






[AI测试]python文字图像识别tesseract
github官网:https://github.com/tesseract-ocr/tesseract
python版本:https://github.com/madmaze/pytesseract
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
tesseract-OCR是一个开源的OCR引擎,能识别100多种语言,专门用于对图片文字进行识别,并获取文本。但是它的缺点是对手写的识别能力比较差。
Tesseract支持各种图像格式,包括PNG,JPEG和TIFF。
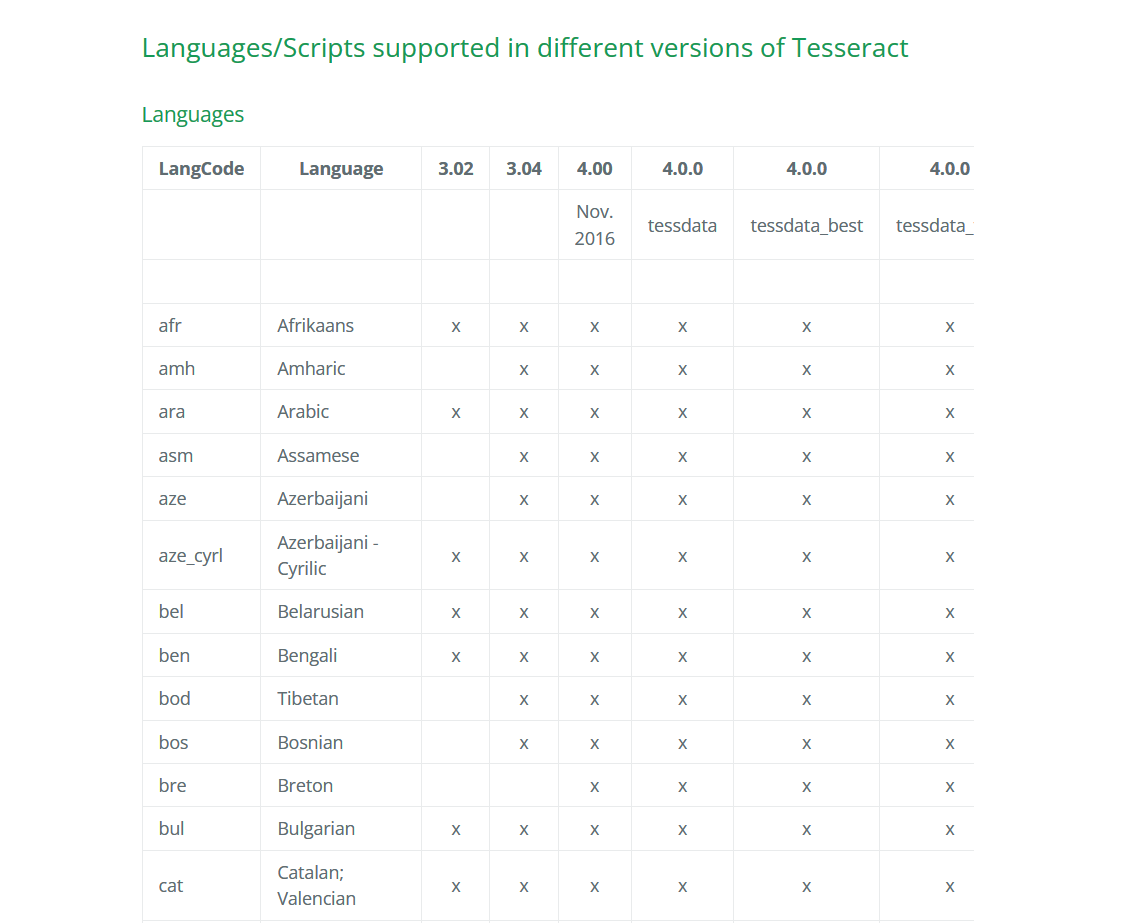
可以识别的语言列表:Languages/Scripts supported in different versions of Tesseract | tessdoc (tesseract-ocr.github.io)
(这么多叉叉把我看迷了)
下载安装
第一步需要先安装Tesseract OCR引擎
第二步需要安装支持python的pytesseract库及其相关依赖
Tesseract OCR引擎下载
安装Tesseract OCR引擎:pytesseract依赖于Tesseract OCR引擎。
官方文档:Introduction | tessdoc (tesseract-ocr.github.io)
根据官方介绍我们需要知道:
- 有两个部分需要安装,引擎本身和语言的训练数据。
- 语言训练的数据包称为“tesseract-ocr-langcode”和“tesseract-ocr-script-scriptcode”,其中
langcode是三个字母的语言代码,scriptcode是四个字母的脚本代码。 - 例如:tesseract-ocr-eng(英语),tesseract-ocr-ara(阿拉伯语),tesseract-ocr-chi-sim(简体中文),tesseract-ocr-script-latn(拉丁字母),tesseract-ocr-script-deva(梵文)等。
