro. casefold( )
>> > name( micro_cf)
'GREEK SMALL LETTER MU'
>> > micro, micro_cf
( 'µ' , 'μ' )
>> > eszett = 'ß'
>> > name( eszett)
'LATIN SMALL LETTER SHARP S'
>> > eszett_cf = eszett. casefold( )
>> > eszett, eszett_cf
( 'ß' , 'ss' )
str . casefold ( ) 个str . lower ( ) 得到不同结果的码点有近 300 个 .
与Unicode相关的其他所有问题一样 , 大小写同一化也很复杂 , 有许多语言层面上的特殊情况 ,
但是Python核心团队尽心尽力 , 提供了一种能满足多数用户需求的方案 .
接下来的内容使用这些规范化知识开发了几个实用函数 .
由前文可知 , 我们可以放心使用NFC和NFD比较字符串 , 结果是合理的 .
对多数应用程序来说 , NFC是最好的规范形式 . 不区分大小写比较应该使用str . casefold ( ) .
如果需要处理多语言文本 , 你的工具箱应该增加示例 4 - 13 中的nfc_equal个fold_equal函数 .
"""
规范化Unicode字符串的使用函数, 确保准确比较.
使用NFC规范形式, 区分大小写:
>>> s1 = 'café'
>>> s2 = 'caf\u0301'
>>> s1 == s2
False
>>> nfc_equal(s1, s2)
True
>>> nfc_equal('A', 'a')
False
使用NFC闺房形式, 大小写同一化:
>>> s3 = 'Straße'
>>> s4 = 'strasse'
>>> 3s == s4
False
>>> nfc_equal(s3, s4)
False
>>> fold_qeual(s3, s4)
True
>>> fold_qeual(s1, s2)
True
>>> fold_qeual('A', 'a')
True
"""
from unicodedata import normalize
def nfc_equal ( str1, str2) :
return normalize( 'NFC' , str1) == normalize( 'NFC' , str )
def fold_equal ( str1, str2) :
return ( normalize( 'NFC' , str1) . casefold( ) ==
normaloze( 'NFC' , str2) . casefold( ) )
除了Unicode规范化和大小写同一化 ( 均为Unicode标准规定 ) 之外 ,
有时需要进行更为深入地转换 , 例如把 'café' 装换成 'cafe' .
4.7 .3 节将说明何时以及如何进行这种转换 .
Google搜索由很多技巧 , 其中一个显然是忽略变音符 ( 例如重音节 , 下加符等 ) ,
至少在某些情形下要这么做 .
去掉音节符不是正确的规范化方式 , 因为这往往会改变词的意思 , 而且可能让人误判搜索结果 .
但这对现实生活有帮助 , 人们有死后很懒 , 或者不知道怎么正确使用变音符 , 而且瓶邪规则会随时间变化 ,
因此实际语言中的重音经常变来变去 .
除了搜索 , 去掉变音还能让URL更易于阅读 , 知道对拉丁语系语言来说如此 .
如果想把字符串中的所有变音符都去掉 , 可以使用示例 4 - 14 中的函数 .
import unicodedata
import string
def shave_marks ( txt) :
"""删除所有变音符"""
norm_txt = unicodedata. normalize( 'NFD' , txt)
shaved = '' . join( c for c in norm_txt
if not unicodedata. combining( c) )
return unicodedata. normalize( 'NFC' , shaved)
示例 4 - 15 演示了shave_marks函数的结果 .
>> > order = '"Herr Voß: • ½ cup od Œtker™ caffè latte • bowl of açaί."'
>> > shave_marks( order)
'"Herr Voß: • ½ cup od Œtker™ caffe latte • bowl of acaι."'
>> > Greek = 'Ζέφυρος, Zéfiro'
>> > shave_marks( Greek)
'Ζεφυρος, Zefiro'
示例 4 - 14 定义的shave_marks函数使用起来没有问题 , 不过有点极端 .
通常 , 去掉变音符时为了把拉丁文变成纯粹的ASCII , 但是shave_marks函数还会修改非拉丁字符 ( 例如希腊字母 ) ,
而且只去掉重音符并不能把它们变成ASCII字符 .
因此 , 我们应该分析各个基字符 , 仅当字符在拉丁字母表中时才删除附加的记号 , 里示例 4 - 16 所示 .
def shave_marks_latin ( txt) :
"""删除所有拉丁基字符上的变音符"""
norm_txt = unicodedata. normalize( 'NFD' , txt)
latin_base = False
preserve = [ ]
for c in norm_txt:
if unicodedata. combining( c) and latin_base:
continue
preserve. append( c)
if not unicodedata. combining( c) :
latin_base = c in string. ascii_letters
shaved = '' . join( preserve)
return unicodedata. normalize( 'NFC' , shaved)
规范化步骤还可以更彻底 , 把西文文本中的常见符号 ( 例如弯引号 , 长破折号 , 项目符号等 )
替换成ascii中的对等字符 .
