






一、基本信息
Paper:论文连接
Year:Received: 27 February 2021 / Revised: 31 July 2021 / Accepted: 2 October 2021
Authors:Waqas Ali1 · Muhammad Saleem2 · Bin Yao1,3 · Aidan Hogan4 · Axel-Cyrille Ngonga Ngomo5
Journal Name:The VLDB Journal
Keywords:Knowledge graph · Storage · Indexing · Query processing · SPARQL
二、Resarch Objectives(s)
该文对RDF知识图的查询技术和系统进行了全面的综述、对最先进的存储、索引、连接处理和查询处理技术进行全面的调查,以及根据分布式存储的需要划分RDF图的高级策略,并在本地环境中有效的评估SPARQL查询来帮助用户为给定的用力选择合适的引擎或基准。
三、Background / Problem Statement
RDF已经成为网络发布知识图的流行格式像Bio2RDF、DBpedia、PubChemRDF、UniProt和Wikidata包含了数十亿个三元组,这些发展带来了对查询大型RDF图的优化技术和引擎的需求。
四、Various Technologies
1、Storge(存储)
数据存储是指数据在内存中的表示方式。不同的存储机制将不同的数据元素连续存储在内存中,从而在压缩和高效数据访问方面进行权衡,以下是RDF存储的各种类别:
- Triple Table(三元组)
- Vertical partitioning(垂直分区)
- Extended vertical partitioning(扩展垂直分区)
- Property Table(属性表)
- Graph-based storage(基于图的存储)
- Tensor- based storage(基于张量的存储)
- Miscellaneous storage
除了常见的基于关系和图的存储,有的引擎提出利用现有的系统实现其他形式的存储,一个例子是使用NoSQL键值、表格或文档存储来进行分布式存储。而最近的技术趋势在实验NoSQL来分布式RDF数据的管理。
2、Indexing(索引)
索引可以在RDF图上进行高效的查找操作(O(1)或者O(log|G|)返回第一个结构或者空结果的时间),最常见的是查找与给定三元组模式匹配的三元组,然而索引也可以用于匹配非单例BGP(具有一个以上的三重模式)、匹配路径表达式等,以下是RDF图提出的索引技术:
- Triple indexes(三重索引)
- Entity-based indexes(基于实体的索引)
- Property-based indexes(基于属性的索引)
- Path indexes(路径索引)
- Join indexes(连接索引)
- Structural indexes(结构索引)
- Quad indexes(四元索引)
- Miscellaneous indexing
不同的索引方案在时间和空间效率方面存在不同的权衡。更全面的索引通常能够更快地评估查询,但它们也需要更多的存储空间,并且在数据发生更改时可能导致更昂贵的更新操作。选择索引方案取决于系统的具体要求,如预计执行的查询类型以及查询性能与数据存储/更新之间的权衡。
3、Join processing
RDF存储采用多样化的查询处理策略,但所有策略都需要将表示查询的逻辑运算符转换为实现操作的“物理运算符”,以实现高效评估操作的算法。我们现在讨论的最重要的运算符是自然连接。
自然连接在RDF数据中的实现涉及将逻辑运算符转化为适当的物理运算符,以便高效地执行连接操作。这可能涉及使用索引或哈希等技术来加速连接过程,并降低查询的时间复杂度。
