






【更新说明】项目代码已在2025年04月02日15点30进行更新,如有问题可评论或私信与我联系!
目录
项目介绍
项目使用ChromeDriver插件,基于Python的第三方库Selenium模拟浏览器运行、PyQuery解析和操作HTML文档,获取淘宝平台中某类商品的详细信息(商品标题、价格、销量、商铺名称、地区、商品详情页链接、商铺链接等),并基于第三方库openpyxl建立、存储于Excel表格中。
【说明】若允许代码出现翻译错误、代码能正常运行但是Excel没有数据等问题,可能是淘宝网页更新了父元素类选择器的缘故,大家可以参照教程检查一下元素是否更新;若网页元素更新,则可参照教程自行修改;【爬虫】教你如何获取淘宝网页父元素类选择器标签(超详细)-CSDN博客
效果预览:

代码部分
引用第三方库
# 代码说明:
'''
代码功能: 基于ChromeDriver爬取taobao(淘宝)平台商品列表数据
输入参数: KEYWORLD --> 搜索商品“关键词”;
pageStart --> 爬取起始页;
pageEnd --> 爬取终止页;
输出文件:爬取商品列表数据
'Page' :页码
'Num' :序号
'title' :商品标题
'Price' :商品价格
'Deal' :商品销量
'Location' :地理位置
'Shop' :商品
'IsPostFree' :是否包邮
'Title_URL' :商品详细页链接
'Shop_URL' :商铺链接
'Img_URL' :图片链接
'''
# 声明第三方库/头文件
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
import time
import openpyxl as op #导入Excel读写库
【第三方库】主要运用到PyQuery、selenium、openpyxl等Python的第三方库;如若缺失,使用pip指令安装即可。
pip install pyquery
pip install selenium
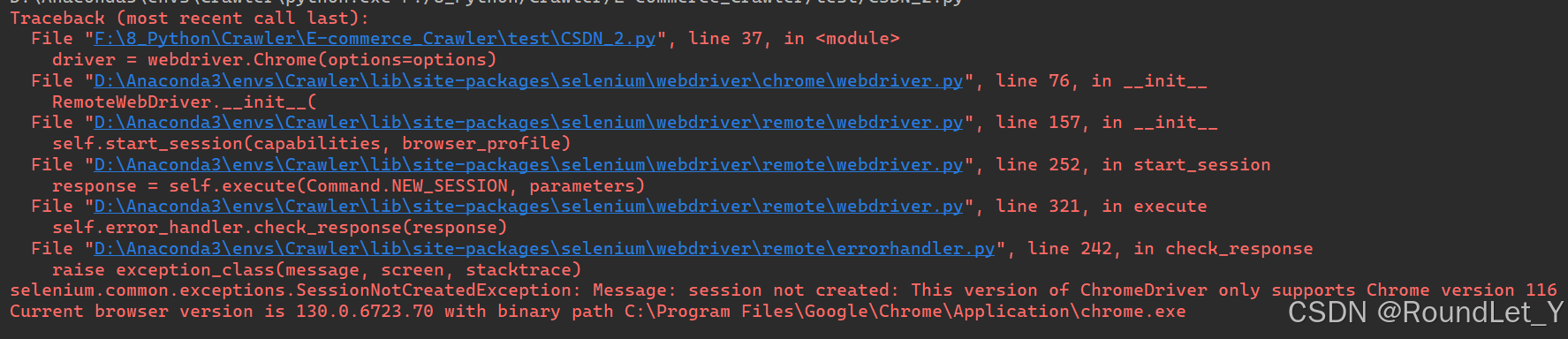
pip install openpyxl【ChromeDriver下载与安装】若运行过程中出现如下问题,可能是ChromeDriver版本与Chrome版本不一致导致,需要对ChromeDriver进行更新。ChromeDriver下载与安装:手把手教你,ChromeDriver下载与安装
全局定义
输入初始参数:
- 爬取商品的关键词KEYWORD
- 爬取网页的起始页pageStart
- 爬取网页的终止页pageEnd
# 全局变量
count = 1 # 写入Excel商品计数
KEYWORD = input('输入搜索的商品关键词Keyword:')# 要搜索的商品的关键词
pageStart = int(input('输入爬取的起始页PageStart:'))# 爬取起始页
pageEnd = int(input('输入爬取的终止页PageEnd:'))# 爬取终止页
# 启动ChromeDriver服务
options = webdriver.ChromeOptions()
# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式
options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 把chrome设为selenium驱动的浏览器代理;
driver = webdriver.Chrome(options=options)
# 反爬机制
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})
# 窗口最大化
driver.maximize_window()
driver.get('https://www.taobao.com')
# wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是20秒)。
# 如果一直到等待时间都没满足则会捕获TimeoutException异常
wait = WebDriverWait(driver,20)主函数
1、建立Excel表格,并设置第一行(表头);
2、调用爬虫主函数Crawer_main,启动爬虫程序;
3、输出.xlsx格式文件。
if __name__ == '__main__':
# 建立Excel表格
try:
ws = op.Workbook() # 创建Workbook
wb = ws.create_sheet(index=0) # 创建worsheet
# Excel第一行:表头
title_list = ['Num', 'title', 'Price', 'Deal', 'Location', 'Shop', 'IsPostFree', 'Title_URL',
'Shop_URL', 'Img_URL']
for i in range(0, len(title_list)):
wb.cell(row=count, column=i + 1, value=title_list[i])
count += 1 # 从第二行开始写爬取数据
except Exception as exc:
print("Excel建立失败!Error:{}".format(exc))
# 开始爬取数据
Crawer_main()
# 保存Excel表格
data = time.strftime('%Y%m%d-%H%M', time.localtime(time.time()))
Filename = "{}_{}_FromTB.xlsx".format(KEYWORD,data)
ws.save(filename = Filename)
print(Filename + "存储成功~")(输入)效果预览:

爬虫主函数代码
1、ChromeDriver服务请求淘宝(https://www.taobao.com)服务,模拟浏览器运行,找到“输入框”输入关键词KEYWORD,并点击“搜索”按键;
2、若弹出登录窗口,使用手机“淘宝”APP,扫码登录(如图所示);
【注意】抓紧时间完成登录,若出现error,则重新运行代码,尽快登录;超时可能出现error
3、判断PageStart是否为1;若PageStart不为1,跳转至PageStart所在页;
4、调用get_goods获取起始页PageStart的商品列表信息;
5、调用page_turning翻页进行翻页,并爬取第PageStart+1页到第PageEnd页商品信息。
# 爬虫main函数
def Crawer_main():
try:
# 搜索KEYWORD
search_goods()
# 判断pageStart是否为第1页
if pageStart != 1:
turn_pageStart()
# 爬取PageStart的商品信息
get_goods(pageStart)
# 从PageStart+1爬取到PageEnd
for i in range(pageStart + 1, pageEnd+1):
page_turning(i)
get_goods(i)
except Exception as exc:
print("Crawer_main函数错误!Error:{}".format(exc))淘宝登录界面示意图:

搜索“关键词”
ChromeDriver服务请求淘宝(https://www.taobao.com)服务,模拟浏览器运行,找到“输入框”输入关键词KEYWORD,并点击“搜索”按键。
# 输入“关键词”,搜索
def search_goods():
try:
print("正在搜索: {}".format(KEYWORD))
# 找到搜索“输入框”
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
# 找到“搜索”按钮
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')))
# 输入框写入“关键词KeyWord”
input.send_keys(KEYWORD)
# 点击“搜索”按键
submit.click()
# 搜索商品后会再强制停止2秒,如有滑块请手动操作
time.sleep(2)
print("搜索完成!")
except Exception as exc:
print("search_goods函数错误!Error:{}".format(exc))翻页函数代码
1、翻页函数page_turning,搜索并点击“下一页”按键,判断页码是否相等;若页码相等获取该页商品列表信息;
2、翻页初始页函数turn_pageStart,找到页码输入框,输入初始页页码,点击“确认”按键跳转至初始页。
# 翻页函数
def page_turning(page_number):
try:
print("正在翻页: 第{}页".format(page_number))
# 强制等待2秒后翻页
time.sleep(2)
# 找到“下一页”的按钮
submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[2]')))
submit.click()
# 判断页数是否相等
wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[1]/em'), str(page_number)))
print("已翻至: 第{}页".format(page_number))
except Exception as exc:
print("page_turning函数错误!Error:{}".format(exc))
# 翻页至第pageStar页
def turn_pageStart():
try:
print("正在翻转:第{}页".format(pageStart))
# 滑动到页面底端
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 滑动到底部后停留3s
time.sleep(3)
# 找到输入“页面”的表单,输入“起始页”
pageInput = wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[3]/input')))
pageInput.send_keys(pageStart)
# 找到页面跳转的“确定”按钮,并且点击
admit = wait.until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[3]')))
