






文章目录
- 前言
- 一、使用步骤
- 二、常用正则表达式
- 三、具体使用例子
前言
本文主要是根据自己平时修改latex中不规范的格式,遇到的一些需要重复修改的一类问题,用正则表达式来提高修改效率。
例如:文中出现转置符号,应该使用命令\top。正确示例:A^{\top};错误示例:A^{T}。
一、使用步骤
首先我们打开.tex文件,ctrl+F快捷键打开查找替换框。如图:
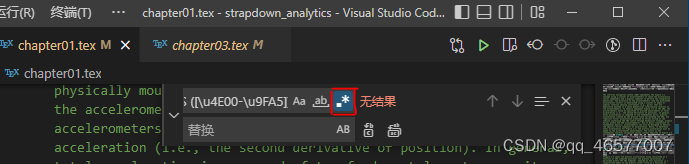
选择红色框(正则表达式进行搜索)。
二、常用正则表达式
- [abc]:这个字符可以是a或b或c
- [a-z] :表示任意一个小写字母
- [0-9] :表示任意一个数字
- [a-zA-Z] :表示任意一个字母
- [a-zA-Z0-9_] :表示任意一个数字字母下划线
- [^abc] :该字符只要不是a或b或c
- ----------------------------------------------------------------------------------------------------------------
- . :表示任意一个字符,没有范围限制
- \d :表示任意一个数字,等同于[0-9]
- \w :表示任意一个单词数字字符,等同于[a-zA-Z0-9_]–单词指字母/数字/_
- \s :表示任意一个空白字符
- \D :表示不是数字
- \W :不是单词字符
- \S :不是空白字符
- ----------------------------------------------------------------------------------------------------------------
- [\u4E00-\u9FA5] :一个汉字
- [\u4E00-\u9FA5\\s]+ : 多个汉字,包括空格
- [\u4E00-\u9FA5]+ :多个汉字,不包括空格
三、具体使用例子
1.英文符号,行内公式使用$……$:
将文中所有INS,转换成$INS$
([\u4E00-\u9FA5]) INS ([\u4E00-\u9FA5])
$1 ($INS$) $2[\u4E00-\u9FA5]:代表一个汉字,要用括号括起来。
$1 ($INS$) $2 : $1,$2代表左右两边的汉字不变。(这里说的是文中的英文字母,所以锁定左右两边汉字,中间英文字母)
2.公式中上标^和下标_的内容均用{}括住:
例如公式中出现C_B^A,变成C_{B}^{A}
_([a-zA-Z])
_{$1}
\^([a-zA-Z])
^{$1}如果是数字,将[a-zA-Z]换成[0-9]。另外,上标加了一个转置符号。
3.公式中除了命令附带括号,其余括号需要加\left和\right。
例如公式中出现(A+B) \times C,变成\left(A+B\right) \times C
\(
\\left(
\)
\\right)如果是中括号,大括号,将小括号替换即可。
4.转置符号使用\top。
例如A^{\top}。
\^T
^{\\top}
5.使用命令\prime代替单引号上标。
例如R'应该使用R^{\prime}。
'
^{\prime}
6.分数应该使用\dfrac{}{}。
例如\dfrac{1}{2}。
\frac
\dfrac7.使用微分符号\dif代替d。
例如\dif{x}。
dx
\dif{x}

















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









