







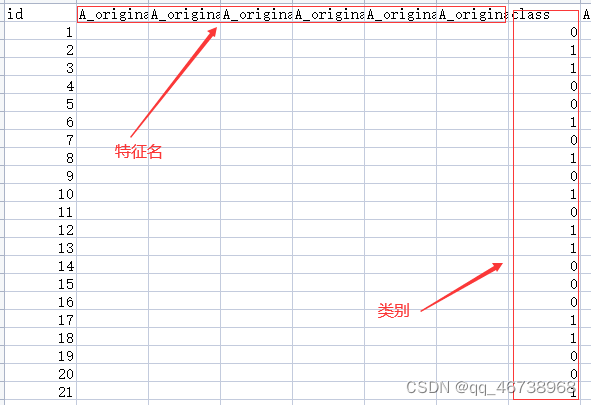
我使用的数据格式如下:
1.1 为什么要进行数据清洗
数据清洗:原始数据往往包含噪声、缺失值和异常值等,这些数据会影响模型的 准确性。通过数据清洗可以去除这些干扰项,提高模型的准确性。
1.2 所使用的库
import numpy as np
import pandas as pd
导入csv数据:
df_A = pd.read_csv((r"C:\**\**\**.csv"))
1.3 将方差为0的特征剔除
代码如下:

1.4 mad异常值检测法
绝对中位差( MedianAbsolute Deviation,MAD) 是一种采用计算各观测值与平均值的距离总和的检测离群值的方法。计算流程:
(1)求出每列中位数MA;
(2)每列减去该中位数并取绝对值得到新的一列;
(3)对新列求中位数MC,则可得MAD = MC * 1.4826;
(4)使用最开始得到的中位数加减MAD倍数:MA±倍数*MAD,超出此范围的数值被认为是异常值。
代码如下:

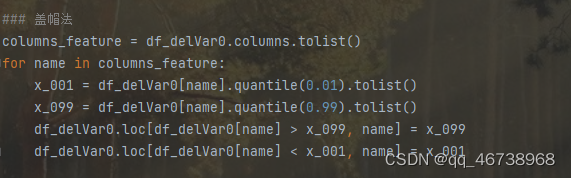
1.5 盖帽法处理异常值
盖帽法:替换数据框里99%以上和1%以下的点,将99%以上的点值=99%的点值;小于1%的点值=1%的点值。
代码如下:
1.6 z-score标准化数据
z-score是用于描述一个数值与其所在数据集均值的差距的统计量,它的作用主要有以下几个方面,我们这里的z-score使用的是第一个标准化数据的作用:
用于标准化数据:z-score可以将数据标准化为具有相同的尺度,方便进行比较和分析。例如,对于一个具有不同单位或不同量级的数据集,可以使用z-score将其转化为标准正态分布,从而比较它们的相对大小。
用于异常值检测:z-score可以帮助识别在数据集中偏离正常值较远的数据点,这些点通常被称为异常值。如果一个数据点的z-score大于某个阈值,则可以将其视为异常值。
用于假设检验:z-score可以用于计算在一个正态分布中一个观察值与其均值之间的差异的概率。这个概率可以用来判断是否需要拒绝某个假设。例如,在医学研究中,可以使用z-score来判断一个药物对患者的治疗效果是否显著。

1.7 使用均值填充NaN值

1.8 还原成原来的数据样式

1.9 代码获取
可以在公众号“python小寒”回复:1325
















 2087
2087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











