







基本介绍&快速入门&张量Tensor&数据集Dataset&数据变换Transforms&网络构建&函数式自动微分&模型训练&保存与加载&使用静态图加速
张量Tensor
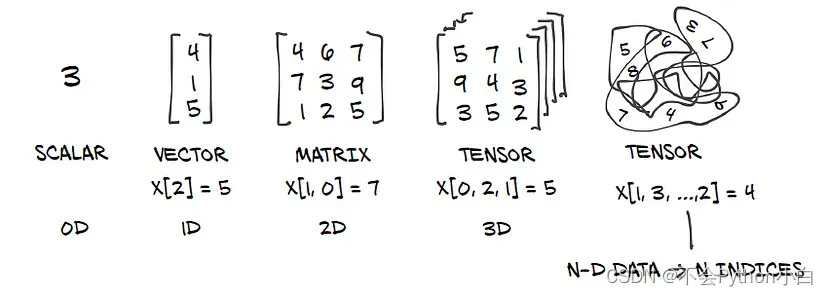
什么是张量?
张量是一种数据结构,它存储了一组数字,且这些数字需要通过多个索引进行访问。在深度学习的背景中,张量是泛化到更高维度的向量和矩阵。
mindspore.Tensor参数
classmindspore.Tensor(input_data=None, dtype=None, shape=None, init=None, internal=False, const_arg=False)
参数:
- input_data (Union[Tensor, float, int, bool, tuple, list, numpy.ndarray])
- 被存储的数据,可以是其它Tensor,也可以是Python基本数据(如int,float,bool等),或是一个NumPy对象。
- 默认值: None 。
- dtype (mindspore.dtype)
- 用于定义该Tensor的数据类型,必须是 mindspore.dtype 中定义的类型。
- 如果该参数为 None ,则数据类型与 input_data 一致。
- 默认值: None 。
- shape (Union[tuple, list, int, mindspore.Symbol])
- 用于定义该Tensor的形状。
- 如果指定了 input_data ,则无需设置该参数。
- 如果 shape 中存在 None 或 Symbol 类型数据,表示创建一个动态形状(dynamic shape)的Tensor,此时不需要设置 input_data 参数;
- 如果 shape 中仅存在整数类型数据,表示创建一个静态形状(static shape)的Tensor,此时必须设置 input_data 或 init 参数。
- 默认值: None 。
- init (Initializer)
- 用于在并行模式中延迟Tensor的数据的初始化
- 如果指定该参数,则 dtype 和 shape 也必须被指定。
- 默认值: None 。
- const_arg (bool)
- 指定该Tensor作为网络输入时是否为常量。
- 默认值: False 。
创建Tensor
张量的创建方式有多种,构造张量时,支持传入Tensor、float、int、bool、tuple、list和numpy.ndarray类型。
方法:
- 通过数据创建
- 从Numpy列表生成
- 使用
initializer构造张量 - 继承张量
1.根据数据直接生成
from mindspore import Tensor
data = [1, 0, 1, 0]
x_data = Tensor(data)
print(x_data, x_data.shape, x_data.dtype)
输出:
[1 0 1 0] (4,) Int64
2.从Numpy数组生成
import numpy as np
np_array = np.array(data)
x_np = Tensor(np_array)
print(x_np, x_np.shape, x_np.dtype)
输出:
[1 0 1 0] (4,) Int64
3.用 init 初始化器构造张量
当使用init初始化器对张量进行初始化时,支持传入的参数有init、shape、dtype。
- init: 支持传入initializer的子类。如:下方示例中的 One() 和 Normal()。
- shape: 支持传入 list、tuple、 int。
- dtype: 支持传入mindspore.dtype。
from mindspore.common.initializer import One, Normal
import mindspore
# 使用 1 初始化张量
tensor1 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=One())
# 用正态分布初始化张量
tensor2 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=Normal())
print("tensor1:\n", tensor1)
print("tensor2:\n", tensor2)
输出:
tensor1:
[[1. 1.]
