









0 前言
笔者前一篇文章提到多GPU的使用可以有手动设置和分布式机制两种,并对手动设置进行训练做了实验和总结。这一篇笔者就来利用分布式策略进行多GPU分布式训练的实验和总结,希望对读者有所裨益~
1 实战
笔者搭建的开发环境是tensorflow-gpu版本的,具体可见这篇文章。
tensorflow支持的分布式策略可见官方文档,或者略看一下笔者之前学习总结的文章。
现在,万事俱备,咱就直接实战。
1.0 单机单卡实验(baseline.py)
首先,需要做一个单机单卡实验作为对照组,以体现后续分布式训练对训练速度的提升。
1.0.1 基础源码:
### import some neccessary modules
import os
import sys
import time
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
### set gpu self_growth
#tf.debugging.set_log_device_placement(True)### show which device each variable on
gpus = tf.config.experimental.list_physical_devices('GPU')
### set gpu visible
tf.config.experimental.set_visible_devices(gpus[1], 'GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)### set gpu self_growth
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print("the num of gpu", len(gpus))
print("the num of logical gpu", len(logical_gpus))
### load data
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
### normalize data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train [None, 28, 28] --> [None, 784]
x_train_scaler = scaler.fit_transform(x_train.reshape(-1, 784)).reshape(-1, 28, 28, 1) # 最后一维 1,>表示1个通道
x_valid_scaler = scaler.transform(x_valid.reshape(-1, 784)).reshape(-1, 28, 28, 1)
x_test_scaler = scaler.transform(x_test.reshape(-1, 784)).reshape(-1, 28, 28, 1)
### make dataset
def make_dataset(images, labels, epochs, batch_size, shuffle=True):
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if shuffle:
dataset = dataset.shuffle(10000)
# prefetch:表示从数据中预先取出来多少个,来给生成数据作准备。为什么说是用来加速的一个函数?
dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)
return dataset
batch_size = 256
epochs = 100
train_dataset = make_dataset(x_train_scaler, y_train, epochs, batch_size)
### build a model
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
activation='selu',
input_shape=(28, 28, 1)))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
# 一般每进行一次pooling层,图像的大小就会缩小,中间的数据就会大大减少,为减少这种信息的损失,故将filters翻倍。
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
# 展平
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='selu')) # 全链接层
model.add(keras.layers.Dense(10, activation="softmax")) # 全链接层
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.SGD(),
metrics=["accuracy"])
model.summary()
### training
history = model.fit(train_dataset,
steps_per_epoch = x_train_scaler.shape[0] // batch_size,
epochs=10)
1.0.2 运行测试
# 建立一个独立文件夹
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow# mkdir MirroredStrategy
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow# cd MirroredStrategy/
# 创建baseline文件,填入基础源码
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# vim baseline.py
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# ls
baseline.py
# 运行起来
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# python baseline.py
...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 128) 1280
_________________________________________________________________
separable_conv2d (SeparableC (None, 28, 28, 128) 17664
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
_________________________________________________________________
separable_conv2d_1 (Separabl (None, 14, 14, 256) 34176
_________________________________________________________________
separable_conv2d_2 (Separabl (None, 14, 14, 256) 68096
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
separable_conv2d_3 (Separabl (None, 7, 7, 512) 133888
_________________________________________________________________
separable_conv2d_4 (Separabl (None, 7, 7, 512) 267264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 512) 2359808
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 2,887,306
Trainable params: 2,887,306
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
214/214 [==============================] - 9s 37ms/step - loss: 2.3027 - accuracy: 0.0998
Epoch 2/10
214/214 [==============================] - 8s 37ms/step - loss: 2.3028 - accuracy: 0.0979
Epoch 3/10
214/214 [==============================] - 8s 37ms/step - loss: 2.3028 - accuracy: 0.0994
Epoch 4/10
