







一、选择题
2-1 在定点二进制运算器中,减法运算一般通过()来实现。
A.原码运算的二进制减法器
B.补码运算的二进制加法器
C.原码运算的十进制加法器
D.补码运算的二进制减法器
2-2 假定用若干块2K x 4位的存储芯片组成一个16K x 8位的存储器,则地址 251FH 所在芯片的最大地址是( )
A.2BFFH
B.2FFFH
C.27FFH
D.25FFH
注释:
芯片的大小为 2K×4 位,而存储器的大小为 16K×8 位,得出要获得这样一个大小的存储器,需要 16 片 2K×4 位的芯片。
如果按字节编址,对应一个大小为 16K×8 位的存储器,需要14位地址,其中高 4 位为片选地址,低 11 位为片内地址,而题目给出的地址 251FH 转换为二进制为0010 0101 0001 1111 B,其高 4 位为1001,即片选地址为 9。
因此,地址 251FH 对应第 9 片芯片,该芯片的最大地址为 0010 0111 1111 1111 B,即27FFH。
2-3 为实现 Cache地址映射,需要将来自CPU的物理地址根据映射方式进行不同划分,下列描述中错误的是 ( )
A.全相联映射方式下,将地址划分为主存块地址和块内偏移地址两部分
B.直接相联映射方式下,根据Cache大小将地址划分为标记(Tag)、索引(Index)和块内偏移地址三部分。其中Index指向Cache特定行位置
C.组相联映射方式下,根据Cache 分组数大小将地址划分为标记(Tag)、索引(Index)和块内偏移地址三部分。其中Index指向Cache特定组位置
D.K路组相联是指CACHE被分成K组
注释:
K路组相联是指主存中的一块可以选择映射到Cache中K个位置
【Computer Organization笔记21】高速缓存 Cache :多路组相联的地址映射、一致性、缺失、MESI协议
2-4 冯诺依曼计算机中指令和数据均以二进制形式存放在存储器中,CPU依据( )来区分它们。
A.指令和数据的地址形式不同
B.指令和数据的寻址方式不同
C.指令和数据的表示形式不同
D.指令和数据的访问时间不同
注释:
冯诺依曼计算机是根据指令周期的不同阶段,来区分从内存中取出的是指令还是数据。
参考:
【计算机组成原理】CPU如何区分指令和数据
2-5 假定有 4 个整数用 8 位补码分别表示 r1=F2H, r2=FEH, r3=F8H, r4=F5H,若将运算结果存放在一个 8 位寄存器中,则下列运算中会发生溢出的是 ()。
A.r1×r2
B.r2×r3
C.r1×r4
D.r2×r4
注释:
r1 = F2H = -14,r2 = FEH = -2
r3 = F8H = -8,r4 = F5H = -11
8位寄存器可以表示的数据范围为 [ − 2 7 ∼ 2 7 − 1 ] [-2^{7} \sim 2^{7} - 1] [−27∼27−1] 即 [ − 128 ∼ 127 ] [-128 \sim 127] [−128∼127]
当 r1 x r4 = -14 x -11 = 154 超过寄存器所能表示的范围,则发生了溢出
2-6 某计算机的 Cache 共有 32 块,采用 8路组相联映射方式(即每组8块)。每个主存块大小为 32B,按字节编址。主存3312号单元所在主存块应装入到的 Cache 组号是___。
A.0
B.1
C.2
D.3
注释:
【知识点】 Cache和主存的映射方法
8路组相联映射,就是 8 个Cache为一组,组与组之间使用直接映射,组内采用全相联映射。
cache共有 32 块,则 cache组数 = 32 / 8 = 4组。第一组为0,即0~3组。
