






强化学习
智能体如何在环境里最大化自己的奖赏。
动作就是决策。
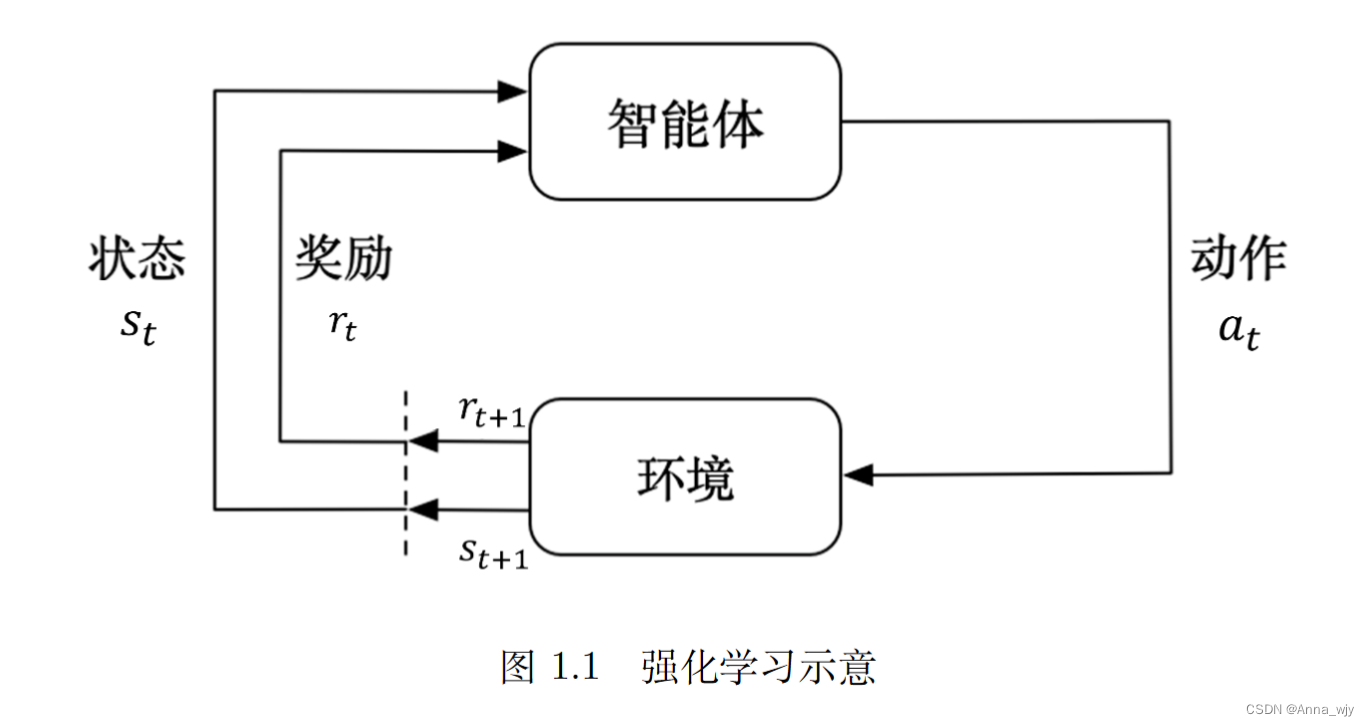
强化学习很难的原因在于智能体不能立刻得到反馈,而我们仍然希望智能体在这个环境里学习。(延迟奖励)
强化学习输入的是时间序列数据,奖励延迟,不断试错。
强化学习可以有超人类的表现。
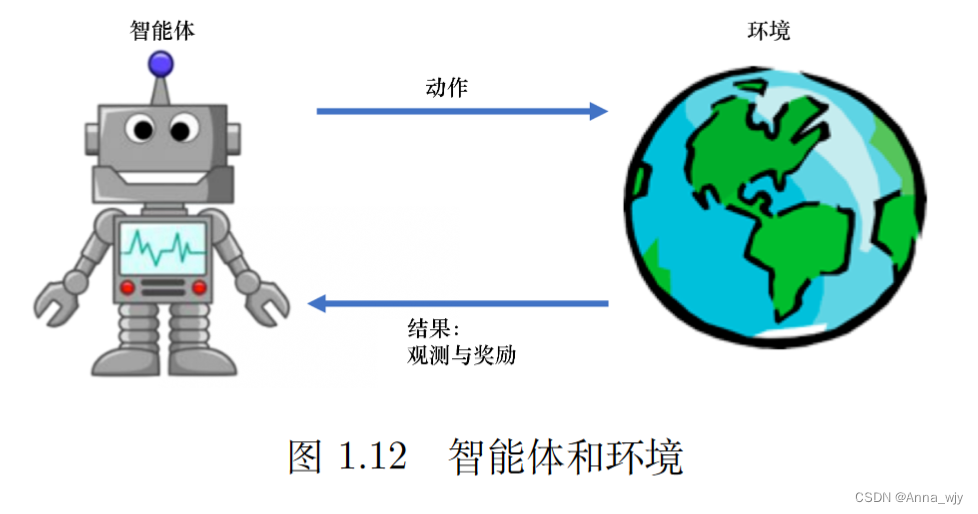
智能体的目的从观测种学到最大化奖励的策略。
强化学习的目的就是最大化智能体可以得到的期望的累计奖赏。
重要课题:近期以及远期奖赏的权衡,如何获得更多的远期奖赏。
当智能体可以观察到环境的所有状态时,环境是完全可观测的,通常情况下被建模成一个马尔可夫决策过程(MDP)的问题。
动作空间分为连续动作空间(360°)以及离散动作空间(上下左右)。
智能体的组成:策略(选择动作)价值函数(对当前状态进行评估)模型(状态转移,奖励函数)
策略:随机性策略(动作概率分布)以及确定性策略(最优的动作)。一般情况使用随机性策略,可以更好的探索环境。(多个智能体博弈时很重要,不要让其他智能体知道你接下来要做什么)