admit.click()
print("已翻至:第{}页".format(pageStart))
except Exception as exc:
print("turn_pageStart函数错误!Error:{}".format(exc))
“下一页”按键示意图:

获取商品列表信息代码
1、滑动页面至页码选择界面(如图所示),待页面所有信息加载完成后,按下“Enter”开始爬取当前页内容;
2、pyquery请求HTML页面信息,并进行解析;
3、商品详细信息(商品标题、价格、销量、商铺名称、地区、详情页链接、商铺链接等)
4、将获取的信息写入字典和Excel表格中;
【更新说明_20250402】近日访问淘宝网页时发现在商品列表中出现了“大家都在搜”的一个窗口,导致原来代码出现了Error,不能完整爬取当前页面所有内容。现针对这个问题在获取商品数据前增加判断item是否为“大家都在搜”。
# 获取每一页的商品信息;
def get_goods(page):
try:
# 声明全局变量count
global count
# 刷新/滑动界面,使所有信息都加载完成后,手动输入数字"1",开始爬取
if input('确认界面加载完毕后,按下“Enter”开始爬取'):
pass
# 获取html网页
html = driver.page_source
doc = pq(html)
# 提取所有商品的共同父元素的类选择器
items = list(doc('div.content--CUnfXXxv > div > div').items())
# print(items)
for item in items:
if item.find('.title--RoseSo8H').text() == '大家都在搜':
pass
else:
# 定位商品标题
title = item.find('.title--qJ7Xg_90 span').text()
# 定位价格
# price_int = item.find('.priceInt--yqqZMJ5a').text()
# price_float = item.find('.priceFloat--XpixvyQ1').text()
# if price_int and price_float:
# # price = float(f"{price_int}{price_float}")
# # price = price_int+price_float
# else:
# price = 0
price = item.find('.innerPriceWrapper--aAJhHXD4').text()
price = float(price.replace('\n', '').replace('\r', ''))
# 定位交易量
deal = item.find('.realSales--XZJiepmt').text()
deal = deal.replace("万","0000") # “万”字替换为0000
deal = deal.split("人")[0] # 以“人”分隔
deal = deal.split("+")[0] # 以“+”分隔
# 定位所在地信息
location = item.find('.procity--wlcT2xH9 span').text()
# 定位店名
shop = item.find('.shopNameText--DmtlsDKm').text()
# 定位包邮的位置
postText = item.find('.subIconWrapper--Vl8zAdQn').text()
postText = "包邮" if "包邮" in postText else "/"
# 定位商品url
t_url = item.find('.doubleCardWrapperAdapt--mEcC7olq')
t_url = t_url.attr('href')
# t_url = item.attr('a.doubleCardWrapperAdapt--mEcC7olq href')
# 定位店名url
shop_url = item.find('.TextAndPic--grkZAtsC a')
shop_url = shop_url.attr('href')
# 定位商品图片url
img = item.find('.mainPicAdaptWrapper--V_ayd2hD img')
img_url = img.attr('src')
# 构建商品信息字典
product = {
'Page': page,
'Num': count-1,
'title': title,
'price': price,
'deal': int(deal),
'location': location,
'shop': shop,
'isPostFree': postText,
'url': t_url,
'shop_url': shop_url,
'img_url': img_url
}
print(product)
# 商品信息写入Excel表格中
wb.cell(row=count, column=1, value=count-1) # 序号
