






一、使用步骤
1.需求分析
爬取肯德基在中国某一城市的餐厅的名称与地址。
2.目标网址
点此跳转:肯德基餐厅信息查询
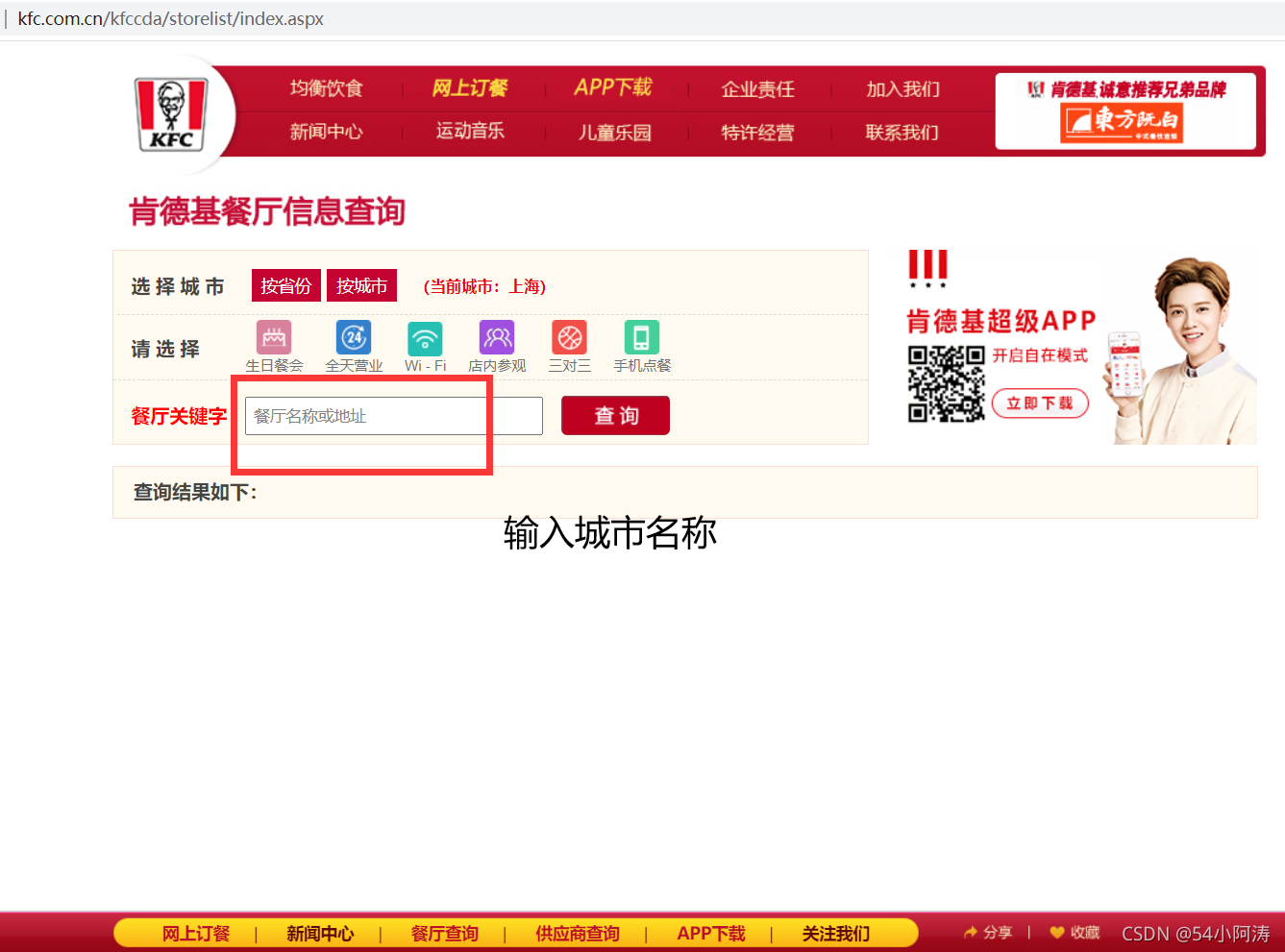
先不要点击“查询”:
抓包:空白处右键-------->检查------>Network:
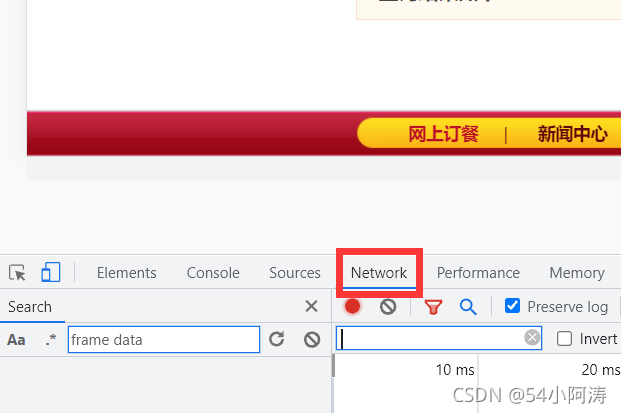
点击“查询”,可以发现页面的地址不变,但是页面的内容改变了。页面中用分页技术显示了该地区的肯德基分店的信息。点击第二页,发现页面的地址也没有变,以上说明这是一个ajax的请求,是异步请求服务器、动态刷新页面。
在确定是ajax后,就可以选择Fetch/XHR而不用选择All,然后选择Headers
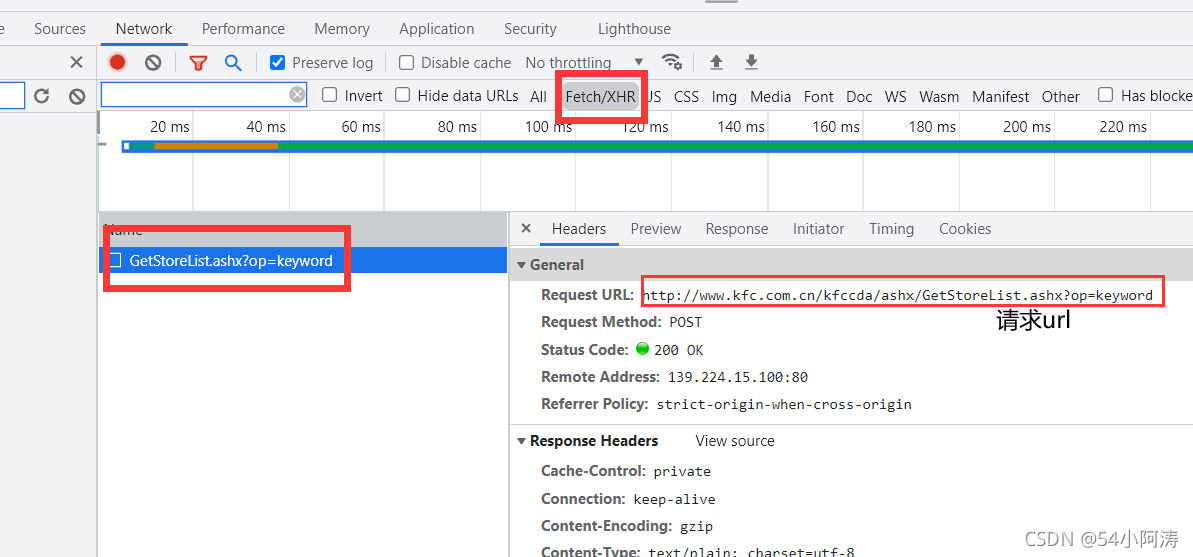 这里可以找到请求URL,以及其请求方式为POST
这里可以找到请求URL,以及其请求方式为POST
继续往下滑,找到Post时携带的参数:
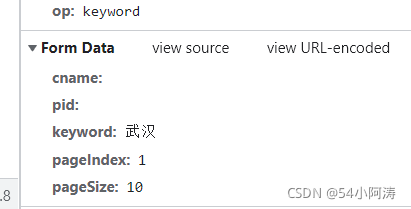
复制参数(空值的参数也要一并复制)
分析参数:
keyword表示要查询的城市;
pageIndex表示要查询的页码,因此我们可以通过修改页码来爬取不同页数的数据;
pageSize:表示一页可以含有多少条数据。

