







猫眼字体处理
本次爬取猫眼的票房榜数据,打开检查工具可以看到,票房的数据都进行了加密

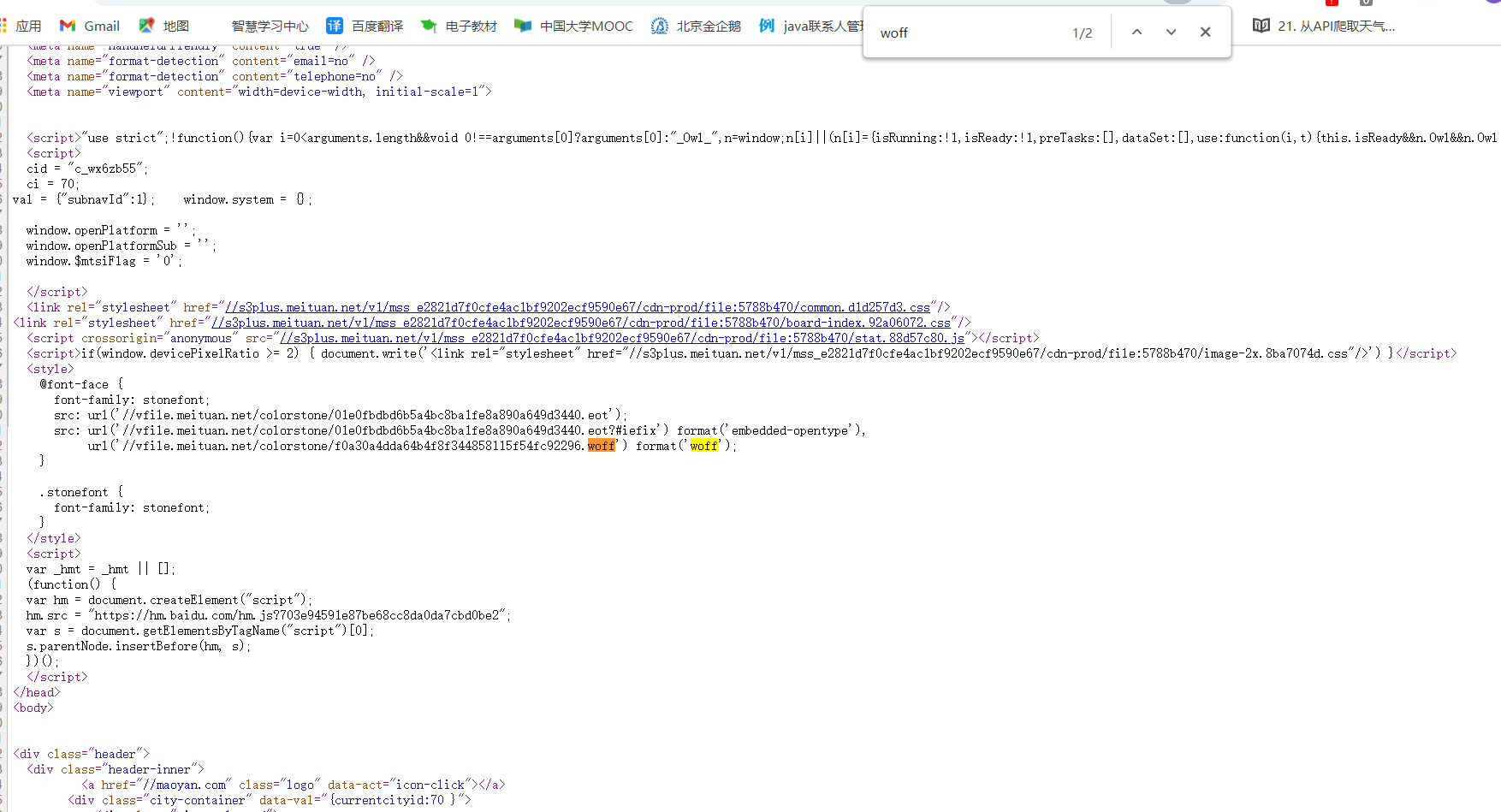
1.首先查看网页的源代码,Ctrl+f 输入 woff
//vfile.meituan.net/colorstone/f0a30a4dda64b4f8f344858115f54fc92296.woff
可以选中这段复制到搜索框中回车,发现可以另存为一个文件,我们需要的就是这个,下载完直接打开发现是乱码,对此还需要处理。
2. 使用re下载woff文件,并用TTFont库进行处理
from fontTools.ttLib import TTFont # 导入TTFont库,处理woff文件
import re
import requests
url = 'https://maoyan.com/board/1'
headers = {
'user-agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
}
response = requests.get(url, headers=headers).text
# 匹配到 //vfile.meituan.net/colorstone/f0a30a4dda64b4f8f344858115f54fc92296.woff
file_url = re.findall("src:.*?,.*?url\('(.*?)'\) format\('woff'\);", response, re.S)[0]
