







一、Redis原理
1.1 redis是单线程还是多线程?
Redis6之前网格IO和键值对读写是由同一个线程来完成。Redis6引入的多线程是网络请求多线程,但是读写还是单线程,所以仍然是并发安全的。
1.2 redis单线程为什么那么快?
- redis基于内存进行操作,速度快。
- 命令为单线程,没有线程切换开销。
- 使用了I/O多路复用机制提升I/O利用率。
- 高效的数据结构,如全局hash表。
- 单线程避免了多线程的频繁的上下文切换。
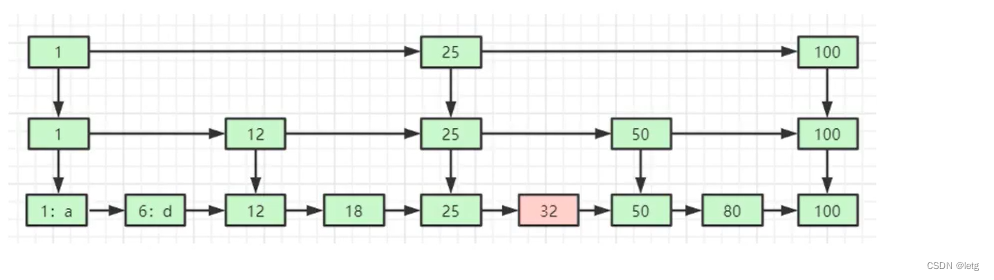
1.3 redis底层数据如何用跳表存储?
zset采用跳表存储,近似于二分查找,能够很快的进行插入,删除和查找
1.4 redis key过期了为什么内存没释放?
- SET命令没有设置过期时间,过期时间会被擦除,则永不过期。
- Redis对于过期的key会采取惰性删除和定时删除两种策略。
- 惰性删除:当读取一个过期的key,发现过期了就会删除这个key。
定时删除:Redis会每100ms去删除过期的key,但只是删除了一部分,所以还是存在key过期但是没有删除,导致内存没有释放。
1.5 Redis key没设置过期时间为什么被redis删除了?
主动清理策略一共分为8种:
针对设置了过期时间的key:
- volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-Iru:会使用LRU算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用LFU 算法筛选设置了过期时间的键值对删除。
针对所有的key做处理:
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-Iru:使用LRU算法在所有数据中进行筛选删除。
- allkeys-lfu:使用LFU算法在所有数据中进行筛选删除。
不处理:
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) O0M command not allowed whenused memory",此时Redis只响应读操作。
1.6 LRU和LFU的区别?
- LRU算法(Least Recently Used,最近最少使用):淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
- LFU算法(Least Frequehtly Used,最不经常使用):淘汰最近一段时间被访问次数最少的数据,以次数作为参考绝大多数情况我们都可以用LRU策略,当存在大量的热点缓存数据时,LFU可能更好点。
1.7 Redis集群的hash分片算法?
HASH_SLOT=CRC16(key)%16384
1.8 Redis主从切换导致缓存雪崩?
如果没有保证主从的时钟一致性,slave比master走得快,master里面大量的key在从节点其实已经过期,而在master里面还没有过期,slave切换为主节点,master就会删除大量过期的key,主线程会发生阻塞,无法处理客户端的请求。并且大量key过期就会导致缓存雪崩。
