







Mysql的DQL操作
- DQL(Data Query Language):数据查询语言,对数据中的数据进行查询【读】
一、单表查询
统计查询SELECT基础
-- 单表语句
SELECT 1 FROM 2 WHERE 3 GROUP BY 4 HAVING 5 ORDER BY 6 LIMIT 7
位置解释
| 位置 | 关键词 | 功能 |
|---|---|---|
| 1 | select | 对数据列的筛选,决定了结果中的列的样式 |
| 2 | from | 决定了数据来源 |
| 3 | where | 对数据行的筛选,一般用于分组前的行的过滤 |
| 4 | group by | 按照……分组…… |
| 5 | having | 对数据行的筛选,一般用于分组后的行的过滤 |
| 6 | order by | 按照……排序…… |
| 7 | limit | 分页查询,根据行号来筛选数据 |
统计查询WHERE子句
- 功能:对数据表中的数据行进行筛选,过滤出需要的数据
-- 语法
SELECT 1 FROM 2 WHERE 条件1 [ and/or 条件2 ……]
多条件:where 后面可以跟多个条件,多个条件可以通过 and 或者 or来连接
- and 表示并列:两个条件都成立就保留
- or 表示或者:满足其中一个条件就保留
- not 表示非:不满足这个条件就保留
条件表达式
-
比较运算符
= : 等于 > : 大于 >= : 大于等于 < : 小于 <= : 小于等于 != : 不等于 <> : 不等于 -
范围查询
BETWEEN A AND B 表示在一个A到B的范围内查询 -
模糊匹配:LIKE: 功能是做字符串的模糊匹配,一般会在where中搭配使用
- like中的 % 表示任意内容的多个字符,_ 表示任意内容的单个字符,匹配可以理解为从左往右匹配
- like性能较差,一般不建议使用
统计分析的需求:分组聚合
规则:分组必聚合,分组聚合后每一组最后只能产生一条结果
常用聚合函数
| 函数 | 语法 | 功能 | 场景 |
|---|---|---|---|
| count | count(列名) 或者 count(1) 或者 count(*) | 用于对表中的某一列的每一组统计行数,注意null不参与count的统计 | 计数 |
| sum | sum(列名) | 用于对表中的某一列的每一组统计求和,注意数值类型才有意义 | 求和 |
| max | max(列名) | 用于对表中的某一列的每一组计算最大值 | 最大 |
| min | min(列名) | 用于对表中的某一列的每一组计算最小值 | 最小 |
| avg | avg(列名) | 用于对表中的某一列的每一组计算平均值,注意数值类型才有意义 | 平均 |
GROUP BY 分组的功能与应用
- 用于对指定的单个或者多个字段进行分组,字段值相同的即为一组,一般会搭配聚合函数使用,实现分组聚合
-- 语法
-- select 1 from 2 [ where 3 ] group by 4 [ having 5 order by 6 limit 7 ]
group by col1, col2 ……
-
场景:在分析需求中出现了以下关键字搭配时候,就可以考虑分组聚合
-- 关键词:每、每个、每种、各个、不同、所有 -- 分组字段:关键词后面的列就是分组字段 -
注意:分组语句中select后面的写法,只能有三种情况
- 分组字段
- 函数结果:聚合函数
- 常量
HAVING的功能与应用
- 用于实现对分组聚合后的结果进行行的过滤
-- 语法
-- select 1 from 2 [ where 3 ] group by 4 having 5 [ order by 6 limit 7 ]
having 条件
注意:
-
如果where和having都能实现相同的需求,优先使用where,原则:Predicate Push Down:谓词下推
-
如果过滤的字段分组聚合之前就有就使用where,如果字段是分组聚合以后才产生就使用having
ORDER BY排序的功能与应用