print(file_url)
with open('D:/temp/maoyan_base1.woff', 'wb') as fp:
content = requests.get('http:' + file_url, headers=headers).content
fp.write(content)
font = TTFont('D:/temp/maoyan_base1.woff')
font.saveXML('D:/temp/maoyan_base1.xml')
打开下载的文件进行查看
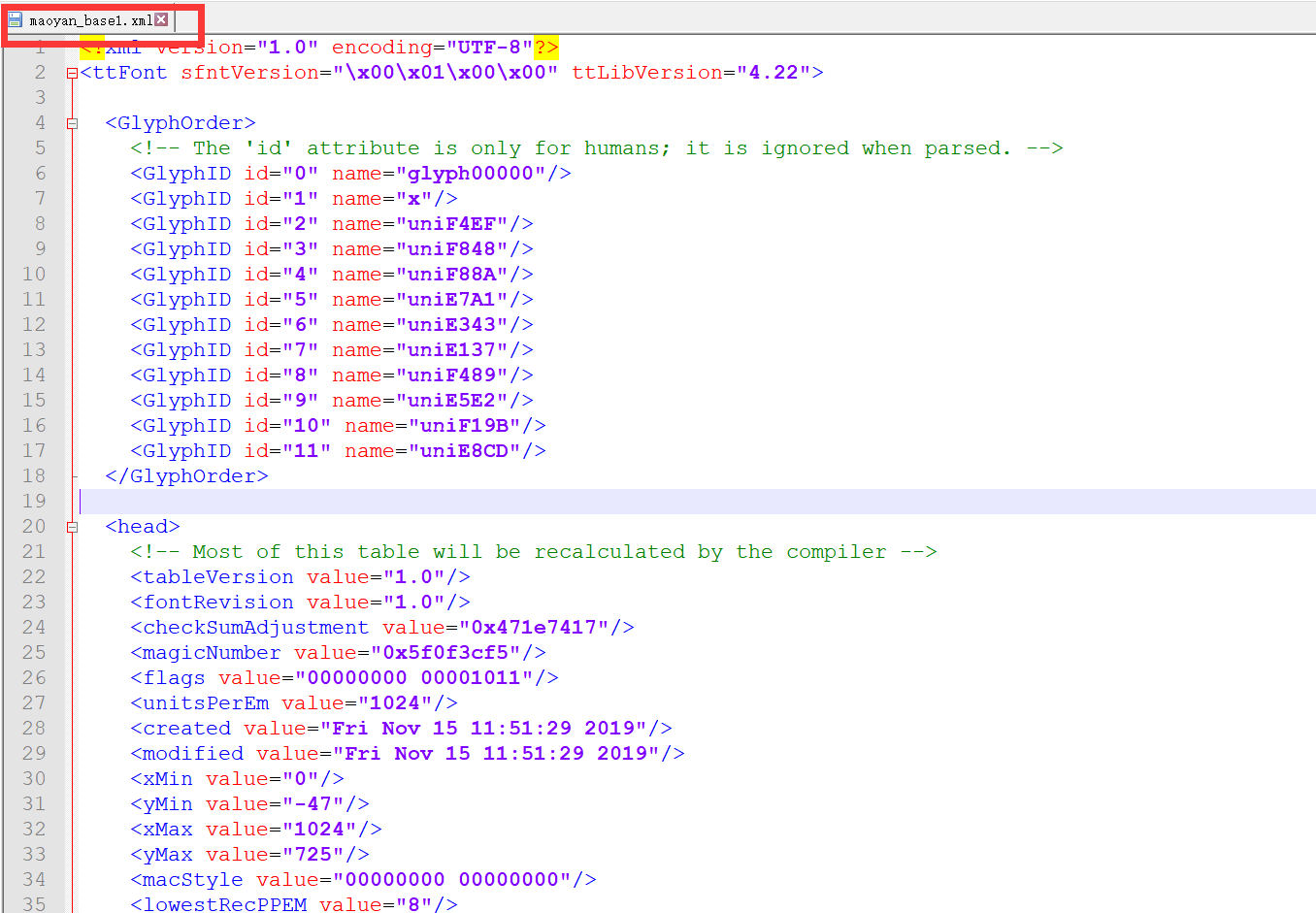
据说这里可以看出数字的规律,但我没看出来(小声bb),所以我接下来借助一个网站对其进行解析
3.使用一个FontStore对其进行解析
**将之前我们下载好的文件打开 (maoyan_base1.woff),然后会出现如下的数字,记住它的排序,接下来我们需使用 **

4.构建代码
import requests
import re
from fontTools.ttLib import TTFont
import pandas as pd
url = 'https://maoyan.com/board/1'
headers = {
'user-agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









