







《Redis设计与实现》笔记
前记:
- 参考配套网站:http://redisbook.com
- 带注释的源码地址:https://github.com/huangz1990/redis-3.0-annotated
- 注意:整本书都是针对3.0之前的版本,而到读书时为止,Redis已经更新到了6.x😥
第一部分:数据结构与对象
一、引言
二、简单动态字符串
1SDS的定义
-
SDS:simple dynamic String 简单动态字符串,是redis的通用字符串数据结构。除了字面量(如打印日志这种不会改变字符串的),其他都用SDS表示redis中的字符串
-
sds.h/sdshdr定义在这个文件中 -
总分配的空间 = len + free
-
struct sdshdr { // 记录 buf 数组中已使用字节的数量 // 等于 SDS 所保存字符串的长度 int len; // 记录 buf 数组中未使用字节的数量 int free; // 字节数组,用于保存字符串 char buf[]; }; -
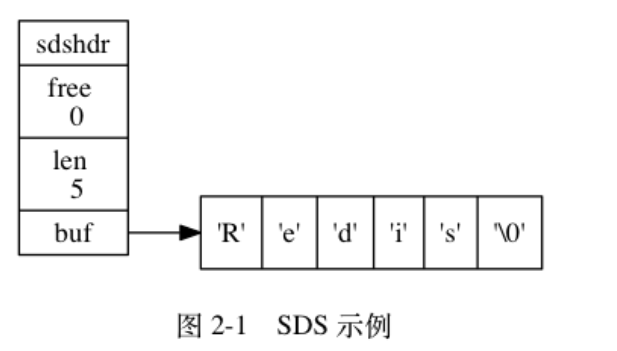
-
特点:
- 遵循C字符串以空字符为结尾的惯例
- 空字符的空间不算在len长度里面
2内存重分配
-
在C语言的环境中,每次增长或者缩短C字符串,程序要对C字符串的数组进行内存重分配操作。
如果拼接时,忘记扩展内存,会造成缓冲区溢出
如果缩短时,忘记释放不用的内存,会造成内存泄露
-
redis内存重分配重新设计的背景:因为redis要求速度快、修改频繁,如果用C原生的内存重分配机制,会导致内存重分配这个操作成为性能的瓶颈
-
SDS实现了两种内存优化策略:
- 空间预分配
- 惰性空间释放
空间预分配
-
使用时机:当SDS进行修改并要扩展时
-
分配空间:要为SDS分配修改所必须用的空间,还要分配额外的未使用空间
-
额外的未使用空间数量公式:
-
如果SDS修改之后,SDS的len小于1MB,则再给free分配和len一样的空间。
如修改后len=13,则free要再分配13,加上空字符,所以总空间:13 + 13 + 1
-
如果SDS修改之后,SDS的len大于等于1MB,则再给free分配1MB的空间。
如修改后len=13MB,则free要再分配1MB,加上空字符,所以总空间:13MB+1MB+1
-
惰性空间释放
- 使用时机:当要优化SDS字符串时,要进行缩短操作
- 动作:不立即使用内存重分配机制,而是用free属性将释放的空间大小记录下来
3其他特点
- 二进制安全
- 普通的C字符串是以‘\0’为结尾的,所以不能保存如图片之类的二进制数据
- 由于SDS的长度界定是len,所以可以保存任何二进制数据
- 兼容部分C函数
- 由于SDS遵循了字符串以空字符串为结尾(本质上是用len来界定,空字符对于SDS是没有用处的),所以是可以用一些标准的库函数的
- SDS是不会造成缓冲区溢出的,因为在增长字符串时(如拼接)会先判断可用空间是否充足。如果不足,会自动扩展
三、链表
-
保存的文件:
adlist.h/listNode -
结点结构定义:
typedef struct listNode { // 前置节点 struct listNode *prev; // 后置节点 struct listNode *next; // 节点的值 void *value; } listNode; -
对结点,用一个列表对结点进行封装:
typedef struct list { // 表头节点 listNode *head; // 表尾节点 listNode *tail; // 链表所包含的节点数量 unsigned long len; // 节点值复制函数 void *(*dup)(void *ptr); // 节点值释放函数 void (*free)(void *ptr); // 节点值对比函数 int (*match)(void *ptr, void *key); } list; -
示意图:
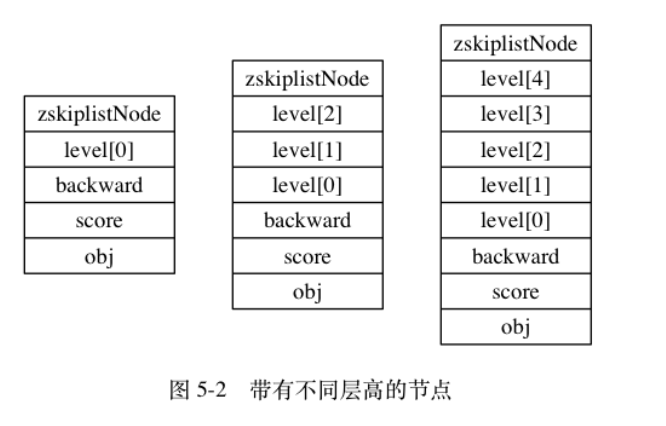
-
应用场景:列表键(LLEN integers 0 10), 发布订阅,慢查询,监视器等
-
Redsi的链表:双向链表
- 双端(双向)
- 无环
- 带头和尾指针
- 带长度计数器
- 多态:用void*指针来保存节点的值。
四、字典
1概述与理解
-
字典,又称为符号表(symbol table)、关联数组(associative array)、映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构
-
redis > set msg "hello", 在数据库创建一个键为”msg“,值为”hello“时,这个键值对是保存在代表数据库的字典里面的 -
字典在redis中的层级结构:
2字典各个结构的实现
哈希节点
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- 值是一个联合属性。可以是指针,和整数
- next指针是为了解决哈希冲突
哈希表
typedef struct dictht {
// 哈希键值对数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
- 属性:
- table是一个dictEntry数组,是可变长的哦~
- size则表示dictEntry数组的总大小,是2的n次方
- used则记录已经使用了多少个dictEntry
- sizemask是一个掩码,和哈希值一起决定一个键应该被放到table数组中的哪个索引上面(具体起怎样起作用,看下面)
字典
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
- 属性:
- type是一组函数操作
- privdata:保存了需要传给那些类型特定函数的可选参数
- ht是哈希表,有两个。一个是常用,一个用于rehash
- trehashidx:记录rehash进行状态。如果不在rehash状态,则值为-1
类型特定函数
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
- 封装了一个字典中的操作
结构图
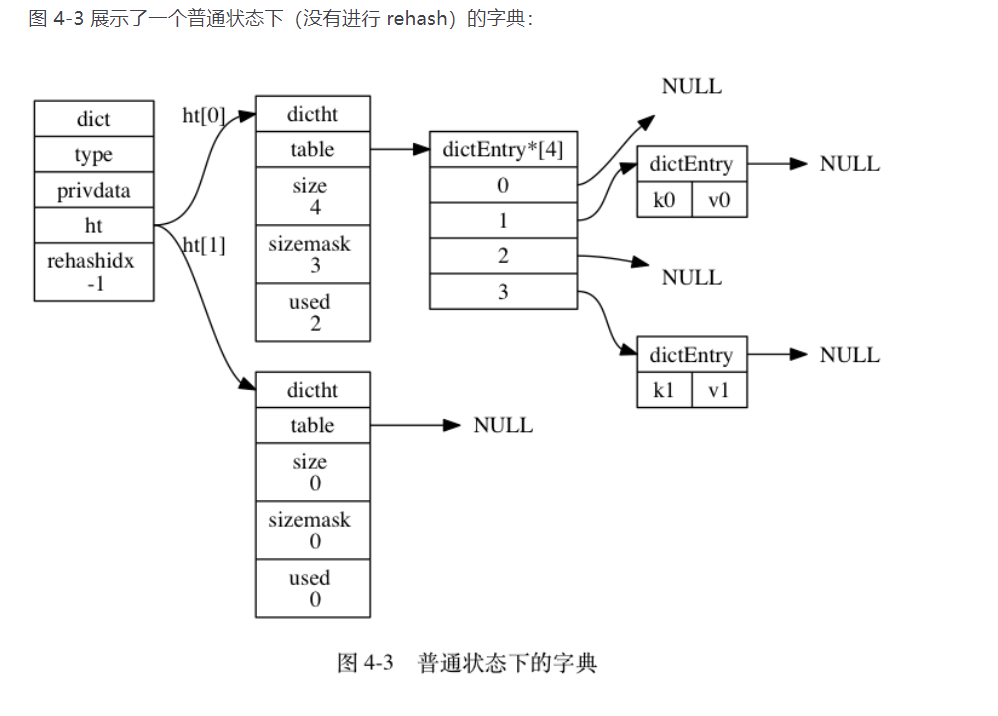
3哈希算法与键冲突
-
哈希算法:
- 首先根据键计哈希值:hash = dict->type->hashFunction(key) (是一个纯数字)
- 然后根据哈希表的掩码sizemask, 计算出index = hash & ht[x].sizemask
-
思考:sizemask的作用?
- 首先明白,哈希表的大小一定是2的n次方,用二进制表示就是10000…
- sizemask的值是 size - 1, 用二进制表示就是11111111…
- 计算出来的哈希值与sizemask相与,可以保证计算出来的索引不越界
-
哈希冲突:
-
如果出现冲突,解决的文案是 链地址法
-
注意:dictEntry中是单链表,所以为了插入性能,新插入的键排在旧的前面
(思考:不用遍历一次,检查重复的键吗?)
-
4rehash
基本知识
-
什么是rehash?为啥要?
随着操作不断进行,哈希表的键值对会增多减少,为了使哈希表的负载因子在一个合理的范围内(防止键太多或太少),要对哈希表进行收缩和扩展
-
负载因子计算公式: 负载因子 = 已保存的节点数量 / 哈希表的大小
-
rehash的步骤:
- 分配空间:为字典中另外一个备用哈希表ht[1]分配空间
- 如果是扩展,则取 ht[1].size = ht[0].used * 2, 向上取到2的n次方幂
- 如果是收缩,则取 ht[1].size = ht[0].used, 向上取到2的n次方幂
- 转移键值对:将ht[0]上面的所有键值对重新计算哈希,放在ht[1]上
- 改名:将ht[0]销毁,ht[1]变成ht[0], ht[1]新建出一个新哈希表,为下一次做准备
- 分配空间:为字典中另外一个备用哈希表ht[1]分配空间
-
rehash的时机:
扩展:
- 没有执行BGSAVE或BGREWRITEAOF时,并且负载因子大于等于1
- 执行BGSAVE或BGREWRITEAOF时,并且负载因子大于等于5
收缩:
- 当负载因子小于0.1时,自动收缩
-
思考:为啥BGSAVE或BGREWRITEAOF时,要把负载因子改成5 ?
- 首先明白,BGSAVE或BGREWRITEAOF都是与磁盘工作相关,要fork子进程处理
- 操作系统对于fork操作,是采用 写时复制 技术,即只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
- 在子进程存在期间,将负载因子提高,可以尽量避免哈希表的扩展工作,也就是尽量避免将父进程内存中的内容复制给子进程,造成内存写入操作(因为扩展的时候,两个进程中的内容发生了改变,所以必须要复制一份出来)
渐近式rehash
-
概念:当hash表中的键值对非常多时如四亿个键值对,如果一次性全部rehash,会造成资源浪费。所以将rehash的动作分多次、渐进式地完成
-
步骤:
-
为ht[1]分配空间
-
将字典中的rehashidx设置成0,表示rehash工作正式开始
-
在rehash期间,程序每次对字典进行curd时,除了正常指定的动作外,然后根据rehashidx的值,将ht[0].table[rehashidx]上所有的键值对转移到ht[1], 然后计数器加1。
简单来说,就是指示旧哈希表中的索引,rehash会一次性把索引上的所有哈希链表节点都搬移。
-
随着字典操作不断进行,ht[0]会全部转移完成。然后将rehashidx的值设置为-1
-
-
ht[0] , ht[1] ?操作怎么做 ?
- 增加只增加到ht[1]
- 删除、查找、更新,会先在ht[0]上动作,找不到,则在ht[1]上动作。即有了一个均摊的作用~
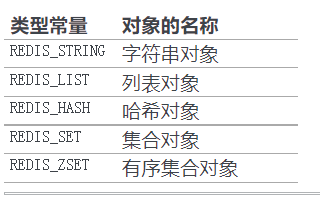
五、跳跃表
1跳跃表数据结构
https://www.jianshu.com/p/dc252b5efca6
-
什么是跳跃表?skiplist是一种基于有序链表的扩展,简称跳表
-
问题背景:怎样能更快查找到一个有序链表的某一节点
问题思路:类似于索引,将关键节点抽取出来
-
跳跃表模型:
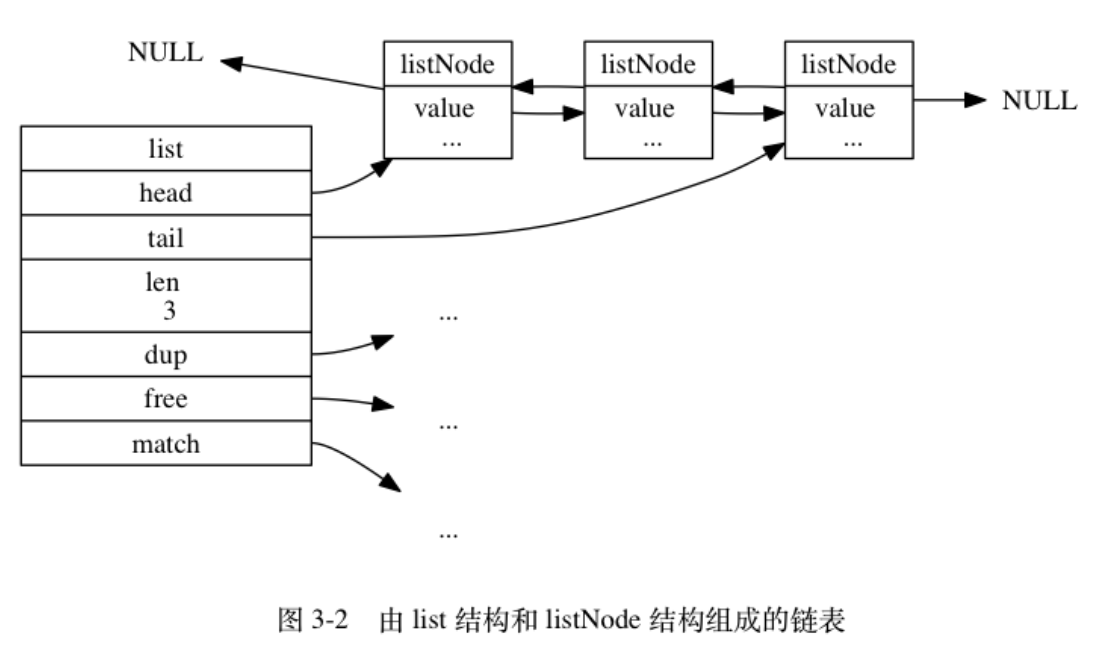
-
新索引的选取:用抛硬币的方式逐层选拔。概念是50%
原因:跳跃表的删除与添加结点是不可预测的,很难用一种有效的算法来保证跳表的索引始终均匀。
但抛硬币的方式可以保证整体均匀,而且与二叉平衡树相比,方法简单,维护成本低
-
插入流程:
-
新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
-
把索引插入到原链表。O(1)
-
利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
-
总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
-
-
删除流程:
-
自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
-
删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
-
总体上,跳跃表删除操作的时间复杂度是O(logN)。
-
-
思考为什么会有序?
本质上就是一种插入排序而已~~
2跳跃表与Redis
跳跃表结点实现

typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
属性:
- 后退指针:指向前面一个,一次只能回退一个
- 分值:double的浮点数,排序按照这个来从小到大排序
- obj属性:字符串对象
- 层:包含 前进指针 与 跨度
层的作用:
- 加快对其他节点的访问速度。一般来说,层越多访问其他节点的速度就越快
- 层的创建根据幂次定律,随机生成1~32的整数
跨度的作用:
- 用来计算排位的。在查找某个节点的过程中,把途中的跨度加起来就是排位了
跳跃表实现

typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
要注意头结点是不算在zskiplist的节点数量和level属性中的
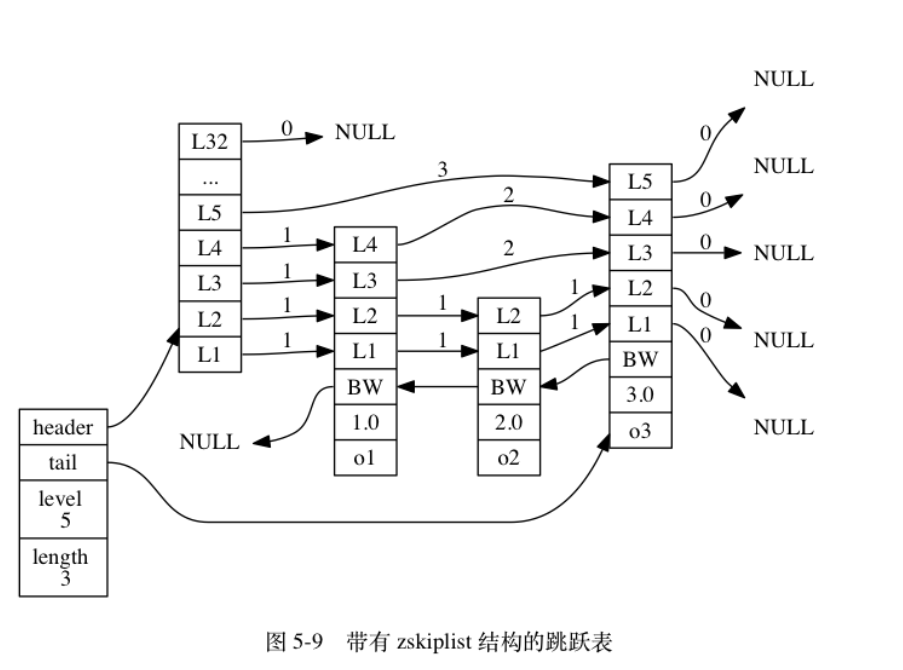
六、整数集合
使用场景:集合只包含整数值,并且数量不多
1实现结构
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
-
contents中的元素是有序的、无重复的,从小到大排序
-
contents中的int8_t的属性是不用的,真正决定数组类型的是encoding编码方式
-
模型如下:
2升级与阶级
-
概念:当一个新元素添加到集合的时候,这个元素的值类型比所有元素都大(注意负数),那么集合要先进行类型的升级,才能将新元素添加到集合中去
-
升级的三个步骤:
- 根据新元素类型,扩展空间
- 将原元素扩展到新类型,并移到正确的内存位置上(保持有序)
- 添加新元素
-
升级时,新元素的摆放位置:一定是在最前面或者最后面。
原因:因为引起升级了嘛,新元素肯定比当前所有元素都小或者大,导致当前类型容纳不下
-
升级的好处:一是提升整数集合灵活性(适应静态类型,可以随意添加不同的类型),二是节约内存
-
降级:不可能出现降级,即使最大的元素都删除了,还是不可能
七、压缩列表
- 压缩列表是redis为了节约内存而开发的
- 更像一种内存紧凑的单链表
- 意义:可以充分利用内存的缓存,即空间局部性原理
1压缩列表结构

属性:
- zlbytes:整个压缩列表的字节数
- zltail: 尾距离压缩列表头的偏移量,可以实现O(1)得到表尾地址
- zllen: 节点的数量(这里会有出入,看书)
- entryX: 实际的结点
- zlend:标志位
2结点结构
前向长度
-
概念:记录了前一个结点的长度
-
作用:可以通过当前的指针和前一个结点的长度,得到前一个结点的指针地址。
实现从尾遍历到头
-
长度:概念前一个结点的长度的不同,可以有 1字节 和 5字节 的长度。5字节中,最前面是一个标志位,所以实际上只有4字节记录长度
编码
-
作用:记录了concent中的 类型 以及 长度
-
值的前两位编码决定类型(有整数和字节数组类型),
其他的决定长度。具体的编码规则看P56
内容
- 可以是一个字节数组 或 整数
- 由encoding属性决定
3连锁更新
-
因为结点中有一个属性记录着前面一个结点的长度。当前面的结点长度发生变化时,当前结点的的“前向长度”属性的字节数可能要改变,导致当前结点的长度发生变化
-
当 当前结点长度发生变化时,可能会导致后面一个结点的长度变化,导致连锁更新现象
-
插入或者删除一个结点元素时,都可能导致连锁更新
-
复杂度:最坏:
需要N次空间重分配,每次空间重分配O(N), 所以连锁更新最坏复杂度为O(N^2)
-
性能问题
- 连锁更新出现的条件之一是,有多个连续的、长度介于250~253字节
- 数量较多,这才能导致性能问题
- 而实际中很难出现这种情况~,所以可以放心
八、对象
1基本概念与认知
- Redis数据库本身就是一本 大字典
- Redis中的每个键值对的键和值都是一个对象
- Redis主要的数据结构有:SDS,双向链表,字典,压缩列表,整数集合等
- Redis没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统
- 五大基本对象:字符串对象、列表对象、哈希对象、集合对象、有序集合对象
- 使用对象的好处:为对象设置不同的数据结构实现,可以优化对象在不同场景下的效率
- 请注意:字符串对象是唯一一个会被其他四种对象嵌套的对象,即使其他对象的值是*void类型
2对象结构
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
//引用计数用的
int refcount;
//空转时长用的
unsigned lru:22;
// ...
} robj;
类型
-
类型的取值决定了这个对象的类型,即五大基本对象:
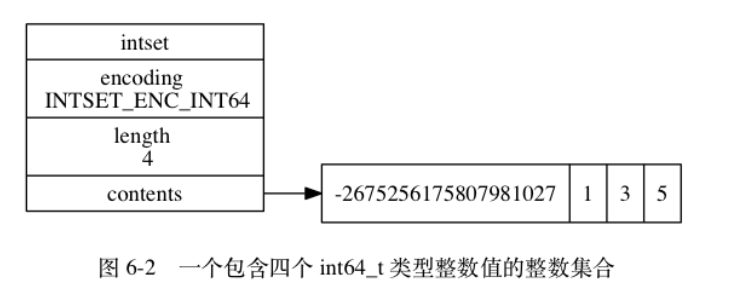
-
对于Redis数据库来说,键总是一个 “字符串对象”, 值可以是任意对象
-
“键"的含义:当说”字符串键“时,指的是这个键对应的值的对象类型type为字符串对象
-
TYPE命令:返回的结果是键对应的值的对象类型type。
对应如下:

编码与底层实现
-
ptr指针指向对象的底层实现的数据结构,类型由对象的encoding编码决定
-
数据结构编码如下:

-
编码 与 类型,两个才真正决定一个对象:

-
OBJECT ENCODING可以查看 键的值对象的编码,输出如下:
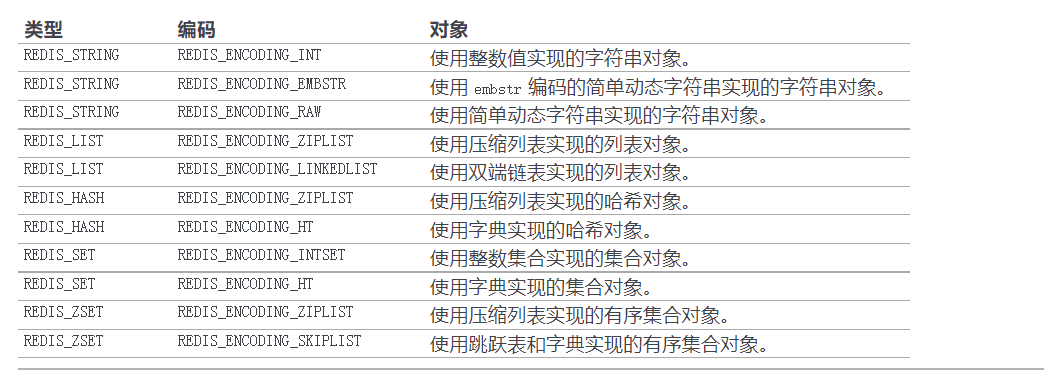
3字符串对象
编码方式int raw embstr
int
- 是字符串是一个整数
- 可以用long类型来表示
embstr: 实际上还是sdshdr
- 当字符串对象是字符串值时,长度小于等于39字节
- 是一种专门用来保存短字符串的一种优化编码
- 好处:
- 内存分配由两次降为一次P65(即为 对象 和 sds数据结构分配空间的操作)
- 内存释放也只要一次
- 由于内存连续,可以充分利用缓存的优势**(空间局部性原理)**
raw: 实际上还是sdshdr
- 当字符串对象是字符串值时,长度大于39字节
- 就是SDS啦~ (注意区别噢:sds是数据结构 而不是 对象)
编码转换
- embstr没有修改有的函数,所以是只读的
- 当对embstr修改时,会转化成raw
- 更多转化情况看 编码命令那个表
编码命令
| 命令 | int 编码的实现方法 | embstr 编码的实现方法 | raw 编码的实现方法 |
|---|---|---|---|
| SET | 使用 int 编码保存值。 | 使用 embstr 编码保存值。 | 使用 raw 编码保存值。 |
| GET | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后向客户端返回这个字符串值。 | 直接向客户端返回字符串值。 | 直接向客户端返回字符串值。 |
| APPEND | 将对象转换成 raw 编码, 然后按 raw 编码的方式执行此操作。 | 将对象转换成 raw 编码, 然后按 raw 编码的方式执行此操作。 | 调用 sdscatlen 函数, 将给定字符串追加到现有字符串的末尾。 |
| INCRBYFLOAT | 取出整数值并将其转换成 long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 | 取出字符串值并尝试将其转换成 long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 | 取出字符串值并尝试将其转换成 long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
| INCRBY | 对整数值进行加法计算, 得出的计算结果会作为整数被保存起来。 | embstr 编码不能执行此命令, 向客户端返回一个错误。 | raw 编码不能执行此命令, 向客户端返回一个错误。 |
| DECRBY | 对整数值进行减法计算, 得出的计算结果会作为整数被保存起来。 | embstr 编码不能执行此命令, 向客户端返回一个错误。 | raw 编码不能执行此命令, 向客户端返回一个错误。 |
| STRLEN | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 计算并返回这个字符串值的长度。 | 调用 sdslen 函数, 返回字符串的长度。 | 调用 sdslen 函数, 返回字符串的长度。 |
| SETRANGE | 将对象转换成 raw 编码, 然后按 raw 编码的方式执行此命令。 | 将对象转换成 raw 编码, 然后按 raw 编码的方式执行此命令。 | 将字符串特定索引上的值设置为给定的字符。 |
| GETRANGE | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 |
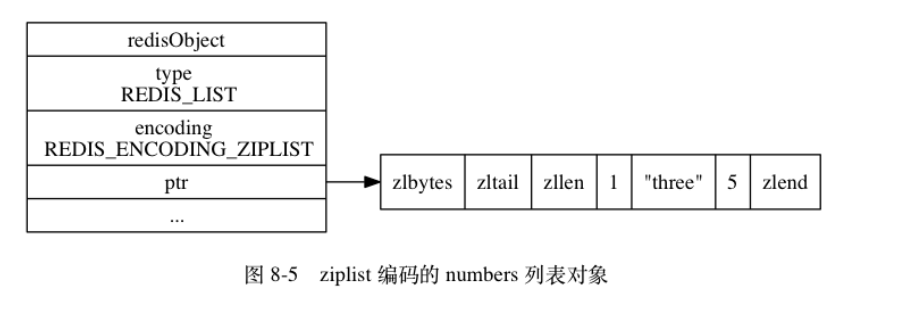
4列表对象
编码方式ziplist&linkedlist
没啥好说的~
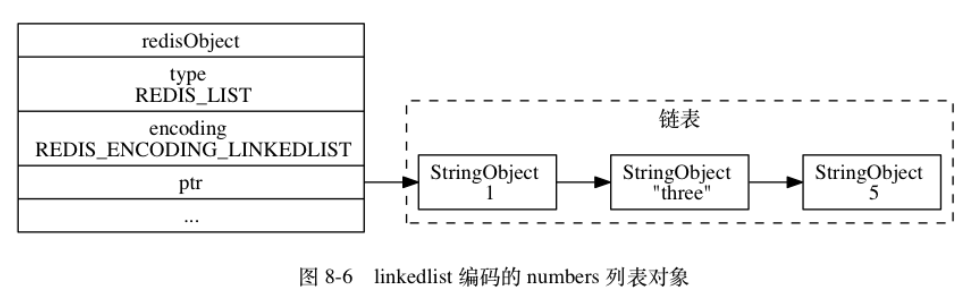
编码转换
当满足以下两个条件时,使用zipList;否则linkedlist
- 所有字符串长度小于64字节
- 元素数量小于512
编码命令
| 命令 | ziplist 编码的实现方法 | linkedlist 编码的实现方法 |
|---|---|---|
| LPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表头。 | 调用 listAddNodeHead 函数, 将新元素推入到双端链表的表头。 |
| RPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表尾。 | 调用 listAddNodeTail 函数, 将新元素推入到双端链表的表尾。 |
| LPOP | 调用 ziplistIndex 函数定位压缩列表的表头节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表头节点。 | 调用 listFirst 函数定位双端链表的表头节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表头节点。 |
| RPOP | 调用 ziplistIndex 函数定位压缩列表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表尾节点。 | 调用 listLast 函数定位双端链表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表尾节点。 |
| LINDEX | 调用 ziplistIndex 函数定位压缩列表中的指定节点, 然后返回节点所保存的元素。 | 调用 listIndex 函数定位双端链表中的指定节点, 然后返回节点所保存的元素。 |
| LLEN | 调用 ziplistLen 函数返回压缩列表的长度。 | 调用 listLength 函数返回双端链表的长度。 |
| LINSERT | 插入新节点到压缩列表的表头或者表尾时, 使用 ziplistPush 函数; 插入新节点到压缩列表的其他位置时, 使用 ziplistInsert 函数。 | 调用 listInsertNode 函数, 将新节点插入到双端链表的指定位置。 |
| LREM | 遍历压缩列表节点, 并调用 ziplistDelete 函数删除包含了给定元素的节点。 | 遍历双端链表节点, 并调用 listDelNode 函数删除包含了给定元素的节点。 |
| LTRIM | 调用 ziplistDeleteRange 函数, 删除压缩列表中所有不在指定索引范围内的节点。 | 遍历双端链表节点, 并调用 listDelNode 函数删除链表中所有不在指定索引范围内的节点。 |
| LSET | 调用 ziplistDelete 函数, 先删除压缩列表指定索引上的现有节点, 然后调用 ziplistInsert 函数, 将一个包含给定元素的新节点插入到相同索引上面。 | 调用 listIndex 函数, 定位到双端链表指定索引上的节点, 然后通过赋值操作更新节点的值。 |
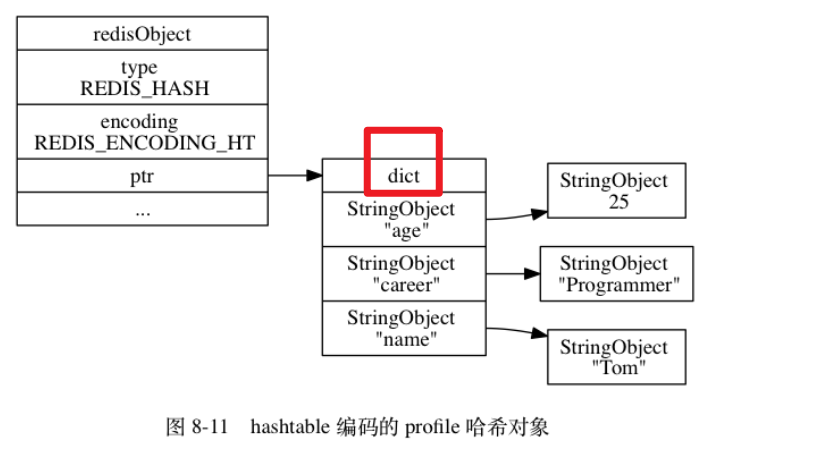
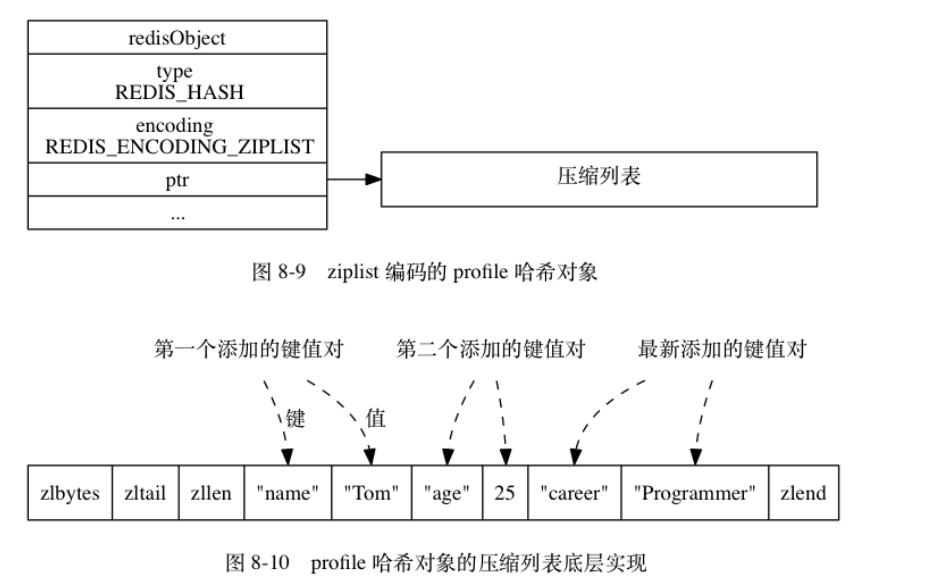
5哈希对象
编码方式ziplist & hashtable
ziplist
hashtable
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fHWfUnHN-1649826570392)(https://s2.loli.net/2022/04/13/rRCZPFiqlhMNxpK.png)]
编码转换
当满足以下两个条件时,使用ziplist;否则hashtable
- 键 和 值 的长度都小于64字节
- 键值对的数量小于512个
编码命令
表 8-9 哈希命令的实现
| 命令 | ziplist 编码实现方法 | hashtable 编码的实现方法 |
|---|---|---|
| HSET | 首先调用 ziplistPush 函数, 将键推入到压缩列表的表尾, 然后再次调用 ziplistPush 函数, 将值推入到压缩列表的表尾。 | 调用 dictAdd 函数, 将新节点添加到字典里面。 |
| HGET | 首先调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后调用 ziplistNext 函数, 将指针移动到键节点旁边的值节点, 最后返回值节点。 | 调用 dictFind 函数, 在字典中查找给定键, 然后调用 dictGetVal 函数, 返回该键所对应的值。 |
| HEXISTS | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。 | 调用 dictFind 函数, 在字典中查找给定键, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。 |
| HDEL | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后将相应的键节点、 以及键节点旁边的值节点都删除掉。 | 调用 dictDelete 函数, 将指定键所对应的键值对从字典中删除掉。 |
| HLEN | 调用 ziplistLen 函数, 取得压缩列表包含节点的总数量, 将这个数量除以 2 , 得出的结果就是压缩列表保存的键值对的数量。 | 调用 dictSize 函数, 返回字典包含的键值对数量, 这个数量就是哈希对象包含的键值对数量。 |
| HGETALL | 遍历整个压缩列表, 用 ziplistGet 函数返回所有键和值(都是节点)。 | 遍历整个字典, 用 dictGetKey 函数返回字典的键, 用 dictGetVal 函数返回字典的值。 |
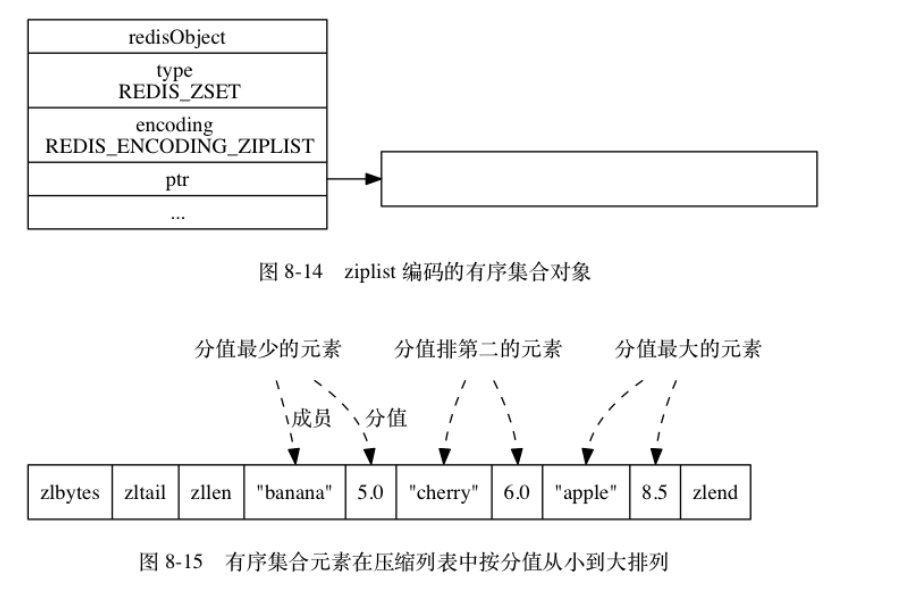
6集合对象
编码方式intset & hashtable
intset
hashtable
- 字典的值为null
编码转换
当满足以下两个条件时,使用intset, 否则使用hashtable。
- 集合元素都是整数值
- 数量不超过512个
第二个条件的上限可以在配置文件修改。
编码命令
表 8-10 集合命令的实现方法
| 命令 | intset 编码的实现方法 | hashtable 编码的实现方法 |
|---|---|---|
