






数据库连接池、线程池、常量池 | 资源池化思想
在学习 Java 开发的过程中不可避免的就是链接数据库,定义常量,多线程开发,但为什么那么做那,不同的资源池到底有多大的影响,这个问题之前从来没考虑过,资源池化为了什么? 有那些好处?如何正确的配置相关参数?
为什么要使用数据库链接池、使用常量池、使用线程池?
使用数据库连接池、常量池和线程池是为了提升程序的性能、可维护性和稳定性:
- 数据库连接池:
- 性能提升:数据库连接的建立是一个相对耗时的操作。连接池会在应用程序启动时创建一定数量的数据库连接,而不是在每次请求时都重新建立连接。这样可以大幅减少了连接和断开的开销,提升了数据库访问性能。
- 资源重复利用:连接池可以重复使用已经创建的连接,而不是每次都新建一个连接。这有效地减少了系统对数据库的访问压力。
- 防止资源耗尽:连接池可以控制连接的数量,避免了因为连接过多而导致系统资源耗尽。
- 常量池:
- 提升代码可读性:通过常量池,可以将一些固定的数值或者字符串抽象出来,以常量的形式存在。这样在代码中使用这些常量,可以使代码更加清晰易读,也便于后期维护。
- 避免硬编码:将常量放入常量池,避免了在代码中直接硬编码常量,使得代码更具可读性和可维护性。
- 线程池:
- 资源复用:线程池可以避免不必要的线程创建和销毁开销,提高了资源的利用率。而且线程可以被重复使用,避免了频繁地创建和销毁线程所带来的性能损耗。
- 控制并发度:线程池可以控制同时运行的线程数量,防止因为创建过多线程导致系统资源耗尽。
- 提高响应速度:通过线程池,可以实现异步处理,提高了程序的响应速度。
共同一点, 统一管理,重复使用, 带来的好处就是资源使用效率得到了提升,响应速度更快,同时对资源最大数进行控制.
数据库连接池
常用的数据库链接池
- HikariCP:
- HikariCP 是一个高性能的开源连接池,相比其他连接池具有更低的内存占用和更快的性能。
- 它是许多Java项目的首选连接池,特别是在Spring Boot等现代Java应用中。
- Apache Commons DBCP:
- Apache Commons DBCP 是Apache开源组织提供的一个开源连接池项目。
- 它提供了一个简单的连接池实现,适用于一般的数据库连接需求。
- C3P0:
- C3P0 是一个比较老牌的连接池实现,提供了丰富的配置选项和可靠的性能。
- Druid:
- Druid 是阿里巴巴开源的数据库连接池项目,提供了监控、统计等丰富的功能。
- 它是一个功能强大、性能优越的连接池实现。
- Tomcat JDBC Pool:
- Tomcat 自带的 JDBC 连接池,提供了一种在独立环境中使用的高性能连接池。
- H2 Database:
- H2 是一个嵌入式数据库,也提供了一个简单但高效的连接池,适合于嵌入式应用和小型应用。
- BoneCP:
- BoneCP 是另一个性能出色的开源连接池,特点是简单易用。
- Vibur DBCP:
- Vibur DBCP 是一个快速、稳定的连接池,具有低的内存消耗。
- Bitronix Transaction Manager:
- BTM 提供了一个高性能的连接池,专门为支持JTA(Java事务API)的应用程序设计。
使用过 C3P0 Druid HikariCP(默认我一直不知道)
查看数据源配置源码


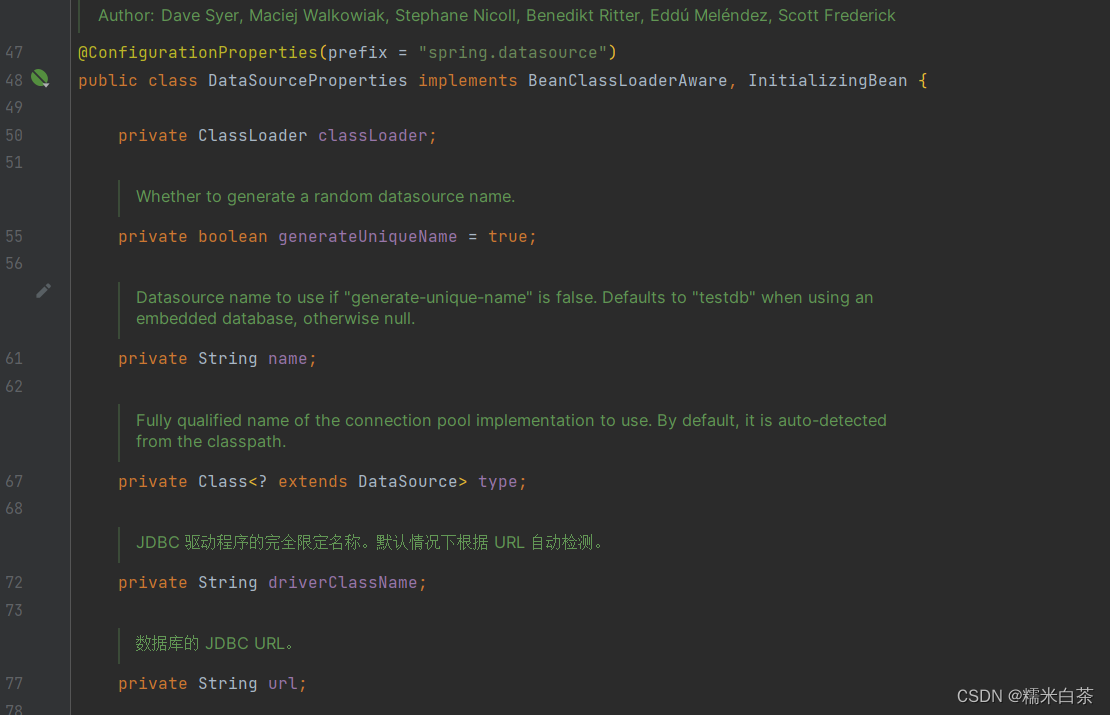
发现该配置包和其所在的位置,找到一些可配置的参数
- 按 ctrl 点击响应的 yml 配置
- 查看所属包的位置,(简单了解包是通过哪个依赖引入的,长时间的积累这种习惯可以更好的掌握代码结构框架)