每个主存块大小是 32B,一个单元一字节,那么,3312号单元的位置 = 3312 / 32 = 103 余 16,即在主存的第103块上。
组相联映射关系公式 cache组号=主存块号 mod cache组数(主存块号除组数取余),代入即cache组号 = 103 mod 4 = 3。
参考:
【408】计算机组成原理-Cache组号的运算
2-7 下列选项中,指执行每条指令所需要的平均时钟周期数的是
A.MIPS
B.IPC
C.CPI
D.机器字长
注释:
MIPS : 单字长定点指令平均执行速度 Million Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数
IPC : Instructions Per Clock/Cycle的缩写,表示CPU每个时钟周期内执行的指令数
2-8 下图是某条指令的执行过程,请根据图中执行步骤,分析该指令最可能是( )
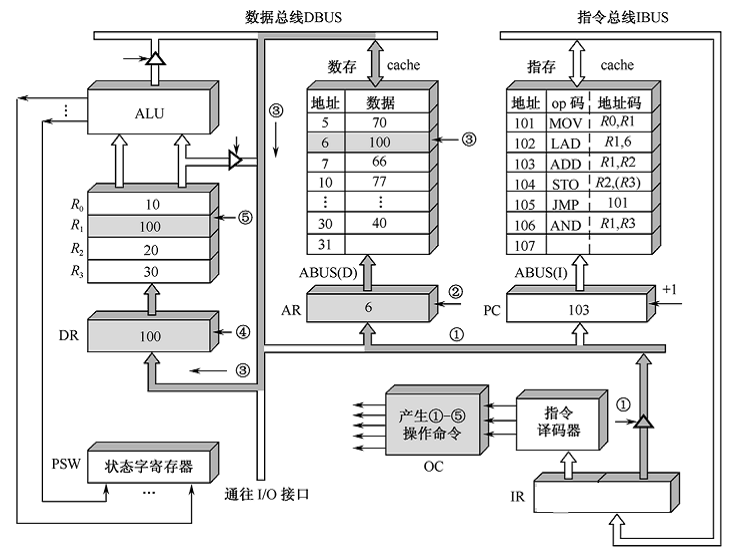
A.LAD
B.STO
C.MOV
D.ADD
E.JMP
2-9 一条跳转指令有 64 位,按字节编址。若该指令是无条件跳转指令,执行后会跳转到[PC的值-2]的程序地址。当取出这条指令但未被译码时,PC 的值自动加( )。
A.-2
B.0
C.1
D.8
注释:
如果按字节编址,PC 的值是自动加1个字长( 位数 / 8),即 64 / 8 = 8
如果按字编址,PC的值是自动加1
2-10 计算机内存按字节编址,内存地址为由低到高排列。设A=0x12345678,采用大端方式下,存放在地址0-3中,则地址3存放的内容为()。
A.0x12
B.0x34
C.0x56
D.0x78
二、多选题
3-1 设x为整数,x的真值为34,以下选项与x不相等的有()
A.补码二进制串为1,011110的数
B.反码二进制串为0,100010的数
C.原码二进制串为0,100010的数
D.反码二进制串为0,011101的数
E.补码二进制串为0,100010的数
F.移码二进制串为1,100010的数
注释:
34 = 0,100010 [原] = 0,100010 [反] = 0,100010 [补] = 0,100010 [移]
参考资料:
计算机组成原理之移码表示法
3-2 下列选项中,不能缩短程序执行时间的措施是
A.减少MIPS
B.增加CPI最大指令的比例
C.对程序进行编译优化
D.提高CPU时钟频率
三、填空题
4-1 (本题考查课程目标2)
某机字长16位,指令16位,定长指令;指令ADD (R1),R0的功能为(R0)+((R1))→(R1),即将R0中数据与R1内容所指向的主存单元的数据相加,并将结果送入R1内容所指向的主存单元中;数据通路图中控制信号为1表示有效,假设MAR输出一直处于使能状态。
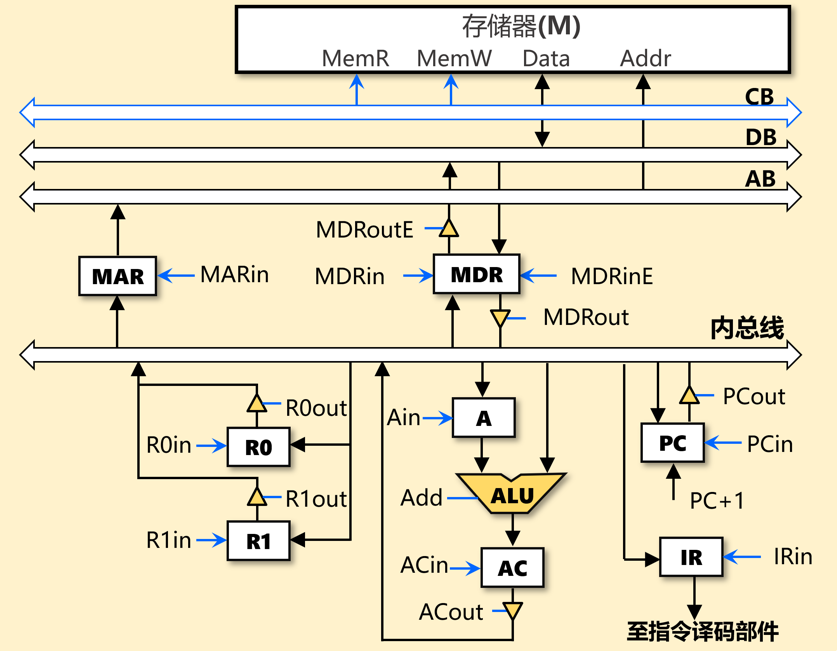
问题1【第0空】:取指令阶段(包括指令译码)共需要 4 个节拍(时钟周期)。
问题2【C1:第1空,C2:第2、3、4空,C3:第5、6空,C6:第7空,C7:第8、9、10空,C8:第11、12空,C9:第13空,C10:第14、15空】:请补全每个节拍(时钟周期)的功能及控制信号。
| 时钟 | 功能 | 有效控制信号 |
|---|---|---|
| C1 | MAR←(PC) | PCout, MARin |
| C2 | MDR←M( MAR ) | MemR , MDRinE ,PC+1 |
| C3 | IR ←(MDR) | MDRout, IRin |
| C4 | 指令译码 | 无 |
| C5 | MAR←(R1) | R1out,MARin |
