







时间: 5月28日 16:00
课程链接:https://live.juejin.cn/4354/yc_teacher-hands/preload
PPT:无
学习手册:https://juejin.cn/post/7101135488974585870#heading-21
课后题:https://juejin.cn/post/7102399708902981663/
项目地址:https://github.com/thuyy/ByteYoungDB
:::
背景知识(学习手册内容)
存储&数据库
存储系统
- 块存储:存储软件栈里的底层系统,接口过于朴素
- 文件存储:日常使用最广泛的存储系统,接口十分友好,实现五花八门
- 对象存储:公有云上的王牌产品,immutable语义加持
- key-value存储:形式最灵活,存在大量开源/黑盒产品
数据库系统
- 关系型:基于关系和关系代数构建的,一般支持事务和SQL访问,使用体验友好的存储产品
- 非关系型:结构灵活,访问方式灵活,针对不同场景有不同的针对性产品
分布式架构
- 数据分布策略:决定了数据怎么分布到集群的多个物理节点,是否均匀,是否做到高性能
- 数据复制协议:影响IO路径的性能、机器故障场景的处理方式
- 分布式事务算法:多个数据库节点协同保障一个事务的ACID特性的算法,通常基于2pc的思想设计
2pc:两阶段提交,第一阶段为投票阶段,第二阶段为提交/执行阶段。第一阶段协调者向所有参与者发送事务预处理请求,参与者在本地实行,返回协调者yes/no,如果都是yes则commit,如果有一个或多个no或者有超时未提交的,则rollback
数据库结构
可以复习MySQL四十五讲第一节内容,笔记链接:https://www.yuque.com/shenjingwa-ev2rj/wfwfwb/xbe3h6
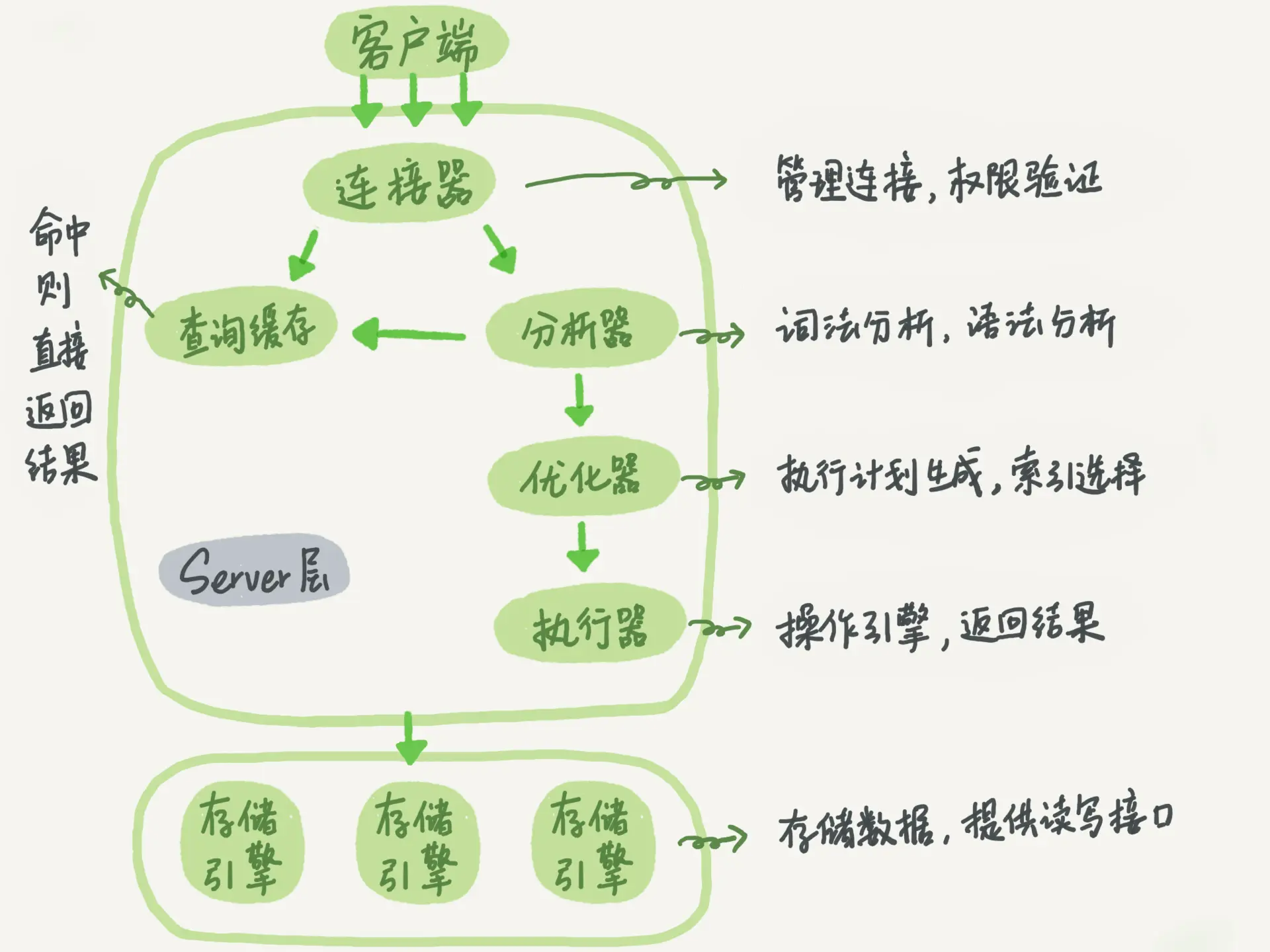
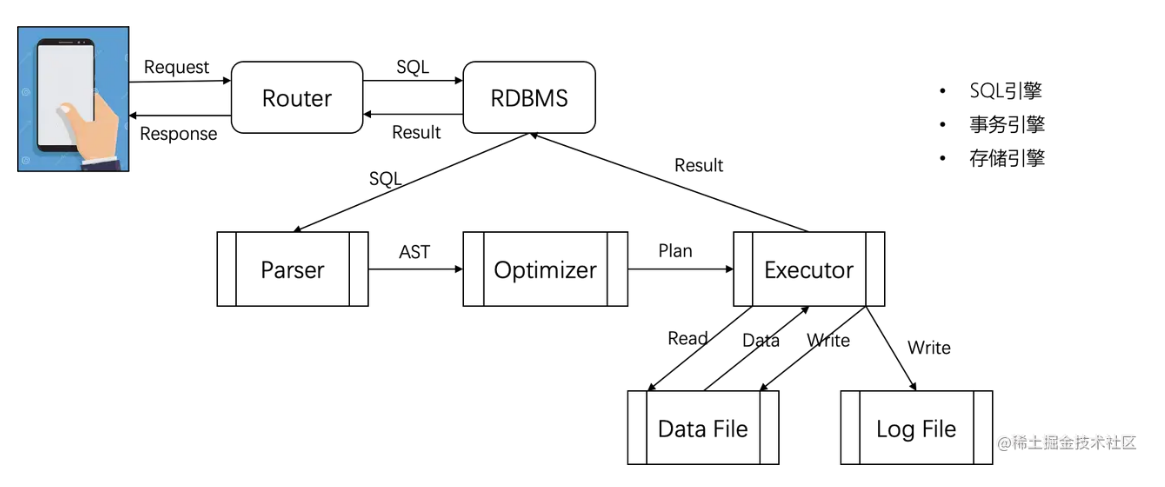
- SQL引擎
- Parser:查询解析,生成语法树,并进行合法性校验(词法分析、语法分析、语义分析)
- Optimizer:根据语法树选择最优执行路径
- Executor:查询执行流程,真实的对数据进行处理
- 事务引擎
- 实现事务的ACID
- 存储引擎
- 存储数据、索引、日志
- 存储数据、索引、日志
项目要求
实现一个内存态数据库 ByteYoungDB,能够支持下面操作:
- Create/Drop Table
- Insert、Delete、Update、Select(CRUD)
- 简单的等值匹配条件
where col = XXX - 支持简单的事务Commit,Rollback
项目设计
项目分解
- 解析用户输入的SQL语句,并进行合法性校验(词法分析、语法分析、语义分析):Parser
- 用户创建的表、列等元信息的管理:MetaData
- 根据SQL语句的语法树,生成计划树:Optimizer
- 根据计划树进行查询执行,这里选择火山模型:Executor
火山模型将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,查询树自顶向下的调用next()接口,数据则自底向上的被拉取处理。
- 内存态数据存储结构设计:Storage
- Commot/Rollback事务支持:Transaction
