






#手把手教学
使用工具:RTX4090 24G VSCode python3.8 cuda11.8
连接上远程服务器之后操作
一、配置环境
我们需要用到datasets、transformers、peft库,直接打开服务器终端,使用清华镜像安装:
清华镜像使用方法
pip install datasets transformers peft -i https://pypi.tuna.tsinghua.edu.cn/simple
下载我们需要用到的数据集(alpaca_gpt4_data_zh.json)和模型(Langboat/bloom-1b4-zh):
使用镜像下载
第一步:
pip install -U huggingface_hub第二步:
export HF_ENDPOINT=https://hf-mirror.com第三步:下载模型
huggingface-cli download --resume-download Langboat/bloom-1b4-zh --local-dir Langboat/bloom-1b4-zh第四步:下载数据集
huggingface-cli download --repo-type dataset --resume-download llm-wizard/alpaca-gpt4-data-zh --local-dir data至此,前期工作结束
二、Code
1.导入相关包
#导入包
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
from datasets import Dataset
from peft import LoraConfig, TaskType, get_peft_model
2.加载分词器、模型和数据
#加载分词器、模型、数据集
tokenizer = AutoTokenizer.from_pretrainen("Langboat/bloom-1b4-zh")
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
data = Dataset.from_json("data/alpaca_gpt4_data_zh.json")
3.处理数据
#定义数据处理函数
def process_func(example):
#设置最大长度
MAX_LENGTH = 256
#初始化输入ID、注意力掩码和标签列表
input_ids,attention_mask,lable = [],[],[]
#对指令和输入进行编码,tokenizer会将句子分成input_ids和attention_mask两行
instruction = tokenizer("/n".join(["Human:" + example["instruction"],example["input_ids"]]).strip + "/n/nAssistant:")
#对输出进行编码,tokenizer会将句子分成input_ids和attention_mask两行
response = tokenizer(example["output_ids"]+tokenizer.eos_token)
#将指令和响应的input_ids拼接起来
input_ids = instruction["input_ids"] + response["input_ids"]
#将指令和响应的attention_mask拼接起来
attention_mask = instruction["attention_mask"] + response["attention_mask"]
#将指令的标签设置为-100,表示不计算损失;将响应的输入ID作为标签
lable = (-100)*len(instruction["input_ids"]) + response["input_ids"]
#超出长度的进行截断
if len(input_ids)>MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
lable = lable[:MAX_LENGTH]
return{
"input_ids":input_ids,
"attention_mask":attention_mask,
"lable":lable
}
