






本文可拆分看,直接看自己有疑惑的部分
一、准备工作
找到自己想要复现的项目:
要复现代码,首先要有自己想要复现的项目,这点不用说,可以自己直接在浏览器或者csdn之类的搜索自己的研究领域的SOTA论文,然后在里面找到对应的项目地址,一般都在github能找到。
以下是我使用的。
论文:Unified Named Entity Recognition as Word-Word Relation Classification
附上github地址(文明上网,我直连的):ljynlp/W2NER: Source code for AAAI 2022 paper: Unified Named Entity Recognition as Word-Word Relation Classification (github.com)
论文如有侵权,请联系我删除。
下载项目(以github上的为例):
以我复现的为例,论文中有给出项目地址(一般在摘要或者第一页的脚注,我的这个在脚注)。

复制地址,在浏览器

点击下载,然后解压到容易找到的路径
阅读README.md
看项目的指示,每个项目里面都有README.md。里面详细的写了运行代码之前的准备工作,如图:
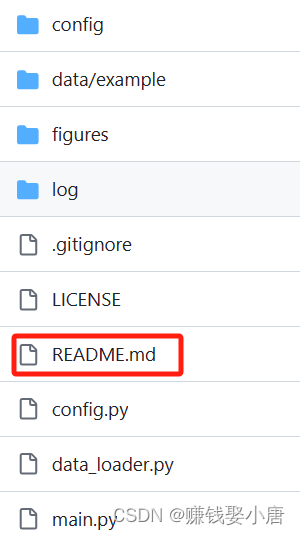
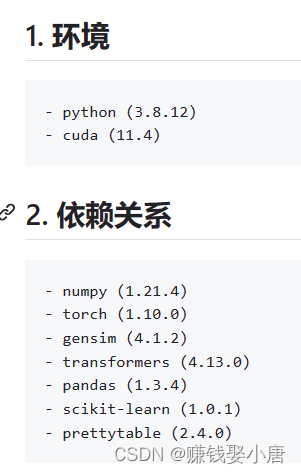

第一张图片是打开README.md,第二、三张图片是README里面的提示。我们可以知道运行代码需要的环境和依赖,以及需要下载的数据集还有处理数据集。