- 数据集下载地址:Traineddata Files for Version 4.00 + | tessdoc (tesseract-ocr.github.io)
Mac安装tesseract
1,安装有四种方式:
"安装tesseract, 同时安装训练工具"
brew install --with-training-tools tesseract
"安装tesseract,同时它还会安装所有语言"
brew install --all-languages tesseract
"安装附加组件"
brew install --all-languages --with-training-tools tesseract
"安装tesseract,但是不安装训练工具,一般情况用这种方式就可以"
brew install tesseract
2,安装完tesseract后,进行测试:
tesseract -v
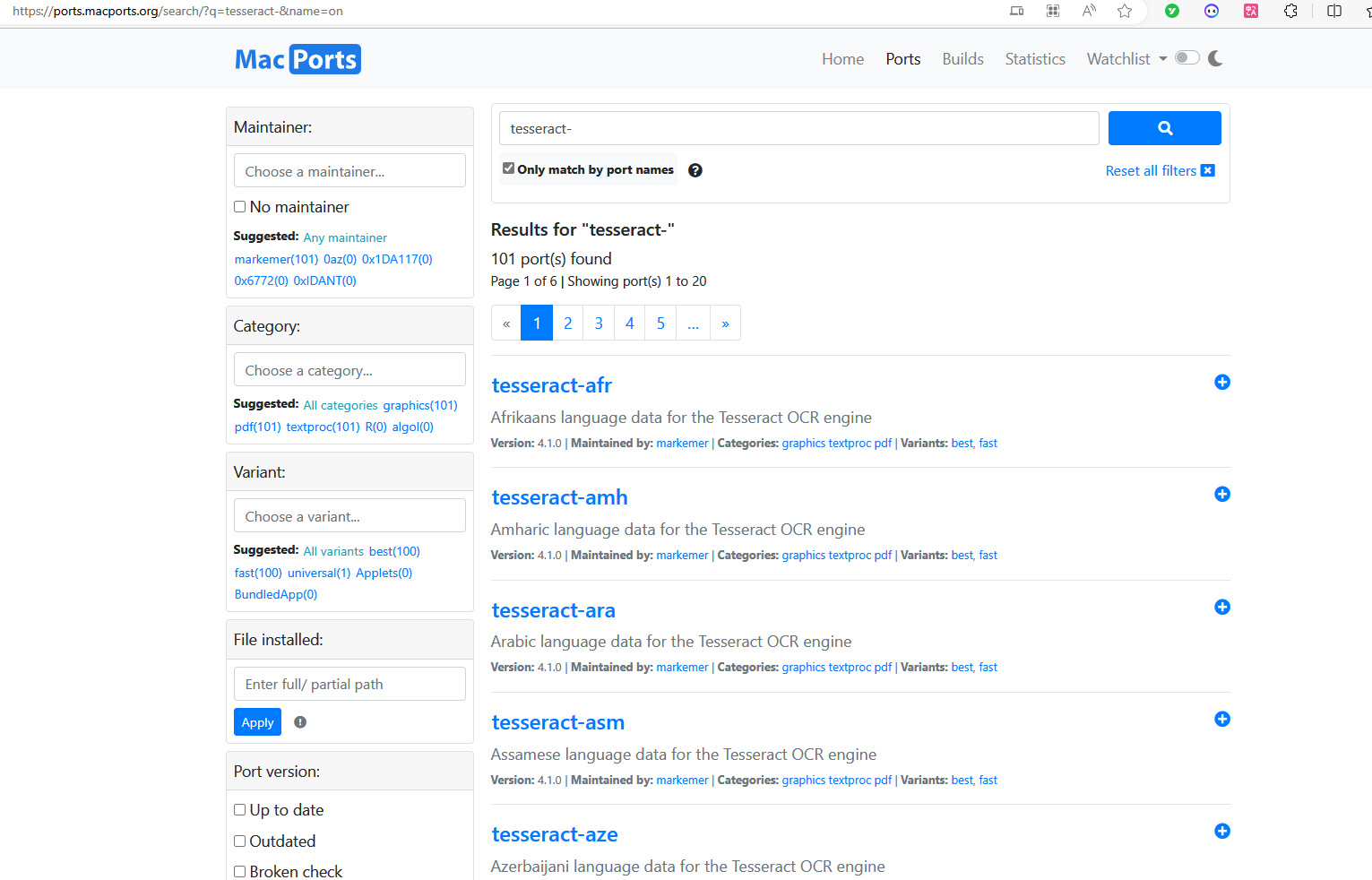
3、安装语言数据集
sudo port install tesseract-<langcode>
支持的语言:https://ports.macports.org/search/?q=tesseract-&name=on
Windows安装tesseract
1、下载tesseract安装包
-
tesseract安装包下载地址: https://digi.bib.uni-mannheim.de/tesseract/
-
-
注意区分32位和64位
-
我下载的是目前最新的,可以点击直接下载64位,tesseract-ocr-w64-setup-5.3.1.20230401.exe
-
网速较慢的可以从我网盘下载
-
链接:https://pan.baidu.com/s/1B5CyYZ5D5qwCXzZ9dnSGpQ?pwd=mwj6 提取码:mwj6
-