示例 4 - 17 中desaciize函数就是这么做的 .
single_map = str . maketrans( """‚ƒ„ˆ‹‘’“”•–—˜›""" ,
"""'f"^<''""---~>""" )
multi_map = str . maketrans( {
'€' : 'EUR' ,
'…' : '...' ,
'Æ' : 'AE' ,
'æ' : 'ae' ,
'Œ' : 'OE' ,
'œ' : 'oe' ,
'™' : '(TM)' ,
'‰' : '<per mille>' ,
'†' : '**' ,
'‡' : '***' ,
} )
multi_map. update( single_map)
def dewinize ( txt) :
"""把cp1252符号替换为ASCII字符或字符序列"""
return txt. translate( multi_map)
def asciize ( txt) :
no_marks = shave_marks_latin( dewinize( txt) )
no_marks = no_marks. replace( 'ß' , 'ss' )
return unicodedata. normalize( 'NFKC' , no_marks)
示例 4 - 8 演示了ascize函数的结果 .
>> > order = '"Herr Voß: • ½ cup od Œtker™ caffè latte • bowl of açaί."'
>> > dewinize( order)
'"Herr Voß: - ½ cup od OEtker(TM) caffè latte - bowl of açaί."'
>> > asciize( order)
'"Herr Voss: - 1⁄2 cup od OEtker(TM) caffe latte - bowl of acaί."'
* * * ----------------------------------------------------------------------------------------- * * *
不同语言删除变音符的规则不一样 . 例如 , 德语把 'ü' 变成 'ue' .
我们定义的asciize函数没有考虑这么多 , 可能适合你的语言 , 也可能不适合 .
不过 , 对葡萄呀语的处理是可以接受的 .
* * * ----------------------------------------------------------------------------------------- * * *
综上 , simplify . py中的函数做的事情超出了标准的规范化 , 而且对文本做进一步处理 , 很有可能改变原意 .
只有知道目标语言 , 目标用户群和转换后的用途 , 才能确定要不要做这么深入地规范化 .
我们对Unicode文本规范化的讨论到此结束 .
接下来探讨Unicode文本排序问题 .
给任何类型的序列排序 , Python都会逐一比较序列中的每一项 .
对字符串来说 , 比较的是码点 .
可是 , 一旦遇到非ASCII字符 , 结果就往往不尽如人意 .
下面对一个巴西产水果的列表进行排序 .
>> > fruits = [ 'caju' , 'atemoit' , 'cajá' , 'açaί' , 'acerola' ]
>> > sorted ( fruits)
[ 'acerola' , 'atemoit' , 'açaί' , 'caju' , 'cajá' ]
不同区域采用的排序规则有所不同 , 葡萄牙语等许多语言按照拉丁字母排序 ,
重音符和下加符几乎没什么影响 . ⑧
( 注 8 : 变音符对排序有影响的情况很少发生 , 只有两个词之间唯有变音节不同时才有影响 .
此时 , 带变音的词排在常规词的后面 . ( 正常情况下a与á相等 , 继续往后比较 . . . ) )
因此 , 排序时 , 'cajá' 视做 'caja' , 必然排在 'caju' 前面 .
排序后的fruits列表应该是下面这样 .
[ 'açaί' , 'acerola' , 'atemoit' , 'caju' , 'cajá' ]
在Python中 , 非ASCII文本的标准排序方式是使用locale . strxfrm函数 .
根据locale模块的文档 , 这个函数 '把字符串转换成适合所在区域进行比较的形式' .
使用locale . strxfrm函数之前 , 必须先为应用设定合适的区域设置 , 还要祈祷操作系统支持这项设置 .
示例 4 - 19 中的命令也许可以做到这一点 .
import locale
my_locale = locale. setlocale( locale. LC_COLLATE, 'pt_BR.UTF-8' )
print ( my_locale)
fruits = [ 'caju' , 'atemoit' , 'cajá' , 'açaί' , 'acerola' ]
sorted_fruits = sorted ( fruits, key= locale. strxfrm)
print ( sorted_fruits)
在区域设置为pt_BR . UTF- 8 的GNU / Linux ( Ubunte19 . 10 ) 中运行示例 4 - 19 , 得到的结果是正确的 .
pt_BR. UTF- 8
[ 'açaί' , 'acerola' , 'atemoit' , 'cajá' , 'caju' ]
因此 , 使用locale . strxfrm函数做排序键之后 , 要调用setlocale ( LC_COLLATE , < < your_locakke > > )
不过 , 有几个问题需要注意 .