价值函数:对未来奖励的预测,用来评估状态好坏。(现在给你100还是明天,肯定是现在,引入折扣因子γ)
模型:状态转移概率以及奖励函数。
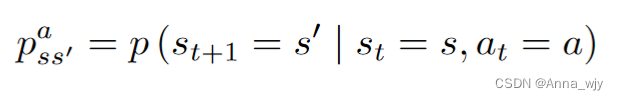
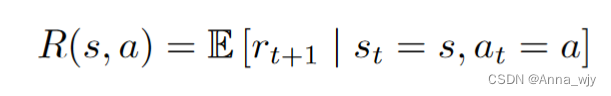
智能体的类型:基于价值的智能体以及基于策略的智能体
基于价值的智能体,需要维护Q表来采取价值最大的动作。(Q-learning, Sarsa)
基于策略的智能体,根据策略采取动作。(Actor_critic)
有模型,免模型强化学习智能体
有模型强 化学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习。(有想象力)
免模型强化学习 是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。(更为简单)
探索与利用的折中
探索:探索环境中可能存在的更好的动作,
利用:采取已经能够带来很大奖励的动作。
(牺牲短期奖励来学习到更好的策略)
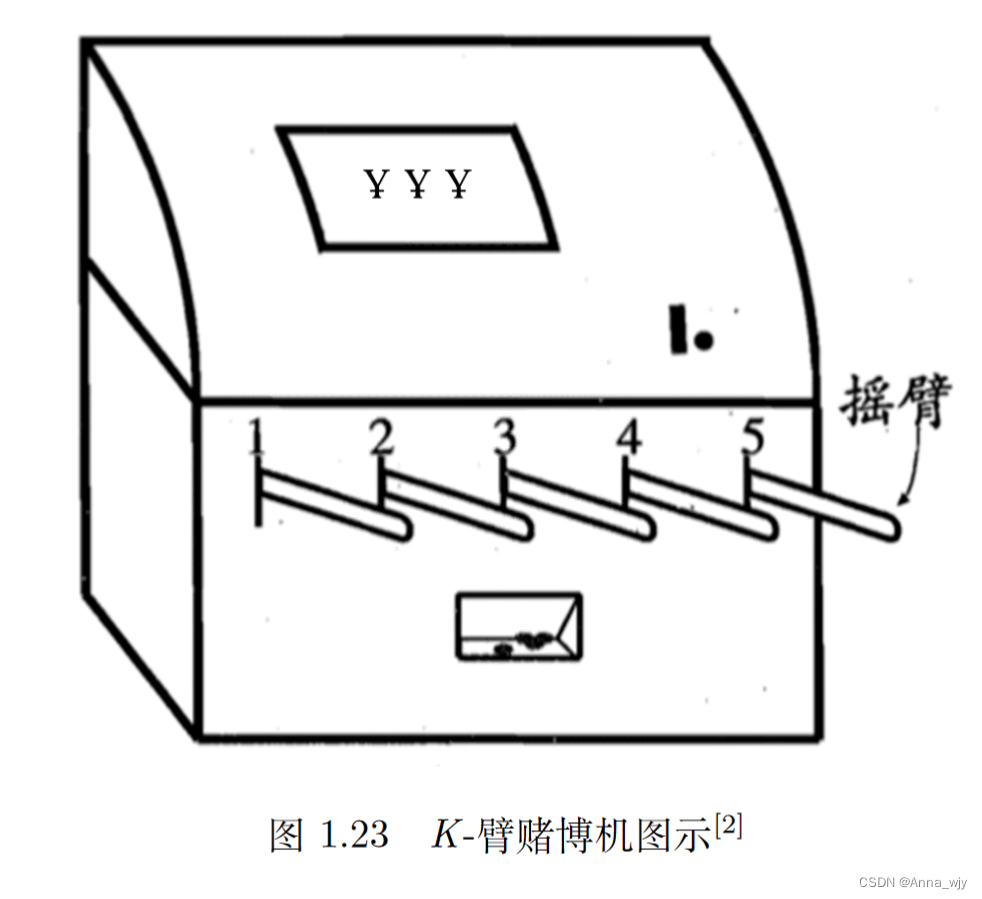
我们可以先最大化单步奖励,引入K-摇臂赌博机。