[1. 1.]]
tensor2:
[[-0.00063482 -0.00916224]
[ 0.01324238 -0.0171206 ]]
init主要用于并行模式下的延后初始化,在正常情况下不建议使用init对参数进行初始化。
4.继承另一个张量
from mindspore import ops
x_ones = ops.ones_like(x_data)
print(f"Ones Tensor: \n {x_ones} \n")
x_zeros = ops.zeros_like(x_data)
print(f"Zeros Tensor: \n {x_zeros} \n")
输出:
Ones Tensor:
[1 1 1 1]
Zeros Tensor:
[0 0 0 0]
Tensor的属性
张量的属性包括形状、数据类型、转置张量、单个元素大小、占用字节数量、维数、元素个数和每一维步长。
- 形状(shape):Tensor的shape,是一个tuple。
- 数据类型(dtype):Tensor的dtype,是MindSpore的一个数据类型。
- 单个元素大小(itemsize): Tensor中每一个元素占用字节数,是一个整数。
- 占用字节数量(nbytes): Tensor占用的总字节数,是一个整数。
- 维数(ndim): Tensor的秩,也就是len(tensor.shape),是一个整数。
- 元素个数(size): Tensor中所有元素的个数,是一个整数。
- 每一维步长(strides): Tensor每一维所需要的字节数,是一个tuple。
Python实现:
x = Tensor(np.array([[1, 2], [3, 4]]), mindspore.int32)
print("x_shape:", x.shape)
print("x_dtype:", x.dtype)
print("x_itemsize:", x.itemsize)
print("x_nbytes:", x.nbytes)
print("x_ndim:", x.ndim)
print("x_size:", x.size)
print("x_strides:", x.strides)
输出:
x_shape: (2, 2)
x_dtype: Int32
x_itemsize: 4
x_nbytes: 16
x_ndim: 2
x_size: 4
x_strides: (8, 4)
Tensor索引
Tensor索引与Numpy索引类似,索引从0开始编制,负索引表示按倒序编制,冒号:和 …用于对数据进行切片。
tensor = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
print("First row: {}".format(tensor[0]))
print("value of bottom right corner: {}".format(tensor[1, 1]))
print("Last column: {}".format(tensor[:, -1]))
print("First column: {}".format(tensor[..., 0]))
输出:
First row: [0. 1.]
value of bottom right corner: 3.0
Last column: [1. 3.]
First column: [0. 2.]
Tensor运算
张量之间有很多运算,包括算术、线性代数、矩阵处理(转置、标引、切片)、采样等,张量运算和NumPy的使用方式类似,下面介绍其中几种操作。
普通算术运算有:加(+)、减(-)、乘(*)、除(/)、取模(%)、整除(//)。
from mindspore import ops
x = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
y = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output_add = x + y
output_sub = x - y
output_mul = x * y
output_div = y / x
output_mod = y % x
output_floordiv = y // x
output_dot = ops.dot(x, y)
print("add:\n", output_add)
print("sub:\n", output_sub)
print("mul:\n", output_mul)
print("div:\n", output_div)
print("mod:\n", output_mod)
print("floordiv:\n", output_floordiv)
print("dot:\n", output_dot)
输出:
add: [5. 7. 9.]
sub: [-3. -3. -3.]
mul: [ 4. 10. 18.]
div: [4. 2.5 2. ]
mod: [0. 1. 0.]
floordiv: [4. 2. 2.]
Tensor合并
concat
concat将给定维度上的一系列张量连接起来。
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.concat((data1, data2), axis=0)
print(output)
print("shape:\n", output.shape)
输出:
[[0. 1.]
[2. 3.]
[4. 5.]
[6. 7.]]
shape:
(4, 2)
stack
stack则是从另一个维度上将两个张量合并起来。
output = ops.stack([data1, data2])
print(output)
print("shape:\n", output.shape)
输出:
[[[0. 1.]
[2. 3.]]
[[4. 5.]
