






6.1 强化学习与深度学习的关系
从训练模式上来看,深度学习和强化学习,尤其是结合了深度学习的深度强化学习,都是基于大量的样本来对相应算法进行迭代更新并且达到最优的,这个过程我们称之为训练。但与另外两者不同的是,强化学习是在交互中产生样本的,是一个产生样本、算法更新、再次产生样本、再次算法更新的动态循环训练过程,而不是一个准备样本、算法更新的静态训练过程。
这本质上还是跟要解决的问题不同有关,强化学习解决的是序列决策问题,而深度学习解决的是“打标签”问题,即给定一张图片,我们需要判断这张图片是猫还是狗,这里的猫和狗就是标签,当然也可以让算法自动打标签,这就是监督学习与无监督学习的区别。而强化学习解决的是“打分数”问题,即给定一个状态,我们需要判断这个状态是好还是坏,这里的好和坏就是分数。当然,这只是一个比喻,实际上强化学习也可以解决“打标签”问题,只不过这个标签是一个连续的值,而不是离散的值,比如我们可以给定一张图片,然后判断这张图片的美观程度,这里的美观程度就是一个连续的值,而不是离散的值。
6.2线性回归

在这类问题中,这样的关系可以用模型来表述,我们的目标是求得一组最优的参数θ∗ ,使得该模型尽可能地能够根据房屋的 m个特征准确预测对应的房价。这类问题也叫做拟合问题,比如我们可以用一条直线来拟合一组散点,这条直线代表的就是模型。用来拟合最优参数的这些散点或者说数据称作样本,实际应用中由于需要拟合的模型是未知且复杂的,不可能用一个简单的函数来表示,因此需要大量的样本来训练模型,这些样本也就是训练集。
6.3梯度下降
其基本思想如下。
- 初始化参数:选择一个初始点或参数的初始值。
- 计算梯度:在当前点计算函数的梯度,即函数关于各参数的偏导数。梯度指向函数值增加最快的方向。
- 更新参数:按照负梯度方向更新参数,这样可以减少函数值。这个过程在神经网络中一般是以反向传播算法来实现的。
- 重复上述二三步骤,直到梯度趋近于 0 或者达到一定迭代次数。
梯度下降本质上是一种基于贪心思想的方法,它的泛化能力很强,能够基于任何可导的函数求解最优解。如图 6-3 所示,假设我们要找到一个山谷中的最低点,也就是下山,那么我们可以从任意一点出发,然后沿着最陡峭的方向向下走,这样就能够找到山谷中的最低点。这里的最陡峭的方向就是梯度方向,而沿着这个方向走的步长就是学习率,这个学习率一般是一个超参数,需要我们自己来设定。
一般情况下,我们会将学习率设定为一个较小的值,这样可以保证我们不会错过最低点,但是如果学习率过小,那么我们就需要更多的迭代次数才能够达到最低点。每次梯度下降的迭代过程中,我们都会选取一个小批量的样本来计算梯度,这个小批量的样本称为一个 batch 。这个批量相当于下山过程中我们看到的视野,如果批量太小的话,由于看不到更远的地方,我们就很容易被一些局部的山峰所迷惑,即陷入局部最优解。但是如果批量太大的话,那么我们就需要更多的计算资源。因此,我们需要根据实际情况来选择一个合适的 batch 大小。
6.4逻辑回归
简单介绍完梯度下降之后,我们就可以继续介绍一些模型了,现在是逻辑回归。注意,虽然逻辑回归名字中带有回归,但是它是用来解决分类问题的,而不是回归问题(即预测问题)。在分类问题中,我们的目标是预测样本的类别,而不是预测一个连续的值。例如,我们要预测一封邮件是否是垃圾邮件,这就是一个二分类问题,通常输出 0 和 1 等离散的数字来表示对应的类别。在形式上,逻辑回归和线性回归非常相似,如图 6-4 所示,就是在线性模型的后面增加一个 sigmoid 函数,我们一般称之为激活函数。
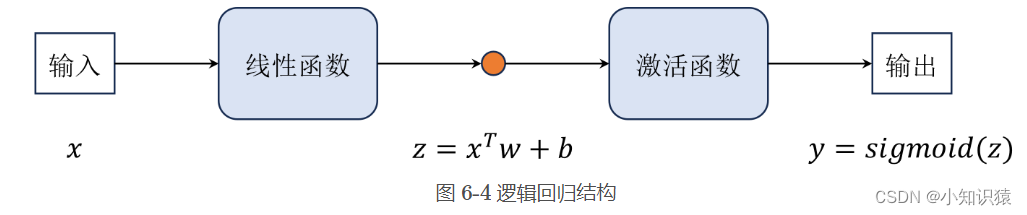
逻辑回归的主要优点在于增加了模型的非线性能力,同时模型的参数也比较容易求解,但是它也有一些缺点,例如它的非线性能力还是比较弱的,而且它只能解决二分类问题,不能解决多分类问题。在实际应用中,我们一般会将多个二分类问题组合成一个多分类问题,例如将 sigmoid 函数换成 softmax 回归函数等。
6.5全连接网络
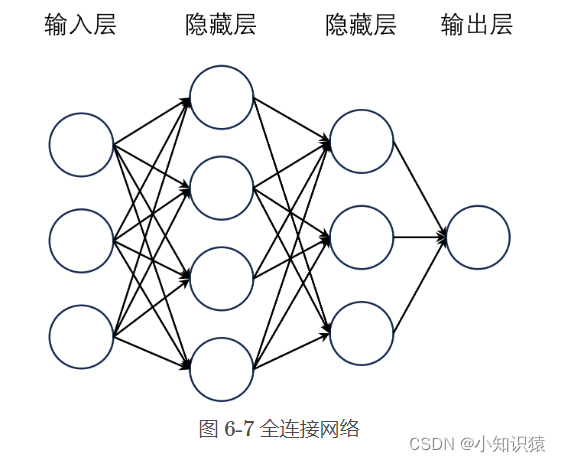
如图 6-7 所示,将线性层横向堆叠起来,前一层网络的所有神经元的输出都会输入到下一层的所有神经元中,这样就可以得到一个全连接网络。其中,每个线性层的输出都会经过一个激活函数(图中已略去),这样就可以增加模型的非线性能力。

