






AC 自动机
引入
AC 自动机是一种用于解决多模式串以及一主串匹配的字符串算法。
问题通常是给出若干个模式串 S 以及主串 T,询问若干个模式串分别在主串中的某些信息。
AC 自动机构建在 Trie 的结构基础上,结合了 KMP 算法的失配指针思想。
在进行多模式串匹配前,只有两个步骤需要去实现:
- 将所有模式串扔进一棵
Trie树中。 - 对于
Trie上的所有节点构建失配指针。
AC 自动机的时间复杂度约为
O
(
n
+
m
)
O(n+m)
O(n+m)。
算法思想
AC 自动机其实就是在 Trie 树上建几条边然后就没了,真的没了。
有关 Trie 树的知识,请出门右转,点这里。
一开始按照 Trie 树的基本构建方法搭建即可。
请注意,Trie 树节点的含义十分重要:
它表示的是某个模式串的前缀,也就是一个状态。
而 Trie 树的边就是状态的转移。
一般 Trie 树的每个节点都代表一个或多个字符串。
建树的代码如下:
const int MAXN = 500005;
int nxt[MAXN][26], cnt; // nxt[i][c] 表示 i 号点所连、存储字符为 c + 'a' 的点的编号
void init() // 初始化
{
memset(nxt, 0, sizeof(nxt));
cnt = 1;
}
void insert(const string &s) // 插入字符串
{
int cur = 1;
for (auto c : s)
{
// 尽可能重用之前的路径,如果做不到则新建节点
if (!nxt[cur][c - 'a'])
nxt[cur][c - 'a'] = ++cnt;
cur = nxt[cur][c - 'a']; // 继续向下
}
}
好了,到了最重要的一点了,如何构建 Fail 指针?
什么是 Fail 指针呢?
如果一个 Trie 树上的节点
u
u
u 的 Fail 指针指向节点
v
v
v,那么这就表示根节点到节点
v
v
v 的字符串是根节点到节点
u
u
u 的字符串的一个后缀。
注意,根节点的所有非空子节点的 Fail 指针都必须指向根节点。
如果看不懂可参考下面这张图。

例如求根节点
0
0
0 的左子树上的那个
c
c
c 节点的 fail 指针,观察可得,根节点到根节点的右子树上的那个
c
c
c 节点组成的字符串(bc)是根节点到根节点的左子树上的那个
c
c
c 节点组成的字符串(abc)的一个后缀,所以
f
a
i
l
左
边
的
c
=
右
边
的
c
的
编
号
fail_{左边的 \ c}=右边的 \ c \ 的编号
fail左边的 c=右边的 c 的编号。
再思考如何在程序上构建 Fail 指针。
对于一个 Trie 树上的节点
u
u
u,设它的父节点为
f
f
f,两个节点通过字符
c
c
c 连接,也就是说
t
r
i
e
f
,
c
=
u
trie_{f,c}=u
trief,c=u。
那么求 Fail 指针有两个情况,如下:
- 如果
t
r
i
e
f
,
c
trie_{f,c}
trief,c 不是空节点,那么就将节点
u
u
u 的
Fail指针指向 t r i e f a i l f , c trie_{fail_{f},c} triefailf,c(肯定满足Fail指针的性质)。 - 如果
t
r
i
e
f
,
c
trie_{f,c}
trief,c 是空节点,那么我们令
s
o
n
f
=
s
o
n
f
a
i
l
f
son_f=son_{fail_{f}}
sonf=sonfailf,即
t
r
f
,
i
=
t
r
f
a
i
l
f
,
i
tr_{f,i} = tr_{fail_{f},i}
trf,i=trfailf,i。这样做令
AC自动机的实现相当于不断拓展字符串的后缀,尝试匹配最后一个字符,如果最后一个字符并不存在,那么我们跳转到下一个可能出现该字符的位置,直到结束为止。
这里的 get_fail 函数将 Trie 树上所有节点按照 BFS 的顺序入队,最后依次求 Fail 指针。
首先我们单独处理根节点,将根节点 0 0 0 的所有非空的子节点入队。
然后每次取出队首处理 Fail 指针,即遍历
26
26
26 个字符依次判断(根据题目判断)。
f
a
i
l
u
fail_{u}
failu 就表示节点
u
u
u 的 Fail 指针指向的节点。
代码如下:
void get_fail()
{
queue<int> q;
for(int i = 0; i < 26; ++i)
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
小 技 巧 \huge{小技巧} 小技巧
对于解决问题时跳 Fail 链的代码,一般如下:
int res = 0;
for(int j = u; j && !tag[j]; j = fail[j])
{
res += num[j];
tag[j] = 1;
}
考虑优化(因为可能重复跳到一个点,时间复杂度暴增),建一棵 Fail 树,
O
(
n
)
O(n)
O(n) 就一遍子树和就行了。
代码如下:
建 Fail 树,根据题目要求选择建正向边还是反向边,下面是建正向边的代码,dfs 时从根节点开始遍历就行了。但如果是建反向边,建边时应记录入度,从每个入度为
0
0
0 的点(即叶子节点)开始遍历。
for(int i = 1; i <= cnt; ++i) add(fail[i], i);
dfs,有时应建
v
i
s
vis
vis 数组判断是否遍历过。
void dfs(int u)
{
for(int i = head[u]; i; i = nxt[i])
{
int v = to[i];
dfs(v);
siz[u] += siz[v];
}
}
这时,就成功地将 O ( n 2 ) O(n^2) O(n2) 优化成了 O ( n ) O(n) O(n)。
然后就没了。。。
应用
不,肯定还没结束。
【模板】AC自动机(简单版)
给定文本串和若干个模式串,求出有多少个不同的模式串在文本串中出现。
对若干个模式串构建好 AC 自动机后,对文本串的每一个前缀跳一遍 Fail 指针就行了。
因为一个字符串的每一个前缀的所有后缀就是这个字符串的所有子串。
一开始记录每个节点对应多少个完整的模式串就行了。
#include<bits/stdc++.h>
using namespace std;
#define _ (int)2e6 + 5
int n;
int tot;
int tr[_][27];
int fail[_];
int tag[_];
int num[_];
char c[_];
void insert(char *c)
{
int len = strlen(c);
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = c[i] - 'a';
if(!tr[u][v]) tr[u][v] = ++tot;
u = tr[u][v];
}
num[u]++;
}
void get_fail()
{
queue<int> q;
for(int i = 0; i < 26; ++i)
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
int query(char *s)
{
int len = strlen(s);
int res = 0;
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = s[i] - 'a';
u = tr[u][v];
for(int j = u; j && !tag[j]; j = fail[j])
{
res += num[j];
tag[j] = 1;
}
}
return res;
}
signed main()
{
// freopen("P3808_2.in", "r", stdin);
// freopen("2.out", "w", stdout);
scanf("%d", &n);
// printf("%d\n", n);
for(int i = 1; i <= n; ++i)
{
scanf("%s", c);
// printf("%s\n", c);
insert(c);
}
get_fail();
scanf("%s", c);
// printf("%s\n", c);
printf("%d\n", query(c));
return 0;
}
【模板】AC自动机(加强版)
给出若干个模式串和一个文本串,求某个模式串在文本串中出现的最大次数和该模式串,且保证不存在两个相同的模式串。
我们考虑如何查询最大出现次数。