项目文件结构:
SQL引擎设计
Parser
SQL语言的解析非常的繁复,因此这里“偷懒”,去github上寻找了一个开源的SQL解析器。https://github.com/hyrise/sql-parser
输入是SQL语句,输出是语法树:
但sql-parser库只能提供词法分析和语法分析,生成查询树,不能进行语义分析,也就是合法性校验。因此我们将sql-parser库进行封装,增加语义分析功能:
bool Parser::parseStatement(std::string query) {
result_ = new SQLParserResult;
SQLParser::parse(query, result_);
if (result_->isValid()) {
return checkStmtsMeta();
} else {
std::cout << "[BYDB-Error] Failed to parse sql statement." << std::endl;
}
return true;
}
Optimizer
根据产生的查询树,生成对应的计划树。计划树由各个基础算子组成,针对本项目中要求的场景,构造了如下基础算子:
比如一条UPDATE查询,对应的计划树如下:(该项目未实现index)
Executor
使用火山模型:
依赖计划树生成对应的执行树,每个Plan生成一个对应的Operator。
每个Operator调用next_.exec()来调用下层Operator产生数据:
class BaseOperator {
public:
BaseOperator(Plan* plan, BaseOperator* next) : plan_(plan), next_(next) {}
~BaseOperator() {}
virtual bool exec() = 0;
Plan* plan_;
BaseOperator* next_;
};
存储引擎
数据结构
因为我们是内存态的数据库,所以数据结构可以设计的比较简单。这里每次申请一批记录的内存,这样可以降低内存碎片化的问题,提高内存访问效率。然后将这批记录的内存放到FreeList中。当有数据插入时,从FreeList中获取一块内存用于写入,并放入DataList。当有数据删除时,将数据从DataList归还到FreeList中。
事务引擎
在不考虑并发的情况下,以及数据无需落盘持久化的情况下,我们的事务引擎设计就变得比较简单。因此不需要实现复杂的MVCC机制,只需要能够实现事务的Commit和Rollback功能即可。
这里我们实现一个undo stack的机制,每次更新一行数据,就把这行数据老的版本push到undo stack中。如果事务回滚,那么就从undo stack中把老版本的数据逐个pop出来,恢复到原有的数据中去。
索引设计
因为这里只要求实现等值匹配,所以可以用最简单的hash索引。
项目库
项目搭建
使用大型C/C++项目中最常用的CMake工具。CMake是一种跨平台编译工具。CMake主要是编写CMakeLists.txt文件通过cmake命令将CMakeLists.txt文件转化为make所需要的Makefile文件,最后用make命令编译源码生成可执行程序或者库文件。
cmake_minimum_required(VERSION 3.8)