wb.cell(row=count, column=2, value=title) # 标题
wb.cell(row=count, column=3, value=price) # 价格
wb.cell(row=count, column=4, value=int(deal)) # 付款人数
wb.cell(row=count, column=5, value=location) # 地理位置
wb.cell(row=count, column=6, value=shop) # 店铺名称
wb.cell(row=count, column=7, value=postText) # 是否包邮
wb.cell(row=count, column=8, value=t_url) # 商品链接
wb.cell(row=count, column=9, value=shop_url) # 商铺链接
wb.cell(row=count, column=10, value=img_url) # 图片链接
count += 1 # 下一行
except Exception as exc:
print("get_goods函数错误!Error:{}".format(exc))淘宝界面页码选择界面示意图:
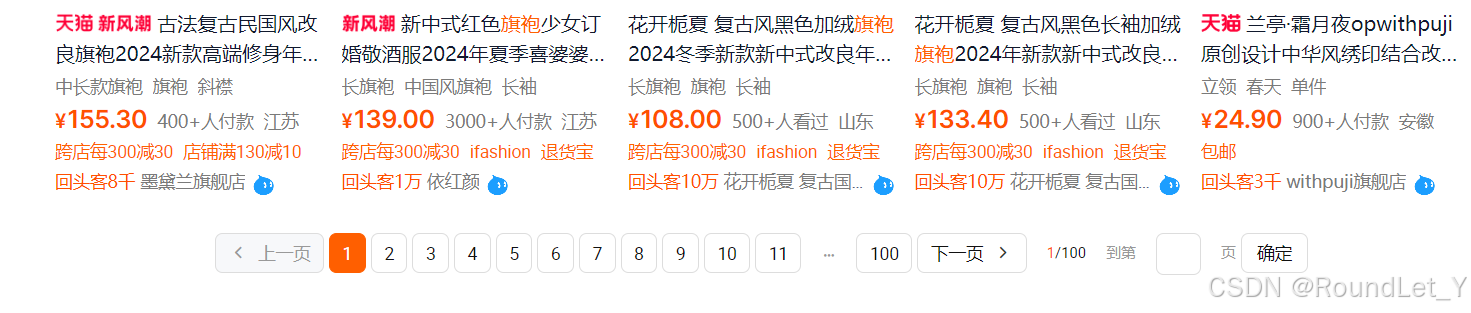
获取商品列表信息示意图:

完整代码
【使用说明】鉴于浏览器请求数据受到网络限制和网页可能出现需要滑动验证等不确定因素,故代码由“定时延时方式”改为“手动确认方式”以便留足时间等待数据请求;数据请求完成后,按下“Enter”开始爬取当前页商品详情(如下图所示)。
【小技巧】请求数据期间,可手动滑动淘宝界面,加载商品详情(注意:滑动到页面选择位置即可)为方便起见,亦可按住“Ctrl”按键滑动鼠标滚轮,使浏览器调整百分比至整个网页全部显示出来。

使用视频教程:
【爬虫】Python实现爬取淘宝商品信息(超详细)
# 代码说明:
'''
代码功能: 基于ChromeDriver爬取taobao(淘宝)平台商品列表数据
输入参数: KEYWORLD --> 搜索商品“关键词”;
pageStart --> 爬取起始页;
pageEnd --> 爬取终止页;
输出文件:爬取商品列表数据
'Page' :页码
'Num' :序号
'title' :商品标题
'Price' :商品价格
'Deal' :商品销量
'Location' :地理位置
'Shop' :商品
'IsPostFree' :是否包邮
'Title_URL' :商品详细页链接
'Shop_URL' :商铺链接
'Img_URL' :图片链接
'''
# 声明第三方库/头文件
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
import time
import openpyxl as op #导入Excel读写库
# 全局变量
count = 1 # 写入Excel商品计数
KEYWORD = input('输入搜索的商品关键词Keyword:')# 要搜索的商品的关键词
pageStart = int(input('输入爬取的起始页PageStart:'))# 爬取起始页
pageEnd = int(input('输入爬取的终止页PageEnd:'))# 爬取终止页
# 启动ChromeDriver服务
options = webdriver.ChromeOptions()
# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式
options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 把chrome设为selenium驱动的浏览器代理;
driver = webdriver.Chrome(options=options)
# 反爬机制
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})
# 窗口最大化
driver.maximize_window()
driver.get('https://www.taobao.com')
# wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是20秒)。
# 如果一直到等待时间都没满足则会捕获TimeoutException异常
wait = WebDriverWait(driver,20)
# 输入“关键词”,搜索
def search_goods():
try:
print("正在搜索: {}".format(KEYWORD))
# 找到搜索“输入框”
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
# 找到“搜索”按钮
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')))
# 输入框写入“关键词KeyWord”
input.send_keys(KEYWORD)
# 点击“搜索”按键
submit.click()
# 搜索商品后会再强制停止2秒,如有滑块请手动操作
time.sleep(2)
print("搜索完成!")
