







多层感知机
XOR问题(Minsky & Papert , 1969)

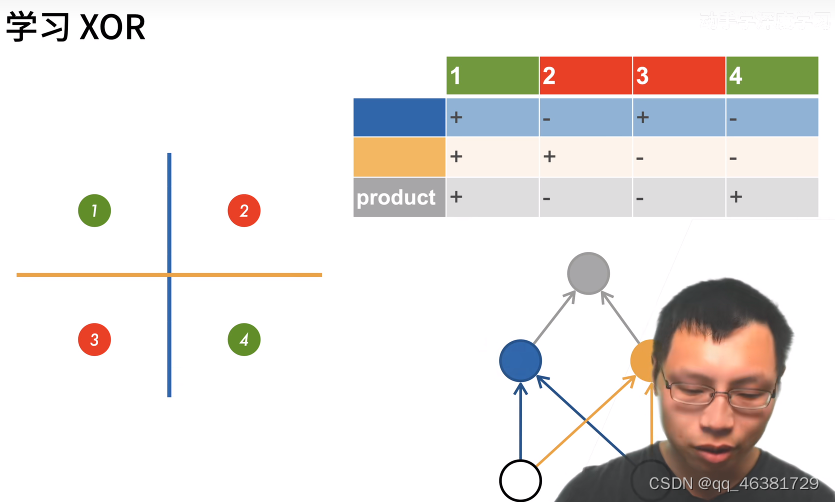
蓝色线表示左正右负,黄色线表示上正下负,然后用蓝黄两个分类器的分类结果做出综合评价,这就将多个小分类器叠加使得分类器从一层变为了多层。
单隐藏层

输入和输出由具体数据和分类树所觉得,而隐藏层的大小是一个超参,可以自行设定。
输⼊层不涉及任何计算,因此使⽤此⽹络产⽣输出只需要实现隐藏层和输出层的计算。因此,这个多层感知机中的层数为2。注意,这两个层都是全连接的。每个输⼊都会影响隐藏层中的每个神经元,⽽隐藏层中的每个神经元⼜会影响输出层中的每个神经元。
单隐藏层–单分类

- 输入是一个N维向量
- w1是一个m*n的矩阵,m个神经元,n维输入,每一个神经元都需要有n个权重去计算输入
- b1为偏移,是一个长为m的向量
- 隐藏层有m个神经元,那么对于输出层的输入就是长为m的向量
- b2就是一个标量,因为是单分类问题,所以控制输出的就只有一个神经元
为什么激活函数是非线性的?
如果说,激活函数是一个线性函数,那么计算结果仍然是线性的,那么这个激活函数无异于就是一个单层感知机。
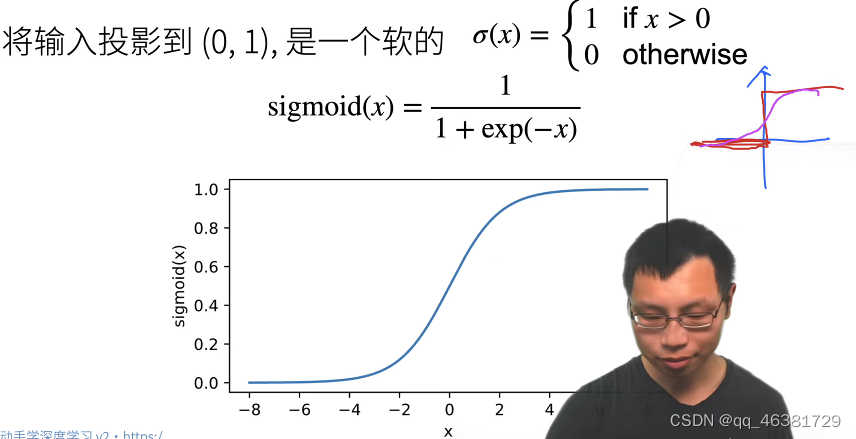
Sigmoid激活函数
Tanh激活函数