| C6 | MDR ←M(MAR) | MemR, MDRinE |
| C7 | A← (MDR) | MDRout , Ain |
| C8 | AC←(R0)+ (A) | Add ,R0out,ACin |
| C9 | MDR ←(AC) | ACout,MDRin |
| C10 | M(MAR) ←(MDR) | MDRoutE, MemW |
注释:
题干已给出取值和译码阶段每个节拍的功能和有效控制信号,我们应以弄清楚取指阶段中数据通路的信息流动为突破口,读懂每个节拍的功能和有效控制信号,然后应用到解题思路中,包括划分执行步骤、确定完成的功能、需要的控制信号。
先分析题干中提供的示例(本部分解题时不做要求):
取指令的功能是根据PC的内容所指的主存地址,取出指令代码,经过MDR,最终送至IR。这部分和后面的指令执行阶段的取操作数、存运算结果的方法是相通的。
C 1 : ( P C ) → M A R C1: (PC) \rightarrow MAR C1:(PC)→MAR
在读写存储器前,必须先将地址(这里为(PC))送至 MAR。
C 2 : M ( M A R ) → M D R , ( P C ) + 1 → P C C2: M(MAR) \rightarrow MDR, (PC) + 1 \rightarrow PC C2:M(MAR)→MDR,(PC)+1→PC
读写的数据必须经过 MDR,指令取出后 PC 自增 1。
C 3 : ( M D R ) → I R C3: (MDR) \rightarrow IR C3:(MDR)→IR
然后将读到的MDR中的指令代码送至IR进行后续操作。
指令“ADD (Rl), R0”的操作数一个在主存中,一个在寄存器中,运算结果在主存中。根据指令功能,要读出R1的内容所指的主存单元,必须先将R1的内容送至MAR,即 ( R 1 ) → M A R (R1) \rightarrow MAR (R1)→MAR。而读出的数据必须经过 MDR,即 M ( M A R ) → M D R M(MAR) \rightarrow MDR M(MAR)→MDR。
因此,将 R1 的内容所指的主存单元的数据读出到MDR的节拍安排如下:
C 5 : ( R 1 ) → M A R C5: (R1) \rightarrow MAR C5:(R1)→MAR
C 6 : M ( M A R ) → M D R C6: M(MAR) \rightarrow MDR C6:M(MAR)→MDR
ALU 一端是寄存器A, MDR 或 R0 中必须有一个先写入 A 中,如 MDR。
C 7 : ( M D R ) → A C7: (MDR) \rightarrow A C7:(MDR)→A
然后执行加法操作,并将结果送入寄存器 AC。
C 8 : ( A ) + ( R 0 ) → A C C8: (A) + (R0) \rightarrow AC C8:(A)+(R0)→AC
之后将加法结果写回到 R1 的内容所指的主存单元,注意 MAR 中的内容没有改变。
C 9 : ( A C ) → M D R C9: (AC) \rightarrow MDR C9:(AC)→MDR
C 10 : ( M D R ) → M ( M A R ) C10: (MDR) \rightarrow M(MAR) C10:(MDR)→M(MAR)
有效控制信号的安排并不难,只需看数据是流入还是流出,如流入寄存器X就是Xin,流
出寄存器 X 就是 Xout。还需注意其他特殊控制信号,如 PC+1、Add 等。
4-2(本题考查课程目标2)
某计算机字长为16位,主存地址空间大小为8GB,按字编址。采用单字长指令格式,指令各字段定义如下图所示:

转移地址采用相对寻址方式,相对偏移量用补码表示。寻址方式如下表所示:
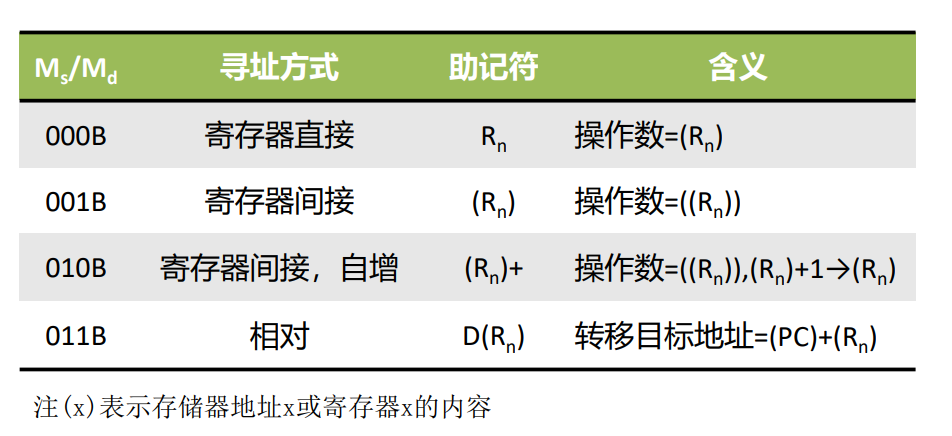
问题1【第0、1、2、3空】: 该指令系统最多可有 16 条指令,该计算机最多有 8 个通用寄存器,存储器地址寄存器MAR至少需要 32 位,存储器数据寄存器MDR至少需要 16 位。
问题2【第4空】: 转移指令的目标地址范围是 0x0000~0x FFFF 。(用十六进制表示,仅限填数字和大写字母,问题3也适用该限制规则)。
问题3【第5空】: 若操作码 1101B 表示加法操作,助记符为add,寄存器R4,R5的编号分别为 100B 和 101B,R4的内容为0x1234,R5的内容为0x5678,地址 0x1234 中的内容为 0x5678 ,地址 0x5678 中的内容为 0x1234 ,则汇编语句add (R4),(R5)+ 逗号前为源操作数,逗号后为目的操作数,对应的机器码是 0x D315 。
【第6、7、8、9空】该指令执行以后,寄存器 R5 和存储单元 0x 5678 号单元的内容会发生改变,改变后的内容分别为是 0x 5679 和 0x 68AC 。
注释:
1)操作码占 4 位,则该指令系统最多可有 2 4 = 2^4= 24=16条指令。操作数占6位,其中寻址方式占 3 位、寄存器编号占 3 位,因此该机最多有 2 3 = 2^3= 23=8个通用寄存器。主存地址空间大小为 8GB,按字编址,字长为16位,共有 8 G B / 2 B = 2 33 / 2 1 = 2 32 8GB/2B = 2^{33}/2^{1} = 2^{32} 8GB/2B=233/21=232 个存储单元,因此MAR至少为32位;因为字长为 16 位,故MDR至少为16位。
2)寄存器字长为 16 位,PC 和 Rn 可表示的地址范围均为 0 ~ 2 16 − 1 0~2^{16} -1 0~216−1,而主存地址空间为 2 16 2^{16} 216,故转移指令的目标地址范围为 0000H~FFFFH( 0 ~ 2 16 − 1 ) (0~2^{16} -1) (0~216−1)。
3)汇编语句“add (R4), (R5)+”,对应的机器码为
字段 OP Ms Rs Md Rd 内容 1101 001 100 010 101 说明 add 寄存器间接 R4 寄存器间接、自增 R5 将对应的机器码写成十六进制形式为1101 0011 0001 0101B=
D315H。
该指令的功能是将 R4 的内容所指存储单元的数据与 R5 的内容所指存储单元的数据相加,并将结果送入 R5 的内容所指存储单元中。(R4)=1234H,(1234H)=5678H;(R5)=5678H,(5678H) =1234H;执行加法操作 5678H+1234H=68ACH,之后 R5 自增。
该指令执行后,R5和存储单元5678H的内容会改变,R5的内容从 5678H 变为5679H,存储单元 5678H 中的内容变为该指令的计算结果68ACH。
参考链接:
题目来源于王道论坛
4-3(本题考查课程目标3)
》. 下载附件,认真阅读2022年《中国科学:信息科学》的综述文献 《计算体系架构研究综述与思考》 全文。本题提供了从知网下载的PDF版以及使用WPS直接转换后的WORD版(两者页码可能不一致)。
》. 考生需快速阅读文献,依据题目要求定位到相关段落,使用原文中的词汇进行填空,使得总结性文字大意与原文保持不变。【 填写限制: 每空只能从原文中提取词汇(包括字母的大小写)作为答案,最多4个汉字,或最多6个英文字符或者数字,不出现中英文混搭的情况】