示例—创建环境(可以直接看 二):
(本地版本,使用服务器可不看)
创建虚拟环境需要使用Anaconda,下载完Anaconda之后,打开命令窗口(搜索教程下载)
如下,我们在conda里面创建了一个名字为myenv(我一般设置成项目名字)的环境,并且python版本为3.8.12,cuda版本为11.4
conda create --name myenv python=3.8.12 cudatoolkit=11.4
(远程服务器版本):
一般都有配置好的,默认版本应该都是3.8,cuda也都有,我没管过,如果需要调整python版本可以搜怎么在远程服务器调整,不难。一般环境不用动,大部分都是兼容的,如果有特殊需要再搜对应的调整版本的教程。第二章的对应部分我也有写,可以直接看第二章怎么搞的。
示例—创建依赖(可以直接看 二):
(本地版本)
在Anaconda终端(可以自己学一下怎么使用conda),路径切换到使用的虚拟环境(也就是激活环境),输入下面的代码,回车
激活环境:
conda activate myenv安装依赖:
pip install argparse numpy prettytable torch transformers scikit-learn
环境和依赖可以自己创建,依赖使用pip安装,这些都可以搜教程。推荐使用conda创建虚拟环境(直接搜怎么使用conda),每个项目创建独立的环境,这样依赖不容易冲突。
(远程服务器版本):