Tanh激活函数,相当于就是-1,1函数的soft平滑版本。
ReLU激活函数(常用)
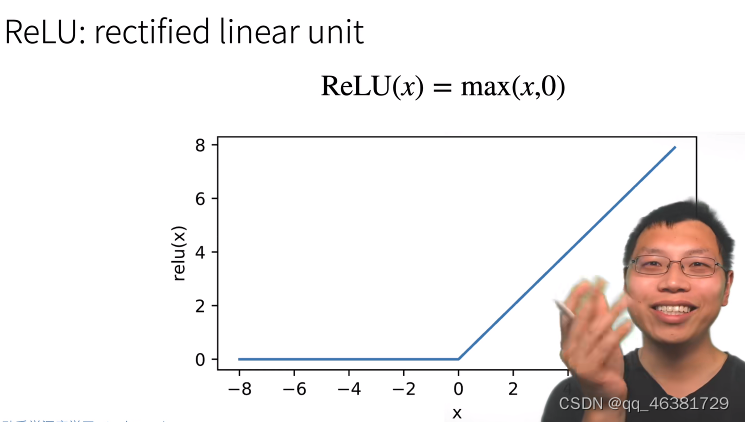
ReLu其实就是一个线性函数,把小于0的部分置为0,熟悉且简单。
多类分类
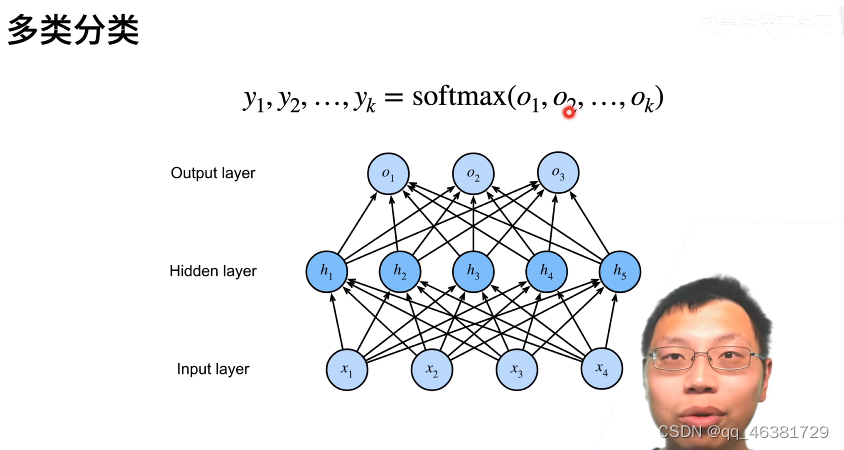
多类分类有多个输出神经元,对一个样本输出多个结果(即对每一类都计算结果),最后使用softmax将长为k的输出向量解释为属于每一类的概率。
如果没有这个隐藏层,那么就是一个softmax回归。
多类分类定义

