







 今天我分享的是一篇名为《通过再平衡增量学习统一分类器》文献,本文由中国科学技术大学的侯赛辉发表在2019年的CVPR顶会上。至(2023年2月)已有500+引用,
今天我分享的是一篇名为《通过再平衡增量学习统一分类器》文献,本文由中国科学技术大学的侯赛辉发表在2019年的CVPR顶会上。至(2023年2月)已有500+引用,
这篇文章有点难,它开发了一个 “统一对待新旧类的分类器”,涉及了三个组件,多次进行蒸馏损失改进,以减轻新旧类样本不平衡带来的影响,从而缓解灾难性遗忘,若有不对的地方,还请大家多多包涵。

近年来,IL在实际应用中越来越受到需求,很多应用系统(人脸识别,产品分类)都需要处理连续的数据流,来了怎么多新数据怎么办?一种自然的方法是简单地对预训练模型进行微调,以适应新的数据, 。然而,这种方法面临着一种严重的挑战,即灾难性遗忘(也就是说,当模型在新数据上进行调优时,它通常会导致在先前数据上的性能显著下降。)
为了克服灾难性遗忘这一难题,人们进行了大量的研究,主要集中在两个方向:尝试识别别并保留原始模型的重要参数、通过知识蒸馏保留原始模型中的知识,虽然这些方法在一定程度上减轻了灾难性遗忘的影响,但总体效果仍然明显不如联合训练(联合训练需要all data,重新训练模型,不符合现实)。
本文旨在探索一种更有效的增量学习方法,特别关注多类的情况。

在这种不均衡的情况下会带来以下几个负面的影响
分类器权重向量不均衡:对于分类器权重参数而言,新类的权重向量的大小明显高于旧类的权重向量。
旧类别的分类器权重和特征会产生漂移:当学习了新类别的信息后,旧类别的一些信息会被遗忘,包括分类器权重,样本的特征等。
类混淆性问题出现:在学习新类别的时候,新类别的分类器权重可能会与旧类别的权重很接近。(这以问题在Bic一文中也有提到,但它没有给出实质性的解决方案)
简而言之:(新类别权重向量的模大于旧类别、出现灾难性遗忘、新类别的权重向量与旧类别相似,模型容易将旧类别数据划分为新类别)这些影响结合会严重影响分类器
通过使用Cosine Normalization 、Less-Forget Constraint、Inter-Class Separation方法重新平衡训练过程,我们所提出的框架可以更有效地保留在前一阶段学习的知识,并减少新旧类之间的混淆。
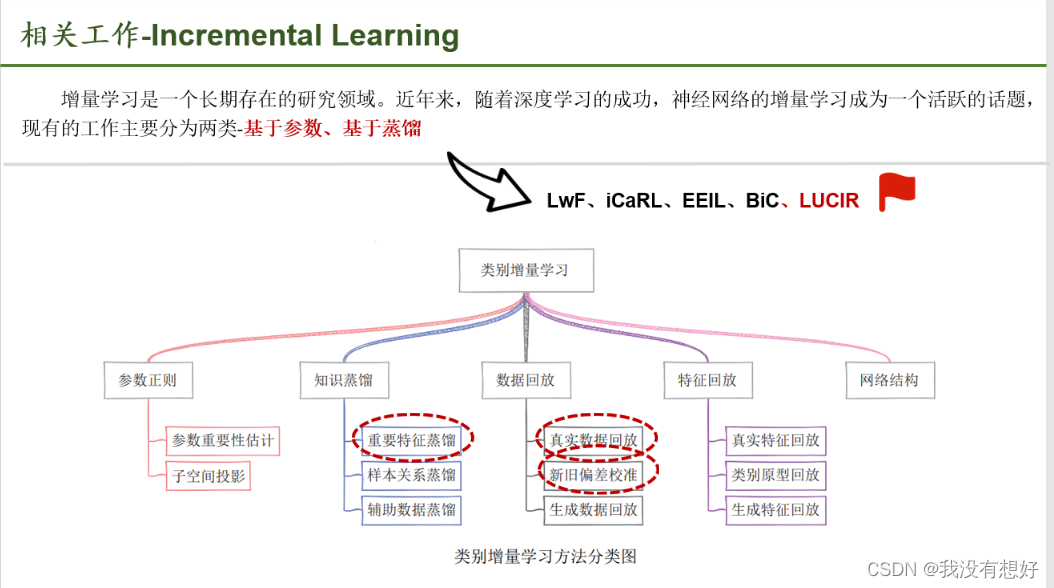 这里主要是对以往的方法的一个归纳,我们简单了解即可。我觉得他这还没有BIC那篇文章介绍的全面,对于基于参数:很难设计一个合理的度量来评估所有参数,本文提出的方法属于基于蒸馏的类别,但与以往的工作存在一个关键的不同之处。我们不是简单地将不同的客观术语结合来平衡新旧类,而是深入研究了不平衡造成的不利影响。
这里主要是对以往的方法的一个归纳,我们简单了解即可。我觉得他这还没有BIC那篇文章介绍的全面,对于基于参数:很难设计一个合理的度量来评估所有参数,本文提出的方法属于基于蒸馏的类别,但与以往的工作存在一个关键的不同之处。我们不是简单地将不同的客观术语结合来平衡新旧类,而是深入研究了不平衡造成的不利影响。
本文也提了一句;网络结构、生成数据回放,本文提出的方法是相互独立的,因此可以与我们的框架相结合,以实现进一步的改进。(展望)。