1.9 Redis的AOF和RDB、混合持久化?
- RDB(宕机后会丢失几分钟的数据)
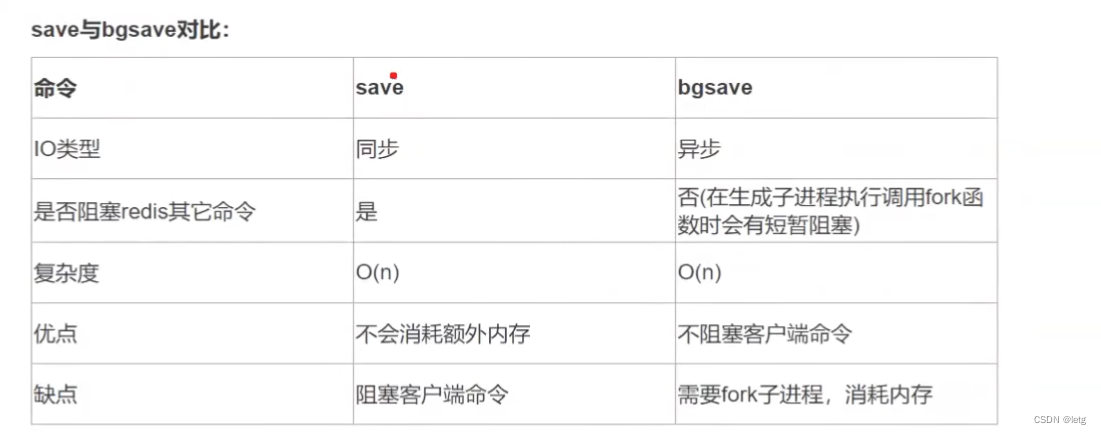
默认情况下,内存数据快照存储在dump.rdb的二进制文件中。可以通过配置 #save 60 1000 (60秒内至少有1000次改动就收集一次数据集)。当触发条件后,redis会将内存的数据进行持久化,save为同步操作,数据集过大就会阻塞客户端的请求。可以采取bgsave。
- bgsave
bgsave采用了操作系统的写时复制技术,在生成快照的同时也可以正常处理写命令。主线程会fork出一个子线程,子线程中的bgsave进程会读取主线程的内存数据,把他们写入rdb文件中。
如果主线程要对数据进行修改,这块数据会被复制一份生成该数据的副本,然后bgsave进程会把这个副本数据写入rdb文件中。
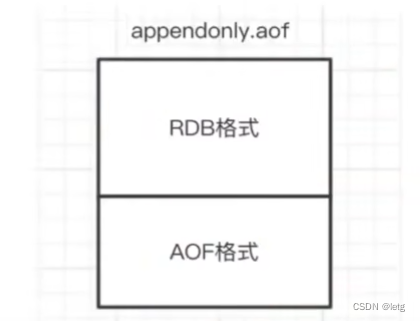
AOF(append-only file)
将修改的每一条指令记录进appendonly.aof中(先写入os.cache,每隔一段时间fsync回磁盘)
配置文件中添加
#appendonly yes
#appendfsync everysec(每秒)/always(每次)/no(由操作系统来调配)
- AOF重写:
对于重复操作一条数据的命令会进行重写优化
auto-aof-rewrite-percentage 100 #大小增长了100%,如128mb,在进行一次aof重写。
auto-aof-rewrite-min-size 64mb #如果aof文件超过64mb,就会进行aof重写。
REDIS4.0之前为了数据安全性,在重启后首先采用AOF来恢复数据。
REDIS4.0之后开启混合持久化方式。
aof-use-rdb-preamble yes
对于混合持久化,AOF在重写时,不再适用RESP命令写入AOP,而是重写这一刻之前的内存做RDB快照处理,将RDB快照内容和AOF增量修改命令存在一起。写入新的AOF文件。新的文件不叫appendonly.aof,等到重写完后新的aof文件才会改名。(恢复数据时,前面的数据直接读取到内存,后面的增量命令进行重放恢复到内存)
1.10 Redis集群网络抖动频繁主从切换?
配置cluster-node-timeout 当持续失联timeout时间,就会进行主从切换
1.11 Redis集群支持批量命令吗?
redis使用mset进行批量操作,但是在集群中需要为同一个分区,否则报错,所以计算hash值的时候,需要给定同一个值。
mset {user1}:1:name wangji {user1}:1:age 666(user1为计算hash值的key)