【第0空】早期的自动化计算机为特定功能而设计,如电子计算机ABC用于解算复杂数学方程。1946年 ENIAC 的诞生开启了计算自动化革命。之后自动化计算和智能化计算取得几十年的发展,推动人类社会进步。
【第1空】 早在1945年,冯诺依曼与戈德斯坦等发表了著名的"101页报告",提出了冯诺依曼计算架构,属于通用电子计算机的设计模型。该架构将计算机分为存储器、算术逻辑单元、控制单元、输入设备和输出设备,并通过不同的 指令集 设计实现多功能和高灵活性。冯诺依曼架构的出现改变了早期计算机的固定功能限制,对后世产生了深远影响。
【第2空】冯诺依曼体系架构采用了数据与指令无差别存放的形式,并采用控制器和数据通路的协作实现了程序控制下的计算过程。随着体系架构的不断演进,之后出现了将数据与指令存储在不同空间的 哈佛 架构。
【第3空】 1959年,基尔比和诺伊斯在德州仪器公司发明了现代集成电路。现代集成电路推动了通用处理器计算性能的快速提升,同时专用集成电路(ASIC)崛起。与通用处理器相比,ASIC具有 控制向量 定制、高效计算和低功耗等优势,在多个领域广泛应用。
【第4空】近年来因计算数据爆炸增长、应用需求多样、便携设备广泛应用,而制程工艺发展放缓,人们开始探索新的发展方向。在通用计算与专用计算发展时期,中国研究团队率先提出了拟态计算的概念,并于 2013 年成功研制出世界首台拟态计算机。
【第5、6空】从宏观层面来看,不仅是计算重心发生了多个阶段的变化,就连计算机系统设计中心也大致经历了三个阶段。例如1971年, 由英特尔 (Intel) 公司 研发的世界上首款微处理器诞生, 运算器与控制器合二为一。在差距还不足够大的情况下, 人们会涉及增加片上 Cache 的大小、提高片外存储带宽等。但处理器性能提升仍然是研究的主要焦点,而存储器的设计目标是突破 容量 的最大值和成本的最小值,导致工业界也划分为了两个明显的阵营, 从设计方法、设计目标, 以及生产工艺等方面有着明显的差别。
【第7、8空】从计算驱动方式上看计算机体系结构,主要包括指令流驱动、数据流驱动、配置流与数据流共同驱动, 以及事件驱动。其中,指令流驱动中代表复杂指令集(CISC)面临多个问题。它可以减小高级语言和机器指令之间的语义差距,但需要增加硬件复杂度和多周期执行;微程序可以提高代码密度,但与超大规模集成电路中采用 硬布线 控制逻辑的现实不符;为了保持向后兼容性,复杂指令集保留了过时的定义,导致指令集冗余和应用开发门槛增加。为减少复杂指令集冗余臃肿、结构复杂等弊端问题, 研究者秉承简单设计哲学,提出精简指令集的概念,到目前为止它已经迭代发展了5代, 被称为“ RISC-V ”。
【第9、10空】 从计算核心构成形式看计算机体系架构, 现代计算机体系架构在计算核心构成方面有着显著的变革。一方面,采用借鉴数据流驱动计算思想的流处理模式拥有大量内核和 并行化 计算模式,尽管工作时钟频率较低。另一方面,充分利用各类异构处理器的优势,将适用的应用程序部署到相应的处理器上,以释放处理器的最大潜力,以追求系统的最佳性能,例如在 2020 年召开的计算机体系结构国际研讨会(ISCA)IBM POWER9 和 z15 芯片上集成了一块专门用于数据压缩的加速器 NXU, 能够将数据压缩速度, 进而提高芯片处理速度, 并且只占用很小的芯片面积。
【第11、12空】而上述无论是通用计算体系架构还是专用集成电路,无论采用指令流驱动还是数据流驱动计算方式,底层硬件逻辑架构都是固定不变的。计算过程中,指令流方式按顺序下发指令完成计算,而数据流方式按顺序处理数据完成计算。因为硬件逻辑结构固定,只能以应用适配。例如指令流驱动计算可以划分为五个步骤,即从最开始的取出指令到最后的 数据回写 阶段,计算效率较低。直到20世纪90年代,人们使用高灵活性的细粒度通用可重构器件和高效性的基于逻辑门的功能定义设备 FPGA ,作为主要计算部件设计面向应用的计算设备。随着它的应用日益广泛,缺点也逐渐显现出来,于是人们开始探索新的可重构计算技术途径, 粗粒度可重构计算架构 (CGRA) 逐步发展起来。
