






1.产生图像数据的分辨率
2.产生图像的大小
3.产生图像是黑白或是RGB彩色
灰度图像,达到识别要求,减少计算量
4.标注数据的精准程度
1.模型标注后,少量标注全部人工校验,大量数据抽检,部分人工检验
2.明确边界框贴合目标边缘(IoU≥0.95)
3.人工复核后加入训练集,防止模型漂移
5.模型训练中的阈值设置
置信度阈值和NMS阈值会影响检测结果
1.过高的置信度阈值可能漏检 过低则误检增多
2.
6.数据集、训练集和验证集的划分比例
1.数据集划分比例不当可能导致过拟合或欠拟合,尤其是数据量不足时
2.验证集要足够大以反映真实分布
7.训练的轮次
1.训练轮次太少可能欠拟合
2.太多可能过拟合
8.训练中的 imgsz图像大小
1.设置imgsz为采集分辨率整数倍(如原图2592×1944,训练时缩放为640×480),保持宽高比。
2.初始阶段使用全量数据粗调(batch_size=32, lr=0.01),后期冻结骨干网络微调头部(batch_size=8, lr=0.0001)。
3. imgsz与训练图像尺寸不匹配会引入缩放失真,影响小目标检测。
9.训练中的batch大小和workers数
1.Batch size和workers影响训练速度和稳定性
2.大的batch size可能更好,但受GPU内存限制,batch_size过大导致梯度震荡
3.使用自适应batch_size(如根据GPU显存动态调整),推荐16-32。
10.置信度、精度、召回率
11.采集时引入可控噪声(如轻微抖动、光照变化)以提升模型鲁棒性