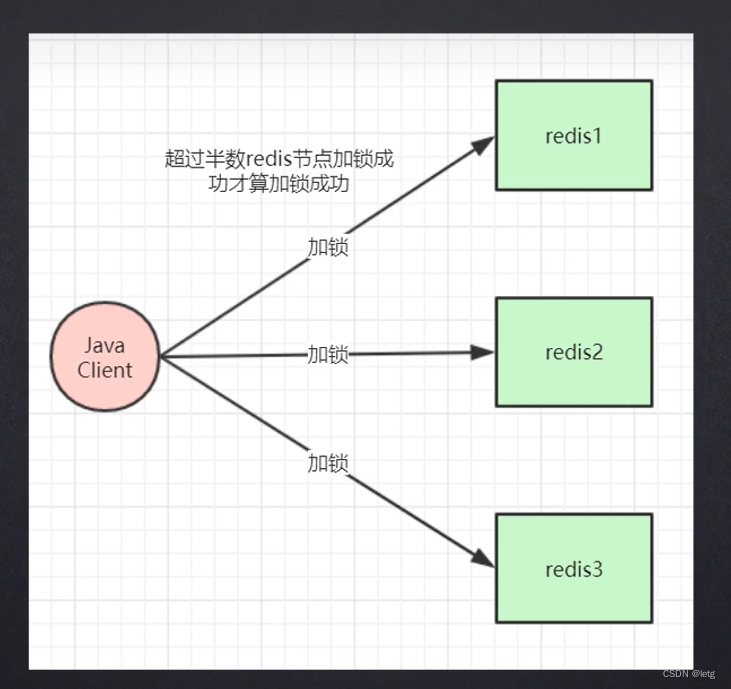
1.12 Redis主从切换分布式锁丢失问题?
在一个主节点操作数据加锁后,锁同步到其他的从节点的过程中,主机宕机导致锁丢失。
- 红锁解决(弄3台redis,这三台和节点没有关系)
1.13 缓存击穿和缓存穿透?
缓存穿透为数据库和缓存都没有数据,缓存击穿为大量key过期访问数据库。
- 缓存穿透可以通过设置空字符串来代替
- 缓存击穿可以通过设置随机过期时间来解决
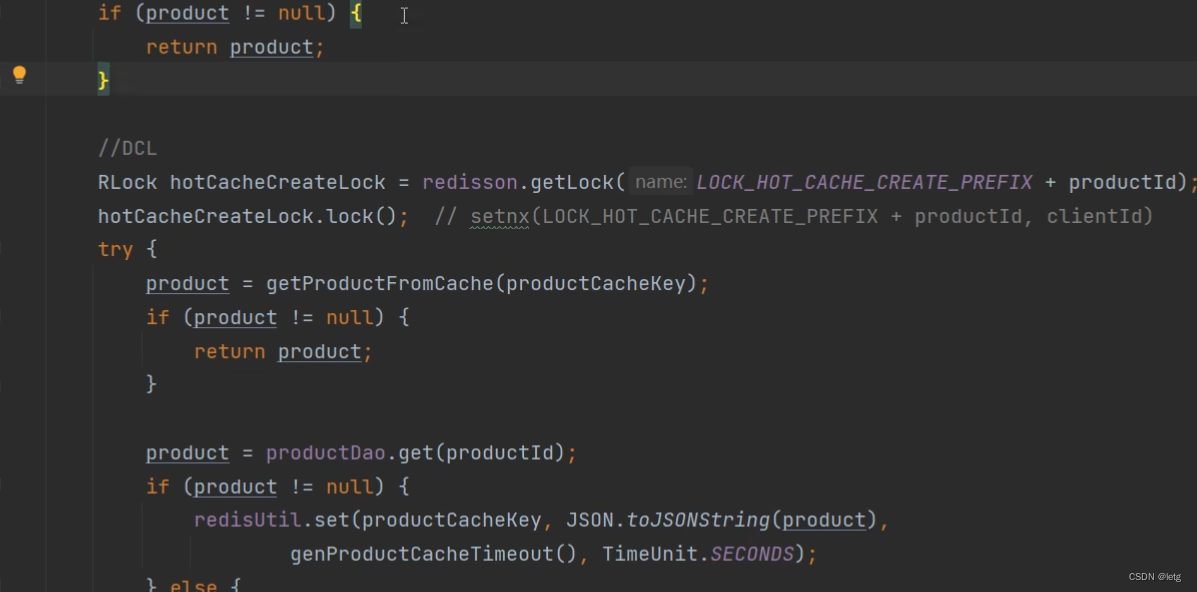
1.14 基于DCL机制解决突发性热点缓存并发重建问题?(重建缓存)
- 加synchronize锁(但是只限于单机jvm进程,集群中每个节点至少进入一次,对于集群,可以通过对象池,不同的产品用不同的对象锁)
- 使用分布式锁(redisson)(分布式锁是为了解决分布式集群下出现的并发问题)
redisson.getLock(“key”)或取锁,lock.lock()进行将这个key锁住,这些代码要写到try里面,finnaly最后要lockl.unlock()释放锁
1.15 缓存与数据库的双写一致性
- 更新完数据库更新缓存
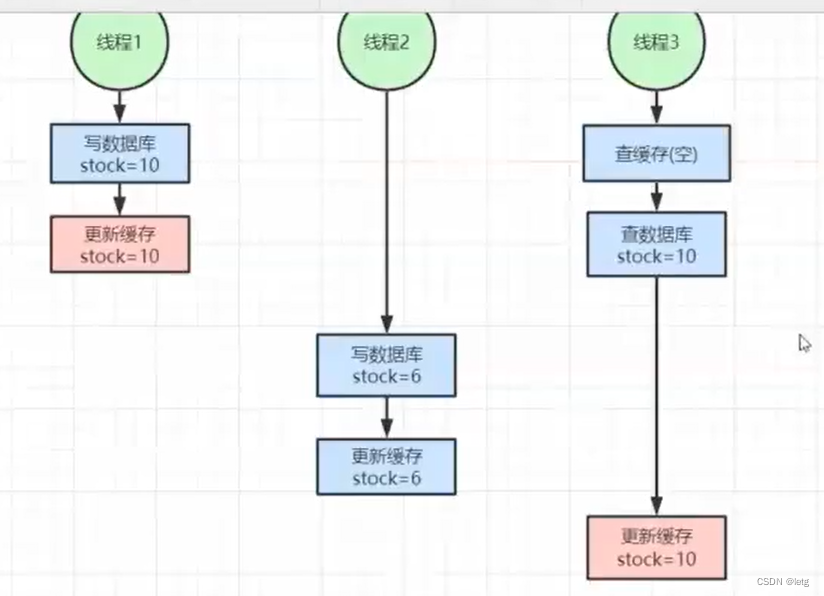 缓存数据为10,数据库数据为6.
