







【论文笔记】LocNet: Global Localization in 3D Point Clouds for Mobile Vehicles
~~~
~~~~
3D 点云中的全局定位是在没有任何先验知识的情况下估计车辆姿态的一个具有挑战性的问题。 本文通过在全局先验图中实现位置识别和度量姿态估计,提出了该问题的解决方案。 具体来说,本文提出了一种使用 siamese LocNets 的 LiDAR 点云半手工表示学习方法,该方法将地点识别问题描述为相似性建模问题。 使用 LocNet 的最终学习表示,提出了一个仅具有距离观察的全局定位框架。 为了证明我们的全局定位系统的性能和有效性,使用 KITTI 数据集与其他算法进行比较,并在我们的长期多会话数据集上进行评估。 结果表明,我们的系统可以达到很高的精度。
本文提出了一种半手工深度神经网络 LocNet 来学习 3D LiDAR 传感器读数的表示,在此基础上,设计了用于全局度量定位的 Monte-Carlo 定位框架。 定位系统的框架如图 1 所示。传感器读数首先被转换为手工制作的旋转不变表示,然后通过网络生成低维指纹。 重要的是,当两个读数的表示接近时,两个读数以很高的概率被收集在同一个地方。 凭借此属性,传感器读数被组织为全局先验图,在该图上呈现基于粒子的定位器,仅提供范围观察,以实现快速收敛以校正位置和方向。
本文的贡献如下:
1.提出了一种结构化点云的手工表示,它实现了旋转不变性,保证了学习表示中的这一特性。
2.在 LocNet 中引入了 Siamese 架构来模拟两个 LiDAR 读数之间的相似性。 由于学习度量建立在欧几里德空间中,因此可以通过简单的计算在欧几里德空间中测量学习到的表示。
3.提出了一个仅具有范围观察的全局定位框架,该框架建立在由姿势和学习表示组成的先验地图上。
方法
~~~
~~~~
所提出的全球定位系统包括两个组件,如图 1 所示,地图构建和定位。 在地图构建组件中,在映射会话中收集的帧通过 LocNet 进行转换以生成相应的指纹,形成基于 kd 树的在线匹配词汇表作为全局先验地图。 在线会话中使用了定位组件,它使用 LocNet 将当前帧转换为特征,以在全局先验图中搜索相似帧。 可以看到两个组件中的关键模块是 LocNet,如图 2 所示。 LocNet 被复制以形成用于训练的 siamese 网络。 当部署在定位系统中时,LocNet,即孪生网络的一个分支,被提取出来用于表示生成。

1.旋转不变表示
~~~
~~~~
LiDAR 数据帧 P 中的每个点都使用笛卡尔坐标中的 (x; y; z) 进行描述,该坐标可以转换为球坐标中的 (r; θ; φ)。 考虑到一般的 3D LiDAR 传感器,仰角 θ 实际上是离散的,因此帧 P 可以分为多个测量环,记为
S
N
i
∈
P
S_N^i ∈ P
SNi∈P,其中 i 是从 1 到 N 的环的索引。 在每个环中,点按方位角 φ 排序,其中每个点用 pk 表示,其中 k 是由 φ 确定的索引。 因此,在每个 LiDAR 帧中,每个点都由环索引
S
N
i
S_N^i
SNi 和 φ 索引 k 索引。
给定一个环
S
N
i
S_N^i
SNi,两个连续点 pk 和 pk−1 之间的二维距离计算为
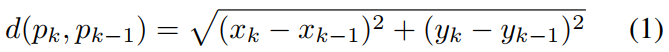
它位于预先指定的范围间隔 d ∈ [dmin; dmax]。
对于整个环,我们计算每对连续点之间的所有距离。 然后,我们设置一个恒定的桶数 b 和一个范围值 I = [dmin; dmax],并将 I 分成大小的子区间:

每个区间对应一个分离区间,如下所示:
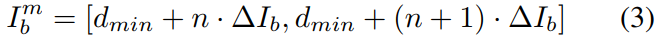
其中 n 是区间索引,环
S
N
i
S_N^i
SNi 中的所有 d 都可以找到它属于哪个区间。 所以环
S
N
i
S_N^i
SNi的直方图可以写成
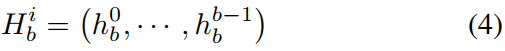
其中
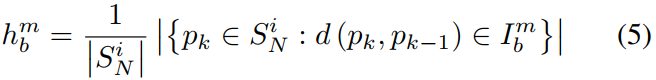
最后,我们按照环从上到下的顺序将 N 个直方图
H
b
i
H_b^i
Hbi 堆叠在一起。 然后从点云 P 生成 N × b 单通道图像表示
R
=
(
H
b
0
;
⋅
⋅
⋅
;
H
b
N
−
1
)
T
R =(H_b^0; · · · ; H_b^{N−1})^T
R=(Hb0;⋅⋅⋅;HbN−1)T。使用这种表示,如果车辆在同一位置旋转,表示保持不变, 因此旋转不变。
全局定位中的一种干扰是移动物体,因为它们可能导致范围分布的不可预测的变化。 通过利用环信息,可以在一定程度上容忍这种扰动,因为运动物体通常发生在地面附近,对应于更高仰角的环与这些动态解耦。
2.学习表征
~~~
~~~~
使用手工表示 R,我们将全局定位问题转换为身份验证问题。 Siamese 网络能够解决这个问题并降低表示的维数,如图 2 所示。
假设孪生神经网络的任何一侧(图2中的Side 1或Side 2)的最终输出是一个d维特征向量
G
W
(
R
)
=
{
g
1
;
⋅
⋅
⋅
;
g
d
}
G_W(R)=\{g_1; · · · ; g_d\}
GW(R)={g1;⋅⋅⋅;gd}。 类图像表示 R1 和 R2 之间的神经网络要学习的参数化距离函数为 DW (R1, R2),表示 GW 输出之间的欧式距离,如下所示:

在孪生卷积神经网络中,最关键的部分是对比损失函数,由 Lecun 等人提出。 [16],显示如下: 
可以看出,损失函数需要一对样本来计算最终损失。 让标签 Y 分配给一对表示 R1 和 R2:如果 R1 和 R2 相似,则 Y = 1,表示两个地方很接近,所以两个帧是匹配的; 如果 R1 和 R2 不同,则 Y = 0,代表两个地方不相同,这是定位和地图系统中最常见的情况。 实际上,对比损失的目的是在训练步骤中尝试降低相似对的 DW 值并增加不同对的 DW 值。 
可以看出,如果两个地方的匹配是真实的,那么计算出来的对比损失应该是一个非常低 值。 如果不是真实的,损失应该是一个更高的值,原始对比损失的第二部分应该是低的以最小化 L(Y, R1, R2)。 使用阈值为
τ
τ
τ 的二元分类器
C
τ
C_τ
Cτ 很容易判断地点识别:
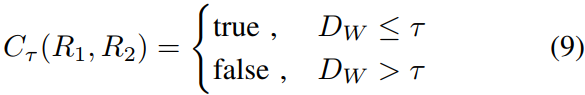
其中参数
τ
τ
τ决定地点识别结果。
综上所述,使用神经网络的优势是显而易见的。 低维表示,指纹
G
W
(
R
)
G_W(R)
GW(R),是在欧几里得空间中学习的,因此可以方便地构建用于全局定位的先验图。
3.全局定位应用
~~~
~~~~
如前所述,移动车辆的全局定位基于先验地图和姿态估计。 因此,首先需要建立一个可靠的先验全局地图,特别是对于长时间运行的车辆。
在本文中,我们利用基于 3D LiDAR 的 SLAM 技术来生成地图,该地图提供了一个度量姿态图
{
X
}
\{X \}
{X},其中每个节点表示一个 LiDAR 帧,其相应的表示
{
G
W
(
R
)
}
\{G_W(R) \}
{GW(R)} 也通过将帧传递到 LocNet 来包括在内,以及整个校正后的全局点云 P 。 因此,我们先前的全局地图 M 组成如下: 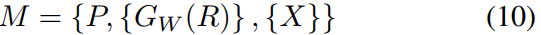
为了提高实时定位的搜索效率,在欧几里德空间中基于集合
{
G
W
(
R
)
}
\{G_W(R) \}
{GW(R)}构建kd-tree K。 因此,先前的全局地图如下:

地图构建完成后,当新的点云 Pt 在时间 t 出现时,首先将其转换为手工表示 Rt,然后通过 LocNet 转换为降维特征 GW (Rt)。 假设它在K中最接近的匹配结果是Rk,而Rk所附的记忆中的位姿是Xk。 因此,匹配的观测值 Z 可以看作是一个仅范围的观测值:

我们利用蒙特卡罗定位来估计连续观察的二维姿态 Xt。 根据高斯分布,根据粒子与观察到的姿态之间的距离计算权重。 在重采样步骤中过滤掉权重较小的粒子,保留高概率的粒子。 经过一些步骤后,MCL 收敛到一个正确的方向,只有范围的观察和连续的里程计。
基于生成的 Xt,我们将其设置为 ICP 算法的初始值 [17],通过将当前点云 Pt 与整个点云 P 配准,帮助车辆实现更精确的 6D 姿态。 总的来说,整个定位过程是从粗到细。
实验
~~~ ~~~~ 所提出的全局定位系统从两个方面进行评估:地点识别的性能、定位的可行性和收敛性。
1.位置识别性能
~~~
~~~~
我们将 LocNet 与其他三种算法进行了比较,主要是基于 3D 点云关键点的方法和基于帧描述符的方法:Spin Image [10]、ESF [11] 和 Fast Histogram [14]。 Spin Image 和 ESF 基于局部描述符,我们将整个点云转换为全局描述符,而 LiDAR 传感器是描述符的中心。 我们在 PCL2 中使用它们的 C++ 实现。 对于 Fast Histogram 和 LocNet,直方图的桶设置为相同的值 b = 80。
在一些论文中,测试集是手动选择的 [13] [15],而我们选择通过彻底匹配数据集中的任何帧对来计算性能。基于算法的矢量化输出,我们使用 kd-tree 生成相似度矩阵,然后通过与基于地面实况的相似度矩阵进行比较来评估性能。这是一个巨大的计算,例如序列 00 的 4541×4541 比较时间的几乎一半。
位置识别算法的结果使用精度和召回度量 [20] 来描述。我们使用 F1 分数的最大值来评估不同的精度-召回关系。根据数据集提供的真实情况,如果两个地方的欧几里得距离小于 p,我们认为它们是相同的。因此阈值 p 的不同值决定了最终的性能。我们在序列 00 上测试了不同的 p 值,结果如表 I 所示。
此外,我们设置 p = 3m 并在其他序列上测试四种方法,F1 分数如表 II 所示。显然,与其他方法相比,所提出的 LocNet 在大多数测试中实现了最佳性能。 
定位概率
~~~
~~~~
为了评估定位的性能,[5] 显示了在目标地图中没有成功定位的情况下行进给定距离的概率。 得益于 SegMatch3 的开源代码,我们在整个提供的目标地图上按顺序 00 运行 10 次,并呈现平均结果。 我们将所有的分割点从开始到结束都记录为成功的定位。 至于其他四种方法,我们基于向量化表示构建 kd 树,并在当前帧到来时寻找最近的姿势。 如果是真正的正匹配,我们将其记录为成功的定位。 这四种方法都没有随机因素,所以我们只运行它们一次。 值得一提的是,SegMatch 可以使用几何验证返回一个完整的定位变换,这与其他地方识别算法不同。
如图 4 所示,车辆可以使用 LocNet 100% 的时间将自身定位在 20 米内。 SegMatch 和 Spin Image 接近 98%,其他两个接近 95%。 几何方法和 LocNets 基于一帧 LiDAR 数据,因此它们可以在 10 米内实现更高比例的计时。 而 SegMatch 依赖于环境的语义分割,因此需要累积 3D 点云,从而导致在短距离行驶时性能较差。 此外,在序列 00 上使用 LocNet 的闭环结果如图 5 所示。这些实验都支持我们的系统有效地在地图中产生正确的拓扑匹配帧。

全局定位性能
~~~
~~~~
我们以两种方式展示了我们的全球定位系统的性能:重新定位和位置跟踪。如果车辆丢失了位置,重定位能力是帮助其定位的关键;来位跟踪不断实现定位。
1)重新定位:重新定位的收敛速度实际上取决于粒子的数量和它们在蒙特卡罗定位中得到的第一次观察。所以很难评估收敛速度。我们给出了在 YQ21 数据集中使用我们的车辆进行重新定位的案例研究(见图 6)。给出了偏航角和位置角的误差,以及配准的均方根 (rmse) 误差,即对齐的点云 P 和 Pt 之间的欧几里德距离。
显然,重新定位过程可以收敛到车辆运行 5m 内的稳定位姿。并且位置的变化会导致注册错误的变化。在多会话数据集中,用于定位的点云与形成地图的那些帧不同,因此使用 ICP 无法将配准误差降低到零。
2)位置跟踪:一旦车辆重新定位,全局定位系统就可以实现车辆的位置跟踪。仅测距观测提供了车辆全局位姿的可靠信息,ICP算法可以帮助车辆更准确地定位。我们测试了第 3-1 天和第 3-2 天,结果如图 7 所示。
基于统计分析,我们的全球定位系统可以实现高精度的位置跟踪。在第 3-1 天,93.0% 的位置错误在 0.1m 以下,在第 3-2 天为 88.9%;对于旋转误差,第 3-1 天有 93.1% 的航向误差低于 0.2°,第 3-2 天下午有 90.7% 的航向误差低于 0.2°。可忽略的误差对车辆的自主导航动作没有影响。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









