






MySQL基础回顾
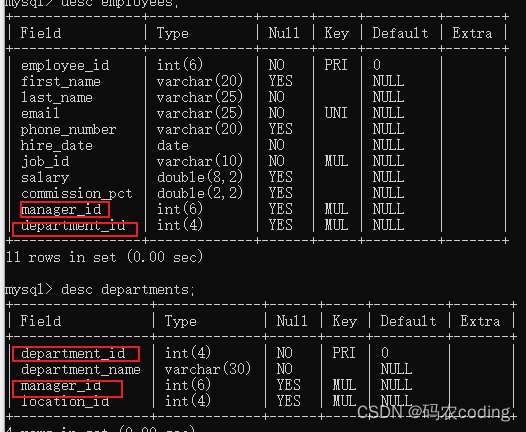
一,MySQL安装和卸载
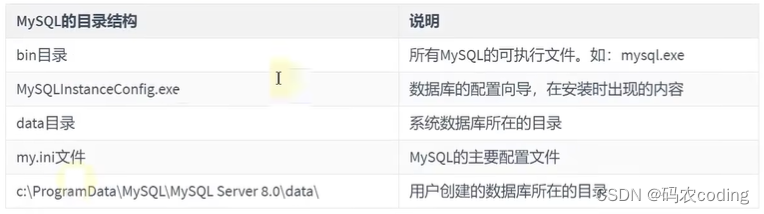
(一)主要目录结构
二,SQL语言
(一)SQL的分类
-
DDL:数据定义语言。CREATE \ ALTER \ DROP \ REANME \ TRUNCATE
-
DML:数据操作语言。INSERT \ DELETE \ UPDATE \ SELECT
-
DCL:数据控制语言。COMMIT \ ROLLBACK \ SAVEPOINT \ GRANT \ REVOKE
-
DQL:数据查询语言。
-
TCL:事务控制语言。
(二)注释
#单行注释(MySQL独有方式)
-- 单行注释(--后面必须有一个空格)
/* 多行注释 */
(三)DQL
1.最基本的SELECT语句
SELECT 1+1;
SELECT 1+1 FROM DUAL; # DUAL为伪表
SELECT * FROM employees; # *为表中所有字段
- 列的别名:
- 字段名 别名(中间有空格)。
- 字段名 as 别名。
- 字段名 “别名”(中间有空格),列的别名使用“”引起来,不要使用‘’。
- 去除重复行:
# 查询员工表中一共有那些部门?
SELECT DISTINCT department_id FROM employees;
- NULL参与运算:
- NULL不等同与0,‘’,‘NULL’。
- NULL参与运算:结果一定也为NULL。
- 着重号``:表名,字段名和关键字冲突,使用着重号进行区分。
# ORDER为排序关键字
SELECT * FROM `order`;
- 查询常数
SELECT '尚硅谷';
- 显示表结构:显示了表中字段的详细信息
DESCRIBE employees;
DESC employees;
2.使用WHERE过滤数据
SELECT 字段1,字段2 FROM 表名 WHERE 过滤条件
3.排序
- 如果没有使用排序操作,默认情况下查询返回的数据是按照添加数据的顺序来显示的。
- 使用ORDER BY对查询到的数据进行排序。
- 升序:ASC
- 降序:DESC
- 如果在ORDER BY没有显示指定排序的方式的话,则默认是升序(ASC)排列。
- 列的别名只能在ORDER BY中使用,不能再WHERE中使用。
- WHERE声明再FROM后,ORDER BY之前。
## 按照salary从高到低的顺序来显示员工信息(降序)
SELECT
e.first_name,
e.last_name,
e.salary
FROM
employees e
ORDER BY
e.salary DESC;
# 按照salary从低到高的顺序来显示员工信息(升序)
SELECT
e.first_name,
e.last_name,
e.salary
FROM
employees e
ORDER BY
e.salary ASC;
# 按照年薪从高到底进行排序(别名实现)
SELECT
e.first_name,
e.last_name,
e.salary * ( 1 + IFNULL( NULL, 0 ) ) * 12 AS year_sal
FROM
employees e
ORDER BY
year_sal DESC;
# 显示员工信息,按照department_id降序排列,salary的升序排列
SELECT
e.first_name,
e.last_name,
e.department_id,
e.salary
FROM
employees e
ORDER BY
e.department_id DESC,
e.salary ASC;
4.分页
- 需求:每页显示pageSize条记录,此时显示pageNo页。
- 公式:LIMIT (pageNo - 1) * pageSize,pageSize;
- 声明顺序:
- WHERE
- ORDER BY
- LIMIT
- LIMIT格式:
- 严格来说:LIMIT 位置偏移量,条目数。
- 结构“LIMIT 0,条目数”等价于“LIMIT 条目数”。
- MySQL8.0新特性:LIMIT a OFFSIZE b(b为偏移量,a为条目数)。
# 每页显示20条记录,此时显示第一页
SELECT
*
FROM
employees
LIMIT 0,
20;
# 每页显示20条记录,此时显示第三页
SELECT
*
FROM
employees
LIMIT 40,
20;
# 查询salary大于6000,按照salary降序排列,每页显示10条,显示第二页
SELECT
*
FROM
employees
WHERE
salary > 6000
ORDER BY
salary DESC
LIMIT 10,
10;
# 查询员工表薪资最高的员工信息
SELECT
*
FROM
employees
ORDER BY
salary DESC
LIMIT 0,
1;
5.多表查询
- 分类:
- 角度一:
- 等值连接
- 非等值连接
- 角度二:
- 自连接
- 非自连接
- 角度三:
- 内连接
- 外连接
- 左外连接
- 右外连接
- 满外连接
- 角度一:
5.1.交叉连接(笛卡尔积)
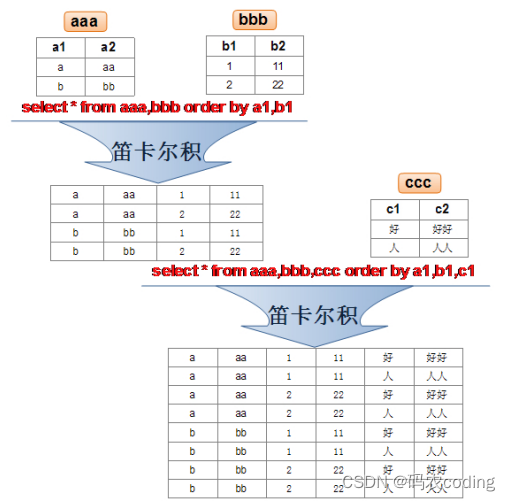
- 交叉连接:表中的所有行相互连接,并没有实际意义。
SELECT
e.employee_id,
d.department_name
FROM
employees e,
departments d;