• 区域设置全局生效 , 因此不建议在库中调用setlocale函数 .
应用程序或框架应该在启动进程时设置区域 , 而且此后不要再修改 .
• 操作系统必须支持你的设定的区域 , 否则serlocale函数会抛出locale . Error :
unsupported locale setting异常 .
• 你必须知道如何拼写区域名称 .
• 操作系统制造商必须正确实现你设定的区域 . 我在Ubuntu 19.10 中成功了 , 但是在macOS 10.14 中失败了 .
在macOS中 , setlocale ( LC_COLLATE , 'pt_BR.UTF-8' ) 调用返回字符串 'pt_BR.UTF-8' , 没有报错 .
但是 , sotred ( fruits , key = locale . strxfrm ) 的结果与sorted ( fruits ) 一样 , 也是错的 .
我在macOS中也试过 , fr_FR , es_ES和de_DE等区域 , locale . strxfrm均未生效 . ⑨
( 注 9 : 同样 , 我没找到解决方案 , 不过我发现其他人也报告了同样的问题 .
本书技术审校之一 Alex Martelli在他装有macOS 10.9 的Macintosh中使用setlocale和locake . strxfrm
没有任何问题 . 可见 , 结果因人而异 . )
因此 , 标准库提供的国际化排序方案有一定效果 ,
但是似乎只对GNU / Linux有良好的支持 ( 可能也支持Windows , 但你得是专家 ) .
即便如此 , 还是要依赖区域设置 , 而这会为部署带来麻烦 .
幸好 , 有一个较为简单的方案可用 , 即PyPI中的pyuca库 .
James Tauber , 意味高产的Django贡献值 , 他一定是感受到了这个痛点 , 因此开发了pyuca库 ,
单纯使用Python实现了Unicode排序算法 ( Unicode Collation Algorithm , UCS ) .
通过示例 4 - 20 可以看到这个库的用法是多么简单 .
>> > import pyuca
>> > coll = pyuca. Collator( )
>> > fruits = [ 'caju' , 'atemoit' , 'cajá' , 'açaί' , 'acerola' ]
>> > sorted_fruits = sorted ( fruits, key= coll. sort_key)
>> > sorted_fruits
[ 'açaί' , 'acerola' , 'atemoit' , 'cajá' , 'caju' ]
这样做简单多了 , 而且在GNI / Linux , masOS和Winsows中都能正确排序--至少这个简短的示例是正确的 .
pyuca不考虑区域设置 . 如果你想自定义排序方式 , 那么可以把自定义的排序表路径传递给Collator ( ) 构造函数 .
pyuca默认使用项目自带的allkeys . txt , 这是Unicode网站中默认UnICODE排序表的副本 .
* --------------------------------------------------------------------------------------------- *
Miro 建议使用PyICU排序Unicode文本
( 技术审校Miroslav Šedivý 是Unicode专家 , 通晓多种语言 . 下面是他对pyuca的评价 . )
pyuca有一种排序算法不考虑个别语言的字母排序 .
例如 , 德语中的Ä位于A和B之前 , 在瑞典语中Ä却位于Z之后 .
这种情况下建议PyICU , 这个库像区域设置一样牢靠 , 但不更改进程使用的区域设置 .
如果你想更改土耳其语中iİ / ıI的大小写 , 也需要使用PyICU .
PyICU中有一个拓展必须编译 , 因此在某些系统中 , 可能比单纯使用Python的pyuca难安装 .
* --------------------------------------------------------------------------------------------- *
随便说一下 , 那个排序表是Unicode数据库中众多数据文件中的一个 .
4.9 节讲解讨论Unicode数据库 .
Unicode标准提供了一个完整的数据库 ( 许多结构化文本文件 ) , 不经包括码点与字符名称之间的映射表 ,
好包括各个字符的元数据 , 以及字符之间的关系 .
例如 , Unicode数据库记录了字符是否可以打印 , 是不是字母 , 是不是数字 , 或者是不是其他数值符号 .
str的isalpha , isprintable , isdecimal和isnumeric等方法就是靠这些信息来判断的 .
str . casefold方法也使用一个Unicode表中的信息 .
* * ------------------------------------------------------------------------------------------- * *
unicodedata . category ( char ) 函数返回char在Unicode数据库中的类别 ( 以两个字母表示 ) .
判断类别使用高层级的str方法更简单 .
例如 , label中的每个字符都属于Lm , Lt , Lu , Ll或Lo类别 , 则label . isalpha ( ) 返回True .
* * ------------------------------------------------------------------------------------------- * *
unicodedata模块中有几个函数用于获取字符的元数据 .
例如 , unicodedata . name ( ) 返回一个字符在标准红的官方名称 , 如图 4 - 5 所示 .