[6. 7.]]]
shape:
(2, 2, 2)
Tensor格式转换
Tensor转为Numpy
与张量创建相同,使用 Tensor.asnumpy() 将Tensor变量转换为NumPy变量。
t = Tensor([1., 1., 1., 1., 1.])
print(f"t: {t}", type(t))
n = t.asnumpy()
print(f"n: {n}", type(n))
输出:
t: [1. 1. 1. 1. 1.] <class 'mindspore.common.tensor.Tensor'>
n: [1. 1. 1. 1. 1.] <class 'numpy.ndarray'>
Numpy 转为Tensor
使用Tensor()将NumPy变量转换为Tensor变量。
n = np.ones(5)
t = Tensor.from_numpy(n)
np.add(n, 1, out=n)
print(f"n: {n}", type(n))
print(f"t: {t}", type(t))
输出:
n: [2. 2. 2. 2. 2.] <class 'numpy.ndarray'>
t: [2. 2. 2. 2. 2.] <class 'mindspore.common.tensor.Tensor'>
from_numpy(array)
- 将Numpy数组转换为张量。
- 当数据为非C连续时,数据会被拷贝成C连续数据后创建张量,否则则通过不复制数据的方式将Numpy数组转换为张量。
稀疏张量
稀疏张量是一种特殊张量,其中绝大部分元素的值为零。
在某些应用场景中(比如推荐系统、分子动力学、图神经网络等),数据的特征是稀疏的,若使用普通张量表征这些数据会引入大量不必要的计算、存储和通讯开销。这时就可以使用稀疏张量来表征这些数据。
MindSpore现在支持最常用的CSR和COO两种稀疏数据格式。
常用稀疏张量的表达形式是<indices:Tensor, values:Tensor, shape:Tensor>。其中,indices表示非零下标元素, values表示非零元素的值,shape表示的是被压缩的稀疏张量的形状。在这个结构下,我们定义了三种稀疏张量结构:CSRTensor、COOTensor和RowTensor。
CSRTensor
CSR(Compressed Sparse Row)稀疏张量格式有着高效的存储与计算的优势。其中,非零元素的值存储在values中,非零元素的位置存储在indptr(行)和indices(列)中。各参数含义如下:
-
indptr: 一维整数张量, 表示稀疏数据每一行的非零元素在values中的起始位置和终止位置, 索引数据类型支持int16、int32、int64。 -
indices: 一维整数张量,表示稀疏张量非零元素在列中的位置, 与values长度相等,索引数据类型支持int16、int32、int64。 -
values: 一维张量,表示CSRTensor相对应的非零元素的值,与indices长度相等。 -
shape: 表示被压缩的稀疏张量的形状,数据类型为Tuple,目前仅支持二维CSRTensor。
CSRTensor的详细文档,请参考mindspore.CSRTensor。
下面给出一些CSRTensor的使用示例:
indptr = Tensor([0, 1, 2])
indices = Tensor([0, 1])
values = Tensor([1, 2], dtype=mindspore.float32)
shape = (2, 4)
# 创造一个 CSRTensor
csr_tensor = CSRTensor(indptr, indices, values, shape)
print(csr_tensor.values)
print(csr_tensor.indices)
print(csr_tensor.shape)
print(csr_tensor.astype(mindspore.float64).dtype)
输出:
[1. 2.]