2、进行安装
-
(1)双击下载好的exe,建议右键以管理员身份运行
-
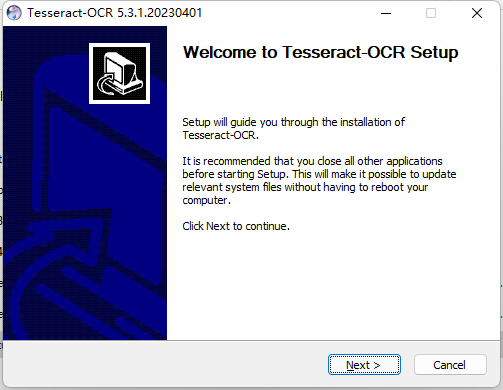
(2)点击next
-
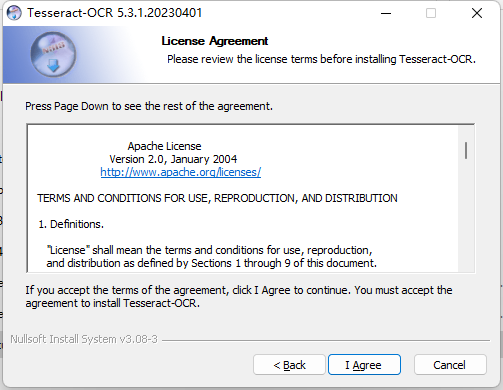
(3)点击
I Agree -
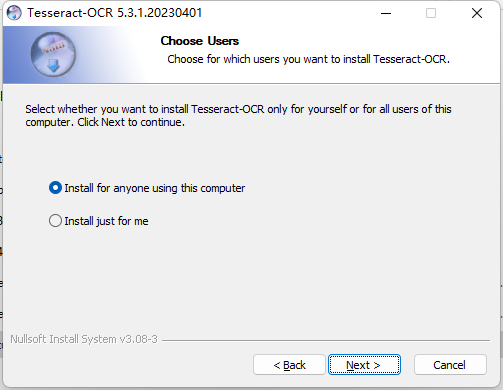
(4)根据需要选择,第一个是为这台电脑所有用户下载,第二个是只为当前用户下载
-
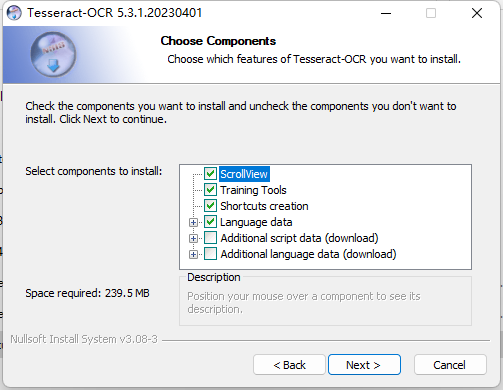
(5)这里是配置语言包下载,可以点开
Additional开头的这两个选项查看需要下载的语言,如果只想要中文那就找到Chinese下载就可以了。选好后再点击Next即可。 -
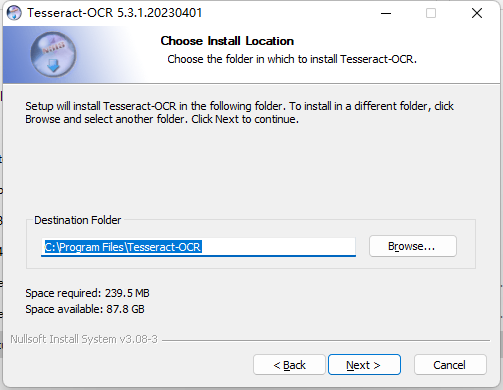
(6)选择你要安装的路径,注意如果不使用默认路径,后续代码会报
FileNotFoundError:[WinError 2]系统找不到指定文件的错误,解决办法就是用tesseract.exe的绝对路径。这里我使用默认路径安装。 -
(7)点击Install
-
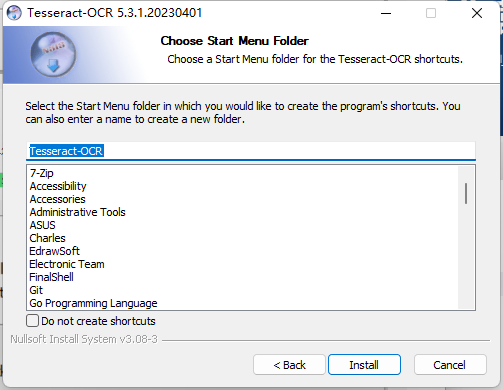
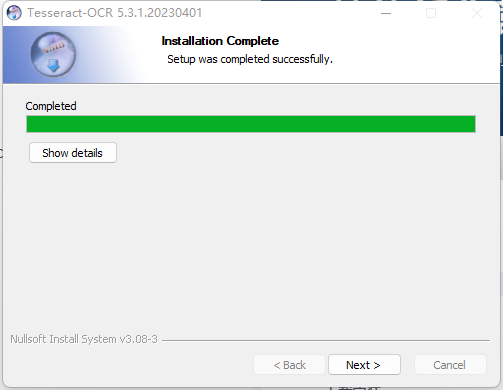
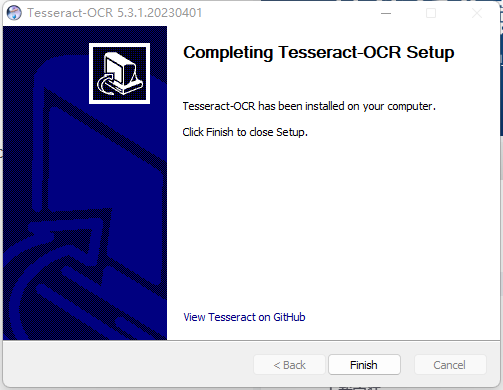
(8)安装完成后点击Next,再点击Finish
-
2、如果上面你下载语言库失败,你可以用如下官方链接自己下载对应语言库数据,都是几十兆
https://github.com/tesseract-ocr/tessdata_best
-
网速不好的用这个 链接:https://pan.baidu.com/s/11k5od_fd3_THN2YiGgmH3w?pwd=mwj6 提取码:mwj6
3、配置环境变量
-
如果你用的是默认地址,