- 为了避免笛卡尔积可以在WHERE加入有效的连接条件,
连接 n个表,至少需要n-1个连接条件。
SELECT
e.employee_id,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id;
5.2.等值连接和非等值连接
- 等值连接示例:
# 查询出公司员工的 last_name,department_name, city
SELECT
e.last_name,
d.department_name,
l.city
FROM
employees e,
departments d,
locations l
WHERE
e.department_id = d.department_id
AND d.location_id = l.location_id;
- 非等值连接示例:
# 查询所有员工的薪资等级
SELECT
e.last_name,
j.grade_level,
e.salary
FROM
employees e,
job_grades j
WHERE
e.salary BETWEEN j.lowest_sal
AND j.highest_sal;
5.3.自连接和非自连接
- 自连接示例:
# 查询所有员工的manger的姓名
SELECT
e1.last_name,
e2.last_name manger
FROM
employees e1,
employees e2
WHERE
e1.manager_id = e2.employee_id;
- 非自连接示例:以上除了自连接示例之外,其余案例均为非自连接。
5.4.内连接和外连接
- 内连接: 合并具有同一列的两个以上的表的行,
结果集中不包含一个表与另一个表不匹配的行。 - 外连接: 两个表在连接过程中除了返回满足连接条件的行以外
还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。 - SQL99语法中:内连接的INNER和外连接的OUTER关键字都可以省略。
- MySQL不支持SQL92语法实现外连接,只支持SQL99语法实现外连接(不包括满外连接,不支持满外连接)。
- 内连接示例:
# 查询出公司员工的姓名和对应部门名
# 1.SQL92内连接
SELECT
e.employee_id,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id;
# 2.SQL99内连接
SELECT
e.employee_id,
d.department_name
FROM
employees e
INNER JOIN departments d ON e.department_id = d.department_id;
- 外连接示例:
# 查询出公司所有员工的姓名和对应部门名
# 1.SQL92外连接,MySQL并不支持此种写法
SELECT
e.employee_id,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id(+) = d.department_id;
# 2.SQL99外连接
SELECT
e.employee_id,
d.department_name
FROM
employees e
LEFT OUTER JOIN departments d ON e.department_id = d.department_id;
SELECT
e.employee_id,
d.department_name
FROM
departments d
RIGHT OUTER JOIN employees e ON e.department_id = d.department_id;
- 满外连接:
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN。
SELECT
e.employee_id,
d.department_name
FROM
employees e
FULL OUTER JOIN departments d ON e.department_id = d.department_id;
5.5.UNION和UNION ALL
- 利用UNION和UNION ALL关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。
- UNION和UNION ALL的区别:
- UNION 操作符返回两个查询的结果集的并集,去除重复记录。
- UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
5.6.七种JOIN的实现
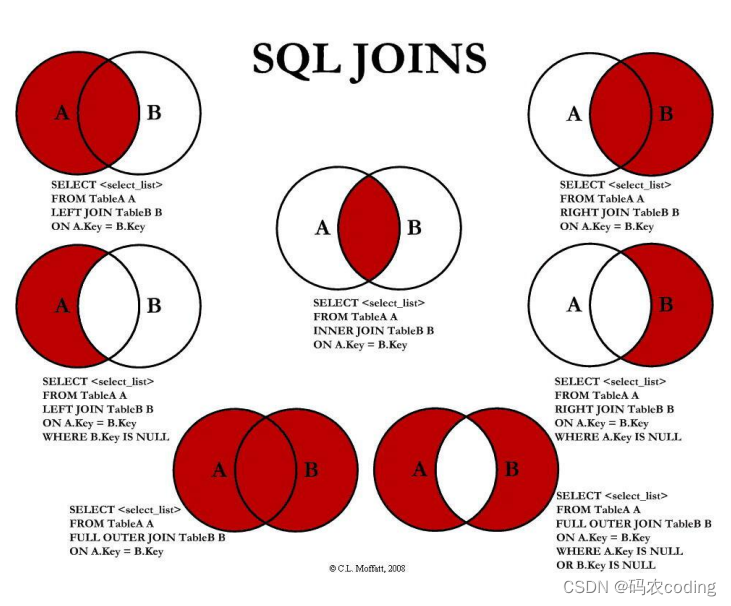
- 中图:
# 中图(共106条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
INNER JOIN departments d ON e.department_id = d.department_id;
- 左上图:
# 左上图(共107条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
LEFT OUTER JOIN departments d ON e.department_id = d.department_id;
- 右上图:
# 右上图(共122条记录,没有人加入的部门共122-106个)
SELECT
e.last_name,
d.department_name
FROM
employees e