| SADD | 调用 intsetAdd 函数, 将所有新元素添加到整数集合里面。 | 调用 dictAdd , 以新元素为键, NULL 为值, 将键值对添加到字典里面。 |
| SCARD | 调用 intsetLen 函数, 返回整数集合所包含的元素数量, 这个数量就是集合对象所包含的元素数量。 | 调用 dictSize 函数, 返回字典所包含的键值对数量, 这个数量就是集合对象所包含的元素数量。 |
| SISMEMBER | 调用 intsetFind 函数, 在整数集合中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 | 调用 dictFind 函数, 在字典的键中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
| SMEMBERS | 遍历整个整数集合, 使用 intsetGet 函数返回集合元素。 | 遍历整个字典, 使用 dictGetKey 函数返回字典的键作为集合元素。 |
| SRANDMEMBER | 调用 intsetRandom 函数, 从整数集合中随机返回一个元素。 | 调用 dictGetRandomKey 函数, 从字典中随机返回一个字典键。 |
| SPOP | 调用 intsetRandom 函数, 从整数集合中随机取出一个元素, 在将这个随机元素返回给客户端之后, 调用 intsetRemove 函数, 将随机元素从整数集合中删除掉。 | 调用 dictGetRandomKey 函数, 从字典中随机取出一个字典键, 在将这个随机字典键的值返回给客户端之后, 调用 dictDelete 函数, 从字典中删除随机字典键所对应的键值对。 |
| SREM | 调用 intsetRemove 函数, 从整数集合中删除所有给定的元素。 | 调用 dictDelete 函数, 从字典中删除所有键为给定元素的键值对。 |
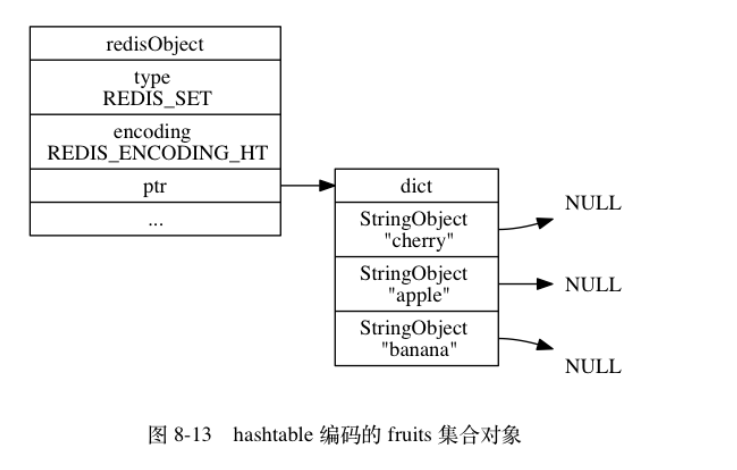
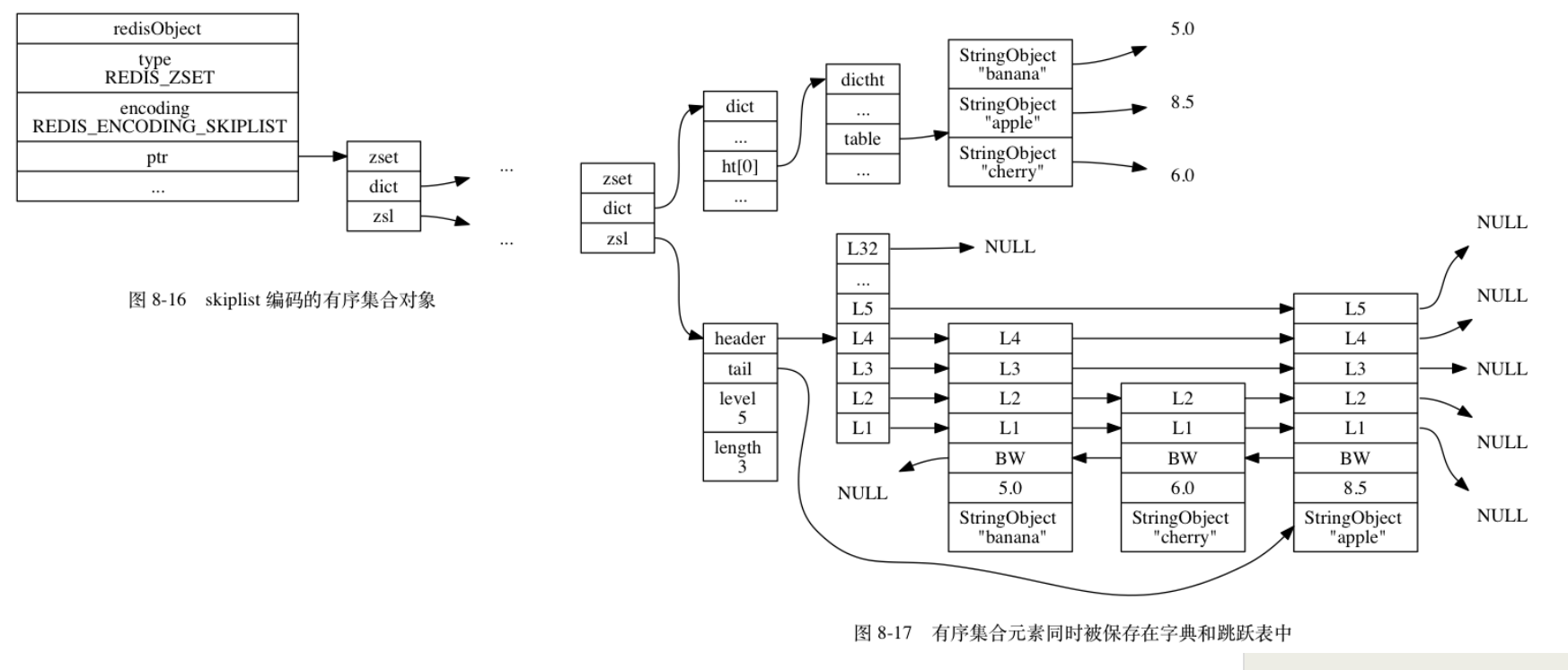
7有序集合对象
编码方式ziplist & skiplist(hashtable)
ziplist
- 第一个是元素的成员
- 第二个是分值
- 集合内的元素按照分值从小到大排序
skiplist
实现结构:
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset
- 字典的作用:提供一个成员到分值的映射
- 字典 和 zskiplist 共享对象变量,不会产生额外的内存
- 思考:为什么需要同时使用 字典 和 跳表?
- 只用字典:可以快速映射,但排序困难
- 只用跳表:可以快速排序、范围查找,但查找成员对应分值困难
- 所以为了让有序集合查找和范围型操作更快执行,同时使用两种结构
编码转换
当满足以下两个条件,使用ziplist;否则skiplist 和 dict
- 元素长度小于64字节
- 元素数量小于128个
两个条件上限是可以在配置文件修改的。
编码命令
表 8-11 有序集合命令的实现方法
| 命令 | ziplist 编码的实现方法 | zset 编码的实现方法 |
|---|---|---|
| ZADD | 调用 ziplistInsert 函数, 将成员和分值作为两个节点分别插入到压缩列表。 | 先调用 zslInsert 函数, 将新元素添加到跳跃表, 然后调用 dictAdd 函数, 将新元素关联到字典。 |
| ZCARD | 调用 ziplistLen 函数, 获得压缩列表包含节点的数量, 将这个数量除以 2 得出集合元素的数量。 | 访问跳跃表数据结构的 length 属性, 直接返回集合元素的数量。 |
| ZCOUNT | 遍历压缩列表, 统计分值在给定范围内的节点的数量。 | 遍历跳跃表, 统计分值在给定范围内的节点的数量。 |
| ZRANGE | 从表头向表尾遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表头向表尾遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZREVRANGE | 从表尾向表头遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表尾向表头遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZRANK | 从表头向表尾遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表头向表尾遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREVRANK | 从表尾向表头遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表尾向表头遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREM | 遍历压缩列表, 删除所有包含给定成员的节点, 以及被删除成员节点旁边的分值节点。 | 遍历跳跃表, 删除所有包含了给定成员的跳跃表节点。 并在字典中解除被删除元素的成员和分值的关联。 |
| ZSCORE | 遍历压缩列表, 查找包含了给定成员的节点, 然后取出成员节点旁边的分值节点保存的元素分值。 | 直接从字典中取出给定成员的分值。 |
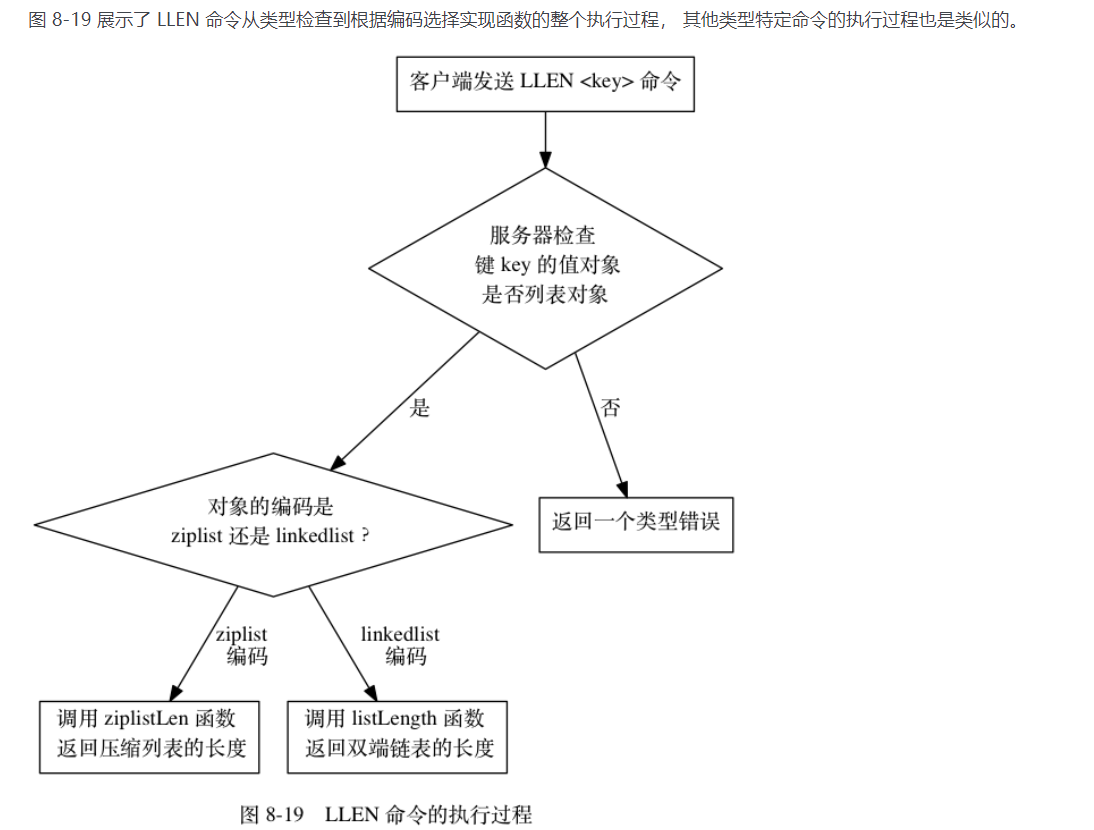
8类型检查与命令多态
- 类型多态:可以处理多种类型如DEL、EXPIRE、RENAME、TYPE、OBJECT
- 编码多态:一个类型中的命令,可以适应不同的编码。
- 简来说就是:一种命令要先检查对象类型看这个命令能否操作这个类型,再检查对象对应的数据结构根据数据结构选择不同的执行方式
9内存回收
-
使用JVM的 引用计数 思想P84
-
生命周期:创建对象、操作对象、释放对象
-
思考:redis如何防止循环引用问题?
但熟悉JVM的都知道,引用计数他有一种缺陷就是,解决不了循环引用的问题。但Redis不知道为啥不存在这个问题?
因为redis对象之间没有深层次的嵌套,因此也就不存在循环引用的隐患。这个地方要好好看看redis对象结构,才能理解。
纵观redis的对象,发现他们用不同的数据结构来实现,所以顶多有一个指向底层的实现数据结构的指针,既然redis对象里面不可以再定义一个别的引用,那么久不会出现循环引用的问题了,因为redis只共享0-9999的数值字符串对象,对于别的对象,ptr指针是不会去寻找是否有相同的,然后指向,所以不存在循环引用。
————————————————
版权声明:本文为CSDN博主「debug-LiXiwen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43958091/article/details/105163643
10对象共享
- 只共享 值为 0到9999 的字符串对象!!!
- 注意:可以通过配置文件修改
- 思考:为啥不共享字符串对象 ?
- 因为检查创建的对象和待共享对象是否完全相同时,会产生性能问题
- 对象如果修改可能会产生 ”写时复制“ 类似的问题
11对象空转时长
- redisObject中的lru属性记录了对象最后一次被程序访问的时间
- 空转时长计算:用当前时间 减 lru
- 当服务器超过maxmemory参数时,会优先释放空转时长高的键
第二部分:单机数据库的实现
九、数据库
1服务器中的数据库
redis.h/redisServer 和 redis.h/redisDb
struct redisServer {
// ...
//
一个数组,保存着服务器中的所有数据库
redisDb *db;
// ...
服务器的数据库数量
int dbnum;
// ...
};
- dbnum默认为16,可以在配置文件中修改
2切换数据库的原理
-
目标数据库:客户端写命令或者读命令的目标数据库
-
是利用一个指针的指向来实现的,即客户端结构中的db指针
-
typedef struct redisClient { // ... // 记录客户端当前正在使用的数据库 redisDb *db; // ... } redisClient; -
3数据库键空间
数据库的结构:
typedef struct redisDb {
// ...
//
数据库键空间,保存着数据库中的所有键值对
dict *dict;
// ...
} redisDb;
- 每个Redis数据库本质上是一本字典
- 键空间:redisDb结构中的dict字典保存了数据库中所有的键值地,这个字典称为键空间
- 对数据库中的键进行添加、删除、更新、取值、清空数据库、对键空间的维护操作(如脏键计数器)等,本质上都是对dic结构进行操作
4键生存时间与过期时间
基本命令一览
- 过期时间是一个Unix时间戳
1
expire <key> <ttl> #多少秒后过期
pexpire <key> <ttl> #则毫秒级别的
2
expireAt <key> <timestamp>
pexpireAt <key> <timestamp>
3
ttl <key> #返回当前键的剩余存活时间,秒级
pttl <key> #毫秒级
4
time #返回redis当前系统时间
"1234" #当前的时间戳
"2132" #当前这一秒逝去的微秒数
5
persist <key> #删除过期时间
设置和移除过期时间的原理
函数层级的原理
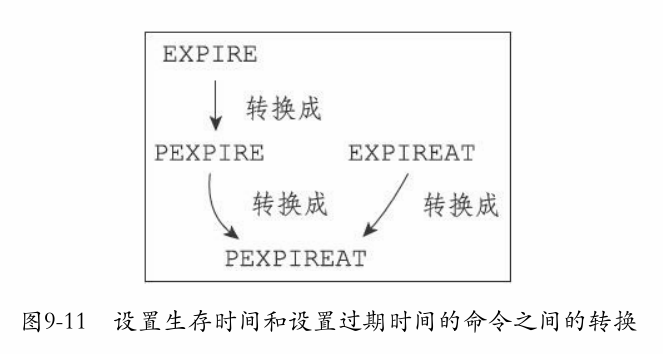
- EXPIRE、PEXPIRE、EXPIREAT三个命令都是使用PEXPIREAT命令来实现的
结构上的原理
typedef struct redisDb {
// ...
//
过期字典,保存着键的过期时间
dict *expires;
// ...
} redisDb;
- 数据库结构redisDb中,保存着一个过期字典,键为过期对象,值为过期时间
- 键为字符串,值为过期时的时间戳(long long)
- 过期字典的键 与 键空间的键 共享空间
- 当添加一个过期时间时,本质上是让过期字典中的键与键空间产生关联
- 移除过期时间,那就是删除过期字典中的键啦~ (persist命令)