C:\Program Files\Tesseract-OCR,把它加到环境变量中即可 -
我的电脑(此电脑) -> 右键点击属性 -> 高级系统设置 -> 环境变量 -> 系统环境变量找到Path点进去 -> 新建 -> 输入你的安装地址
-
# 默认安装地址则输入以下内容 C:\Program Files\Tesseract-OCR
4、验证是否安装成功
- ctrl+R 输入cmd回车
- 输入
tesseract -v,显示出内容就证明成功,如果出现不是内部命令巴拉巴拉的,就说明环境变量没搞好,重新配一下 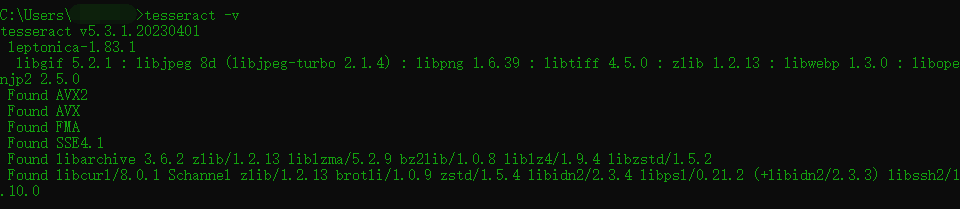
安装pytesseract
pip install pytesseract
其他相关依赖安装
pip install opencv-python
pip install pillow
代码demo
from PIL import Image
import pytesseract
im = Image.open('imgs\csdn_homepage.png')
# 识别文字,并指定语言
string = pytesseract.image_to_string(im, lang='chi_sim')
print(string)
对应识别的图片如下:
运行结果如下:

看到这识别出来的内容,我头顶上大写的无语,甚至想给电脑一拳!我都写了这么多内容了,你就这???
调整思路(无效)
查阅相关资料发现,预下载的中文包是比较小,准确率不高。
通过官网得知,tessdata_best下的语言包识别准确度是最高的,于是我就直接去下载了。
前文也有提到:https://github.com/tesseract-ocr/tessdata_best,网盘链接也在前面了。
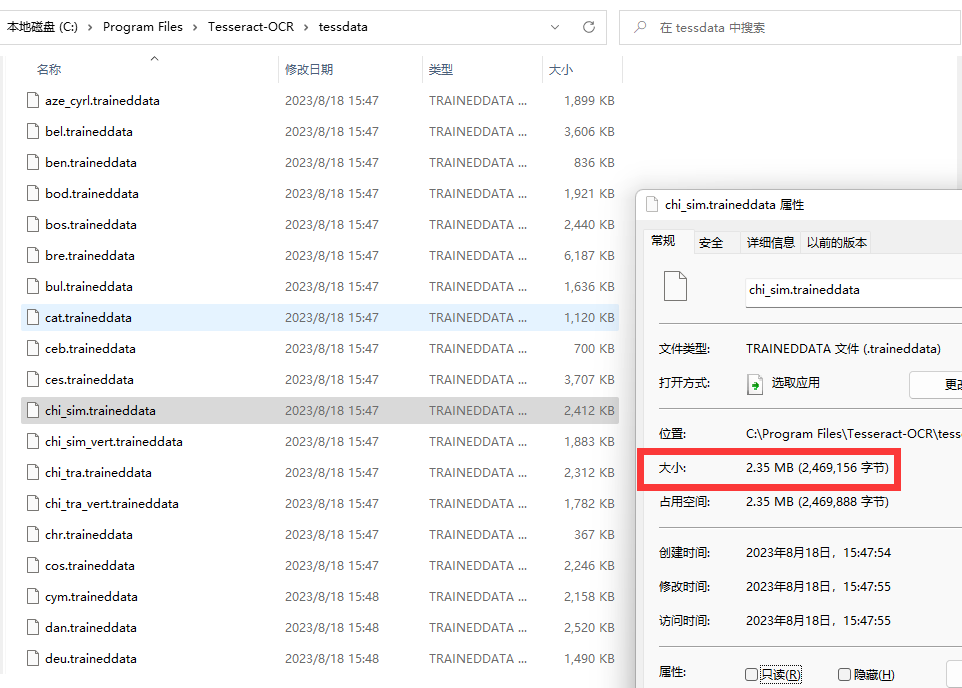
把下载好的包解压,将里面的内容复制到C:\Program Files\Tesseract-OCR\tessdata目录下(先将该目录内容全部删干净)。
之后再去运行代码。