214/214 [==============================] - 8s 37ms/step - loss: 2.3027 - accuracy: 0.0970
Epoch 5/10
214/214 [==============================] - 8s 37ms/step - loss: 2.3027 - accuracy: 0.0961
Epoch 6/10
214/214 [==============================] - 8s 38ms/step - loss: 2.3027 - accuracy: 0.0982
Epoch 7/10
214/214 [==============================] - 8s 38ms/step - loss: 2.3027 - accuracy: 0.0978
Epoch 8/10
214/214 [==============================] - 8s 38ms/step - loss: 2.3027 - accuracy: 0.0965
Epoch 9/10
214/214 [==============================] - 8s 39ms/step - loss: 2.3027 - accuracy: 0.0981
Epoch 10/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3027 - accuracy: 0.0957
1.0.3 结果分析
观察运行输出可知,整个模型大约有300万个参数,大约8s左右会遍历整个数据集一遍。
整个数据集样本数大约55000
≈
\approx
≈ 256(batch_size)*214(batch)
问题:为何准确率只有0.1左右了??模型参数太大了吗
可见,默认情况下,此demo每训练完一轮平均花费8s。
1.1 单机多卡实验(MirroredStrategy)
1.1.1 修改代码
- 将设置一个GPU可见去掉,因为我们得用到所有GPU。
### set gpu self_growth
#tf.debugging.set_log_device_placement(True)### show which device each variable on
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)### set gpu self_growth
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print("the num of gpu", len(gpus))
print("the num of logical gpu", len(logical_gpus))
- 修改数据集
batch_size_per_replica = 256 # make sure 256 samples on 1 device
batch_size = batch_size_per_replica * len(logical_gpus) # total batch_size is the sum
epochs = 100
- 加入分布式策略
### build a model
strategy = tf.distribute.MirroredStrategy()
with strategy.scope(): # the layers of the model and the process of compiling model are all included
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu',
input_shape=(28, 28, 1)))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
# 一般每进行一次pooling层,图像的大小就会缩小,中间的数据就会大大减少,为减少这种信息的损失,故将filters翻倍。
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
# 展平
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='selu')) # 全链接层 128->512
model.add(keras.layers.Dense(10, activation="softmax")) # 全链接层
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.SGD(),
metrics=["accuracy"])
model.summary()
### training
history = model.fit(train_dataset,
steps_per_epoch = x_train_scaler.shape[0] // batch_size,
epochs=10)
- 添加一个画图部分(以下代码不成功)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# define a function
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1) # set the scope of y axis
plt.show()
# draw
plot_learning_curves(history)
# 此句可不用,只是记录在此
# Returns the loss value & metrics values for the model in test mode
model.evaluate(x_test_scaled, y_test)
1.1.2 运行测试
# 复制代码进行分布式修改
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# cp baseline.py single_machine_multi_gpu.py
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# ls
baseline.py single_machine_multi_gpu.py
# 修改代码
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# vim single_machine_multi_gpu.py
# 运行起来
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# python single_machine_multi_gpu.py
Epoch 1/10
107/107 [==============================] - 7s 43ms/step - loss: 2.3027 - accuracy: 0.0971
Epoch 2/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3026 - accuracy: 0.0993
Epoch 3/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3027 - accuracy: 0.0971
Epoch 4/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3026 - accuracy: 0.1009
Epoch 5/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3027 - accuracy: 0.0972
Epoch 6/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3027 - accuracy: 0.0994
Epoch 7/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3026 - accuracy: 0.0970
Epoch 8/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3026 - accuracy: 0.0998
Epoch 9/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3026 - accuracy: 0.0979
Epoch 10/10
107/107 [==============================] - 5s 43ms/step - loss: 2.3027 - accuracy: 0.0972
1.1.3 结果分析
可见,单机双卡进行分布式训练的情况下,此demo每训练完一轮平均花费5s。比单卡训练提升了将近一倍
1.2 多机多卡同步训练(MultiWorkerMirroredStrategy)
1.2.1 修改代码1
### import some neccessary modules
import os
import sys