RIGHT OUTER JOIN departments d ON e.department_id = d.department_id;
- 左中图:
# 左中图(共1条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id
WHERE
d.department_id IS NULL;
- 右中图:
# 右中图(共16条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
RIGHT JOIN departments d ON e.department_id = d.department_id
WHERE
e.department_id IS NULL;
- 左下图:
# 左下图(共1+106+16条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id UNION ALL
SELECT
e.last_name,
d.department_name
FROM
employees e
RIGHT JOIN departments d ON e.department_id = d.department_id
WHERE
e.department_id IS NULL;
SELECT
e.last_name,
d.department_name
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id
WHERE
d.department_id IS NULL UNION ALL
SELECT
e.last_name,
d.department_name
FROM
employees e
RIGHT OUTER JOIN departments d ON e.department_id = d.department_id;
- 右下图:
# 右下图(共1+16条记录)
SELECT
e.last_name,
d.department_name
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id
WHERE
d.department_id IS NULL UNION ALL
SELECT
e.last_name,
d.department_name
FROM
employees e
RIGHT JOIN departments d ON e.department_id = d.department_id
WHERE
e.department_id IS NULL;
5.7.SQL99语法新特性
- 自然连接(NATURAL JOIN):自动查询两张连接表中
所有相同的字段,然后进行等值连接,省去了连接条件 。
# SQL92标准中:
SELECT
e.employee_id,
e.last_name,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id
AND e.manager_id = d.manager_id;
# SQL99标准中:
SELECT
e.employee_id,
e.last_name,
d.department_name
FROM
employees e
NATURAL JOIN departments d;
- USING连接:
指定数据表里的同名字段进行等值连接。但是只能配合JOIN一起使用。
# SQL92标准中:
SELECT
e.employee_id,
e.last_name,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id;
# SQL99标准中:
SELECT
e.employee_id,
e.last_name,
d.department_name
FROM
employees e
JOIN departments d USING ( department_id );
6.分组

- 分组之后数据会聚合。
GROUP BY 声明在FROM后面,WHERE后面,ORDER BY前面,LIMIT前面。
# 查询各个部门的平均工资,最高工资
SELECT
d.department_name '名称',
avg( e.salary ) '平均工资',
max( e.salary ) '最高工资'
FROM
employees e
INNER JOIN departments d ON e.department_id = d.department_id
GROUP BY
e.department_id;
# 查询各个department_id,job_id的平均工资(两种方式)
SELECT
avg( e.salary ),
e.department_id,
e.job_id
FROM
employees e
GROUP BY
e.department_id,
e.job_id;
SELECT
avg( e.salary ),
e.department_id,
e.job_id
FROM
employees e
GROUP BY
e.job_id,
e.department_id;
# 查询各个部门的平均工资,按照平均工资升序排列
SELECT
d.department_name '名称',
avg( e.salary ) '平均工资',
max( e.salary ) '最高工资'
FROM
employees e
INNER JOIN departments d ON e.department_id = d.department_id
GROUP BY