此处有十几句脏话…
冷静下来,是我能力不足,是我不会训练模型,是我不应该只会捡现成用。
过了几分钟,脏话…
模型训练
可以在网上自己搜资料,参考资料里面我也放了一篇。
模型训练搜索关键词:tesseract-ocr训练方法
我不折腾了,这就是没有根据需求调研好相关资料的下场,看到一个就去莽还莽失败了。
更改方案
大家一定要记住,研究新东西,先调研,再踏进去。
简单的github搜索:
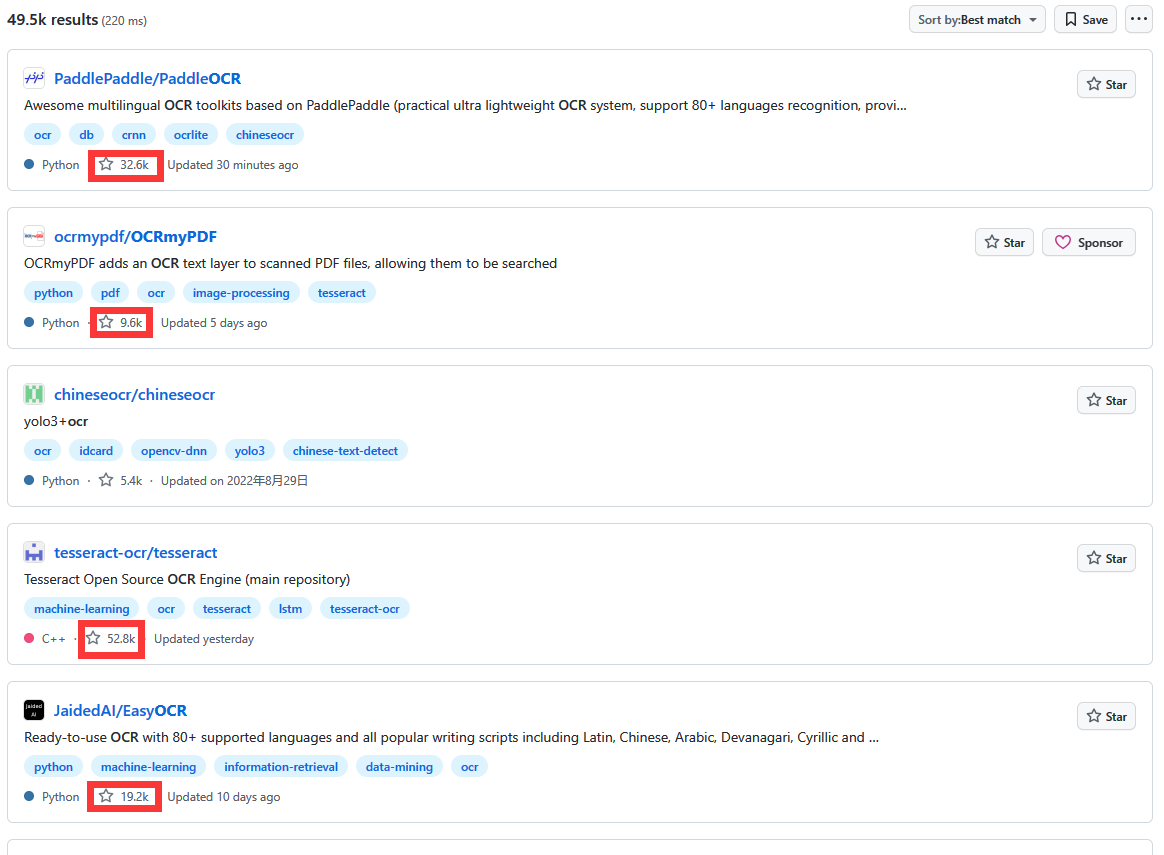
经过多方面的考察,发现:
Tesseract OCR
- 优点:支持补充训练
- 缺点:中文识别巨差!巨差!(暴躁怒吼声)
EasyOCR
- 优点:ocr识别还可以,优于一般开源模型
- 缺点:识别速度很慢,不支持训练
Paddle OCR
- 优点:可以补充训练,ocr识别效果好,执行速度快,文档齐全,资料多
- 缺点:偶尔会出现部分内容丢失的情况
CnOCR
- 优点:支持训练自己的模型,执行速度快,识别效果也不错
- 缺点:训练比PaddleOCR麻烦,极少更新维护
已有代码
虽然失败了,但是相关代码还是放出来,给有需要的小伙伴使用。
只拿取文字(官方代码)
import cv2
import pytesseract
from PIL import Image
im = 'imgs\csdn_homepage.png'
img_cv = cv2.imread(im)
# By default OpenCV stores images in BGR format and since pytesseract assumes RGB format,
# we need to convert from BGR to RGB format/mode:
img_rgb = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
print(pytesseract.image_to_string(img_rgb, lang='chi_sim'))