import time
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from tensorflow import keras
# Set TF_CONFIG
import json
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["172.17.0.2:12345", "172.17.0.3:23456"]
},
'task': {'type': 'worker', 'index': 0}
})
# Open a strategy scope
strategy = tf.distribute.MultiWorkerMirroredStrategy()
### set gpu self_growth
#tf.debugging.set_log_device_placement(True)### show which device each variable on
gpus = tf.config.experimental.list_physical_devices('GPU')
### set gpu visible
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)### set gpu self_growth
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print("the num of gpu", len(gpus))
print("the num of logical gpu", len(logical_gpus))
### load data
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
### normalize data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train [None, 28, 28] --> [None, 784]
x_train_scaler = scaler.fit_transform(x_train.reshape(-1, 784)).reshape(-1, 28, 28, 1)
x_valid_scaler = scaler.transform(x_valid.reshape(-1, 784)).reshape(-1, 28, 28, 1)
x_test_scaler = scaler.transform(x_test.reshape(-1, 784)).reshape(-1, 28, 28, 1)
### make dataset
def make_dataset(images, labels, epochs, batch_size, shuffle=True):
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if shuffle:
dataset = dataset.shuffle(10000)
dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)
return dataset
batch_size = 256
epochs = 100
train_dataset = make_dataset(x_train_scaler, y_train, epochs, batch_size)
### build a model
with strategy.scope(): # the layers of the model and the process of compiling model are all included
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu',
input_shape=(28, 28, 1)))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.SGD(),
metrics=["accuracy"])
model.summary()
### training
history = model.fit(train_dataset,
steps_per_epoch = x_train_scaler.shape[0] // batch_size,
epochs=10)
1.2.2 修改代码2
修改代码1之后,单独一台先开始运行是没有问题的,先开始的那台会等第二台开始运行,但第二台开始后两台机器同时训练时还是会报错。
报错信息如下:
...
2022-06-15 13:26:12.416728: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:301] Initialize GrpcChannelCache for job worker -> {0 -> 172.17.0.2:12345, 1 -> 172.17.0.3:23456}
2022-06-15 13:26:12.416967: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc://172.17.0.2:12345
Traceback (most recent call last):
File "two_machine_worker01.py", line 30, in <module>
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
File "/environments/tf2_py3/lib/python3.6/site-packages/tensorflow/python/framework/config.py", line 510, in set_visible_devices
context.context().set_visible_devices(devices, device_type)
File "/environments/tf2_py3/lib/python3.6/site-packages/tensorflow/python/eager/context.py", line 1411, in set_visible_devices
"Visible devices cannot be modified after being initialized")
RuntimeError: Visible devices cannot be modified after being initialized
所以是GPU设置那一块出现了问题。
多方尝试,包括
- 只设置自增长不设置指定设备可见,同样会报错:
RuntimeError: Physical devices cannot be modified after being initialized - 甚至全部隐去GPU设置相关的代码,运行后报错:
...
2022-06-15 14:06:40.989257: E tensorflow/stream_executor/cuda/cuda_blas.cc:226] failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED
2022-06-15 14:06:41.940360: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2022-06-15 14:06:42.046350: E tensorflow/stream_executor/cuda/cuda_dnn.cc:336] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
...
tensorflow.python.framework.errors_impl.UnknownError: 3 root error(s) found.
(0) Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node sequential/conv2d/Conv2D (defined at usr/lib/python3.6/threading.py:916) ]]
[[GroupCrossDeviceControlEdges_0/Identity_6/_93]]
(1) Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node sequential/conv2d/Conv2D (defined at usr/lib/python3.6/threading.py:916) ]]
(2) Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node sequential/conv2d/Conv2D (defined at usr/lib/python3.6/threading.py:916) ]]
[[update_0/AssignAddVariableOp/_81]]
0 successful operations.