e.department_id
ORDER BY
平均工资 ASC;
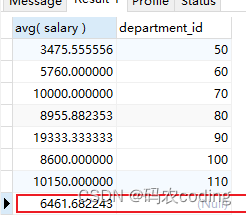
- WTIH ROLLUP会将整个表中的所有数据做一次整体聚合。
SELECT
avg( salary ),
department_id
FROM
employees
GROUP BY
department_id WITH ROLLUP;
SELECT
avg( salary )
FROM
employees;

- 当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
SELECT
avg( salary ) avgsal,
department_id
FROM
employees
GROUP BY
department_id WITH ROLLUP
ORDER BY
avgsal;
/* 错误信息:
SELECT
avg( salary ) avgsal,
department_id
FROM
employees
GROUP BY
department_id WITH ROLLUP
ORDER BY
avgsal
> 1221 - Incorrect usage of CUBE/ROLLUP and ORDER BY
> Time: 0s
*/
- SELECT中出现的分组函数的字段必须声明在GROUP BY中。反之,GROUP BY中声明的字段可以不出现在SELECT中。
# 正确情况
SELECT
AVG( salary ),
department_id
FROM
employees
GROUP BY
department_id;
# 错误情况:last_name字段不是声明在GROUP BY中的字段,虽然在MySQL可以查询出结果,但是数据结果是错误的。
SELECT
AVG( salary ),
last_name
FROM
employees
GROUP BY
department_id;
7.HAVING的使用
- 如果过滤条件中使用了聚合函数,则必须使用HAVING替换WHERE,否则报错。
- HAVING必须声明在GROUP BY的后面。
- 开发中,我们使用HAVING的前提是SQL中使用了GROUP BY。
# 查询各个部门的最高工资比10000高的部门信息
# 错误写法:
SELECT
department_id
FROM
employees
WHERE
max( salary ) > 10000
GROUP BY
department_id;
/*
select department_id from employees where max(salary) > 10000 GROUP BY department_id
> 1111 - Invalid use of group function
> Time: 0.001s
*/
# 正确写法:
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
max( salary ) > 10000;
- WHERE和HAVING的选择:
- 当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
WHERE过滤条件中不能使用聚合函数。 - 当过滤条件中没有聚合函数时,则此过滤条件必须声明在WHERE中或HAVING中都可以。但是,建议声明在HAVING中。
- 当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
- WHERE和HAVING的对比:
# 查询部门id为10,20,30,40的最高工资比10000高的部门信息
# 方式1(推荐,执行效率高于方式1):
SELECT
department_id
FROM
employees
WHERE
department_id IN ( 10, 20, 30, 40 )
GROUP BY
department_id
HAVING
max( salary ) > 10000;
# 方式2:
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
department_id IN ( 10, 20, 30, 40 ) AND max( salary ) > 10000;
8.子查询
- 子查询在主查询之前一次执行完成。
- 子查询的结果被主查询使用。
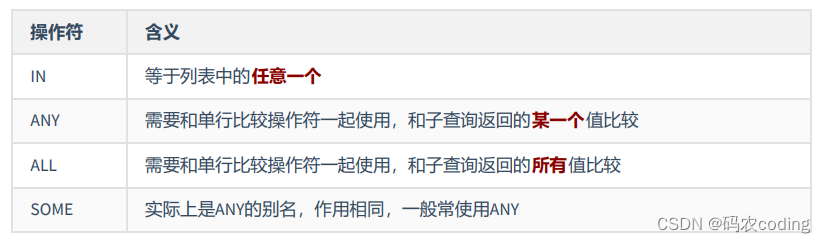
- 子查询要包含在括号内,单行操作符对应单行子查询,多行操作符对应多行子查询。
- 子查询分类:
- 从内查询返回结果的条目数:单行子查询和多行子查询。
- 内查询是否被执行多次:相关子查询和不相关子查询。
- 相关子查询需求:查询工资大于本部门平均工资的员工信息。
- 不相关子查询需求:查询工资大于本公司平均工资的员工信息。
8.1.单行子查询
- 子查询中的空值问题:子查询不返回任何行。
SELECT
last_name,
job_id
FROM
employees
WHERE
job_id = ( SELECT job_id FROM employees WHERE last_name = 'Haas' );
# 题目:查询工资大于149号员工工资的员工的信息
SELECT
*
FROM
employees
WHERE
salary > ( SELECT salary FROM employees WHERE employee_id = 149 );