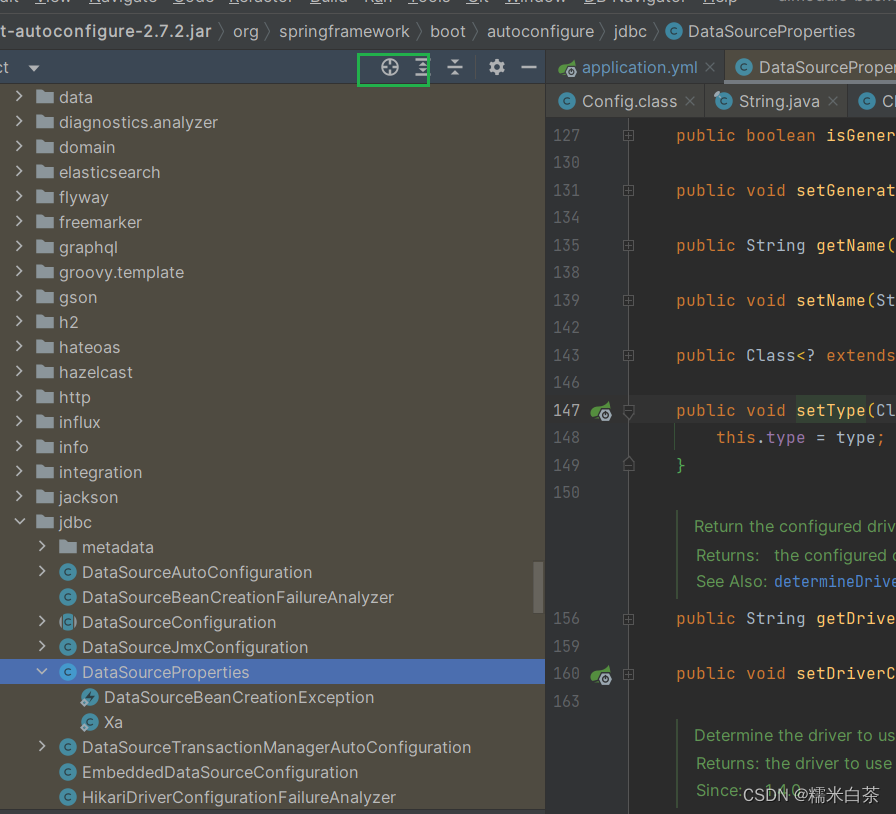
@ConfigurationProperties(prefix = "spring.datasource") 这个注解加配置是实现配置 yml 注入参数的一种方式,通常sdk 的编写需要引入相关包依赖,例如拼写提示
ps: api 签名调用sdk 编写发布会专门整理笔记的
查看参数详情
/**
* Fully qualified name of the connection pool implementation to use. By default, it
* is auto-detected from the classpath.
*/
private Class<? extends DataSource> type;
/**
* Fully qualified name of the JDBC driver. Auto-detected based on the URL by default.
*/
private String driverClassName;
/**
* JDBC URL of the database.
*/
private String url;
/**
* Login username of the database.
*/
private String username;
/**
* Login password of the database.
*/
private String password;
type 和 driverClass 是我们主要关注的两个参数
在Spring Boot中,
type和driver-class-name这两个配置项分别对应于数据源的不同设置。
type:
作用:
type属性指定了要使用的数据源类型。Spring Boot支持多种数据源,包括:
com.zaxxer.hikari.HikariDataSource(默认)org.apache.tomcat.jdbc.pool.DataSourcecom.alibaba.druid.pool.DruidDataSourceorg.apache.commons.dbcp2.BasicDataSource使用:你可以在
application.properties或application.yml中设置spring.datasource.type来指定要使用的数据源类型。例如:spring.datasource.type=com.zaxxer.hikari.HikariDataSource
driver-class-name:
作用:
driver-class-name配置项用于指定所使用数据库的JDBC驱动程序的类名。使用:你可以在
application.properties或application.yml中设置spring.datasource.driver-class-name来指定数据库驱动程序的类名。例如:spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver注意:在使用Spring Boot时,默认的数据源是HikariCP,它是一个高性能的JDBC连接池。因此,通常情况下你不需要显式地设置
driver-class-name,除非你需要使用特定的数据库驱动程序或自定义数据源。总结:
type指定了要使用的数据源类型(连接池实现),而driver-class-name用于指定JDBC驱动程序的类名。好吧是两种东西,连接池是我们具体要关注的东西,因为他是资源池化的主角.