见第二章
处理数据集:
项目中给出了示例数据集:(如左图)
我点击链接下载数据集:(中图)
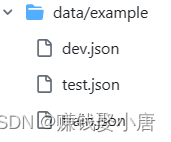
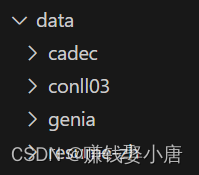
我下载完之后需要把数据集copy到data文件目录底下(如右图)
data/example 实际上是data文件夹下面有一个example,可以直接删除,实在不会就连data文件夹一起删除,然后在原来的路径下重新创建一个。
二、在远程服务器配置环境
这个也算准备工作的一部分,单独拎出来说
在自己电脑运行:
如果自己电脑有GPU,就可以按照第一章的创建环境步骤直接在本地创建,然后到第三章内容,下面的都是连接远程服务器。
在远程服务器运行:
一般项目的都需要使用GPU,我们就需要连接远程服务器(如果自己电脑GPU性能好当我没说)
我一般在autodl租用服务器,可以自己搜怎么租用服务器,这里连接服务器我以我使用的VSCode为例(可以搜自己使用的IDE工具):
先选择无卡模式开机(省钱),然后连接服务器(以VSCode为例):
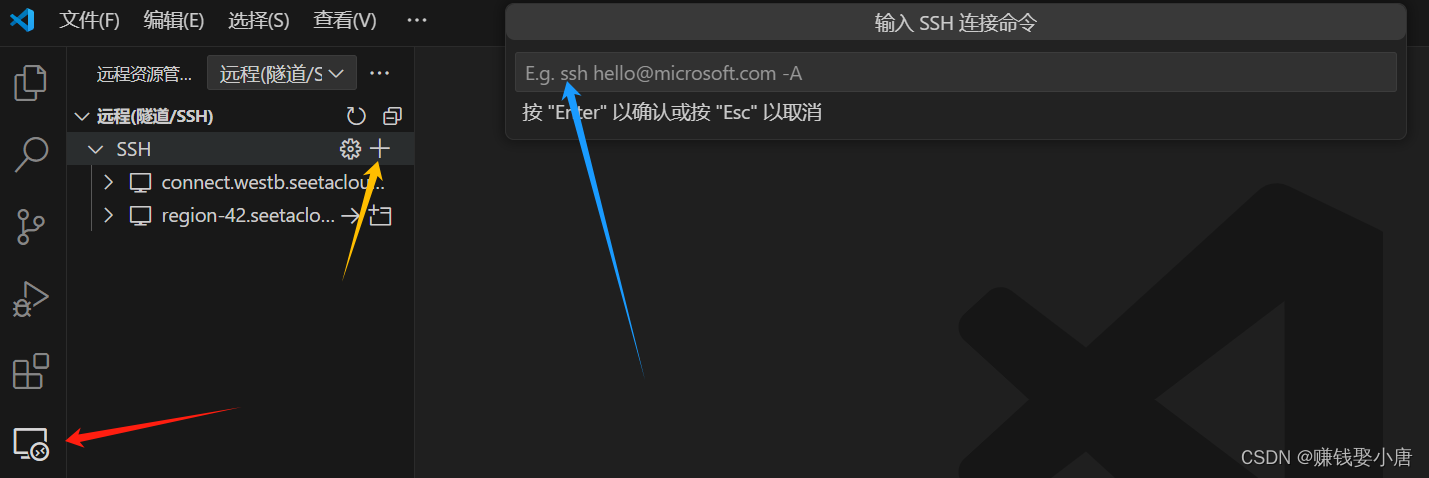
下载Remote-SSH插件
点击红色箭头,然后黄色箭头,在蓝色箭头输入绿色方框的登录指令

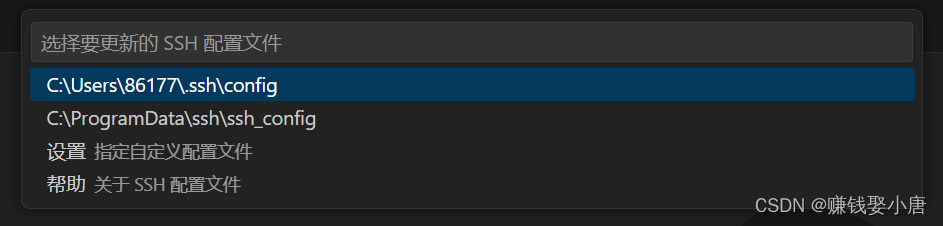
点第一个
输入黑色方框密码(忘截图了不影响)
