






前言
Pandas是建立在Numpy上的一个Python数据处理库,能够轻松处理带标签数据和关系数据。
creating, reading and writing
创建数据
用到的函数主要是DataFrame和Series
import pandas as pd
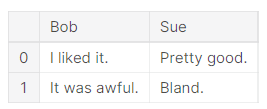
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
##DataFrame 是表格,创建格式如上,输出如下图一,默认第一列是从0到n的整数
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
##如果需要定义列标签,用index这个参数即可,如图二

##Series是个列表,与DataFrame类似,列标签通过变量index添加
pd.Series([1, 2, 3, 4, 5])
##输出
0 1
1 2
2 3
3 4
4 5
dtype: int64
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
##输出
2015 Sales 30
2016 Sales 35
2017 Sales 40
Name: Product A, dtype: int64
读取数据
一般用于读取的数据都是.csv格式,所以用函数 pd.read_csv() 来读取。
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")
##可以用shape函数来查看数据矩阵的大小,输出表示129971行,14列
wine_reviews.shape
##输出
(129971, 14)
##可以用head()函数来查看前5列
wine_reviews.head()
##有的csv文件自带第一列(索引),但是pandas有时并不能自动识别它,而是自动建立一个新的(索引),也就是之前提到过的从0到n的正整数。
## 遇到这种情况,解决方法如下,指定参数 index_col
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)


向文件中写入数据
animals = pd.DataFrame({'Cows': [12, 20], 'Goats': [22, 19]}, index=['Year 1', 'Year 2'])
animals.to_csv("cows_and_goats.csv")
Indexing, Selecting and Assigning
检索
在Python中,对列的索引很简单。如定义一个字符串矩阵 review ,它的第一行,也即表头,就是列的索引,每个值一般成为一个标签,假设其中一个标签为country。可以通过 review.country 来得到 country 这一列,或者 review[‘country’] 来得到。前者适用范围比后者小,如标签为 country size 的列,则不能通过 review.country size 来得到。
若要检索特定行列位置的数据,则通过 review[‘country’][0] 来索引,先列后行。
在pandas中,一般用函数 loc 和 iloc 来索引。其中 loc 常用于label-based selection ,即通过标签检索,这里的标签常常是字符串。 而 iloc 用于数字检索。
loc 和 iloc 另一个区别在于索引的范围。 在索引 1:10 时, loc 将会选择 0,1,2,……9,而 iloc 将会选择 0,1,2……9,10。之所以会有这样的区别,是因为 iloc 的使用场景经常是字符串,左右两边都闭的区间比较方便。原句引用如下:
Why the change? Remember that loc can index any stdlib type: strings, for example. If we have a DataFrame with index values Apples, …, Potatoes, …, and we want to select “all the alphabetical fruit choices between Apples and Potatoes”, then it’s a lot more convenient to index df.loc[‘Apples’:‘Potatoes’] than it is to index something like df.loc[‘Apples’, ‘Potatoet’] (t coming after s in the alphabet).
与Python相反,pandas 对于行的索引更加简单。
沿用上述例子,review.iloc[0] 索引得到的结果是第一行。即,对于pandas来说,先行后列。
若想索引得到第一列,则需要 review.iloc[:,0] ,表示所有行的第一个。
添加
增加新的行可以使用函数 set_index() ,如 review.set_index(‘title’) ,此操作是建立一个新的行,并且该行第一个位置赋值为字符串 ’title’ ,其余空缺。该行位于此矩阵的第一行。















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









