




从今天开始,给大家介绍Python爬虫相关知识,今天主要内容是爬虫的基础理论知识。
一、爬虫简介
爬虫是指通过编写程序,来模拟浏览器访问Web网页,然后通过一定的策略,爬取指定内容。因此,爬虫的编写通常分为两个部分,第一部分是更好的模拟浏览器,第二部分是在爬虫爬取的网页信息中,通过一定的方法,提取出我们想要的数据。
爬虫可以快速筛选互联网上的指定数据信息,因此具有很高的应用价值。有一种说法称:“互联网上有”
二、爬虫合法性和编写注意事项
爬虫本身在法律上是不被禁止的,但是爬虫本身作为一项技术,就尤其危险性。编写爬虫的风险主要有以下2点:
1、爬虫干扰了被访问网页的正常运营。
2、爬虫爬取了受保护的数据信息,例如他人隐私数据信息等。
因此,我们在编写爬虫程序时,要特别注意以上两点。一是合理设置爬虫爬取的速度,必要时可以使用sleep()函数可以增加爬虫爬取网页的时间间隔,特备是要审慎使用多线程;二是注意不要爬取收到法律保护的信息,即使是爬取网络上的公开信息,也要注意信息的处理和使用,尽量避免将爬虫爬取的信息传递出去。
在互联网发展初期,各大搜索引擎和知名网站站长之间约定了一个“君子协定”——robots协议。robots协议是各大站点在自己网站的主页面下,创建了一个robots.txt的文件,在该文件中规定了哪些爬虫可以爬取哪些网页,或者不可以爬取哪些网页。
例如,淘宝的robots.txt文件内容如下所示:
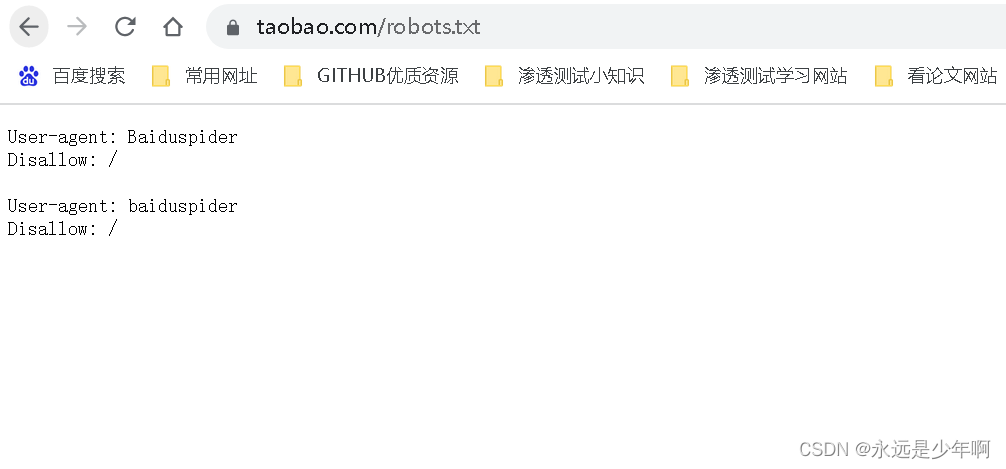
从上图可以看出,淘宝网站拒绝百度爬虫爬取自己的任何站点。
腾讯的robots.txt文件内容如下所示:

从上图中可以看出,腾讯允许任何爬虫爬取自己的任何页面。
CSDN的robots.txt文件内容如下所示:
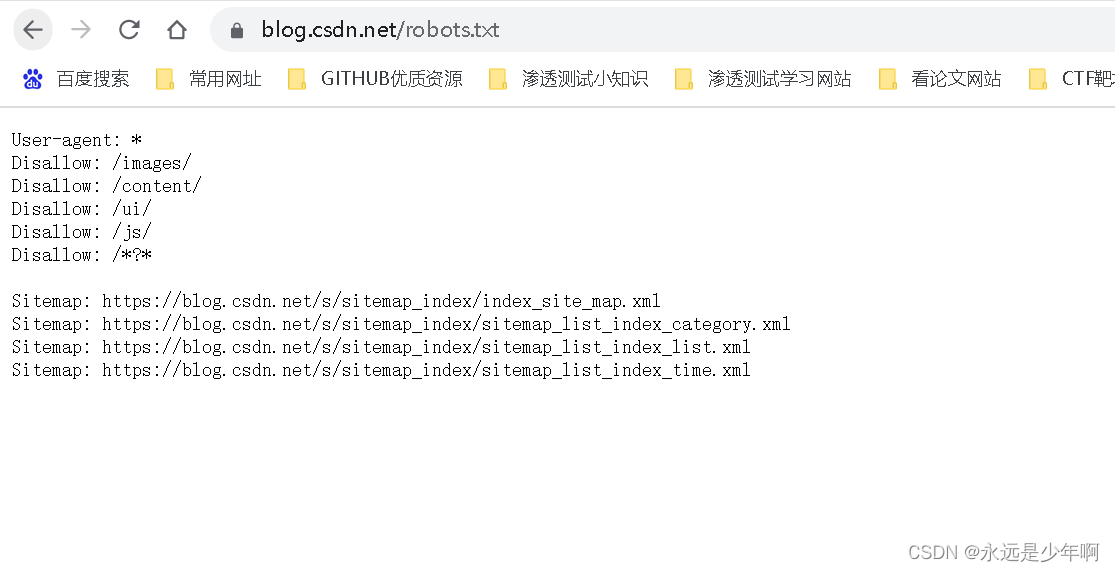
从上图中可以看出,CSDN拒绝了任何爬虫爬取/images/、/ui/等页面。
注意,robots协议之所以是一个“君子协议”,就是因为robots协议本身没有任何强制性!但是这并不意味着robots协议可有可无,有些公司因为违反robots协议而爬取他人网站信息而被迫赔偿的也有很多案例。
三、爬虫的矛与盾
不同的网站对于爬虫的态度是不同的,有的站点可能欢迎“善意”的爬虫爬取自己站点的信息,甚至刻意优化自己的网页,以方便爬虫获取网站信息;有的站点可能不喜欢任何爬虫的爬取;有的可能只允许部分爬虫爬取自己的网页,但是会拒绝其他的爬虫爬取网页。
为了应对爬虫的爬取,各大网站会设置反爬虫机制,通过一定的技术手段,限制爬虫爬取自己网站的信息。须知,爬虫爬取的网页是公开的网页。因此,反爬机制的核心就是区分正常浏览器对网站的访问和爬虫对网站的访问。与之对应的是爬虫的反反爬策略,爬虫会想办法伪装成浏览器,绕过网站的反爬机制,从而爬取到信息。
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200




















 2523
2523



 到【灌水乐园】发言
到【灌水乐园】发言