0 derived errors ignored. [Op:__inference_train_function_2183]
Function call stack:
train_function -> train_function -> train_function
failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED和Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR:这两个错误都是在说明 显存不够,因此自增长还是需要的。
1.2.3 修改代码3
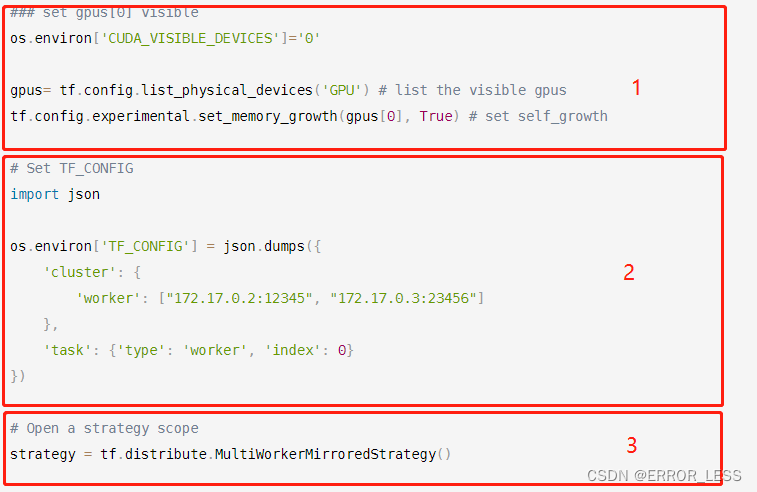
由于是设置指定设备可见或自增长与分布式策略实例化谁先谁后的问题,因此我决定换一种方式进行指定GPU可见并设置自增长。
具体代码如下:
### import some neccessary modules
import os
import sys
import time
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from tensorflow import keras
### set gpus[0] visible
os.environ['CUDA_VISIBLE_DEVICES']='0'
gpus= tf.config.list_physical_devices('GPU') # list the visible gpus
tf.config.experimental.set_memory_growth(gpus[0], True) # set self_growth
# Set TF_CONFIG
import json
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["172.17.0.2:12345", "172.17.0.3:23456"]
},
'task': {'type': 'worker', 'index': 0}
})
# Open a strategy scope
strategy = tf.distribute.MultiWorkerMirroredStrategy()
### set gpu self_growth
#tf.debugging.set_log_device_placement(True)### show which device each variable on
#gpus = tf.config.experimental.list_physical_devices('GPU')
### set gpu visible
#tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
#for gpu in gpus:
# tf.config.experimental.set_memory_growth(gpu, True)### set gpu self_growth
#logical_gpus = tf.config.experimental.list_logical_devices('GPU')
#print("the num of gpu", len(gpus))
#rint("the num of logical gpu", len(logical_gpus))
### load data
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
### normalize data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train [None, 28, 28] --> [None, 784]
x_train_scaler = scaler.fit_transform(x_train.reshape(-1, 784)).reshape(-1, 28, 28, 1)
x_valid_scaler = scaler.transform(x_valid.reshape(-1, 784)).reshape(-1, 28, 28, 1)
x_test_scaler = scaler.transform(x_test.reshape(-1, 784)).reshape(-1, 28, 28, 1)
### make dataset
def make_dataset(images, labels, epochs, batch_size, shuffle=True):
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if shuffle:
dataset = dataset.shuffle(10000)
dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)
return dataset
batch_size = 256 * 2
epochs = 100
train_dataset = make_dataset(x_train_scaler, y_train, epochs, batch_size)
### build a model
with strategy.scope(): # the layers of the model and the process of compiling model are all included
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu',
input_shape=(28, 28, 1)))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, # 32->128
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=256, kernel_size=3, # 64->256
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=512, kernel_size=3, # 128->512
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.SGD(),
metrics=["accuracy"])
model.summary()
### training
history = model.fit(train_dataset,
steps_per_epoch = x_train_scaler.shape[0] // batch_size,
epochs=10)
注意:一下三部分的顺序不能错,否则会报错。
1.2.4 运行测试3
(tf2_py3) root@4553a63d0dd6:/share/distributed tensorflow/MultiWorkerMirroredStrategy# python two_machine_worker02.py
...
