







这在前面其实是跳过了的,那时候觉得这部分内容太难所以没有学习,但是现在稍微可以看懂了一点,而且沟槽的大计基居然要学这个知识点,所以做个整理。
为什么小数不能准确存储
这其实是一个题外话,应该放在存储那篇来讲,但是那篇没有讲,所以在这里做一个补充。
这要涉及到进制转换的规则,例如将二进制数转换为十进制:
n
u
m
=
∑
i
=
1
n
b
i
⋅
2
i
−
1
num = \sum_{i=1}^{n}{b_i}·2^{i-1}
num=i=1∑nbi⋅2i−1
这里的num就是得到的十进制数,而
b
i
{b_i}
bi是二进制数的第
i
{i}
i位,
2
i
−
1
{2^{i-1}}
2i−1则是第
i
{i}
i位的权重。将这一位上的数与这一位的权重相乘,再求和,就可以得到十进制数字。将那个
2
{2}
2换成其他数字,比如说
8
{8}
8,就可以达成八进制数与十进制数的转换。
在整数部分这种转换进行得很好,很明显每一个十进制整数都可以与一个二进制整数一一对应,它们可以相互转换。但是在小数部分,这件事就不一样了:
| 位 | …… | 3 | 2 | 1 | 0 | -1 | -2 | …… |
|---|---|---|---|---|---|---|---|---|
| 权重 | …… | 4 | 2 | 1 | 0.5 | 0.25 | 0.125 | …… |
这里的“0”指小数点右边第一位。
可以看到小数部分的权重很明显是不能表示所有的小数的。这就是小数不能准确表示的本质。
浮点数与定点数
C语言使用定点数格式来存储整形数据,包括int、short、long等等,而float和double类型的小数则使用浮点数格式来存储。
“浮点”“定点”中的“点”指的是小数点,“浮点”就是小数点是可以动的,用类似于科学计数法的方法来移动小数点;而定点就是小数点不能动,整数部分和小数部分分开存储。
在这一点上需要区分一下概念:浮点数不是小数,浮点数与定点数都是数据存储的方式,而非一种数据类型,其实小数可以用定点的方式存储,整数也可以用浮点的方式存储。
定点数
定点数是最符合直觉的方式;它用固定的位数来分别存储整数部分和小数部分,例如如果我们用4个字节来存储一个定点数,其中2个字节是整数部分,2个字节是小数部分,随后将要存储的小数转化为二进制,对应的部分放进去即可。

整数部分不足的位,在前面补0;小数部分不足的位,在后面补0.转化的时候,中间加一个小数点,就是所存储的数字。
精度
整数部分一定精确。小数部分除了最后一位可能不精确之外,其他位都是精确的。也就是说,精度在31位~32位。
范围
所有的位都置为1,此时数值最大,为:
n
u
m
=
∑
i
=
−
15
16
1
⋅
2
i
−
1
=
2
−
16
(
1
−
2
32
)
1
−
2
=
2
16
−
2
−
16
num = \sum_{i=-15}^{16}{1}·2^{i-1}=\frac{2^{-16}(1-2^{32})}{1-2}=2^{16} - 2^{-16}
num=i=−15∑161⋅2i−1=1−22−16(1−232)=216−2−16
这个数字接近
2
16
2^{16}
216,也就是65536.而最小可以表示的数除了0之外就是
2
−
16
2^{-16}
2−16。
总结
定点数的优点是精度高,因为所有的位都用来存储数字;缺点是取值范围小,不能表示很大或者很小的数字,有些有效位不多的数字却非常小,用定点数只能望洋兴叹,比如: 9 × 1 0 − 28 9\times10^{-28} 9×10−28这样的数字,就不能再用定点数表示了。可是它明明有效数字很小啊,所以有了浮点数这种方法。
浮点数
这也是C语言标准规定的小数的存储方式。本质上说,浮点数就是用了科学计数法:
n
u
m
=
(
−
1
)
s
i
g
n
×
m
a
n
t
i
s
s
a
×
b
a
s
e
e
x
p
o
n
e
n
t
num=(-1)^{sign}\times mantissa\times base ^{exponent}
num=(−1)sign×mantissa×baseexponent
其中:
- n u m num num是要表示的小数
- s i g n sign sign是这个数字的符号(这点在定点数那里好像没有提及,但是也可以加上,是不影响前面的讨论的)
- b a s e base base是基数,或者说进制。
- e x p o n e n t exponent exponent是指数,一般就用十进制表示,指的是小数点的移动。
- m a n t i s s a mantissa mantissa是尾数,或者说精度,是base进制的小数,并且 1 ≤ m a n t i s s a < b a s e 1\leq mantissa \lt base 1≤mantissa<base,在十进制下的科学计数法里,这个关系是: 1 ≤ m a n t i s s a < 10 1\leq mantissa \lt 10 1≤mantissa<10,这样一比较就可以理解了。这个式子等价于表示说 m a n t i s s a mantissa mantissa在这个进制下小数点前面只能有一位。
例如,转换19.625这个数字:
[ 19.625 ] 10 = [ 10011.101 ] 2 = 1.0011101 × 2 4 [19.625]_{10}=[10011.101]_{2}=1.0011101\times 2^{4} [19.625]10=[10011.101]2=1.0011101×24
存储
接下来我们将这个数存储到内存中。其中,
b
a
s
e
base
base是不用存储的,需要存储的只有
s
i
g
n
sign
sign、
m
a
n
t
i
s
s
a
mantissa
mantissa和
e
x
p
o
n
e
n
t
exponent
exponent。
对于19.625而言,
s
i
g
n
=
0
sign=0
sign=0,
m
a
n
t
i
s
s
a
=
1.0011101
mantissa = 1.0011101
mantissa=1.0011101,
e
x
p
o
n
e
n
t
=
4
exponent = 4
exponent=4
- s i g n sign sign的存储:只需要一个位就可以了。
- m a n t i s s a mantissa mantissa的存储:通过前面的讨论,其实在二进制下, 1 ≤ m a n t i s s a < 2 1\leq mantissa \lt 2 1≤mantissa<2,也就是说mantissa的整数部分一定是1,那么我们只需要存储其小数部分就可以了。不妨将其小数部分设为 m a n t mant mant,即 m a n t i s s a = 1. m a n t mantissa = 1.mant mantissa=1.mant留待后面讨论。
- e x p o n e n t exponent exponent的存储:指数是一个整形,并且是有正负号的,那么是否需要像前面所说的用补码等方法来存储它呢?其实这就是这整个方案中最为重要的部分,在后面再作讨论
内存分配
了解了需要存储的都是什么之后就可以开始分配内存了。C语言中float与double的内存模式如图:

符号直接放,尾数就按照前面所讨论的那样放入
m
a
n
t
mant
mant就可以了。
至于指数的存储方法,虽然是一个有符号的整数,但是没有采用前面的补码的方式(因为没有必要,太过麻烦),所以存储思路变成了“范围移动”。在float中,指数部分有8位,理论上可以表示0-255的值,在这里面没有负数,那如果我指定其范围为-127-128呢?这样没有溢出,与补码的方法不同,这样我只要在存储时将指数加上127,读取时在取出之后再减去127就可以了。这里的127我们称其为中间值,其计算公式为:
m
e
d
i
a
n
=
2
n
−
1
−
1
median=2^{n-1}-1
median=2n−1−1
对于float而言,其中间值就是127,而double是1023.我们再设内存中存储的指数是
e
x
p
exp
exp,则其关系为:
e
x
p
o
n
e
n
t
=
e
x
p
−
m
e
d
i
a
n
exponent = exp - median
exponent=exp−median
e
x
p
=
e
x
p
o
n
e
n
t
+
m
e
d
i
a
n
exp = exponent + median
exp=exponent+median
精度
float 和 double 的尾数部分是有限的,固然不能容纳无限的二进制;即使小数能够转换成有限的二进制,也有可能会超出尾数部分的长度,此时也不能容纳。这样就必须“四舍五入”,将多余的二进制“处理掉”,只保留有效长度的二进制,这就涉及到了精度的问题。 也就是说,浮点数不一定能保存真实的小数,很有可能保存的是一个近似值。
总之,float的精度在二进制下是23-24位,十进制下是7-8位。double的精度在二进制下是52-53位,十进制下是15-16位。
IEEE 754 标准
这就是C语言的编译器所采用的浮点数标准。在这个标准中还有一些其他的特性。
特殊值
标准规定,当 e x p exp exp的所有位都是1时,这个浮点数不再是一个正常的浮点数,它将会用来表示特殊值。
- 如果 m a n t mant mant的所有位都是0,表示无穷大,正负与 s i g n sign sign相关;
- 如果 m a n t mant mant不是所有位都是0,表示NaN(Not a Number)
非规格化浮点数
当
e
x
p
exp
exp的所有位都是0时:
转换公式由原来的:
m
a
n
t
i
s
s
a
=
1.
m
a
n
t
mantissa = 1.mant
mantissa=1.mant
e
x
p
o
n
e
n
t
=
e
x
p
−
m
e
d
i
a
n
exponent = exp - median
exponent=exp−median
变成了:
m
a
n
t
i
s
s
a
=
0.
m
a
n
t
mantissa = 0.mant
mantissa=0.mant
e
x
p
o
n
e
n
t
=
1
−
m
e
d
i
a
n
exponent = 1 - median
exponent=1−median
可以看到
e
x
p
o
n
e
n
t
exponent
exponent变成了恒定的值,float为-126,double为-1022.同时尾数前面的数也不再是1了,而是0.
在非规格化浮点数中,当尾数
m
a
n
t
mant
mant的所有二进制位都为0时,整个浮点数的值就是0.这时候如果
s
i
g
n
sign
sign是1,就是-0,反之为+0.