tokenized_data = data.map(process_func,remove_columns=ds.column_names)处理数据是为了将文本数据转换为机器学习模型可以理解的格式。机器学习模型不能直接处理原始文本,因此需要将文本转换为数字表示。这通常通过分词(Tokenization)完成,其中文本被分割成更小的单元(如单词或子词),并转换为对应的唯一整数标识符。
input_ids:是模型输入的词汇标识符列表。这些标识符对应于输入文本中的词或子词。
attention_mask:是用于指示哪些标记应该被模型关注,哪些不应该。
lable:是用于训练模型的输出。在这个例子中,指令部分被赋予标签 -100,这是因为在某些任务中,我们可能不想对指令部分进行损失计算,只想让模型学习生成响应。
4.设置config(调用LoRA):
其实这个特别短,也特别简单,下面罗列全部的参数:
-
r: 这是 LoRA 的核心参数之一,表示低秩矩阵的秩。较小的秩意味着添加的参数更少,因此训练更快,但可能会降低模型的表达能力。 -
target_modules: 这个参数指定了哪些模块应该添加 LoRA 适配层。通常,只会对模型的关键层(如注意力机制的自注意力层和前馈网络)应用 LoRA。 -
task_type: 这个参数定义了微调任务的类型,例如TaskType.CAUSAL_LM表示因果语言建模任务,TaskType.SEQ_2_SEQ_LM表示序列到序列的语言建模任务等。 -
inference_mode: 这个参数用于控制模型在推理时的行为。设置为False时,模型在推理时使用 LoRA 适配层;设置为True时,模型在推理时忽略 LoRA 适配层,使用原始预训练模型的权重。 -
lora_alpha: 这是一个超参数,用于缩放 LoRA 适配层的输出。在某些情况下,调整这个参数可以帮助提高模型的性能。 -
lora_dropout: 这是 LoRA 适配层中的 dropout 概率。添加 dropout 可以帮助模型泛化,减少过拟合。 -
bias: 这个参数指示是否在 LoRA 适配层中添加可训练的偏置项。 -
modules_to_save: 这个参数用于指定在保存模型时应该包含哪些模块。这通常用于确保 LoRA 适配层被正确保存。
我们这里只设置任务类型,其他的都使用默认值。
config = LoraConfig(tasktype=TaskType.CAUSAL_LM)
model = get_peft_model(model, config)5.定义训练参数
这里的保存路径需要自己设置,把save_path替换成自己想要保存的路径
args = TrainingArguments(
output_dir="save_path",# 指定模型训练结果的输出目录。
per_device_train_batch_size=8, # 指定每个设备(如GPU)上的批次大小
gradient_accumulation_steps=8,# 指定梯度累积步数。在本例子中,每8个步骤进行一次梯度更新。
save_steps=1000,#指定模型保存的频率。在本例子中,每1000个步骤保存一次模型
num_train_epochs=4 #指定训练的总轮数
)6.初始化训练器
#初始化训练器
trainer = Trainer(
model=model,#指定训练模型
args=args, #指定训练参数
train_dataset=tokenized_ds, #指定数据集
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) #指定数据收集器。其中tokenizer是分词器,padding=True表示对输入进行填充以保持批次大小一致。
)
trainer.train()至此,代码已经写完了,直接点击运行开始训练。
三、对比模型
其实可以先对比训练之前和训练之后的模型推理效果
原模型: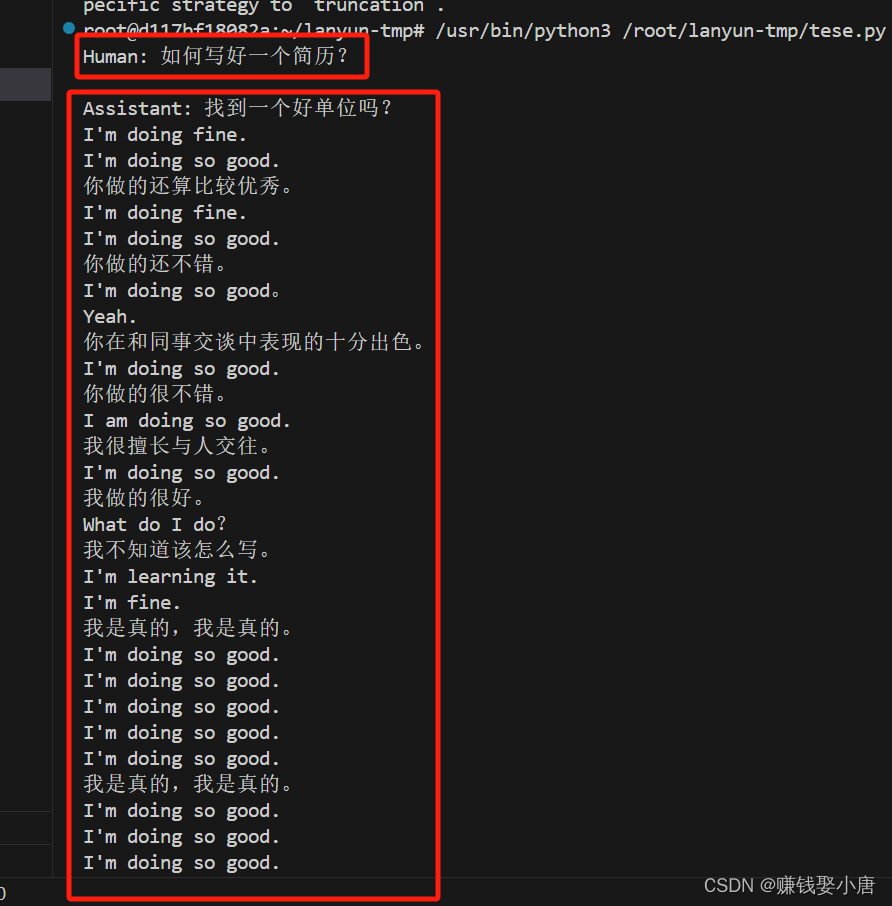
微调后的:

测试代码:自己填充一下文件路径,这个会直接输出两个答案,直观对比
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("原模型路径", low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained("原模型路径")