【第13、14空】当下随着信息革命时代的到来, 数据量呈爆炸式增长趋势, 针对不同应用任务, 各类算法层出不穷, 嵌入式设备、边缘终端与移动终端广泛应用, 对计算系统提出了更高的要求。从计算需求角度来看, 不论是 科学计算 技术还是人工智能技术, 待处理数据量均呈大幅增长趋势, 从数据中快速挖掘出感兴趣的信息难度越来越大。在未来,国内外研究人员提出面向特定应用领域的 软件定义 计算体系架构已经成为未来计算体系架构演进的重要方向,作者也为后续该类体系架构的研究与发展提出了一条可行的技术途径。
4-4 (本题考查课程目标2)
某16位计算机中,带符号整数用补码表示,数据Cache和指令Cache分离。下表给出了指令系统中部分指令格式,其中Rs和Rd表示寄存器,mem表示存储单元地址,(x)表示寄存器x或存储单元x的内容。

该计算机采用 5 段流水方式执行指令,各流水段分别是取指( IF )、译码 / 读寄存器( ID )、执行 / 计算有效地址( EX )、访问存储器( M )和结果写回寄存器( WB ),流水线采用“按序发射,按序完成”方式,没有采用转发技术处理数据相关,并且同一个寄存器的读和写操作不能在同一个时钟周期内进行。请回答下列问题:
问题1【第0、1空】: 若 int 型变量x的值为-260,存放在寄存器R1中,则寄存器R1中的值为0x FEFC(仅填阿拉伯数字和大写字母,下同);执行指令“ SHL R1 ” 后,R1的值为0x FDF8 。
问题2【第2空】:若某个时间段中,有连续的50条指令进入流水线,在其执行过程中没有发生任何阻塞,则执行这 50条指令需要 54 个时钟周期。
问题3【第3、4空】: 若高级语言程序中某赋值语句为 x=a+b , x 、 a 和 b 均为 int 型变量,它们的存储单元地址分别表示为 [x] 、 [a] 和 [b] 。该语句对应的指令序列及其在指令流水线中的执行过程如下图所示。
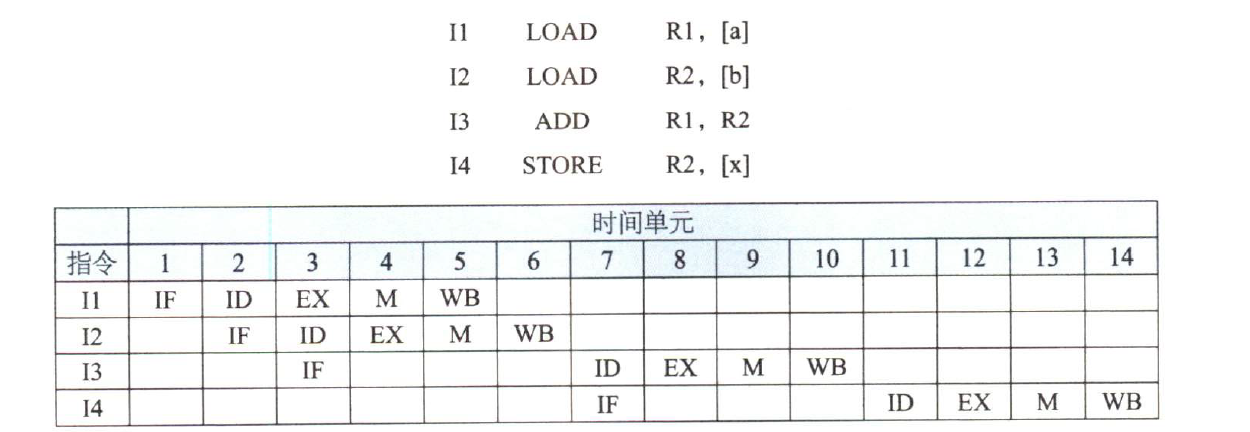
则这 4 条指令执行过程中, I3 的 ID 段被阻塞的原因是 数据 冲突,I4的IF段被阻塞的原因是 结构 冲突。
问题4【第5、6空】:若高级语言程序中某赋值语句为 x=x*2+a , x 和 a 均为 unsigned int 类型变量,它们的存储单元地址分别表示为 [x] 、 [a] ,并且同一个寄存器的读和写操作可以在同一个时钟周期内进行,则至少需要编译出 5 条汇编指令(限填阿拉伯数字),执行这条语句至少需要 14 个时钟周期。
注释:
1)x 的机器码为 [ x ] 补 = 1111 1110 1111 1100 B [x]_{补} = 1111 \; 1110 \; 1111 \; 1100B [x]补=1111111011111100B,即指令执行前(R1)=FEFCH,右移1位后为 1111 1101 1111 1000 B 1111 \; 1101 \; 1111 \; 1000B 1111110111111000B,即指令执行后(Rl)=FDF8。
2)每个时钟周期只能有一条指令进入流水线,从第5个时钟周期开始,每个时钟周期都会有一条指令执行完毕,因此至少需要 50 + 4 =54个时钟周期。
计算公式:n + 4 (n 为指令条数)