剩余生存时间计算原理
- 很简单,从过期字典中拿到指定键的过期时间戳,减去当前时间即可
- 注意拿的过程中要判定是否在字典中~
过期键的判定
- 很简单,从过期字典中拿到指定键的过期时间戳,和当前时间比较,大于则未过期;小于则过期
- 同样注意拿的过程中要判定是否在字典中~
5过期删除策略
定时和定期为主动删除,惰性删除为被动删除
-
定时删除
- 在设置键和过期时间的同时,设置一个定时器
-
惰性删除
- 过期了也不删除,在取键的时间才判断是否过期与删除操作
-
定期删除
- 定周期对数据库进行检查
-
效率问题:
- 定时:对内存最友好,对CPU不好
- 惰性删除:对CPU最友好,对内存不好,还可能造成内存泄露
- 定期:是上述两种策略的中和,隔时间清理,即有利于cpu,又有利于内存。难点在于:确定删除操作的时长和频率
6Redis中的过期键删除策略
- Redis中使用的是惰性删除 与 定期删除策略
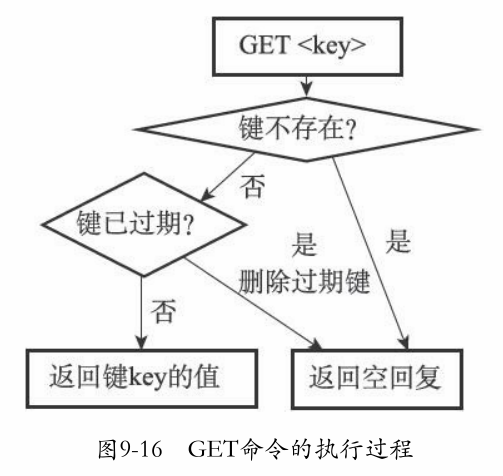
惰性原理
-
惰性删除策略的实现:过滤器
所有输入键在执行前都要调用expireIfNeeded函数
-
由于键可能被删除了,因此所有的键命令必须要处理键不存在的情况
思考:为啥这里还要删除过期键?不是已经过滤了吗 ?
原因:可能其它客户端在过滤后又删除了,而且这样设计更有利于程序的鲁棒性
(理解错啦:下面图中的“键已过期?” 才是过滤器。 因为redis是串行的,在一个命令中,怎么可能出现“其它客户端”的操作呢)
定期原理
- 周期性控制函数serverCron 调用定期删除策略函数activeExpireCycle
- 操作原理:在规定的时间内,多次遍历各个数据库,从过期字典中随机抽取键来检查,删除已经过期的键
- activeExpireCycle的大概过程如下:P110
7AOF、RDB和复制功能对过期键的处理
RDB
- 生成RDB时:已过期的键不会保存在文件中
- 载入RDB时:
- 主服务器:过期的键会被自动忽略。
- 从服务器:全部载入,然后在主从同步的时候再删除
AOF
- 生成AOF时:当键被过期清除时,会显式在aof文件中追加一条del命令
- 载入aof时:那当然是一条条命令执行啦,反正过期的键即使载入后,也会被del删除
- AOF重写:在重写工作时,已经过期的键会被检查并忽略,也就是说不会被保存在aof文件中
复制
- 主服务器当删除一个键时,会向从服务器发送del命令
- 从服务器的键即使过期,但仍然像正常的键那样操作,直到收到del命令才删除
- 好处:通过主服务器来统一删除过期键,可以** **
8数据库通知
-
通知类型:
- 键空间通知:关注的是“某个键执行了什么命令”,即某个键发生了什么事
- 键事件通知:关注的是“某个命令被什么键执行了”,即某个事在什么键上发生了
-
键空间通知 和 键事件通知 是通过一个参数实现的:notify-keyspace-events
思考:为什么两类通知用一个参数就可以配置两个呢?
原因是:这两类通知都是在一个函数内notifyKeyspaceEvent实现的,里面都是调用了pubsubPublishMessage函数。仅仅是参数(频道、名称)不同而已。本质就是对一条命令进行 “某个键发生了什么事” 和 “某个事在什么键上发生了” 信息的抽取。
-
notifyKeyspaceEvent函数调用时机:在每个基本命令执行成功后,会调用
-
两个函数细节:P115
-
实现原理:发布订阅,内部的函数就是调用了PUBLISH发布函数
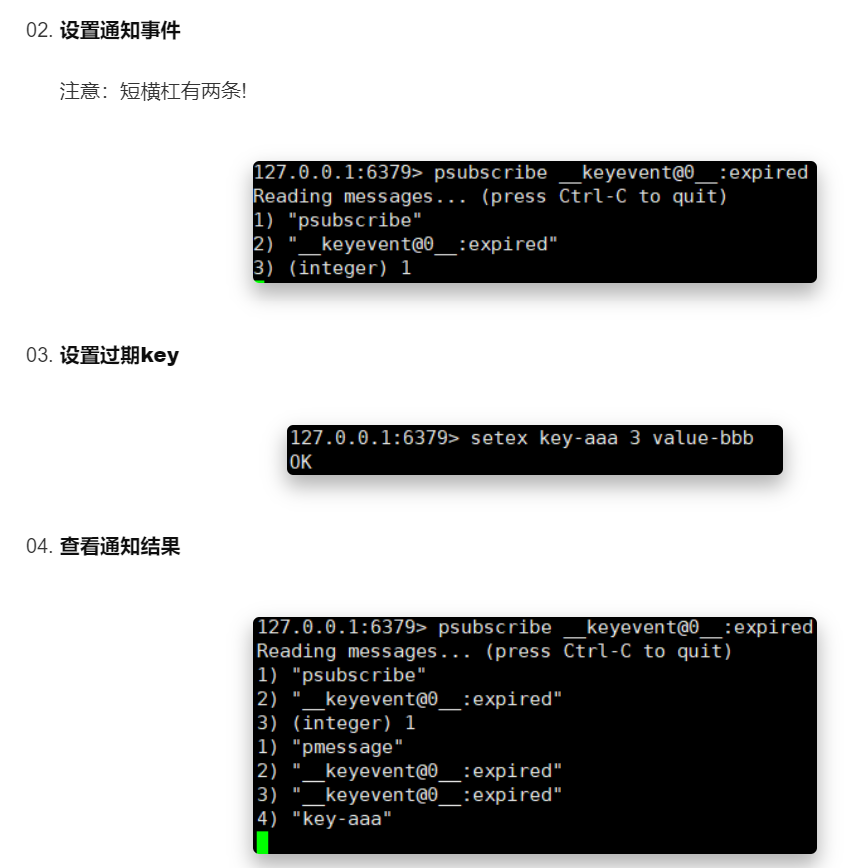
9与通知事件的关系
步骤:
- 就是,首先客户端用模式订阅,订阅自己所关心的通知类型(键事件和键空间通知合在一个模式中)
- 当键上发生了事情后,会将键空间通知 和 键事件通知组合出一个模式
- 然后调用PUBLISH发布函数,遍历模式链表找到客户端,发送。
通知的格式:
- 可以看到,本质上是一种模式订阅
- 那么谁来发布呢?当一个基本命令执行后,会执行一个通知处理函数(具体看上面的通知原理),然后再调用模式的发布命令 publish 发布
十、RDB持久化
1基本概念与理解
- 数据库状态:当前服务器中所有数据库的键值对,称为数据库状态
- RDB持久化功能生成的RDB文件是一个经过压缩的二进制文件
- RDB的功能:将Redis在内存中的数据库状态保存到磁盘里面
2创建
- 不论是save还是bgsave命令,创建的时候都是调用rdbSave函数,只是调用方式不同~一个是阻塞调用,一个是子进程调用P119
save命令
- 当执行save命令时,服务器会被阻塞,直到rdb文件创建完成为止
BGsave命令
- 会派生出一个子进程
- BGSAVE不能和save、bgsave、bgrewriteaof三个命令同时执行。不能和bgrewriteaof的原因是效率的原因
3载入
- reids没有专门用于载入rdb的文件的命令,在启动时自动载入
- 由于aof文件更新频率通常比rdb高,服务器会优先使用aof还原数据库状态(如果aof开启)
- 载入时,整个服务器都处于阻塞状态
4自动间隔保存原理
-
配置文件 :
save 900 1在900秒内,对数据库至少修改了1次,则自动执行 BGSAVE命令 -
保存的结构示例:
save 900 1 save 300 10 save 60 10000 struct redisServer { // ... // 记录了保存条件的数组 struct saveparam *saveparams; // ... }; struct saveparam { // 秒数 time_t seconds; // 修改数 int changes; }
-
dirty计数器(在redisServer中):记录上一次成功执行save/bgsave命令后,数据库进行了多少次修改(写入,删除,更新等)
-
lastsave属性(在redisServer中):是一个unix时间戳,记录上一次成功执行save/bgsave命令的时间戳
-
思考的方向:把握
save 900 1的意义即可。 -
检查条件是否满足:
serverCron默认每隔100ms会执行一次:
def serverCron(): # ... #遍历所有保存条件 for saveparam in server.saveparams: #计算距离上次执行保存操作有多少秒 save_interval = unixtime_now()-server.lastsave #如果数据库状态的修改次数超过条件所设置的次数 #并且距离上次保存的时间超过条件所设置的时间 #那么执行保存操作 if server.dirty >= saveparam.changes and save_interval > saveparam.seconds: BGSAVE() # ...
5RDB文件结构
整体结构:
全大写的表示Redis定义的常量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jjTRRs5j-1649826570400)(https://s2.loli.net/2022/04/13/lU5mzwWpn9rRu3I.png)]
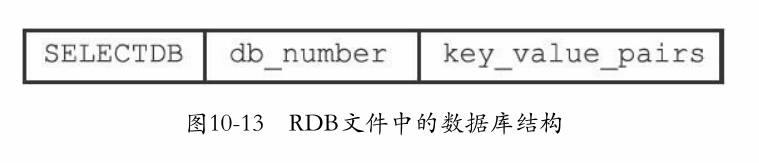
databases部分:

key_value_pairs部分(过期与不过期):
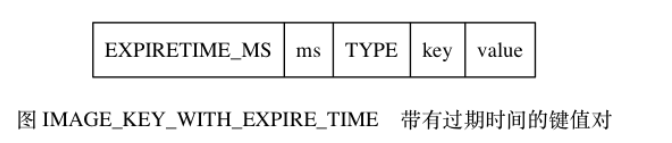


type编码:
TYPE记录了value的类型,长度为1字节,值可以是以下常量的其中
一个:
·REDIS_RDB_TYPE_STRING
·REDIS_RDB_TYPE_LIST
·REDIS_RDB_TYPE_SET
·REDIS_RDB_TYPE_ZSET
·REDIS_RDB_TYPE_HASH
·REDIS_RDB_TYPE_LIST_ZIPLIST
·REDIS_RDB_TYPE_SET_INTSET
·REDIS_RDB_TYPE_ZSET_ZIPLIST
·REDIS_RDB_TYPE_HASH_ZIPLIST
以上列出的每个TYPE常量都代表了一种对象类型或者底层编码,
当服务器读入RDB文件中的键值对数据时,程序会根据TYPE的值来决
定如何读入和解释value的数据。key和value分别保存了键值对的键对象
和值对象:
字符串对象(重点):
-
由于key总是字符串对象,所以保存方法和value一样。以下讨论的都是value部分。
-
由于其他四种对象都嵌套字符串对象,并且字符串对象是其他四种对象唯一的嵌套对象,所以对字符串的理解非常重要。
-
如果是整数:(value部分)