K-臂赌博机有 K 个摇臂,赌徒在投入 一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒 的目标是通过一定的策略最大化自己的奖励,即获得最多的硬币[2]。
若仅为获知每个摇臂的期望奖励,则 可采用仅探索(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖励期望的近似估计。
若仅为执行奖励最大的动作,则可采用 仅利用(exploitation-only)法:按下目前最优的(即到目前为止平均奖励最大的)摇臂,若有多个摇臂 同为最优,则从中随机选取一个。
探索与利用相互矛盾,加强一方必定削弱另一方,这就是探索利用窘境。想要累计奖励最大,必须在二者之间达成较好的折中。
马尔可夫决策过程
智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把下一个状态传给智能 体。
在强化学习中,智能体与环境就是这样进行交互的,这个交互过程可以通过马尔可夫决策过程来表示, 所以马尔可夫决策过程是强化学习的基本框架。
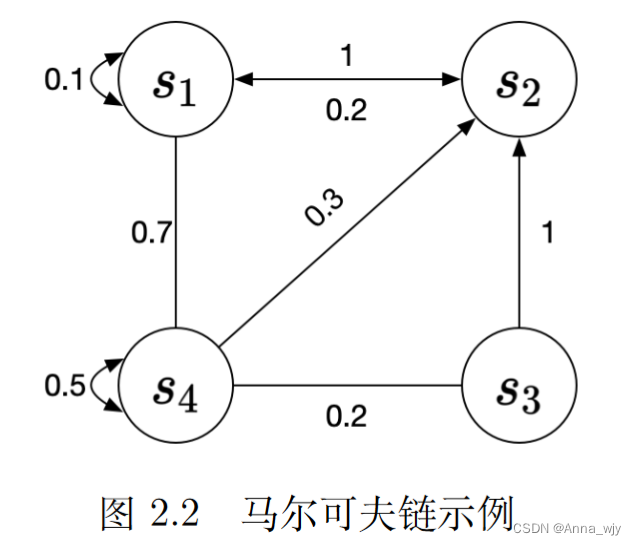