些常见的 JDBC 驱动程序:
- MySQL Connector/J: 用于连接MySQL数据库。
- Oracle JDBC Driver: 用于连接Oracle数据库。
- PostgreSQL JDBC Driver: 用于连接PostgreSQL数据库。
- Microsoft JDBC Driver for SQL Server: 用于连接Microsoft SQL Server数据库。
- SQLite JDBC Driver: 用于连接SQLite数据库。
- H2 Database Engine: H2是一个嵌入式数据库,也提供了JDBC驱动。
- Derby Database: Apache Derby是一个Java关系数据库,也有相应的JDBC驱动。
- MariaDB Connector/J: 用于连接MariaDB数据库,它与MySQL兼容。
- DB2 JDBC Driver: 用于连接IBM DB2数据库。
- SAP HANA JDBC Driver: 用于连接SAP HANA数据库。
- Amazon Redshift JDBC Driver: 用于连接Amazon Redshift数据仓库。
- Snowflake JDBC Driver: 用于连接Snowflake云数据平台。
每个数据库都有自己的JDBC驱动程序,你需要根据你的项目所使用的具体数据库来选择合适的驱动程序。这些驱动程序通常由数据库供应商提供,也可以在Maven等构建工具的仓库中找到。
type 参数传入的数据库连接池到底做了什么?


等等 等等我没有看到他有显示的默认值啊,可是为什么我不写配置文件他有个默认实现那?
Spring Boot 自动配置机制
好吧先说明这是一个坑,大概了解一些,深入需要时间我也不太确定多久。
Spring Boot采用了一种自动配置(auto-configuration)的机制来简化项目的配置过程。
当你在application.properties或application.yml文件中没有显式指定数据源的实现类时,Spring Boot会根据类路径上的依赖自动选择一个默认的数据源。
在数据源的自动配置过程中,Spring Boot会依次检查类路径上是否存在以下数据源的依赖,如果找到则使用:
- HikariCP: HikariCP是一个高性能的JDBC连接池,是Spring Boot的默认选择。
- Tomcat CP (Tomcat Connection Pool): 如果没有发现HikariCP,Spring Boot会尝试使用Tomcat CP。
- Commons DBCP (Apache Commons Database Connection Pool): 如果上述两者都没有找到,Spring Boot会尝试使用Commons DBCP。
这种机制是通过Spring Boot的自动配置特性实现的。Spring Boot会根据类路径上的依赖以及应用的配置,自动配置所需的Beans。
如果你希望明确指定使用哪个数据源,可以在application.properties或application.yml文件中显式指定spring.datasource.type属性,如之前所示:
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
这样会覆盖自动配置机制,强制使用指定的数据源类型。
总的来说,Spring Boot的自动配置机制是基于一系列约定和规则,让开发者可以在不需要大量配置的情况下,快速搭建一个功能完善的应用。
总结 : 不知道大家注意了没,刚开始我说的包结构问题,可以猜测这个包内的所有选项都有这种机制,即我们不写 yml 配置,也会通过auto-configuration 来帮助我们实现快速初始化(可能比我们初始给个默认值要优雅,约定大于配置,配置大于编码嘛)。当然具体机制是个坑,嗯以后一定回填的,我相信。
整合 C3p0 查看参数
https://blog.csdn.net/xiaozhuangyumaotao/article/details/106245797
先上链接
跟着操作后成功换成 c3p0 的链接池,检查一下配置,发现成功更改了那几个参数.


引入 c3p0
依赖 pom
<!-- https://mvnrepository.com/artifact/com.mchange/c3p0 --> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>0.9.5.2</version> </dependency>更改 yml 配置
spring: datasource: type: com.mchange.v2.c3p0.ComboPooledDataSource driverClass: com.mysql.jdbc.Driver jdbcUrl: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8 user: root password: root maxPoolSize: 200 minPoolSize: 10 initialPoolSize: 10 acquireIncrement: 5 idleConnectionTestPeriod: 28000 maxIdleTime: 28000新建 数据源配置类
package com.yidiansishiyi.aimodule.config; import javax.sql.DataSource; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.jdbc.DataSourceBuilder; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter; @Configuration public class DataSourceConfiguration extends WebMvcConfigurerAdapter { @Bean(name = "dataSource") @Qualifier(value = "dataSource") @Primary @ConfigurationProperties(prefix = "spring.datasource") public DataSource dataSource(){ DataSource dataSource= DataSourceBuilder.create() .type(com.mchange.v2.c3p0.ComboPooledDataSource.class).build(); return dataSource; } }配置类详解
@Configuration: 这个注解表示这是一个配置类,它会被Spring容器扫描并加载,用于配置应用程序的一些组件。@Bean(name = "dataSource"): 这个注解告诉Spring容器,要创建一个名为"dataSource"的Bean,并将其纳入Spring的管理中。这个Bean将是一个数据源对象,用于管理数据库连接。@Qualifier(value = "dataSource"): 这个注解用于指定要注入的Bean的名称,通常用于解决多个相同类型的Bean存在时的歧义性。在这里,它确保将名为"dataSource"的Bean注入到需要数据源的地方。@Primary: 当有多个同一类型的Bean时,@Primary注解用于标识首选的Bean。如果多个数据源被定义,Spring将优先选择带有@Primary注解的数据源。@ConfigurationProperties(prefix = "spring.datasource"): 这个注解用于将application.properties或application.yml中以"spring.datasource"为前缀的属性值绑定到这个配置类中的属性。这些属性包括数据库的连接URL、用户名、密码等。
总结,翻译一下就是,告诉spring 我定义了一个新的 dataSource 的 Bean 我将要将他注册到名为 dataSource 的插槽里(如果没有的话根据 auto-configuration 机制会自动注入一个,然后通过注解 @Primary 来定义冲突时候首选这个,最后再来定义一下可以通过 yml 配置传入参数的路径 )
- 从结果上来看配置文件内的配置项确实有被加载进来,但是并没有看到如何注入使用这些参数的?
