







【论文笔记】Monocular Camera Localization in 3D LiDAR Maps
~~~
~~~~
在给定地图中定位相机对于基于视觉的导航至关重要。与使用相机获取的地图进行视觉定位的常用方法相比,我们提出了一种新方法,该方法可以跟踪单目相机相对于给定 3D LiDAR 地图的姿态。我们采用基于局部束调整的视觉里程计系统来从图像特征重建一组稀疏的 3D 点。这些点与地图连续匹配,以在线方式跟踪相机姿势。我们的视觉定位方法有几个优点。由于它仅依赖于匹配的几何体,因此它对环境光度学外观的变化具有鲁棒性。利用全景 LiDAR 地图还提供了视点不变性。然而,低成本和轻量级的相机传感器用于跟踪。我们展示了真实世界的实验,证明我们的方法在长轨迹和不同条件下准确估计了 6-DoF 相机姿势。
在本文中,我们提出了一种在 3D LiDAR 地图中跟踪单目相机的 6-DoF 姿态的方法。由于我们的方法不是用于全局定位,因此需要对该地图中的初始位姿进行粗略估计。我们采用基于局部束调整的视觉里程计系统来重建相对于一组稀疏 3D 点的相机姿势。这项工作的主要贡献是通过匹配它们的几何形状并应用估计的相似性变换来间接定位相机,从而将该点集与给定的地图连续对齐。我们将估计问题表述为非线性最小二乘误差最小化,并在迭代最近点过程中解决它。图 1 显示了 3D LiDAR 地图中的相机图像和相应的位姿。