6.6更高级的神经网络
通常来说,基于线性模型的神经网络已经足够适用于大部分的强化学习问题。但是对于一些更复杂更特殊的问题,我们可能需要更高级的神经网络模型来解决。这些高级的神经网络理论上能够取得更好的效果,但从实践上来看,这些模型在强化学习上的应用并不是很多,因为这些模型的训练过程往往比较复杂,需要调整的参数也比较多,而且这些模型的效果并不一定比基础的神经网络模型好很多。
因此,读者在解决实际的强化学习问题时还是尽量简化问题,并使用基础的神经网络模型来解决。在这里我们只是简要介绍一些常用的高级神经网络模型,感兴趣的读者可以自行深入了解。
6.6.1卷积神经网络
卷积神经网络(,convolutional neural network,CNN)适用于处理具有网格结构的数据,如图像(2D网格像素点)或时间序列数据(1D网格)等,其中图像是用得最为广泛的。比如在很多的游戏场景中,其状态输入都是以图像的形式呈现的,并且图像能够包含更多的信息,这个时候我们就可以使用卷积神经网络来处理这些图像数据。在使用卷积神经网络的时候,我们需要注意以下几个主要特点:
- 局部感受野:传统的线性神经网络每个节点都与前一层的所有节点相连接。但在CNN中,我们使用小的局部感受野(例如3x3或5x5的尺寸),它只与前一层的一个小区域内的节点相连接。这可以减少参数数量,并使得网络能够专注于捕捉局部特征。
- 权重共享:在同一层的不同位置,卷积核的权重是共享的,这不仅大大减少了参数数量,还能帮助网络在图像的不同位置检测同样的特征。
- 池化层:池化层常常被插入在连续的卷积层之间,用来减少特征图的尺寸、减少参数数量并提高网络的计算效率。最常见的池化操作是最大池化( Max-Pooling ),它将输入特征图划分为若干个小区域,并输出每个区域的最大值。
- 归一化和 Dropout :为了优化网络的性能和防止过拟合,可以在网络中添加归一化层(如 Batch Normalization )和 Dropout 。
6.6.2循环神经网络
循环神经网络(,recurrent neural network,RNN)适用于处理序列数据,也是最基础的一类时序网络。在强化学习中,循环神经网络常常被用来处理序列化的状态数据,例如在 Atari 游戏中,我们可以将连续的四帧图像作为一个序列输入到循环神经网络中,这样一来就能够更好地捕捉到游戏中的动态信息。但是基础的 RNN 结构很容易产生梯度消失或者梯度爆炸的问题,因此我们通常会使用一些改进的循环神经网络结构,例如 LSTM 和 GRU 等。LSTM 主要是通过引入门机制(输入门、遗忘门和输出门)来解决梯度消失的问题,它能够在长序列中维护更长的依赖关系。而 GRU 则是对 LSTM 的简化,它只有两个门(更新门和重置门),并且将记忆单元和隐藏状态合并为一个状态向量,性能与 LSTM 相当,但通常计算效率更高。
还有一种特殊的结构,叫做 Transformer。虽然它也是为了处理序列数据而设计的,但是是一个完全不同的结构,不再依赖循环来处理序列,而是使用自注意机制 (self-attention mechanism) 来同时考虑序列中的所有元素。并且 Transformer 的设计特别适合并行计算,使得训练速度更快。自从被提出以后,Transformer 就被广泛应用于自然语言处理领域,例如 BERT 以及现在特别流行的 GPT 等模型。
















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