- 输入依然是长为n的向量
- 隐藏层W1依然是m*n的矩阵,对于m个神经元,和长为n的输入向量,每个神经元都要对输入进行计算
- 输出层W2是m*k的矩阵,输出层接受长为n的向量的输入,输入长为k的向量
- 最后需要softmax对输出向量进行处理
多隐藏层
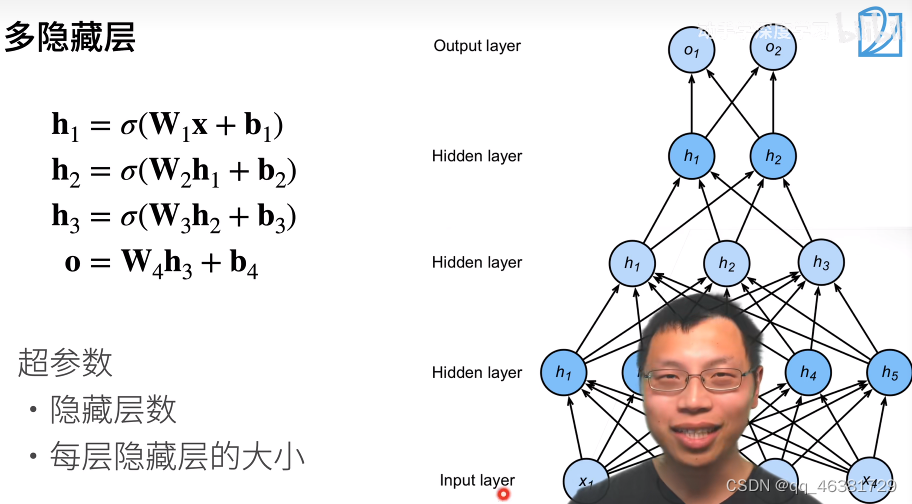
每一层都有自己的权重、偏移和激活函数(必须要有),上一层的输出作为下一层的输入,最后的输出不需要激活函数。因为激活函数主要是用来解决层数塌陷的问题,因为没有激活函数的话,该层的计算结果是线性的,传入下一层,下一层的计算结果依然是线性的,这两层线性计算就相当于一层计算。
1. 深度神经网络主要是控制隐藏层的大小、层数和相关参数。
**2.可以选择单隐藏层把隐藏层做的大一点;也可以用多隐藏层,从上到下一层比一层小,逐层压缩,提炼信息;也可以先扩张,再压缩 **
3. 可以先压缩再扩张,但单次的扩张程度不一太大。
总结

QA
- 神经网络中的一层实际指的是带权重的一层,出去输入层,剩下的就是层数。每一层包含了该层的权重 W,b 和激活函数,以及当前层的计算方法
- SVM替代了感知机,多层感知机解决了XOR的问题,但多层感知机没有流行是因为要解决隐藏层数量、大小、收敛等问题,工作量太大
- 理论上来说一层感知机可以拟合所有数据,但实际上不可实现,因为优化函数解决不了
- 激活函数的本质就是引入非线性特点,激活函数对于任务来说远没有选择隐藏层大小和数量重要
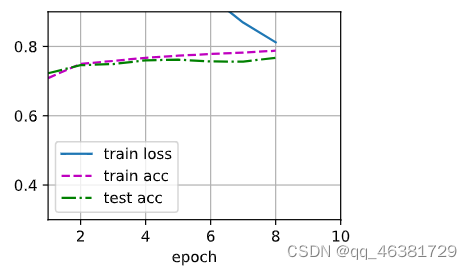
实现
import torch
from torch import nn
from d2l import torch as d2l
# 设置批量大小,读取数据
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
# 设置输入输出和隐藏层节点数
num_inputs,num_outputs,num_hiddens = 784, 10, 256
# 初始成随机数,第一层大小是数据输入和隐藏层规模
W1 = nn.Parameter(
torch.randn(num_inputs,num_hiddens,requires_grad=True)
)
b1 = nn.Parameter(
torch.zeros(num_hiddens,requires_grad=True)
)
# 上一层的输出和感知机输出
W2 = nn.Parameter(
torch.randn(num_hiddens,num_outputs,requires_grad=True)
)
b2 = nn.Parameter(
torch.zeros(num_outputs,requires_grad=True)
)
params = [W1,b1,W2,b2]
# 实现ReLU激活函数
def relu(x):
a = torch.zeros_like(x)
return torch.max(x,a)
# 实现模型
def net(x):
x = x.reshape((-1,num_inputs))
h = relu(x @ W1 + b1)
return (h @ W2 + b2)
# 损失
loss = nn.CrossEntropyLoss()
# 训练
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params,lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater)
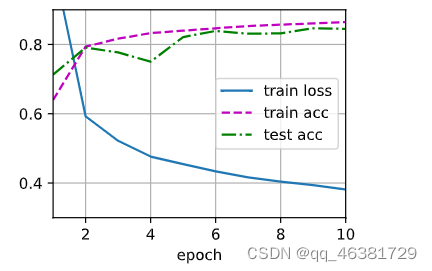
PyTorch实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10))
def init_weights(m):
if type(m)==nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net.apply(init_weights);
batch_size,lr,num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(),lr=lr)
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)














 1466
1466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