12.需监控漏检率(False Negative Rate, FNR≤0.1%)
除mAP外,需监控漏检率(False Negative Rate)
13.部署模型后持续收集困难样本(如模棱两可的预测结果),定期迭代更新模型。
.
14.采用余弦退火学习率(cos_lr)和早停(patience=50),防止过拟合
15.YOLOv8的n/s版本(如YOLOv8n-1280),或通过TensorRT量化压缩模型。
如何在实际生产中更新模型而不影响生产
总结:高精度生产场景需以“零漏检”为第一目标,通过硬件选型→数据规范→算法调优→工程部署的全链路协同,最终达到mAP@0.5≥0.95、FNR≤0.05%的严苛指标。同时需设计容错机制(如不确定样本自动分拣至人工复检),平衡自动化与可靠性。
github下载加速器
1.网址
在github上下载文件时,鼠标右键需要下载的文件,点击复制下载地址,将下载地址复制到加速器中,转换为新的加速版下载地址,然后在网页上复制该地址,即可加速下载
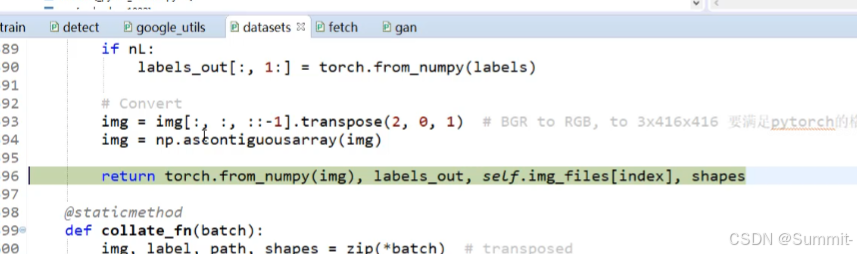
1.搭载yolo环境中的一些问题
(1)numpy包的版本问题,进行模型训练和推理时会在datasets中的yorch.from_numpy中报错
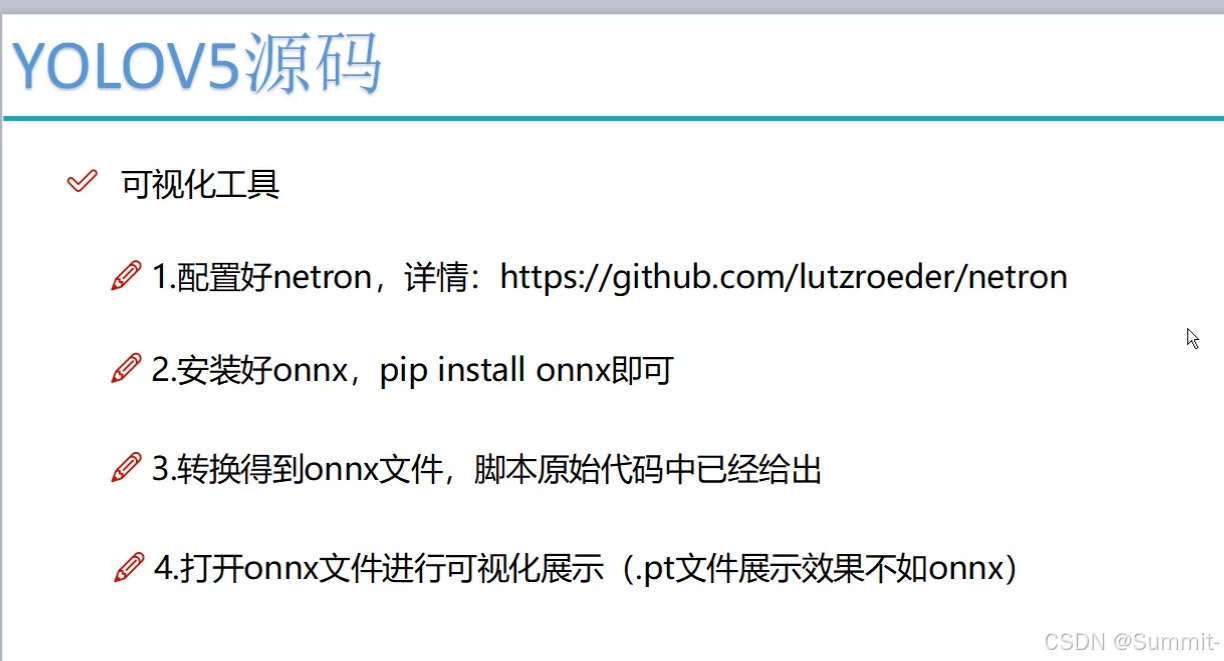
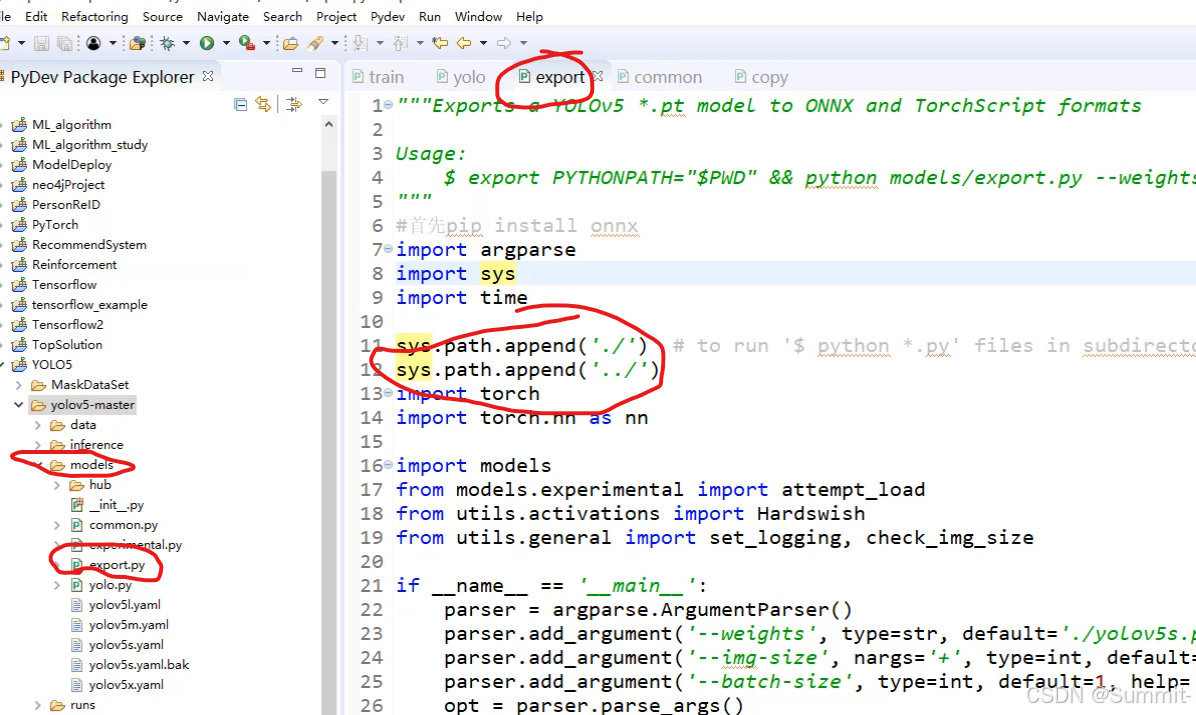
将训练好的模型图转化出来



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