数据重采样:即在construct data时,对数量大的类少采样,对数量小的类多采样。
代价敏感学习:通过对各个类的loss赋以不同的权重来提高数据少的类的“存在感”。
在这项工作中,我们从不同的角度解决增量学习中的不平衡问题,而不是直接调整采样比例或损失权值。


除了在所有类上计算的交叉熵损失外;通过对蒸馏函数多次改进,引入了一种新型的蒸馏损失 (进行较少遗忘约束)它基于特征进行计算;同时, 𝐿mr 是一种间隔排序损失,用于分离新旧类(类间分离);这些交叉熵损失、新型蒸馏损失、间隔排序损失共同作用,以实现更有效的多类增量学习。这三部分也是本文的难点所在。
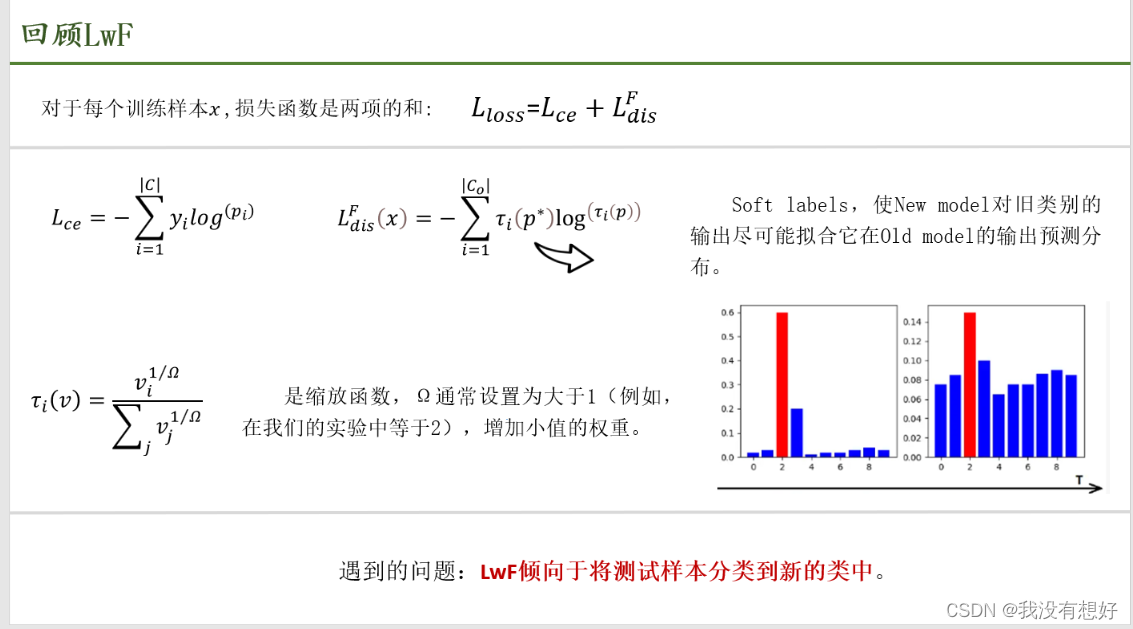
为什么回顾?因为本文要在上面做改进, 𝐿𝑐𝑒是是标准交叉熵损失,𝐿𝑑𝑖𝑠是蒸馏损失
交叉熵中的C是所有观察到的类的集合, y是ground truth的one-hot编码,p是由softmax获得的相应类概率。
𝐿𝑑𝑖𝑠𝐹作用:让New model类别输出预测分布尽可能拟合Old model输出预测分布, 𝐿𝑐𝑒作用作用:减少Old model中的错误信息被蒸馏到New model网络中。
当温度太小时, 不同类别之间的差距很大,很小的logits对应的softmax被压到0,就发挥不了知识蒸馏的作用,就蒸馏不出知识,和普通的softmax(T=1)一样了,当温度太大时, soft targets 的差距就被拉平了,很小的logits可以蒸出很高的softmax,虽然可以传递信息但是有噪声。
为了解决“LwF倾向于将测试样本分类到新的类中 ”这个问题,iCaRL提出了一种名为“最接近样本均值”的分类策略。虽然iCaRL对LwF进行了改进,但它在长类序列上的性能仍然不令人满意。
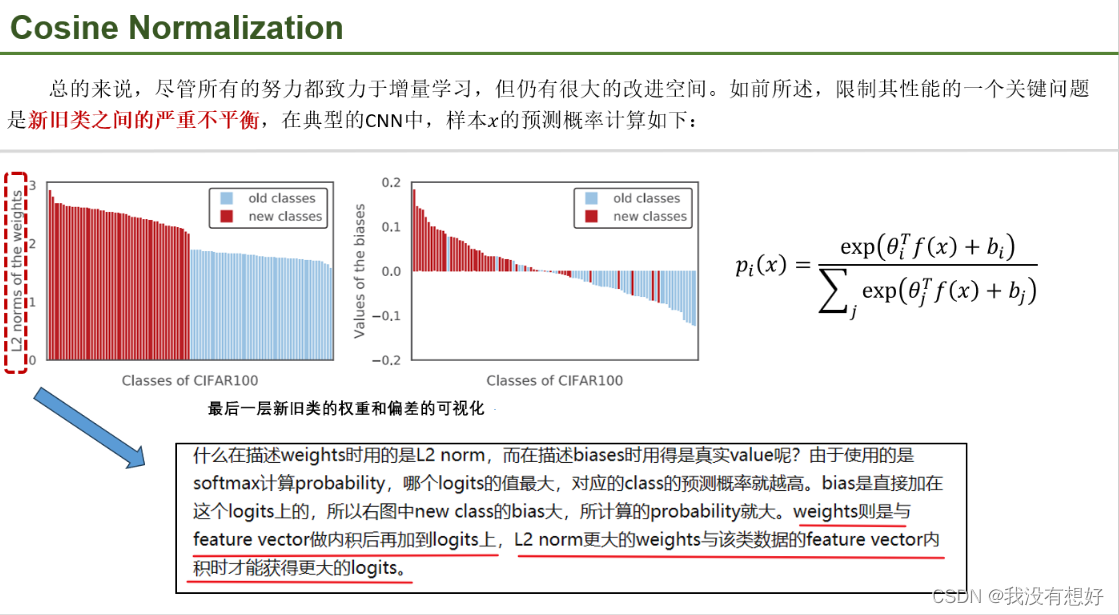
其中f(x)提取的feature,θ和b分别是表示最后一层对应class i 的weights和偏置向量。图清晰地展示了数据不平衡对模型的影响。类别权重向量的L2范式大于旧类别权重向量;新类别的偏置(参数b )基本大于0,旧类别的偏置(参数b )基本小于0,即(new class在最后一层的weights和biases更大),图说明不平衡导致了模型更倾向把数据预测成新的class