⑩ ( 注 10 : 这是一个图像 , 二不是代码清单 ,
因为我写这本书时 O ' Reilly的数字出版工具链对表情符的支持尚不完整 . )
>> > from unicodedata import name
>> > name( 'A' )
'LATIN CAPITAL LETTER A'
>> > name( 'ã' )
'LATIN SMALL LETTER A WITH TILDE'
>> > name( '♛' )
'BLACK CHESS QUEEN'
>> > name( '😸' )
'GRINNING CAT FACE WITH SMILING EYES'
图 4 - 5 : 在Python控制台中探索unicodedata . name ( )
你可以利用name ( ) 函数构建一个应用程序 , 让用户通过名称搜索字符 .
图 4 - 6 展示了命令行脚本cf . py的效果 .
该脚本的参数为一个或多个单词 , 列出Unicode官方名称中带有这些单词的字符 .
cf . py脚本的源码在示例 4 - 21 中 .
$ . / cf. py cat smiling
U+ 1F638 😸 GRINNING CAT FACE WITH SMILING EYES
U+ 1F63A 😺 SMILING CAT FACE WITH OPEN MOUTH
U+ 1F63B 😻 SMILING CAT FACE WITH HEART- SHAPED EYES
图 4 - 6 : 使用cf . py查找微笑猫表情
* * * ----------------------------------------------------------------------------------------- * * *
不同的操作系统和不同应用程序对表情符号的支持差很大 .
近几年 , macOS终端对表情符号的支持最好 , 其次是GNU / Linux的现代化图形终端 ,
在Windows中 , cmd . exe和PowerShell现在支持Unicode输出 , 但 我在 2020 年 1 月写这一节时 ,
仍然不能显示表情符号--至少不是 '开箱即用' .
本书极速审校Leonardo Rochael告诉我 , Windows发布了全新的Windows Terminal ,
对Unicode的支持可能不陈旧的Microsoft控制台要更好 .
我还没来得及试试 .
* * * ----------------------------------------------------------------------------------------- * * *
注意 , 在示例 4 - 21 中 , find函数内的if语句使用issubset ( ) 方法
快速测试query集合中的所有单词是否出现在根据字符名称构成的单词列表中 .
得益于Python丰富的集合API , 我们不用嵌套语句for循环 , 再加上一个is语句检查 .
import sys
import unicodedata
START, END = ord ( ' ' ) , sys. maxunicode + 1
def find ( * query_words, start= START, end= END) :
query = { w. upper( ) for w in query_words}
for code in range ( start, end) :
char = chr ( code)
name = unicodedata. name( char, None )
if name and query. issubset( name. split( ) ) :
print ( f'U+ { code: 04x } \t { chr ( code) } \t { name} ' )
def mian ( words) :
if words:
find( * words)
else :
print ( 'Please provide words to find.' )
if __name__ == '__main__' :
mian( sys. argv[ 1 : ] )
unicodedata模块还有一些有趣的函数 .
4.9 .2 节会介绍其中的几个函数 , 用于从有数值意义的字符串中获取信息 .
unicodedata模块中有几个函数可以检查Unicode字符是不是表示数值 ,
如果是的话 , 还可能确定人类可读的具体数值 , 而不是码点数 .
输了 4 - 22 演示了unicodedata . name ( ) 和unicode . numeric ( ) 函数 ,
以及str的 . isdecimal ( ) 和 . isnumeric ( ) 方法 .
import unicodedata
import re
re_digit = re. compile ( r'\d' )
sample = '1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285'
for char in sample:
print ( f'U+ { ord ( char) : 04x } ' ,
char. center( 6 ) ,
're_dig' if re_digit. match ( char) else '_ ' ,
'isdig' if char. isdigit( ) else '_ ' ,
'isnum' if char. isnumeric( ) else '_ ' ,
f' { unicodedata. numeric( char) : 5.2f } ' ,
unicodedata. name( char) ,
sep= '\t' )
如果你的终端使用的字体自持所有这些字符的字形 , 则运行示例 4 - 22 得到的结果如图 4 - 7 所示 .
# 图 4 - 7 的内容 :
$ python3 numerics_demo . py
U + 0031 1 re_dig isdig isnum 1.00 DIGIT ONE
U + 00 bc ¼ _ _ isnum 0.25 VULGAR FRACTION ONE QUARTER
U + 00 b2 ² _ isdig isnum 2.00 SUPERSCRIPT TWO
U + 0969 ३ re_dig isdig isnum 3.00 DEVANAGARI DIGIT THREE
U + 136 b ፫ _ isdig isnum 3.00 ETHIOPIC DIGIT THREE
U + 216 b Ⅻ _ _ isnum 12.00 ROMAN NUMERAL TWELVE
U + 2466 ⑦ _ isdig isnum 7.00 CIRCLED DIGIT SEVEN
U + 2480 ⒀ _ _ isnum 13.00 PARENTHESIZED NUMBER THIRTEEN
U + 3285 ㊅ _ _ isnum 6.00 CIRCLED IDEOGRAPH SIX
图 4 - 7 : maxOS终端中显示的数值字符及其元数据 ; re_dig表示字符匹配正则表达式r '\d'
元数据 ( Metadata ) : 指的是数据的描述性信息 ( 多个数据组成 ) .
