Celery是一个强大的异步任务队列 / 作业队列框架 , 它主要用于处理大量消息 , 同时为操作提供稳定可靠的消息传输机制 .
Celery的分布式特性允许任务分散到多个计算节点上并行处理 , 从而提高系统的可扩展性 , 可靠性和性能 .
Celery使用消息代理 ( 如 : RabbitMQ , Redis ) 来实现任务的发布和消费 , 支持任务的并发执行 , 定时调度和结果收集 .
分布式含义主要包括以下几个方面 :
* 1. 任务分散与并行处理 : 在Celery中 , 任务不再局限于单一的计算节点或进程 .
相反 , 它们可以被分散到多个计算节点 ( 可能是不同的服务器或虚拟机 ) 上进行处理 .
这些节点上的工作进程 ( Workers ) 可以并行地从任务队列中取出任务并执行 , 从而利用多核CPU或多台服务器的计算能力来加速任务处理 .
* 2. 网络通信与协作 : 这些分散在不同节点上的工作进程需要通过网络通信来协作 .
Celery使用消息中间件 ( 如 : RabbitMQ , Redis等 ) 作为通信桥梁 ,
工作进程从消息中间件接收任务消息 , 并将执行结果发送回消息中间件或指定的结果存储 .
这种网络通信机制使得各个节点之间能够实时共享任务状态和结果 , 确保任务能够按照预期的顺序和逻辑被执行 .
* 3. 高效的任务调度与执行 : Celery提供了一个强大的任务调度和执行框架 , 支持多种任务路由策略 , 优先级排序 , 重试机制等高级功能 .
这些功能使得Celery能够根据不同的业务需求和系统负载情况 , 智能地调度任务到最合适的节点上执行 , 从而实现高效的任务处理 .
* 4. 提高系统的可扩展性 , 可靠性和性能 : 由于Celery的分布式特性 , 系统可以轻松地通过增加计算节点来扩展处理能力 ,
以应对日益增长的任务量 .
同时 , 由于任务被分散到多个节点上执行 , 即使某个节点发生故障也不会影响整个系统的运行 , 从而提高了系统的可靠性和容错性 .
最后 , 通过并行处理和高效的任务调度机制 , Celery能够显著提高系统的处理性能 , 缩短任务处理时间 .
综上所述 , Celery的分布式含义是指它能够将任务分散到多个计算节点上并行处理 , 并通过网络通信和协作机制实现高效的任务调度和执行 .
这种分布式架构不仅提高了系统的可扩展性和可靠性 , 还显著提升了系统的处理性能 .
Celery的核心组件主要包括以下几个部分 :
* 1. 消息中间件 ( Broker ) .
作用 : 作为客户端和工作进程 ( Worker ) 之间的通信桥梁 , 负责接收来自客户端的任务消息 , 并将其分发给可用的Worker .
常见实现 :
- RabbitMQ : 高性能 , 可靠性强 , 支持复杂路由规则 , 是官方推荐的生产环境消息代理 .
- Redis : 轻量级 , 速度快 , 适合小规模应用或作为开发环境的选择 .
- Amazon SQS : 托管服务 , 无需自行维护服务器 , 适合云环境 .
* 2. 任务执行单元 ( Worker ) .
作用 : 从消息中间件获取待处理的任务 , 执行实际的业务逻辑 , 即运行被装饰为Celery任务的函数 .
特点 :
- Worker可以部署在多台服务器上 , 以分布式的方式运行 , 提高任务处理的并发性和吞吐量 .
- Worker内部维护子进程池 , 用于并行执行任务 .
- Worker通过Gossip协议等机制进行任务分配和选举 , 确保任务能够被合适的节点处理 .
* 3. 任务执行结果存储 ( Result Backend ) .
作用 : 存储每个已完成任务的结果 , 以便后续查询或处理 .
常见实现 :
- Redis : 速度快 , 适合小规模应用 .
- RabbitMQ : 虽然主要用于消息传递 , 但也可以用于结果存储 .
- 数据库 : 如PostgreSQL , MySQL等 , 适合需要持久化存储结果的应用场景 .
* 4. 任务调度器 ( Celery Beat ) .
作用 : 周期性地将配置中到期需要执行的任务发送到任务队列 .
Beat进程会读取配置文件的内容 , 并根据配置的时间间隔或特定时间点将任务添加到队列中 .
特点 :
- 提供了接口允许开发者自定义调度器 , 以满足复杂的定时任务需求 .
- 可以与Worker协同工作 , 实现定时任务和异步任务的统一处理 .
* 5. 客户端 ( Producer ) .
作用 : 用于发布后台作业 .
当与Web框架 ( 如Flask , Django ) 一起工作时 , 客户端通常与Web应用一起运行 , 并通过调用Celery API来发布任务 .
特点 :
- 客户端通过发送任务消息到消息中间件来触发任务的执行 .
- 可以是任何能够调用Celery API的应用程序或脚本 .
Celery框架的工作流程 :
* 1. 任务定义 : 任务是执行具体操作的逻辑单元 , 可以是Python函数或类的方法 .
这些任务通过装饰器 ( 如 @ app . task ) 被Celery识别 .
* 2. 任务提交 : 当应用程序需要执行某个任务时 , 它会调用该任务的 . delay ( ) 方法或 . apply_async ( ) 方法 .
这些方法负责将任务信息 ( 如函数名 , 参数等 ) 封装成消息 , 并发送到配置好的Broker队列中 .
* 3. Broker队列 : Broker队列是存储待执行任务的消息代理 , 如 : RabbitMQ , Redis等 .
它接收来自客户端的任务发布请求 , 并将这些任务消息存储在队列中等待处理 .
* 5. Worker工作者 : Worker是负责执行任务的工作进程 .
它启动后会连接到Broker , 并持续监听队列中的任务消息 .
一旦有新的任务消息到达 , Worker就会从队列中取出该任务 , 并在本地环境中执行它 .
执行结果会根据配置决定是否保存到结果存储 ( Backend ) 中 .
如果是异步任务 , Worker执行完毕后通常会将结果发送到Backend .
* 6. 调度器 ( Celery Beat ) : Celery Beat是一个独立的进程 , 用于定时调度任务的执行 .
它根据配置文件 ( 如 : Celery Beat Schedule ) 中定义的时间表 , 周期性地将定时任务发送到Broker队列中 .
Worker同样会监听这些由Celery Beat发送的定时任务 , 并执行它们 .
* 7. 结果存储 ( Backend ) : 结果存储用于保存任务的执行结果 .
Worker在执行完任务后 , 可以选择将结果发送到配置的Backend中 .
应用程序可以通过查询Backend来获取任务的执行结果 .
注意 : Worker是持续运行的进程 , 它会不断地从队列中取出任务并执行 , 直到被显式停止 .
同时 , Celery Beat也是一个持续运行的进程 , 它会根据配置的时间表定期向队列中发送任务 . 这样 , 就实现了任务的异步处理和定时调度 .
* celery -A yourmodule worker --loglevel = info : 启动Celery Worker进程 , 以便处理异步任务 .
-A选项后跟着项目名称 , –loglevel指定日志级别 .
* celery -A yourmodule beat --loglevel = info
启动Celery Beat进程 , 用于调度周期性任务 .
* celery -A yourmodule flower : 启动Flower , 一个用于监控和管理Celery集群的Web界面 .
* celery -A yourmodule purge : 清除所有已完成的任务结果 .
* celery -A yourmodule inspect active : 查看当前活动任务的信息 .
* celery -A yourmodule inspect scheduled : 查看所有计划任务的信息 .
* celery -A yourmodule inspect reserved : 查看所有已预订的任务 .
* celery -A yourmodule inspect revoked : 查看已撤销的任务 .
* celery -A yourmodule status : 查看Celery Worker的状态 .
* celery -A yourmodule control shutdown : 关闭Celery Worker .
* celery -A yourmodule control pool_grow n : 增加工作池中的工作进程数 .
* celery -A yourmodule control pool_shrink n : 减少工作池中的工作进程数 .
* celery -A yourmodule control rate_limit task_name rate : 限制任务的执行速率 .
* celery -A yourmodule control cancel_consumer worker_name : 取消指定Worker的所有任务 .
* celery -A yourmodule control enable_events : 启用Celery事件 .
* celery -A yourmodule control disable_events : 禁用Celery事件 .
* 1. 创建Celery应用 .
下载Celery框架命令 : pip install celery .
在Python中 , 首先需要导入Celery并创建一个Celery实例 .
这个实例需要指定应用的名称以及消息队列 ( Broker ) 的连接信息 .
Celery第一个参数用于指定Celery应用的名称 , 它作为 Celery 应用的唯一标识符 .
在分布式系统中 , 这有助于区分来自不同Celery应用的任务和消息 .
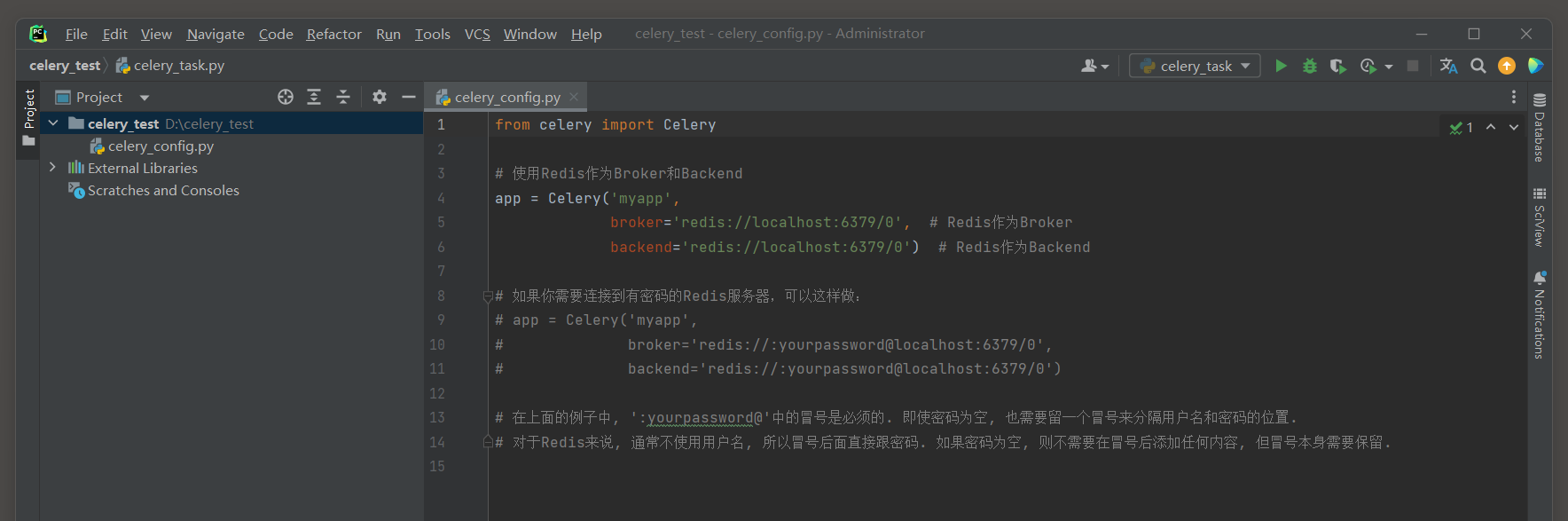
如果使用Redis作为消息队列 ( Broker ) 和任务结果存储后端 ( Backend ) , 需要按照Redis的连接字符串格式来填写 .
Redis的连接字符串通常包含主机名 , 端口 ( 可选 , 默认为 6379 ) , 数据库索引 ( 可选 , 默认为 0 ) 以及密码 ( 如果设置了的话 ) .
from celery import Celery
app = Celery( 'myapp' ,
broker= 'redis://localhost:6379/0' ,
backend= 'redis://localhost:6379/0' )
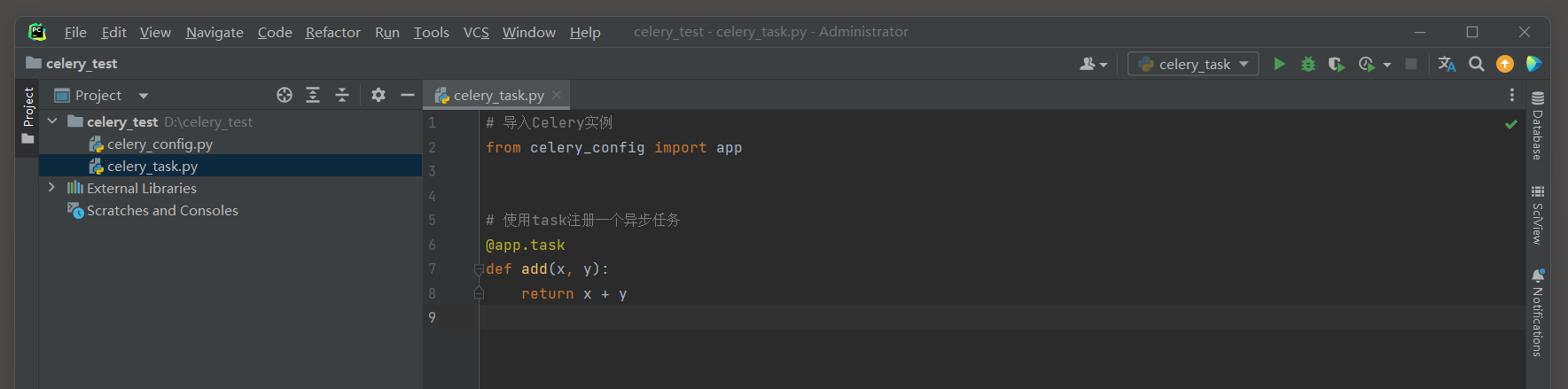
* 2. 定义任务 .
在Celery应用中 , 使用 @ app . task装饰器将Python函数标记为Celery任务 . 这些函数将能够异步执行 .
from celery_config import app
@app. task
def add ( x, y) :
return x + y
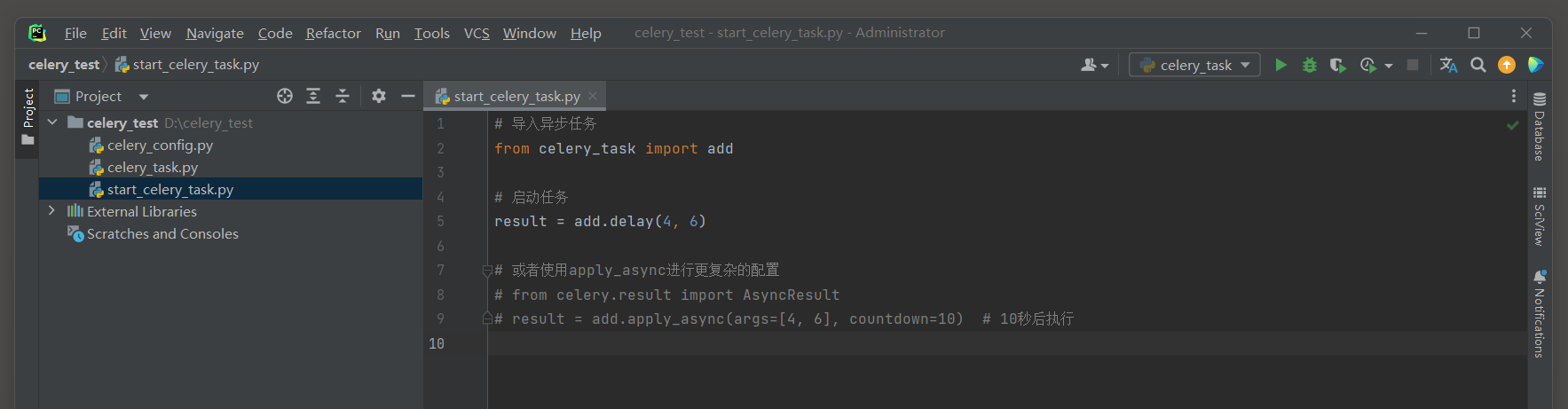
* 3. 提交任务 .