如前所述,由于数据不平衡,导致模型的weights和bias都更favor new class。为了解决这个问题,我们建议在最后一层使用余弦归一化,论文做了两个工作
一方面, 在计算预测概率时对 softmax 操作中的特征向量和类别权重进行二范数归一化,这样所有类别的权重向量、特征向量的L2范数均为1
另一方面,去除偏置(论文里面也没有说为什么这样做?)
右边公式中的bar表示对向量除以其模长来归一化,尖括号表示内积,即计算cosine similarity
η是一个学习参数,和蒸馏时用的温度是同一个作用,<𝑣−1,𝑣−2>的范围被限制为[−1,1](cos的范围),如果后面直接接一个softmax会导致输出的概率都很低,因此通过乘上一个因子 η(应该是小于1的数) ,使得softmax后的最大概率值可以接近1。
在改进之前,输出层新类的权重(红线)会比旧类(蓝线)大得多,导致网络倾向于将结果预测成新类。经过余弦标准化,权重都压到了高维球体内部一个固定的范围,即可消除新旧class的embedding模长不同的问题
L2正则化还有个好处:有助于模型收敛
 下一步,将这个learnable scalar η 去除(因为这里没用softmax了),并把LwF的用软标签+cross entropy方式改为:在softmax之前,新旧模型针对各class算出的cosine similarity的欧式距离尽量小,从而蒸馏损失为:如图所示,其中f∗和θ∗为原始模型中的特征提取器和类嵌入,Co为旧类的个数。
下一步,将这个learnable scalar η 去除(因为这里没用softmax了),并把LwF的用软标签+cross entropy方式改为:在softmax之前,新旧模型针对各class算出的cosine similarity的欧式距离尽量小,从而蒸馏损失为:如图所示,其中f∗和θ∗为原始模型中的特征提取器和类嵌入,Co为旧类的个数。