-
如果是字符串:
无压缩(重点):
有压缩:(根据lzf算法,压缩前后len参数,压缩后的字符串来进行还原)

列表、集合、哈希、有序集合
- 由于它们其中的元素只能是字符串对象,所以本质上和保存字符串对象非常地像,仅仅在头多了长度指示及编码指示。
- 注意的是,zset中,score是double类型,但保存的时候一律转成字符串对象
- 生成的时候,有这些元素的值,可以动态地生成了。其他一些不必要的信息就不用保存了。这点和mysql中的redo日志的思想有点一样。




INSET集合、ZIPLIST
将整个对象转化成字符串对象保存在rdb中。载入的时候转化回即可。
原因:
- 短小
- 在内存中的连续的
6分析RDB文件
od -c dump.rdb
十一、AOF持久化
1基本概念与理解
- aof:append only file
- 写入aof的所有命令都是以 redis命令请求格式保存的,是纯文本格式,可以直接打开
2持久化原理
-
持久化的步骤可以分为三个:追加、写入、同步
-
afo缓冲区结构:
struct redisServer { // ... // AOF 缓冲区 sds aof_buf; // ... }; -
追加:当服务器在执行完一个写命令后,会以协议格式将被执行的命令追加加服务器状态的aof_buff缓冲区的未尾
-
写入:指的是将aof_buff缓冲区,写入到系统的文件缓冲区中
-
同步:将系统文件缓冲区的内存真正写入到磁盘中
-
Redis的服务器的进程就是一个事件循环:
def eventLoop(): while True: #处理文件事件,接收命令请求以及发送命令回复 #处理命令请求时可能会有新内容被追加到 aof_buf缓冲区中 processFileEvents() #处理时间事件 processTimeEvents() #考虑是否要将 aof_buf中的内容写入和保存到 AOF文件里面 flushAppendOnlyFile() -
flushAppendOnlyFIle()持久化行为的控制:
appendfsync的参数决定,在配置文件中可以修改。
- always: 写入并同步
- everysec:写入,但隔一秒同步
- no:写入,但同步由操作系统决定
这三个参数的效率与安全(数据丢失问题)在P141(自己想想都知道了~
3载入和数据还原
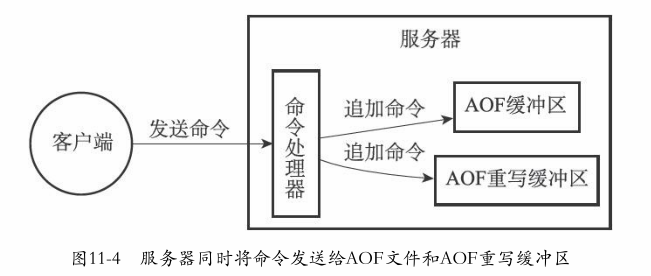
步骤:
- 创建一个伪客户端
- 从aof中读出一个命令
- 执行命令
- 重复2、3步骤
4AOF重写
-
为什么要重写:为了解决aof文件体积膨胀的问题
-
实现基础:不需要对原aof文件进行分析等,直接对当前的数据库状态进行aof重写
-
实现原理:由一条命令去代替原先的多个命令,即一个键的多个值同时设置,可以省空间
如: sadd myset v1 sadd myset v2 sadd myset v3 在服务器运行的过程中,必须保存三个命令。 可以重写为: sadd myset v1 v2 v3 压缩成了一条! -
一条命令的元素个数也是有限制的,超过64个,则不能在一条命令中。
如 sadd myset v1 ...... v64 v65 那么必须拆分成: sadd myset v1 .... v64 sadd myset v65 -
在代码的实现上,也很简单P145
- 取出一个键的所有值
- 合并成一条或多条命令
- 如果有过期时间,也要重写(读出来,重新expire一下)
5AOF后台重写
-
即 BGrewriteAOF命令的原理
-
为什么要后台重写?
普通的aof会阻塞,如果io太多,影响效率
-
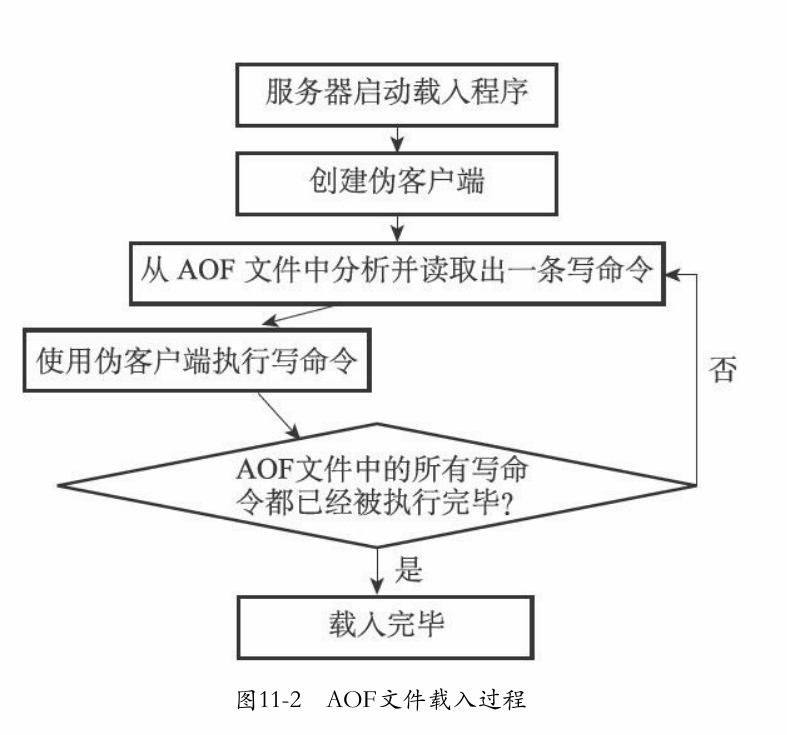
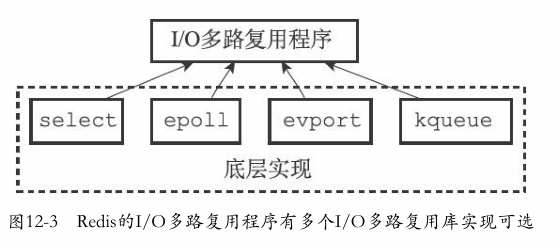
后台重写基本特征:
- 子进程在aof期间,父进程可以继续处理请求
- 子进程使用的是数据副本,可以避免锁的问题
-
后台重写的问题:在子进程写入aof期间,父进程会修改数据,导致状态不一样
-
解决方案:设置一个aof重写缓冲区(在redisServer结构中)(所以就没有必要用“写时复制机制”)
-
原理步骤:
- 父进程fork一个子进程
- 子进程处理当前数据库状态的aof重写工作
- 父进程如果有修改,则将修改后的aof追加到 afo重写缓冲区中,并且也会追加到aof缓冲区(这样可以保证原有的aof服务正常进行)
- 子进程完成后通知父进程(阻塞)
- 父进程将aof缓冲区中的命令追加到子进程完成的aof文件中(阻塞)
- 将新aof原子地覆盖原aof(阻塞)
-
原理图:
十二、事件
1操作系统基本知识
多路复用IO
https://www.zhihu.com/question/32163005
https://blog.csdn.net/tjiyu/article/details/52959418
IO 多路复用是5种I/O模型中的第3种,对各种模型讲个故事,描述下区别:
故事情节为:老李去买火车票,三天后买到一张退票。参演人员(老李,黄牛,售票员,快递员),往返车站耗费1小时。
1.阻塞I/O模型(串行)
老李去火车站买票,排队三天买到一张退票。
耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
2.非阻塞I/O模型(一个请求一个线程)
老李去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。
耗费:往返车站6次,路上6小时,其他时间做了好多事。
3.I/O复用模型
https://www.cnblogs.com/aspirant/p/9166944.html
1.select/poll
老李去火车站买票,委托黄牛,然后每隔6小时电话黄牛询问,黄牛三天内买到票,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,黄牛手续费100元,打电话17次
2.epoll
老李去火车站买票,委托黄牛,黄牛买到后即通知老李去领,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,黄牛手续费100元,无需打电话
4.信号驱动I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,免黄牛费100元,无需打电话
5.异步I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李并快递送票上门。
耗费:往返车站1次,路上1小时,免黄牛费100元,无需打电话
1同2的区别是:自己轮询
2同3的区别是:委托黄牛
3同4的区别是:电话代替黄牛
4同5的区别是:电话通
- 思考:为什么称为文件?因为沿用了linux“一切皆文件”的思想
3文件事件
文件事件的构成