图 4 - 7 中的第 6 列是在字符上调用unicodedata . numeric ( char ) 函数得到的结果 .
这表明 , Unicode知道表示数字的符号的数值 .
因此 , 如果你想创建一个支持泰米尔数字和罗马数字的电子表格应用程序 , 那就放心去做吧 ! .
图 4 - 7 表明 , 正则biodasr '\d' 能匹配阿拉伯数字 1 和梵文数字 3 , 但是不能匹配isdigit方法判断为数字的其他字符 .
可见 , re模块对Unicode的支持并不充分 .
PyPI中有个新开发的regex模块 , 它的目标是最终取代re模块 , 提供更好的Unicode支持 .
⑪ 4.10 节将回过头来讨论re模块 .
( 注 11 : 不对这个示例来说 , regex模块在识别数字方法的表现并不比re模块更好 . )
本章用到了unicodedata模块中的几个函数 , 但是还有很多没有涵盖 .
请阅读unicodedata模块的文档进一步学习 .
接下来的内容会简要说明双模式API .
这种API提供的函数 , 接收的参数即可以是str也可以是bytes , 具体如何处理则根据参数的类型而定 .
Python标准库中的一些函数能接受str或bytes为参数 ,
根据其具体类型展示不同的行为 , re和os模块中就有这样的函数 .
如果使用bytes构建正则表达式 , 则 \ d和 \ w等模式只能匹配ASCII字符 ;
相比之下 , 如果是str模式 , 那就能匹配ASCII之外的Unicode数字和字母 .
示例 , 4 - 23 和图 4 - 8 展示了str和bytes模式对字母 , ASCII数字 , 上面和泰米数字的匹配情况 .
import re
re_numbers_str = re. compile ( r'\d+' )
re_words_str = re. compile ( r'\w+' )
re_numbers_bytes = re. compile ( rb'\d+' )
re_words_bytes = re. compile ( rb'\w+' )
text_str = ( "Ramanujan saw \u0be7\u0bed\u0be8\u0bef"
" as 1729 = 1³ + 12³ = 9³ + 10³." )
text_bytes = text_str. encode( 'utf-8' )
print ( f'Text\n { text_str!r } ' )
print ( 'Numbers' )
print ( ' str :' , re_numbers_str. findall( text_str) )
print ( ' bytes:' , re_numbers_bytes. findall( text_bytes) )
print ( 'Words' )
print ( ' str :' , re_words_str. findall( text_str) )
print ( ' bytes:' , re_words_bytes. findall( text_bytes) )
$ python3 ramanujan. py
Text
'Ramanujan saw ௧௭௨௯ as 1729 = 1³ + 12³ = 9³ + 10³.'
Numbers
str : [ '௧௭௨௯' , '1729' , '1' , '12' , '9' , '10' ]
bytes : [ b'1729' , b'1' , b'12' , b'9' , b'10' ]
Words
str : [ 'Ramanujan' , 'saw' , '௧௭௨௯' , 'as' , '1729' , '1³' , '12³' , '9³' , '10³' ]
bytes : [ b'Ramanujan' , b'saw' , b'as' , b'1729' , b'1' , b'12' , b'9' , b'10' ]
图 4.8 : 运行示例 4 - 13 中的ramanujan . py 脚本得到的结果截图 .
示例 4 - 23 是随便举的例子 , 目的是说明一个问题 ;
使用正则表达式可以搜索str和bytes , 但是在后一种情况下 ,
ASCII范围外的字节序列不会被当成数字和组成单词的字符 .
str正则表达式有个re . ASCII标准 , 能让 \ w , \ W , \ b , \ B , \ d , \ D , \ s和 \ S只能匹配ASCII字符 .
详re模块的文档 .
另一个重要的双模式模块是os .
GNU / Linux内核不理解Unicode , 因此你可能会遇到一些文件名 ,
其中的字节序列对任何合理的编码方案来说都是无效的 , 不能解码成str .
如果你使用客户端连接不同的操作系统中的文件服务器 , 那就尤其要注意这个问题 .
为了规避这个问题 , os模块中所有接受文件名或路径名的函数 , 即可以传入str参数 , 也可以传入bytes参数 .