在代码中 , 可以通过调用任务函数并使用 . delay ( ) 方法将任务提交给Celery进行异步处理 .
. apply_async ( ) 方法提供了更多配置选项 .
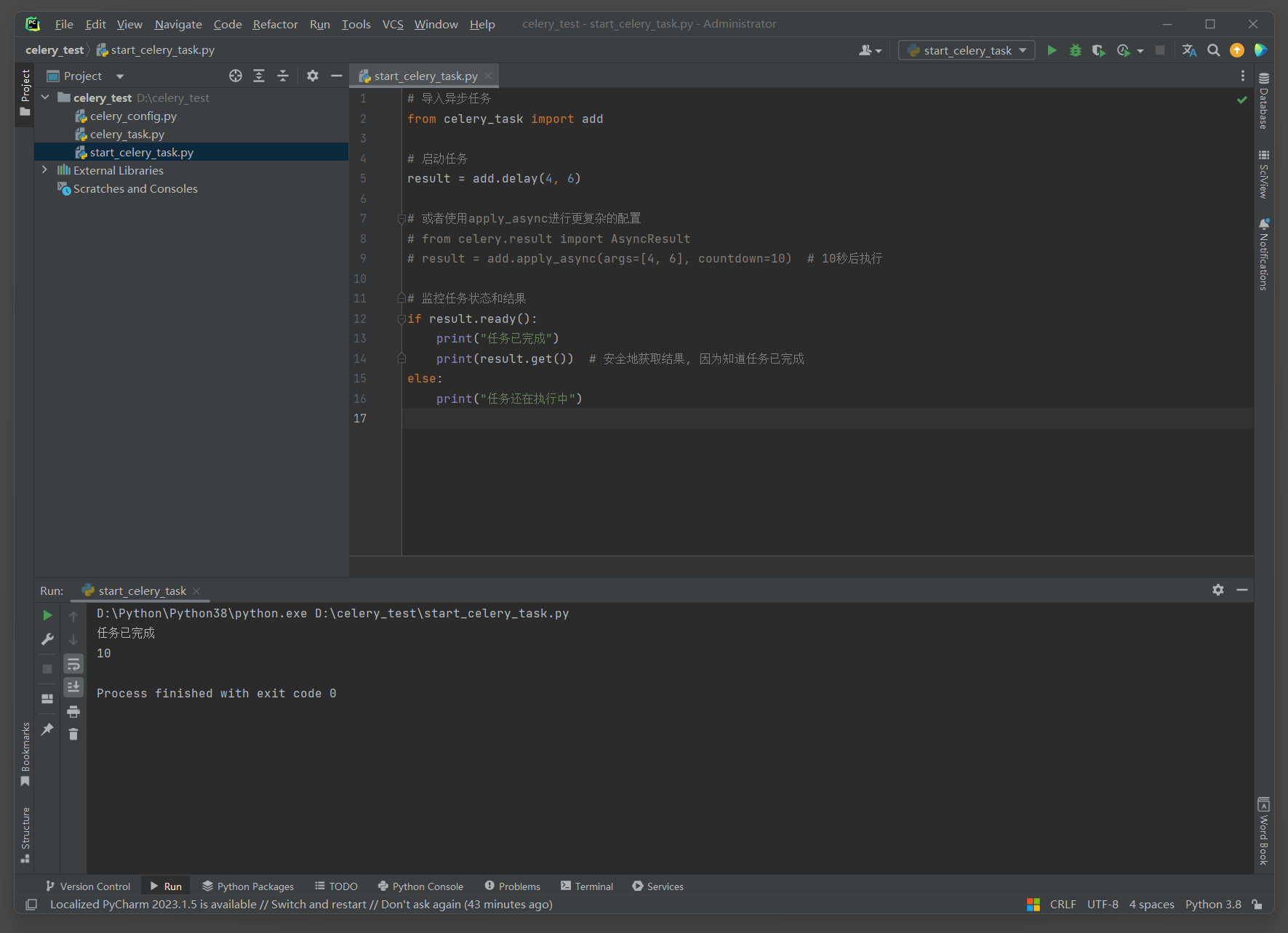
from celery_task import add
result = add. delay( 4 , 6 )
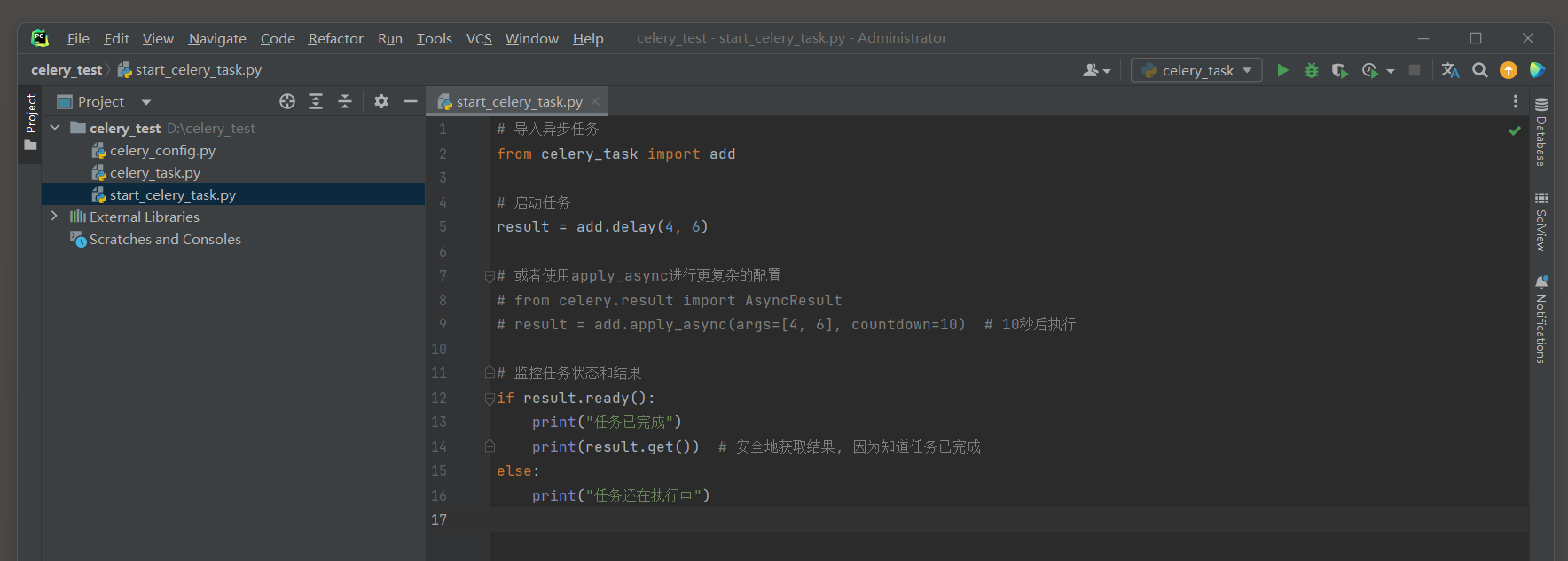
* 4. 获取任务结果 .
使用 . get ( ) 方法可以获取任务的执行结果 . 这会导致调用线程阻塞 , 直到任务完成 .
result = result. get( )
print ( result)
* 5. 监控任务状态和结果 .
Celery提供了状态和结果相关的方法 , 用于查询任务的状态 , 获取任务的结果等 .
if result. ready( ) :
print ( "任务已完成" )
print ( result. get( ) )
else :
print ( "任务还在执行中" )
from celery_task import add
result = add. delay( 4 , 6 )
if result. ready( ) :
print ( "任务已完成" )
print ( result. get( ) )
else :
print ( "任务还在执行中" )
* 5. 启动Celery Worker .
启动Celery Worker进程来处理任务的执行 .
Worker会监听消息队列中的任务 , 并在有任务到达时执行 .
在启动Celery worker或beat时 , 需要使用-A ( 或--app ) 参数来指向包含了任务定义的模块路径 .
( 本例为 : celery_task . py , 后缀可以省略 ) .
在终端中执行以下命令 : celery -A yourmodule worker --loglevel = info , 替换yourmodule为任务定义所在的模块名 .
windows中执行task时报错 : Task handler raised error : ValueError ( ' not enough values to unpack ( expected 3 , got 0 )
windows中执行task需要安装eventlet模块 , 安装命令 : pip install eventlet .
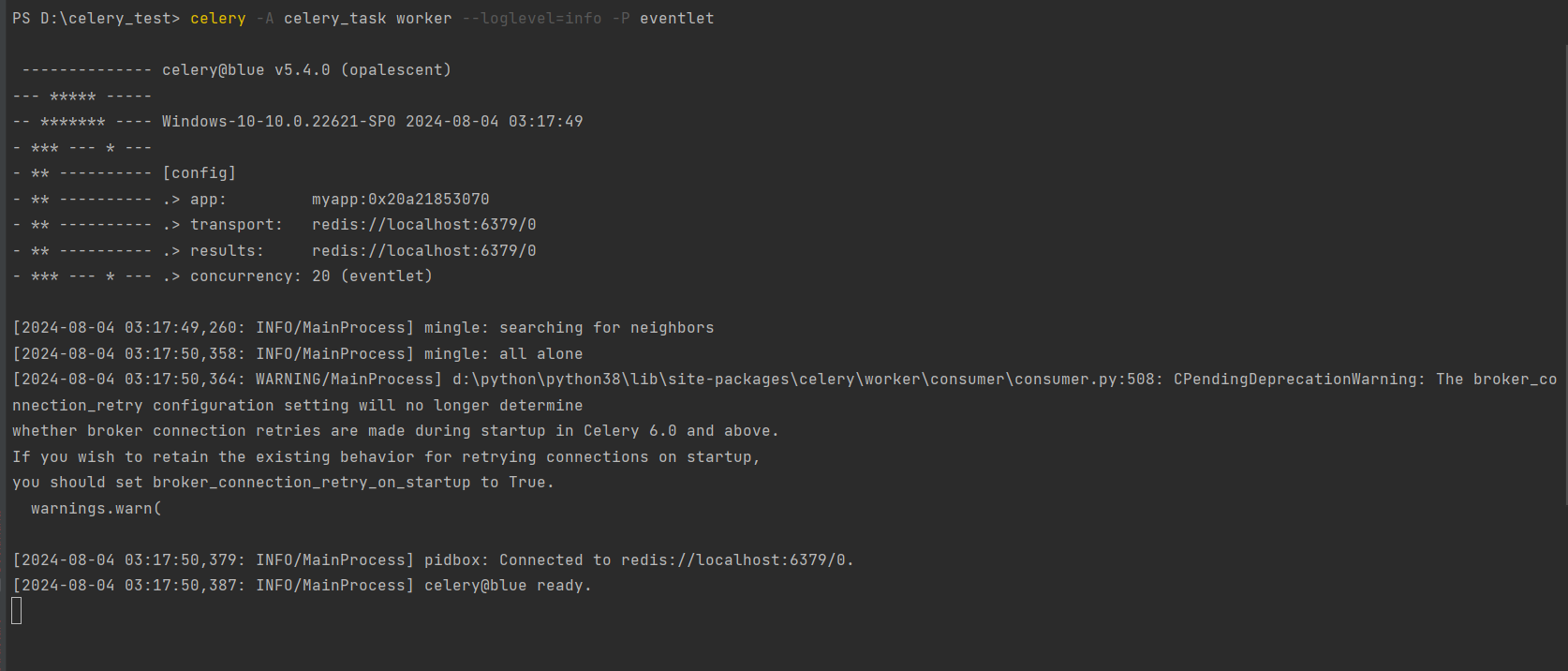
重新启动worker并携带eventlet模块 : celery -A celery_task worker --loglevel = info -P eventlet .
PS D: \celery_test> celery - A celery_task worker - - loglevel= info - P eventlet
- - - - - - - - - - - - - - celery@blue v5. 4.0 ( opalescent)
- - - ** ** * - - - - -
- - ** ** ** * - - - - Windows- 10 - 10.0 .22621 - SP0 2024 - 08 - 04 03 : 17 : 49
- ** * - - - * - - -
- ** - - - - - - - - - - [ config]
- ** - - - - - - - - - - . > app: myapp: 0x20a21853070
- ** - - - - - - - - - - . > transport: redis: // localhost: 6379 / 0
- ** - - - - - - - - - - . > results: redis: // localhost: 6379 / 0
- ** * - - - * - - - . > concurrency: 20 ( eventlet)
- - ** ** ** * - - - - . > task events: OFF ( enable - E to monitor tasks in this worker)
- - - ** ** * - - - - -
- - - - - - - - - - - - - - [ queues]
. > celery exchange= celery( direct) key= celery
[ tasks]
. celery_task. add
[ 2024 - 08 - 04 03 : 17 : 49 , 194 : WARNING/ MainProcess] d: \python\python38\lib\site- packages\celery\worker\consumer\consumer. py: 508 : CPendingDeprecationWarning: The broker_connection_retry configuration setting will no longer determine
whether broker connection retries are made during startup in Celery 6.0 and above.
If you wish to retain the existing behavior for retrying connections on startup,
you should set broker_connection_retry_on_startup to True .
warnings. warn(
出现一个警告信息 , 是关于 Celery 6.0 及更高版本中对连接重试配置的一个变更通知 .
在Celery 6.0 之前的版本中 , connection_retry配置项可能用于控制在启动过程中是否对消息代理 ( broker ) 连接进行重试 .
但从Celery 6.0 开始 , 这个配置项不再直接影响启动时的连接重试行为 .