马尔可夫性质:下一个状态只与当前状态有关。

离散时间的马尔可夫过程也称为马尔可夫链(Markov chain)
马尔可夫奖励过程:马尔可夫链加上奖励函数。
回报与价值函数
回报:
![]()
价值函数:(回报的期望)
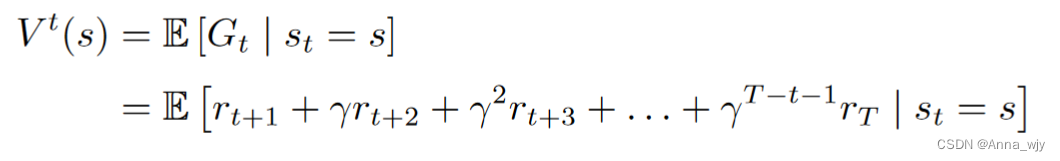
引入折扣因子的原因
1.马尔可夫过程是带环的,避免无穷奖励。
2.未来的评估不一定准确,对未来奖励添加一个折扣。
3.我们更希望立刻得到奖励,而不是以后。
贝尔曼方程
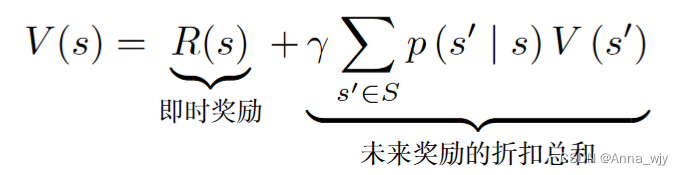
贝尔曼方程定义了当前状态以及未来状态之间的关系。
贝尔曼方程的推导:
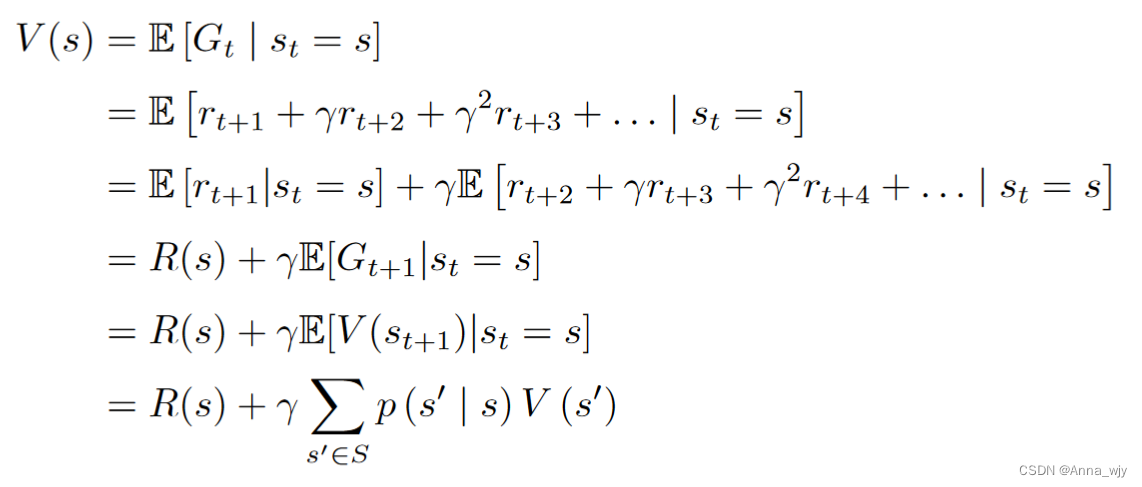
蒙特卡洛(MC)
蒙特卡洛方法是一种基于经验采样的学习方法,它的核心思想是通过模拟多次实验(或称为轨迹),根据实验结果来估计值函数(价值函数)或策略的方法。
动态规划(DP)
动态规划是一种基于递归与迭代的优化方法,通常用于解决具有最优子结构的问题,特别是在序列决策问题中广泛应用。
时序差分(TD)
时序差分学习是一种结合了蒙特卡洛方法和动态规划的学习方法,它通过不断地更新估计值函数来学习。