传入str参数时 , 使用sys . getfilesystemencoding ( ) 获得的编码解码器自动转换参数 ,
操作系统回显时也使用该编码解码器解码 .
这几乎就是我们想要的行为 , 与Uniocde三明治最佳实践一致 .
( 使用sys . getfilesystemencoding ( ) 获取文件系统使用的编码 , 将字符串转为对应的字节序列去操作 . )
但是 , 如果必须处理 ( 可能是为了修正 ) 那些无法使用上述方法自动处理的文件名 ,
则可以把bytes参数传给os模块中的函数 , 得到bytes类型的返回值 .
如此一来 , 便可以处理任何文件或路径名 , 不管里面有多少鬼符 , 如示例 4 - 24 所示 .
>> > os. listdir( '.' )
[ 'abc.txt' , 'digits-of-π.txt' ]
>> > os. listdir( b'.' )
[ b'abc.txt' , b'digits-of-\xcf\x80.txt' ]
为了便于动手处理str或bytes类型的文件名或路径名 ,
os模块还提供了特殊的编码解码函数os . fsencode ( name_or_path ) 和os . fsdecode ( name_or_path ) .
这两个函数接受的参数可以是str或bytes类型 , 自Python 3.6 起 , 还可以是实现了os . PathLike接口的对象 .
Unicode话题深似海 , 我们对str和bytes的探索暂且告一段落 .
本章首先澄清了人们对一个字符等于一个字节的误解 .
随着Unicode的广泛使用 , 我们必须把文件字符串与它们在文件中的二进制序列表述区分开 ,
而且这是Python 3 强制要求区分的 .
对bytes , bytearray和memoryview等二进制序列数据类型做了简要概述之后 ,
我们转到了编码和解码的话题 , 通过示例展示了重要的编码解释器 ,
随后讨论了如何避免和处理臭名昭著的UnicodeEncodeError和UnicodeDecodeError ,
以及由于Python源文件编码错误导致的SytaxError .
然后 , 我们说明了再没有元数据的情况下检测编码的理论和实际情况 :
理论上 , 做不到这一点 ; 但实际上 , Chardet包能够正确处理一些流行的编码 .
随后介绍了字节序标记 , 这是UTF- 16 和UTF- 32 文件中常见的编码提示 , 某些UTF- 8 文件中也有 .
接下来的 4.6 节演示了如何打开文本文件 , 这是一项简单的任务 , 不过有个陷阱 ;
打开文本文件时encoding = 关键参数不是必须的 , 但是应该指定 .
如果没有指定编码 , 那么程序会想方法生成 '纯文本' , 如此一来 , 不一致的默认编码就会导致跨平台不兼容性 .
然后 , 我们说明了Python使用的几个默认编码设置 , 以及检测方法 .
对Windows用户来说 , 现实不容乐观 : 这些设置在同一台设备中往往有不同的值 , 而且各个设置相互不兼容 .
而对GNU / Linux和masOS用户来说 , 情况就好多了 , 几乎所有地方使用的默认编码都是UTF- 8.
Unicode为某些字符提供了不同的表示 , 匹配文本之前一定要规范化 .
说明规范化和大小写同一化 , 我给出了几个实用函数 , 你可以根据自己的需求改编 ,
其中有个函数locale模块正确排序Unicode文本 ( 有一些注意事项 ) .
此外 , 还可以使用外部包pyuca , 由此摆脱对捉摸不定的区域配置的依赖 .
最后 , 我们利用Unicode数据库编写了一个命令行实用脚本 , 按名称搜索字符 .
得益于Python强大的功能 , 这个脚本只有 28 行代码 .
我们还简单介绍了Unicode元数据 , 简要说明了双模式API .
双模式API提供的函数 , 根据传入的参数是str还是bytes类型 , 会产生不同的结果 .
Ned Batchelder在 2012 年PyCon US上所做的演讲非常出色 ,
题为 'Pragmatic Unicode, or, How Do I Stop the Pain?' .
Ned很专业 , 除了幻灯片和视频之外 , 他还提供了完整的文字记录 .
Esther Nam和Travis Fischer在PyCon 2014 上做了一场精彩的演讲 ,
题为 'Character encoding and Unicode in Python: How to(╯°Д°)╯︵ ┻━┻ with dignity' .
本章开头那句简短有力的话就是出自这次演讲 : '文本给人类阅读, 字节序列供计算机处理.'
本书第一版技术审校之一Lennert Regebro在 'Uniconfusing Unicode: What Is Unicode?'
这篇文中提出来 'Uaeful Mental Model of Unicode(UMMU)' 这一概念 .
Unicode是个复制的标准 , Lennart提出的UMMU是个很好的切入点 .