# 题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 )
AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );
#题目:返回公司工资最少的员工的last_name,job_id和salary(最少工资的可能有多人,所以不可以使用limit)
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
salary = ( SELECT min( salary ) FROM employees );
#题目:查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id
SELECT
employee_id,
manager_id,
department_id
FROM
employees
WHERE
employee_id NOT IN ( 141, 174 )
AND (
manager_id IN ( SELECT manager_id FROM employees WHERE employee_id IN ( 141, 174 ) )
AND department_id IN ( SELECT department_id FROM employees WHERE employee_id IN ( 141, 174 ) )
);
SELECT
employee_id,
manager_id,
department_id
FROM
employees
WHERE
employee_id NOT IN ( 141, 174 )
AND ( manager_id, department_id ) IN ( SELECT manager_id, department_id FROM employees WHERE employee_id IN ( 174, 141 ) );
# 题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT
department_id,
min( salary )
FROM
employees
WHERE
department_id IS NOT NULL
GROUP BY
department_id
HAVING
min( salary ) > ( SELECT min( salary ) FROM employees WHERE department_id = 50 );
# 题目:显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’。
SELECT
department_id
FROM
departments
WHERE
location_id = 1800;
SELECT
employee_id,
last_name,
CASE
department_id
WHEN ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN
'Canada' ELSE 'USA'
END 'location'
FROM
employees;
8.2.多行子查询
# 题目:返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees e
WHERE
job_id <> 'IT_PROG'
AND salary < ANY ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' );
# 题目:查询平均工资最低的部门id
# 方式1
SELECT
department_id
FROM
employees
GROUP BY
department_id
ORDER BY
avg( salary ) ASC
LIMIT 1;
# 方式2
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
avg( salary ) <= ALL ( SELECT avg( salary ) FROM employees GROUP BY department_id );
# 方式3
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
avg( salary ) = ( SELECT min( avg_sal ) FROM ( SELECT avg( salary ) avg_sal FROM employees GROUP BY department_id ) t );
# 空值问题
# 错误写法:该子查询中返回manager_id中有一条记录为NULL,所以整个查询不返回任何行
SELECT
last_name
FROM
employees
WHERE
employee_id NOT IN ( SELECT manager_id FROM employees );
# 正确写法
SELECT
last_name
FROM
employees
WHERE
employee_id NOT IN ( SELECT manager_id FROM employees WHERE manager_id IS NOT NULL );
8.3.相关子查询
- 如果子查询(内)的执行依赖于外部查询(外),通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为
关联子查询。
# 题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
# 方式一
SELECT