3) I 3 I_3 I3 的 I D ID ID 段被阻塞的原因∶因为 I 3 I_3 I3 与 I 1 I_1 I1 和 I 2 I_2 I2 都存在数据相关,需等到 I 1 I_1 I1 和 I 2 I_2 I2 将结果写回寄存器后, I 3 I_3 I3 才能读寄存器内容,所以 I 3 I_3 I3 的 I D ID ID 段被阻塞。 I 4 I_4 I4 的 I F IF IF 段被阻塞的原因:因为 I 4 I_4 I4 的前一条指令 I 3 I_3 I3 在 I D ID ID 段被阻塞,所以 I 4 I_4 I4 的 I F IF IF 段被阻塞。
注意∶要求"按序发射,按序完成",因此第 2 小问中下一条指令的 I F IF IF 必须和上一条指
令的 I D ID ID 并行,以免因上一条指令发生冲突而导致下一条指令先执行完。
4)因 2*x 操作有左移和加法两种实现方法,因此 x=x*2+a 对应的指令序列为
I1 LOAD R1,[x] I2 LOAD R2,[a] I3 SHL RI //或者 ADD R1,R1 I4 ADD R1,R2 I5 STORE R2,[x] 这5条指令在流水线中执行过程如下图所示。
时间单元 指令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 I1 IF ID EX M WB I2 IF ID EX M WB I3 IF ID EX M WB I4 IF ID EX M WB I5 IF ID EX M WB (注意:同一个寄存器的读和写操作可以在同一个时钟周期内进行,所以 ID 和 WB 可以同时进行)
因此执行 x = x*2 + a 语句最少需要
14个时钟周期。
四、程序填空题
5-1 利用C语言程序输出某些特定的数字
这是一道利用C语言程序输出某些特定的数字,以复习计算机组成原理中常见的概念。
(1)输出整数a的补码(十六进制,前缀带0x;若a的值为0则直接输出0);
(2)输出单精度浮点数对应的IEEE754标准编码十进制数;
(3)保留整数c第3位到第6位的结果,其他位全部置0,输出变换后的十进制数(设最低位为第1位);
(4)将整数c第3位到第6位全部置1,其他位全部保留,输出变换后的十进制数(设最低位为第1位);
(5)判断a乘以c的符号,如果是乘积为正则输出0;如果是乘积为负则输出1。
温馨提示:
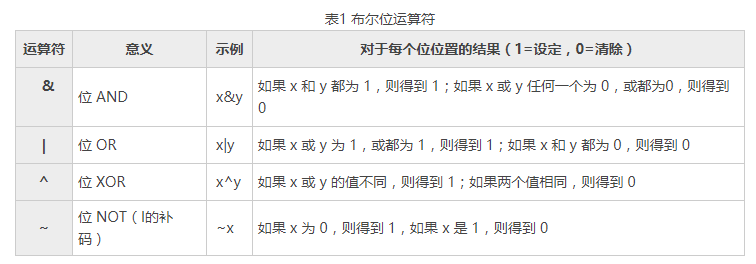
表2 移位运算符
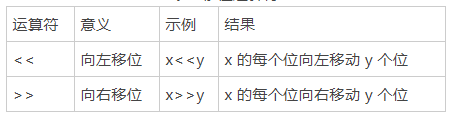

#include <stdio.h>
int main()
{
int a;
float b;
int c ;
while(~scanf("%d %f %x",&a,&b,&c))
{
printf("%#x\n",a);
printf("%d\n", *(int*)& b);
printf("%d\n", 0x3c& c);
printf("%d\n", 0x3c| c);
printf("%d\n",(a^c) >>31&0x1);
}
return 0;
}
输入样例
-1 11.375 0x8fa
输出样例
0xffffffff
1094057984
56
2302
1
五、编程题
7-1 求最小码距(简洁版)
计算机组成原理老师给小明出了一道求最小码距的题目,
有以下由1个字节组成的合法编码集{0xA9,0xC7,0xDF,0xBE},该编码集的最小码距是__
小明知道码距,也知道最小码距的概念。码距是指
信息编码中,两个合法编码对应位上编码不同的位数,比如10101和00110从第1位开始依次有第1位、第4、第5位不同,因此码距为3,任意组合的码距最小值称为最小码距。