马尔可夫过程:状态转移
马尔可夫决策过程:相比多了动作
状态动作值函数,状态值函数
Q(s,a)状态动作值函数:在某一状态下,采取某一动作,到达最终状态很多很多次的平均期望价值。
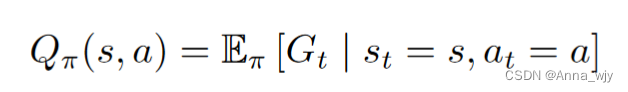
V(s)状态值函数:在某一状态下,根据某一策略,到达最终状态很多很多次的平均期望价值。(对Q函数中的动作进行加和)
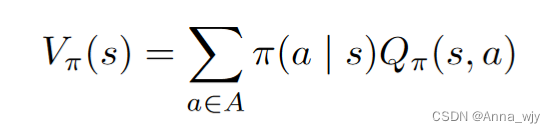
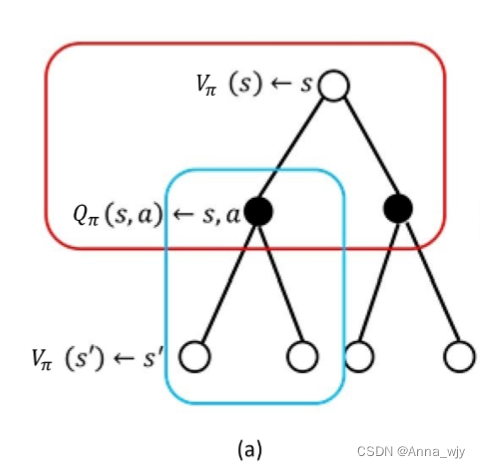
Q函数贝尔曼方程推导:

当前状态的状态值函数以及状态动作值函数与下一状态的状态值函数以及状态值函数的关联。
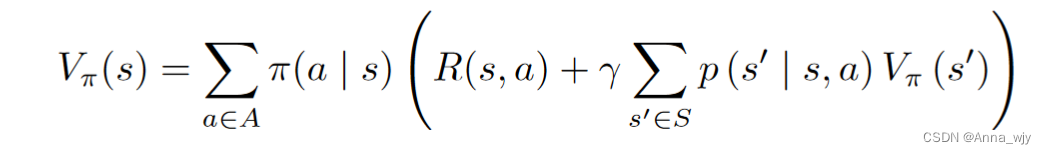
![]()
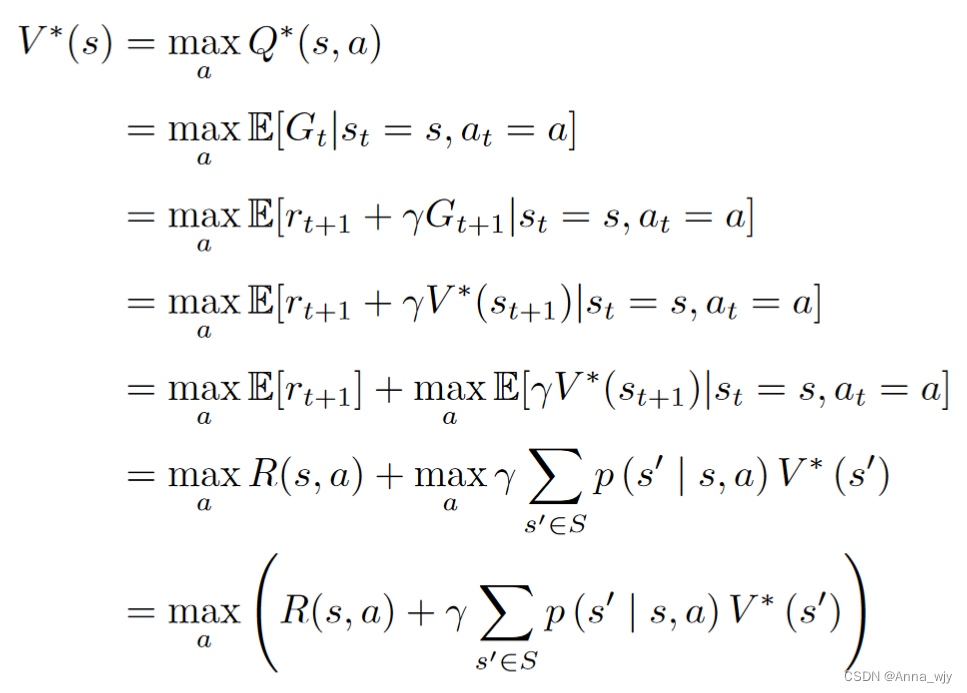
来自datawhale的rasyrl 以及自己的理解。















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