ComboPooledDataSource.class 就是问题的正解了,但是它很干净,没有看到具体实现啊,答案在它继承的抽象类中(其中提供了默认实现) ,如图所示 参数如何配置成功的也就可以理解了。
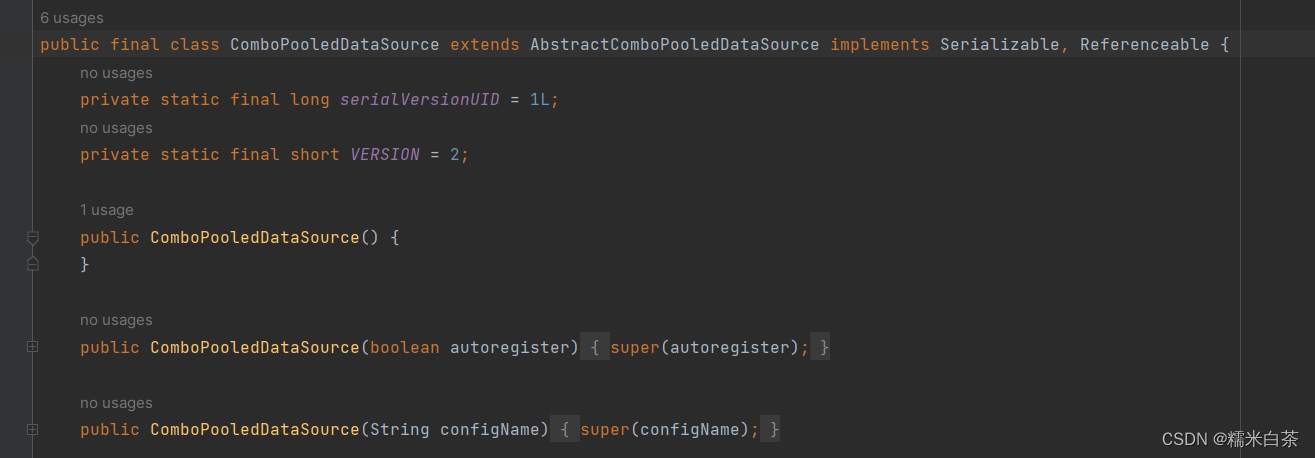
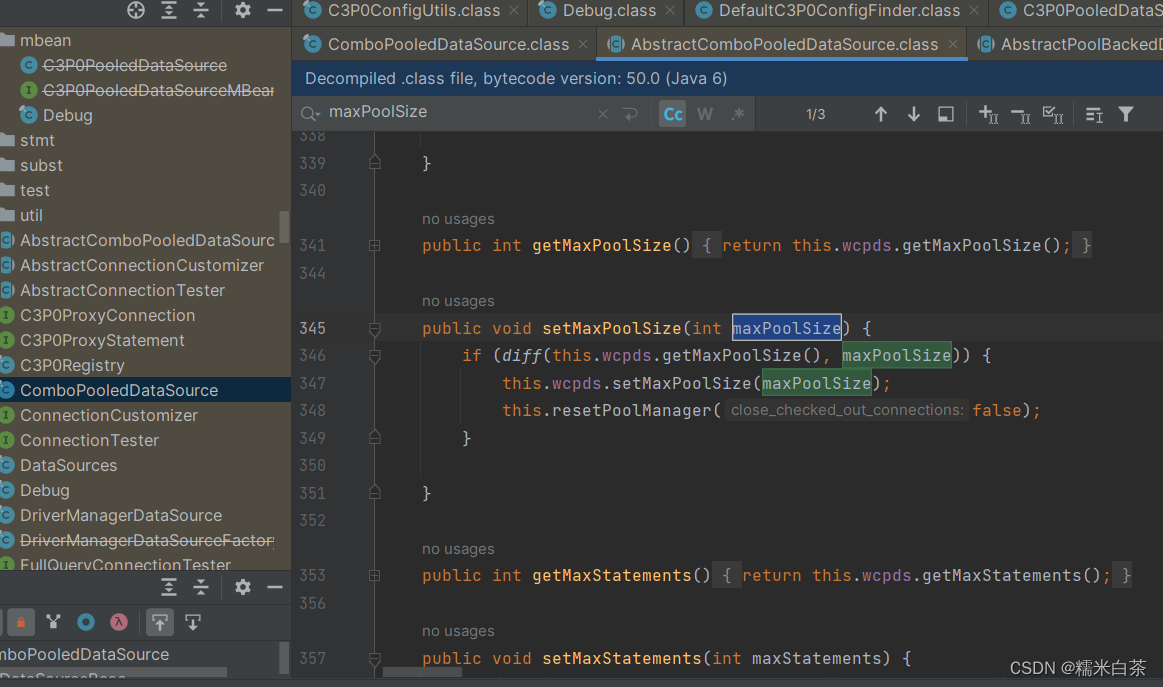
c3p0 配置项分析
这是一个典型的Spring Boot配置文件,用于配置数据源(DataSource)的参数。下面是各项配置的解释:
type: com.mchange.v2.c3p0.ComboPooledDataSource:
- 作用:指定了数据源的类型,这里是使用了 C3P0 连接池。
driverClass: com.mysql.cj.jdbc.Driver:
- 作用:指定了数据库驱动的类名,这里是 MySQL 的驱动。
jdbcUrl: jdbc:mysql://124.222.184.3/yidiansishiyi:
- 作用:指定了数据库的连接地址,包括了数据库类型(jdbc:mysql://)、主机地址(124.222.184.3)、数据库名(yidiansishiyi)等信息。
user: yidiansishiyi:
- 作用:指定了连接数据库的用户名。
password: zyeE75mZjmxm7XGT:
- 作用:指定了连接数据库的密码。
maxPoolSize: 521:
- 作用:指定了连接池中最大的连接数。当系统需要连接时,连接池中的连接数会自动增长,但不会超过这个值。
minPoolSize: 10:
- 作用:指定了连接池中最小的连接数。即使系统闲置,连接池中也会保持至少这么多的连接。
initialPoolSize: 10:
- 作用:指定了连接池在启动时创建的连接数。
acquireIncrement: 5:
- 作用:指定了当连接池中的连接耗尽时,一次同时获取的连接数。
idleConnectionTestPeriod: 28000:
- 作用:指定了连接在池中保持空闲的最长时间,超过这个时间会被回收。
maxIdleTime: 28000:
- 作用:指定了连接池中连接的最大空闲时间,超过这个时间连接会被销毁。
这些配置项是为了优化数据库连接的使用,比如通过连接池维护一组预先创建好的连接,避免了频繁创建和关闭连接的开销,同时也能控制连接的数量和超时时间,以保证系统的稳定性和性能表现。
数据库链接池总结 :
配置的作用是为了更好的发挥数据库的性能,池的作用就是定义最高上线,统一管理链接,是为了优化数据库的使用,而连接池的作用是管理和复用数据库连接,从而提高系统的性能和稳定性。连接池可以控制连接的数量,避免频繁创建和销毁连接,从而减轻数据库的压力,提升了系统的整体性能。按照 springboot 的机制默认链接池应该也会定义这些参数来达到更好的性能,同样找到了 。根据不同的业务和真实情况选择合适的数据库链接池,更改合适的链接配置需要相关的实际经验,当然大多数情况下不会追求机制的性能,不会关心相应的配置,但是有一个很好玩的思想,软件永远无法凌驾于硬件之上,但是好的却有利用率的不同,在牛逼的软件配置带不起来也是无用的,但是相应的,如果无法发挥全部性能,机器的性能再怎么强也是无用功。这块具体使用需要有很深的经验,最起码我现在做不到 qwq。不过要配置的化百度会有些大佬给出一些经验值。

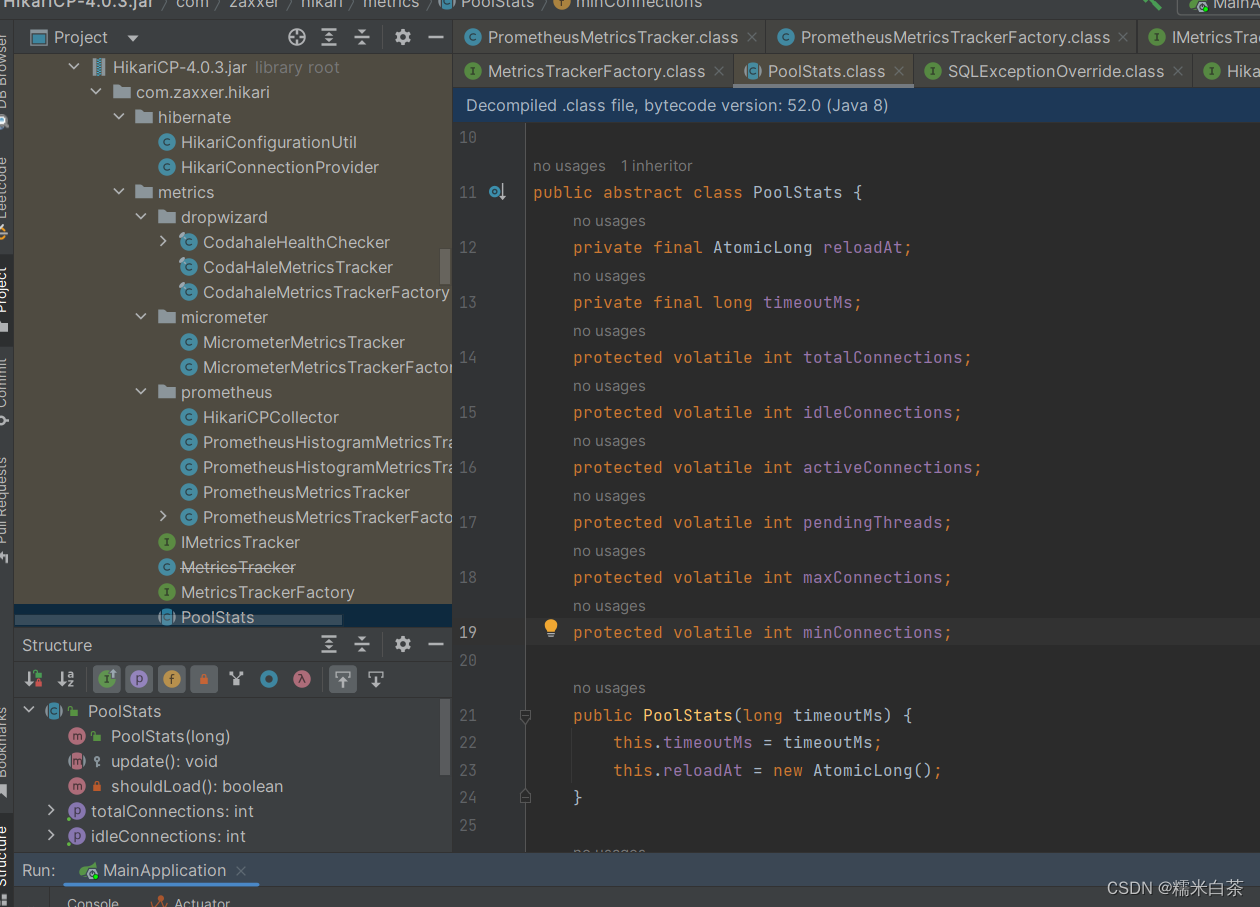
常量池
好吧这是一个坑 , 有关于 jvm 的我也就大概了解一些 ,不过思想还是同一个嘛,主打一个资源复用,限制最大占用资源范围。有时间回来填。
线程池
线程池的常见知识点
- 为什么使用线程池:
- 资源控制:限制同时执行的线程数量,避免资源耗尽。
- 提高性能:线程的创建和销毁是有开销的,线程池可以复用已经创建的线程,减少了这种开销。
- 任务队列:可以将任务排队,等待线程池中的线程来执行,避免任务过多导致系统崩溃。
- 线程池的参数:
- corePoolSize:线程池的基本大小,即保持活跃的线程数量,即使它们处于空闲状态。
- maximumPoolSize:线程池的最大大小,包括活跃和等待的线程。
- keepAliveTime:非核心线程的空闲时间,超过这个时间就会被回收。
- workQueue:用于保存等待执行的任务的阻塞队列。