# 创建生成文本的管道
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0,do_sample=True)
# 输入文本
ipt = "Human:早上容易饿怎么办?\n\nAssistant: "
# 生成文本,设置截断,加载PeftModel之前
response_before = pipe(
ipt,
max_length=256,
truncation=True,
num_return_sequences=1,
do_sample=True, # 使用采样而不是贪婪解码
temperature=0.7, # 控制生成文本的随机性
top_k=50, # 保证生成文本的多样性
top_p=0.95, # 控制生成文本的质量
repetition_penalty=2.0 # 减少重复生成的现象
)
print("Before loading PeftModel:", response_before)
# 加载PEFT模型
p_model = PeftModel.from_pretrained(model, model_id="微调之后的模型保存路径")
# 生成文本,设置截断,加载PeftModel之后
response_after = pipe(
ipt,
max_length=256,
truncation=True,
num_return_sequences=1,
do_sample=True, # 使用采样而不是贪婪解码
temperature=0.7, # 控制生成文本的随机性
top_k=50, # 保证生成文本的多样性
top_p=0.95, # 控制生成文本的质量
repetition_penalty=2.0 # 减少重复生成的现象
)
print("After loading PeftModel:", response_after)
四、合并模型
为什么要合并模型?因为LoRA微调是加了额外的层,但是这个层并不是原模型的层,就好像给手机贴了个膜,这个膜并不属于手机的一部分,我们要把这个膜融入手机屏幕上面,成为手机的一部分。其实也可以不合并,但是走完完整的流程。
-
简化推理流程:合并后的模型可以作为一个单一的模型进行推理,这样可以简化推理流程,也就是推理的更快,答复更快。
-
减少推理时的资源消耗:合并后的模型在推理时不需要额外的LoRA适配层参数,可以减少内存和计算资源的使用。
-
提高模型的兼容性:合并后的模型可以更容易地与其他系统或库集成,因为它遵循原始模型的架构和接口。
-
便于模型分享和分发:合并后的模型可以作为一个单一的权重文件进行分享和分发,而不需要额外的适配层信息。
from transformers import pipeline from transformers import AutoTokenizer, AutoModelForCausalLM from peft import PeftModel # 加载模型和分词器 model = AutoModelForCausalLM.from_pretrained("原模型路径", low_cpu_mem_usage=True) tokenizer = AutoTokenizer.from_pretrained("原模型路径") # 加载微调后的模型 p_model = PeftModel.from_pretrained(model, model_id="微调后的模型路径") # 合并和卸载微调模型 merge_model = p_model.merge_and_unload() # 创建生成文本的管道 pipe = pipeline("text-generation", model=merge_model, tokenizer=tokenizer, device=0) # 输入文本 ipt = "Human:晚上吃什么更有营养?\n\nAssistant: " # 生成文本,设置截断 response = pipe(ipt, max_length=256, truncation=True) print(response)没有实习,日常焦虑。。。。
















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