小明想借助计算机帮忙自己算出答案,今后无论老师出何种组合,他都能一键运行答案,于是他开始了最小码距的代码编写。
输入格式:
1.第一行读入1个整数N(2≤N≤8),代表需要输入的编码个数。
2.第二行输入N个编码(用十六进制表示,编码位数≤8),中间用空格隔开。
输出格式:
1.首先根据用户输入编码的顺序依次进行比较,每一行两两编码间的码距
2.最后一行输出最小码距(十进制)
3.其他要求:输出所有编码时都需要加前缀0x,如0x0
输入样例:
在这里给出一组输入。例如:
4
0xa9 0xc7 0xdf 0xbe
6
0xa9 0xc7 0xdf 0xbe 0xbe 0x0
输出样例:
在这里给出相应的输出。例如:
0xa9 0xc7 CD:5
0xa9 0xdf CD:5
0xa9 0xbe CD:4
0xc7 0xdf CD:2
0xc7 0xbe CD:5
0xdf 0xbe CD:3
The MinCD is 2
0xa9 0xc7 CD:5
0xa9 0xdf CD:5
0xa9 0xbe CD:4
0xa9 0xbe CD:4
0xa9 0x0 CD:4
0xc7 0xdf CD:2
0xc7 0xbe CD:5
0xc7 0xbe CD:5
0xc7 0x0 CD:5
0xdf 0xbe CD:3
0xdf 0xbe CD:3
0xdf 0x0 CD:7
0xbe 0xbe CD:0
0xbe 0x0 CD:6
0xbe 0x0 CD:6
The MinCD is 0
代码长度限制 16 KB
时间限制 400 ms
内存限制 400 MB
参考代码一:
#include <stdio.h>
int main(void)
{
int n, num[10];
scanf("%d", &n);
for (int i = 0; i < n; ++i) {
scanf("%x", &num[i]);
}
int res = 1000;
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
int a = num[i];
int b = num[j];
int cnt = 0;
while (a != b) {
if ((a & 1) != (b & 1)) {
cnt += 1;
}
a >>= 1;
b >>= 1;
}
if (res > cnt) res = cnt;
printf("0x%x 0x%x CD:%d\n", num[i], num[j], cnt);
}
}
printf("The MinCD is %d\n", res);
}
参考代码二:
#include <stdio.h>
int main(void)
{
int n, num[10];
scanf("%d", &n);
for (int i = 0; i < n; ++i) {
scanf("%x", &num[i]);
}
int res = 100;
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
int x = num[i] ^ num[j];
int cnt = 0;
while (x > 0) {
++cnt;
x -= x & -x;
}
res = res > cnt ? cnt : res;
printf("0x%x 0x%x CD:%d\n", num[i], num[j], cnt);
}
}
printf("The MinCD is %d\n", res);
return 0;
}
















 9674
9674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