- 工作流程:
- 当一个新任务提交给线程池时,线程池会检查核心线程是否已满。
- 如果未满,将创建新线程来执行任务。
- 如果已满,任务将被放入工作队列中等待执行。
- 如果工作队列也满了,而线程池中的线程数又未达到最大值,会创建新的非核心线程来执行任务。
- 如果工作队列和线程池的线程数都满了,会执行拒绝策略。
- 拒绝策略:
- AbortPolicy:默认的拒绝策略,会抛出
RejectedExecutionException异常。 - CallerRunsPolicy:在任务提交者的线程中执行任务。
- DiscardPolicy:直接丢弃任务,不做任何处理。
- DiscardOldestPolicy:丢弃等待队列中最旧的任务,然后尝试重新提交任务。
- AbortPolicy:默认的拒绝策略,会抛出
- 线程池的类型:
- FixedThreadPool:固定数量的线程池,corePoolSize 和 maximumPoolSize 值相等,工作队列使用 LinkedBlockingQueue。
- CachedThreadPool:可缓存的线程池,corePoolSize 为0,maximumPoolSize 为 Integer.MAX_VALUE,适用于执行大量短期异步任务的情况。
- ScheduledThreadPool:定时任务的线程池。
- 使用Executor框架:
Executor和ExecutorService接口提供了更高级别的抽象,可以更方便地管理线程池。
- Java中的实现:
- Java 提供了
java.util.concurrent.Executors类,可以方便地创建不同类型的线程池。
- Java 提供了
- 最佳实践:
- 根据应用的需求选择合适的线程池类型和参数,避免过度配置。
- 注意线程安全,避免共享资源的竞态条件。
在Java中,常用的线程池实现包括:
- FixedThreadPool:
- 固定大小的线程池,所有任务将在同一时间内执行,直到达到最大线程数。
- 使用
Executors.newFixedThreadPool(int n)创建。
- CachedThreadPool:
- 根据需要创建新线程的线程池,但在先前构建的线程可用时将重用它们。
- 可以灵活地回收空闲线程,适用于执行许多短期异步任务的情况。
- 使用
Executors.newCachedThreadPool()创建。
- SingleThreadExecutor:
- 只有一个线程的线程池,所有任务按顺序执行。
- 使用
Executors.newSingleThreadExecutor()创建。
- ScheduledThreadPool:
- 延迟或定时执行任务的线程池。
- 使用
Executors.newScheduledThreadPool(int corePoolSize)创建。
- WorkStealingPool(Java 8+):
- Java 8 引入的一种线程池,用于执行 ForkJoinTask 任务。
- 通过
ForkJoinPool.commonPool()获取。
- FixedScheduledThreadPool(Java 8+):
- 一种固定大小的定时任务线程池。
- 使用
Executors.newFixedScheduledThreadPool(int corePoolSize)创建。
- SingleThreadScheduledExecutor(Java 8+):
- 类似于SingleThreadExecutor,但可以执行延迟或定时任务。
- 使用
Executors.newSingleThreadScheduledExecutor()创建。
- ForkJoinPool:
- 用于执行
ForkJoinTask的线程池,通常用于解决大规模任务的并行处理。 - 通过
new ForkJoinPool(int parallelism)构造。
- 用于执行
- ThreadPoolExecutor(定制):
- 可以根据需求自定义参数的线程池。
- 使用
ThreadPoolExecutor类进行构建。
吐槽一下,并发编程这一块还没搞明白,一些使用多线程的场景还是比较清楚的,比如响应时间过长,分片处理,守护线程监视任务进度等等。在处理IO密集型任务(如网络请求)或者大量计算密集型任务(如数据处理)时,使用多线程可以显著提升程序的性能。还需要深入学习整理知识点,但暂时只讨论资源池化思想。