Python文档中 'Unicode HOWTO' 一文从几个不同的角度对本章涉及的话题做了讨论 ,
涵盖历史简介 , 句法细节 , 编码解码器 , 正则表达式 , 文件名和Unicode的I / O最佳实践 ( 即 Unicode 三明治 ) ,
而且每一节都给出了大量参考资料链接 .
Dive into Python 3 ( Mark pilgrim著 ) 是一本非常优秀的书 , 第 4 章讲到了Python 3 Unicode的支持 , 内容翔实 .
此外 , 该书第 15 章说明了Chardet库从Python2移植到Python 3 的过程 .
这是一个宝贵的案例分析 , 从中可以看出 , 从旧的str类型转换到新的bytes类型是造成迁移如此痛苦的主要原因 ,
也是检测编码的库应该关注的重点 .
如果你用过了Python2 , 但是刚接触Python 3 , 可以阅读Guido van Rossum写的 "What's New in Python 3.0" .
这篇文章简要列出了新版的 15 点变化 .
Guido开门见山地说道 : '你自以为知道的二进制数据要列出了新版的15点变化' .
Armin Ronacher的博客文章 'Tht Updated Guido Unicode on Python'
深入分析了Python 3 中Unicode的一些陷阱 ( Armin不太喜欢Python 3 ) .
< < Python Cookbook中文版 ( 第 3 版 ) > > 的第二章 '字符串和文本' 中有几个经典示例
谈到了Unicode规范化 , 文本清洗 , 以及在字节序列上执行面向文本的操作 .
第 5 章涵盖文件和I / O , '5.17将字节数据写入文本文件' 指出 , 任何文本文件的底层都有一个二进制流 ,
如果需要可以直接访问 . 之后 , '6.11读写二进制结构的数组' 用到了struct模块 .
Nick Coghlan的 'Python Notes' 博客中有两篇文章与本章的话题联系紧密 :
'Python 3 and ASCII Compatible Binary Protocols' 和 'Processing Text Files in Python 3' .
强烈推荐阅读 .
Python支持的编码列表参见codes模块文档中的 'Standard Encodings' 一节 .
如果需要通过编程方式获得那个列表 , 请看CPython源码中的 / Tools / unicode / listcodesc . py脚本是怎么做的 .
Unicode Explained ( Jukka K . Korpela著 ) 和Unicode Demystified ( Richard Gillam著 )
这两本书不是针对Python的 , 但是在我学习Unicode相关概念时给了我很大的帮助 .
Programming with Unicode ( Victor Stinner著 ) 是一本自出版图书 ,
可以免费阅读 ( Creative Commons BY-SA ) , 其中讨论了Unicode一般性话题 ,
还介绍了主流操作系统和几门编程语言 ( 包括Python ) 相关的工具和API .
W3C网站中的 'Case Folding:An Introduction' 和 ' Character Model for the World Wide Web :
Srting Matching ' 页面讨论了规范化相关的概念 , 前一篇是介绍性文章 ,
后一篇则是枯燥的标准用语写就的工作草案-- 'Unicode Standard Annex #15--Unicode Normalization Forms'
也是这种风格 . Unicode网站中的 'Frequently Asked Questions, Normalization' 更容易理解 ,
Mark Davis写的 'NFC FAQ' 也不错 . MARK是多个Unicode算法的作者 , 写作本书时 , 他还想担任Unicode联盟主席 .
2016 年 , 纽约现代艺术博物馆 ( Museum of Modern Art , MoMa ) 收藏了最初的 176 个表情符号 .
这些表情符号是栗天穣崇在 1999 年为日本移动运营商NTT DOCOMO设计的 .
根据Emojipedia网站中的 'Corrections the Record on the First Emoji Set' 一文 ,
表情符号的历史还可以追溯更早的时期-- 1997 年日本SoftBank公司最先在手机中部署了一套表情包 .
SoftBank的那套表情包有 90 个表情符号 , 现已纳入Unicode , 例如U + 1 F4A9 ( OILE OF POO ) .
Matthew Pothenberf创建的emojitracker网站实时更新Twitter上表情的使用量 .
在我写下这段话时 , Teitter最流行的表情符号是 FACE WITH TEARS OF JOY ( U + 1 F602 ) ,
使用量超过 3 313 667 315 次 .
* ---------------------------------------------杂谈-------------------------------------------- *
在源码中因该使用非ASCII名称吗?
Python 3 允许在源码中使用非ASCII标识符 .
> > > ação = 'PBR' # ação = stock
> > > ε = 10 * * - 6 # ε = epsilon
有写人不喜欢这样做 .
坚持使用ASCII标识符的最常见理由是 , 让每个人都能轻松地阅读和编辑代码 .