如果希望保持Celery在启动时对消息代理连接进行重试的原有行为 ,
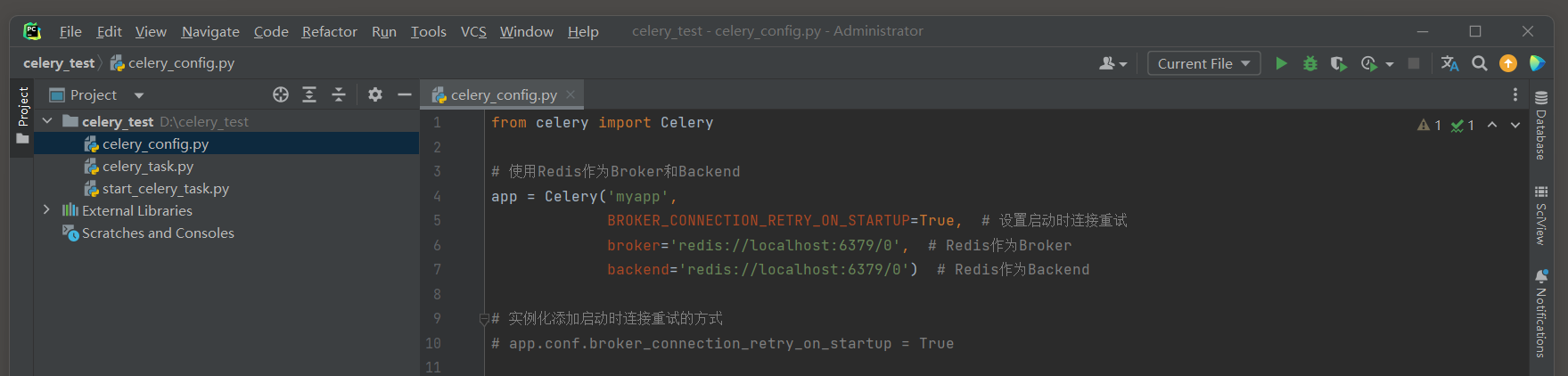
需要在Celery配置中明确设置broker_connection_retry_on_startup为True .
这样做可以确保在Celery尝试连接到消息代理时 , 如果遇到问题 , 它会根据配置进行重试 .
from celery import Celery
app = Celery( 'myapp' ,
BROKER_CONNECTION_RETRY_ON_STARTUP= True ,
broker= 'redis://localhost:6379/0' ,
backend= 'redis://localhost:6379/0' )
使用Ctrl + C向Celery worker发送SIGINT信号 , 导致它优雅地关闭 .
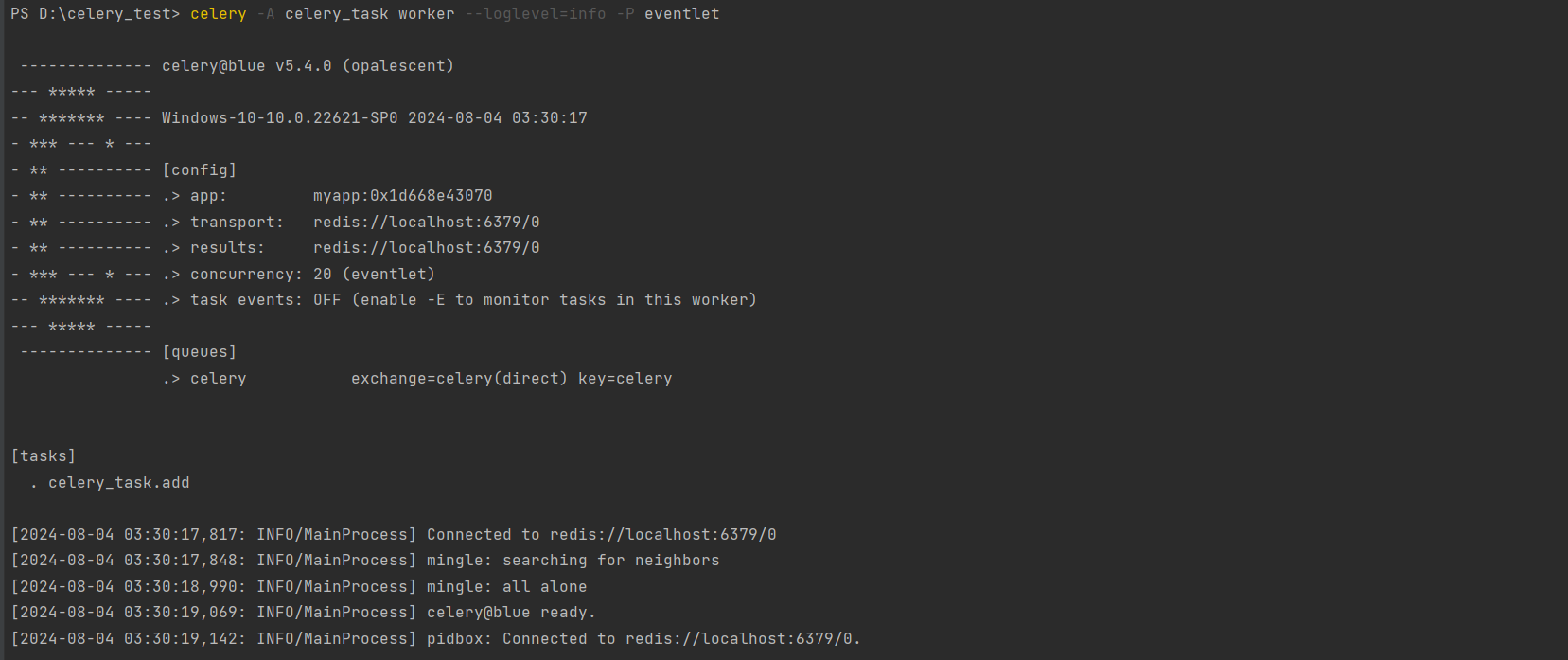
重新启动Celery Worker进程 .
PS D: \celery_test> celery - A celery_task worker - - loglevel= info - P eventlet
- - - - - - - - - - - - - - celery@blue v5. 4.0 ( opalescent)
- - - ** ** * - - - - -
- - ** ** ** * - - - - Windows- 10 - 10.0 .22621 - SP0 2024 - 08 - 04 03 : 30 : 17
- ** * - - - * - - -
- ** - - - - - - - - - - [ config]
- ** - - - - - - - - - - . > app: myapp: 0x1d668e43070
- ** - - - - - - - - - - . > transport: redis: // localhost: 6379 / 0
- ** - - - - - - - - - - . > results: redis: // localhost: 6379 / 0
- ** * - - - * - - - . > concurrency: 20 ( eventlet)
- - ** ** ** * - - - - . > task events: OFF ( enable - E to monitor tasks in this worker)
- - - ** ** * - - - - -
- - - - - - - - - - - - - - [ queues]
. > celery exchange= celery( direct) key= celery
[ tasks]
. celery_task. add
[ 2024 - 08 - 04 03 : 30 : 17 , 817 : INFO/ MainProcess] Connected to redis: // localhost: 6379 / 0
[ 2024 - 08 - 04 03 : 30 : 17 , 848 : INFO/ MainProcess] mingle: searching for neighbors
[ 2024 - 08 - 04 03 : 30 : 18 , 990 : INFO/ MainProcess] mingle: all alone
[ 2024 - 08 - 04 03 : 30 : 19 , 069 : INFO/ MainProcess] celery@blue ready.
[ 2024 - 08 - 04 03 : 30 : 19 , 142 : INFO/ MainProcess] pidbox: Connected to redis: // localhost: 6379 / 0.
* celery -A celery_task worker --loglevel = info -P eventlet 命令解释 :
- celery : 这是启动 Celery 的命令行工具 .
- -A celery_task : 这个选项告诉Celery加载名为celery_task的模块 ( 或包 )
- worker : 这个子命令告诉Celery启动一个或多个工作进程来处理任务 .
- --loglevel = info : 设置日志级别为info , 这意味着Celery将输出更详细的运行信息 .
- -P eventlet : 指定使用eventlet作为并发库 .
eventlet是一个协程库 , 它允许Celery在单个进程中并发执行多个任务 . 这对于I / O密集型任务特别有用 .
* 输出解释 :
第 1 行 : 显示Celery的版本 ( v5 . 4.0 ) .
第 2 行 : 纤细平台信息 : 当前运行的操作系统 , 以及日期和时间 .
第 5 行 : 配置信息提示 .
第 6 行 : app : 显示正在使用的Celery应用实例的名称和内存地址 .
第 7 行 : transport : 显示消息代理 ( Broker ) 的配置 , 这里是Redis .
第 8 行 : results : 显示结果后端的配置 , 这里是Redis .
第 9 行 : concurrency : 显示并发工作进程的数量 , 这里设置为 20 , 使用eventlet作为并发库 .
第 10 行 : task events : 显示任务事件是否启用 ( 这里是关闭的 , 可以通过-E 选项启用 ) .
第 11 行 : 队列信息 : 显示Celery配置的队列 , 这里只有一个名为celery的队列 , 使用direct交换器 .
* 任务列表 :
- 列出已注册的任务 , 这里只有一个名为celery_task . add的任务 .
* 日志信息 :
- 连接到Redis的日志 .
- 尝试与其他Celery worker交互的日志 ( 这里显示没有其他worker在运行 ) .
- worker准备好的日志 .
- 连接到Redis以进行进程间通信 ( pidbox ) 的日志 .
- 等待任务 . . .
* 7. 启动 Celery worker 后 , worker会在后台运行 , 等待来自应用程序或其他地方的异步任务请求 .
要触发异步任务 , 您通常需要在另一个Python脚本 , 命令行界面 ( CLI ) , Web应用程序或其他类型的程序中调用这些任务 .
当前实例中为 : start_celery_task . py脚本 , 运行脚本即可触发任务提交 .
Celery worker不断地轮询消息代理以查找新的任务消息 .
一旦找到新任务 , worker会将其从消息代理中取出并进行反序列化 .
然后 , worker会在其工作进程中 ( 在例子中是使用eventlet并发库 ) 执行该任务 .
一旦任务执行完成 , worker会更新消息代理和结果后端以反映任务的状态和结果 .
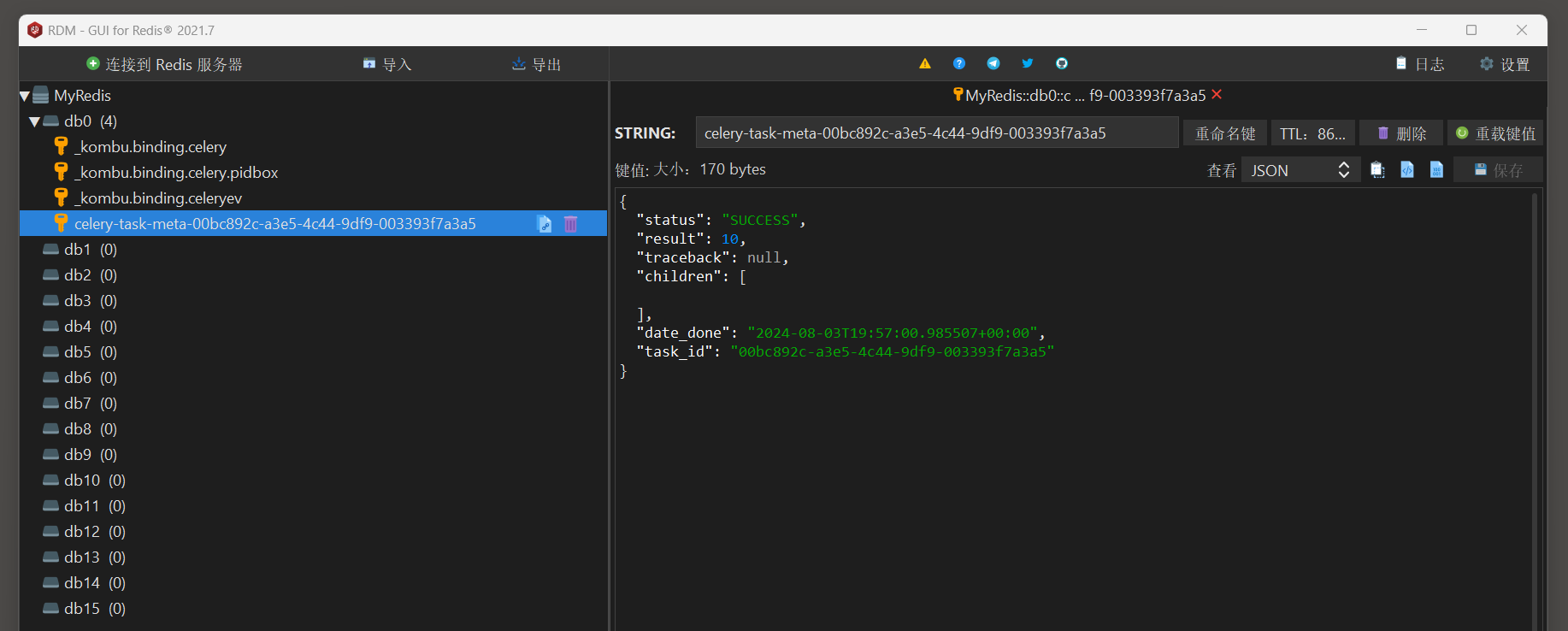