使用 Java 并发包自定义线程
先上一种实现的代码 , 当然这个肯定不是最优解法
yml 配置
spring:
thread:
pool:
capacity: 40
maximum-pool-size: 16
keep-alive-time: 30
core-pool-size: 8
配置类
package com.yidiansishiyi.aimodule.config;
import lombok.Data;
import org.jetbrains.annotations.NotNull;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.*;
@Data
@Configuration
@ConfigurationProperties(prefix = "spring.thread.pool")
public class ThreadPoolExecutorConfig {
private Integer corePoolSize,maximumPoolSize,capacity;
long keepAliveTime;
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadFactory threadFactory = new ThreadFactory() {
private int count = 1;
@Override
public Thread newThread(@NotNull Runnable r) {
Thread thread = new Thread(r);
thread.setName("线程" + count);
count++;
return thread;
}
};
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(capacity), threadFactory);
return threadPoolExecutor;
}
}
使用
使用之前配置类中注入到 spring 中的 threadPoolExecutor (这是咱自定义的)
使用默认的执行器,应该会有默认的配置,最大链接数之类的
@Resource
private ThreadPoolExecutor threadPoolExecutor;
@Override
public BiResponse genChartByAiAsync(MultipartFile multipartFile, GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {
User loginUser = userService.getLoginUser(request);
HashMap<String, String> userInputs = this.getUserInput(multipartFile, genChartByAiRequest);
// 插入到数据库
Chart chart = new Chart();
chart.setName(genChartByAiRequest.getName());
chart.setGoal(genChartByAiRequest.getGoal());
chart.setChartData(userInputs.get("csvData"));
chart.setChartType(genChartByAiRequest.getChartType());
chart.setStatus("wait");
chart.setUserId(loginUser.getId());
boolean saveResult = this.save(chart);
ThrowUtils.throwIf(!saveResult, ErrorCode.SYSTEM_ERROR, "图表保存失败");
// todo 建议处理任务队列满了后,抛异常的情况
CompletableFuture.runAsync(() -> {
// 先修改图表任务状态为 “执行中”。等执行成功后,修改为 “已完成”、保存执行结果;执行失败后,状态修改为 “失败”,记录任务失败信息。