-
是多路复用的,一个程序监控多个套接字
-
文件事件处理器有四个部分组成:套接字、IO多路复用程序、文件事件分派器、事件处理器
-
虽然文件事件是可能并发地出现,但是所有产生事件的套接字会放到一个队列里面,有序、同步地传送到文件事件分派器。
当一个套接字处理完成后,才转到下一个套接字
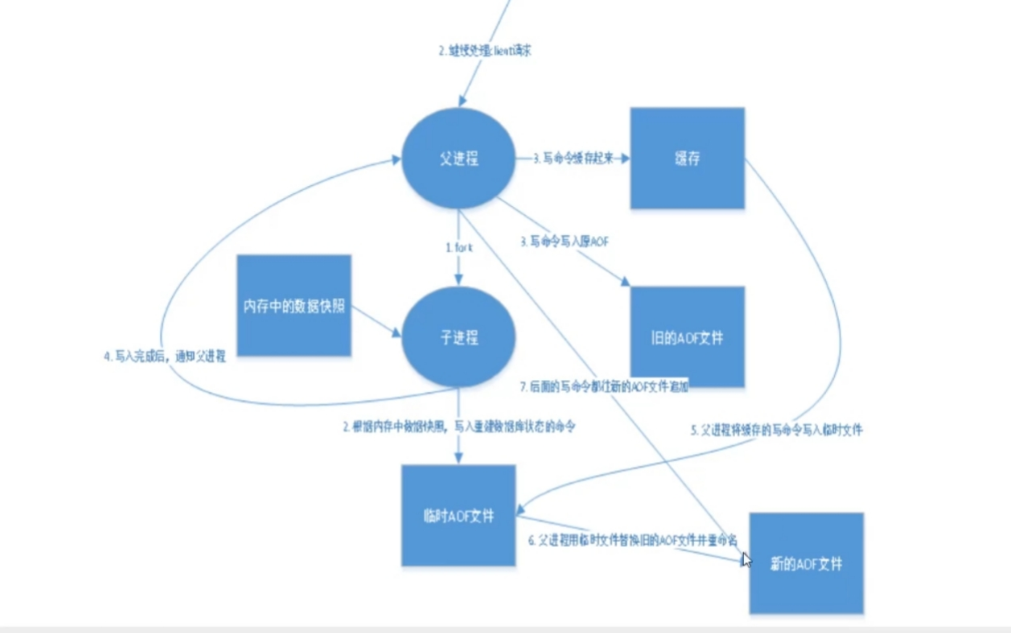
-
事件处理器实际上是一个个的函数
IO多路复用程序的实现
-
包装了操作系统中的select\poll\epoll等函数
-
这些函数提供的api是相同的,所以底层实现是可以互换的
-
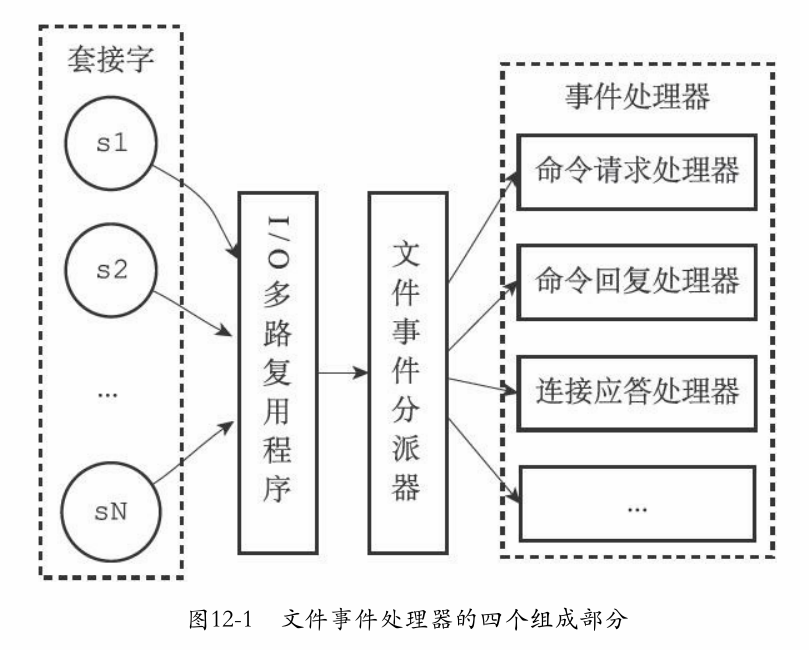
-
代码:
/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */ # ifdef HAVE_EVPORT # include "ae_evport.c" # else # ifdef HAVE_EPOLL # include "ae_epoll.c" # else # ifdef HAVE_KQUEUE # include "ae_kqueue.c" # else # include "ae_select.c" # endif # endif # endif
事件类型
- 有两类:AE_READABLE(可读)、AE_WRITABLE(可写)。注意,可读可写是相对于服务器这边的套接字而言的
- 如果一个套接字可读可写,那么服务器会优先处理读事件
API
提供了一系列的api,包括创建关联套接字事件处理器、取消关联、得到处理器名称、阻塞事件、超时等待事件发生、文件事件分派器、得到底层实现等。
文件事件处理器
- 有很多,常用的有三个
- 连接处理器:服务器先让 可读 事件关联到连接处理器,当有客户端连接时,则运行连接处理器
- 命令请求处理器:当连接过后,服务器让 可读 事件关联到请求处理器,当有请求时,则运行请求处理器(存在于客户端连接服务器的整个过程中)
- 命令回复处理器:服务器让 可写 事件关联到命令回复处理器,当有请求需要回复时,则运行命令回复处理器
- 总结::先关联,再运行。
4时间事件
-
分类:
- 定时:到指定的时间执行一次
- 定期:周期执行
-
Redis中只使用周期性事件
-
时间事件的属性:
- id:事件事件的全局唯一id
- when:什么时候发生,unix时间戳
- timeProc:执行函数,即到时间,执行这个函数
-
时间事件放在一个无序的链表中:
-
时间事件函数的实现:
1.遍历所有的时间事件函数 2.计算是否到达 3.到达则执行 4.判断是定时还是周期事件,重新设置 时间事件的属性 -
serverCron函数就是通过时间事件函数来实现的。即将timeProc指针存储serverCron函数的地址
5两类事件的调度与执行
-
文件事件 与 时间事件的调度执行如下:(重要,可以理解时间事件与文件事件的关系)
1.获取最近发生的时间事件的间隔val 2.阻塞val时间, 等待 文件事件 (以val时间为参数,调用aeApiPoll函数) 3.处理所有文件事件 4.处理所有时间事件 -
以val时间为参数,调用aeApiPoll函数的好处:
- 避免服务器对时间事件进行频繁地轮询(忙等待)
- 确保aeApiPoll函数不会阻塞太久,保证时间事件正常执行
-
Redis主代码:
def main(): #初始化服务器 init_server() #一直处理事件,直到服务器关闭为止 while server_is_not_shutdown():aeProcessEvents() #服务器关闭,执行清理操作 clean_server() -
从函数可以看到,时间事件的处理在文件事件处理之后,因此时间事件的处理时间会比设定的时间要晚一些
十三、客户端
- 本章就是对redisClient结构里面的属性进行一个详细的说明
struct redisServer {
list *clients; //一个链表,保存了所有的客户端状态
}
typedef struct redisClient {
//属性
}
下面对属性进行详细说明
-
int fd;- 记录客户端正在使用的套接字描述符
- 伪客户端的值为-1
- 普通客户端的值为大于-1的整数
- 描述符是操作系统层面的东西,对应操作系统中一个文件描述符表中的索引,打开现存文件或新建文件时,内核会返回一个文件描述符。
-
robj *name- 记录客户端的名字
- 如果没有设置,则为null
-
int flags- 记录了客户端的角色 和 状态P165
- 标志是通过 “或”操作,实现多个标志用一个变量实现的
- 角色:如主、从服务器
- 状态:如正在阻塞、在下执行什么命令、缓冲区超过大小了吗、强制aof等
-
sds querybuf- 输入缓冲区,用于保存客户端发送的命令请求
- 是一个SDS字符串,动态的
- 超过1GB会被服务器强制关闭(默认)
-
robj **argv和int argc-
argv是一个数组,记录一个个参数的值
-
argc记录数组的长度
-
注意:如set key value, set也算是一个参数,所以长度为3。所以argv[0]就是存储命令用的
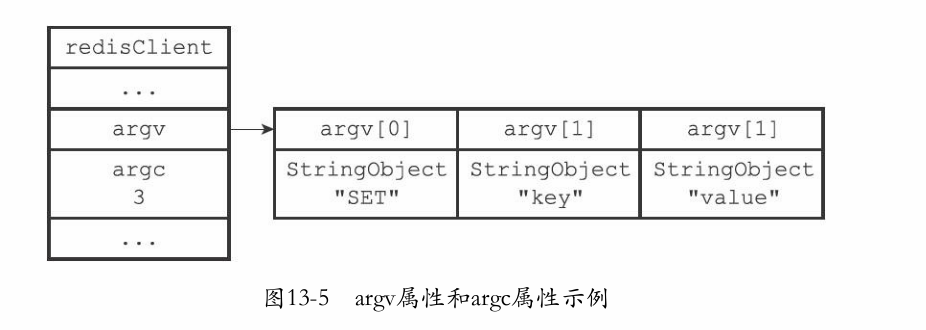
-
-
struct redisCommand *cmd-
首先,redis内部有一个命令表,是一个字典
-
针对命令表的键查找,是不区分大小写的,所以redis 命令对大小写不敏感(注意,是对argv[0]大小写不敏感)
-
当客户端要执行某个命令时,通过查命令表,就将cmd指针指向对应的函数
-
-
char buf[REDIS_REPLY_CHUNK_BYTES]和int bufpos- 是固定(输出)缓冲区
- 用来保存如ok等比较小的字符
- 当固定用完后,或者字符太大,则放进reply链表里面
-
list *reply- 可变(输出)缓冲区
- 是一个链表
- 硬性限制:如果超过,立即关闭客户端
- 软性限制:如果超过软性限制但没有超过硬性限制,如果持续时间超过预定的值,则客户端关闭(和下面的时间属性联合计算)。
- 通过client-output-buffer-limit来设硬软性限制
-
int authenticated- 身份验证,通过为1,不通过为0
- 当开启身份验证功能时,如果为0,服务器只执行auth命令,其他命令拒绝
-
时间属性
time_t ctime: 记录创建客户端的时间。可以计算客户端与服务器连接了多少秒time_t lastineraction: 记录客户端与服务器最后一次互动的时间。可以计算客户端空转时长,决定是否摧毁客户端time_t obuf_soft_limit_reached_time:记录输出缓冲区第一次到达软性限制的时间
十四、服务器
1命令执行的过程
由上到下,依次展示。
发送命令请求
人键入命令后,客户端将命令转化成 协议格式, 发送给服务器
读取命令请求
当命令发来时,套接字变得可读,调用命令请求处理器,将命令保存在querybuf中
分析命令请求
对querybuf中的命令进行抽取,抽取到argv和argc参数中
接着以下就是执行命令执行器
命令执行器(1):查找命令的实现
在命令表中,首先来说redisCommand结构的主要属性
- name:记录命令的名字,如set
- proc:记录命令的实现函数,如setCommand
- arity:记录命令的参数个数,-3代表 >= 3 (和redisClient中的argc属性的计算方法一样,set也算一个参数)
- 其他标志位和辅助位:记录写入命令、占用大量内存标志、执行次数、执行时长等P178
查找命令,就是通过argv[0]为键,对命令表进行查询
命令执行器(2):执行预备操作
- 判断cmd指针是否为null
- 判断参数个数是否正确
- 身份验证
- 内存检查
- 等等P182
命令执行器(3):调用命令执行函数
client->cmd->proc(client) (clent里面保存着命令与参数)
命令执行器(4):执行后续工作
- 如日志
- 耗费时长记录
- aof记录
- 主从同步
- 等等
将命令回复给客户端
当套接字变得 可写 时,调用命令回复处理器,将命令写入缓冲区并回复。
注意:回复完成后,会清空输出缓冲区
客户端展示结果给用户
客户端将协议格式转化成人可以读的格式,展示屏幕
也就是说,命令格式的转化全部是在客户端完成的。可以减少服务器的压力
2serverCron函数
-
每隔100ms执行一次。就是一个时间事件。功能有很多个。
-
更新服务器时间缓存:因为 获取系统时间要进行系统调用,花时间,所以缓存起来,用于精度不高的场景如时间打印
-
更新LRU时钟:用于计算对象的空转时长(为什么不用上面的服务器时间缓存?不理解)
-
更新服务器每秒执行命令的次数(100ms抽样一次,取16次的平均值 / 10 * 1000)
-
更新服务器内存峰值记录
-
处理SIGTERM信号:对redisServer.shutdown_asap属性检查,看是否关闭服务器
-
管理客户端资源:serverCron会调用clientCron函数
- 查检客户端空转时长,看是否要关闭
- 释放缓冲区 P189 (??? 不是输出缓冲区会自动清空吗 ?)
-
管理数据库资源:通过调用 databasesCron函数,对部分数据库检查,删除过期键,并rehash
-
执行被延迟的BGREWRITEAOF:
因为这个命令和BGSAVE冲突,被延迟的时候,记录一下,等等再执行
-
记录BGREWRITEAOF的子进程id,也看有没有BGREWRITEAOF有没有执行(-1代表没有)
-
将aof缓冲区写入aof文件
-
关闭客户端:如果输出缓冲区太大
-
增加cronloops计数器:记录serverCron函数执行次数
3初始化服务器
-
初始化服务器状态结构 initServerConfig
是一些比较通用的状态结构
- 运行id
- 配置文件路径
- 端口号
- 创建命令表(除了这个,其他数据结构不初始化)
- 等等
-
载入配置选项
根据用户设置的参数,对服务器参数进行设置,对默认参数进行覆盖
-
初始化服务器数据结构
- clients链表
- db数组
- 等等
- 思考:为什么要先载入用户配置后,才初始化数据结构?如果先初始化数据结构,那么用户参数设置进来,又要改变数据结构,非常麻烦。所以将server状态初始化分为两步来执行 :初始化一般属性–初始化数据结构
-
还原数据库状态
- aof
- rdb
-
执行事件循环。初始化工作圆满完成,可以处理命令了。
第四部分:独立功能的实现
十八、发布与订阅
1频道的订阅与退订
-
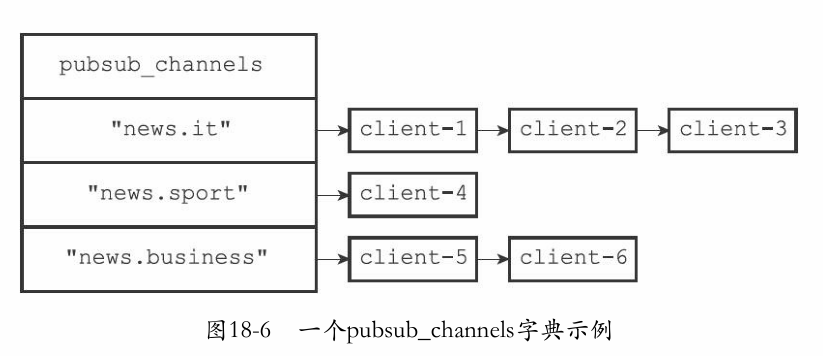
redis的频道订阅关系是存放在redisServer中的频道-订阅字典中的:
键为频道名,值为订阅的客户端链表 (和watch字典有异曲同工之妙)
struct redisServer { // ... //保存所有频道的订阅关系 dict *pubsub_channels; // ... };
-
客户端当订阅频道时,找到对应的频道,将自己加入到链表就好了(没有则创建新的字典键)
-
退订频道:找到对应的频道,将自己从链表中删除就好了(如果删除后,变成了空链表,则将该频道删除)
2模式的订阅与退订
-
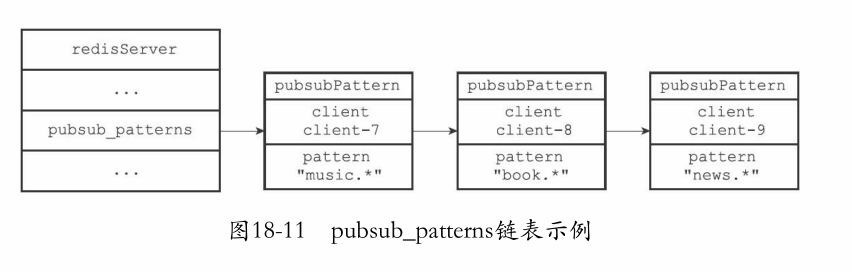
模式订阅关系是将订阅关系保存在服务器状态中的模式订阅链表中的:
struct redisServer { // ... //保存所有模式订阅关系 list *pubsub_patterns; // ... };链表的节点是一个模式结构,记录模式名和客户端
typedef struct pubsubPattern { //订阅模式的客户端 redisClient *client; //被订阅的模式 robj *pattern; } pubsubPattern; -
示意图如下:
-
当客户端订阅时:新建一个pubsubPattern结构,然后加入到链表中去
-
退订:遍历链表,将模式名和客户端名相同的去除
-
思考:为什么要把模式记录下来?这样的话在以后增加新的频道时,模式也可以对新的频道进行匹配
3发送消息
-
执行
publish <channel> <message>命令时,服务器的动作有两个:- 将message发送给channel频道的所有订阅者
- 遍历模式链表,如果模式与 匹配,则发送
也就是说,在发布的时候,会同时去匹配精确频道和模式频道
-
发送普通消息:从pubsub_channels字典中,拿到订阅者名单,遍历链表发送消息即可
-
发送模式订阅者:遍历模式链表,如果频道与客户端两个属性匹配,则发送
4查看订阅信息(命令总结)
-
查看订阅信息:
pubsub channels [pattern] 返回服务器当前被订阅的频道
pubsub numsub [channel-1, channel-2…] 返回这些频道订阅者的数量
pubsub numpat 返回服务器当前被订阅模式的数量
上面三个命令都是通过读取分析频道字典、模式链表来实现的
-
普通的命令:
subscribe <channel> 订阅 unsubscribe <channel> 退订 psubscribe <pattern> 模式订阅 punsubscribe <pattern> 退订模式 publish <channel> <message> 发布
5与通知事件的关系
通知的格式:
- 可以看到,本质上是一种模式订阅
- 那么谁来发布呢?当一个基本命令执行后,会执行一个通知处理函数(具体看上面的通知原理),然后再调用模式的发布命令 publish 发布
十九、事务
1基本概念与理解
- Redis通过multi, exec, watch等命令实现事务功能
- redis事务的特点:
- 将多个命令打包,然后一次性、按顺序执行命令
- 事务执行期间,redis不会中断事务去执行其他客户端的命令请求
- redis事务的三个阶段:
- 事务开始
- 命令入队
- 事务执行
2事务的顺序与实现
事务开始
将客户端的状态设置为事务状态:
redisClient.flags |= REDIS_MULTI
命令入队
-
当客户端处于非事务状态时,发送来的命令会被立即执行
-
如果客户端进入了事务状态,除了exec, discard, watch, multi四个命令,其他命令都放入队列中
-
事务状态:redis客户端中记录了自己的事务状态,保存在mstate属性中
typedef struct redisClient { // ... //事务状态 multiState mstate; /* MULTI/EXEC state */ // ... } redisClient; -
事务队列 与 计数器:在事务状态中
队列FIFO,放入命令。用的是一个multiCmd数组实现的
计数器则是队列中命令的个数
typedef struct multiState { //事务队列,FIFO顺序 multiCmd *commands; //已入队命令计数 int count; } multiState; -
事务命令:multiCmd结构,保存参数,参数数量,命令指针
typedef struct multiCmd { //参数 robj **argv; //参数数量 int argc; //命令指针 struct redisCommand *cmd; } multiCmd; -
状态图如下:
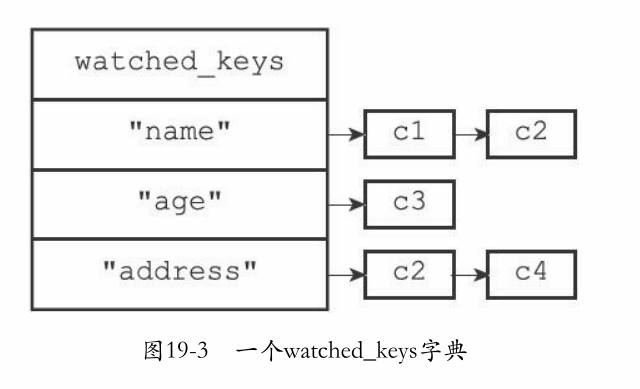
执行事务
- 当客户端发送exec命令时,会被服务器立即执行
- 事务会执照顺序执行队列中的命令,然后将回复保存在一个回复队列中,一次性回复给客户端
- 小细节:移除REDIS_MULTI标志的方法 : client.flags &= ~REDIS_MULTI (取反再与)
- 从exec的伪代码可以看出,命令是一条条执行的,是立即生效的。
3WATCH命令的实现
watch数据库键的实现
-
watch命令是一个乐观锁,当执行exec命令时,如果命令队列中的键被其他客户端修改时,exec命令会拒绝执行
-
watch命令的记录,是通过数据库中的一个 watched_key字典实现的:
键为被监视的键,值为一个执行了watch该键的客户端链表:注意是保存在数据库结构中的。
typedef struct redisDb { //注意是保存在数据库结构中的 // ... //正在被WATCH命令监视的键 dict *watched_keys; // ... } redisDb;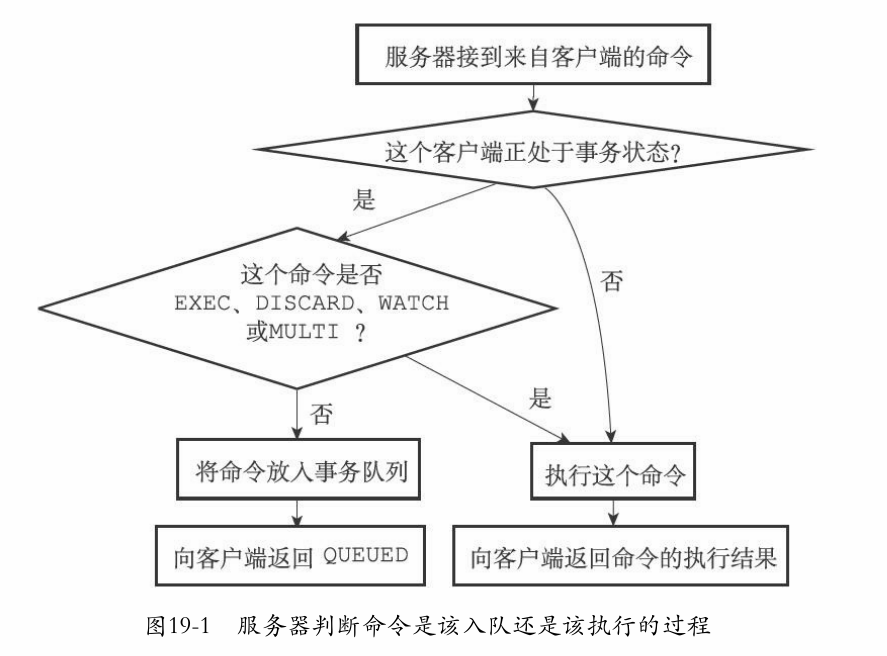
-
当一个客户端watch一个键时,会自动地把自己加入到该键对应的链表中
监视机制的触发
- 对于数据库所有的修改命令,在执行之后都会调用tochWatchKey函数,对 watch字典进行检查,将该键对应的客户端的状态设置为 REDIS_DIRTY_CAS, 代表该事务已经被破坏
判断事务是否安全
- 当客户端要执行exec命令时,如果客户端状态是REDIS_DIRTY_CAS,那么服务器会拒绝执行该事务
4Redis的ACID特性
原子性
- Redis事务是具有原子性的,事务中的命令要么不执行,要么全部执行
- 但是redis没有提供事务回滚的功能,即使某个命令在执行期间出现了错误,整个事务也会执行下去,直到所有命令执行完毕
- 注意:由于不像mysql那样提供了回滚功能,所以在事务的过程中如果宕机,命令只执行了一部分,并且没有恢复机制。这里其实是体现不出原子性的~ 上面所说的原子性应该是特指,事务如果成功提交则会执行且执行到底,不会中途中断;而不是说每个命令都会成功执行
一致性
- 一致性 的理解:一种逻辑上的正确性。数据符合数据库本身的定义,没有非法无效的数据
- 通过三个方法保证事务的一致性(我感觉不好处理像”转账“这样事务的一致性~,因为原子性不能保证,所以一致性也很难说可以保证)
- 入队错误:如果在入队的过程中,有命令本身就是错误的,那么客户端提交事务时,服务器会拒绝
- 执行错误:执行中错误,会自动忽略当前错误的命令,事务不会受错误命令的影响
- 服务器停机:有持久化的保证(我感觉这里说得有点奇怪,不太明白)
隔离性
-
隔离性是指:多个事务并发执行,事务之间不会受影响,犹如串行效果
-
由于redis事务是串行的,当然保证隔离性
耐久性
- 首先明白,redis没有为事务提供任何额外的持久化功能,所以redis持久化性质由持久化模式决定
- 仅仅当启用aof,且同步模式为appendfsync为always时,事务才具有持久性。当然no-appendfsync-on-rewrite模式要关闭。no-appendfsync-on-rewrite打开时:在执行bgsave或bgrewiteaof时,aof会停止同步
二十三、慢查询日志
1基本概念与理解
- Redis的慢查询日志功能是用户记录执行超过给定时长的命令请求,用户可以通过日志来监视和优化查询速度
- 服务器配置:
- slowlog-log-slower-than : 指定执行超过多少ms,则请求被记录
- slowlog-max-len:指定服务器最多保存多少条慢查询日志
- 注意:慢查询日志是保存在内存中的
2慢查询日志的保存
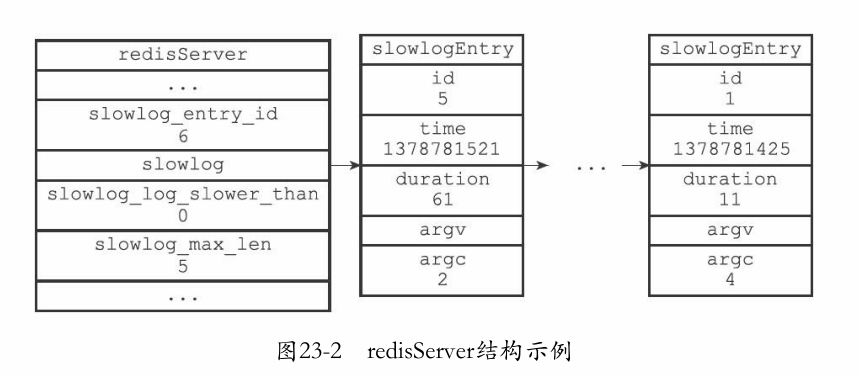
服务器中的状态结构保存着与慢查询相关的属性:
struct redisServer {
// ...
//下一条慢查询日志的ID
long long slowlog_entry_id;
//保存了所有慢查询日志的链表
list *slowlog;
//服务器配置slowlog-log-slower-than选项的值
long long slowlog_log_slower_than;
//服务器配置slowlog-max-len选项的值
unsigned long slowlog_max_len;
// ...
};
链表中的结点则是 日志的具体信息:
typedef struct slowlogEntry {
//唯一标识符
long long id;
//命令执行时的时间,格式为UNIX时间戳
time_t time;
//执行命令消耗的时间,以微秒为单位
long long duration;
//命令与命令参数
robj **argv;
//命令与命令参数的数量
int argc;
} slowlogEntry;
示意图:
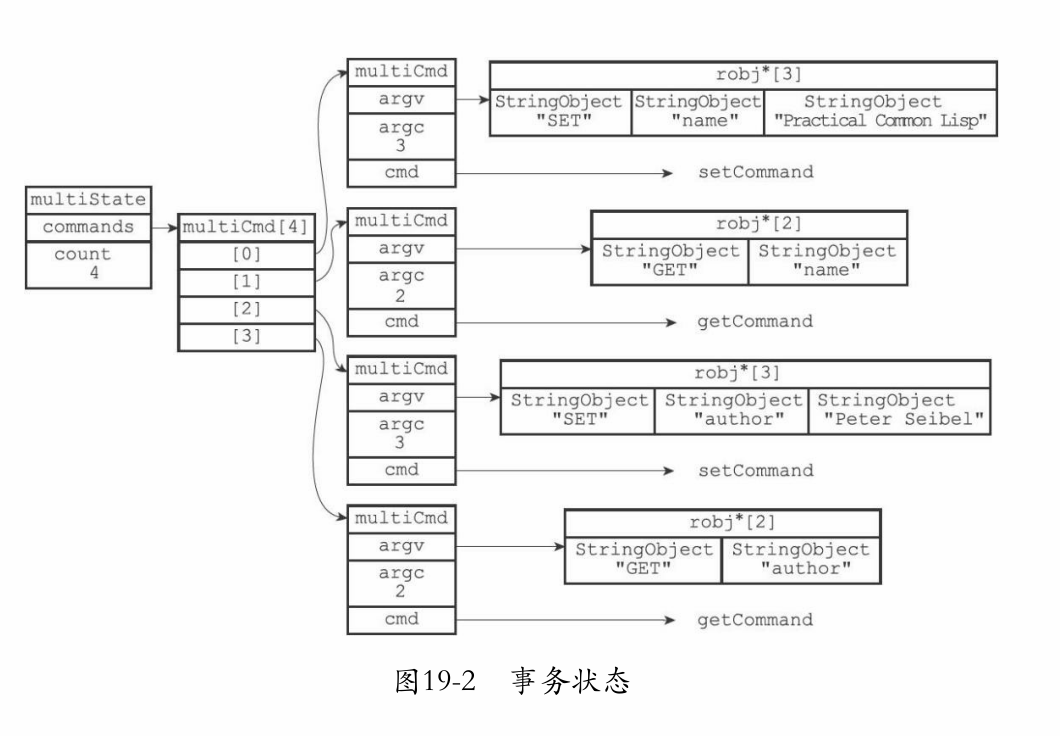
3日志的阅览与删除
SLOWLOG GET命令。- 阅览:就是遍历redisServer.slowlog链表
- 删除:就是删除redisServer.slowlog链表的结点
3添加新日志
当执行完一个命令后,添加的过程如下:
- 统计命令的执行时间
- 如果服务器开启了慢查询,且命令执行时间超过了预定值,则开始日志记录,添加到日志链表头
- 如果日志数量过多,则删除最老的















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