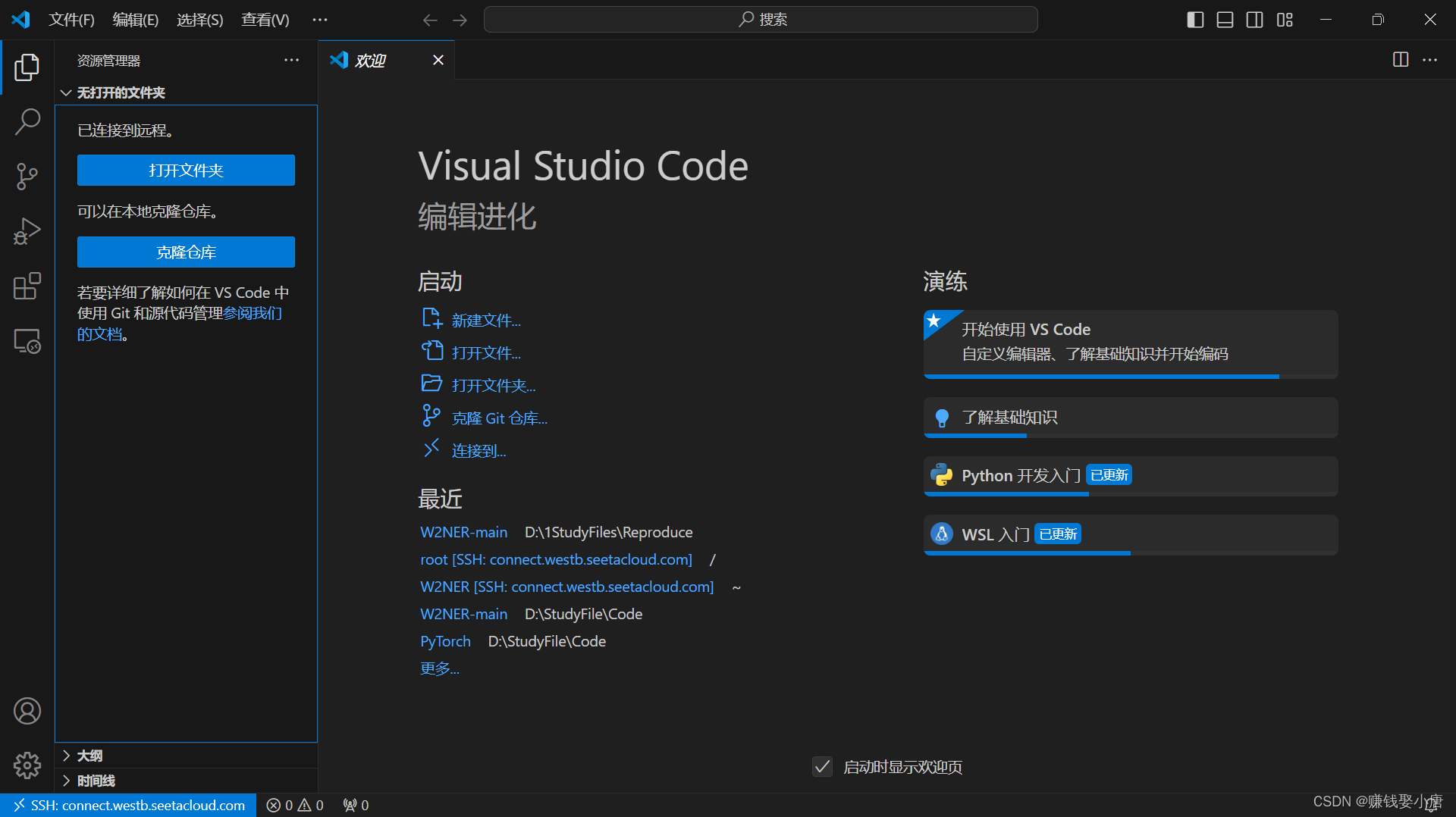
连接成功
打开文件夹,我一般在根目录底下
然后创建一个项目名称的文件夹,把本地文件都copy进去(也可以使用VSCode的github插件直接导入,但是这个帖子给小白看的,这里就不写那么麻烦了)
点击红色箭头选择解释器,然后出现绿色框所示窗口。可以创建虚拟环境,我这里使用创建的3.8.19版本的虚拟环境。
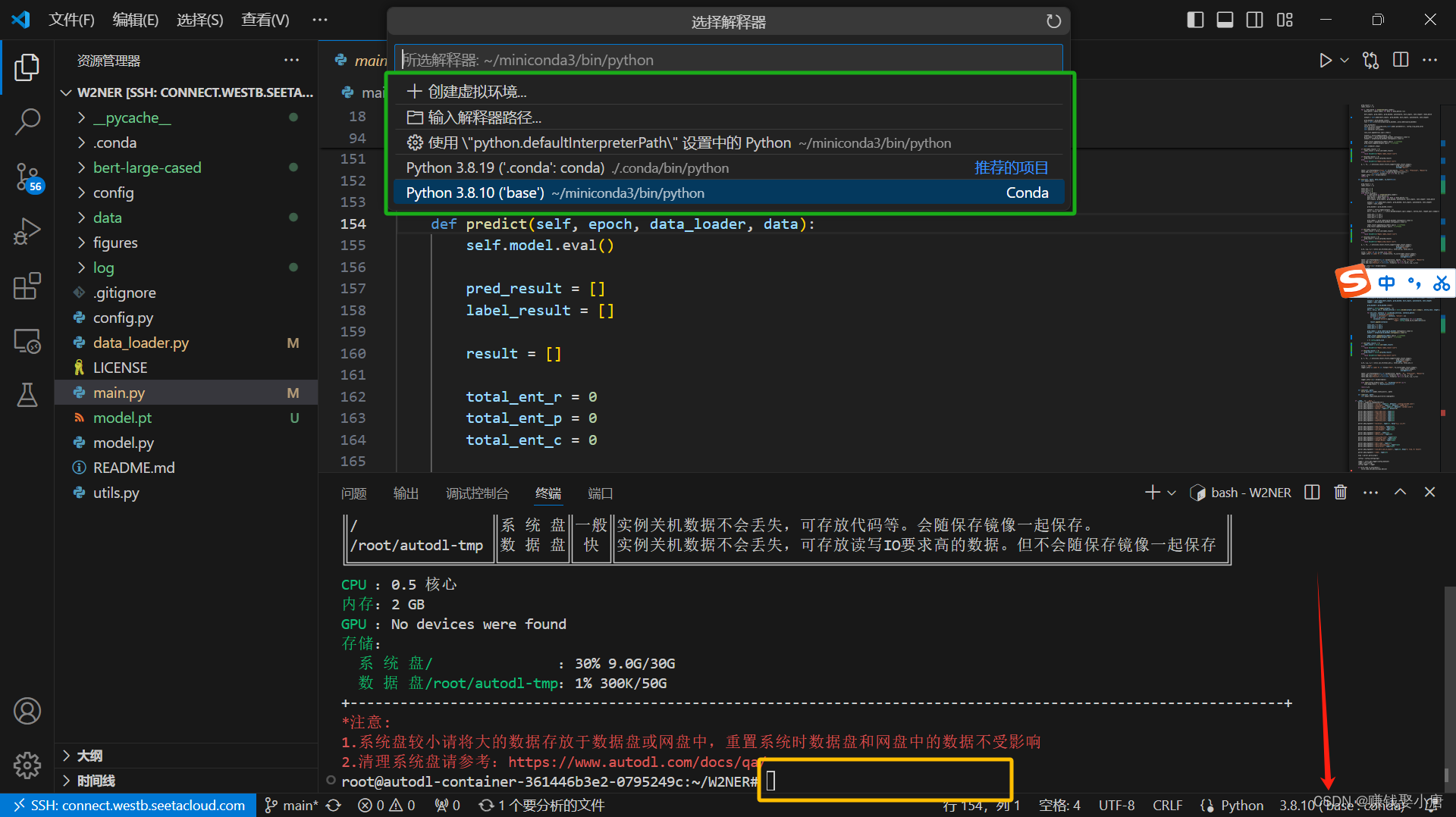
接第一章创建环境和依赖
(在远程服务器可以直接使用VSCode的终端输入命令,也就是上图黄色框)
环境没有管,就用的base,如果想要改环境看我下面的链接。
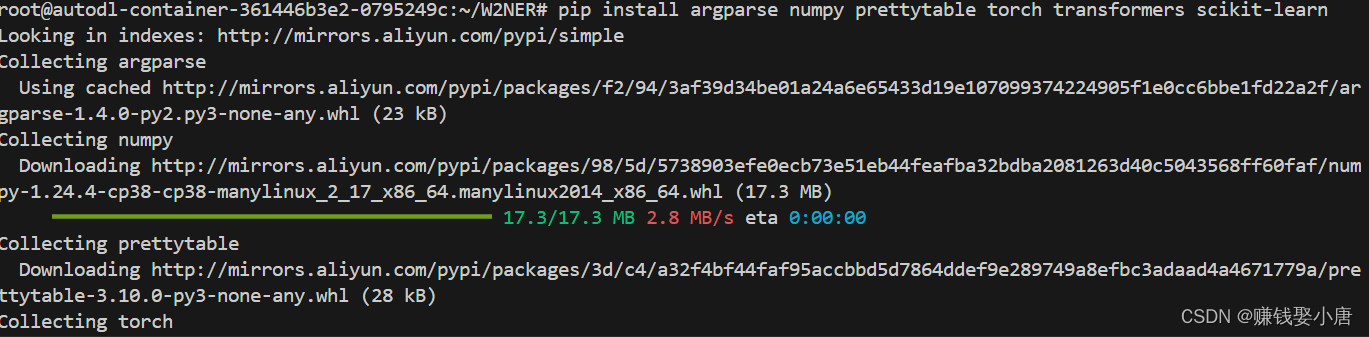
在上图黄色方框输入安装依赖的代码(不推荐在root目录下下载,可能会导致权限问题),不过我就是在root下下载的,没问题,看自己
pip install argparse numpy prettytable torch transformers scikit-learn等待安装完毕就好了
不过我在这个过程中遇到了一个cannot import name ‘triu’ from ‘scipy.linalg’报错,这是由于SciPy在1.13版本中删掉了这个函数,使用低一点的版本就好了。我使用的1.11.4,代码如下:
pip install scipy==1.11.4下载完需要安装,一直等到红色方框里的出现才算安装完成