Chart updateChart = new Chart();
updateChart.setId(chart.getId());
updateChart.setStatus("running");
boolean b = this.updateById(updateChart);
if (!b) {
handleChartUpdateError(chart.getId(), "更新图表执行中状态失败");
return;
}
// 调用 AI
String result = getAiGenerateChart(userInputs.get("userInput"));
Chart updateChartResult = new Chart();
String genResult = "",genChartNew = "";
if (StringUtils.isNotBlank(result)){
String[] splits = result.split("【【【【【");
String genChart = splits[1].trim();
genChartNew = DataCleaningUtils.extractJsonPart(genChart);
genResult = splits[2].trim();
chart.setGenChart(genChartNew);
chart.setGenResult(genResult);
}
updateChartResult.setId(chart.getId());
updateChartResult.setGenChart(genChartNew);
updateChartResult.setGenResult(genResult);
// todo 建议定义状态为枚举值
updateChartResult.setStatus("succeed");
boolean updateResult = this.updateById(updateChartResult);
if (!updateResult) {
handleChartUpdateError(chart.getId(), "更新图表成功状态失败");
}
}, threadPoolExecutor);
BiResponse biResponse = new BiResponse();
biResponse.setChartId(chart.getId());
return biResponse;
}
CompletableFuture 介绍
CompletableFuture 是 Java 8 中引入的一个类,用于简化异步编程。它提供了一种简单而强大的方式来处理异步任务的结果。
以下是一些 CompletableFuture 的重要特性:
- 异步执行任务: 你可以将一个任务交给
CompletableFuture异步执行,而不会阻塞主线程。 - 链式操作: 你可以将多个操作链接在一起,形成一个操作链,这样一个操作的结果会作为下一个操作的输入。
- 异常处理: 可以轻松地处理异常情况,确保在任务完成时得到通知,而不管它是正常完成还是出现异常。
- 组合多个 CompletableFuture: 可以等待多个
CompletableFuture完成后再进行下一步操作。 - 超时处理: 可以设置一个超时时间,如果任务在规定时间内未完成,可以执行相应的操作。
- 同时执行多个任务: 可以同时执行多个任务,并在所有任务完成后进行后续操作。
下面是一个简单的示例,演示了如何使用 CompletableFuture:
javaCopy codeimport java.util.concurrent.CompletableFuture;
public class CompletableFutureExample {
public static void main(String[] args) {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello")
.thenApplyAsync(result -> result + " World")
.thenApplyAsync(result -> result + "!");
future.thenAcceptAsync(System.out::println);