[0 1]
(2, 4)
Float64
上述代码会生成如下所示的CSRTensor:
[
1
0
0
0
0
2
0
0
]
\left[ \begin{matrix} 1 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \end{matrix} \right]
[10020000]
COOTensor
COO(Coordinate Format)稀疏张量格式用来表示某一张量在给定索引上非零元素的集合,若非零元素的个数为N,被压缩的张量的维数为ndims。各参数含义如下:
indices: 二维整数张量,每行代表非零元素下标。形状:[N, ndims], 索引数据类型支持int16、int32、int64。values: 一维张量,表示相对应的非零元素的值。形状:[N]。shape: 表示被压缩的稀疏张量的形状,目前仅支持二维COOTensor。
COOTensor的详细文档,请参考mindspore.COOTensor。
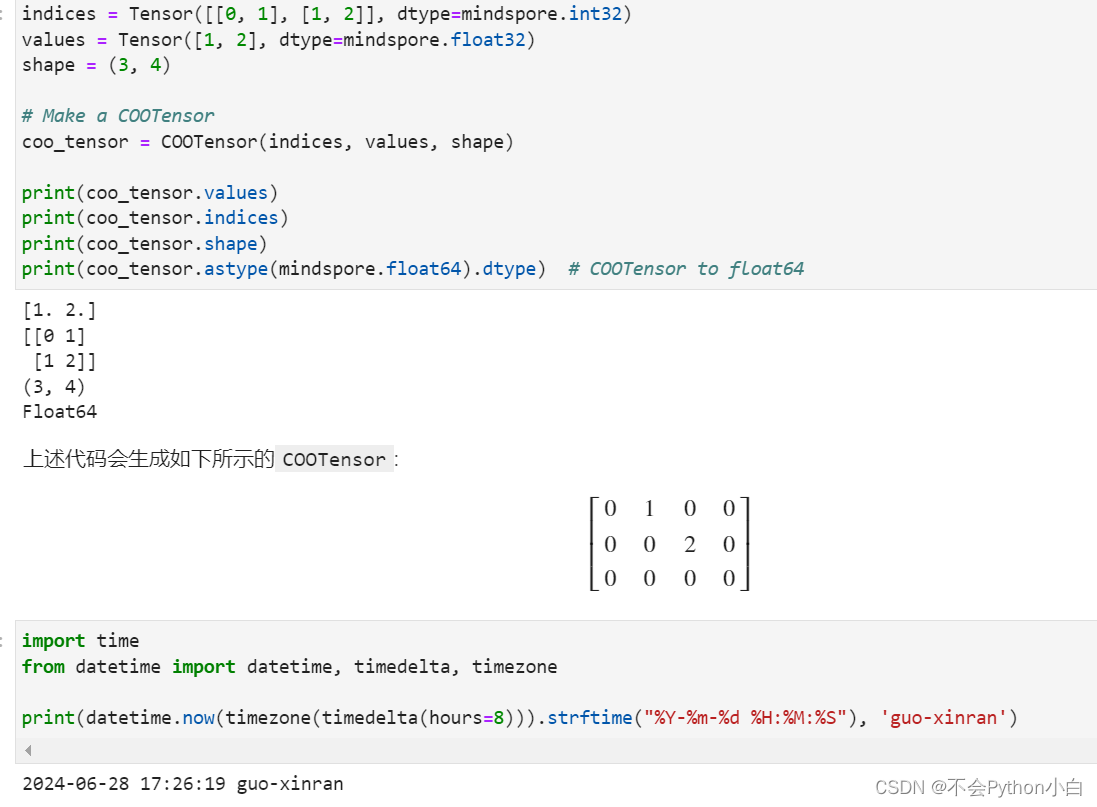
下面给出一些COOTensor的使用示例:
indices = Tensor([[0, 1], [1, 2]], dtype=mindspore.int32)
values = Tensor([1, 2], dtype=mindspore.float32)
shape = (3, 4)
# 创建一个 COOTensor
coo_tensor = COOTensor(indices, values, shape)
print(coo_tensor.values)
print(coo_tensor.indices)
print(coo_tensor.shape)
print(coo_tensor.astype(mindspore.float64).dtype) # COOTensor to float64
输出:
[1. 2.]
[[0 1]
[1 2]]
(3, 4)
Float64
上述代码会生成如下所示的COOTensor:
[ 0 1 0 0 0 0 2 0 0 0 0 0 ] \left[ \begin{matrix} 0 & 1 & 0 & 0 \\ 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 0 \end{matrix} \right] 000100020000
















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