except Exception as exc:
print("search_goods函数错误!Error:{}".format(exc))
# 翻页至第pageStar页
def turn_pageStart():
try:
print("正在翻转:第{}页".format(pageStart))
# 滑动到页面底端
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 滑动到底部后停留3s
time.sleep(3)
# 找到输入“页面”的表单,输入“起始页”
pageInput = wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[3]/input')))
pageInput.send_keys(pageStart)
# 找到页面跳转的“确定”按钮,并且点击
admit = wait.until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[3]')))
admit.click()
print("已翻至:第{}页".format(pageStart))
except Exception as exc:
print("turn_pageStart函数错误!Error:{}".format(exc))
# 获取每一页的商品信息;
def get_goods(page):
try:
# 声明全局变量count
global count
# 刷新/滑动界面,使所有信息都加载完成后,按下Enter,开始爬取
if input('确认界面加载完毕后,按下“Enter”开始爬取'):
pass
# 获取html网页
html = driver.page_source
doc = pq(html)
# 提取所有商品的共同父元素的类选择器
items = list(doc('div.content--CUnfXXxv > div > div').items())
# print(items)
for item in items:
if item.find('.title--RoseSo8H').text() == '大家都在搜':
pass
else:
# 定位商品标题
title = item.find('.title--qJ7Xg_90 span').text()
# 定位价格
# price_int = item.find('.priceInt--yqqZMJ5a').text()
# price_float = item.find('.priceFloat--XpixvyQ1').text()
# if price_int and price_float:
# # price = float(f"{price_int}{price_float}")
# # price = price_int+price_float
# else:
# price = 0
price = item.find('.innerPriceWrapper--aAJhHXD4').text()
price = float(price.replace('\n', '').replace('\r', ''))
# 定位交易量
deal = item.find('.realSales--XZJiepmt').text()
deal = deal.replace("万","0000") # “万”字替换为0000
deal = deal.split("人")[0] # 以“人”分隔
deal = deal.split("+")[0] # 以“+”分隔
# 定位所在地信息
location = item.find('.procity--wlcT2xH9 span').text()
# 定位店名
shop = item.find('.shopNameText--DmtlsDKm').text()
# 定位包邮的位置
postText = item.find('.subIconWrapper--Vl8zAdQn').text()
postText = "包邮" if "包邮" in postText else "/"
# 定位商品url
t_url = item.find('.doubleCardWrapperAdapt--mEcC7olq')
t_url = t_url.attr('href')
# t_url = item.attr('a.doubleCardWrapperAdapt--mEcC7olq href')
# 定位店名url
shop_url = item.find('.TextAndPic--grkZAtsC a')
shop_url = shop_url.attr('href')
# 定位商品图片url
img = item.find('.mainPicAdaptWrapper--V_ayd2hD img')
img_url = img.attr('src')
# 构建商品信息字典
product = {
'Page': page,
'Num': count-1,
'title': title,
'price': price,
'deal': int(deal),
'location': location,
'shop': shop,
'isPostFree': postText,
'url': t_url,
'shop_url': shop_url,
'img_url': img_url
}
print(product)
# 商品信息写入Excel表格中
wb.cell(row=count, column=1, value=count-1) # 序号
wb.cell(row=count, column=2, value=title) # 标题
wb.cell(row=count, column=3, value=price) # 价格
wb.cell(row=count, column=4, value=int(deal)) # 付款人数
wb.cell(row=count, column=5, value=location) # 地理位置
wb.cell(row=count, column=6, value=shop) # 店铺名称
wb.cell(row=count, column=7, value=postText) # 是否包邮
wb.cell(row=count, column=8, value=t_url) # 商品链接
wb.cell(row=count, column=9, value=shop_url) # 商铺链接
wb.cell(row=count, column=10, value=img_url) # 图片链接
count += 1 # 下一行
except Exception as exc:
print("get_goods函数错误!Error:{}".format(exc))
# 翻页函数
def page_turning(page_number):
try:
print("正在翻页: 第{}页".format(page_number))
# 强制等待2秒后翻页
time.sleep(2)
# 找到“下一页”的按钮
submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[2]')))
submit.click()
# 判断页数是否相等
wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[1]/em'), str(page_number)))
print("已翻至: 第{}页".format(page_number))
except Exception as exc:
print("page_turning函数错误!Error:{}".format(exc))
# 爬虫main函数
def Crawer_main():
try:
# 搜索KEYWORD
search_goods()
# 判断pageStart是否为第1页
if pageStart != 1:
turn_pageStart()
# 爬取PageStart的商品信息
get_goods(pageStart)
# 从PageStart+1爬取到PageEnd
for i in range(pageStart + 1, pageEnd+1):
page_turning(i)
get_goods(i)
except Exception as exc:
print("Crawer_main函数错误!Error:{}".format(exc))
if __name__ == '__main__':
# 建立Excel表格
try:
ws = op.Workbook() # 创建Workbook
wb = ws.create_sheet(index=0) # 创建worsheet
# Excel第一行:表头
title_list = ['Num', 'title', 'Price', 'Deal', 'Location', 'Shop', 'IsPostFree', 'Title_URL',
'Shop_URL', 'Img_URL']
for i in range(0, len(title_list)):
wb.cell(row=count, column=i + 1, value=title_list[i])
count += 1 # 从第二行开始写爬取数据
except Exception as exc:
print("Excel建立失败!Error:{}".format(exc))
# 开始爬取数据
Crawer_main()
# 保存Excel表格
data = time.strftime('%Y%m%d-%H%M', time.localtime(time.time()))
Filename = "{}_{}_FromTB.xlsx".format(KEYWORD,data)
ws.save(filename = Filename)
print(Filename + "存储成功~")【不足】不足之处,恳请批评指正,我们共同进步!


















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