2022-06-16 01:57:56.572001: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:worker/replica:0/task:1/device:GPU:0 with 10261 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce GTX 1080 Ti, pci bus id: 0000:04:00.0, compute capability: 6.1)
2022-06-16 01:57:56.573728: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:301] Initialize GrpcChannelCache for job worker -> {0 -> 172.17.0.2:12345, 1 -> 172.17.0.3:23456}
2022-06-16 01:57:56.574024: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc://172.17.0.3:23456
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 128) 1280
_________________________________________________________________
separable_conv2d (SeparableC (None, 28, 28, 128) 17664
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
_________________________________________________________________
separable_conv2d_1 (Separabl (None, 14, 14, 256) 34176
_________________________________________________________________
separable_conv2d_2 (Separabl (None, 14, 14, 256) 68096
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
separable_conv2d_3 (Separabl (None, 7, 7, 512) 133888
_________________________________________________________________
separable_conv2d_4 (Separabl (None, 7, 7, 512) 267264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 512) 2359808
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 2,887,306
Trainable params: 2,887,306
Non-trainable params: 0
_________________________________________________________________
2022-06-16 01:57:58.157235: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:656] In AUTO-mode, and switching to DATA-based sharding, instead of FILE-based sharding as we cannot find appropriate reader dataset op(s) to shard. Error: Found an unshardable source dataset: name: "TensorSliceDataset/_2"