二、代码
import requests
#1.指定url,注意这里不要去掉?op=keyword,否则爬到-1000
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
#2.UA伪装
headers={
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Mobile Safari/537.36'
}
#爬虫函数
def catchinfo(kw,pnum):
#3.post参数处理
param={
"cname":"",
"pid": "",
"keyword": kw, #这个keyword传给url中的OP,所以,url中的op不能去掉
"pageIndex": str(pnum), #页数
"pageSize": "10",
}
#4.发送请求
resp=requests.post(url=url,params=param,headers=headers)
if resp.status_code==200:
print('请求成功')
#5.接收响应
return resp.json()
def main():
#输入要查询的城市
kw=input('please input the city name: ')
#从第一页开始
page=1
print('{}市的所有KFC店:'.format(kw))
#读取所有页
while True:
#调用爬虫
json_data=catchinfo(kw,page)
#当不再有数据时停止循环
if not json_data['Table1']:
print('读取完毕')
break
else:
#写入文本
with open(f'{kw}.txt','a',encoding='utf-8') as fp:
fp.write(str(json_data))
for i in range(len(json_data['Table1'])):
#只输出店名和地址信息,其他存入文本
print('【{}】{}'.format(json_data['Table1'][i]['storeName'],json_data['Table1'][i]['addressDetail']))
page+=1 #进入下一页
if __name__ == '__main__':
main()
结果:
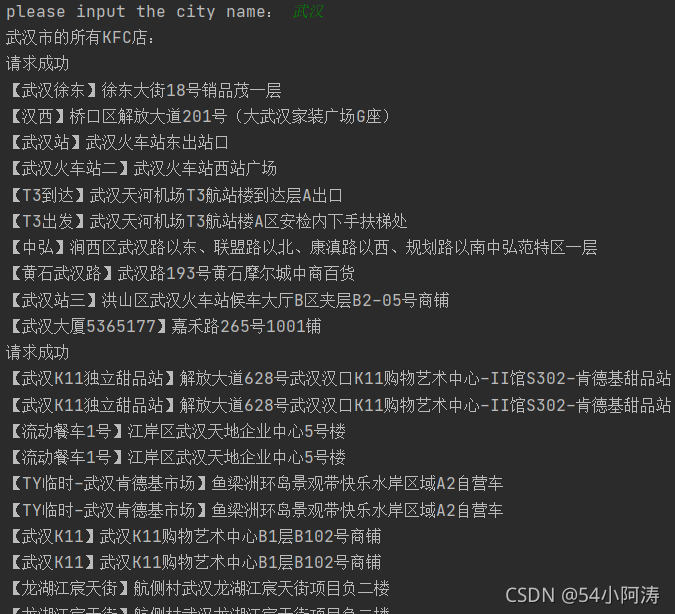
参考:爬虫

















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