记 n u m u num_u numu,为以 u u u 为结尾的那个唯一的字符串读入时的编号。
最后在统计答案时用一个 v i s vis vis 数组存储出现的次数,取最大值。
统计答案的方法上面说过了。
然后遍历 v i s vis vis 数组,当 v i s i vis_i visi 与最大值相同时,就输出第 i i i 个模式串。
多测记得清空。(别问为什么,血的教训)
#include<bits/stdc++.h>
using namespace std;
#define _ (int)5e5 + 5
int n;
int tot;
int tr[_][27];
int fail[_];
int tag[_];
int num[_];
int vis[_];
char c[_][151];
void insert(char *c, int id)
{
int len = strlen(c);
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = c[i] - 'a';
if(!tr[u][v]) tr[u][v] = ++tot;
u = tr[u][v];
}
num[u] = id;
}
void get_fail()
{
queue<int> q;
for(int i = 0; i < 26; ++i)
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
int query(char *s)
{
int len = strlen(s);
int res = 0;
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = s[i] - 'a';
u = tr[u][v];
for(int j = u; j; j = fail[j])
{
if(!num[j]) continue;
vis[num[j]]++;
}
}
for(int i = 1; i <= n; ++i) res = max(res, vis[i]);
return res;
}
void init()
{
tot = 0;
memset(tag, 0, sizeof tag);
memset(vis, 0, sizeof vis);
memset(tr, 0, sizeof tr);
memset(fail, 0, sizeof fail);
memset(num, 0, sizeof num);
memset(vis, 0, sizeof vis);
}
signed main()
{
while(scanf("%d", &n) && n)
{
init();
for(int i = 1; i <= n; ++i)
{
scanf("%s", c[i]);
insert(c[i], i);
}
get_fail();
scanf("%s", c[n + 1]);
int ans = query(c[n + 1]);
printf("%d\n", ans);
for(int i = 1; i <= n; ++i)
if(vis[i] == ans) printf("%s\n", c[i]);
continue;
}
return 0;
}
P5357 【模板】AC自动机(二次加强版)
给你一个文本串 S 和若干个模式串,请你分别求出每个模式串在 S 中出现的次数。
我们可以建出 AC 自动机后把文本串在上面跑一遍,每到达一个节点就把树上这个节点到根路径上的节点计数器
+
1
+1
+1。
然后建一棵 Fail 树,即连一条有向边
f
a
i
l
i
→
i
fail_{i} \to i
faili→i。
建 Fail 树其实就是优化上面跳 Fail 链的时间复杂度。
如果听不懂,可以回到上面好好看看。
那么,一个模式串,在文本串中出现的次数就是 Fail 树上它结束的节点子树的权值和,没了。
#include<bits/stdc++.h>
using namespace std;
#define _ (int)2e6 + 5
int n;
int cnt;
int tr[_][27];
int fail[_];
int tag[_];
int num[_];
int vis[_];
int siz[_];
char c[_][250];
int tot, head[_], to[_ << 1], nxt[_ << 1];
void add(int u, int v)
{
to[++tot] = v;
nxt[tot] = head[u];
head[u] = tot;
}
void insert(char *c, int id)
{
int len = strlen(c);
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = c[i] - 'a';
if(!tr[u][v]) tr[u][v] = ++cnt;
u = tr[u][v];
}
num[id] = u;
}
void get_fail()
{
queue<int> q;
for(int i = 0; i < 26; ++i)
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
void dfs(int u)
{
for(int i = head[u]; i; i = nxt[i])
{
int v = to[i];
dfs(v);
siz[u] += siz[v];
}
}
void query(char *s)
{
int u = 0;
int len = strlen(s);
for (int i = 0; i < len; ++i)
{
int v = s[i] - 'a';
u = tr[u][v];
++siz[u];
}
for(int i = 1; i <= cnt; ++i) add(fail[i], i);
dfs(0);
for(int i = 1; i <= n; ++i) printf("%d\n", siz[num[i]]);
}
signed main()
{
scanf("%d", &n);
for(int i = 1; i <= n; ++i)
{
scanf("%s", c[i]);
insert(c[i], i);
}
get_fail();
scanf("%s", c[n + 1]);
query(c[n + 1]);
return 0;
}
[TJOI2013]单词
一篇文章由许多模式串组成,请你求出知道每个模式串分别在文章中出现了多少次。
模式串之间互相隔开。
例:
3 3 3 个模式串
a,aa,aaa
则出现次数分别为 6 6 6, 3 3 3, 1 1 1。
这题也要建 Fail 树,具体看上面。
首先,定义一个节点的权值为该节点属于的字符串个数。
那么,一个节点表示的字符串,在整个字典树中出现的次数就是子树的权值和,没了。
#include<bits/stdc++.h>
using namespace std;
#define _ (int)2e6 + 5
int n;
int cnt;
int tr[_][27];
int fail[_];
int tag[_];
int num[_];
int vis[_];
int siz[_];
char c[_];
int tot, head[_], to[_ << 1], nxt[_ << 1];
void add(int u, int v)
{
to[++tot] = v;
nxt[tot] = head[u];
head[u] = tot;
}
void insert(char *c, int id)
{
int len = strlen(c);
int u = 0;
for(int i = 0; i < len; ++i)
{
int v = c[i] - 'a';
if(!tr[u][v]) tr[u][v] = ++cnt;
u = tr[u][v];
siz[u]++;
}
num[id] = u;
}
void get_fail()
{
queue<int> q;
for(int i = 0; i < 26; ++i)
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
void dfs(int u)
{
for(int i = head[u]; i; i = nxt[i])
{
int v = to[i];
dfs(v);
siz[u] += siz[v];
}
}
void query()
{
for(int i = 1; i <= cnt; ++i) add(fail[i], i);
dfs(0);
for(int i = 1; i <= n; ++i) printf("%d\n", siz[num[i]]);