日志信息 :
数据库信息 :
异步任务执行后返回的结果 :
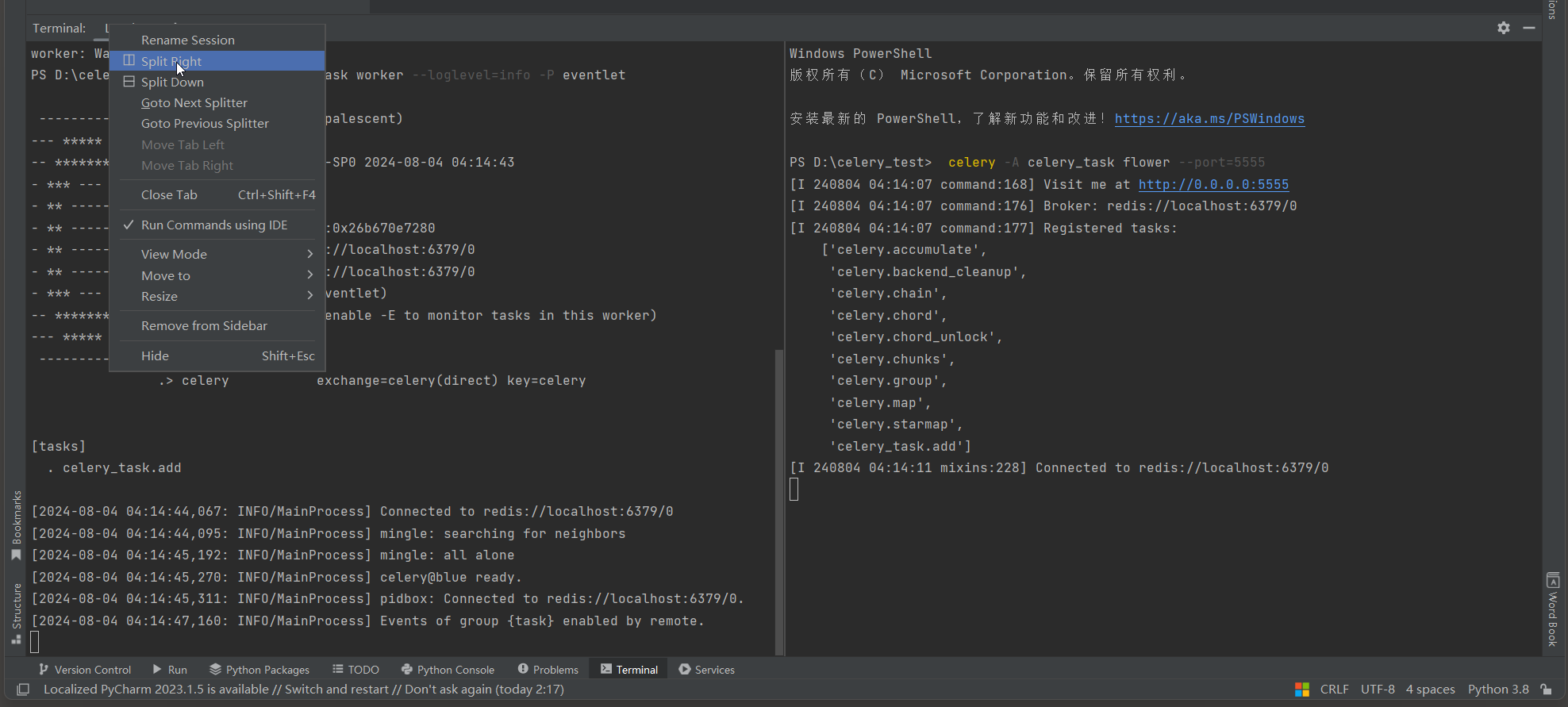
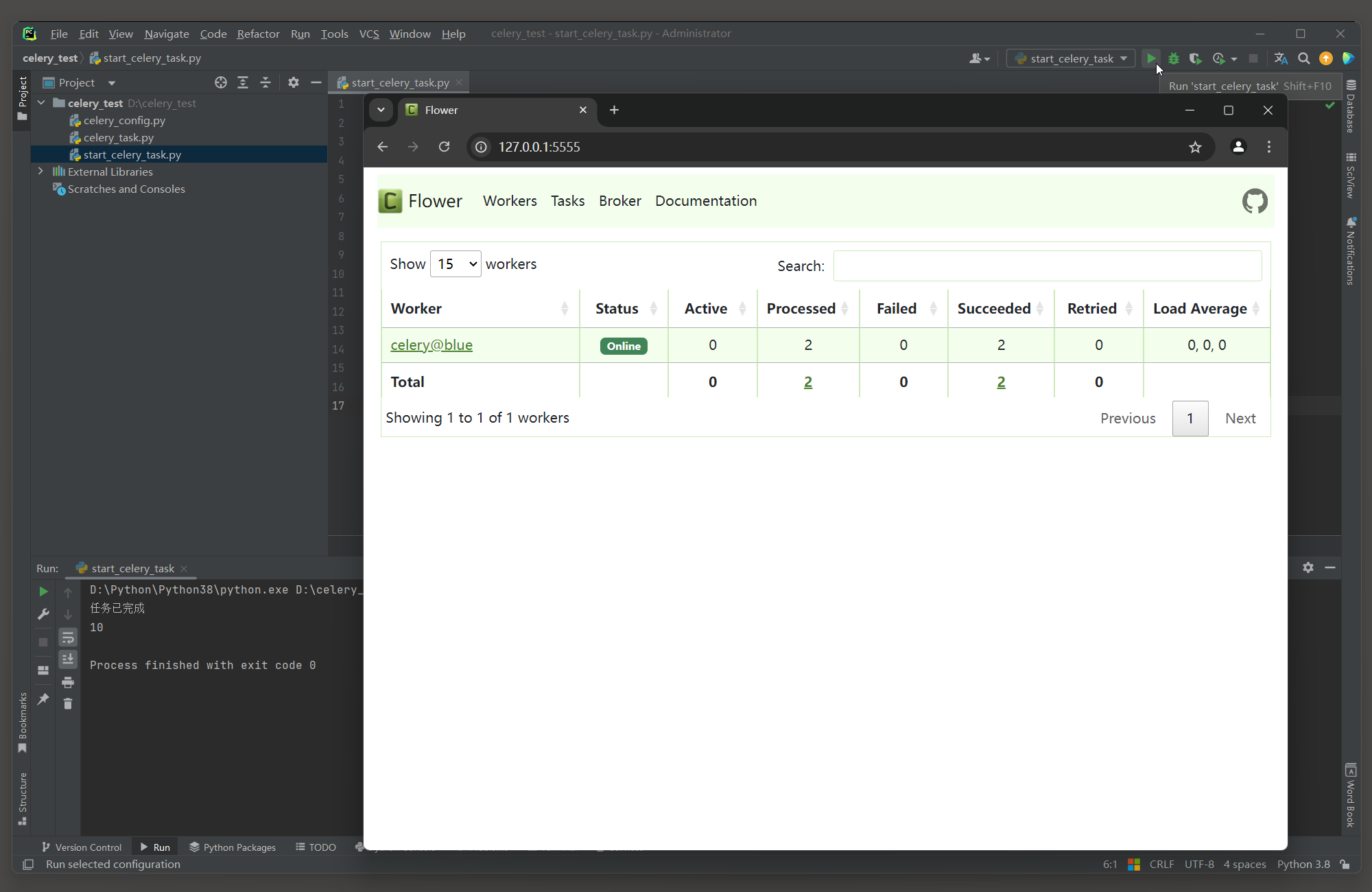
* 7. 使用Flower进行监控 .
Flower是一个Celery的Web监控工具 , 可以实时查看任务队列的状态和统计信息 .
安装Flower : pip install flower .
另起一个终端并执行启动Flower命令 : celery -A yourmodule flower --port = 5555 .
( Celery worker 和Flower是一起启动的 . . . )
然后在浏览器中访问 : http : / / localhost : 5555 , 查看监控界面 .
* 8. 错误处理和重试 .
Celery支持任务的重试机制 , 以增强任务的稳定性和可靠性 .
BROKER_CONNECTION_RETRY_ON_STARTUP = True和retry方法 ( 优先级高 ) 都是重试机制 , 前者一直重试 , 后者可指定重试次数 .
from celery import Celery
app = Celery( 'myapp' ,
broker= 'redis://localhost:6379/0' ,
backend= 'redis://localhost:6379/0' )
from celery_config import app
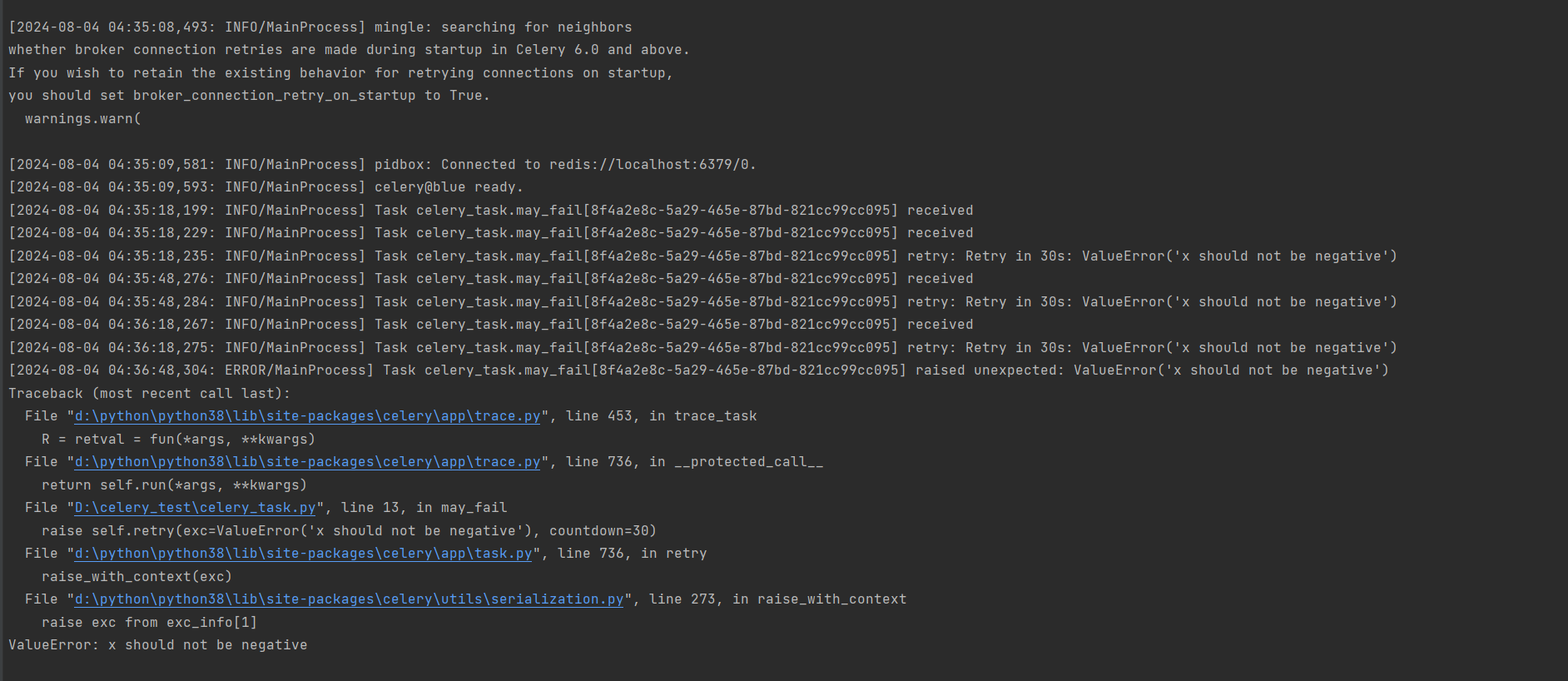
@app. task ( bind= True , max_retries= 3 , default_retry_delay= 35 )
def may_fail ( self, x, y) :
if x < 0 :
raise self. retry( exc= ValueError( 'x should not be negative' ) , countdown= 30 )
return x / y
task参数解释 :
* bind = True : 使得Celery能够传递任务实例 ( self ) 到任务函数中 , 允许任务访问自己的属性 , 比如重试计数或当前重试延迟 .
* max_retries = 3 : 指定了任务在放弃之前可以重试的最大次数 .
在这个例子中 , 如果任务因为某种原因失败 , 它将最多被重试 3 次 .
* default_retry_delay = 30 : 设置了在每次重试之间的默认延迟时间 ( 以秒为单位 ) .
在这个例子中 , 如果任务需要重试 , 它将在每次失败后等待 30 秒再尝试 .
self . retry ( ) 方法提供了一种方便的方式来重新调度当前任务的一个新版本 , 通常是在捕获到某些异常或条件不满足时 .
self . retry ( ) 方法是在任务执行过程中调用的 , 并且它会自动处理任务的重试逻辑 ,
包括等待时间countdown , 重试次数max_retries , 异常exc等 .
task与retry ( 优先级高 ) 中很多参数一致 . . .
from celery_task import may_fail
result = may_fail. delay( - 1 , 6 )
if result. ready( ) :
print ( "任务已完成" )
print ( result. get( ) )
先启动Celery worker : celery -A celery_task worker --loglevel = info -P eventlet .
再运行start_celery_task . py脚本 , 查看日志信息 , 30 秒执行一次任务 , 一共执行 3 次 .
这里只是报错 , 而不是停止 , Celery worker任然在运行 , 还能继续处理任务的 . . .
* 9. 并发和扩展性 .
Celery支持通过启动多个Worker进程来增加并发处理任务的能力 , 从而提高系统的吞吐量 .
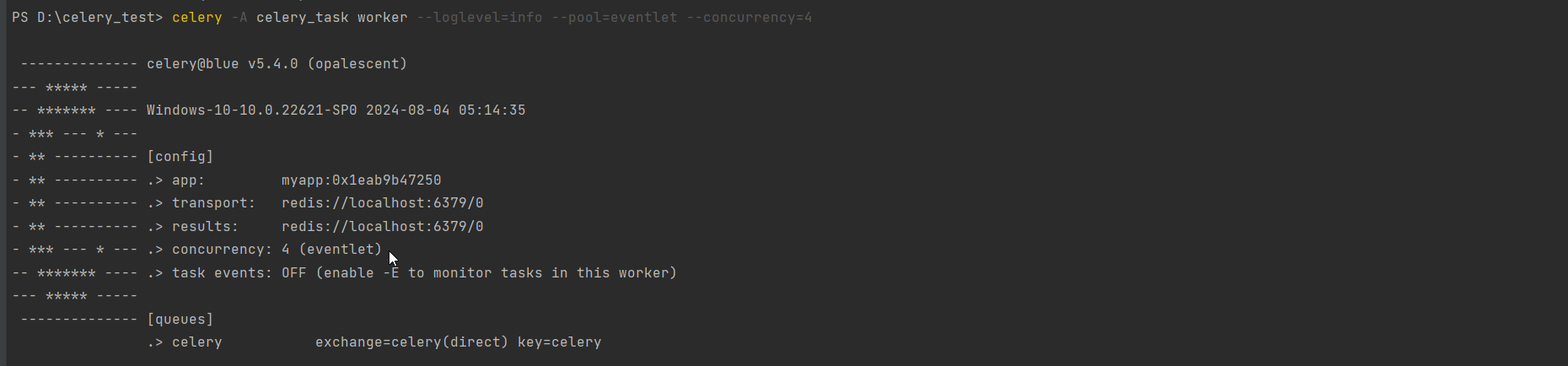
启动 4 个并发的Worker进程 : celery -A yourmodule worker --loglevel = info --concurrency = 4 ( windows中不能执行 ) .
如果想要运行Celery worker并使用eventlet池 , 同时希望并发执行 4 个任务 ,
可以执行命令 : celery -A celery_task worker --loglevel = info --pool = eventlet --concurrency = 4 .
其中 , --pool = eventlet指定了使用eventlet池 , 而--concurrency = 4 则设置了并发执行的任务数 ( 即greenlets的数量 ) .
不指定--concurrency参数默认并发工作进程的数量为 20.
PS D: \celery_test> celery - A celery_task worker - - loglevel= info - - pool= eventlet - - concurrency= 4
. . .
- ** * - - - * - - - . > concurrency: 4 ( eventlet)
@ app . task和 @ shared_task是Celery中用于定义任务的两种不同装饰器 , 它们之间存在明显的区别 .
from celery import Celery
app = Celery( 'my_app' , broker= 'amqp://guest@localhost//' )
@app. task
def my_task ( ) :
pass
from celery import shared_task
@shared_task
def add ( x, y) :
return x + y
以下是这两者的详细比较 :
* 1. 定义与用途 .
- @ app . task : 这是Celery库提供的装饰器 , 用于在具体的Celery应用程序中定义任务 .
当创建一个Celery应用程序对象 ( 通常命名为 app ) , 并使用 @ app . task装饰器来定义任务函数时 ,
这些任务函数仅在该特定的Celery应用程序中可用 .
- @ shared_task : 这是Celery提供的另一个装饰器 , 用于定义共享任务 ( shared task ) .
共享任务是指可以在多个Celery应用程序之间共享的任务 .
通过使用 @ shared_task装饰器 , 可以在一个Celery应用程序中定义任务 , 并将其标记为共享任务 ,
以便其他使用相同配置的Celery应用程序可以直接导入和使用该任务 .
* 2. 依赖性与可移植性 .
- @ app . task : 任务依赖于特定的Celery应用程序实例 .