缓存数据为10,数据库数据为6. - 更新完数据库删除缓存
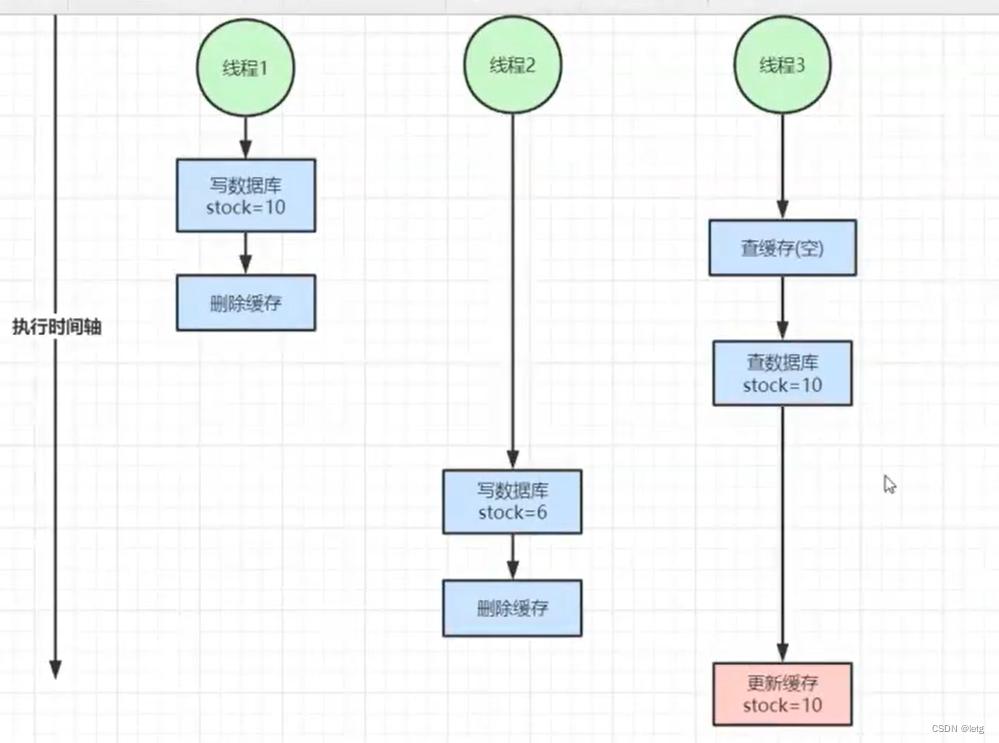
数据库数据为6,缓存数据为10
- 采用分布式锁来解决
- 采用读写锁来解决
- 重建缓存采用分布式锁过期。
Rlock lock = redisson.getLock()
lock.tryLock(3,TimeUnit.Seconds)//重建缓存必须小于3秒,分布式锁3秒后会直接失效,串行转并行。
1.16 利用多级缓存解决redis线上集群缓存雪崩?
大量的并发访问一个缓存,同一个数据是在相同的节点上,会造成节点挂掉,造成缓存雪崩。
- 基于JVM进程的缓存Map。














 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