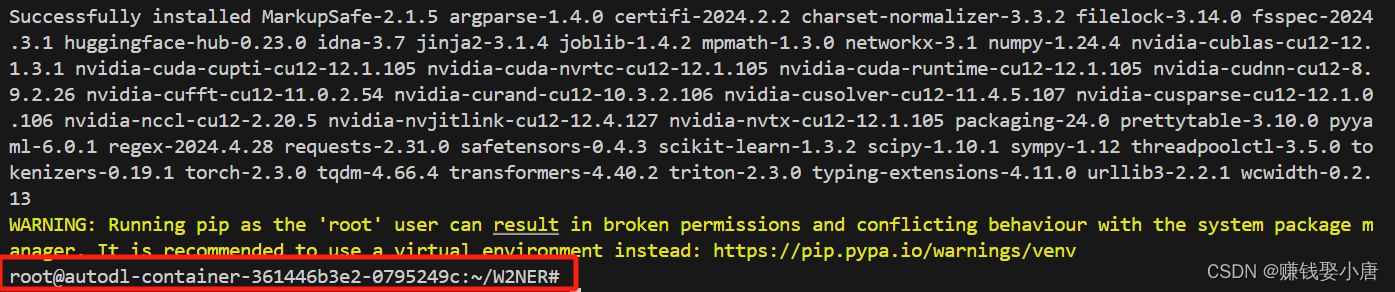
黄色的是因为我在根目录下进行的命令,如果你不是就不会有黄色的提示,不过目前没啥影响。可以在我的另外一个帖子看怎么创建并使用虚拟环境。(手把手教程)怎么在autodl使用虚拟环境并且创建python环境,也就是解决Running pip as the ‘root‘ user can result in brok-CSDN博客
三、下载模型
因为我的网络连接huggingface不稳定,不能使用线上的模型,所以需要下载到本地(指服务器地址)。这篇论文使用的是bert-large-cased模型。如果不知道自己使用的哪个模型,直接跑代码,看报错信息就行,或者发给GPT问一问。
这个就是比较简单的了,附上链接:HF-Mirror - Huggingface 镜像站,使用方法二直接下载,如图(这里我就不给代码了,可以直接跳转链接copy代码):
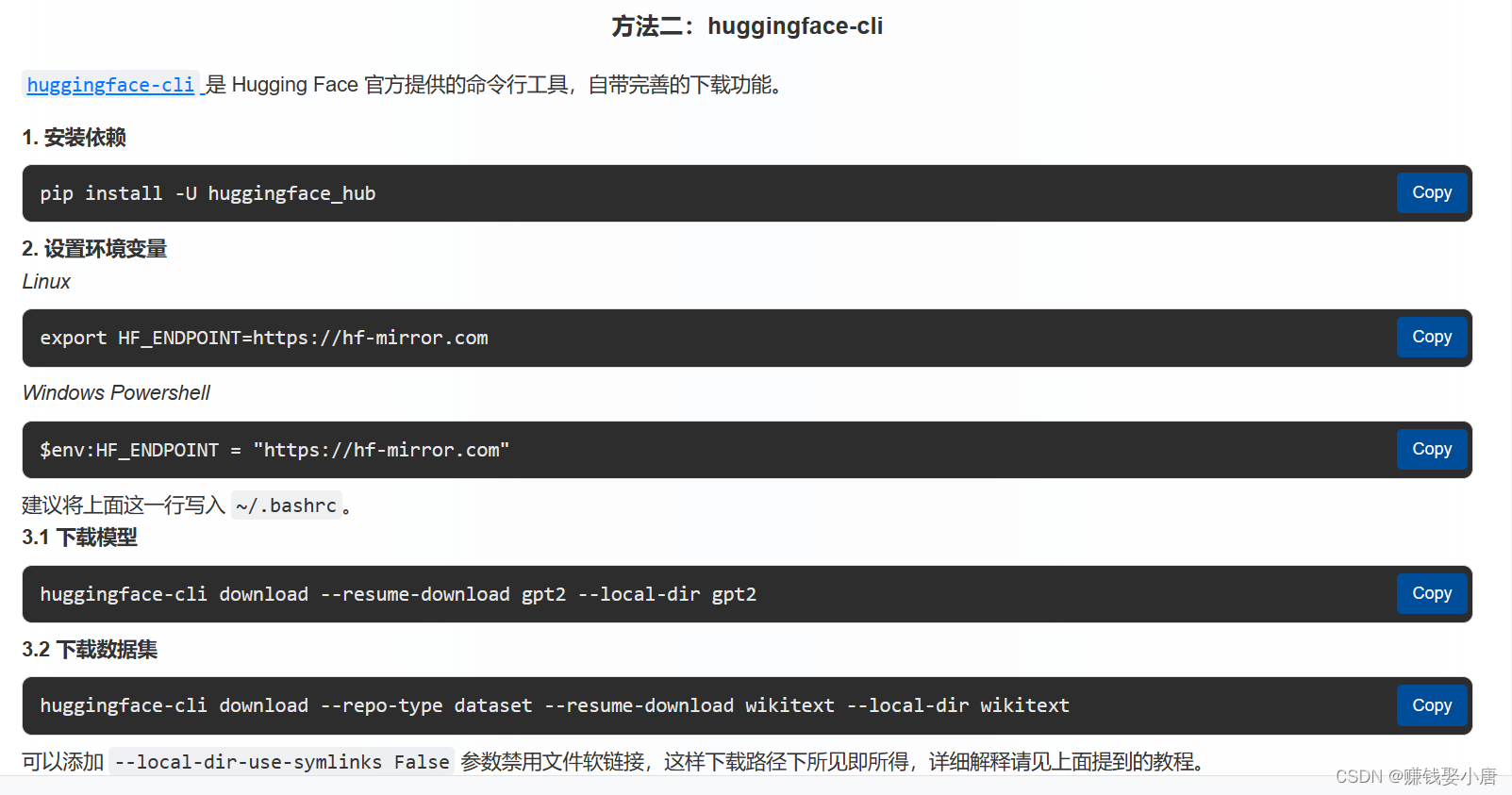
值得注意的是第二步,远程服务器使用的是Linux,所以不要使用windows的命令。
更值得注意的是第三步:huggingface-cli download --resume-download gpt2 --local-dir gpt2
其中第一个gpt2代表模型名称,要改成自己的。第二个gpt2是下载到本地的路径,推荐使用绝对路径。比如我的: huggingface-cli download --resume-download bert-large-cased --local-dir /root/W2NER/bert-large-cased