- 用于对指定的单个或者多个字段进行排序,可以对每个字段按照从左往右指定升序或者降序
-- 语法
-- select 1 from 2 [ where 3 group by 4 having 5 ] order by 6 [ limit 7 ]
order by col1 , col2 [asc | desc]
LIMIT的功能与应用
- 用于对select语句的结果根据需求查询固定行的数据
- 分页查询
-- 语法
-- select 1 from 2 [ where 3 group by 4 having 5 order by 6 ] limit 7
limit M, N :表示从第M条开始显示N条数据
M:表示从第几条开始,第一行为0,第二行为1,第N行为N-1,M默认为0
N:表示显示几条
一般用于分页查询或者搭配order by 实现TopN
保存SELECT语句的结果
方案一:create table …… as select ……
-
功能:用于将select语句的结果直接创建成一张不存在的新表,将结果保存到表中
-
分类:DDL
-
场景:结果表不存在
-- 例
-- 查询每种性别的平均年龄,并按照平均年龄降序排序,将结果保存到表中
CREATE TABLE IF NOT EXISTS db_test_bigdata01.tb_result02
AS
SELECT
gender,
avg(age) as avg_age
FROM tb_topn
GROUP BY gender
ORDER BY avg_age DESC;
方案二:insert into …… select ……
-
功能:用于将select语句的结果插入到一张已存在的表中,将结果保存到表中
-
分类:DML
-
场景:结果表已经存在了
-- 例
-- 创建结果表
CREATE TABLE IF NOT EXISTS db_test_bigdata01.tb_result03
(
`gender` varchar(1),
`avg_age` decimal(20,4)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
;
-- 写入结果表
INSERT INTO db_test_bigdata01.tb_result03
SELECT
gender,
avg(age) as avg_age
FROM tb_topn
GROUP BY gender
ORDER BY avg_age DESC;
二、多表查询:关联查询
内连接:inner join
-
功能:用于根据关联条件,保留**两边都存在**的数据
-
语法:INNER JOIN,其中 INNER 可以省略
SELECT * FROM A INNER JOIN B ON 条件;
- 场景:两边都有,结果就有,取两份数据的交集
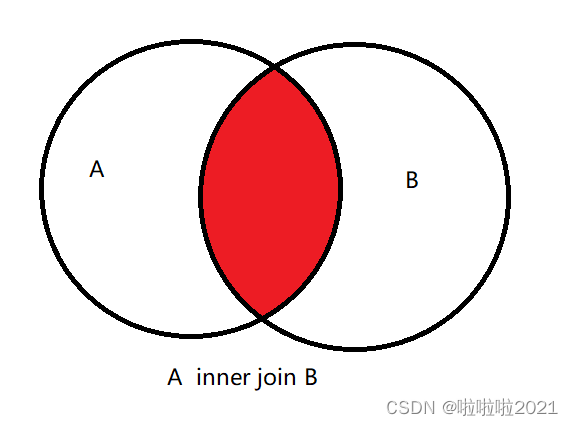
注意:在使用内连接时,可以省略 inner 关键词,关联条件也可以省略,如果省略了关联条件,就构建了**笛卡尔积**,我们把这种没有关联条件的join,叫做cross join,结果是两张表的无差别关联,数据有A * B 条,一般不建议使用
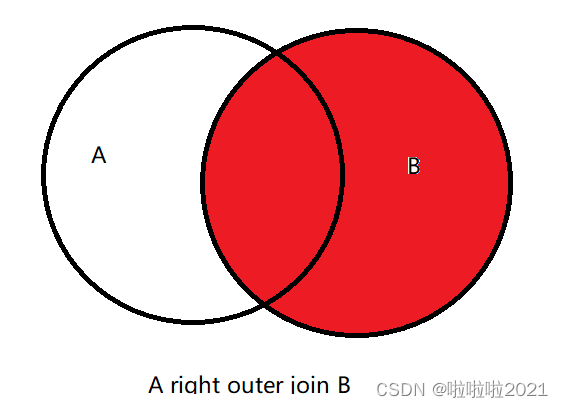
外连接
-
功能:用于根据关联条件,保留 左边的 或者 右边的 或者 全部的 数据
-
语法:outer关键词可以省略
SELECT * FROM A LEFT OUTER JOIN B ON 条件;
SELECT * FROM A RIGHT OUTER JOIN B ON 条件;
-
left outer join:左连接,保留左边所有的数据行,如果右边没有与之对应的行,则右边表的字段为null
-
right outer join:右连接,保留右边所有的数据行,如果左边没有与之对应的行,则左边表的字段为null
-
场景
- left join:左边有,结果就有,用于返回左表的所有数据并带上右表的列
- right join:右边有,结果就有,用于返回右表的所有数据并带上左表的列