}
signed main()
{
scanf("%d", &n);
for(int i = 1; i <= n; ++i)
{
scanf("%s", c);
insert(c, i);
}
get_fail();
query();
return 0;
}
[JSOI2012]玄武密码
要求对于每一个模式串,求出其最长的前缀 p p p,满足 p p p 是文本串的子串。
我们可以先找出文本串的所有子串结束的节点,标记为 1 1 1。
然后对于每一个模式串,判断这个模式串的前缀结束的节点是否被标记为 1 1 1,最后取长度的最大值即可。
#include <bits/stdc++.h>
using namespace std;
#define MAXN (int) 1e7 + 7
#define MAXM (int) 1e5 + 7
#define MAXT (int) 100 + 7
int n, m;
char kkk[MAXN];
char c[MAXM][MAXT];
int cnt;
int tr[MAXN][4];
int tag[MAXN];
int fail[MAXN];
int change(char c)
{
if(c == 'E') return 0;
if(c == 'S') return 1;
if(c == 'W') return 2;
if(c == 'N') return 3;
}
void insert(char *s)
{
int t = 0;
int len = strlen(s);
for(int i = 0; i < len; ++i)
{
int b = change(s[i]);
if(!tr[t][b]) tr[t][b] = ++cnt;
t = tr[t][b];
}
}
void get_fail()
{
queue<int> q;
for(int i = 0; i < 4; ++i)
{
if(tr[0][i])
{
q.push(tr[0][i]);
}
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(int i = 0; i < 4; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
void Find(char *s)
{
int t = 0;
int len = strlen(s);
for(int i = 0; i < len; ++i)
{
int v = change(s[i]);
t = tr[t][v];
for(int j = t; j && !tag[j]; j = fail[j])
{
tag[j] = 1;
}
}
}
int query(char *s)
{
int res = 0;
int t = 0;
int len = strlen(s);
for(int i = 0; i < len; ++i)
{
int v = change(s[i]);
t = tr[t][v];
if(tag[t]) res = max(res, i + 1);
}
return res;
}
signed main()
{
scanf("%d%d", &n, &m);
scanf("%s", kkk);
for(int i = 1; i <= m; ++i)
{
scanf("%s", c[i]);
insert(c[i]);
}
get_fail();
Find(kkk);
for(int i = 1; i <= m; ++i)
printf("%d\n", query(c[i]));
return 0;
}
[HNOI2006]最短母串问题
给定 n n n 个字符串 ( S 1 , S 2 , . . . , S n ) (S_1,S_2,...,S_n) (S1,S2,...,Sn),要求找到一个最短的字符串 T T T,使得这 n n n 个字符串 ( S 1 , S 2 , . . . , S n ) (S_1,S_2,...,S_n) (S1,S2,...,Sn) 都是 T T T 的子串。
找到字符串间相同前缀和后缀,删掉一个,然后连起来。
例如 ABCD 和 BCDABC,相同前后缀为 ABC,最短的
T
T
T 应为 ABCDABC。
考虑状态压缩,将第
i
i
i 个字符串在 Trie 树上结束的节点的权值记为
2
i
2^i
2i,
∣
|
∣ 起来就行,若某一时刻的状态为
2
n
−
1
2^n-1
2n−1,意为找到了所有的字符串。
建完 AC 自动机后,跑一边 bfs,每次遍历时将遍历到的点和其 Fail 链上所有的权值
∣
|
∣ 起来,最后输出答案即可。
具体看代码。
没优化的代码
#include <bits/stdc++.h>
#define re register
using namespace std;
int n;
int cnt;
int tr[1005][27];
bool vis[1 << 16][1005];
int tag[1005];
int fail[1005];
char c[301];
inline int read()
{
re int x = 0;
re char c = getchar();
while(c < '0' || c > '9') c = getchar();
while(c >= '0' && c <= '9') x = (x << 3) + (x << 1) + (c - 48), c = getchar();
return x;
}
inline void insert(char *c, int k)
{
re int len = strlen(c);
re int t = 0;
for(re int i = 0; i< len; ++i)
{
int v = c[i] - 'A';
if(!tr[t][v]) tr[t][v] = ++cnt;
t = tr[t][v];
}
tag[t] |= (1 << k);
}
inline void get_fail()
{
queue<int> q;
for(re int i = 0; i < 26; ++i)
{
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(re int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
}
struct abc
{
int u, v;
string s;
};
inline void Find()
{
queue<abc> q;
q.push({0, 0, ""});
vis[0][0] = 1;
int sum, k;
while(!q.empty())
{
abc now = q.front();
q.pop();
for(re int i = 0; i < 26; ++i)
{
int v = tr[now.v][i];
if(!vis[now.u][v])
{
sum = now.u;
k = v;
while(k)
{
sum |= tag[k];
k = fail[k];
}
vis[sum][v] = 1;
if(sum + 1 == (1 << n))
{
cout << now.s + char(i + 'A') << endl;
return;
}
q.push({sum, v, now.s + char(i + 'A')});
}
}
}
}
signed main()
{
n = read();
for(re int i = 1; i <= n; ++i)
{
scanf("%s", c);
insert(c, i - 1);
}
get_fail();
Find();
return 0;
}
用 Fail 树优化的代码
#include <bits/stdc++.h>
#define re register
using namespace std;
int n;
int cnt;
int tr[1005][27];
bool vis[1 << 16][1005];
int tag[1005];
int fail[1005];
char c[301];
inline int read()
{
re int x = 0;
re char c = getchar();
while(c < '0' || c > '9') c = getchar();
while(c >= '0' && c <= '9') x = (x << 3) + (x << 1) + (c - 48), c = getchar();
return x;
}
int tot, head[1005], to[2010], nxt[2010];