因此 , 如果在不同的Celery应用程序中想要使用相同的任务 , 需要在每个应用程序中都重新定义它 .
这在单个项目或单个Celery应用程序的上下文中很有用 , 但不利于跨项目的代码复用 .
- @ shared_task : 不依赖于特定的Celery应用程序实例 .
它加载到内存后会自动添加到Celery对象中 , 因此可以在多个Celery应用程序之间共享 .
这使得任务的可移植性和可重用性更强 , 特别是在多个项目或组件需要共享通用任务时 .
* 3. 使用场景 .
- 如果任务仅在特定的Celery应用程序中使用 , 那么使用 @ app . task就足够了 .
- 如果任务需要在多个Celery应用程序之间共享 , 或者想要提高任务的代码复用性和可维护性 , 那么使用 @ shared_task会更合适 .
* 4. 注意事项 .
- 当使用 @ shared_task时 , 请确保所有相关的Celery应用程序都已正确配置 ,
并且它们使用相同的消息代理 ( 如 : RabbitMQ , Redis等 ) 和结果后端 ( 如果需要的话 ) .
- 无论是 @ app . task还是 @ shared_task , 定义的任务都可以异步执行 , 并可以返回结果 .
可以使用delay ( ) 方法或apply_async ( ) 方法来异步调用这些任务 .
通过一个具体的例子来说明任务在多个Celery应用程序之间共享 .
假设你有两个Python项目 , 它们都需要执行一些通用的后台任务 , 比如发送电子邮件 , 处理图片上传等 .
这些任务在逻辑上是相似的 , 因此希望避免在两个项目中重复编写相同的代码 .
使用 @ app . task的情况需要会在每个Django项目的Celery配置中分别定义这些任务 .
例如 , 在第一个项目中 :
from celery import Celery
app = Celery( 'project1' , broker= 'amqp://guest@localhost//' )
@app. task
def send_email ( recipient, subject, body) :
pass
然后在第二个项目中 , 需要再次定义相同的任务 :
from celery import Celery
app = Celery( 'project2' , broker= 'amqp://guest@localhost//' )
@app. task
def send_email ( recipient, subject, body) :
pass
这种方法的问题在于 , 如果发送电子邮件的逻辑需要更新 , 需要在两个项目中都进行更改 , 这增加了维护的复杂性和出错的风险 .
使用 @ shared_task , 可以在一个独立的Python模块或包中定义这些共享任务 , 并在需要时从两个项目中导入它们 .
注意 : 使用 @ shared_task , 多个Celery应用程序必须连接到同一个消息代理 ( Redis等中间件 ) , 或者至少能够互相通信的消息代理 .
只要它们都能连接到同一个消息代理实例或兼容的实例集 , 任务就可以被正确发送和接收 .
先说明一下 @ shared_task的绑定任务特性 :
from celery import Celery, shared_task
@shared_task
def add ( x, y) :
return x + y
print ( add. app)
app1 = Celery( broker= 'amqp://' )
print ( add. app is app1)
print ( add. app)
app2 = Celery( broker= 'redis://' )
print ( add. app is app2)
print ( add. app)
调用 @ shared_task饰后的add任务 , 它会尝试找到一个已经存在的Celery应用实例 .
( 通常是通过查找当前模块或父模块中的celery应用实例 , '如果有多个则使用离调用最近的' ) .
如果没有找到 , 它会创建一个新的默认Celery应用实例 . 这个新创建的实例将绑定到被装饰的任务上 , 并通过task . app属性访问 .
代码中 , 首先定义了一个add任务 , 然后创建了app1和app2两个Celery应用实例 .
add任务在app1和app2创建之前就已经被定义 , 并且由于此时还没有显式创建Celery应用实例 ,
@ shared_task装饰器会创建一个默认的Celery应用实例并将其绑定到add任务上 .
在定义Celery实例之后 , 调用饰后的add任务 , 那么它会自动将任务重新绑定到最近Celery实例上 .
了解情况后可以继续进行实验了 .
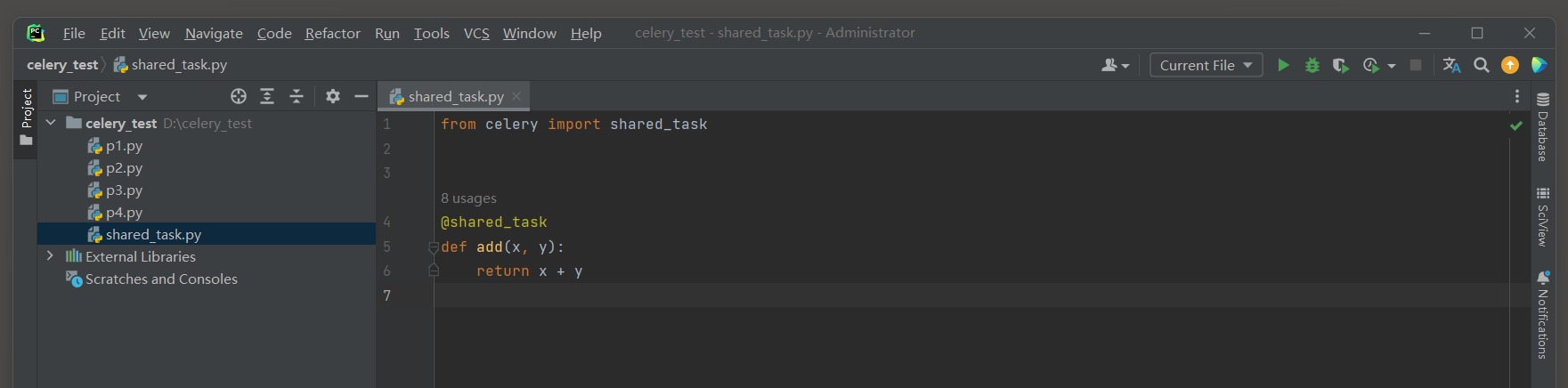
首先 , 创建一个包含共享任务的模块 ( 例如 , shared_tasks . py ) :
from celery import shared_task
@shared_task
def add ( x, y) :
return x + y
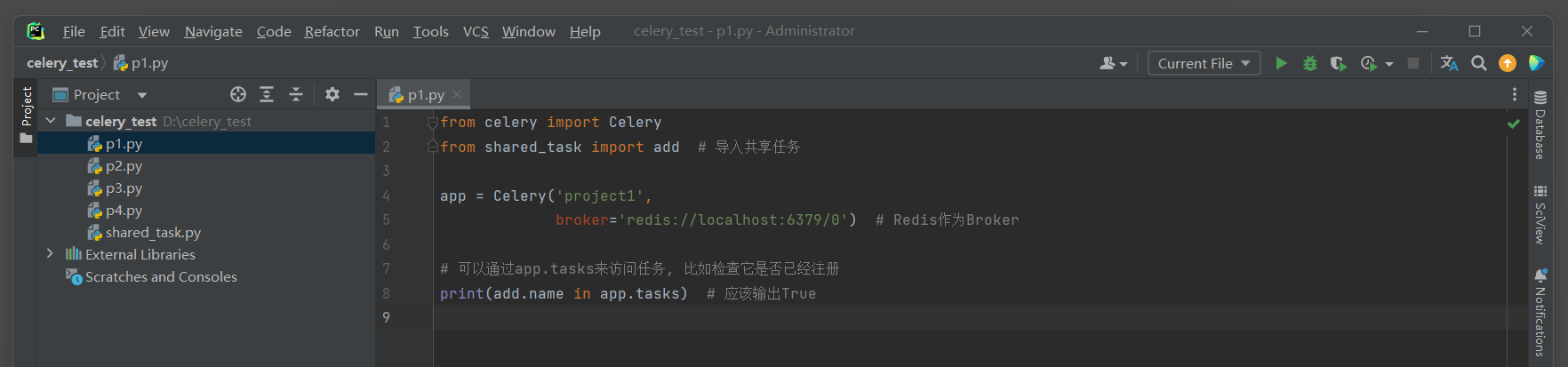
然后 , 在第一个Python项目中导入共享任务 :
from celery import Celery
from shared_task import add
app = Celery( 'project1' ,
broker= 'redis://localhost:6379/0' )
print ( add. name in app. tasks)
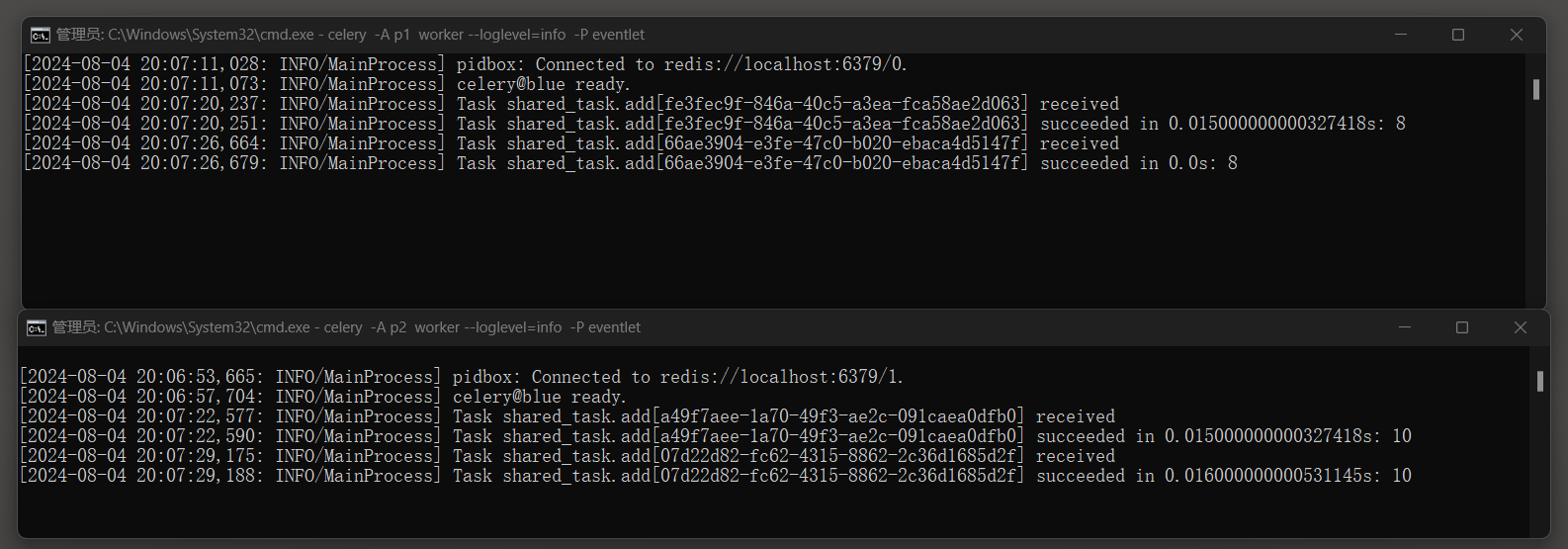
启动Celery Worker进程 : celery -A p1 worker --loglevel = info -P eventlet
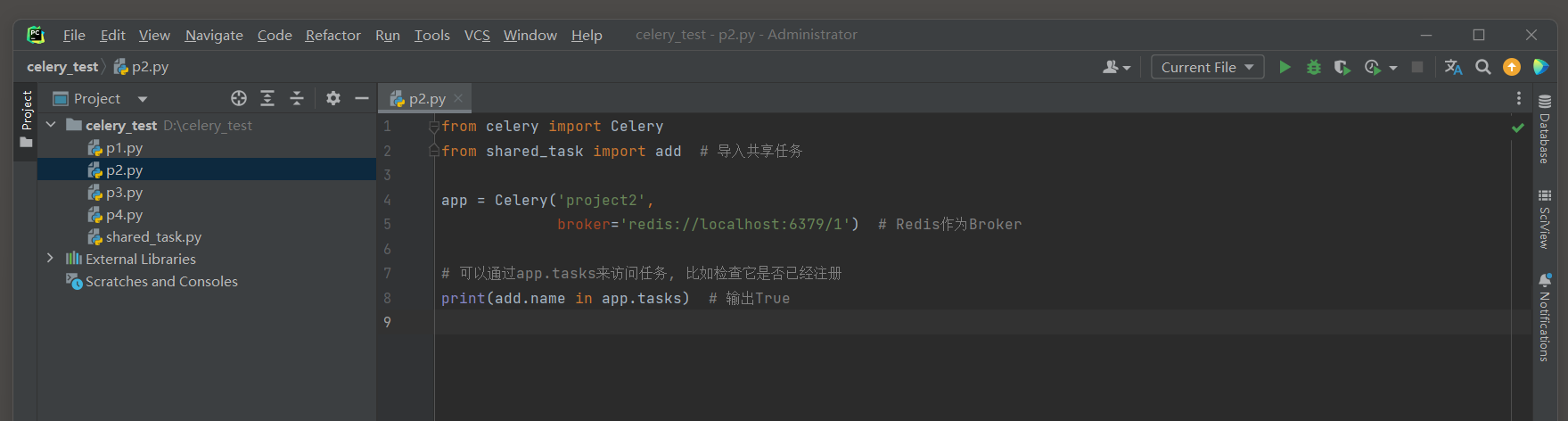
在第二个Django目中导入这个共享任务 :
from celery import Celery
from shared_task import add
app = Celery( 'project2' ,
broker= 'redis://localhost:6379/1' )
print ( add. name in app. tasks)
并启动Celery Worker进程 : celery -A p2 worker --loglevel = info -P eventlet
定义一个脚本使用提交任务 , 使用标识符为project1的Celery实例作为配置 :
from p1 import add
result = add. delay( 4 , 4 )
print ( f'任务ID:: { result. id } ' )
再定义一个脚本使用提交任务 , 使用标识符为project1的Celery实例作为配置 :
from p2 import add
result = add. delay( 5 , 5 )
print ( f'使用结果ID触发的任务: { result. id } ' )
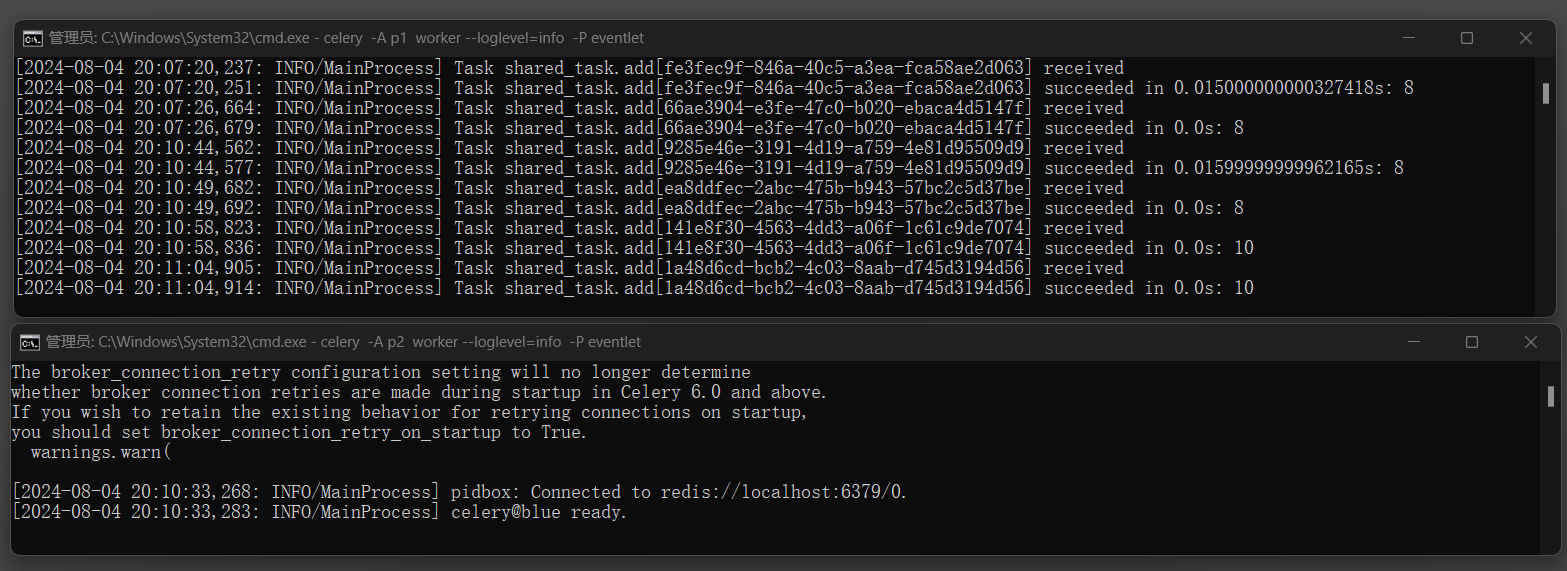
分别运行脚本p3 , p4两次 , 查看消息日志 :
这样 , 如果发送电子邮件的逻辑需要更新 , 只需在shared_tasks . py中进行更改 ,
然后两个项目都会自动使用更新后的逻辑 , 而无需在每个项目中分别进行更改 .