project(ByteYoungDB)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_COMPILER "g++")
set(CMAKE_CXX_FLAGS "-g -Wall -Werror -std=c++17")
// O0是不做优化,O2会做优化
set(CMAKE_CXX_FLAGS_DEBUG "-O0")
set(CMAKE_CXX_FLAGS_RELEASE "-O2 -DNDEBUG ")
set(CMAKE_INSTALL_PREFIX "install")
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/lib)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/bin)
include_directories(${CMAKE_SOURCE_DIR}/sql-parser/include)
add_subdirectory(src/main)
add_subdirectory(src/sql-parser-test)
参考学习资料:
《CMake Cookbook中文版》 - Bookset
代码仓
编译
linux系统按照README.md中编译
非linux环境,下载sql-parser库代码,make生成libsqlparser.so,替换到ByteYoungDB/sql-parser/lib/libsqlparser.so目录下
收获
parser
分析器支持词法分析、语法分析、语义分析。词法分析和语法分析是借助sql-parser开源项目实现的,本项目在其基础上实现了语义分析
Optimzer
如果有where条件,会生成filter过滤后的一个计划树
如果表结构是a,b,c的顺序,但指定b,c,a输出,那会在优化器这一步去按要求生成对应的计划树
因为本身并没有支持很复杂的查询,所以没有什么优化的
Executor
执行器会先进行初始化,根据分析器生成的plan结构生成对应的operator的结构,深度优先的遍历,先生成最底层的,再依次往上生成
最下层的执行器调用存储引擎的接口去扫描表进行表的操作
执行器根据生成的去执行operator结构,使用火山模型,自顶向下通过next()函数去调用下层,再自底向上去返回结果
存储引擎
存储引擎实现两个链表,跟上文的数据结构中的内容一样
一条数据的结构其实是变长char数组,之后根据计算再去申请其内存大小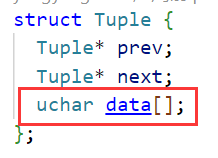
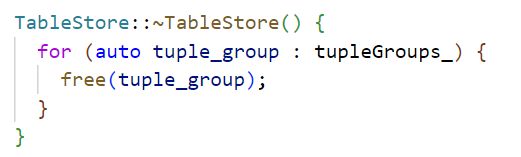
每次申请内存后会存到tupleGroups,方便之后统一进行内存的释放
事务
设计三种undo类型:增删改,是一个栈的数据结构
输入begin,开启事务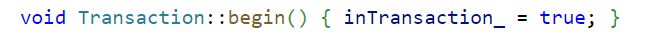
以insert操作为例,在存储引擎中,会判断是否在事务内,如果是,则增加对应操作的undo
如果用户进行rollback,则将undo栈进行pop,去恢复数据
delete操作进行undo数据恢复的时候需要注意将对应的内存放到freelist中供之后操作使用















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