last_name,
salary,
department_id
FROM
employees t1
WHERE
salary > ( SELECT avg( salary ) FROM employees t2 WHERE t2.department_id = t1.department_id );
# 方式二
SELECT
last_name,
salary,
t1.department_id
FROM
employees t1,
( SELECT department_id, avg( salary ) avg_sal FROM employees GROUP BY department_id ) t2
WHERE
t1.department_id = t2.department_id
AND t1.salary > t2.avg_sal;
# 题目:查询员工的id,salary,按照department_name 排序
# 方式一
SELECT
e.employee_id,
e.salary
FROM
employees e
JOIN departments t ON e.department_id = t.department_id
ORDER BY
t.department_name;
# 方式二
SELECT
employee_id,
salary
FROM
employees t1
ORDER BY
( SELECT department_name FROM departments t2 WHERE t1.department_id = t2.department_id );
# 题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
SELECT
employee_id,
last_name,
job_id
FROM
employees t1
WHERE
2 <= ( SELECT count( 1 ) FROM job_history t2 WHERE t1.employee_id = t2.employee_id );# 题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
# 方式一
SELECT
employee_id,
last_name,
department_id
FROM
employees
WHERE
employee_id IN ( SELECT DISTINCT manager_id FROM employees WHERE manager_id IS NOT NULL );
# 方式二
SELECT DISTINCT
e2.employee_id,
e2.last_name,
e2.department_id
FROM
employees e1
JOIN employees e2 ON e1.manager_id = e2.employee_id;
# 方式三
SELECT
employee_id,
last_name,
job_id,
department_id
FROM
employees e1
WHERE
EXISTS ( SELECT * FROM employees e2 WHERE e1.employee_id = e2.manager_id );
# 题目:查询departments表中,不存在于employees表中的部门的department_id和department_name
SELECT
department_id,
department_name
FROM
departments d
WHERE
NOT EXISTS ( SELECT 1 FROM employees e WHERE e.department_id = d.department_id );
9.SQL底层执行原理
- SELECT语句的完整结构:
SELECT ...,...(聚合函数)
FROM ...,...
WHERE 多表连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ...,...(ASC/DESC)
LIMIT ...,...
- SQL语句执行过程:
FROM -> ON(笛卡尔积数据过滤) -> LEFT/RIGHT JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
- 关键字声明顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT
三,运算符和函数
(一)运算符
- 字符串存在隐式转换,如果转换不成功,则看作0。
- NULL参与 的运算,结果为NULL。
SELECT 0 = 'a'; # 结果:1
1.算术运算符
- 除法:/ 和 DIV。
- 取余:% 和 MOD。
# 在SQL中,+ 没有连接作用,在JAVA中结果为1001。
SELECT 100 + '1' FROM DUAL; # 结果:101
# DIV为除法,分母为0,结果为NULL。
SELECT 100 DIV 0 FROM DUAL; # 结果:NULL
2.比较运算符
- 比较运算返回结果:真返回1,假返回0,NULL。
- <=>:安全等于,为NULL而生。
SELECT 1 <=> NULL,NULL <=> NULL; # 结果:0 1
# 查询表中commisson_pct为null的记录
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct <=> NULL;