为什么要有非规格化浮点数
以float为例,对于规格化浮点数,最小的取值(这里指绝对值的取值,说成分辨率或许更好)是当
m
a
n
t
mant
mant都是0、
e
x
p
exp
exp的最低位为1时,取值为
1.0
×
2
−
126
1.0\times 2^{-126}
1.0×2−126。
而对于非规格化浮点数,由于尾数前面的整数部分不再是1,它的最小取值会更小,这时的最小取值
m
a
n
t
mant
mant的最低位为1,整个最小取值再减小了
2
−
23
2^{-23}
2−23,达到了
2
−
149
2^{-149}
2−149,这个值会更加接近0.
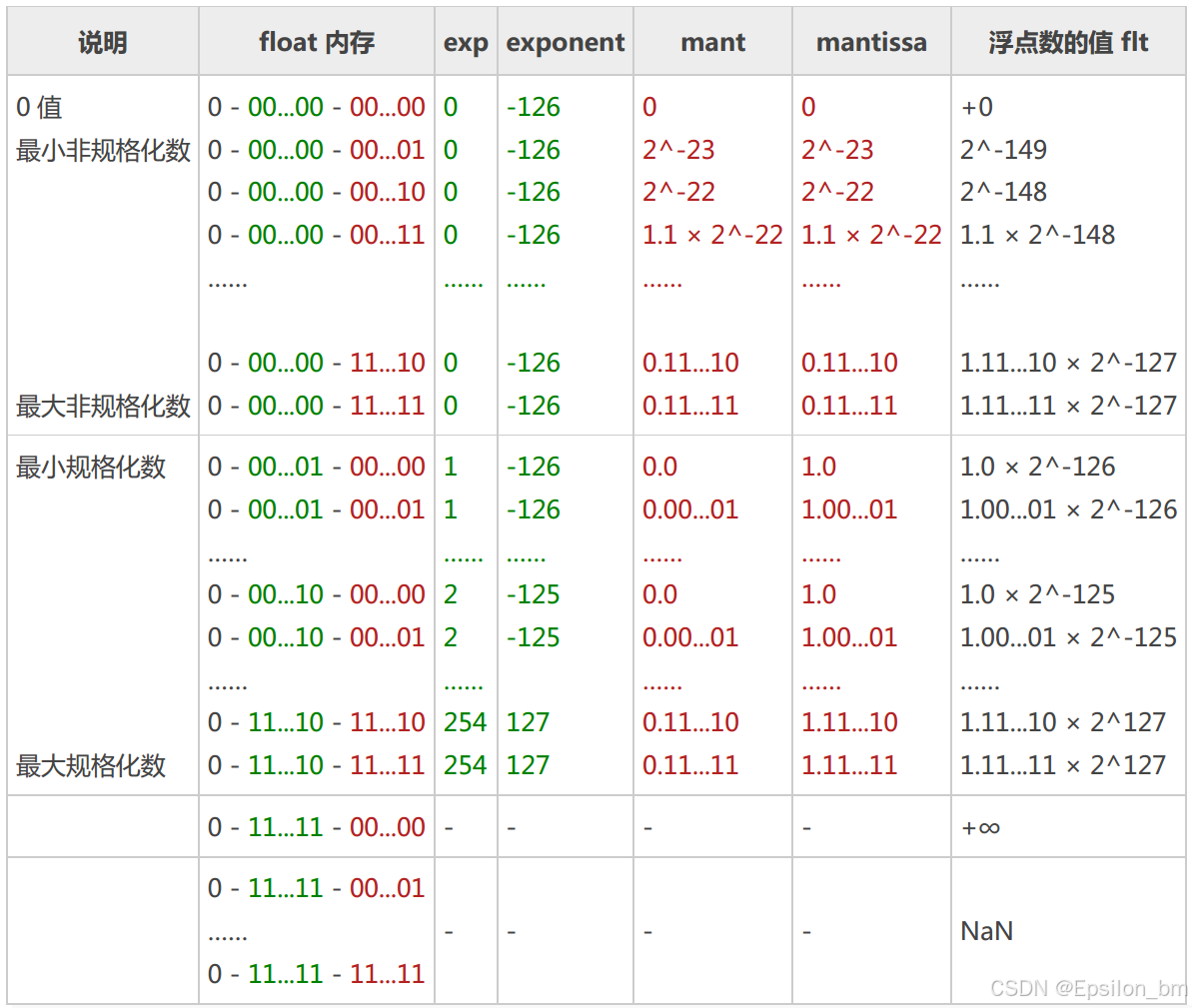
整个数值过渡的过程如上表。
舍入模式
舍入模式的运用在于尾数的舍去。
总共有四种舍入模式:
- 最近舍入:将结果舍入为最为接近且可以表示的值。当有两个最为接近的值的时候,取其中的偶数。
- 向上舍入:将结果舍入为最为接近的、比原值大且可以表示的值。(即ceil())
- 向下舍入:将结果舍入为最为接近的、比原值小且可以表示的值。(即floor())
- 截断舍入:直接舍去多余的部分。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