自然连接是RDF查询处理中的关键运算符之一,因为它可以用于合并具有相关性的数据,从而支持复杂的查询。通过将查询操作转换为合适的物理运算符,RDF存储可以优化查询性能,并提供高效的数据检索和查询结果生成。以下是RDF存储中指出的连接技术:
- Pairwise join algorithms(成对连接算法)
- Multiway joins(多路连接)
- Worst case optimal joins(最坏情况下的最优连接)
- Translations to linear algebra(转换成线性代数)
- Join reordering(连接重排序)
- Caching(缓存,基于实践中查询可能具有重叠或相似模式的观察——是重用以前为其他查询所做的工作。具体来说,我们可以考虑缓存查询的结果。)
4、 Query processing
我们将RDF存储定义为能够存储、索引和处理RDF图上的连接操作的引擎,而SPARQL引擎则支持超出连接之外的各种功能。我们描述了一些有效评估这些功能的技术,包括关系代数(超出连接的部分)和属性路径。我们还介绍了一些针对SPARQL的通用扩展,以支持递归和分析功能。
- Relational algebra (beyond joins)连接之外的关系代数
- Property paths(属性路径)
- Recursion(递归)
- Analytics(分析)
- Graph query rewriting(图查询优化)
- Multi-query Optimization(多查询优化)
最近的工作涉及SPARQL的递归和分析,以支持其他RDF数据管理场景和知识图用例
5、Partitioning
在分布式RDF存储和SPARQL引擎中,数据在一个机器集群上进行分区,以实现水平扩展,其中可以向集群分配更多的机器来处理更大的数据量。然而,横向扩展是以网络通信成本为代价的。因此,一个关键的优化是选择一种分区方案,该方案通过强制执行各种形式的局部性来降低通信成本,主要是允许在每个单独的机器上处理某些类型的(中间)连接。
- Triple/quad-based partitioning(基于三重/四重的分区)
- Graph-based partitioning(基于图的分区)
- Query-based partitioning(基于查询的分区)
- Replication(复制)
基于三重/四重的分区是计算和维护最简单的,它只依赖于单个元组中的数据,允许将同一分区键上的联接推送到各个机器。基于图的分区允许在单个机器上评估更复杂的图模式,但计算和维护成本更高(例如,考虑动态数据)。在可用的情况下,有关查询的信息可以用于基于工作负载的分区,该分区对数据进行分区或复制,以便为常见的子模式启用局部性。复制可以以冗余存储为代价,进一步提高负载平衡、本地性和容错性。
五、 Research challenges and future directions
尽管近年来在RDF存储的规模和效率方面取得了重大进展,但随着RDF图的规模和以更复杂的方式查询它们的需求的增加,这些仍然是核心挑战。
- 使用SPARQL高效查询动态RDF图方面还需要做更多的工作,包括高效支持读写、增量索引、缓存等的存储。
- 查询优化大多数工作都集中在优化联接和基本图形模式上。我们发现优化SPARQL1.1特性的工作相对较少,如属性路径、否定等,需要做更多的工作。
- 查询量高的SPARQL端点每天处理数百万个查询。这一挑战促使人们进一步研究利用频繁子查询的工作负载感知或缓存策略。另一个研究挑战是如何确保有效的策略为许多客户端提供服务,同时避免服务器过载,其中允许暂停和恢复昂贵查询请求的抢占等方法是进一步开发的有希望的想法。
- 使用各种基准来评估比较不同的RDF存储,但它们往往侧重于系统级别的比较,从而混淆了技术。在RDF/SPARQL设置中的单个技术级别上进行更细粒度的评估对于理解存在的不同权衡非常有用。此外,还为SPARQL1.0提出了许多基准测试,其中缺乏包括属性路径等特性的基准测试。