inline void add(int u, int v)
{
to[++tot] = v;
nxt[tot] = head[u];
head[u] = tot;
}
int inv[1005];
int dfn[1005];
inline void dfs(int u)
{
dfn[u] = 1;
for(re int i = head[u]; i; i = nxt[i])
{
int v = to[i];
if(dfn[v]) continue;
dfs(v);
tag[u] |= tag[v];
}
}
inline void insert(char *c, int k)
{
re int len = strlen(c);
re int t = 0;
for(re int i = 0; i< len; ++i)
{
int v = c[i] - 'A';
if(!tr[t][v]) tr[t][v] = ++cnt;
t = tr[t][v];
}
tag[t] = tag[t] | (1 << k);
}
inline void get_fail()
{
queue<int> q;
for(re int i = 0; i < 26; ++i)
{
if(tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
}
while(!q.empty())
{
int now = q.front();
q.pop();
for(re int i = 0; i < 26; ++i)
{
int v = tr[now][i];
if(v)
{
fail[v] = tr[fail[now]][i];
q.push(v);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
}
for(re int i = 1; i <= cnt; ++i)
{
add(i, fail[i]);
inv[fail[i]]++;
}
}
struct abc
{
int u, v;
string s;
};
inline void Find()
{
queue<abc> q;
q.push({0, 0, ""});
vis[0][0] = 1;
int sum, k;
while(!q.empty())
{
abc now = q.front();
q.pop();
for(re int i = 0; i < 26; ++i)
{
int v = tr[now.v][i];
if(!vis[now.u][v])
{
sum = now.u;
k = v;
sum |= tag[k];
vis[sum][v] = 1;
if(sum + 1 == (1 << n))
{
cout << now.s + char(i + 'A') << endl;
return;
}
q.push({sum, v, now.s + char(i + 'A')});
}
}
}
}
signed main()
{
n = read();
for(re int i = 1; i <= n; ++i)
{
scanf("%s", c);
insert(c, i - 1);
}
get_fail();
for(re int i = 1; i <= cnt; ++i)
if(!inv[i] && !dfn[i]) dfs(i);
Find();
return 0;
}
[JSOI2007]文本生成器
有若干个长度固定且完全随机的文章,文章间互不相同,都是大写英文字母。
如果一篇文章中至少包含我们了解的一个单词,那么我们说这篇文章是可读的(我们称文章 s s s 包含单词 t t t,当且仅当单词 t t t 是文章 s s s 的子串)。
请你输出所有文章中,可读文章的数量。
答案对 1 0 4 + 7 10^4+7 104+7 取模。
运用容斥原理,答案 = = = 所有文章数量 − - − 不可读文章数量。
先将所有我们了解的单词插入到 AC 自动机中,将字符串在 Trie 树上结束的节点标记为
1
1
1,意为这个字符串是可读的(用
t
a
g
tag
tag 数组储存)。
t a g i tag_i tagi 若为 1 1 1,说明是可读的,否则不可读。
然后在构建失陪指针时,转移 t a g tag tag 的值。
因为如果一个字符串的后缀时可读的,那么这个字符串也是可读的。
注意这里要用 ∣ | ∣,有 1 1 1 即为真,否则为假。
tag[tr[u][i]] |= tag[fail[tr[u][i]]];
最后,根据 AC 自动机 dp,设
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j] 表示长度为
i
i
i 且后缀字符为 AC 自动机上节点
j
j
j 的不可读文章数量,其中不能出现可读文章,所以有转移方程:
for (int i = 0; i < m; ++i)
for (int j = 0; j <= cnt; ++j)
for (int k = 0; k < 26; ++k)
if (!tag[tr[j][k]])
dp[i + 1][tr[j][k]] = (dp[i + 1][tr[j][k]] + dp[i][j]) % mod;
下面是 A C C O D E AC \ CODE AC CODE
#include <bits/stdc++.h>
using namespace std;
const int mod = 10007;
inline int read()
{
char tr = getchar();
int x = 0;
while (tr < '0' || tr > '9')
tr = getchar();
while (tr >= '0' && tr <= '9')
x = x * 10 + tr - '0', tr = getchar();
return x;
}
#define _ (int)1e4 + 7
int n, m, cnt, tr[_][27], dp[250][_], fail[_];
bool tag[_];
char str[_];
void insert(char *str)
{
int now = 0;
int len = strlen(str);
for (int i = 0; i < len; ++i)
{
int p = str[i] - 'A';
if (!tr[now][p])
tr[now][p] = ++cnt;
now = tr[now][p];
}
tag[now] = 1;
}
void get_fail()
{
queue<int> q;
for (int i = 0; i < 26; ++i)
if (tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = 0; i < 26; ++i)
if (tr[u][i])
{
fail[tr[u][i]] = tr[fail[u]][i];
tag[tr[u][i]] |= tag[fail[tr[u][i]]];
q.push(tr[u][i]);
}
else
tr[u][i] = tr[fail[u]][i];
}
}
int qpow(int a, int b)
{
int ans = 1;
while (b)
{
if (b & 1)
{
ans = ans * a % mod;
}
a = a * a % mod;
b /= 2;
}
return ans;
}
signed main()
{
n = read();
m = read();
for (int i = 1; i <= n; ++i)
scanf("%s", str), insert(str);
get_fail();
dp[0][0] = 1;
for (int i = 0; i < m; ++i)
for (int j = 0; j <= cnt; ++j)
for (int k = 0; k < 26; ++k)
if (!tag[tr[j][k]])
dp[i + 1][tr[j][k]] = (dp[i + 1][tr[j][k]] + dp[i][j]) % mod;
int ans = qpow(26, m);
for (int i = 0; i <= cnt; ++i)
ans = (ans - dp[m][i] + mod) % mod;
printf("%d\n", ans);
}
[POI2000]病毒
给出
n
n
n 个 01 串,求是否存在一个无限长的 01 串,使得这
n
n
n 个 01 串都不是这个无限长的 01 串的子串。
对于这个题只需要建好 AC 自动机,然后在 AC 自动机上找一个环
为什么?
