







 本文探讨了在机器学习中,特别是支持向量机(SVM)的优化目标,从逻辑回归的代价函数出发,引入新代价函数并解释了SVM的数学定义,强调了正则化参数在模型选择中的作用。
本文探讨了在机器学习中,特别是支持向量机(SVM)的优化目标,从逻辑回归的代价函数出发,引入新代价函数并解释了SVM的数学定义,强调了正则化参数在模型选择中的作用。
在机器学习的旅程中,我们已经接触了多种学习算法。在监督学习中,选择使用算法 A 还是算法 B 的重要性逐渐减弱,而更关键的是如何在应用这些算法时优化目标。这包括设计特征、选择正则化参数等因素,这些在不同水平的实践者之间可能表现出截然不同的效果。
在支持向量机(Support Vector Machine,SVM)这一强大而受欢迎的算法中,我们发现了一种更为清晰且强大的学习方式,尤其在处理复杂非线性方程时。在这篇文章中,我们将深入研究支持向量机,了解其优化目标和数学定义。
优化目标的起点
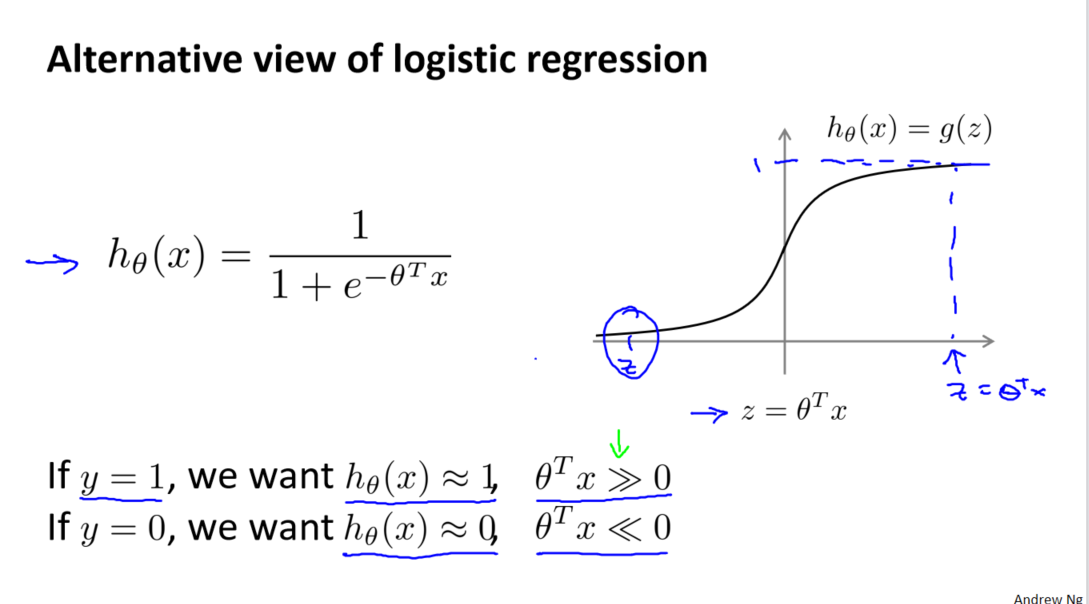
与以往一样,我们从优化目标开始。在逻辑回归中,我们熟悉的是假设函数和 S 型激励函数。然而,支持向量机采用了一种更为直接和强大的方式来学习。我们将逐步从逻辑回归演变到支持向量机。
首先,我们回顾了逻辑回归中的代价函数,其中每个样本对总代价函数都有贡献。对于样本(𝑥,𝑦),我们考虑了当 𝑦 = 1 时的情况,其中代价函数项为 −log(1 − 1 / (1 + 𝑒^(−𝑧)))。通过观察这个函数在 𝑧(表示为 𝜃^𝑇𝑥) 增大时的行为,我们理解了逻辑回归在观察正样本时试图将 𝜃^𝑇𝑥 设得非常大的原因。
构建支持向量机
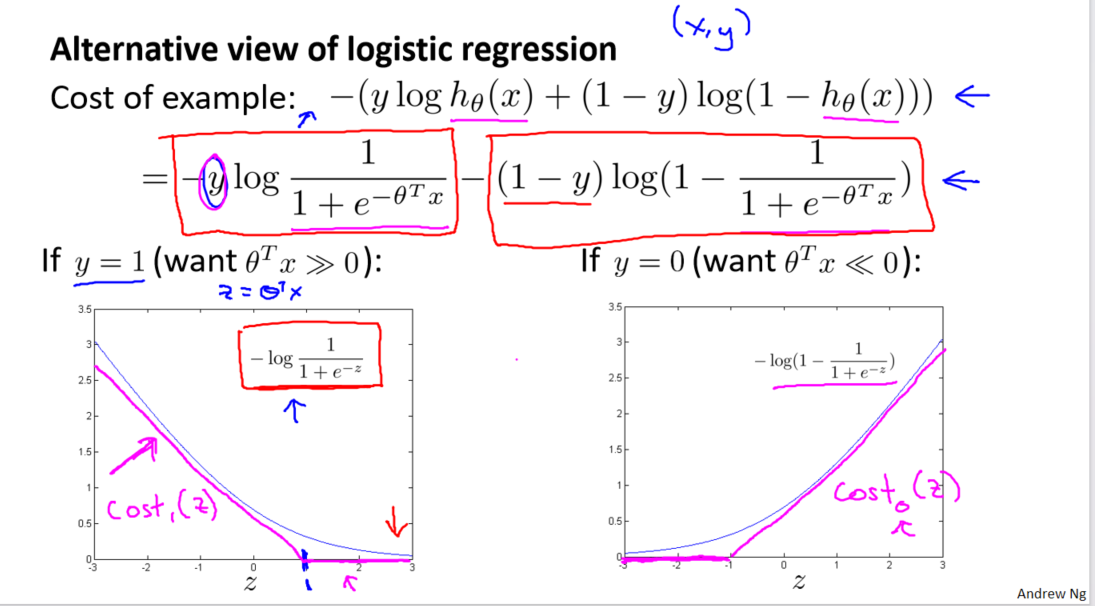
现在,我们开始构建支持向量机。我们将逻辑回归中的代价函数进行修改,引入两条新的线段,分别对应于𝑦 = 1 和 𝑦 = 0 的情况。这为支持向量机的建立奠定了基础。
我们引入两个新的代价函数,分别命名为cos𝑡1(𝑧)和cos𝑡0(𝑧),其中 𝑧 表示 𝜃^𝑇𝑥。这两个函数在数学上是连续的线段,代表了支持向量机的优化目标。
支持向量机的代价函数形式为 𝐶 × cos𝑡1(𝑧) + cos𝑡0(𝑧),其中 𝐶 是一个权衡项,代替了逻辑回归中的正则化参数 𝜆。通过调整 𝐶 的大小,我们可以灵活地调整对拟合训练样本和正则化项的重视程度。
SVM 的数学定义
支持向量机通过最小化优化目标函数来学习参数,这一目标函数包含了代价函数和正则化项。通过将逻辑回归中的正则化参数 𝜆 替换为 𝐶,我们得到了支持向量机的数学定义。最终,支持向量机的假设函数直接预测 𝑦 的值是 1 还是 0,根据 𝜃^𝑇𝑥 大于或等于 0 的情况。

参考资料:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