方法
我们方法的目标是在 3D LiDAR 地图中定位单目相机。输入是图像流和表示为点云的地图,输出是帧速率下的 6-DoF 相机姿态估计。我们的方法建立在视觉里程计系统的基础上,该系统使用局部束调整从图像特征重建相机姿势和一组稀疏的 3D 点。给定相机相对于这些点的姿势,我们通过将重建的点与地图对齐来间接定位相机。
一旦基于 ORB-SLAM [13] 组件的视觉里程计提供了由两个关键帧姿势和最少量 3D 点组成的第一个局部重建,就会执行对齐。由于我们的方法不是用于全局定位,因此需要对初始重建和地图之间的转换进行粗略估计。随后,我们的方法在更新时对齐局部重建,即通过摄像机跟踪选择一个新的关键帧并将其添加到局部映射中。由于我们的方法直接对ORB-SLAM维护的地图进行操作,因此在对齐过程中需要暂停局部映射。因此,对齐必须运行得足够快,以避免长时间中断,从而导致相机跟踪失败,因为地图未覆盖新探索的区域。通过不断地将局部重建与地图对齐,我们消除了视觉里程计积累的漂移。由于我们使用单目相机,漂移不仅发生在平移和旋转中,还发生在尺度上。因此,我们实现了与 7-DoF 相似变换的对齐。在本节的其余部分,我们首先讨论局部重建,然后讨论局部重建和地图之间的数据关联,最后详细说明我们解决的优化问题,以估计用于执行对齐的变换。我们使用齐次坐标来表示刚体和相似变换:
局部重建
视觉里程计系统通过解决局部束调整问题来重建关键帧姿势和 3D 点。什么被认为是局部的,是由一个covisibility graph决定的,covisibility graph描述了关键帧之间有多少图像特征是covisible的。通过该图直接连接到当前关键帧的所有关键帧以及这些关键帧观察到的所有点都是视觉里程计局部估计问题的变量。我们在由两组定义的局部重建中包含相同的关键帧和点
坚持这个选择有两个原因。首先,它确保我们使用一致的局部重建,因为束调整优化是在我们对齐之前执行的。其次,对齐不会影响并可能破坏视觉里程计,因为我们统一变换其局部束调整问题。
数据关联
为了确定局部重建与地图的对齐,我们搜索 D 中重建点和地图点之间的对应关系
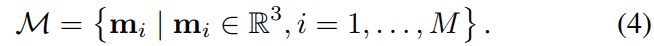
我们在 ICP 方案中执行此操作,即根据 k = 1 上的当前相似性变换估计更新数据关联; : : : ; K 次迭代。对于每个重建的点,我们在地图中找到它最近的邻居,它存储在 kd 树中以允许快速查找。如果最近邻足够近,则将该对添加到对应集
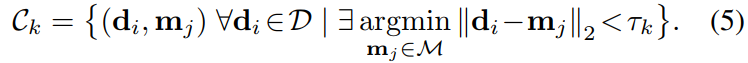
我们减少迭代 k 上的距离阈值 τk。 τmax 和 τmin 是我们方法的参数,定义了线性阈值函数
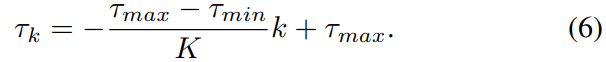
随着算法的收敛,点到点的距离越来越小,我们可以更严格地选择阈值,以便只保留高质量的关联。完全基于最近邻寻找对应关系的一个主要问题是重建点的集合通常仅与地图部分重叠。因此点 di 可能在 M 中没有有意义的对应关系,即使它们的位置是完美估计的。由于 LiDAR 的垂直视野有限,因此部分重叠通常是由于映射不完整造成的。源自未映射几何结构的重建点将与地图的边界点相关联,从而导致有偏差的变换估计。由于这些可能会在准确性和收敛性方面产生严重后果,因此我们使用下面描述的地图局部点分布来细化对应集。
1)局部点分布:为了分析其局部点分布,地图被体素化为分辨率Δ取决于其密度。我们对每个体素内均值为 μ(V) 2 R3 的点的协方差矩阵 Σ(V) 2 R3×3 进行主成分分析
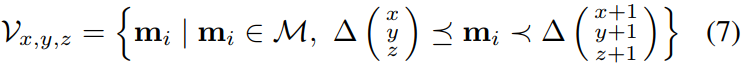
对齐
给定一组对应关系,我们估计将局部重建与地图对齐的相似变换。精炼对应集 Ck0 被迭代更新。在每次迭代 k 我们估计
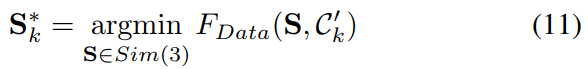
通过使用 Levenberg-Marquardt 算法用 g2o [11] 解决非线性最小二乘最小化问题。我们估计当前关键帧 Tc 的参考帧中的变换 S∗ k。与地图参考系中的参数化相比,这是有利的,因为优化变量更好地对应于我们想要用 Sk 补偿的漂移维度。因此我们对精化的对应集进行变换,得到
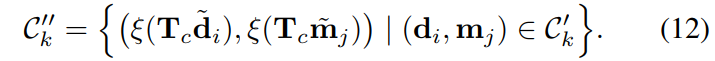
我们的误差函数是对应点之间的平方欧几里得距离:

我们使用 Huber 成本函数对数据关联中的异常值更加稳健。正如 Fitzgibbon [6] 所示,这会导致目标函数更好的收敛特性。我们选择内核大小 r∆ = τmin 以保留所有迭代 k 的二次误差范围。一旦我们估计了所有迭代的 S∗ k,我们计算联合相似性变换
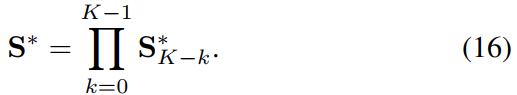
为了将局部重建与地图对齐,我们将所有点位置 di 和关键帧姿势 Ti(如 III-A 中定义的)使用 S。由于它位于当前关键帧的参考帧中,因此在应用之前必须将其转换回地图的参考帧:
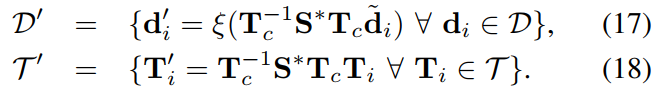














 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