来一波逆向思维。假设我们构造出了一个无限长的安全代码,再拿到 AC 自动机上匹配,会发生什么?
没错,当我们一位一位地匹配的时候,我们会发现,永远都不会跳到某个病毒代码段结尾的位置。
那我们的问题就变成了在 AC 自动机中寻找一个环,并且环上没有任何危险节点,并且还要注意,这个环能被根节点访问到。
#include <bits/stdc++.h>
#define _ 300010
using namespace std;
int n, tr[_][2], fail[_], cnt;
int tot, ind[_], head[_], to[_ << 1], nxt[_ << 1];
bool tag[_];
char s[_];
void insert(char *a)
{
int t = 0;
int len = strlen(a);
for (int i = 0; i < len; i++)
{
int ch = a[i] - '0';
if (!tr[t][ch])
tr[t][ch] = ++cnt;
t = tr[t][ch];
}
tag[t] = 1;
}
void get_fail()
{
queue<int> q;
for (int i = 0; i < 2; i++)
if (tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while (!q.empty())
{
int now = q.front();
q.pop();
tag[now] |= tag[fail[now]];
for (int i = 0; i < 2; i++)
if (tr[now][i])
{
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else
tr[now][i] = tr[fail[now]][i];
}
}
void add(int u, int v)
{
to[++tot] = v;
nxt[tot] = head[u];
head[u] = tot;
}
int vis[_], viss[_];
void dfs(int p)
{
if (tag[p])
return;
if (vis[p])
{
puts("TAK");
exit(0);
}
if (viss[p])
return;
vis[p] = viss[p] = 1;
dfs(tr[p][0]);
dfs(tr[p][1]);
vis[p] = 0;
}
signed main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
scanf("%s", s);
insert(s);
}
get_fail();
dfs(0);
puts("NIE");
return 0;
}
[HNOI2004]L语言
给定 n n n 个模式串 s s s 和 m m m 个主串 t t t,对于每一个 t t t,请求出其最长的前缀,满足该前缀是由若干模式串(可以多次使用)首尾拼接而成的。
1 ≤ n ≤ 20 , 1 ≤ m ≤ 50 , 1 ≤ ∣ s ∣ ≤ 10 , 1 ≤ ∣ t ∣ ≤ 1 0 6 1 \leq n \leq 20,1 \leq m \leq 50,1 \leq |s| \leq 10,1 \leq |t| \leq 10^6 1≤n≤20,1≤m≤50,1≤∣s∣≤10,1≤∣t∣≤106 。
比较简单,用 v i s vis vis 数组记录是否存在合法前缀,一步一步递推就行了。
下面是 A C C O D E AC \ CODE AC CODE
#include <bits/stdc++.h>
using namespace std;
const int N = 2e6 + 5;
int n, m, tot, tr[N][26], cnt[N], fail[N];
char str[N];
bool b[N];
void insert(char *str)
{
int p = 0, l = strlen(str);
for (int i = 0; i < l; i++)
{
int t = str[i] - 'a';
if (!tr[p][t])
tr[p][t] = ++tot;
p = tr[p][t];
}
cnt[p] = l;
}
void get_fail()
{
queue<int> q;
for (int i = 0; i < 26; i++)
{
if (tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
}
while (!q.empty())
{
int t = q.front();
q.pop();
for (int i = 0; i < 26; i++)
{
int p = tr[t][i];
if (!p)
tr[t][i] = tr[fail[t]][i];
else
{
fail[p] = tr[fail[t]][i];
q.push(p);
}
}
}
}
signed main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
{
scanf("%s", str);
insert(str);
}
get_fail();
while (m--)
{
int ans = 0;
scanf("%s", str + 1);
int l = strlen(str + 1);
memset(b, 0, sizeof(b));
b[0] = 1;
for (int i = 1, j = 0; i <= l; i++)
{
int t = str[i] - 'a';
j = tr[j][t];
int p = j;
while (p)
{
if (b[i - cnt[p]])
{
b[i] = 1;
ans = max(ans, i);
break;
}
p = fail[p];
}
}
printf("%d\n", ans);
}
return 0;
}
[USACO12JAN]Video Game G
有 n n n 个串, s 1 , s 2 , … s n s_1,s_2,\dots s_n s1,s2,…sn。
试构造一个长度为 k k k( k k k 是给定的)的串 x x x,使得对于 ∀ 1 ≤ i ≤ n , s i \forall 1 \leq i \leq n,s_i ∀1≤i≤n,si 在 x x x 中的出现次数之和最大。
输出这个最大值。
串只包含 A,B,C 三个字符。
考虑对
s
i
s_i
si 建 AC 自动机。
然后 dp。
记
d
p
[
i
]
[
u
]
dp[i][u]
dp[i][u] 表示为长度为
i
i
i 的字符串,且当前已计算的节点是 Trie 上的编号为
u
u
u 的节点的最大得分。
记
t
a
g
[
k
]
tag[k]
tag[k] 表示在 Trie 以点
k
k
k 为结尾的字符串的个数。
然后将 t a g tag tag 下传。
则转移方程为:
for (int i = 0; i < m; ++i)
for (int j = 0; j <= cnt; ++j)
for (int k = 0; k < 3; ++k)
dp[i + 1][tr[j][k]] = max(dp[i + 1][tr[j][k]], dp[i][j] + tag[tr[j][k]]);