下载完之后还需要注意,模型所在路径和代码里面引用的路径要保持一致。这个帮不了,需要自己核对代码,不过一般是直接创建个和模型名字一样的文件夹,把模型下载到里面就行,具体情况具体分析。
四、修改代码
由于这个项目是2022年的,里面用到的一些方法啊什么的,参数都会有变化,之前的写法可能跑不通。我直接一次次的跑,一次次报错,然后根据报错信息修改,直到修改完毕就能跑起来了。
修改完之后记得把服务器切换到有卡模式,这样才能用GPU。在无卡模式下配置环境省钱(0.1/h)。
比如说我遇到这个错误:

这是源代码中的错误。可能是编译程序更新或者什么其他之类的,导致之前的写法不能用了,就会出现这种情况,需要一步步修改。至此,大问题都解决完了,基本上就能跑了。
五、致谢/致歉
感谢女朋友在我科研道路上的支持和鼓励还有安慰!
技术有限,时间有限,献丑了。本文是因为没有找到自己看得懂的复现代码的流程,所以自己复现完了写一篇。本文只写了自己觉得比较重要、小白(本人就是小白)容易犯错和不懂的部分,有些小细节没有写(大多数都搜得到),而且有些术语用的比较混乱,比如“命令”和“代码”这两个名词我没有作区分。如果有错误欢迎指正。如果有其他问题也可以随时和我私信联系沟通交流。


















 3061
3061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