这大大提高了代码的复用性和可维护性 .
如果将两个Celery实例配置为使用同一个消息中间件 ,
这些实例可以共享任务队列 , worker就是随机的了 ( 一个累死累活 , 另外一个不干活 ) .
app = Celery( 'project1' ,
BROKER_CONNECTION_RETRY_ON_STARTUP= True ,
broker= 'redis://localhost:6379/0' )
app = Celery( 'project2' ,
BROKER_CONNECTION_RETRY_ON_STARTUP= True ,
broker= 'redis://localhost:6379/0' )
在Django项目中使用Celery可以实现异步任务处理 , 比如发送电子邮件 , 文件处理 , 数据导入等耗时操作 , 而不会阻塞Web请求的响应 .
以下是在Django项目中设置和使用Celery的基本步骤 :
* 1. 配置消息代理 .
在Django的settings . py文件中 , 添加Celery的配置项 , 包括指定消息代理 .
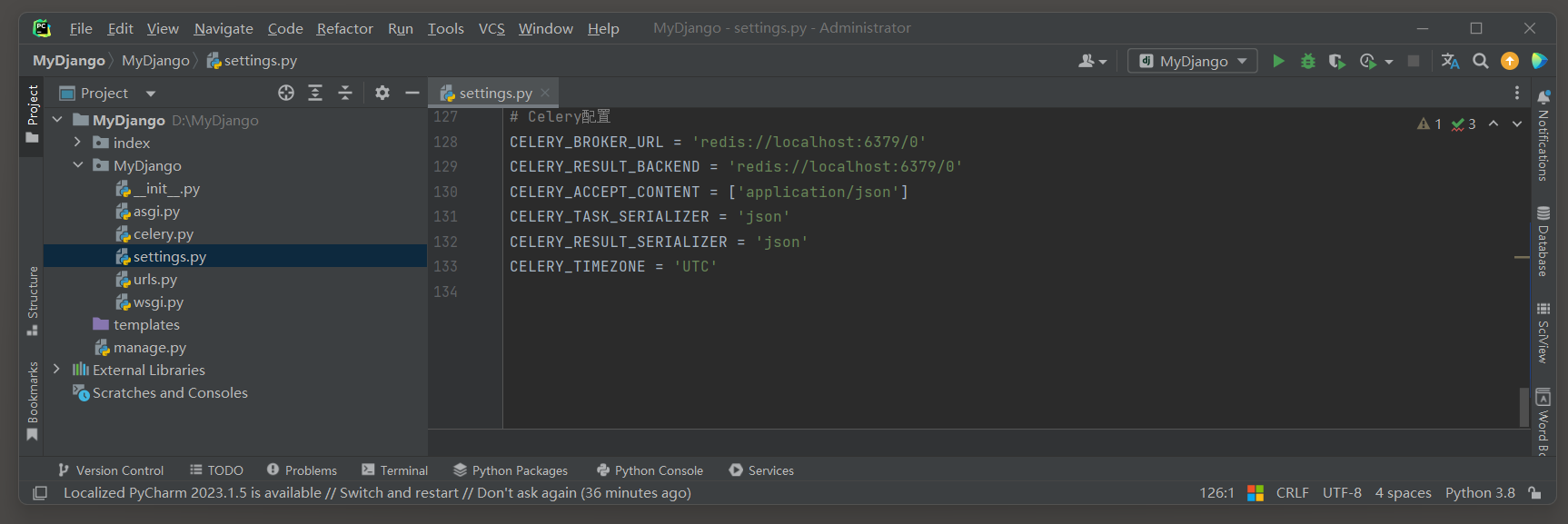
CELERY_BROKER_URL = 'redis://localhost:6379/0'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
CELERY_ACCEPT_CONTENT = [ 'application/json' ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'UTC'
配置项说明 :
* 1. CELERY_BROKER_URL : 这是Celery用来与消息代理通信的URL .
* 2. CELERY_RESULT_BACKEND : 这是Celery用来存储任务结果的URL .
* 3. CELERY_ACCEPT_CONTENT : 这个设置指定了Celery接受的消息内容类型 .
例子中 , 它被设置为 [ 'application/json' ] , 这意味着Celery将只接受JSON格式的任务消息 .
* 4. CELERY_TASK_SERIALIZER : 这个设置指定了Celery序列化任务时使用的格式 .
例子中 , 它被设置为 'json' , 这意味着所有发送给任务的消息都将被序列化为JSON格式 .
* 5. CELERY_RESULT_SERIALIZER : 这个设置指定了Celery序列化任务结果时使用的格式 .
例子中 , 它被设置为 'json' ,这意味着所有任务结果都将被序列化为 JSON 格式。
* 6. CELERY_TIMEZONE : 这个设置指定了Celery使用的时区 .
例子中 , 它被设置为 'UTC' , 即协调世界时间 . 这有助于确保任务的时间戳和任务结果的时间戳在分布式系统中是一致的 .
注意从 : Celery 4. x版本开始 , 一些设置项的命名已经发生了变化 .
例如 , CELERY_BROKER_URL和CELERY_RESULT_BACKEND等前缀为CELERY_的设置项在Celery 4. x及更高版本中通常不再需要CELERY_前缀 ,
而是直接使用broker_url和result_backend等名称 .
但是 , 为了与Django项目的其他部分 ( 如第三方库 ) 保持兼容性 , 仍然可以在Django的settings . py文件中使用带有CELERY_前缀的设置项 ,
只要Celery版本和任何相关的第三方库都支持这种用法 .
* 2. 配置Celery .
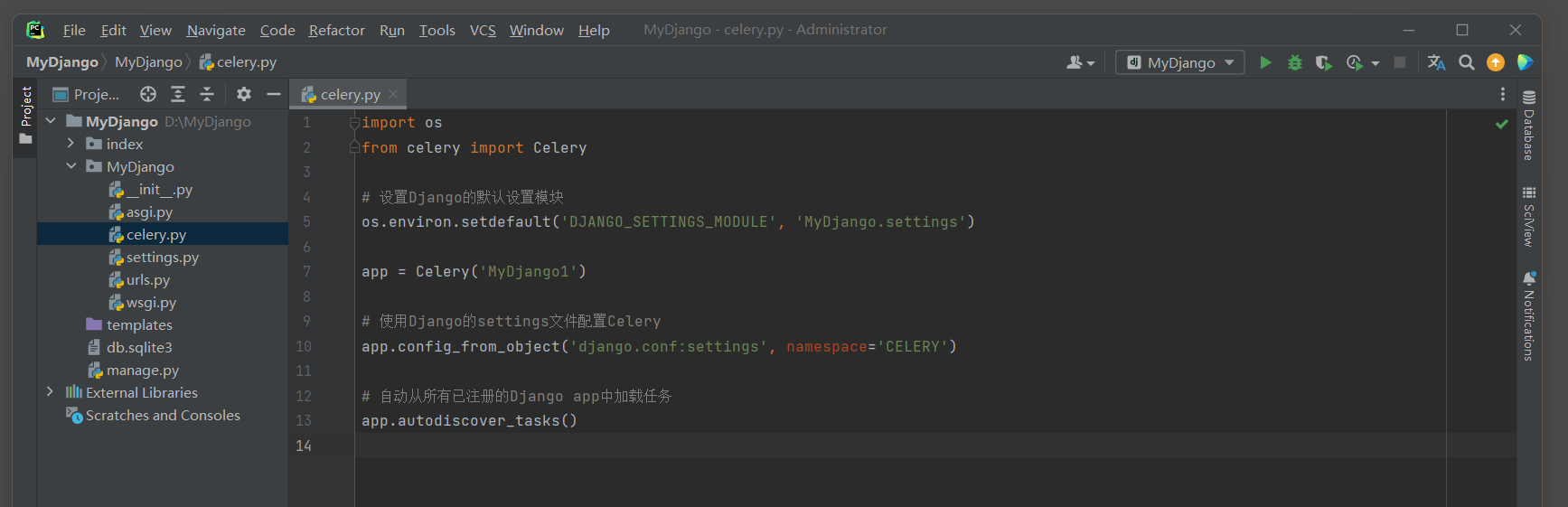
在Django的根项目配置包下创建一个新的Python文件 , 通常命名为celery . py , 这个文件将用于配置Celery实例 .
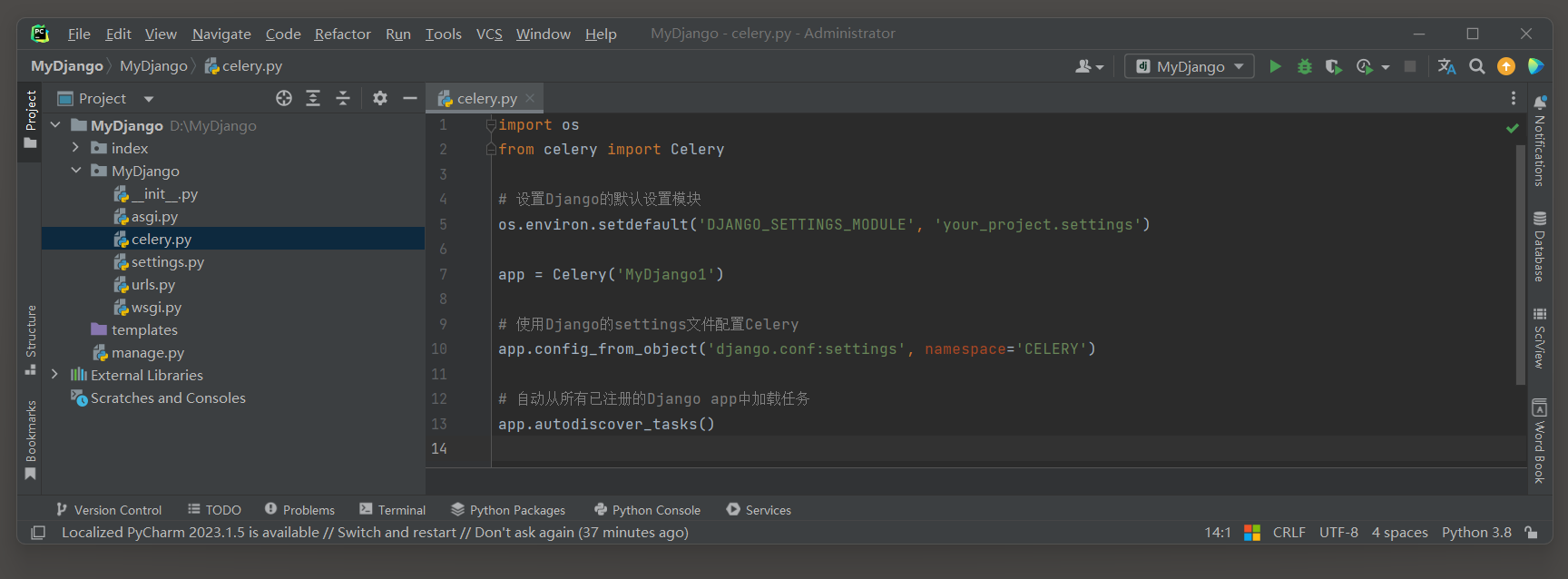
import os
from celery import Celery
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
app = Celery( 'MyDjango1' )
app. config_from_object( 'django.conf:settings' , namespace= 'CELERY' )
app. autodiscover_tasks( )
代码的详细解释 :
* os . environ . setdefault ( 'DJANGO_SETTINGS_MODULE' , 'your_project.settings' )
这行代码通过os . environ . setdefault方法设置了环境变量DJANGO_SETTINGS_MODULE的默认值 .
这个环境变量告诉Django在哪里查找设置文件 ( settings . py ) .
'your_project.settings' 应该替换为你的Django项目的实际设置模块路径 .
这个步骤是必要的 , 因为Celery需要知道Django的设置信息 , 以便能够正确地加载Django应用并找到其中的任务 .
一旦DJANGO_SETTINGS_MODULE被正确设置 , 就可以使用字符串配置路径 'django.conf:settings' 来访问Django设置 .
* app . config_from_object ( 'django.conf:settings' , namespace = 'CELERY' )
这行代码告诉Celery从Django的设置文件中加载配置 .
django . conf : settings是Django设置的Python路径 , 而namespace = 'CELERY' 是一个可选参数 ,
它告诉Celery只加载那些以CELERY_开头的设置项 .
这样做的好处是 , 可以在Django设置文件中为Celery定义专门的配置 , 而不会与其他Django设置项混淆 .
* app . autodiscover_tasks ( )
在Celery中 , 任务通常定义在Django应用的tasks . py文件中 .
这行代码告诉Celery自动搜索并注册所有Django应用中定义的Celery任务 .
为了实现这一点 , Celery会遍历INSTALLED_APPS中列出的所有Django应用 , 并查找其中的tasks . py文件 .
如果找到了这样的文件 , Celery就会加载并注册其中定义的所有任务 .
这样 , 就可以在Django应用的任何地方通过任务名来调用这些任务了 .
* 3. 初始化配置包 .