注意我这里是以
0
0
0 为 Trie 的根节点。
m m m 是读入的 k k k。
c
n
t
cnt
cnt 是 Trie 上的节点个数。
答案为:
for (int i = 0; i <= cnt; ++i)
ans = max(ans, dp[m][i]);
下面是 A C C O D E AC \ CODE AC CODE
#include <bits/stdc++.h>
using namespace std;
#define int long long
inline int read()
{
char tr = getchar();
int x = 0;
while (tr < '0' || tr > '9')
tr = getchar();
while (tr >= '0' && tr <= '9')
x = x * 10 + tr - '0', tr = getchar();
return x;
}
#define _ (int)1e5 + 7
int n, m, cnt, tr[_][3], dp[2000][500], fail[_];
int tag[_];
char str[_];
void insert(char *str)
{
int now = 0;
int len = strlen(str);
for (int i = 0; i < len; ++i)
{
int p = str[i] - 'A';
if (!tr[now][p])
tr[now][p] = ++cnt;
now = tr[now][p];
}
tag[now]++;
}
void get_fail()
{
queue<int> q;
for (int i = 0; i < 3; ++i)
if (tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = 0; i < 3; ++i)
if (tr[u][i])
{
fail[tr[u][i]] = tr[fail[u]][i];
q.push(tr[u][i]);
}
else
tr[u][i] = tr[fail[u]][i];
tag[u] += tag[fail[u]];
}
}
signed main()
{
n = read();
m = read();
for (int i = 1; i <= n; ++i)
{
scanf("%s", str);
insert(str);
}
get_fail();
int ans = 0;
for(int i = 0; i < m; ++i)
for(int j = 1; j <= cnt; ++j) dp[i][j] = INT_MIN;
for (int i = 0; i < m; ++i)
for (int j = 0; j <= cnt; ++j)
for (int k = 0; k < 3; ++k)
dp[i + 1][tr[j][k]] = max(dp[i + 1][tr[j][k]], dp[i][j] + tag[tr[j][k]]);
for (int i = 0; i <= cnt; ++i)
ans = max(ans, dp[m][i]);
printf("%lld\n", ans);
}
/*
20 1000
CACAACCCCBACA
ACCACAACC
ACAABCACACCACA
A
CCACAACCCCBACA
BCACACCACAAC
CBACAABCACACCA
CCACAACCCC
CACCACAACCCCBA
AABCACACCA
CCCCBACAAB
ACCACAACCCCBA
ACCACAACCCCBAC
C
CAACCCCBACAA
ACAACCCCBACAAB
CCACAACC
ACAABCACACCACAA
CCACAACCCCBACAA
ACAACCCCBACAABC
*/
[SCOI2012]喵星球上的点名
比较恶心的一道题。
有 N N N 只喵,每只喵有一个名和一个姓(两个字符串)。
还有 M M M 次点名(也是一个字符串),如果一只喵的名或姓中包含这个字符串,这只喵就会喊“到”。
有两问 :
-
对于每次点名询问有多少只喵喊“到”。
-
对于每一只喵问询她喊了多少次“到”。
字符集 ∣ Σ ∣ ≤ 1 0 4 |\Sigma| \le 10^4 ∣Σ∣≤104, 总字符串长不超过 2 × 1 0 5 2 \times 10^5 2×105。
先可以把一只喵的名和姓合并在一起,中间插入一个不存在的字符,这样就不需要考虑两个串了,类似于 Manacher 的预处理。
询问是类似于字符串 x x x 在字符串 y y y 中是否出现过。
考虑 AC 自动机
fail
\text{fail}
fail 树的性质,
fail
\text{fail}
fail 指针指向的是最长相同后缀。
如果字符串
A
A
A 是字符串
B
B
B 的后缀, 那么在 AC 自动机上面,从
B
B
B 开始跳
fail
\text{fail}
fail 树,一定可以跳到
A
A
A。
也就是说, B B B 在 A A A 的子树内, A A A 是 B B B 的祖先。(在 fail \text{fail} fail 树上)
判断 A A A 是否在 B B B 中出现过,就可以对于 B B B 的每一个前缀(子串一定是一个前缀的后缀),在 fail \text{fail} fail 树上暴力往上跳进行修改或者查询即可。
但是暴力跳 fail \text{fail} fail 复杂度可能不太对,但是好像也可以通过此题,这里给出一个复杂度为 O ( n log n ) \mathcal{O}(n \log n) O(nlogn) 的做法。
第一问
对于一个名字串的每一个前缀(总前缀个数不超过字符串总长),覆盖它到根的路径(覆盖表示加多次算一次)。
对每一个名字串都这么做,看点名串总共被多少个名字串给覆盖。
树上链修改,单点查询的问题先转化成树上单点修改,子树查询的问题。
由于覆盖多次算只算一次,就要把覆盖多的部分减掉。
对名字串的前缀按 dfs \text{dfs} dfs 序排序,减掉的部分就是每相邻节点的 lca \text{lca} lca。
这样就可以做覆盖多次算一次了。
第二问
对于一个名字串的所有一个前缀,看它们总共覆盖了多少点名串。
树上单点修改,链查询的问题先转化串树上子树修改, 单点查询的问题。
同样利用上面的方法,减掉 dfs \text{dfs} dfs 序相邻节点 lca \text{lca} lca 的贡献即可。
下面是 A C C O D E AC \ CODE AC CODE
#include <bits/stdc++.h>
using namespace std;
const int _ = 2e5 + 5;
int n, m;
int last;
int endd[_], enddd[_];
inline int read()
{
int x = 0;
char ch = getchar();
while (!isdigit(ch))
ch = getchar();
while (isdigit(ch))
x = x * 10 + ch - '0', ch = getchar();
return x;
}
vector<int> g[_ << 1];