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct IS NULL;
# 错误写法:NULL = NULL,返回结果为NULL,并不是1,所以此种写法不会查到任何记录
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct = NULL;
- IS NULL \ IS NOT NULL \ ISNULL:
# 查询表中commisson_pct为null的记录(三种)
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct <=> NULL;
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct IS NULL;
SELECT
last_name,
commission_pct
FROM
employees
WHERE
ISNULL(commission_pct);
# 查询表中commisson_pct不为null的记录(两种)
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct IS NOT NULL;
SELECT
last_name,
commission_pct
FROM
employees
WHERE
NOT commission_pct <=> NULL;
SELECT
last_name,
commission_pct
FROM
employees
WHERE
NOT ISNULL(commission_pct);
- LEAST(set) \ GREATEST(set):最大和最小。
SELECT LEAST(1,2,3),GREATEST(3,2,1) FROM DUAL; # 结果:1 3
# 查询first_name和last_name的较小值
SELECT
LEAST( first_name, last_name ),
first_name,
last_name
FROM
employees;
- BETWEEN…AND:查询范围内的数据,包括边界。
# 查询工资在6000到8000的员工信息
SELECT
last_name,
salary
FROM
employees
WHERE
salary BETWEEN 6000
AND 8000;
SELECT
last_name,
salary
FROM
employees
WHERE
salary >= 6000
AND salary <= 8000;
# 查询工资不在6000到8000的员工信息
SELECT
last_name,
salary
FROM
employees
WHERE
NOT salary BETWEEN 6000
AND 8000;
- IN(set) \ NOT IN(set):在set集合中的数据。
# 查询部门为10,20,30部门的员工信息
SELECT
last_name,
department_id
FROM
employees
WHERE
department_id IN ( 10, 20, 30 );
# 查询工资不是6000,7000,8000的员工信息
SELECT
last_name,
salary
FROM
employees
WHERE
salary NOT IN ( 6000, 7000, 8000 );
- LIKE:模糊查询。
- %:代表不确定个数的字符,包括0个。
- _:代表一个不确定的字符。
# 查询last_name中包含字符'a'的员工信息
SELECT
last_name
FROM
employees
WHERE
last_name LIKE '%a%';
# 查询last_name中以字符'a'开头的员工信息
SELECT
last_name
FROM
employees
WHERE
last_name LIKE 'a%';
# 查询last_name中包含字符'a'且包含字符'e'的员工信息
SELECT
last_name
FROM
employees
WHERE
last_name LIKE '%a%'
OR last_name LIKE '%e%';
# 查询last_name中第二个字符为'a'的员工信息
SELECT
last_name
FROM
employees
WHERE
last_name LIKE '_a%';
# 查询第二个字符是_且第三个字符是'a'的员工信息(转义字符\或$)
SELECT
last_name
FROM
employees
WHERE
last_name LIKE '_\_a%';
- REGEXP \ RLIKE:正则表达式。
3.逻辑运算符
- 逻辑运算返回结果:真返回1,假返回0,NULL。
- 逻辑且优先级高于逻辑或。
- NOT \ !:逻辑非。
- AND \ &&:逻辑且。
- OR \ ||:逻辑或。
- XOR:逻辑异或。
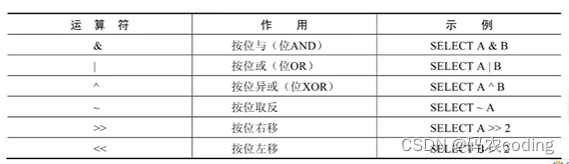
4.位运算符
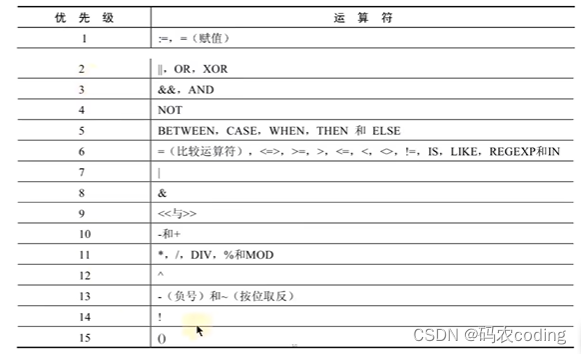
5.运算符的优先级
(二)单行函数
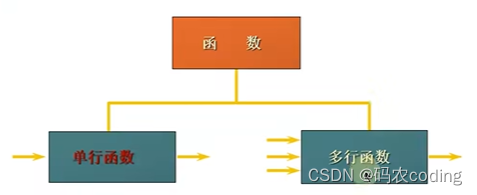
- 单行函数:
- 只对一行进行变换。
- 每行返回一个结果。
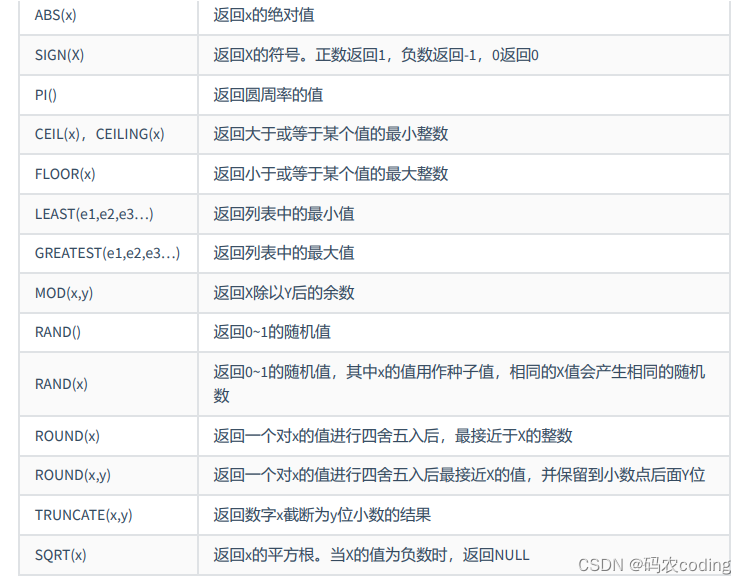
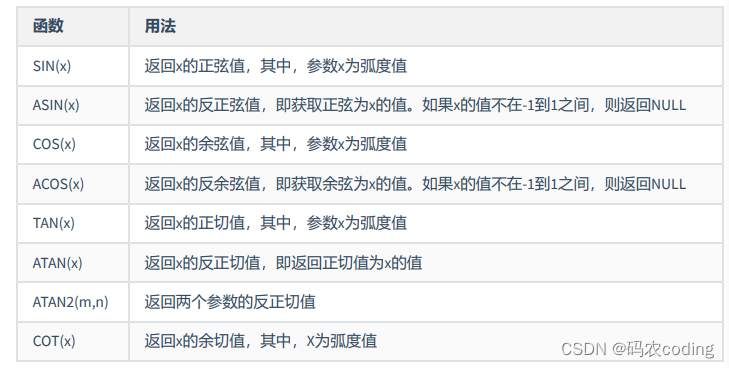
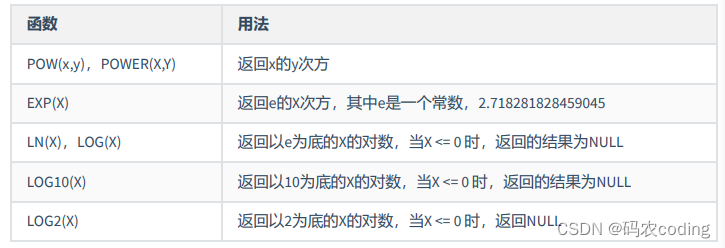