这是一种局部的限制(只限制角度),可能会导致新的模型在保持feature和embedding的夹角不变情况下,整体发生了较大的旋转(这种情况可能导致损失函数结果一样,但是向量空间坐标完全改变),这使得我们希望新模型尽量去逼近旧模型的愿望落空。
这种设计背后的基本原理是,作者认为FC中的权重在一定程度上反映了类与类之间的关系,因此,固定权重向量(从而保留类与类之间的关系),让训练后的特征提取器尽可能与训练前的一致,从而抵抗灾难性遗忘。
其中 𝑓∗(x)-和 𝑓(x)-分别是原始模型和当前模型提取的L2归一化特征,鼓励当前网络提取的特征方向与原始模型的特征方向相似,当 𝑓∗(x)-和 𝑓(x)-)完全不相似(180°夹角),损失函数取得最大值2,完全相似时损失函数为0(0°夹角,新模型完全逼近旧模型)。
在实践中,由于每个阶段引入的新类数量不同,保留先前知识的需要程度也不同。为此,我们建议自适应地设置损失𝐿𝑑𝑖𝑠𝐺的权重,其中|Cn|和|C|是每个阶段中新旧类的数量,λbase是每个数据集的固定常数。一般来说,λ随着新类与旧类之比的增加而增加。

上面讨论的两个idea,其实是对LwF的蒸馏损失的两次改进,cosine normalization 将𝐿𝑑𝑖𝑠𝐹改进为𝐿𝑑𝑖𝑠𝐶 ,而less-forget又将𝐿𝑑𝑖𝑠改进为𝐿𝑑𝑖𝑠𝐺
文章提出了利用旧类别保留的样本去解决这个问题,作者此处引入了间隔排序损失来确保新旧类被清晰地分开。m是间隔阈值, 𝜃(x)-是旧类别的保留的样本x的权重,𝜃𝑘-是被选为x的hard negatives(也就是最容易让旧类别x被错误归入的新类)样例的前k个新类权重之一。
具体地:对于旧类别的保留的样本x,使用x的正则化特征作为锚点,让其x的正则化权重(我们认为是positive)尽量接近锚点,让对x产生最高响应(指,对应输入 x, 该类得到的logits值比较高,也就是最容易让x被错误归入的类)的新类(hard negatives)正则化权重(我们认为是negatives)尽量远离锚点。(为了找到𝜃𝑘-(hard negatives的权重),本文提出了在线挖掘方法)4
设置间隔阈值m,对于旧类别数据,随着优化的进行,旧类别分支的输出与新类别分支的输出会逐渐拉大,从而防止将旧类别的数据划分为新类别的数据。,只有当这两者的距离超过m才能得到0 loss值(最优状态)

我们从一个训练了50个类的模型开始,剩下的50个类分为1、2、5和10个阶段。 为了模拟现实情况

iCaRL-CNN(橙线)效果最差,通过与iCaRL-NME(最接近样本均值分类)(绿线)相比,我们可以得到一个结论:NME可以降低普通CNN里面FE层和FC层之间的耦合性,从而减少灾难性遗忘。
结论2:图中可以看到Our-CNN的方法,取得了最佳效果, 在100个类的整体性能比iCaRL提高了6%以上,并且与Our-NME相当(两线重合),因此,可以直接采用CNN的预测结果进行预测,这表明我们的方法很好地处理了新旧类之间的不平衡。
比较有意思的是Ours-CNN与Ours-NME差距不大,两者只是采用的分类器不同,NME并不会出现分类偏好的情况,这在一定程度上说明,使用论文提出的损失函数进行增量学习,可以让CNN分类器抵抗分类偏好,达到使用NME一样的效果。

CBF的影响相对较小,因为前三个组件减轻了不平衡的不利影响、CBF(蓝线)好橙线可以说100%重合,也就说明在三个组件的组合上,再加CBF,无多大意义。


iCaRL-CNN(图9(a))倾向于将样本划分为新的类,而这是由于新旧类之间的严重不平衡造成的,后三种方法都减轻了不平衡的不利影响

与之前的哪些方法相比,本文不是简单地将不同的客观术语结合来平衡新旧类(泛泛而谈),而是深入研究了不平衡造成的不利影响,并提出了一个系统的解决方案,从多个角度克服了这个问题。















 2784
2784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









