







Kylin(麒麟)的诞生背景
- ebay-中国团队研发的,是第一个真正由中国人自己主导、从零开始、自主研发、并成为Apache顶级开源项目
Hive的性能比较慢,支持SQL灵活查询,特别慢- HBase的性能快,
原生不支持SQL,可以使用phoenix构建二级索引。 - Kylin是将先将数据进行
预处理,将预处理的结果放在HBase中。效率很高
Kylin的应用场景
-
Kylin 典型的应用场景如下:
-
用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
-
每天有数G甚至数十G的数据增量导入
-
有10个以内
较为固定的分析维度 -
Kylin 的核心思想是
利用空间换时间,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存 -
使用kylin的公司

为什么要使用Kylin
- Kylin 是一个 Hadoop 生态圈下的 MOLAP 系统,是 ebay 大数据部门从2014 年开始研发的支持 TB 到 PB 级别数据量的分布式
Olap分析引擎。其特点包括: - 可扩展的超快的 OLAP 引擎
- 提供 ANSI-SQL 接口
- 交互式查询能力
- MOLAP Cube 的概念(立方体)
- 与 BI 工具可无缝整合
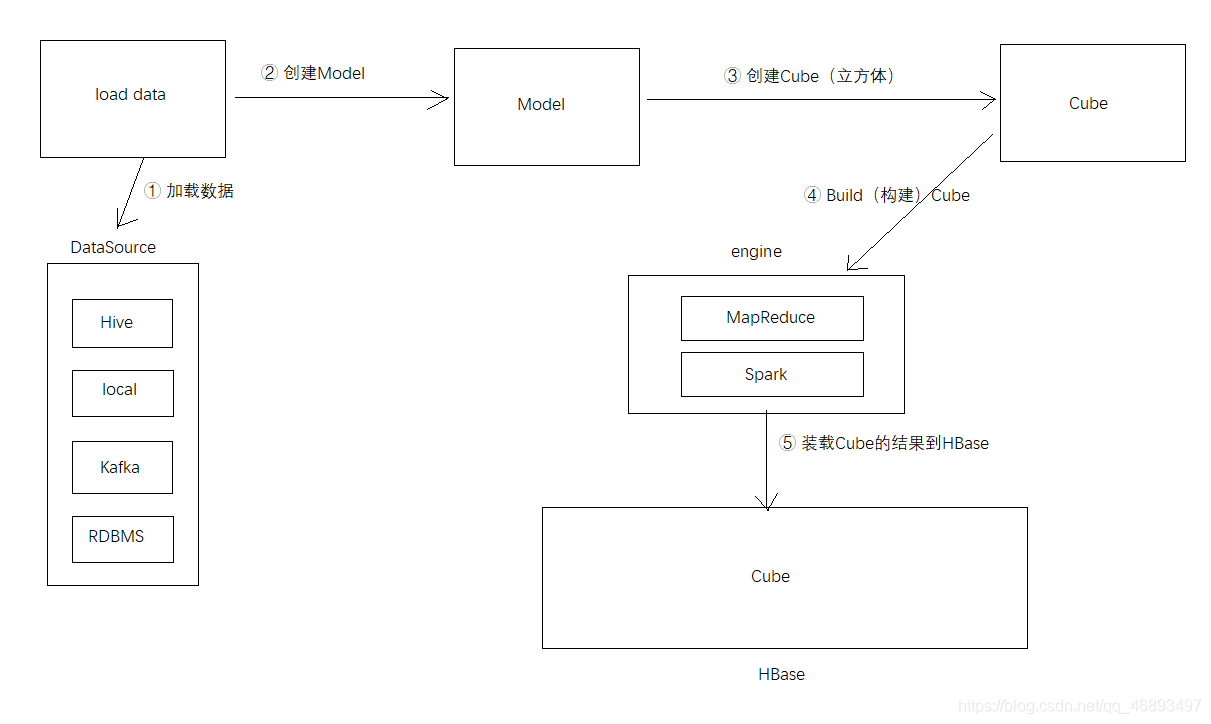
Kylin的总体架构
- Kylin 依赖于 Hadoop、Hive、Zookeeper 和 Hbase
- kylin数据流程图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