int cnt_node, dep[_], dfn[_], top[_], fa[_], hson[_], siz[_];
void dfs1(int u, int d = 1)
{
dep[u] = d;
siz[u] = 1;
for (auto v : g[u])
{
if (dep[v])
continue;
fa[v] = u;
dfs1(v, d + 1);
siz[u] += siz[v];
if (!hson[u] || siz[v] > siz[hson[u]])
hson[u] = v;
}
}
void dfs2(int u, int topf)
{
top[u] = topf;
dfn[u] = ++cnt_node;
if (hson[u])
dfs2(hson[u], topf);
for (auto v : g[u])
{
if (v != fa[u] && v != hson[u])
dfs2(v, v);
}
}
int cnt;
struct
{
int fa, fail;
map<int, int> to;
} tr[_ << 1];
void insert(int x)
{
int &v = tr[last].to[x];
if (!v)
v = ++cnt, tr[v].fa = last;
last = v;
}
int getfail(int u, int c)
{
if (tr[u].to.count(c))
return tr[u].to[c];
else if (!u)
return u;
return tr[u].to[c] = getfail(tr[u].fail, c);
}
void Getfail()
{
queue<int> q;
for (auto i : tr[0].to)
q.push(i.second);
while (!q.empty())
{
int now = q.front();
q.pop();
for (auto i : tr[now].to)
{
tr[i.second].fail = getfail(tr[now].fail, i.first);
q.push(i.second);
}
}
for (int i = 1; i <= cnt; ++i)
g[tr[i].fail].push_back(i);
}
int c[_];
void clearr()
{
memset(c, 0, sizeof c);
}
int lowbit(int x)
{
return x & -x;
}
void update(int x, int w)
{
for (int i = x; i <= cnt + 1; i += lowbit(i))
c[i] += w;
}
int query(int x)
{
int ans = 0;
for (int i = x; i; i -= lowbit(i))
ans += c[i];
return ans;
}
void Update(int x, int y, int val)
{
update(x, val);
update(y + 1, -val);
}
int Query(int x, int y)
{
return query(y) - query(x - 1);
}
int LCA(int x, int y)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
x = fa[top[x]];
}
return dep[x] < dep[y] ? x : y;
}
bool cmp(int x, int y)
{
return dfn[x] < dfn[y];
}
int a[_];
void solve1()
{
clearr();
for (int i = 1; i <= n; ++i)
{
int opt = endd[i];
int ret = 0;
while (opt)
{
a[++ret] = opt;
update(dfn[opt], 1);
opt = tr[opt].fa;
}
sort(a + 1, a + ret + 1, cmp);
for (int j = 1; j < ret; ++j)
update(dfn[LCA(a[j], a[j + 1])], -1);
}
for (int i = 1; i <= m; ++i)
{
int opt = enddd[i];
printf("%d\n", Query(dfn[opt], dfn[opt] + siz[opt] - 1));
}
}
void solve2()
{
clearr();
for (int i = 1; i <= m; ++i)
{
int opt = enddd[i];
Update(dfn[opt], dfn[opt] + siz[opt] - 1, 1);
}
for (int i = 1; i <= n; ++i)
{
int opt = endd[i];
int ret = 0, res = 0;
while (opt)
{
a[++ret] = opt;
res += query(dfn[opt]);
opt = tr[opt].fa;
}
sort(a + 1, a + ret + 1, cmp);
for (int j = 1; j < ret; ++j)
res -= query(dfn[LCA(a[j], a[j + 1])]);
printf("%d%c", res, " \n"[i == n]);
}
}
signed main()
{
n = read();
m = read();
for (int i = 1; i <= n; ++i)
{
last = 0;
int len = read();
for (int j = 1; j <= len; ++j)
{
int x = read();
insert(x);
}
insert(-1);
len = read();
for (int j = 1; j <= len; ++j)
{
int x = read();
insert(x);
}
endd[i] = last;
}
for (int i = 1; i <= m; ++i)
{
last = 0;
int len = read();
for (int j = 1; j <= len; ++j)
{
int x = read();
insert(x);
}
enddd[i] = last;
}
Getfail();
dfs1(0);
dfs2(0, 0);
solve1();
solve2();
return 0;
}
[BJOI2017]魔法咒语
个人认为是最恶心的一道题了。
有 n n n 个基本单词 a 1 , a 2 , … a n a_1,a_2,\dots a_n a1,a2,…an 和 m m m 个禁忌单词 z 1 , z 2 , … z m z_1,z_2,\dots z_m z1,z2,…zm。
现在可以将基本单词组合起来,只有组合成的字符串没有出现禁忌单词,就认为这个组合是合法的。
注意:一个基本词汇可以出现零次、一次或多次;只要组成方式不同就认为是不同的禁咒法术,即使书写形式相同。
试着求出有多少种长度为 L L L 的合法组合。
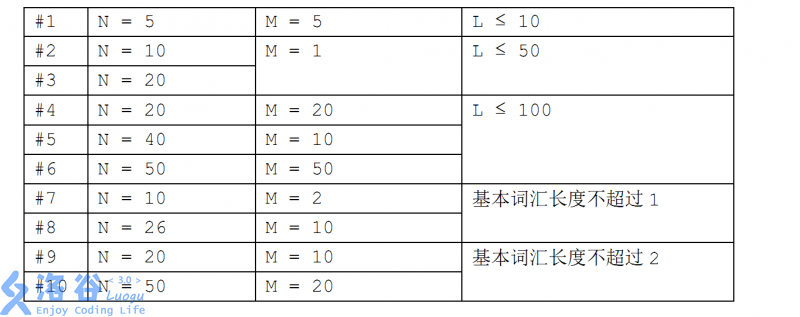
对于
100
%