# OR
img_rgb = Image.frombytes('RGB', img_cv.shape[:2], img_cv, 'raw', 'BGR', 0, 0)
print(pytesseract.image_to_string(img_rgb, lang='chi_sim'))
(输出的内容很惨,还有大量文字丢失)
识别文字并返回对应坐标
# -*- coding: utf-8 -*-
'''
@Time : 2023/8/18 13:01
@Email : Lvan826199@163.com
@公众号 : 梦无矶的测试开发之路
@File : python文字识别.py
'''
__author__ = "梦无矶小仔"
import cv2
import pytesseract
# 设置语言数据
# 下面一行代码很重要
tessdata_dir_config = '--tessdata-dir "C:\Program Files\Tesseract-OCR\\tessdata"'
# 1、加载并预处理图像
image = cv2.imread('imgs\csdn_homepage.png') # 替换为你的图像文件路径,注意文件名不能有中文
# 根据图像的复杂性,还可以在预处理步骤中使用额外的图像处理技术,如阈值化、去噪、边缘检测等,以提高准确度和结果。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # cv2让图片黑白
# 2、执行文字识别和坐标提取 英语就是eng
results = pytesseract.image_to_data(gray, lang='chi_sim', config=tessdata_dir_config, output_type=pytesseract.Output.DICT)
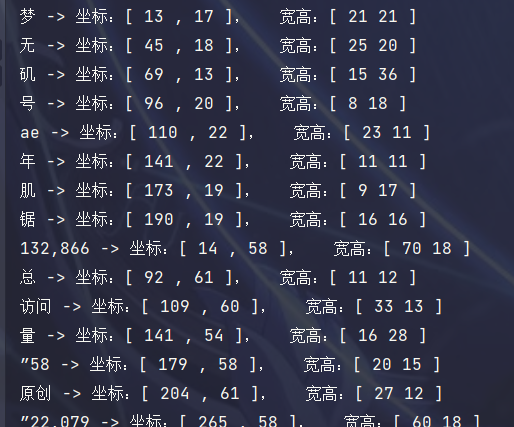
text_coords = []
for i, text in enumerate(results['text']):
if text.strip():
x = results['left'][i]
y = results['top'][i]
width = results['width'][i]
height = results['height'][i]
text_coords.append({'text': text, 'x': x, 'y': y, 'width': width, 'height': height})
# 输出结果
for coord in text_coords:
print(coord['text'], '-> 坐标:[', coord['x'], ",", coord['y'], "], ", "宽高:[", coord['width'], coord['height'], "]")
输出样式:
相关参考资料
# 官方文档
https://tesseract-ocr.github.io/tessdoc/
# 里面提到了艺术字的识别
https://www.jianshu.com/p/3326c7216696
# 简单的安装教程
https://zhuanlan.zhihu.com/p/186225362
# 比较详细的安装教程及pytesseract基本使用
https://zhuanlan.zhihu.com/p/341306710
# mac安装pytesseract
https://blog.csdn.net/wodedipang_/article/details/84585914
# 模型训练
https://www.cnblogs.com/cnlian/p/5765871.html
# OCR调研报告
https://blog.csdn.net/weixin_41021342/article/details/127203654
下一篇更新PaddleOCR,祝我成功!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