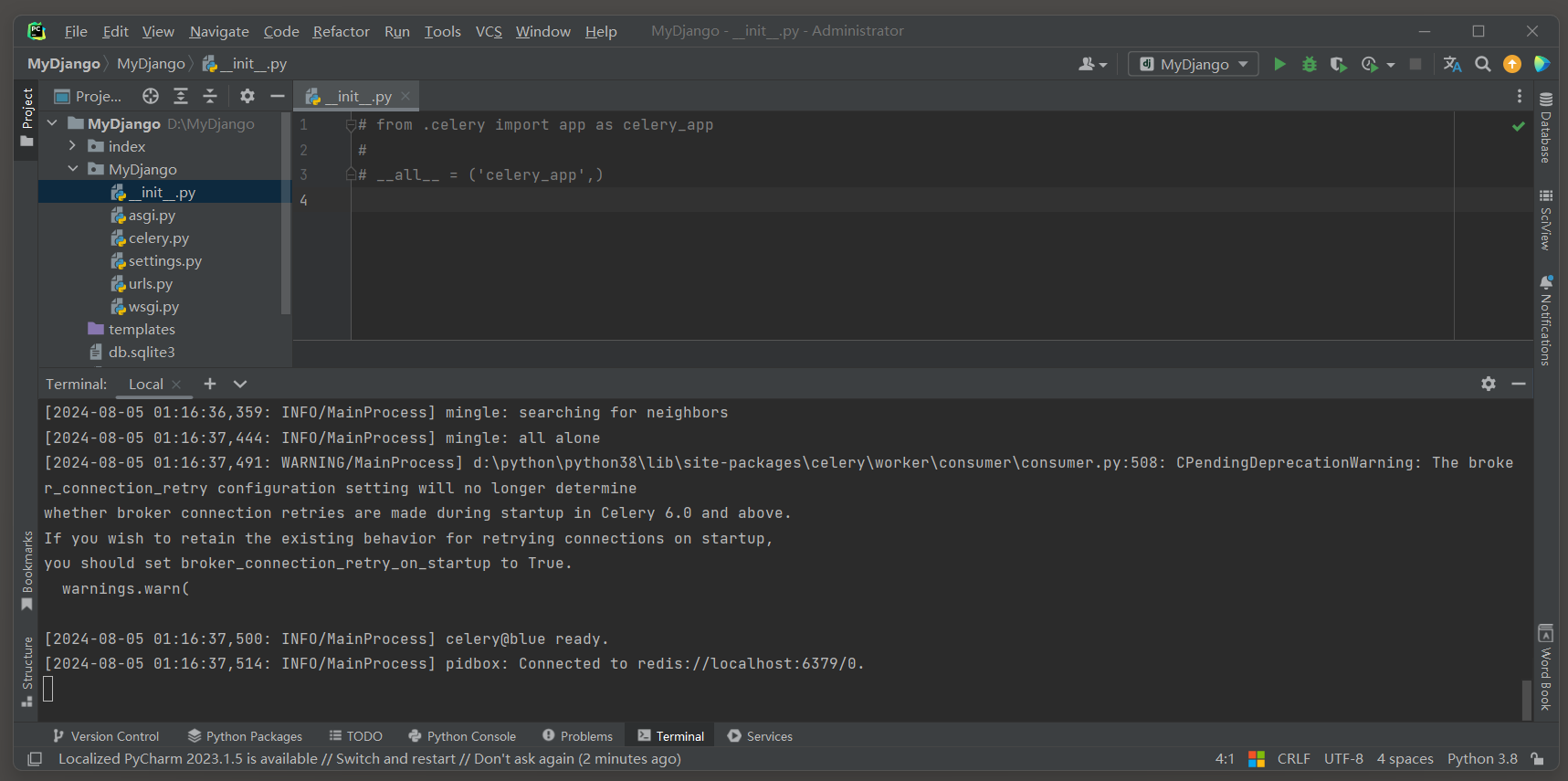
在Python包的__init__ . py文件中加载Celery应用 ( app ) 是一种常见的做法 , 特别是希望在整个包或应用中方便地访问Celery实例时 .
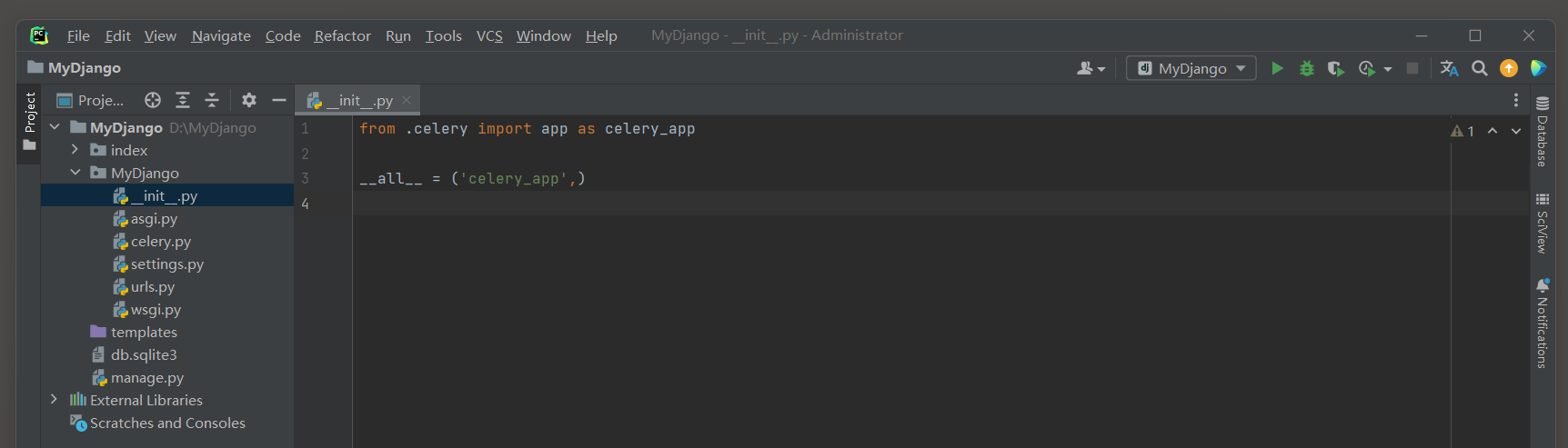
from . celery import app as celery_app
__all__ = ( 'celery_app' , )
这行代码的主要作用是为了能够让共享任务能够绑定到Celery实例 .
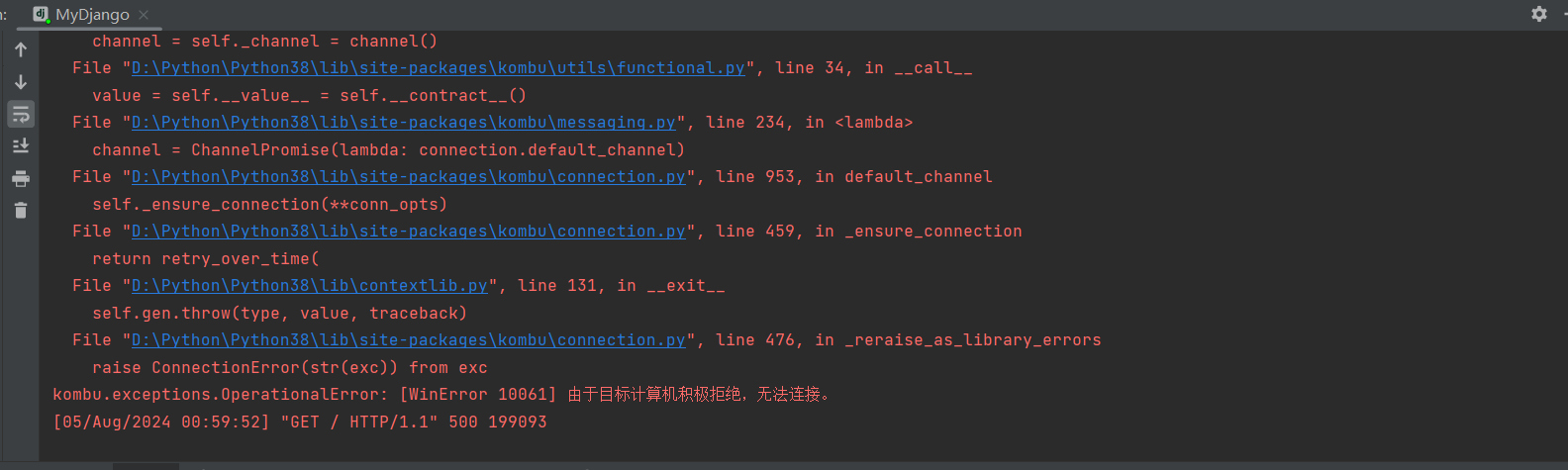
如果不写则会报错 :
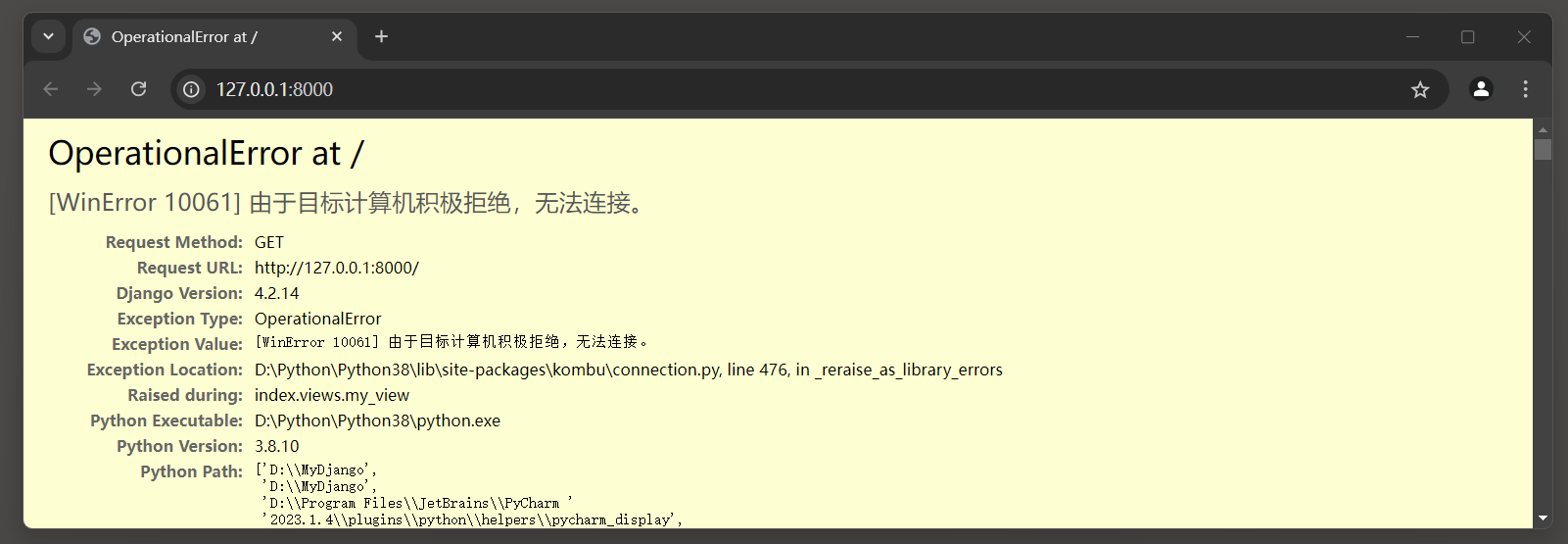
raise ConnectionError ( str ( exc ) ) from exc
kombu . exceptions . OperationalError : [ WinError 10061 ] 由于目标计算机积极拒绝 , 无法连接 .
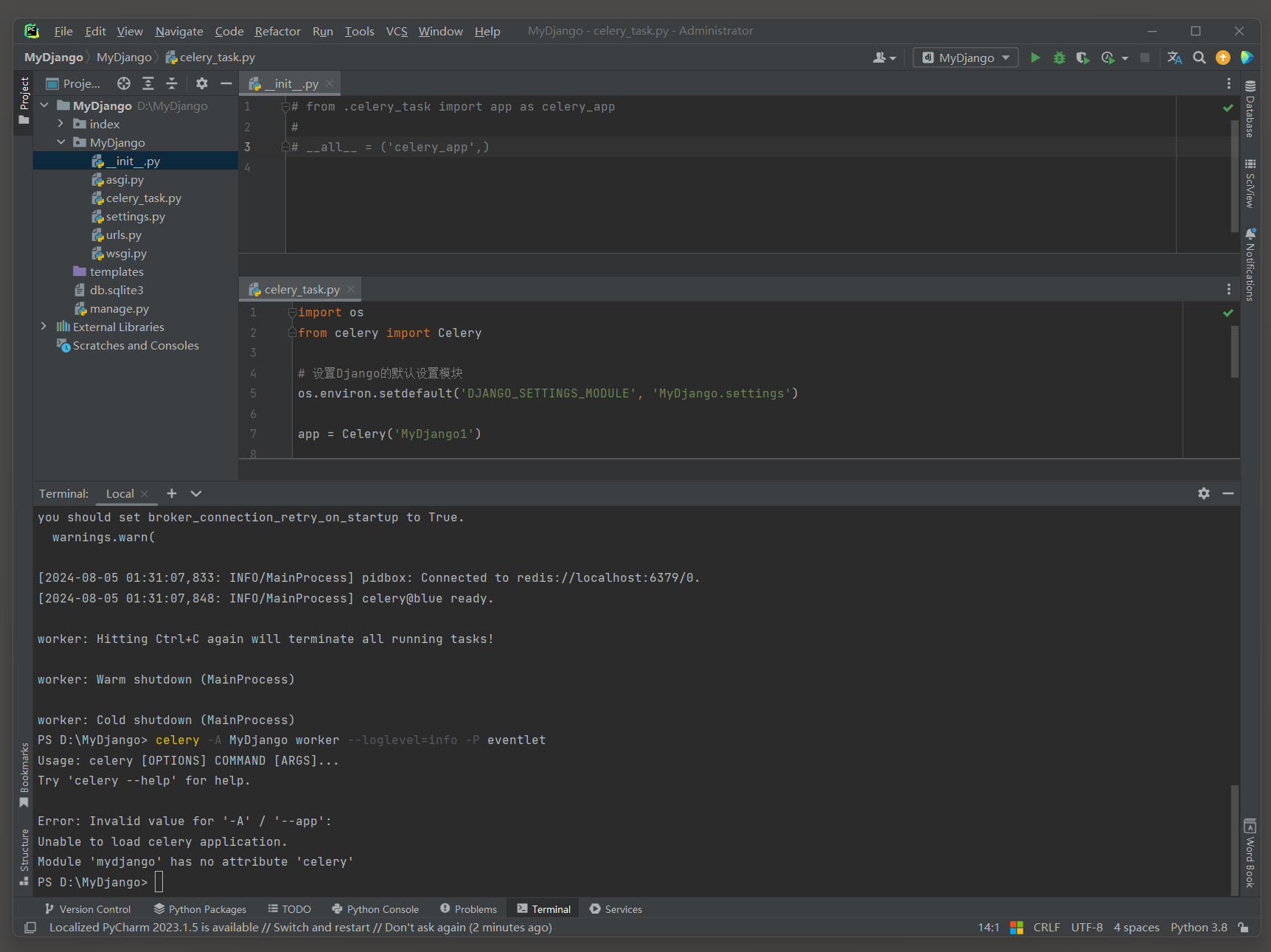
疑惑点 : 没有在__init__ . py中加载Celery应用 ( app ) , 执行 : celery -A MyDjango worker --loglevel = info -P eventlet 居然能成功 .