// 等待任务完成
future.join();
}
}
在这个例子中,我们首先通过 supplyAsync 异步执行一个任务,返回一个 CompletableFuture。接着使用 thenApplyAsync 方法,将一个转换函数应用于前一个阶段的结果,得到一个新的 CompletableFuture。最后,我们通过 thenAcceptAsync 定义了一个消费者,用于处理最终的结果。
这只是 CompletableFuture 的一个简单示例,它提供了许多强大的功能来处理各种异步编程场景。
ThreadPoolExecutor 执行器参数
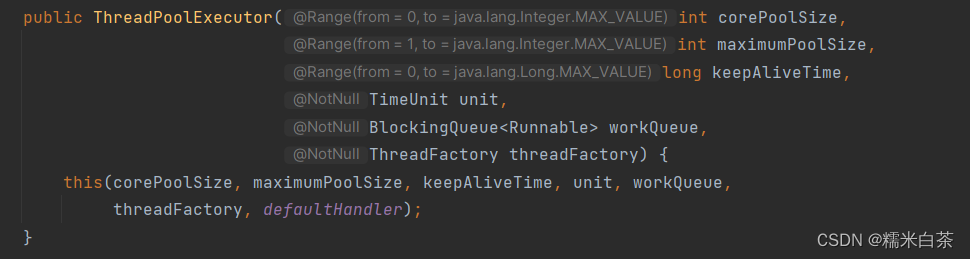
corePoolSize: 这是线程池的基本大小,也就是在没有任务执行时,线程池的大小保持在这个水平。即使线程是空闲的,也不会被回收。maximumPoolSize: 这是线程池允许的最大线程数。当线程池中的线程数大于corePoolSize并且工作队列已满时,线程池会创建新的线程,直到达到这个最大值。keepAliveTime: 当线程池中的线程数大于corePoolSize时,多余的空闲线程的存活时间。如果超过这个时间,空闲线程将被终止。unit:keepAliveTime参数的时间单位,通常是秒、毫秒等。workQueue: 这是一个阻塞队列,用于存储等待执行的任务。当任务提交到线程池时,如果线程池中的线程数小于corePoolSize,则会创建新线程来执行任务。如果线程池中的线程数大于等于corePoolSize,则将任务放入到workQueue中等待执行。threadFactory: 这是一个线程工厂,用于创建新的线程。通常用于指定线程的命名规则、优先级等。defaultHandler: 这是一个拒绝策略,当工作队列和线程池都满了,无法继续执行新的任务时,会调用该策略来处理。默认情况下是抛出RejectedExecutionException异常。
总结
可以看出来 资源池化思想在很多场景下都会使用他们主要有大概以下几点的相通处和有点
- 最大容量和最小容量:这两个参数是资源池的基础。最小容量确保在低负载时也有足够的资源可用,保证了系统的稳定性。最大容量则限制了资源的使用,防止过度消耗服务器资源。
- 增加策略:这决定了何时以及如何向池中添加新的资源。增加策略可以基于多种条件,例如当前资源使用率、请求等待时间等。通过合理的增加策略,可以动态地调整资源池的大小,以满足系统的实际需求。
- 减小策略:减小策略用于在资源不再需要时释放它们。这可以防止资源的浪费和滥用。一个有效的减小策略可以保证资源能够及时地被回收,从而释放出更多的系统资源。
- 异常处理:处理异常情况是确保系统稳定性的重要一环。当资源出现故障或不可用时,正确的处理方式可以避免系统崩溃或严重延迟。这可能包括重新尝试、降级处理或者报警通知等。
- 监控和统计:对资源池的监控和统计是保证其正常运行的关键。通过实时监控资源的使用情况,可以及时发现并解决潜在的问题,从而提高系统的稳定性和性能。
- 合理配置参数:针对具体的应用场景和负载特性,合理地配置资源池的参数是非常重要的。例如,最大容量、最小容量、增加策略的阈值等,都需要根据实际情况进行调整。
- 资源的有效性检测:定期检测资源的有效性是保证系统稳定性的重要手段之一。通过定期检测资源的可用性,可以及时发现并处理无效的资源,防止其对系统造成影响。
我想到一个每个人可能都会遇见但当时可能觉得很脑残的问题
注水问题,一边注水一遍放水
资源池 = 游泳池
排水口 = 线程池内的工作线程 , 连接池中的链接(资源)
排水 = 工作内容但是还有些使用时候的问题,例如配置,这些都不是有一个固定解法的,需要去尝试,去积累经验,去看去做每一台机器可能都有它的脾气,每一个版本的软件(数据库) 也会有他的脾气,很复杂。 总之资源池化的思想在很多场景下都会见到,平时也可以尝试使用这种思想更好的完成工作。
遗留问题
- 常量池
- auto-configuration
- 链接池链接数据库时候具体事项
- 性能测试,找到复合条件的链接配置
- juc 编程
- 自动装配机制
- 资源池化的工作运用实战

















 4803
4803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