- 集成RDF和SPARQL在Web上被广泛采用,用于管理和查询知识图。然而,在这种设置中,通常会考虑其他类型的任务,包括联合查询、推理、丰富、细化、学习、分析等。在SPARQL中支持或集成这些任务的功能方面,还需要做更多的工作。
六、Notes
1、什么是RDF和RDF Graph?
RDF(Rersource Description Framework 资源描述框架):一种描述和表示信息的标准化格式,其核心思想是以三元组(Triple)的形式表示信息,每个三元组由主体(Subject)、谓词(Predicate)和对象(Object)组成。主体表示所描述的资源,谓词表示资源的属性或关系,对象表示与资源相关联的值或其他资源。
RDF图(RDF graph):是指由RDF三元组组成的图形结构,用于表示和描述资源之间的关系和属性。RDF图是RDF数据模型的可视化形式,通过节点和边来展示资源和它们之间的连接。如下图所示:
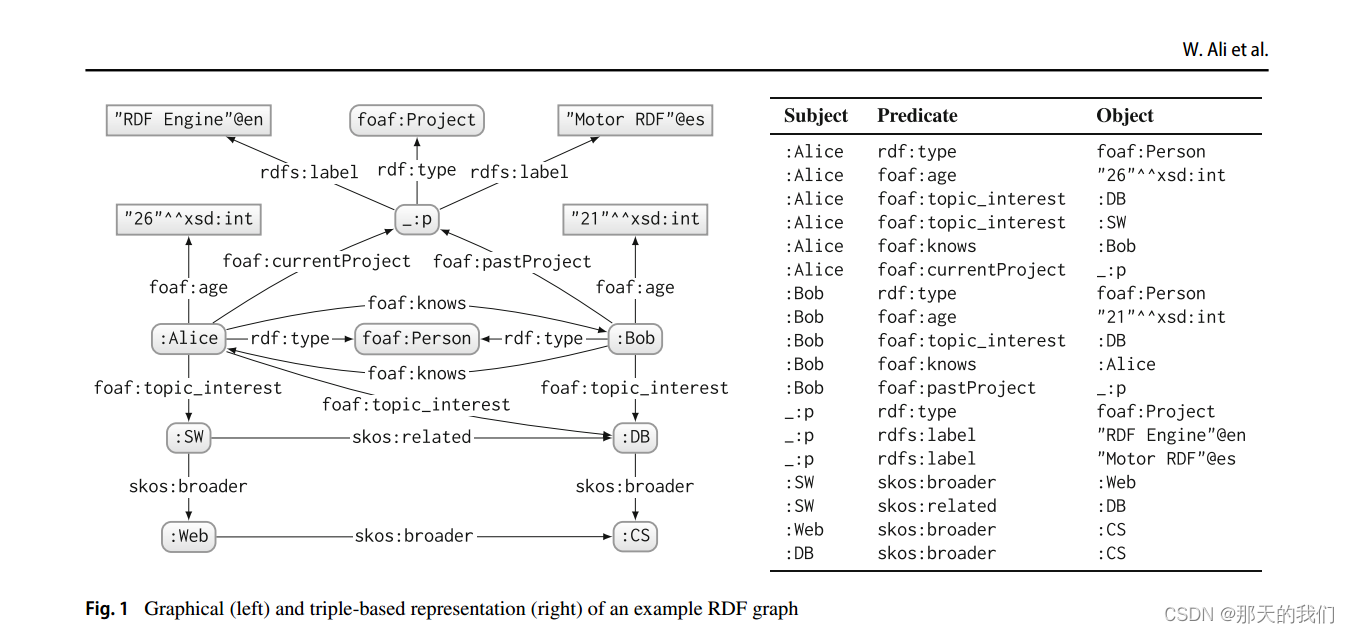
RDF部分术语:
-
“rdf:”:这是RDF词汇的命名空间前缀,代表了RDF(Resource Description Framework)的核心词汇。它用于表示RDF的基本概念,如"rdf:type"表示资源的类型,"rdf:property"表示属性等。
-
rdfs:":这是RDFS词汇的命名空间前缀,代表了RDF Schema词汇。它用于表示RDF模式的元数据,如"rdfs:Class"表示类(class),"rdfs:subClassOf"表示类的子类关系、rdfs:label是一个属性,用于表示资源的标签或标识符的人类可读名称。
-
“owl:”:这是OWL词汇的命名空间前缀,代表了Web本体语言(Web Ontology Language)。它用于表示更丰富的本体概念和关系,如"owl:Class"表示OWL类,"owl:ObjectProperty"表示对象属性等。
-
“foaf:”:这是FOAF词汇的命名空间前缀,代表了Friend of a Friend。它用于描述人和社交关系,如"foaf:Person"表示人,"foaf:knows"表示社交关系等
-
“skos”:skos:broader是SKOS(Simple Knowledge Organization System)词汇中的一个属性,用于表示概念之间的层次关系,即更一般(更宽泛)概念和更具体(更具体)概念之间的关系。skos:related属性用于表示两个概念之间的相关性或关联性。它表达了两个概念之间存在某种关系,但是这中关系不属于更具体的关系,表示的关系比较广泛,例如“动物”和“自然保护”。如果这两个概念之间存在某种相关性,但又不适合使用更具体的关系类型来描述,可以使用skos:related属性来表示它们之间的关系。
-
“_:p”:表示Bob和Alice共享项目。
-
“@es”:在RDF中,@es表示一个字符串文本带有语言标签,其中"es"代表西班牙(Spanish)例如,“Motor RDF”@es表示一个使用西班牙语(Spanish)的字符串文本,其中"Motor RDF"是实际的文本内容。除了"es"表示西班牙语外,还有其他语言标签如"en"表示英语,"fr"表示法语等。
2、SPARQL
是为RDF开发的一种查询语言和数据获取协议,它是为W3C所开发的RDF数据模型所定义,但是可以用于任何可以用RDF来表示的信息资源。它于2008年1月15日正式成为一项W3C推荐标准,于2013年3月发布SPARQL1.1。
第一次做博客笔记,作为自己科研笔记来看,研一目前想往RDF存储方向发展,这篇综述其实很多都没有看懂,所以笔记可能也会很粗糙,未来我希望一步步把那些技术以自己的理解的语言进行不断优化和改进,欢迎各位小伙伴一起学习交流!















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