仔细一看 , 模块名和文件名重名了 . . .
修改文件名 , 执行 : celery -A MyDjango worker --loglevel = info -P eventlet 出错 , 这就正常了 , . . .
创建一个Python项目 , 执行 : celery -A MyDjango worker --loglevel = info -P eventlet , 成功 .
分析下原因 :
-A MyDjango 参数 : 告诉Celery命令去哪个模块或包中寻找Celery应用实例 .
在的例子中 , Celery会在MyDjango目录下寻找名为celery的模块 ( 即celery . py 文件 ) ,
并期望在这个模块中找到一个Celery应用实例 ( 通常是通过 Celery ( ) 类创建的 ) .
所以 , 够启动Celery worker的原因是Django项目中有一个celery . py文件 , 该文件定义了Celery应用实例 .
* 4. 创建任务 .
在Django的app中 , 创建一个tasks . py文件来定义你的Celery任务 .
from celery import shared_task
@shared_task
def add ( x, y) :
return x + y
@shared_task
def multiply ( x, y) :
return x * y
* 5. 运行Celery Worker .
在命令行工具中 , 从Django项目的根目录运行Celery worker .
PS D: \MyDjango> celery - A MyDjango worker - - loglevel= info - P eventlet
- - - - - - - - - - - - - - celery@blue v5. 4.0 ( opalescent)
- - - ** ** * - - - - -
- - ** ** ** * - - - - Windows- 10 - 10.0 .22621 - SP0 2024 - 08 - 04 23 : 34 : 07
- ** * - - - * - - -
- ** - - - - - - - - - - [ config]
- ** - - - - - - - - - - . > app: MyDjango1: 0x2010d937fd0
- ** - - - - - - - - - - . > transport: redis: // localhost: 6379 / 0
- ** - - - - - - - - - - . > results: redis: // localhost: 6379 / 0
- ** * - - - * - - - . > concurrency: 20 ( eventlet)
- - ** ** ** * - - - - . > task events: OFF ( enable - E to monitor tasks in this worker)
- - - ** ** * - - - - -
- - - - - - - - - - - - - - [ queues]
. > celery exchange= celery( direct) key= celery
[ tasks]
. index. tasks. add
. index. tasks. multiply
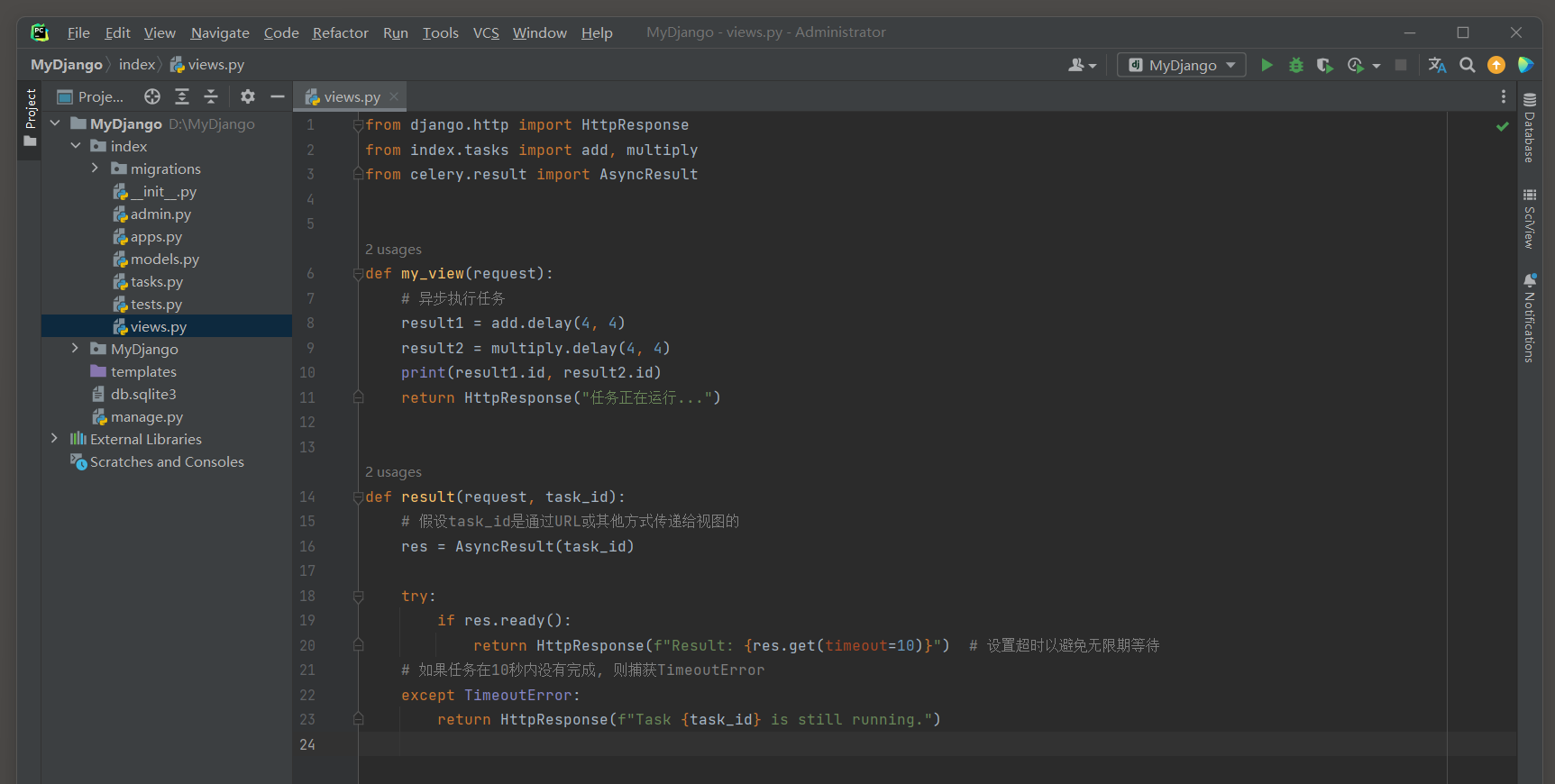
* 6. 调用任务 .
在Django视图中 , 可以异步地调用这些任务 .
from django. http import HttpResponse
from index. tasks import add, multiply
def my_view ( request) :
result1 = add. delay( 4 , 4 )
result2 = multiply. delay( 4 , 4 )
print ( result1, result2)
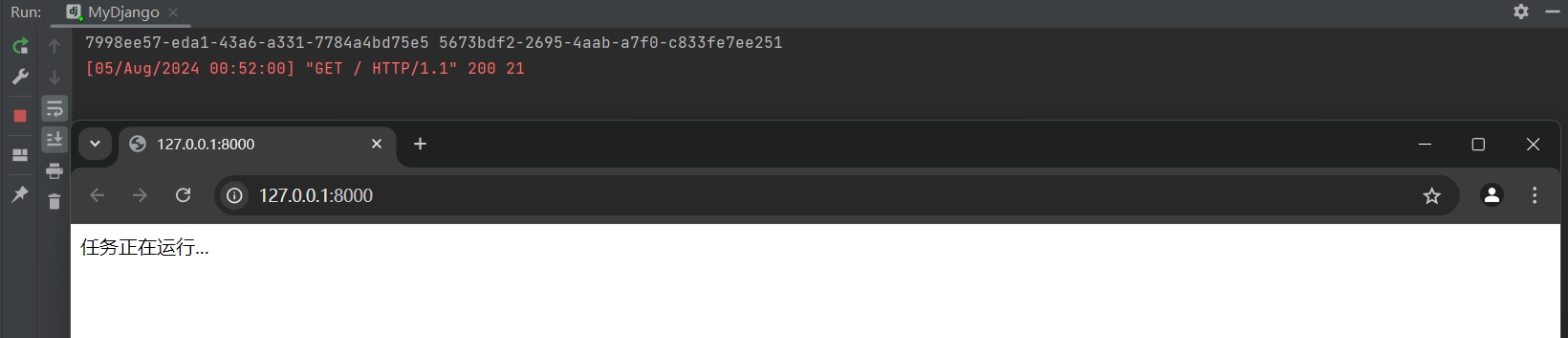
return HttpResponse( "任务正在运行..." )
delay方法 , 它会立即返回一个AsyncResult实例 , 而不是任务的实际结果 .
这个AsyncResult实例可以用来检查任务的状态 , 获取结果 ( 如果可用 ) 或等待结果完成 .
然而 , 直接在视图中返回了一个HttpResponse对象 , 这意味着Django视图函数会立即响应HTTP请求 , 而不会等待add和multiply任务完成 .
这是异步编程的典型模式 , 在Web应用中尤其有用 , 因为它允许Web服务器立即响应请求 , 而不必等待可能耗时的后台任务完成 .
result1 . id 和 result2 . id 是可以直接获取的 , 它们分别代表了两个异步任务的唯一标识符 ( 通常是UUID形式的字符串 ) .
这些ID可以用作查询任务状态或结果的键
* 7. 获取异步结果 .
由于 . get ( ) 会阻塞直到任务完成 , 因此通常不会直接在Web视图中调用它 .
相反 , 可以在另一个视图 , 后台任务或定时任务中检查任务状态并获取结果 .
from celery. result import AsyncResult
from django. http import HttpResponse
def check_task_status ( request, task_id) :
result = AsyncResult( task_id)
try :
if result. ready( ) :
return HttpResponse( f"Result: { result. get( timeout= 10 ) } " )
except TimeoutError:
return HttpResponse( f"Task { task_id} is still running." )
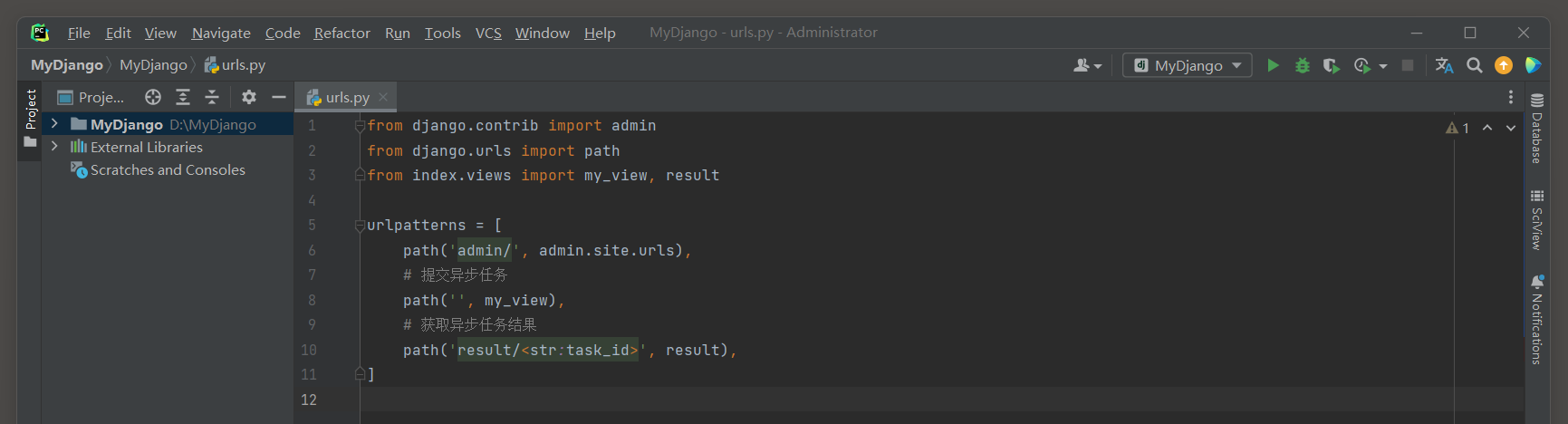
* 8. 设置路由 .
from django. contrib import admin
from django. urls import path
from index. views import my_view, result
urlpatterns = [
path( 'admin/' , admin. site. urls) ,
path( '' , my_view) ,
path( 'result/<str:task_id>' , result) ,
]
* 9. 启动项目 .
访问 : 127.0 .0 .1 : 8000 , 返回一个提示信息 .
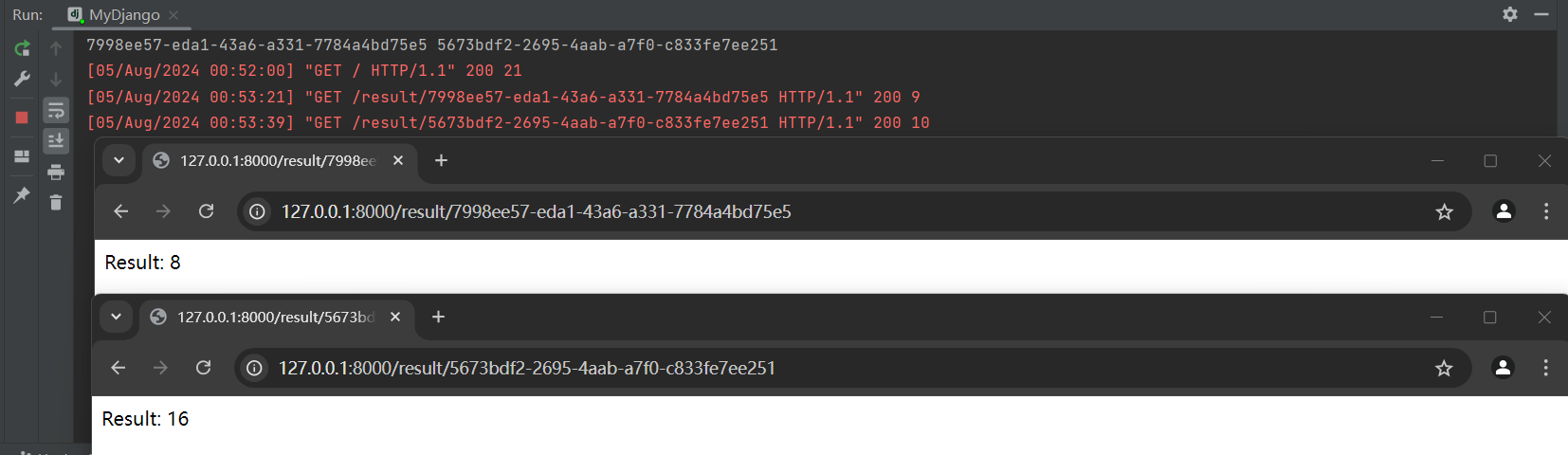
再分别访问 :
http : / / 127.0 .0 .1 : 8000 /result/ 7998 ee57-eda1- 43 a6-a331- 7784 a4bd75e5
http : / / 127.0 .0 .1 : 8000 /result/ 5673 bdf2- 2695 - 4 aab-a7f0-c833fe7ee251
获取异步任务的结果 .

























 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