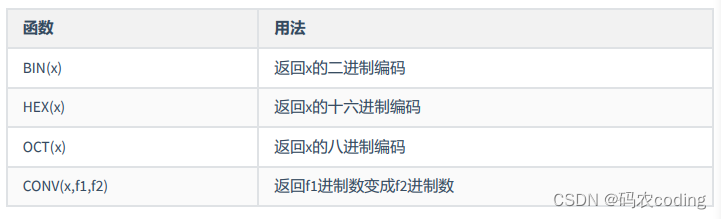
1.数值函数

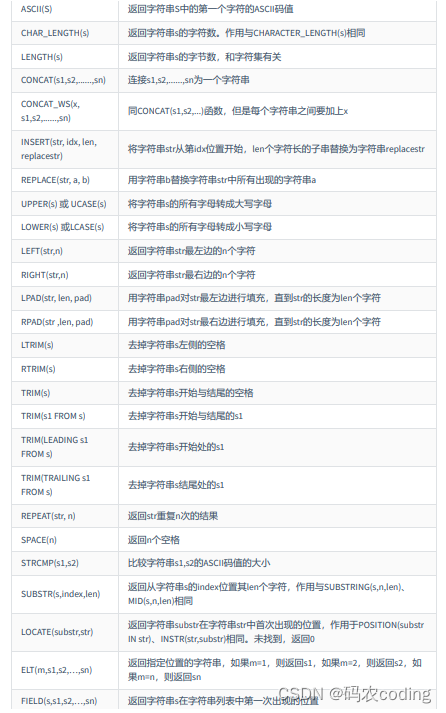
2.字符串函数
- 注意:
MySQL中,字符串的位置是从1开始的。

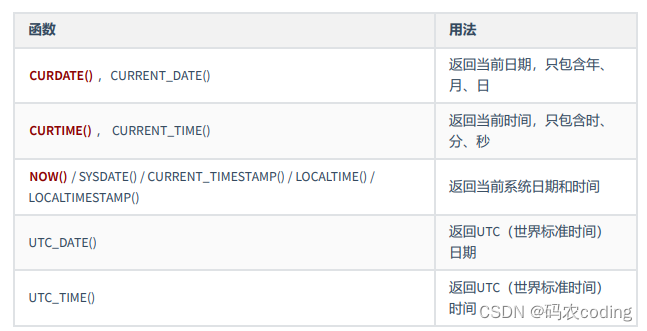
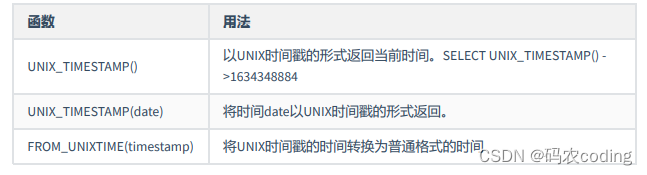
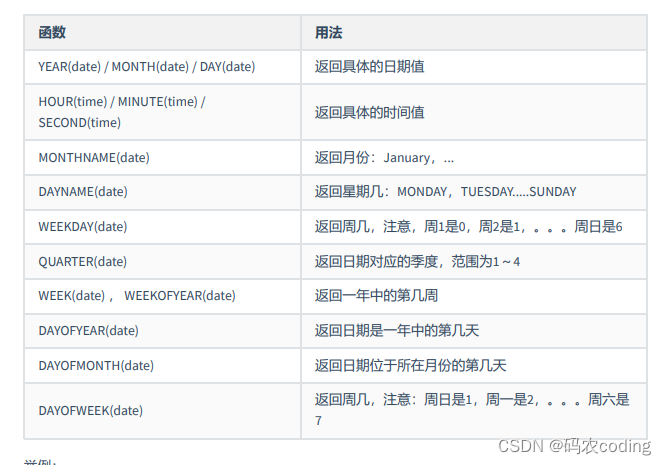
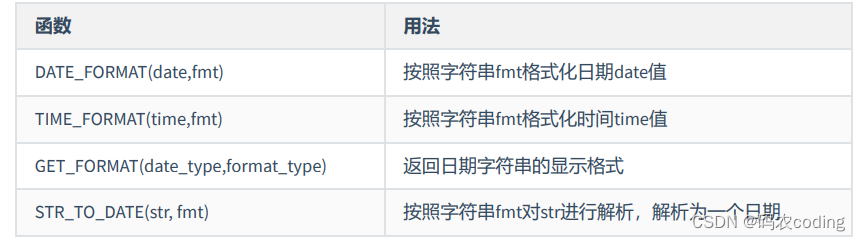
3.日期时间类型函数
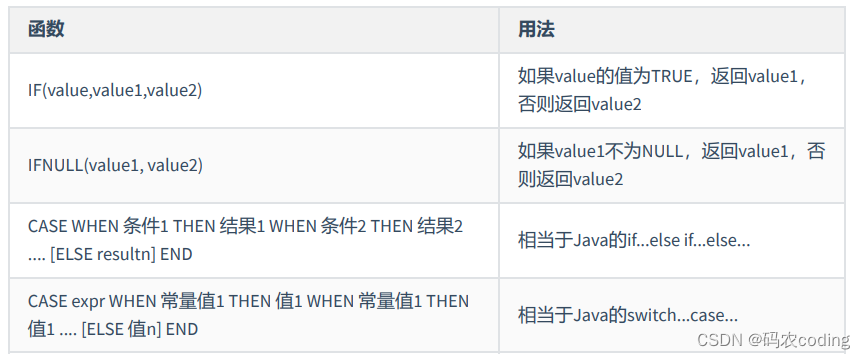
4.流程控制函数
SELECT
IF
( 1 > 0, '正确', '错误' );
SELECT
IFNULL( NULL, 'HELLO' );
SELECT
CASE
WHEN
5 > 6 THEN
'5>6'
WHEN 10 > 9 THEN
'10>9' ELSE 'error'
END;
SELECT
CASE
1
WHEN 1 THEN
'我是1'
WHEN 2 THEN
'我是2' ELSE '你是谁'
END;
SELECT
e.last_name,
e.salary,
CASE
WHEN e.salary >= 15000 THEN
'高新'
WHEN e.salary >= 10000 THEN
'潜力股'
WHEN e.salary >= 8000 THEN
'屌丝' ELSE '草根'
END "discribe"
FROM
employees e
ORDER BY
e.salary DESC;
SELECT
e.last_name,
e.job_id,
CASE
e.job_id
WHEN 'IT_PROG' THEN
e.salary * 1.1
WHEN 'ST_CLERK' THEN
e.salary * 1.15
WHEN 'SA_REP' THEN
e.salary * 1.20 ELSE e.salary
END 'REVISED_SALARY'
FROM
employees e
ORDER BY
REVISED_SALARY DESC;
# 查询部门号为 10,20, 30 的员工信息, 若部门号为 10, 则打印其工资的 1.1 倍, 20 号部门, 则打印其工资的 1.2 倍, 30 号部门打印其工资的 1.3 倍数。
SELECT
e.last_name,
e.department_id,
CASE
e.department_id
WHEN 10 THEN
e.salary * 1.1
WHEN 20 THEN
e.salary * 1.2
WHEN 30 THEN
e.salary * 1.3 ELSE e.salary
END 'REVISED_SALARY'
FROM
employees e
WHERE
e.department_id IN ( 10, 20, 30 );
5.加密和解密函数

6.MySQL信息函数
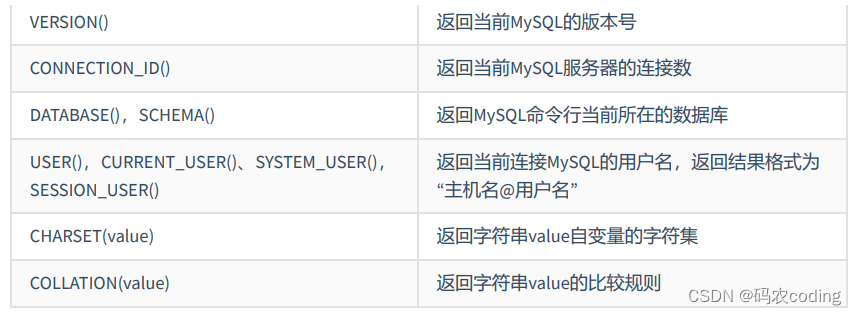
(三)聚合函数(多行函数)
- 聚合函数作用于一组数据,并对一组数据返回一个值。
- MySQL中聚合函数不允许嵌套使用。
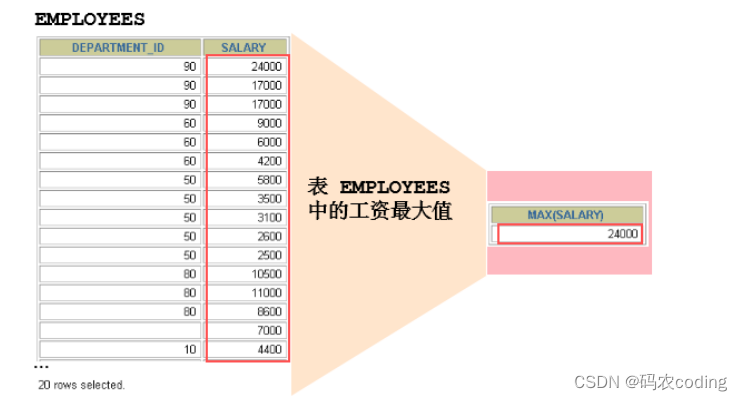
1.AVG和SUM函数
- 可以对数值型数据使用AVG和SUM函数。
- SUM和AVG函数不统计为NULL的数据。
SELECT
AVG( e.salary ),
SUM( e.salary ),
MAX( e.salary ),
MIN( e.salary )
FROM
employees e;
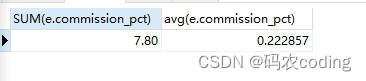
# commission_pct数据存在为NULL的字段。
SELECT
SUM( e.commission_pct ),
avg( e.commission_pct )
FROM
employees e;
- 查询结果:
2.MIN和MAX函数
- 可以对任意数据类型的数据使用MIN和MAX函数。
SELECT
MAX( hire_date ),
MIN( hire_date )
FROM
employees;
3.COUNT函数
- COUNT(*)返回表中记录总数,适用于
任意数据类型,COUNT(expr) 返回expr不为空的记录总数。 - count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
SELECT
count( * )
FROM
employees; # 107
SELECT
count( 1 )
FROM
employees; # 107
SELECT
count( e.commission_pct )
FROM
employees e; # 35
- 需求:查询公司的平均奖金率
# 错误写法,计算未包括奖金率为NULL的员工。
SELECT
AVG( e.commission_pct )
FROM
employees e;
SELECT
SUM( e.commission_pct ) / count( 1 ),
avg( IFNULL( e.commission_pct, 0 ) )
FROM
employees e;















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