100\%
100% 的数据,
1
≤
N
,
M
≤
50
,
1
≤
L
≤
1
0
8
1 ≤ N, M ≤ 50,1 ≤ L ≤ 10^8
1≤N,M≤50,1≤L≤108,基本词汇的长度之和不超过
100
100
100,忌讳词语的长度之和不超过
100
100
100。保证基本词汇不重复,忌讳词语不重复。
注意数据范围,本题其实是两道题合起来。
一道是前 60 p t s 60pts 60pts, L L L 比较小。
用计数 DP,上面其实已经讲过了。
一道是后面的 40 p t s 40pts 40pts, L L L 比较大,但基本单词长度比较小,很容易想到用矩阵快速幂。
详细部分自行去看题解吧。
下面是 A C C O D E AC \ CODE AC CODE。
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int mod = 1e9 + 7;
const int _ = 2e3 + 7;
int n, m, l;
int Len[_];
int cnt, tr[_][27], fail[_], tag[_];
char str[_], s[205][_];
int M;
int dp[205][_];
struct juzhen
{
int a[205][205];
juzhen()
{
memset(a, 0, sizeof a);
}
};
juzhen operator*(const juzhen &a, const juzhen &b)
{
juzhen c;
for (int k = 0; k <= M; ++k)
{
for (int i = 0; i <= M; ++i)
{
for (int j = 0; j <= M; ++j)
{
c.a[i][j] = (c.a[i][j] + a.a[i][k] * b.a[k][j]) % mod;
}
}
}
return c;
}
void qpow(juzhen &ans, juzhen &a, int b)
{
while (b)
{
if (b & 1)
{
ans = ans * a;
}
a = a * a;
b >>= 1;
}
}
void insert(char *s)
{
int p = 0;
for (int i = 1, len = strlen(s + 1); i <= len; ++i)
{
int v = s[i] - 'a';
if (!tr[p][v])
tr[p][v] = ++cnt;
p = tr[p][v];
}
tag[p] = 1;
}
void getfail()
{
queue<int> q;
for (int i = 0; i < 26; ++i)
{
if (tr[0][i])
{
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
}
while (!q.empty())
{
int now = q.front();
q.pop();
for (int i = 0; i < 26; ++i)
{
if (tr[now][i])
{
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else
{
tr[now][i] = tr[fail[now]][i];
}
}
tag[now] |= tag[fail[now]];
}
}
int read()
{
int x = 0;
char c = getchar();
while (c < '0' || c > '9')
c = getchar();
while (c >= '0' && c <= '9')
{
x = x * 10 + c - '0';
c = getchar();
}
return x;
}
void write(int x)
{
if (x > 9)
{
write(x / 10);
}
putchar(x % 10 + '0');
}
int kkk(int id, int p)
{
for (int i = 1, len = Len[id]; i <= len; ++i)
{
int v = s[id][i] - 'a';
if (tag[p])
return -1;
p = tr[p][v];
}
if (tag[p])
return -1;
return p;
}
signed main()
{
cin >> n >> m >> l;
for (int i = 1; i <= n; ++i)
{
scanf("%s", s[i] + 1);
Len[i] = strlen(s[i] + 1);
}
for (int i = 1; i <= m; ++i)
{
scanf("%s", str + 1);
insert(str);
}
getfail();
if (l <= 100)
{
dp[0][0] = 1;
for (int i = 0; i < l; ++i)
{
for (int j = 0; j <= cnt; ++j)
{
for (int k = 1; k <= n; ++k)
{
if (Len[k] + i > l)
continue;
int p = kkk(k, j);
if (p != -1)
{
dp[i + Len[k]][p] = (dp[i + Len[k]][p] + dp[i][j]) % mod;
}
}
}
}
int ans = 0;
for (int i = 0; i <= cnt; ++i)
ans = ans + dp[l][i], ans %= mod;
write(ans % mod);
printf("\n");
}
else
{
juzhen a, ans;
M = 2 * cnt + 1;
for (int i = 0; i <= cnt; ++i)
{
if (tag[i])
continue;
for (int j = 1; j <= n; ++j)
{
if (Len[j] == 1)
{
int v = tr[i][s[j][1] - 'a'];
if (tag[v])
continue;
a.a[v + cnt + 1][i + cnt + 1]++;
}
else if (Len[j] == 2)
{
int v = tr[i][s[j][1] - 'a'];
int vv = tr[v][s[j][2] - 'a'];
if (tag[v] || tag[vv])
continue;
a.a[vv + cnt + 1][i]++;
}
}
}
for (int i = cnt + 1; i <= M; ++i)
a.a[i - cnt - 1][i]++;
for (int i = 0; i <= M; ++i)
ans.a[i][i] = 1;
qpow(ans, a, l);
int Ans = 0;
for (int i = cnt + 1; i <= M; ++i)
Ans = (Ans + ans.a[i][cnt + 1]) % mod;
write(Ans);
printf("\n");
}
return 0;
}















 2381
2381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