-
注意:任意一边没有对应的值,就会为null

全连接与自连接
语法:FULL OUTER JOIN,mysql不支持,但是可以使用左连接和右连接的结果进行union得到
(SELECT * FROM A LEFT JOIN B ON 条件)
union
(SELECT * FROM A RIGHT JOIN B ON 条件)

自连接:自己与自己连接就叫做自连接,简单点理解A JOIN A
SELECT * FROM A m join A n ON 条件;
多表查询:UNION
-
功能:实现对两张数据表的行的合并
-
语法:
-- union:会去重 select …… union select …… -- union all:不会去重 select …… union all select …… -
注意:要求两份数据的字段个数必须一致
distinct的功能及使用
-
解决:distinct去重
-
功能:用于对表中的数据实现去重
-
语法
select distinct 字段 from 表
MySQL去重方式
- 方式一:group by col
- 方式二:union
- 方式三:distinct
- 方式四:窗口函数
多表查询:子查询
-
定义:如果一条SQL语句A内部包含了别的select语句B,我们称B这个查询语句为子查询,SQL A为主查询,A是一个带有子查询的语句
-
设计:为了提高代码开发效率,避免多次分步骤查询,可以直接在一条SQL语句中实现复杂的数据查询,提高代码复用性
-
分类:出现位置进行划分
- 条件子查询:查询的条件依赖于另外一个查询语句的结果,可以用于select、delete、update中
- 发生在过滤中:where、having
- 数据源子查询:查询的数据来自于另外一个查询语句的结果,主要用于select语句中
- 发生数据来源中:from
- 字段子查询:查询的字段来自于另外一个查询语句的结果,主要用于select语句中
- 结果作为字段:select
- 条件子查询:查询的条件依赖于另外一个查询语句的结果,可以用于select、delete、update中
条件子查询
-
功能:用于在一条SQL语句中,通过一个子查询来实现条件过滤
-
场景:一般用在where子句中, 支持select、update、delete,过滤条件依赖于一条select语句的结果
-
语法
select …… from where …… (select ……)
update …… where …… (select ……)
delete from …… where …… (select ……)
数据源子查询
-
功能:用于在一条SQL语句中,通过一个子查询来构造查询的数据内容
-
场景:一般用在select语句中,常用于继续对上一步的结果继续进行处理
-
语法
select …… from (select ……)
字段子查询
-
功能:用于select通过子查询生成一列的数据
-
场景:一般用在select后面,不常用
-
语法
select ……, (select …… ) as col from ……
子查询的CTE表达式
-
功能:可以将每一步SQL的结果临时构建一个表名,再继续下一步对上一步的表名进行处理
-
场景:一般用于数据源子查询中,MySQL8之后可用
-
语法
-- 单层
WITH tmp_tb_name AS (
SELECT ……
)
SELECT …… FROM tmp_tb_name
-- 多层
WITH tmp_tb_name1 AS (
SELECT ……
), tmp_tb_name2 AS (
SELECT …… FROM tmp_tb_name1
), tmp_tb_name3 AS (
SELECT …… FROM tmp_tb_name2
)
SELECT …… FROM tmp_tb_name3















 1874
1874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