op: "TensorSliceDataset"
input: "Placeholder/_0"
input: "Placeholder/_1"
attr {
key: "Toutput_types"
value {
list {
type: DT_DOUBLE
type: DT_UINT8
}
}
}
attr {
key: "output_shapes"
value {
list {
shape {
dim {
size: 28
}
dim {
size: 28
}
dim {
size: 1
}
}
shape {
}
}
}
}
...
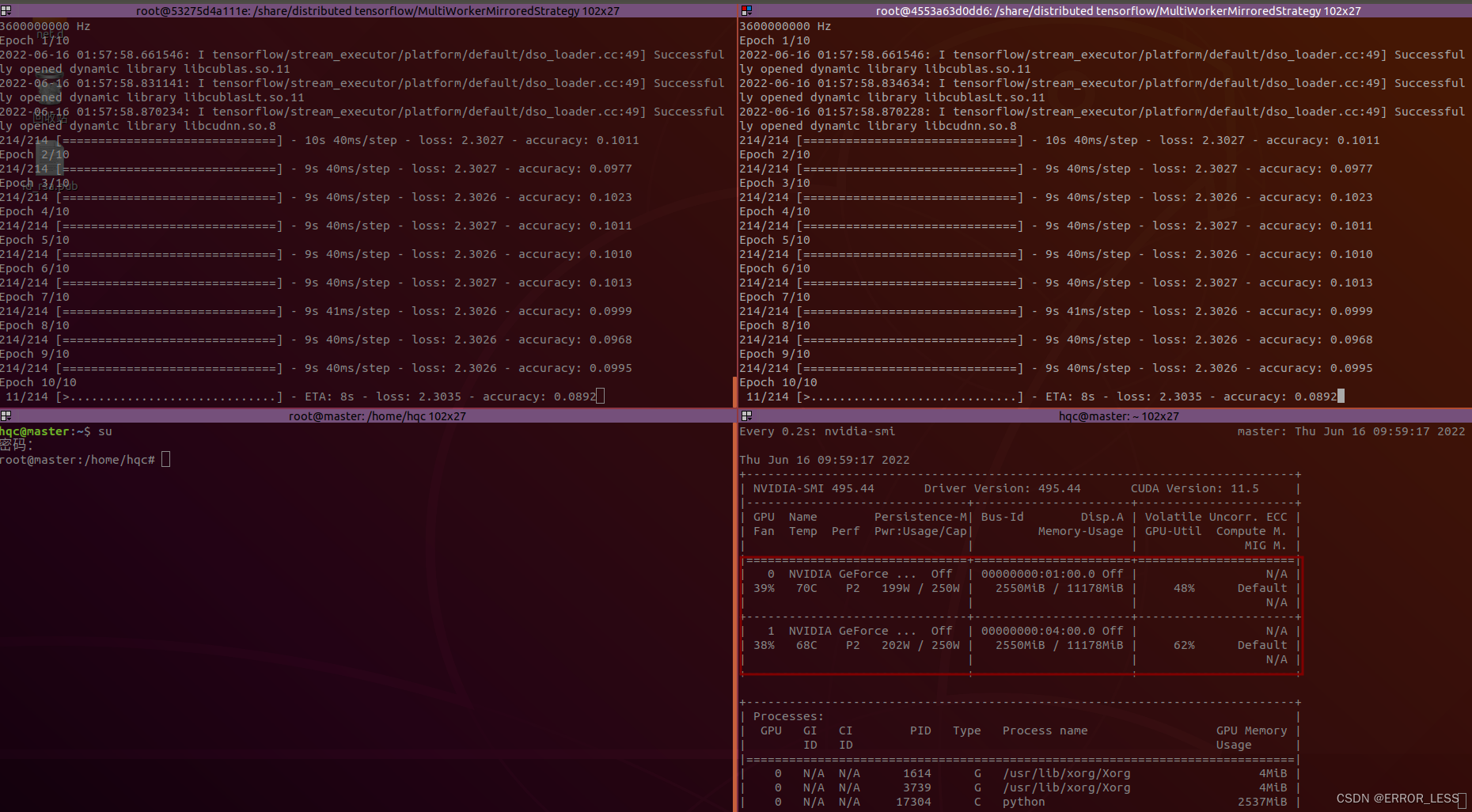
Epoch 1/10
214/214 [==============================] - 10s 40ms/step - loss: 2.3027 - accuracy: 0.1011
Epoch 2/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3027 - accuracy: 0.0977
Epoch 3/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3026 - accuracy: 0.1023
Epoch 4/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3027 - accuracy: 0.1011
Epoch 5/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3026 - accuracy: 0.1010
Epoch 6/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3027 - accuracy: 0.1013
Epoch 7/10
214/214 [==============================] - 9s 41ms/step - loss: 2.3026 - accuracy: 0.0999
Epoch 8/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3026 - accuracy: 0.0968
Epoch 9/10
214/214 [==============================] - 9s 40ms/step - loss: 2.3026 - accuracy: 0.0995
Epoch 10/10
214/214 [==============================] - 9s 41ms/step - loss: 2.3027 - accuracy: 0.0992
1.2.5 结果分析3
发现训练完一轮平均花费9s,比单机训练平均8s还多,为什么呢?
- 多1秒可能花费在两台机器间的通信上
- 而未体现分布式的优势可能是两台机器各自训练,并未聚合参数之后再更新啥的,因此基础训练时间就花费了8s,再加上两台机器之间的通信延迟1s,最终变为9s。
因此,可能还需要修改代码,体现分布式的优势。
1.2.6 修改代码4
将baseline.py和two_machine_worker01.py、two_machine_worker02.py中每轮训练的batch_size调大,这样就更能体现分布式训练的优势。
将以上3个文件中的batch_size加倍变为512。
1.2.7 运行测试4
运行baseline.py
(tf2_py3) root@53275d4a111e:/share/distributed tensorflow/MirroredStrategy# python baseline.py
...