这种观点没有抓住要点--观点的持有者希望的是源码对于目标群体是可读的和可编辑的 , 而不是 '所有人' .
在一家跨国企业中 , 或者一个开源项目中 , 如果希望世界各地的人都能共享代码 , 那么标识推荐使用英语 ,
因此也要使用ASCII字符 .
然而 , 如果你是巴西的一名教师 , 你的学生更喜欢阅读用葡萄牙语命名的变量和函数 ( 当然 , 拼写要正确 ) ,
那么使用本地化键盘可以让他们轻松地输入变音符和重读元音 .
既然Python可以解析Unicode名称 , 而且现在源码默认使用UTF- 8 编码 ,
那么我认为没有必要项过去在Python 2 中那样 , 用不带重音符的葡头牙语言编写标识符 ,
除非你也要使用Python 2 运行代码 .
如果使用葡头牙语命名 , 却省略重音符 , 那么对任何人来说 , 代码都不可能更易于阅读 .
这是我作为一个说葡萄牙语的巴西人的观点 , 不过我相信这个道理是无国界的 :
任何人都应该选择能让团队成员更容易理解代码的语言 , 并使用正确的字符拼写 .
'纯文本' 是什么?
不经常处理英语文本的人 , 往往误认为 '纯文本' 指的是 ' ASCII .
Unicode词汇表是这样定义纯文本的 :
只由特定标准的码点序列组成的计算机编码文本 , 不含其他格式化或结构化信息 .
这个定义的前半句说的很好 , 但是后半句我不认同 .
HTML就包含格式化和结构化信息 , 但它依然是纯文本 ,
因为HTML文件中的每个字节都表示一个文本字符 ( 通常使用UTF- 8 编码 ) , 没有任何字节表示文本之外的信息 .
. png或 . xsl文档则不同 , 其中多数字节表示打包的二进制值 , 例如RGB值和浮点数 .
在纯文本中 , 数字使用符号序列表示 .
本书英文版使用一种名为AsciiDoc的存文本格式撰写 ( 把 'Ascii' 和 'Doc' 放在一起 , 有点讽刺 ) ,
它是O ' Reilly优秀的图书出版平台Atlas工具链中的一部分 .
AsciiDoc源文件是纯文本 , 但用的是UTF- 8 编码 , 而不是ASCII . 不然撰写本章必定痛苦不堪 .
姑且不论名称 , AsciiDos是一个很棒的工具 . ⑫
( 注 12 : 本书译稿页用AsciiDoc撰写 , 然后转换成图灵社区使用的Markdown格式 .
Markdown源文件也是纯文本 . ---译者注 )
Unicode世界正在不断扩张 , 但是有些边缘场景缺少支撑工具 .
比如 , 我想使用的字符在本书使用的字体中就不一定有 .
因此 , 本章有好几个代码示例用图像代替了 .
不过 , Ubuntu和macOS的终端能正确显示多数Unicode文本 , 包括 'mojibale' ( 文件化け ) 这个日语词 .
str的码点在RAM中如何表示
Python官方文档对str的码点在内存中如何存储避而不谈 . 毕竟 , 这是实现细节 .
理论上 , 怎么存储都没关系 , 不管内部表述如何 , 输出时每个str都要编码成bytes .
在内存中 , Python 3 使用固定数量的字节存储str的各个码点 , 以便高效访问任何字符或切片 .
从Python 3.3 起 , 创建str对象 , 解释器会检查里面的字符 , 选择最经济的内存布局 :
如果字符都在latin1字符集中 , 则使用一个字节存储一个码点 ;
否则 , 根据字符串中的具体字符 , 选择 2 个或 4 个字符存储一个码点 .
这是简要说明 , 完整细节请参阅 'PEP 393--Flexible String Representation' .
Python 3 对int类型的处理方式也像字符串表述一样灵活 :
如果一个整数在一个机器字中放下 , 那就存储在一个机器字中 ;
否则 , 解释器采用变长表述 , 类似于Python 2 中的long类型那样 .
这种崇明的做法得到推广 , 真是让人欣喜 !
然而 , 对应Python 3 , Armin Ronacher有句要说 . 他向我解释了这样做在实验中为什么不好 :
在一个原本全是ASCII字符的文本中添加一个RAT字符 ( U + 1 F400 ) , 内存中存储各个字符的数组会立即变大 .
原来 , 每个字符只占一个字节 , 而现在全占 4 个字节 .
此外 , 由于Unicode字符能以各种方式组合 , 按位置检索字符就没那么容易了 ,
从Unicode文本中提取切片也没有想象中那么简单 , 而且结果往往是错的 , 会产生乱码 .
随着表情符号的流行 , 这些问题只会越来越严重 .
* --------------------------------------------------------------------------------------------- *




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









