









1、Google浏览器模拟登录淘宝
先下载chromedriver
链接:https://pan.baidu.com/s/1YoUCxtmrWXKxcoO9wwZwNA
提取码:ulg0

配置chromedriver
将该文件添加到python.exe chorme.exe 同目录下
import random
import time
# 修改代码如下
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
避开淘宝对selenium的检测,避免滑动验证
class Taobao_Infos:
# 魔术方法 构造方法
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
# self 类属性的作用可以共用
self.url = url
self.options = ChromeOptions()
self.options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.options.add_experimental_option('useAutomationExtension', False)
self.driver = Chrome(options=self.options)
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
登录
# 登录 类方法
def login_Infos(self):
# 控制浏览器去打开淘宝登录网页
self.driver.get(self.url)
if self.driver.find_element_by_xpath('//*[@id="fm-login-id"]'):
user = self.driver.find_element_by_xpath('//*[@id="fm-login-id"]')
user.send_keys('账号')
time.sleep(5)
if self.driver.find_element_by_xpath('//*[@id="fm-login-password"]'):
password = self.driver.find_element_by_xpath('//*[@id="fm-login-password"]')
password.send_keys('密码')
time.sleep(random.randint(1,6))
self.driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
time.sleep(random.randint(1, 6))
self.driver.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a/span').click()
time.sleep(random.randint(1,3))
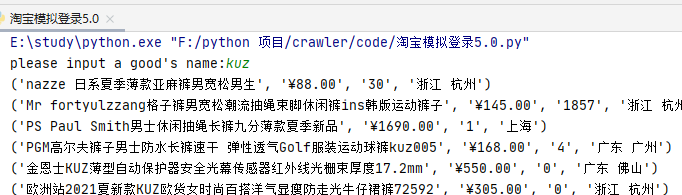
self.driver.find_element_by_xpath('//*[@id="q"]').send_keys(input("please input a good's name:"))
time.sleep(random.randint(1,3))
self.driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
2、多线程爬取bs4
#获取商品信息
page = self.driver.page_source
soup = BeautifulSoup(page,'lxml')
shop_data_list = soup.find('div',class_='grid g-clearfix').find_all_next('div',class_='items')
#多个信息
shop_name_list = []
shop_price_list = []
shop_peoplenumber_list = []
shop_location_list = []
for shop_data in shop_data_list:
#name
shop_image_data = shop_data.find_all('div',class_='pic')
for shop_data_a in shop_image_data:
shop_data_a = shop_data.find_all('a',class_="pic-link J_ClickStat J_ItemPicA")
for shop_name in shop_data_a:
shop_name =shop_name.find_all('img')[0]['alt']
shop_name_list.append(shop_name)
shop_price_data = shop_data.find_all('div',class_='price g_price g_price-highlight')
for shop_price in shop_price_data:
shop_price_list.append(shop_price.text.strip())
#peoplenumber
shop_peoplenumber_data = shop_data.find_all('div',class_='deal-cnt')
for shop_peoplenumber in shop_peoplenumber_data:
shop_peoplenumber_list.append(shop_peoplenumber.text[:-3])
#shop location
shop_location_data = shop_data.find_all('div',class_='location')
for shop_location in shop_location_data:
shop_location_list.append(shop_location.text)
shop_data = zip(shop_name_list,shop_price_list,shop_peoplenumber_list,shop_location_list)
for data in shop_data:
print(data)
Taobao_Infos().login_Infos()
所有代码
import random
import time
# 修改代码如下
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup # 数据筛选 网页选择器
# 爬虫流程 面向对象
class Taobao_Infos:
# 魔术方法 构造方法
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
# self 类属性的作用可以共用
self.url = url
self.options = ChromeOptions()
self.options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.options.add_experimental_option('useAutomationExtension', False)
self.driver = Chrome(options=self.options)
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 登录 类方法
def login_Infos(self):
# 控制浏览器去打开淘宝登录网页
self.driver.get(self.url)
if self.driver.find_element_by_xpath('//*[@id="fm-login-id"]'):
user = self.driver.find_element_by_xpath('//*[@id="fm-login-id"]')
user.send_keys('账号')
time.sleep(5)
if self.driver.find_element_by_xpath('//*[@id="fm-login-password"]'):
password = self.driver.find_element_by_xpath('//*[@id="fm-login-password"]')
password.send_keys('密码')
time.sleep(random.randint(1,6))
self.driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
time.sleep(random.randint(1, 6))
self.driver.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a/span').click()
time.sleep(random.randint(1,3))
self.driver.find_element_by_xpath('//*[@id="q"]').send_keys(input("please input a good's name:"))
time.sleep(random.randint(1,3))
self.driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
#获取商品信息
page = self.driver.page_source
soup = BeautifulSoup(page,'lxml')
shop_data_list = soup.find('div',class_='grid g-clearfix').find_all_next('div',class_='items')
#多个信息
shop_name_list = []
shop_price_list = []
shop_peoplenumber_list = []
shop_location_list = []
for shop_data in shop_data_list:
#name
shop_image_data = shop_data.find_all('div',class_='pic')
for shop_data_a in shop_image_data:
shop_data_a = shop_data.find_all('a',class_="pic-link J_ClickStat J_ItemPicA")
for shop_name in shop_data_a:
shop_name =shop_name.find_all('img')[0]['alt']
shop_name_list.append(shop_name)
shop_price_data = shop_data.find_all('div',class_='price g_price g_price-highlight')
for shop_price in shop_price_data:
shop_price_list.append(shop_price.text.strip())
#peoplenumber
shop_peoplenumber_data = shop_data.find_all('div',class_='deal-cnt')
for shop_peoplenumber in shop_peoplenumber_data:
shop_peoplenumber_list.append(shop_peoplenumber.text[:-3])
#shop location
shop_location_data = shop_data.find_all('div',class_='location')
for shop_location in shop_location_data:
shop_location_list.append(shop_location.text)
shop_data = zip(shop_name_list,shop_price_list,shop_peoplenumber_list,shop_location_list)
for data in shop_data:
print(data)
Taobao_Infos().login_Infos()
4、体悟
了解了selenium能模拟浏览器密码模拟登录网站,网站有反selenium机制就要想办法隐藏selenium,然后知道
self.driver.find_element_by_xpath(’//*[@id=“q”]’).send_keys(input(“please input a good’s name:”))

依照输入框为例,element中按下元素选择器,这样就能找到element中的输入框的xpath

单击右键,copy xpath
多线程爬取
from bs4 import BeautifulSoup
page = self.driver.page_source
将page转化为bs4能读的lxml
soup = BeautifulSoup(page,‘lxml’)
取的div 标签class= ‘grid g-clearfix’ div,class_='items’的数据
shop_data_list = soup.find(‘div’,class_=‘grid g-clearfix’).find_all_next(‘div’,class_=‘items’)
可以按照找输入框的方式找到数据所在标签位置,然后再根据标签找到数据


还有一些细节方面这里就不写了。有见解的小伙伴欢迎交流
这里是爬取的内容由于是第一次模拟登录的原因就没有写入数据库,
以及没有使用代理IP爬取海量内容。下次再解决这个问题















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