2022-06-16 02:40:15.547549: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10261 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce GTX 1080 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1)
the num of gpu 2
the num of logical gpu 1
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 128) 1280
_________________________________________________________________
separable_conv2d (SeparableC (None, 28, 28, 128) 17664
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
_________________________________________________________________
separable_conv2d_1 (Separabl (None, 14, 14, 256) 34176
_________________________________________________________________
separable_conv2d_2 (Separabl (None, 14, 14, 256) 68096
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
separable_conv2d_3 (Separabl (None, 7, 7, 512) 133888
_________________________________________________________________
separable_conv2d_4 (Separabl (None, 7, 7, 512) 267264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 512) 2359808
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 2,887,306
Trainable params: 2,887,306
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
107/107 [==============================] - 10s 76ms/step - loss: 2.3026 - accuracy: 0.1019
Epoch 2/10
107/107 [==============================] - 8s 77ms/step - loss: 2.3026 - accuracy: 0.0971
Epoch 3/10
107/107 [==============================] - 8s 77ms/step - loss: 2.3026 - accuracy: 0.0992
Epoch 4/10
107/107 [==============================] - 8s 77ms/step - loss: 2.3027 - accuracy: 0.0982
Epoch 5/10
107/107 [==============================] - 8s 77ms/step - loss: 2.3026 - accuracy: 0.0964
Epoch 6/10
107/107 [==============================] - 8s 77ms/step - loss: 2.3026 - accuracy: 0.0989
Epoch 7/10
107/107 [==============================] - 9s 81ms/step - loss: 2.3026 - accuracy: 0.1006
Epoch 8/10
107/107 [==============================] - 9s 82ms/step - loss: 2.3026 - accuracy: 0.0993
Epoch 9/10
107/107 [==============================] - 9s 82ms/step - loss: 2.3026 - accuracy: 0.0995
Epoch 10/10
107/107 [==============================] - 9s 80ms/step - loss: 2.3026 - accuracy: 0.0994
可见,训练完一轮平均要花费9s左右,每一步花费80ms左右
运行分布式策略:
(tf2_py3) root@4553a63d0dd6:/share/distributed tensorflow/MultiWorkerMirroredStrategy# python two_machine_worker02.py
...
2022-06-16 02:37:26.436193: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:301] Initialize GrpcChannelCache for job worker -> {0 -> 172.17.0.2:12345, 1 -> 172.17.0.3:23456}
2022-06-16 02:37:26.436514: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc://172.17.0.3:23456
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 128) 1280
_________________________________________________________________
separable_conv2d (SeparableC (None, 28, 28, 128) 17664
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
_________________________________________________________________
separable_conv2d_1 (Separabl (None, 14, 14, 256) 34176
_________________________________________________________________
separable_conv2d_2 (Separabl (None, 14, 14, 256) 68096
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
separable_conv2d_3 (Separabl (None, 7, 7, 512) 133888
_________________________________________________________________
separable_conv2d_4 (Separabl (None, 7, 7, 512) 267264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 512) 2359808
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 2,887,306
Trainable params: 2,887,306
Non-trainable params: 0
_________________________________________________________________
...
Epoch 1/10
107/107 [==============================] - 8s 58ms/step - loss: 2.3026 - accuracy: 0.0964
Epoch 2/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.0998
Epoch 3/10
107/107 [==============================] - 6s 57ms/step - loss: 2.3026 - accuracy: 0.0982
Epoch 4/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.0978
Epoch 5/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3027 - accuracy: 0.1006
Epoch 6/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.1032
Epoch 7/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3027 - accuracy: 0.0999
Epoch 8/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.1015
Epoch 9/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.0959
Epoch 10/10
107/107 [==============================] - 6s 58ms/step - loss: 2.3026 - accuracy: 0.0991
可见,每轮训练完平均花费6s,每步平均花费58ms。
1.2.8 结果分析4
batch_size = 256
| 单机单卡 | 双机双卡 | |
|---|---|---|
| 每轮训练时间 | 8s | 9s |
| 每步训练时间 | 38ms | 40ms |
batch_size = 256 * 2
| 单机单卡 | 双机双卡 | |
|---|---|---|
| 每轮训练时间 | 9s | 6s |
| 每步训练时间 | 78ms | 58ms |
结论:
- 在每轮训练数据量越大时,多机多卡相对于单机单卡的优势就越明显。
- 双机双卡比单机单卡能提升小于一倍的训练效率,原因时多机之间有通信时延的考虑。















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









